Think in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning
Paper: arXiv:2604.04746v3 Code: 代码搜索未找到开源实现 Code reference: N/A(no public GitHub repo found; pseudocode and mapping are reconstructed from paper text/source only)
1. Motivation(研究动机)
当前 text-to-image / unified multimodal generation 的核心瓶颈不是“能不能生成漂亮图”,而是复杂 prompt 下的 visual logic:空间关系、对象数量、属性绑定、世界知识约束很容易在 single-pass 生成中被一次性错误提交。例如论文 teaser 中的 bear/spoon 关系,模型可能生成 plausible 但 relation 错误的图。Text-only CoT 能分解语言推理,但它看不到中间图像,因此无法根据已经画出的状态判断“对象还没画”还是“画错了”。
本文要解决的是:让 unified multimodal model 在生成图像时显式地产生一条可监督、可解释的 interleaved trajectory,而不是直接输出最终图。这个问题值得做,因为一旦中间状态可见,模型就能在生成过程中执行局部计划、草图、检查和修正,最终把原本黑盒的一次性生成变成可控的逐步构图过程。

Figure 1 解读:左侧 single-pass generation 直接把完整 prompt 压到一次生成里,关系错误后没有可见修正机会;右侧 process-driven interleaved reasoning 把图像构成拆成 Plan → Sketch → Inspect → Refine 的循环,让模型在每一步同时维护文本计划和视觉状态。
2. Idea(核心思想)
核心思想是把 image generation 重新定义为 text tokens 与 vision tokens 共同演化的轨迹:每一步先用文本说明下一笔要画什么,再生成当前视觉草图,然后用文本检查草图是否违反 prompt,最后必要时再生成修正后的视觉状态。与传统 single-shot diffusion/T2I 或 text-only CoT 的区别在于,这里的 reasoning 被中间图像 grounding:文本会决定下一步视觉变化,而视觉中间态又反过来约束下一轮文本推理。
本文的关键创新不是新增一个外部 critic,而是构造 dense step-wise supervision,让 BAGEL-7B 端到端学会发出 interleaved sequence。中间态的歧义通过两类约束处理:visual intermediate 要保持 spatial/semantic consistency;textual intermediate 要保留已有视觉知识,同时识别并修正 prompt-violating elements。
3. Method(方法)
3.1 Overall framework
给定 prompt 和 unified multimodal model ,生成过程被写成:
每个循环包含四个阶段:
- Plan:根据原始 prompt 与累计上下文生成 step-level instruction
<ins>...</ins>和全局 scene description<des>...</des>。 - Sketch:条件于该 instruction,生成更新后的 draft image,即当前视觉中间态。
- Inspect:同时检查文本 instruction/global description 与原始 prompt 的一致性,以及 draft image 与 step-level instruction 的一致性。
- Refine:若发现冲突,输出
<refine>...</refine>并生成 corrected visual update。
视觉输出由 <|vision_start|> 与 <|vision_end|> 标记,模型在同一 autoregressive sequence 中切换文本与视觉生成模式。直觉上,这相当于把复杂 prompt 的全局约束分摊到多个局部更新;每一步只需要解决当前局部 region / object / relation,同时保留已生成状态,从而减少一次性求解所有关系的组合压力。
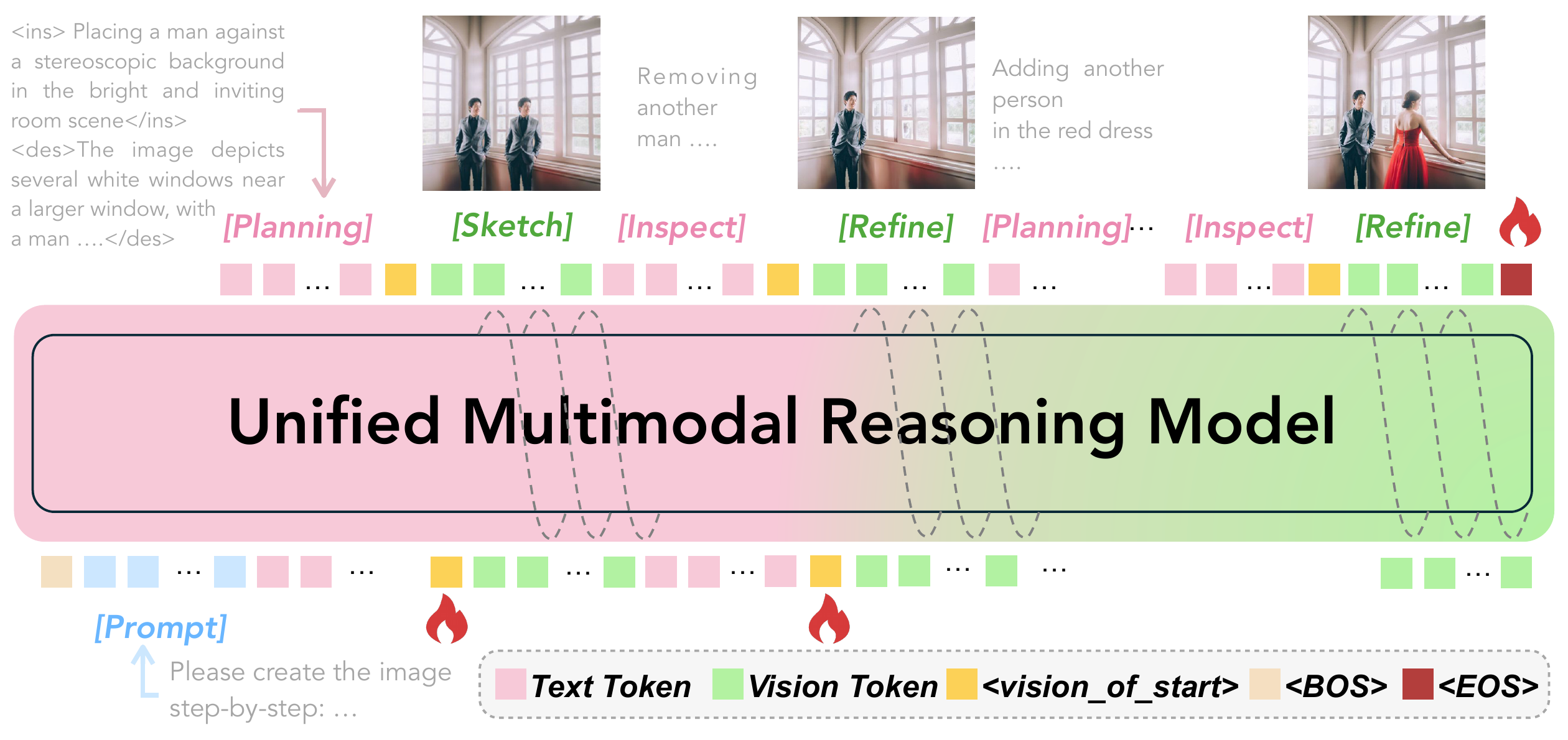
Figure 2 解读:pipeline 展示统一模型如何在单条序列中交替生成 pink text tokens 与 green vision tokens。文本侧不仅生成计划,还承担 inspect/refine 的语义诊断;视觉侧则把计划落实为 draft/refined state,使下一轮推理有真实图像上下文。
3.2 Intermediate reasoning data construction
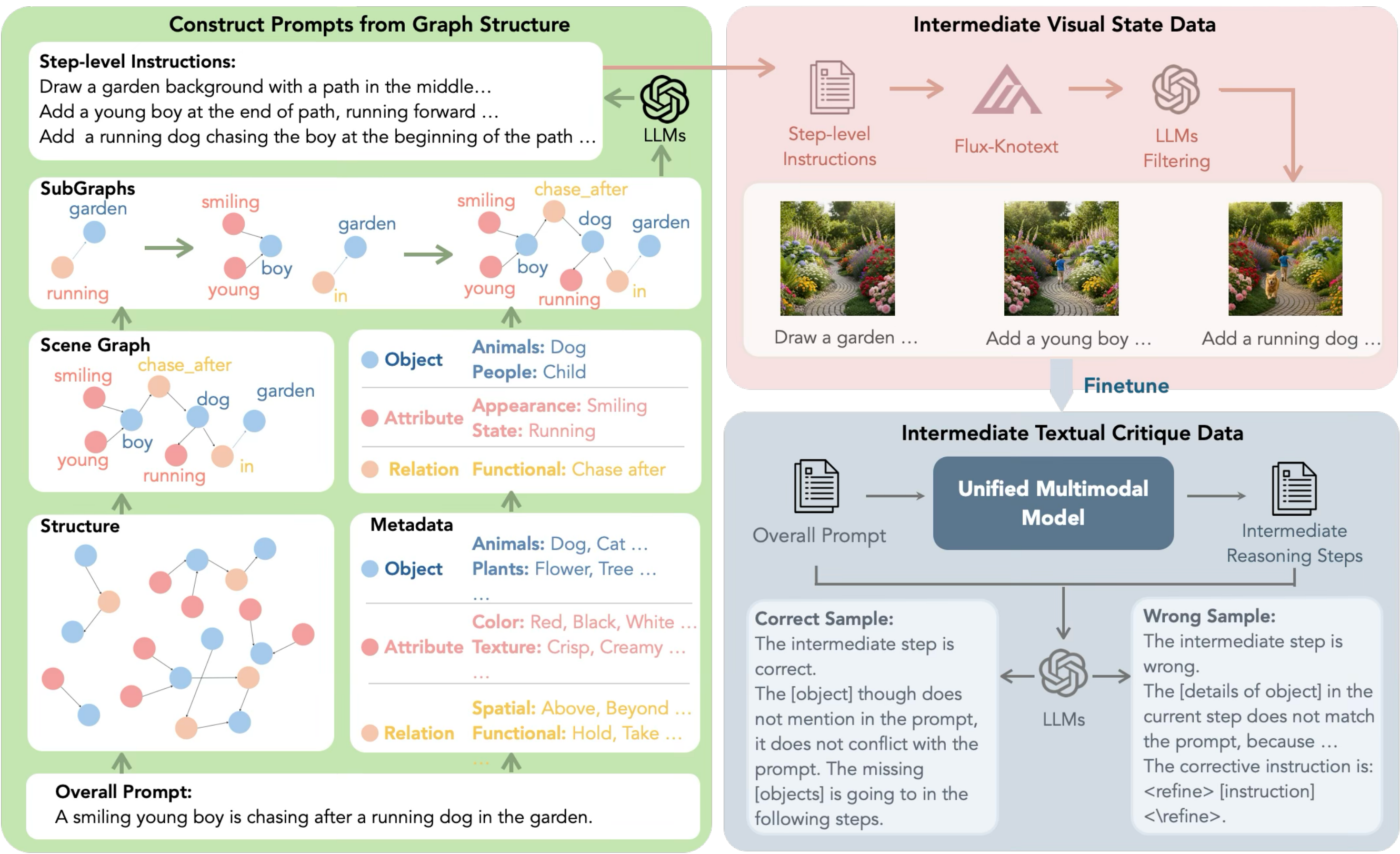
Figure 3 解读:数据管线从完整 prompt 出发,先通过 scene graph subsampling 得到无矛盾的 incremental prompts,再用 GPT/filtering 与 self-sampling 构造文本冲突和图文对齐两类 critique 监督。它的目的不是只给最终图监督,而是覆盖 plan、sketch、inspect、refine 四个阶段。
三类训练子集如下:
| Subset | Scale | 作用 |
|---|---|---|
| Multi-turn Generation | 32,012 samples;avg prompt length 152.8;avg 3.51 images/sample;max 5 images/sample | 用 scene graph 的 object/attribute/relation 子图采样生成局部递增 prompt,并用 Flux-Kontext 合成/过滤中间图,让模型学会 step-by-step plan + sketch。 |
| Instruction-Intermediate Conflict | 15,201 samples;6,905 positive / 8,296 negative | 从 multi-turn fine-tuned model self-sample 中间轨迹,用 GPT 判断 textual intermediate 与原始 prompt 是否冲突,并生成 textual analysis / corrective instruction。 |
| Image-Instruction Alignment | 15,000 samples;5,000 positive / 10,000 negative | 基于 Gen-Ref 扩展,判断当前 draft image 是否与 step instruction 对齐;负例包含 error analysis 与 refinement instruction。 |
3.3 Training objective
文本 token 用 next-token Cross-Entropy,只在 textual segments 上计算,并额外监督 <|vision_start|> / <|vision_end|> 以学习模态切换:
视觉 token 继承 BAGEL 的 Rectified Flow 生成范式:
总目标为:
3.4 Pseudocode(基于论文重构;无公开代码)
import torch
import torch.nn.functional as F
def generate_process_driven_image(model, prompt, max_steps=5):
"""Plan -> Sketch -> Inspect -> Refine interleaved inference."""
context = [prompt]
image_state = None
for step in range(max_steps):
plan_text = model.generate_text(
context,
required_tags=("<ins>", "</ins>", "<des>", "</des>"),
)
context.append(plan_text)
draft = model.generate_image(
context,
start_token="<|vision_start|>",
end_token="<|vision_end|>",
)
context.append(draft)
image_state = draft
inspect_text = model.generate_text(
context,
required_tags=("<refine>", "</refine>"),
allow_empty_refine=True,
)
context.append(inspect_text)
if "<refine>" in inspect_text and not is_empty_refine(inspect_text):
image_state = model.generate_image(
context,
start_token="<|vision_start|>",
end_token="<|vision_end|>",
)
context.append(image_state)
if model.emitted_final_vision_end_without_next_start(context):
break
return image_state, context
def build_multi_turn_generation_subset(prompt, scene_graph, flux_kontext, gpt_filter):
"""Scene-graph subsampling creates contradiction-free incremental prompts."""
trajectory = []
for subgraph in ordered_subgraph_expansion(scene_graph, max_steps=5):
step_instruction = render_step_instruction(subgraph)
if should_augment_instruction(step_instruction):
step_instruction = rewrite_with_gpt(
step_instruction,
operations=("add", "refine", "remove", "swap"),
)
image = flux_kontext.generate(prompt=step_instruction)
if gpt_filter.is_consistent(image=image, instruction=step_instruction):
trajectory.append((step_instruction, image))
return trajectory
def build_instruction_intermediate_conflict_subset(model, raw_prompt, gpt_judge):
"""Text-side critique supervision from the model's own sampled traces."""
trace = model.sample_intermediate_reasoning_trace(raw_prompt)
examples = []
for text_state in trace.textual_intermediates:
verdict = gpt_judge.check_prompt_consistency(text_state, raw_prompt)
if verdict.is_conflict:
critique = gpt_judge.write_error_analysis(text_state, raw_prompt)
correction = gpt_judge.write_corrective_instruction(text_state, raw_prompt)
examples.append((text_state, critique, correction, 0))
else:
explanation = gpt_judge.explain_consistency(text_state, raw_prompt)
examples.append((text_state, explanation, None, 1))
return examples
def build_image_instruction_alignment_subset(gen_ref_samples, gpt_judge):
"""Vision-side critique supervision for draft-image vs step-instruction mismatch."""
examples = []
for image, instruction in gen_ref_samples:
aligned = gpt_judge.check_image_instruction_alignment(image, instruction)
if aligned:
explanation = gpt_judge.explain_alignment(image, instruction)
examples.append((image, instruction, explanation, None, 1))
else:
error = gpt_judge.describe_visual_error(image, instruction)
refine_instruction = gpt_judge.write_refinement_instruction(image, instruction)
examples.append((image, instruction, error, refine_instruction, 0))
return examples
def train_step(model, batch, lambda_ce):
"""Joint text CE + image Rectified-Flow MSE for interleaved sequences."""
outputs = model(batch.context_tokens, batch.image_latents, return_flow=True)
text_loss = F.cross_entropy(
outputs.text_logits[batch.text_mask],
batch.text_targets[batch.text_mask],
)
switch_loss = F.cross_entropy(
outputs.text_logits[batch.vision_boundary_mask],
batch.boundary_targets[batch.vision_boundary_mask],
)
predicted_flow = outputs.flow_prediction[batch.image_mask]
target_flow = batch.z0[batch.image_mask] - batch.z1[batch.image_mask]
image_loss = F.mse_loss(predicted_flow, target_flow)
loss = lambda_ce * (text_loss + switch_loss) + image_loss
loss.backward()
return {"loss": loss, "text_loss": text_loss, "image_loss": image_loss}3.5 Code-to-paper mapping(无公开实现)
代码搜索未找到开源实现,因此没有可验证的 source file / class / training config anchor;下表只记录论文结构到应有实现模块的映射,不能视为真实代码引用。
| Paper concept | Paper source / figure | Expected implementation module if released | 当前代码状态 |
|---|---|---|---|
| Plan → Sketch → Inspect → Refine interleaved inference | Sec. 3 Framework;Fig. 2 | generation loop / tokenizer-modal switch / stopping rule | 未找到公开实现 |
| Scene-graph subsampling multi-turn data | Sec. 3 Intermediate Reasoning Collection;Fig. 3 | data construction for incremental prompts | 未找到公开实现 |
| Instruction-intermediate conflict reasoning | Sec. 3;Table dataset stats | self-sampling + GPT judge text critique builder | 未找到公开实现 |
| Image-instruction alignment reasoning | Sec. 3;Gen-Ref extension | visual draft vs instruction evaluator / refine data builder | 未找到公开实现 |
| Joint CE + Rectified Flow training | Sec. 3 Training Objectives | BAGEL-7B finetuning loss / multimodal batch collator | 未找到公开实现 |
代码搜索记录(2026-05-16):检查 arXiv PDF/HTML、Hugging Face paper page 中的链接;用 WebSearch 查询 exact title + GitHub、method name + GitHub、author/org + GitHub;用 gh search repos/code 查询 exact title 和 “Process-Driven Image Generation”;均未发现官方或可确认的公开实现。
4. Experimental Setup(实验设置)
- Base model:BAGEL-7B unified multimodal understanding/generation model;所有参数 end-to-end finetune。
- Training data:process-based interleaved reasoning dataset,包括约 32K multi-turn generation、15,201 instruction-intermediate conflict、15,000 image-instruction alignment;实验段落另以 30K/15K/15K 概述,精确统计见 Table dataset stats。
- Training config:1 node × 8 NVIDIA H100 GPUs;10,000 steps;packed sequence length 33,000 tokens;learning rate ;cosine decay。
- Evaluation:GenEval(object-centric compositional T2I:single object、two objects、counting、colors、position、color attributes);WISE(world knowledge reasoning:culture、time、space、biology、physics、chemistry)。Baselines 包含 generation-only models(PixArt-、SDv2.1、DALL-E 2/3、SDXL、SD3-Medium、FLUX.1-dev 等)、unified multimodal models(Janus、Janus-Pro-7B、Show-o/Show-o2、BAGEL 等)和 process baselines(BAGEL+GPT Planner/Inspector、PARM TTS/RL+TTS)。
5. Experimental Results(实验结果)
5.1 Main benchmark results
GenEval(Single / Two / Counting / Colors / Position / Color Attr. / Overall)
| Model | Single | Two | Counting | Colors | Position | Color Attr. | Overall |
|---|---|---|---|---|---|---|---|
| FLUX.1-dev (12B) | 0.98 | 0.93 | 0.75 | 0.93 | 0.68 | 0.65 | 0.82 |
| Janus-Pro-7B | 0.99 | 0.89 | 0.59 | 0.90 | 0.79 | 0.66 | 0.80 |
| BAGEL-7B* | 0.99 | 0.95 | 0.76 | 0.87 | 0.51 | 0.56 | 0.77 |
| Ours (BAGEL-7B + Process-Driven) | 0.99 | 0.95 | 0.75 | 0.87 | 0.72 | 0.69 | 0.83 |
关键点:相对 BAGEL-7B*,overall 从 0.77 提升到 0.83;Position 从 0.51 到 0.72,Color Attr. 从 0.56 到 0.69。它的 overall 也略高于 12B FLUX.1-dev 的 0.82,但不是每个子项都最高。
WISE(Culture / Time / Space / Biology / Physics / Chemistry / Overall)
| Model | Culture | Time | Space | Biology | Physics | Chemistry | Overall |
|---|---|---|---|---|---|---|---|
| FLUX.1-dev | 0.48 | 0.58 | 0.62 | 0.42 | 0.51 | 0.35 | 0.50 |
| BAGEL | 0.76 | 0.69 | 0.75 | 0.64 | 0.75 | 0.58 | 0.70 |
| Ours (BAGEL + Process-driven) | 0.74 | 0.82 | 0.73 | 0.70 | 0.76 | 0.78 | 0.76 |
关键点:overall 从 0.70 到 0.76;Time 从 0.69 到 0.82,Chemistry 从 0.58 到 0.78,说明逐步的 textual-visual reasoning 对世界知识与结构语义更有帮助。
5.2 Process baseline comparison
| Reasoning Strategy | Training Dataset | Inference Cost | GenEval |
|---|---|---|---|
| BAGEL + GPT (Planner) | - | 50 | 0.60 |
| BAGEL + GPT (Inspector) | - | 50 | 0.80 |
| PARM (TTS) | 400K | 1000 | 0.67 |
| PARM (RL + TTS) | 688K | 1000 | 0.77 |
| Ours (SFT) | 62K | 131 | 0.83 |
Ours 用 62K samples 达到 0.83,比 PARM (RL + TTS) 的 688K / 1000 cost / 0.77 更省数据和推理成本。论文解释为 semantic partitioning 更可解释:监督的是具体对象/关系/属性的中间视觉状态,而不是 PARM 式 blurry latent/noise-level intermediate。
5.3 Ablations
| Ablation | Color | Position | Color Attr. |
|---|---|---|---|
| w/o aug. | 0.81 | 0.58 | 0.50 |
| w/o aug. + Self-critique | 0.84 | 0.61 | 0.53 |
| w/ aug. | 0.82 | 0.67 | 0.62 |
| w/ aug. + Self-critique | 0.87 | 0.72 | 0.69 |
| Critique construction | Color | Position | Color Attr. |
|---|---|---|---|
| baseline | 0.82 | 0.67 | 0.62 |
| + scene graph | 0.83 | 0.70 | 0.67 |
| + self-sampling | 0.87 | 0.72 | 0.69 |
| Intermediate supervision | Counting | Colors | Position | Color Attr. |
|---|---|---|---|---|
| baseline | 0.61 | 0.84 | 0.66 | 0.62 |
| + Instruction-intermediate conflict | 0.62 | 0.85 | 0.71 | 0.65 |
| + Image-instruction alignment | 0.73 | 0.86 | 0.69 | 0.65 |
| w/ both (ours) | 0.75 | 0.87 | 0.72 | 0.69 |
Ablation 说明三件事:多样编辑操作(refine/remove/swap)尤其提升 relation/attribute;self-sampling critique 比 scene-graph symbolic correction 更贴近模型自身错误分布;text-side conflict 和 image-side alignment 是互补的,前者更推 Position,后者明显推 Counting。

Figure 4 解读:可视化轨迹展示每一步如何从 plan/sketch 到 inspect/refine。第二、三行分别对应两类错误:step-level instruction 与 overall prompt 冲突,以及 draft image 与 instruction 不一致;前者需要改 instruction,后者主要需要改视觉结果。

Figure 5 解读:补充可视化显示最终图在 GenEval/WISE prompt 上具有较强细节和审美质量。它主要支撑 qualitative fidelity,但真正证明方法有效的仍是上面的 GenEval/WISE 与 ablation 数字。
5.4 Limitations / open questions
作者没有单列 Limitations;结论中明确的未来方向是扩展到 video、3D space 和 real-time human-in-the-loop control。基于论文方法本身,当前可复现风险包括:数据构造依赖 GPT judge / Flux-Kontext,公开代码与 checkpoint 未找到;同时实验主要集中在 T2I compositional/world-knowledge benchmarks,还没有证明同样的 interleaved process 能直接迁移到长视频、3D 或交互式编辑。