1. Motivation (研究动机)
- 当前 Test-Time Scaling (TTS) 在视频生成里主要沿用 diffusion/flow 模型的全局多步去噪与候选搜索:一次性同时去噪整段视频会把搜索空间推到高维全局空间,候选生成、reward 评估与多步 denoising 都很贵;更关键的是,它通常只能事后选择整段视频,难以在局部时间点注入可控修正。
- Streaming Video Generation 的优势是 chunk-by-chunk autoregressive synthesis:每个 chunk 只需少量 denoising steps,并天然保留历史上下文。但现有 streaming 方法的长视频稳定性受限于固定 KV-cache/attention sink 管理:早期视觉信息被压缩或丢弃后,长程语义锚点会漂移,导致 temporal inconsistency、motion discontinuity 与 visual quality degradation。
- 这篇论文要解决的具体问题是:如何把 TTS 从“整段视频上做昂贵候选搜索”改造成“每个 streaming chunk 上做低成本、可反馈、可更新 memory 的主动优化”。如果解决这个问题,就能在不重新训练模型的情况下,把短视频模型/streaming backbone 推向更长时长,并同时提升 temporal consistency、motion smoothness 与 frame-level visual fidelity。
2. Idea (核心思想)
Stream-T1 的核心 insight 是:Streaming generation 的 chunk 边界不是负担,而是 TTS 最自然的决策点;每生成一个 chunk,都可以用上一个高质量 chunk 的 latent noise 作为下一步搜索先验,用 short/long reward 选择候选,并用 reward 反馈决定哪些历史 KV-cache 应该被丢弃、EMA 压缩或追加为长期 sink。
关键创新不是单纯把 Beam Search 套到视频生成上,而是把“搜索对象”拆成三类可干预状态:initial noise、candidate branch、context memory。相比 Best-of-N/Beam Search 这类只在固定候选池里被动挑最优结果的方法,Stream-T1 会在生成过程中主动改变后续 chunk 的 noise initialization 与 memory routing,因此搜索会影响未来轨迹,而不是只影响当前选择。
3. Method (方法)
3.1 Overall framework
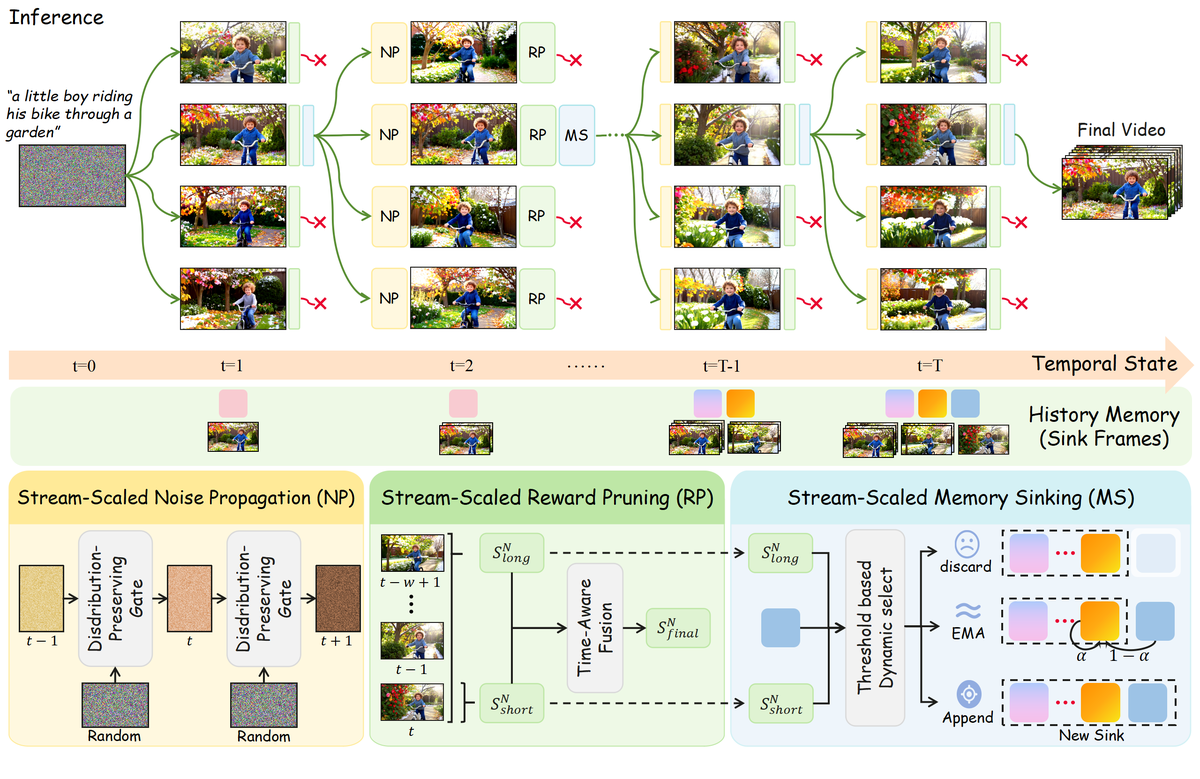
Figure 1 解读:Figure 1 展示了 Stream-T1 的 chunk-level scaling pipeline。上半部分是按时间推进的 search tree:每个 chunk 会从当前 beam 扩展多个候选,经过 Stream-Scaled Reward Pruning (RP) 后保留较优路径,并把最终候选串接成 Final Video。下半部分对应三个核心模块:Noise Propagation (NP) 用历史最优 noise 初始化新 chunk;Reward Pruning 用 short/long reward 融合筛选候选;Memory Sinking (MS) 根据 reward 信号更新 history memory,把被滑动窗口挤出的 KV-cache 路由到 discard、EMA 或 append 三种路径。

Figure 2 解读:Figure 2 给出 Figure 1 案例的完整搜索路径。它强调 Stream-T1 的搜索不是一次性在整段视频上展开,而是每个 chunk 只扩展局部候选并沿时间保留优胜分支;这种“shallow search tree with wide branches”让 TTS 的计算集中在当前 chunk,避免全局高维搜索爆炸。
整体流程以 LongLive 为 streaming backbone。第 个 chunk 的生成被分成三步:先用历史最优 noise 构造当前 chunk 的初始 latent;再对每个 beam 扩展 个候选并用 reward 评分,保留 top-;最后用 reward 历史判断被滑动窗口挤出的历史 KV-cache 是否应进入长期 sink。直觉上,Stream-T1 同时利用了两种连续性:相邻高质量 chunk 的 noise latent 通常有相关性,适合做“下一步初值”;高质量但语义未突变的历史 KV-cache 有冗余,适合 EMA 压缩;高质量且发生语义转折的 KV-cache 则不应被平均掉,而应作为新的长期 anchor 追加保存。
3.2 Stream-Scaled Noise Propagation
论文把第一个 chunk 的 initial noise 设为标准高斯:
从第 个 chunk 开始,不再完全随机采样,而是用上一 chunk 的最优 noise latent 和新噪声做 spherical-style interpolation:
其中 控制相邻 chunk 的 temporal correlation。这个公式保留边缘分布仍为 ,但给当前 chunk 一个与历史高质量生成轨迹相关的 prior,因此不会破坏 diffusion/flow 模型的标准噪声假设。
实际代码里,pipelines/stream_scaling.py 的 _build_candidate_noise 对 block_idx == 0 直接返回 sample_noise;后续 chunk 返回 noise_fusion_sigma * beam["noise"] + sqrt(1 - noise_fusion_sigma**2) * sample_noise,其中 noise_fusion_sigma 对应论文的 。
import math
import torch
def stream_scaled_noise_propagation(beam, block_idx, shape, generator, beta, device, dtype):
sample_noise = torch.randn(*shape, generator=generator, device=device, dtype=dtype)
if block_idx == 0:
return sample_noise
previous_best_noise = beam["noise"]
return beta * previous_best_noise + math.sqrt(1.0 - beta ** 2) * sample_noise3.3 Stream-Scaled Reward Pruning
每个 chunk step 维护 条 beam。每条 beam 生成 个 next-chunk candidates,因此候选池大小为 ;对所有候选计算 reward 后保留 top-。
局部 frame-level fidelity 用 image reward 计算:
长程 temporal coherence 用最近 个 chunk 的 sliding window video reward 计算:
最终分数使用随时间变化的融合权重:
这里 是 chunk 内 frame 数, 是 long reward 的 sliding window size, 是目标总 chunk 数, 是 short-score weight 的上界。这样早期更重视 long coherence,后期逐步增加局部 aesthetic/detail 的权重,但不会让 short reward 过大而造成 frame repetition 或 motion stagnation。
代码中 _decode_short_candidate_video 会把当前 denoised latent 解码成 frames 并送入 image reward inferencer;_decode_long_candidate_video 会拼接 sliding window 内的视频输出并计算 long score;_compute_hybrid_score 用 alpha = current_start_frame / (num_output_frames - current_num_frames),再用 short_score_fusion_threshold 截断。
import torch
def compute_short_score(image_reward_model, decoded_frames):
frame_scores = [image_reward_model(frame) for frame in decoded_frames]
return torch.stack(frame_scores).mean()
def compute_long_score(video_reward_model, generated_chunks, window_size):
window = generated_chunks[-window_size:]
return video_reward_model(torch.cat(window, dim=1))
def hybrid_reward(short_score, long_score, current_start_frame, total_frames, chunk_frames, tau):
alpha = current_start_frame / (total_frames - chunk_frames)
alpha = min(alpha, tau)
return alpha * short_score + (1.0 - alpha) * long_score
def reward_prune(candidates, top_k):
return sorted(candidates, key=lambda c: c["score"], reverse=True)[:top_k]3.4 Stream-Scaled Memory Sinking
Memory Sinking 的目标是解决 fixed sliding-window KV-cache 的两难:全部丢弃历史会丢掉长程语义;全部保留会爆显存;简单 EMA 又可能把不同场景/动作的特征混在一起。Stream-T1 用 reward feedback 判断被挤出 window 的 chunk 是低质量噪声、同场景冗余信息,还是值得保留的新语义锚点。
质量门控为:
语义转折检测为:
如果 ,丢弃该 chunk 的 KV-cache:
如果 ,说明质量高但仍在同一场景中,使用 EMA 更新最近 sink:
如果 ,说明高质量且发生显著语义变化,直接 append 新 anchor:
注意力计算时把 sink 和 local window 拼接:
代码分两层实现:pipelines/stream_scaling.py::_update_reward_history 计算 ema 与 append 标志;wan/modules/causal_model_stream_t1.py 根据这些标志更新 current_sink_size、current_kv_cache_size 与 append_sink_start_frame,并在 attention 中把 roped_k_ema_sink 与 append sinks 拼接。
def update_memory_route(reward_history, current_key, short_score, long_score, short_threshold, long_threshold):
history_keys = sorted(reward_history.keys(), key=lambda k: int(k))
recent_short = [reward_history[k]["short_score"] for k in history_keys]
average_short = sum(recent_short) / len(recent_short)
previous_long = reward_history[history_keys[-1]]["long_score"]
is_short_high = (short_score - average_short) > short_threshold
is_long_low = (previous_long - long_score) > long_threshold
reward_history[current_key]["ema"] = is_short_high and not is_long_low
reward_history[current_key]["append"] = is_short_high and is_long_low
return reward_history
def route_evicted_kv(sink_k, sink_v, evicted_k, evicted_v, ema, append, alpha, max_sink_size):
if append and sink_k.size(1) < max_sink_size:
sink_k = torch.cat([sink_k, evicted_k], dim=1)
sink_v = torch.cat([sink_v, evicted_v], dim=1)
elif ema:
sink_k = torch.cat([sink_k[:, :-1], alpha * sink_k[:, -1:] + (1 - alpha) * evicted_k], dim=1)
sink_v = torch.cat([sink_v[:, :-1], alpha * sink_v[:, -1:] + (1 - alpha) * evicted_v], dim=1)
return sink_k, sink_v3.5 End-to-end chunk search pseudocode
下面伪代码按开源实现的控制流抽象:inference 初始化 KV/cache,_generate_initial_candidates 先从空 beam 扩展候选,后续 _generate_followup_candidates 从现有 beams 展开分支;每个 candidate 内部运行 denoising、短/长 reward、memory route 标记,然后按分数剪枝。
def stream_t1_inference(pipeline, text_prompt, num_blocks, top_k, beam_size):
conditional_dict = pipeline.text_encoder([text_prompt])
pipeline._initialize_kv_cache(batch_size=1, dtype=torch.bfloat16, device="cuda")
pipeline._initialize_crossattn_cache(batch_size=1, dtype=torch.bfloat16, device="cuda")
beams = [pipeline._build_initial_beam(output=None)]
for block_idx in range(num_blocks):
if block_idx == 0:
candidates = pipeline._generate_initial_candidates(
conditional_dict=conditional_dict,
beam=beams[0],
block_idx=block_idx,
current_start_frame=0,
)
else:
candidates = pipeline._generate_followup_candidates(
conditional_dict=conditional_dict,
beams=beams,
block_idx=block_idx,
current_start_frame=block_idx * pipeline.num_frame_per_block,
)
beams = sorted(candidates, key=lambda c: c["score"], reverse=True)[:top_k]
return beams[0]["output"]Code reference:
main@600454e(2026-05-07) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Entry script / config loading | stream_scaling.py, configs/stream_scaling.yaml | loads LongLive/Wan2.1 weights, LoRA adapter, prompts, beam_size, top_k, sliding_window_size, noise_fusion_sigma |
| Chunk-level generation pipeline | pipelines/stream_scaling.py | StreamT1CausalInferencePipeline.inference, _build_initial_beam, _generate_initial_candidates, _generate_followup_candidates |
| Stream-Scaled Noise Propagation | pipelines/stream_scaling.py | _build_candidate_noise |
| Candidate denoising with KV-cache | pipelines/stream_scaling.py, utils/wan_wrapper_stream_t1.py | _run_denoising_loop, WanDiffusionWrapper.forward |
| Short/long reward scoring | pipelines/stream_scaling.py | _decode_short_candidate_video, _decode_long_candidate_video, _compute_hybrid_score |
| Reward-guided memory route flags | pipelines/stream_scaling.py | _update_reward_history sets reward_score[key]["ema"] / reward_score[key]["append"] |
| Dynamic KV-cache sink update | wan/modules/causal_model_stream_t1.py | attention/cache update logic using current_sink_size, append_sink_start_frame, roped_k_ema_sink, append sinks |
4. Experimental Setup (实验设置)
- Backbone / model:Stream-T1 在 LongLive 上评估;LongLive 基于
Wan2.1-T2V-1.3B。论文设置 attention window size 为 9,sink size 为 3;开源配置中sink_size=3、max_sink_size=15、sliding_window_size=10、beam_size=2、top_k=2、denoising_step_list=[1000,750,500,250]、seed=42。 - Datasets / prompts:5s 视频使用 VBench 的 946 个 prompts;30s 视频使用 MovieGen 的前 128 个 prompts。所有视频为 16 FPS,分辨率 。
- Baselines:短/长视频 SOTA 对比包括 CausVid、Self-forcing、LongLive;TTS 对比包括 LongLive、Best-of-N、Beam Search、Stream-T1/Ours。
- Metrics:VBench/VBench-Long 指标包括 Subject Consistency、Background Consistency、Motion Smoothness、Imaging Quality、Aesthetic Quality;VideoAlign 指标包括 VQ (visual quality)、MQ (motion quality)、TA (text alignment)。论文未详细说明 GPU 型号/数量、训练 steps、learning rate、batch size;该方法是 test-time/inference-time scaling,不引入额外训练配置。
5. Experimental Results (实验结果)
5.1 5s generation:Table 1
| Method | Subject Consistency | Background Consistency | Motion Smoothness | Imaging Quality | Aesthetic Quality | VQ | MQ | TA |
|---|---|---|---|---|---|---|---|---|
| CausVid | 96.33 | 95.56 | 98.66 | 69.69 | 62.90 | 0.433 | 0.550 | 1.02 |
| Self-forcing | 95.26 | 95.67 | 98.67 | 71.61 | 63.97 | 0.099 | 0.088 | 1.193 |
| LongLive | 97.00 | 96.78 | 99.12 | 71.28 | 65.28 | 0.285 | 0.350 | 1.193 |
| Stream-T1 (on LongLive) | 97.25 | 97.05 | 99.15 | 71.42 | 65.98 | 0.426 | 0.629 | 1.305 |
5s 场景中,Stream-T1 在 Subject Consistency、Background Consistency、Motion Smoothness、Aesthetic Quality、MQ、TA 上最好;Imaging Quality 与 VQ 排名第二。相对 LongLive,TA 从 1.193 提升到 1.305,MQ 从 0.350 提升到 0.629。
5.2 30s generation:Table 2
| Method | Subject Consistency | Background Consistency | Motion Smoothness | Imaging Quality | Aesthetic Quality | VQ | MQ | TA |
|---|---|---|---|---|---|---|---|---|
| CausVid | 97.91 | 96.74 | 98.15 | 66.32 | 59.71 | -0.144 | 0.328 | 0.501 |
| Self-forcing | 97.18 | 96.37 | 98.35 | 68.35 | 59.19 | -0.461 | -0.216 | 0.656 |
| LongLive | 97.90 | 96.82 | 98.78 | 68.99 | 61.56 | -0.169 | -0.002 | 1.073 |
| Stream-T1 (on LongLive) | 98.43 | 97.18 | 99.03 | 69.10 | 62.11 | -0.073 | 0.226 | 1.170 |
30s 场景中,Stream-T1 在 VBench-Long 的五个指标上均超过 LongLive,并在 VideoAlign 的 VQ/TA 上最好;MQ 低于 CausVid 的 0.328,但显著高于 LongLive 的 -0.002。结果说明 chunk-level scaling 对长视频更关键,因为它直接改善了累积误差和长程一致性。
5.3 与通用 TTS 的对比:Table 3
| Method | Subject Consistency | Background Consistency | Motion Smoothness | Imaging Quality | Aesthetic Quality | VQ | MQ | TA |
|---|---|---|---|---|---|---|---|---|
| LongLive | 97.90 | 96.82 | 98.78 | 68.99 | 61.56 | -0.169 | -0.002 | 1.073 |
| + Best of N | 98.13 | 96.88 | 98.86 | 69.34 | 61.97 | -0.083 | 0.062 | 1.160 |
| + BeamSearch | 98.28 | 97.03 | 98.90 | 69.05 | 61.85 | -0.077 | 0.165 | 1.159 |
| + Ours | 98.43 | 97.18 | 99.03 | 69.10 | 62.11 | -0.073 | 0.226 | 1.170 |
Best-of-N 和 Beam Search 已经能带来提升,但 Stream-T1 在所有列上都更优。关键差异是:Best-of-N/Beam Search 主要扩展候选池;Stream-T1 同时更新候选生成的 noise prior 与后续 attention memory,因此 reward feedback 会改变未来生成条件。

Figure 3 解读:Figure 3 是 CausVid、Self-Forcing、LongLive 与 Stream-T1 的 qualitative comparison。论文指出,CausVid 与 Self-Forcing 在长序列中出现 frame-level visual distortion;LongLive 缓解了局部失真但 temporal consistency 仍会下降;Stream-T1 在 30s 过程中更稳定地保持主体、背景和动作连贯。
5.4 Ablation:Table 4 与 Figure 4
| Method | Subject Consistency | Background Consistency | Motion Smoothness | Imaging Quality | Aesthetic Quality | VQ | MQ | TA |
|---|---|---|---|---|---|---|---|---|
| w/o Stream-Scaled Memory Sinking | 98.30 | 97.04 | 98.92 | 69.51 | 61.90 | -0.083 | 0.188 | 1.146 |
| w/o Stream-Scaled Noise Propagation | 98.35 | 97.14 | 98.98 | 69.07 | 61.99 | -0.094 | 0.176 | 1.164 |
| w/o Stream-Scaled Reward Pruning | 98.04 | 96.88 | 98.87 | 69.17 | 61.22 | -0.173 | 0.014 | 1.035 |
| Ours | 98.43 | 97.18 | 99.03 | 69.10 | 62.11 | -0.073 | 0.226 | 1.170 |

Figure 4 解读:Figure 4 展示了三个模块的 qualitative ablation。去掉 Memory Sinking 会削弱背景稳定性;去掉 Noise Propagation 会出现局部结构 artifact,例如 subject tail;去掉 Reward Pruning 会造成 semantic misalignment 和 aesthetic degradation。结合 Table 4,Reward Pruning 的移除对 TA 影响最大,从 1.170 降到 1.035;Memory Sinking 虽让 Imaging Quality 数值升到 69.51,但 Subject/Background/Motion 与 VideoAlign 均下降,说明单帧画质不能替代长程一致性。
5.5 总体结论与限制
实验整体说明,Stream-T1 的收益主要来自三类反馈闭环:noise prior 让下一 chunk 从更可能成功的 latent 区域起步;reward pruning 同时约束局部视觉质量和长程时序一致性;memory sinking 把高质量历史片段变成可长期引用的语义 anchor。作者未单列 limitations;论文也未详细报告额外 wall-clock latency、显存曲线和硬件配置,因此实际部署时仍需评估 candidate expansion 与 reward model evaluation 带来的 inference-time 开销。