Unlocking Complex Visual Generation via Closed-Loop Verified Reasoning
Paper: arXiv:2605.14876v1 Project: CLVR Project
1. Motivation (研究动机)
当前 T2I 模型主要还是单步生成:把完整 prompt 一次性映射到像素。论文指出这在简单 prompt 上有效,但遇到包含多实体、空间关系、文字渲染、风格约束的复杂语义时,容易出现属性混淆、实体缺失和关系错位;继续扩大参数规模只能带来边际收益递减。
把 CoT/多步推理直接搬到图像生成也不够:已有思路常见问题是计划没有逐步视觉验证、只在最后做整体反思、长上下文图文历史很难被 reward model 稳定评分,以及每轮都做完整扩散去噪导致推理成本过高。
这篇论文要解决的具体目标是:让图像生成像 agent 一样反复“计划 → 生成/编辑 → 验证 → 修正/终止”,并且把这种闭环能力训练进 VLM 控制器和 diffusion generator,同时用低步数推理让系统可部署。问题值得研究,因为它把复杂视觉生成从单次前向的容量上限,转成可随任务难度增加推理步数的 test-time scaling 问题。
2. Idea (核心思想)
核心洞察:复杂 T2I 不应该只依赖更大的单步模型,而应把 VLM 的语义规划能力和 diffusion 的像素执行能力放进一个带验证的闭环里。CLVR 的新意不是简单 prompt rewrite,而是让每一步生成后都有视觉检查与可执行反馈,失败轨迹被过滤或修正,最终得到可靠的多步轨迹来训练模型。
相比 Uni-CoT 或开环 rewrite,CLVR 的关键差异有三点:第一,训练数据来自 state-constrained controller 与 step-level/global verification,而不是未验证的语言计划;第二,PPRL 把长图文历史蒸馏成短而可评估的 proxy prompt,降低 reward attribution 噪声;第三,DSWM 直接合并 alignment 增量和 distillation 增量,把闭环推理的每步扩散成本压到 4 NFEs。
3. Method (方法)
3.1 总体框架

Figure 2 解读:CLVR 被拆成三条链路:左侧是 SFT + PPRL 的训练流程,中间是 VLM 控制器驱动的闭环推理流程,右侧是 -Space Weight Merge。整体逻辑是先用 verified trajectories 教会模型多步规划与编辑,再用 proxy reward 做 diffusion RL,最后把对齐后的能力和低步数 distillation prior 合到同一个 checkpoint 中。
论文把 CLVR 分成三类核心组件:
- Trajectory Synthesis:用 state-constrained VLM controller 生成 interleaved CoT trajectories,并在每一步做视觉验证。
- Diffusion Alignment:先 SFT 适配多步轨迹,再用 PPRL 在长图文上下文上做更稳定的 RL。
- Efficient Deployment:推理时使用 trajectory-accumulative conditioning 保留历史约束,再用 DSWM 复用 4-step distillation prior。
3.2 Verified trajectory synthesis

Figure 3 解读:数据引擎是一个 Perceive-Reason-Act 循环:VLM 先观察当前 canvas,判断与目标 prompt 的差距,再选择 initial generation、image editing、result validation 或 termination 等工具。每个工具调用后都经过验证,因此训练集里的轨迹不仅有最终图像,还有中间观察、修正理由和可追溯的动作序列。
被动验证是 step-level gatekeeper:每次 generative tool call 后,sub-agent 根据动态 checklist 判断 diffusion 模型是否执行了当前指令;失败就丢弃整条轨迹,避免错误污染数据。主动验证则由 controller 显式调用,用来判断当前 canvas 是否满足用户目标;若发现语义缺口,就返回可执行反馈,让 controller 修改计划。最后,系统还用 Gemini 2.5 Pro 和 Seed 1.8 做 blind A/B judge,只有两者都认为多步结果优于单步 baseline 的轨迹才保留。

Figure 7 解读:这个训练样例展示了闭环数据为什么有价值:系统先生成基础图,再发现背景缺少 “AM” logo 并补上;随后又发现摩托车尾部细节不可见,于是改变视角以包含尾灯和车牌。它不是一次性补全 prompt,而是在视觉反馈中逐步修复缺失约束。
3.3 Proxy Prompt Reinforcement Learning (PPRL)
给定完整轨迹 ,训练时随机截断到步骤 ,构造局部多模态上下文:
直接拿 去打分会让 reward model 面对冗长图文历史,噪声很大。PPRL 用一个强 VLM teacher 把历史蒸馏成 proxy prompts:
最终 proxy reward 为:
直觉上,PPRL 把“长历史理解”交给 teacher VLM,把 RL reward 变成短文本 + reference image 的显式目标;这样 reward 更像对当前步骤做 credit assignment,而不是让 reward model 从整段 CoT 里猜当前图像应该满足什么。
3.4 Closed-loop inference
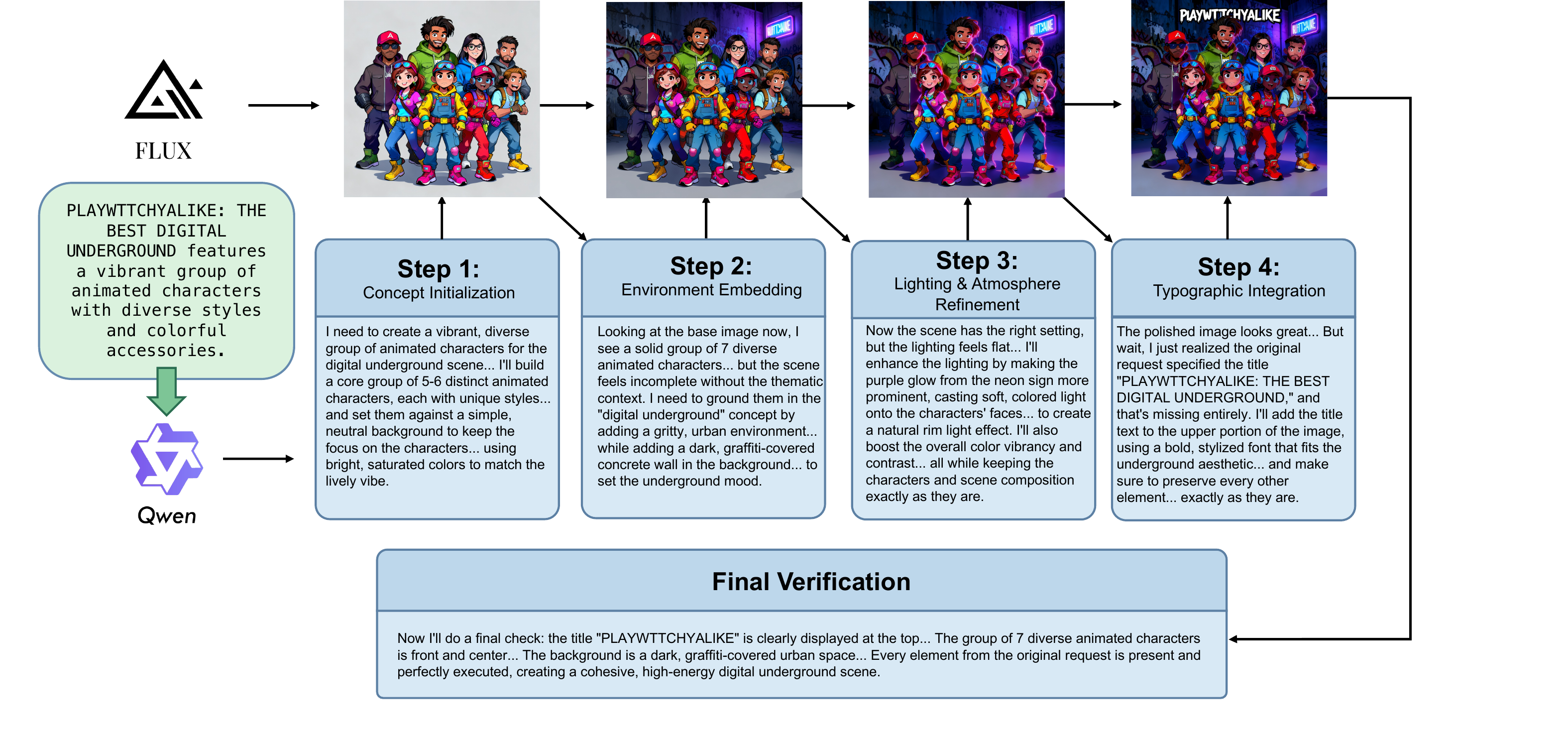
Figure 6 解读:这个推理案例显示 CLVR 如何把复杂 prompt 拆成多轮:先初始化主体概念,再嵌入环境,随后调整灯光氛围,最后补充 typography。每轮不仅生成图像,还把上轮图像和推理文本带入下一轮,因此后续编辑能保留已有元素而不是重新开始。
推理时,VLM controller 是 router policy ,diffusion model 是 context-aware generator 。每轮 VLM 读取历史 ,采样推理文本和动作 。若动作是 <|image_gen|>,则更新条件 并生成 ;若动作为 <|terminate|>,输出当前 canvas。
以下为论文机制级伪代码;代码搜索未找到开源实现,因此它不是 released code 的逐行映射:
def clvr_inference(user_prompt, vlm_controller, diffusion_generator, max_iters=8):
history = {"prompt": user_prompt, "steps": []}
canvas = None
for t in range(max_iters):
reasoning, action = vlm_controller.route(history, canvas)
if action == "terminate":
return canvas, history
if action == "image_gen":
condition = build_trajectory_accumulative_condition(user_prompt, history, reasoning)
canvas = diffusion_generator.generate_or_edit(condition, previous_image=canvas)
history["steps"].append({"reasoning": reasoning, "image": canvas})
return canvas, history3.5 -Space Weight Merge (DSWM)
闭环推理如果每步都用 28-step diffusion,延迟会很高;但对 CLVR 模型重新做大规模 trajectory distillation 又很贵。DSWM 的做法是把 base model 作为锚点,直接合并 distillation 权重增量和 alignment 权重增量:
论文给出的几何直觉是:distillation increment 更像把 off-manifold 状态拉回数据流形的 normal-space 修正;alignment increment 则沿数据流形 tangent space 重新分配概率密度,以满足指令和奖励。因此两者近似解耦,可以线性合并而不明显破坏能力。
3.6 代码搜索状态
代码搜索未找到开源实现。已检查 arXiv 页面和项目页,项目页只提供 paper/figures/results;进一步用 web search 与 GitHub repo/code search 查询标题、“Closed-Loop Visual Reasoning”、“Proxy Prompt Reinforcement Learning”、“Delta-Space Weight Merge”、“CLVR_Proj” 等关键词,未发现对应官方仓库。因此本笔记不设置 github / github_ref,也不提供 released-code mapping table。
4. Experimental Setup (实验设置)
4.1 数据与训练集
训练数据从 FLUX-Reason-6M 的初始 prompts 出发。论文附录 A.3 写到,系统从约 candidate prompts 中筛选出 20,861 条高质量 trajectories,保留率 20.9%;训练轨迹与 4.3 的 probing data 及评测 benchmark 严格隔离。
数据生成由 Gemini 2.5 Pro 作为 VLM controller、Seedream 4 作为 diffusion agent,状态机为 generate_base_image → inspect → edit/refine → validate → finalize。每个状态有固定 retry budget;格式错误、逻辑不一致、质量退化或 judge 不通过都会导致轨迹丢弃。最终数据导出为 ShareGPT 格式,并用 <IMG_GEN_n> token 对齐多步 reasoning 和 diffusion conditioning。
4.2 模型与训练配置
- 模型:VLM controller 固定为 Qwen3-VL 8B;diffusion model 使用 FLUX.2 Klein 4B 和 9B。
- SFT:VLM 基于 Qwen3-VL 8B 做 full-parameter fine-tuning,bf16,cosine LR,learning rate ,warmup ratio 0.1,3 epochs,per-device batch size 1,gradient accumulation 8。Diffusion SFT 基于 FLUX.2 DiT 做 full-parameter fine-tuning,使用同一批 20,861 trajectory metadata,learning rate ,3 epochs,per-device batch size 1,训练分辨率 。
- RL:Diffusion RL 使用 DiffusionNFT,从 SFT warmup checkpoint 初始化,LoRA rank 128、,分辨率 ,rollout 采样步数 8,learning rate ,KL penalty ,per-device batch size 1,group size 16,CFG 4.0。T2I/I2I 任务混合权重为 1:1;I2I 的 step count 1/2/3/≥4 采样权重也为 1:1:1:1。
- 硬件与推理:所有 SFT/RL 与主实验使用 8 张 NVIDIA H20。Base branch 推理为 28 sampling steps + CFG 4.0;distilled/DSWM branch 为 4 steps、无 CFG(guidance scale 1.0)。闭环最多 8 次 image generation cycles。
4.3 Benchmarks、baselines 与 metrics
主要 benchmark 包括 GenEval、GenEval++、ImagineBench、PRISM 和 WiseBench;PRISM 关注 imagination、entity、text rendering、style affection、composition、long text 等维度,WiseBench 覆盖 cultural、time、space、biology、physics、chemistry 等知识型生成维度。复杂度 probe 使用 10 个 tiers,并以 LLM-as-a-judge 计算 AUC Pass,同时用 作为 backbone capacity 的 spectral proxy。
对比对象覆盖 SD3.5、FLUX.1-dev、Qwen-Image、Seedream 3.0、Janus-Pro-7B、BAGEL、T2I-R1、Uni-CoT、Process-Driven、FLUX.2 4B/9B base 等开源或统一多模态模型;GPT-4o 和 Gemini 2.5-Flash-Image 作为 proprietary upper-bound reference。
5. Experimental Results (实验结果)
5.1 主结果

Figure 1 解读:PRISM qualitative results 展示 CLVR 对密集 prompt 的处理能力:它不是只在一张图里塞入更多元素,而是通过多轮 reasoning 保留实体、关系、风格和文字约束。这个 teaser 对应论文后续的 PRISM 定量结果。
- GenEval:CLVR (9B) overall = 0.88,CLVR (4B) = 0.87;对应 FLUX.2 9B base = 0.80、FLUX.2 4B base = 0.74。CLVR 9B 也略高于 Qwen-Image 0.87、Uni-CoT 0.83、T2I-R1 在 WiseBench/其他表中的推理增强 baseline。
- WiseBench:CLVR (9B) overall = 0.76,接近 GPT-4o upper bound 0.80;CLVR (4B) = 0.74,而 FLUX.2 9B base = 0.52、FLUX.2 4B base = 0.44。
- PRISM:CLVR (9B) overall = 82.1,超过 FLUX.2 9B base 72.7 和最强开源 baseline Qwen-Image 79.9,距离 GPT-4o 86.3 仍有差距;CLVR (4B) = 76.3,相比 FLUX.2 4B base 65.7 提升明显。
- GenEval++ / ImagineBench:CLVR (9B) overall 分别为 0.689 / 8.830;CLVR (4B) 为 0.616 / 8.435;FLUX.2 9B base 为 0.307 / 7.274,说明闭环推理对组合属性、空间/计数/多物体等复杂约束更有效。

Figure 4 解读:视觉对比中,CLVR 4B 相比 FLUX.2 4B、Uni-CoT、Nano Banana 2 和 Qwen-Image 更能保留 prompt 中加粗的关键控制信号。这个图主要支持“闭环自校正优于单步生成/开环 reasoning”的定性结论。
5.2 Semantic complexity probe
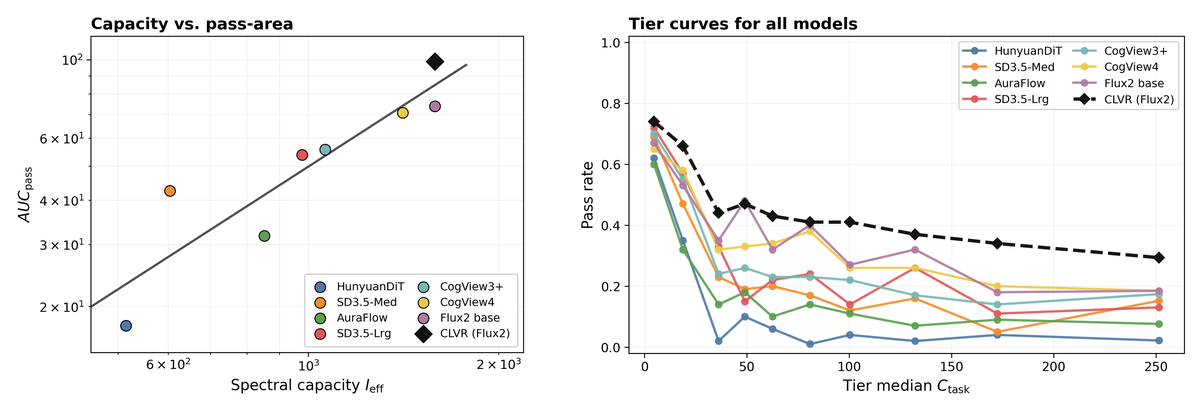
Figure 5 解读:左图把模型能力 proxy 与 AUC Pass 联系起来,显示单步模型需要更高有效容量才能获得有限提升;右图按 复杂度分层,显示单步 baseline 随复杂度上升迅速退化,而 CLVR 在高复杂度 tiers 仍保持更高 pass rate。它支撑论文的核心动机:复杂语义存在单步容量天花板,闭环推理能绕过一部分参数扩展需求。
5.3 Ablation 与效率
Prompt rewrite 并不能解释 CLVR 的收益:在 Table 4/6 中,Qwen3-VL 8B open-loop rewrite 让 WiseBench 从 0.48 升到 0.64,但 GenEval 从 0.81 降到 0.78;CLVR + PPRL 则在 GenEval / WiseBench 达到 0.87 / 0.74。说明外部语义扩写能补知识,但不能替代任务分解和视觉自校正。
训练组件上,FLUX.2 4B base 在 GenEval 为 0.74;CLVR without PPRL 为 0.78;加入 PPRL 后为 0.83;DSWM + CLVR + PPRL 达到 0.87。附录更细的 Table 6 显示:VLM SFT only 已能把 GenEval 提到 0.86,但 WiseBench 只有 0.65;Diffusion SFT + PPRL 使 WiseBench 升到 0.74,体现 proxy prompt reward 对长上下文 alignment 的贡献。
效率上,DSWM 把 distilled branch 统一为 4-step、no-CFG decoding。论文在 2 张 NVIDIA H20、vLLM 部署下统计 GenEval 553 例和 PRISM 700 例:最常见的 2-iteration 轨迹,Base 平均 E2E 287.0 秒,DSWM 为 25.5 秒,约 11× 加速;GenEval 中约 68% 样本在 2 iterations 内完成,28% 需要 3 iterations,少数到 4–5 iterations,均低于 8-iteration 上限。
5.4 局限与结论
作者承认当前系统的闭环步数和终止标准主要由模型自主决定,用户难以显式控制质量/成本 trade-off;未来需要 thinking budget 接口,让用户指定最大推理步数、反馈频率或资源上限。
另一个限制是论文主要研究 static image generation。闭环视觉推理可以扩展到 consistent multi-image generation、long-form video synthesis、3D asset creation 和 interactive design workflow,但会引入时间一致性、跨视角几何约束以及动态用户偏好等新问题。