CutClaw: Agentic Hours-Long Video Editing via Music Synchronization
Paper: arXiv:2603.29664 Code: GVCLab/CutClaw Code reference:
main@db48d08b(2026-04-17)
1. Motivation (研究动机)
长视频剪辑与音乐同步是高频但高度重复的创作任务:人类剪辑师需要从 1–3 小时素材中找镜头、理解剧情/人物、贴合音乐节拍并保证叙事连贯。现有自动剪辑或 moment retrieval 方法多处理短视频片段,缺少对 hours-long footage 的结构化理解,也很难把 music rhythm 变成精确 cut points。
本文想解决的具体问题是:给定长视频、目标音乐和文本剪辑指令,自动生成一个短视频 timeline,使画面语义符合指令、镜头叙事连贯,并在节拍/段落上与音乐对齐。
这个问题值得研究,因为它把 multimodal understanding、agent planning、temporal grounding 和 audio-visual synchronization 结合到一个真实 production workflow 中;解决后可以显著降低影视/VLOG/music video 的人工剪辑成本。
2. Idea (核心思想)
核心 insight 是把 hours-long editing 拆成“bottom-up deconstruction + music-anchored planning + top-down grounding + reviewer gate”:先把连续视频/音频离散成可检索结构,再让 Playwriter 用音乐结构做叙事骨架,Editor 在限定场景内找精确片段,Reviewer 拒绝不合法或低质量结果。
关键创新不是单个 VLM 模型,而是一个多 agent 协作流程:视频被聚合成 shots/scenes,音频被解析成 downbeat/pitch/spectral keypoints 和 sections,shot plan 只输出约束而不是最终时间戳,最终由 ReAct-style Editor 反复调用 retrieval/trim/review 工具落地。
与 NarratoAI 的 subtitle-driven editing 或 UVCOM/Time-R1 的 moment retrieval 不同,CutClaw 同时优化 narrative instruction、visual quality 和 music synchronization;baseline 往往能找到相关片段,但无法保持节奏结构和跨镜头叙事。
3. Method (方法)
3.1 Overall framework
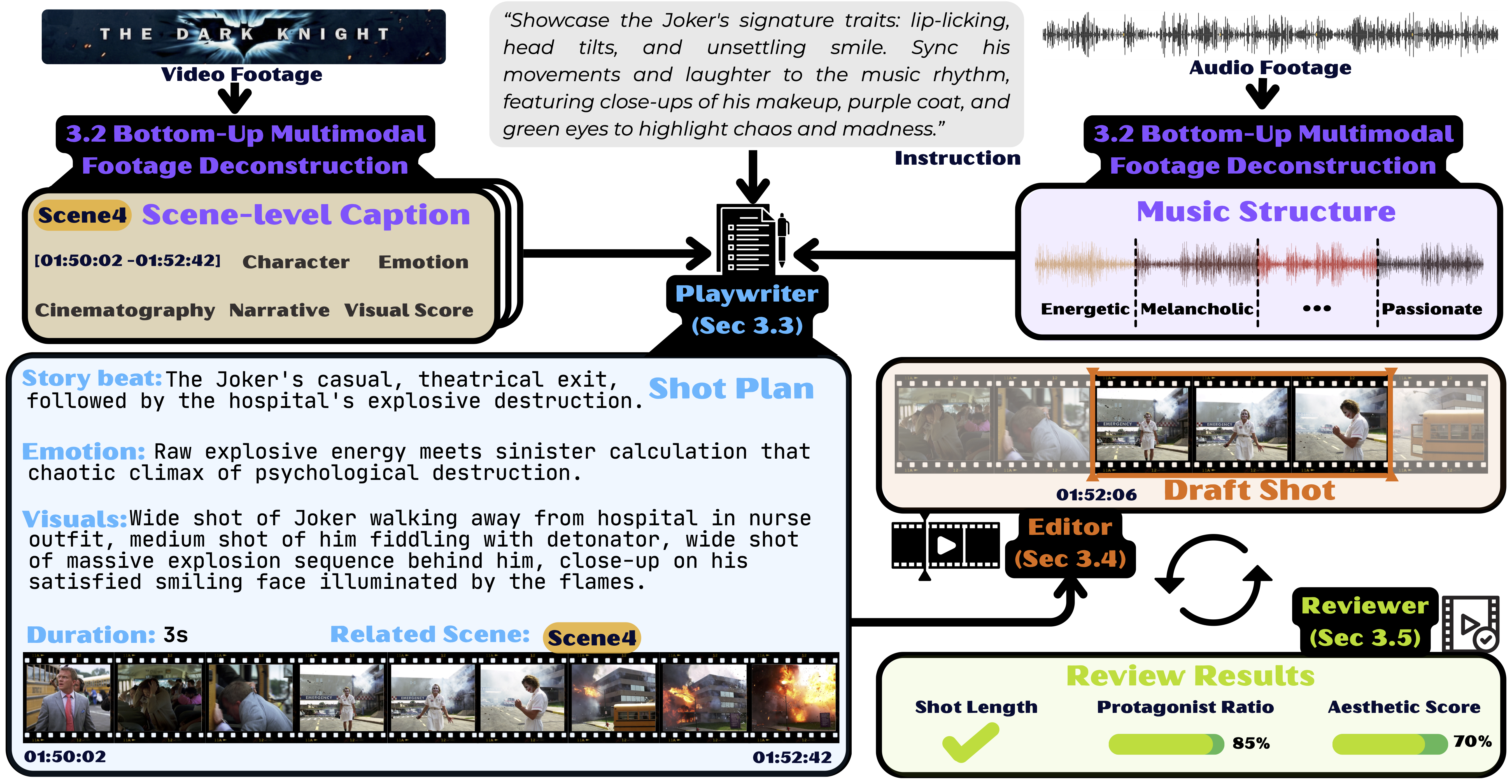
Figure 1 解读:CutClaw 从 Video Footage、Audio Footage 和 Instruction 三路输入开始。底部左侧做 scene-level caption,右侧做 music structure;Playwriter 生成 draft shot plan,Editor 根据 related scenes 找候选镜头,Reviewer 检查 shot length、protagonist ratio、aesthetic score 后决定是否接受或退回。这个闭环把高层叙事和低层时间戳定位分开。
总体目标把 final timeline $\mathcal{E}=(c_1,\dots,c_N)$ 写成多目标最大化:
直觉上,音乐同步不能在最后“微调时间戳”解决,因为镜头选择本身就要受音乐段落、情绪和节拍约束。CutClaw 因此先用音频结构决定 temporal skeleton,再把视觉素材填入这个 skeleton,减少全局搜索复杂度。
3.2 Bottom-up multimodal footage deconstruction

Figure 2 解读:视频侧先用 shot boundary detection 切出 atomic shots,再用 Qwen3-VL 给每个 shot 生成环境、人物、摄影、动作、字幕等属性;相邻 shots 通过语义相似度聚合成 scenes。这样 hours-long footage 被压缩成 scene-level searchable database,后续 agent 不需要把整段视频塞进上下文窗口。
音频侧把连续音乐解析成 keypoints:downbeats $\mathcal{K}_{db}$、pitch changes $\mathcal{K}_{pc}$、spectral energy changes $\mathcal{K}_{se}$,合成候选池并过滤:
每个时间点的强度可写为:
3.3 Playwriter: music-anchored script synthesis
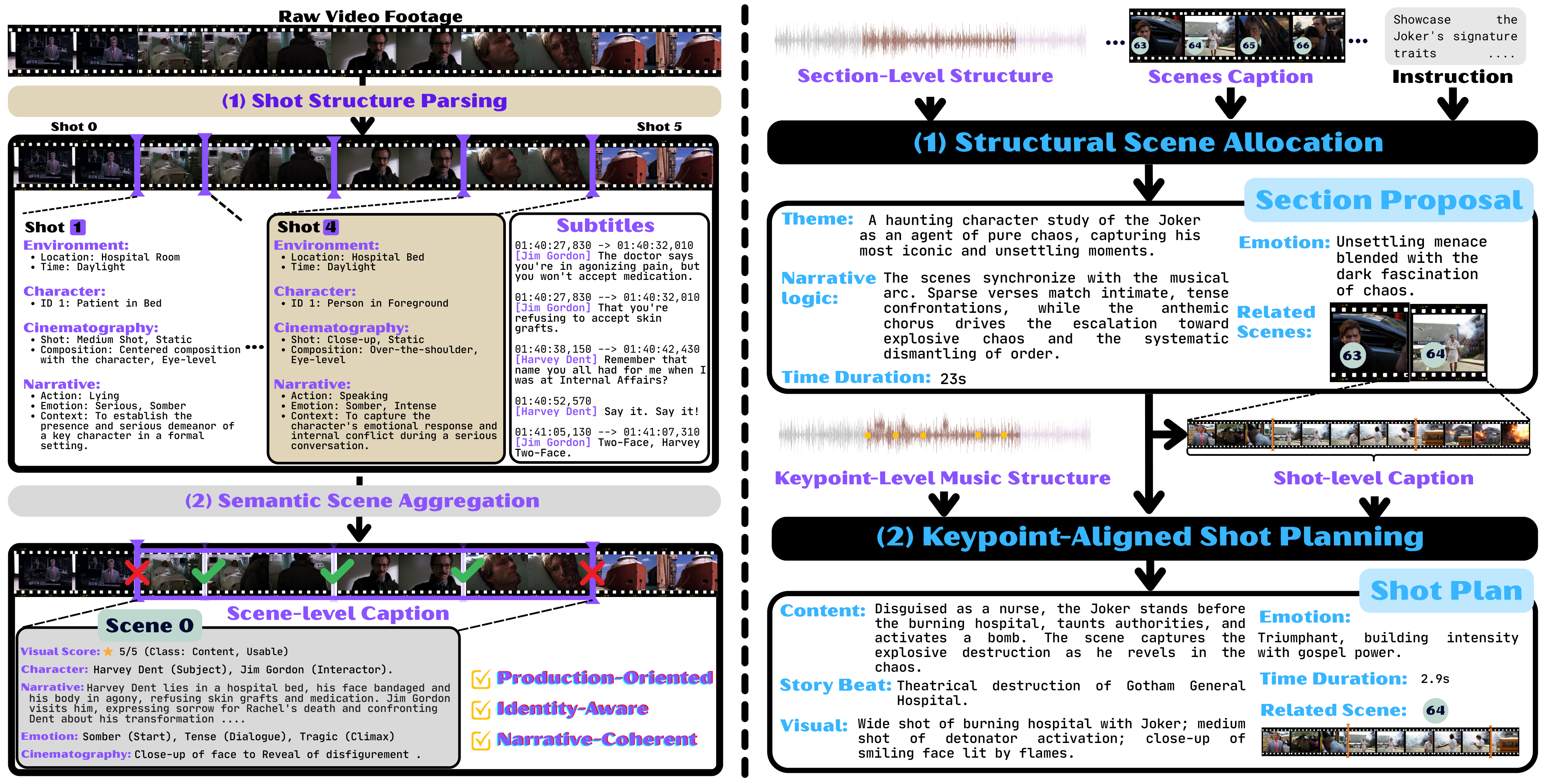
Figure 3 解读:左侧展示 shot-to-scene 聚合,右侧展示 Playwriter 的两步:先把音乐 section 映射到候选 visual scenes,生成 Section Proposal;再把每个 keypoint-level music segment 转成 shot-level caption、duration 和 related scene constraint。Playwriter 不直接输出最终剪辑时间戳,而是输出可由 Editor 执行的局部检索约束。
全局 scene allocation 写作:
并强制不同 music units 不复用同一 scene:
这个 disjoint resource allocation 是为了避免视觉重复,让音乐段落之间有明确叙事推进。
3.4 Editor and Reviewer
Editor 是 ReAct-style agent。对每个 shot spec $p_i=(\tau_i,z_{id},d_i)$,它先在推荐 scene 附近检索,再调用 fine-grained trimming 分析候选片段,最后提交一个连续时间范围。若局部 scene 不够,搜索空间可扩展:
最终 clip 选择可理解为在满足时长 $|c|=\tau_i$ 的候选中最大化 aesthetic 和 protagonist ratio:
Reviewer 是 rejection sampling gate,检查 protagonist identity/presence、时间重叠、duration tolerance、aesthetic quality 和 transition validity。released code 中 review_clip 先检查与已用片段是否 overlap,review_finish 再验证是否只输出一个连续 shot 且时长匹配。

Figure 4 解读:这是一次具体执行 trace:agent 先根据 music section 读取 shot plan,再通过搜索/裁剪/检查工具多轮选择片段;错误候选会被 review 拦下,最终形成多个与音乐 keypoint 对齐的 clips。它说明 CutClaw 的“agentic”不是泛称,而是具体体现在多轮 tool calls 和 rejection gate。
3.5 Qualitative comparison

Figure 5 解读:上半部分对比 music synchronization,下半部分对比 narrative-driven instruction。CutClaw 的 clips 在节奏段落和视觉语义上更连贯;UVCOM/Time-R1 容易选到视觉相关但节奏错位的片段,NarratoAI 依赖字幕时在 VLOG 或少对白场景中受限。
3.6 Source-based pseudocode
import json
def build_scene_database(video_path, scene_folder):
shots = pyscenedetect(video_path, fps=2.0)
shot_records = []
for shot in shots:
attrs = qwen3_vl_caption(shot.frames, fields=["environment", "character", "motion", "cinematography"])
subtitles = whisper_v3_turbo(shot.audio)
shot_records.append({"time": shot.time_range, "attrs": attrs, "subtitles": subtitles})
scenes = aggregate_adjacent_shots(shot_records, similarity_threshold=0.5, min_len_sec=30.0, max_len_sec=300)
save_json_scenes(scene_folder, scenes)
return scenes
def generate_music_anchored_shot_plan(scene_folder, audio_json, instruction, main_character):
proposal = generate_structure_proposal_with_retry(
video_scene_path=scene_folder,
audio_caption_path=audio_json,
user_instruction=instruction,
main_character=main_character,
)
plan = []
for section in proposal["sections"]:
music_segments = load_keypoint_segments(audio_json, section["audio_range"])
shot_plan = generate_shot_plan_with_retry(
music_segments,
section,
scene_folder_path=scene_folder,
user_instruction=instruction,
main_character=main_character,
)
plan.extend(shot_plan["shots"])
return plan
def edit_one_shot(editor, shot, used_ranges):
candidates = semantic_neighborhood_retrieval(
related_scenes=shot.get("related_scenes"),
recommended_scenes=shot.get("related_scenes"),
scene_folder_path=editor.video_scene_path,
)
analysis = fine_grained_shot_trimming(
time_range=choose_candidate_range(candidates, target_duration=shot["time_duration"]),
frame_path=editor.frame_folder_path,
transcript_path=editor.transcript_path,
)
proposed = select_best_range(analysis, target_duration=shot["time_duration"])
overlap_result = review_clip(proposed, used_time_ranges=used_ranges)
finish_result = editor.reviewer.review_finish(proposed, target_length_sec=shot["time_duration"])
if "OK" in overlap_result and "success" in finish_result.lower():
commit(proposed)
used_ranges.append(parse_seconds(proposed))
return proposed
return None
def cutclaw_pipeline(video_path, music_path, instruction):
scenes = build_scene_database(video_path, scene_folder="scene_summaries_video")
audio_json = parse_music_structure(music_path, methods=["downbeat", "pitch", "mel_energy"])
shot_plan = generate_music_anchored_shot_plan("scene_summaries_video", audio_json, instruction, main_character="")
editor = EditorCoreAgent("captions.json", "scene_summaries_video", audio_json, "timeline.json", max_iterations=4)
used_ranges, timeline = [], []
for shot in shot_plan:
clip = edit_one_shot(editor, shot, used_ranges)
if clip is not None:
timeline.append(clip)
return render_video(video_path, timeline, music_path)Code reference:
main@db48d08b(2026-04-17) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Scene search / editor tools | src/core.py | semantic_neighborhood_retrieval, fine_grained_shot_trimming, review_clip, commit |
| Editor ReAct agent | src/core.py | EditorCoreAgent, ParallelShotOrchestrator |
| Playwriter structure proposal / shot plan | src/Screenwriter_scene_short.py | generate_structure_proposal_with_retry, generate_shot_plan_with_retry, Screenwriter |
| Reviewer gate | src/Reviewer.py | review_clip, review_finish, ReviewerAgent |
| Runtime defaults | src/config.py | VIDEO_FPS, VIDEO_RESOLUTION, AUDIO_DETECTION_METHODS, ENABLE_REVIEWER, SCENE_EXPLORATION_RANGE |
| Rendering final timeline | render/render_video.py | video composition utilities |
论文公式与 released code 实现差异:论文实验写明 inference 时 video footage downsample 到 short-side 360p、2 FPS;released code src/config.py 默认 VIDEO_RESOLUTION=240、VIDEO_FPS=2。因此复现实验时不能只用默认 config,需要显式把 resolution 调到论文设置或记录差异。
4. Experimental Setup (实验设置)
- Datasets:benchmark 包含 10 个 source pairs,来自 5 部 feature-length films 和 5 个 long-duration VLOGs;每段 raw footage 长 1–3 小时,总计约 24 小时;音频为 10 个 segmented music tracks,覆盖 Pop/Jazz/OST/Rock/R&B;目标短视频 20 秒到 1 分钟;每个 pair 有 Character-Centric 与 Narrative-Centric 两类指令,总计 20 个 evaluation cases。
- Baselines:NarratoAI(subtitle-driven editing;不适用于缺少密集字幕的 VLOG)、UVCOM(moment retrieval)、Time-R1(temporal grounding)。
- Evaluation metrics:Visual Quality 与 Instruction Follow 由 GPT-5.2 评分;AV Harmony 用 audio onset 与 video scenes 的最小 temporal offset
$\Delta t$量化,并严格奖励$\Delta t\le0.1s$;user study 还评估 Human-Likeness。 - Implementation / config:论文使用 MiniMax-M2.1 作为 Editor/Reviewer,Gemini3-Pro 作为 Playwriter,PySceneDetect 做 shot boundary,Whisper-v3-turbo 做 ASR,Qwen3-VL-30B-A3B 做 visual captioning,Qwen3-Omni-30B-A3B 做 music captioning。released code 默认
VIDEO_FPS=2,SHOT_DETECTION_FPS=2.0,SCENE_MIN_LENGTH_SECS=30,MAX_SCENE_DURATION_SECS=300,AUDIO_DETECTION_METHODS=[downbeat,pitch,mel_energy],AGENT_MODEL_MAX_TOKEN=8192,AGENT_MODEL_MAX_RETRIES=4,PARALLEL_SHOT_MAX_WORKERS=4,MIN_PROTAGONIST_RATIO=0.7,SCENE_EXPLORATION_RANGE=3。
5. Experimental Results (实验结果)
Main quantitative results:CutClaw 在全部自动指标上领先。Visual Quality Avg:NarratoAI 75.7、UVCOM 72.4、Time-R1 72.9、CutClaw 77.6。Instruction Follow Avg:NarratoAI 64.0、UVCOM 62.6、Time-R1 61.5、CutClaw 70.0。AV Harmony Avg:NarratoAI 84.9、UVCOM 79.3、Time-R1 76.4、CutClaw 86.5。
Ablation:w/o Audio 使 AV Harmony Avg 从 86.5 降到 77.2;w/o Editor 使 Instruction Follow Avg 从 70.0 降到 65.6;w/o Reviewer 使 Visual Quality Avg 从 77.6 降到 76.0,但 AV Harmony Avg 为 87.2,说明 Reviewer 主要帮助质量和合法性,不一定直接提高节拍指标。
User study:25 名参与者、80 个 evaluation items,共 2,000 opinions。CutClaw 的平均偏好票:Visual Quality 49.8%、Instruction Follow 50.2%、Audio-Visual Harmony 53.0%、Human-Like 48.8%;第二名 Time-R1 分别为 21.4%、21.0%、20.0%、23.8%。

Figure 6 解读:teaser 展示输入包括用户指令、hours-long footage 和 music footage,输出是一条按音乐结构切分并满足视觉/叙事约束的短视频 timeline。底部用图标标出 music synchronization、following instruction、visually appealing 三个目标。
作者明确限制:系统虽然保证叙事流,但缺少高级 visual hooks,例如生成式视觉特效或特定 monologue highlights;多阶段 pipeline 处理长素材会带来高 inference latency,未来需要优化速度或加入 coarse-to-fine real-time feedback。