1. Motivation (研究动机)
Video generation 模型(尤其是基于 diffusion 的视频生成模型)最近被发现具有非平凡的推理能力:在给定首帧与自然语言指令后,模型能够生成一段在时空上一致、且逻辑合理的视频,从而解决迷宫、拼图、物理预测等推理任务。
但现有认知存在几个关键空白:
- Chain-of-Frames (CoF) 假说被默认采用:先前工作(Wiedemer et al., 2025;ChronoEdit 等)默认视频模型的推理”沿帧序列逐步展开”,即后帧在前帧基础上推导结论。这是一种从自回归文本模型延伸出来的直觉假设,但从未被严格验证。
- 内部机制不透明:对 DiT 架构在视频推理中各层的功能分工、denoise 过程中语义决策如何形成,几乎没有系统分析。
- 缺少提升视频推理能力的训练外手段:目前提升视频推理能力主要依赖更大模型或更多数据,没有利用模型内部 reasoning manifold 的 training-free 方法。
这些空白使得”视频模型为什么会推理、什么时候会推理、能否被外部引导”这三个问题无法回答;也直接制约了视频作为新一代推理载体(the next substrate for reasoning in intelligent systems)的进一步发展。
2. Idea (核心思想)
论文的核心主张:diffusion-based 视频模型的推理并非沿 “帧轴” 逐步展开,而是沿 “diffusion 去噪步骤轴” 展开。作者把这一机制命名为 Chain-of-Steps (CoS)。
与 CoF 相比,CoS 有两个关键差异:
- 推理空间不同:CoS 中每个去噪步骤都对整段视频的所有帧同时进行更新,推理在”整段视频”这个 workspace 里同时推进,而非一帧接一帧线性推进。
- 推理动态不同:早期去噪步骤对应多路径并行探索(multi-path / superposition),中期步骤完成关键剪枝与决策,晚期步骤巩固结果。这与 LLM 的 Chain-of-Thought 在语义上呈现类比关系。
基于这一机制,作者进一步:
- 发现 3 类涌现推理行为(working memory / self-correction / perception-before-action);
- 在单次 diffusion step 内揭示 DiT 的功能分工(感知 → 推理 → 巩固);
- 提出一个 training-free 的 latent-level ensemble 方法:对 mid-layer(20–29)的 latent 做多随机种子平均,从而在 reasoning-active window 里稳定多样推理轨迹,得到 +3.1% Overall score 的提升。
3. Method (方法)
3.1 Overall framework
论文整体是一篇”机制分析 + 训练外方法”的混合工作,没有新的训练目标或新的架构。流水线可划分为四块:
- 沿 diffusion 步骤分析推理动态:通过解码每一步的 clean latent 观察模型思考过程(Sec. 3)。
- 涌现推理行为分析:识别 working memory / self-correction / perception-before-action(Sec. 4)。
- 层级功能分析:token-level L2 能量可视化 + layer-wise latent swapping 对 DiT 内部做因果探测(Sec. 5)。
- training-free 的多 seed latent ensemble:基于上述发现设计的实际推理增强方法(Sec. 6)。
整个 teaser 如图 1 所示:
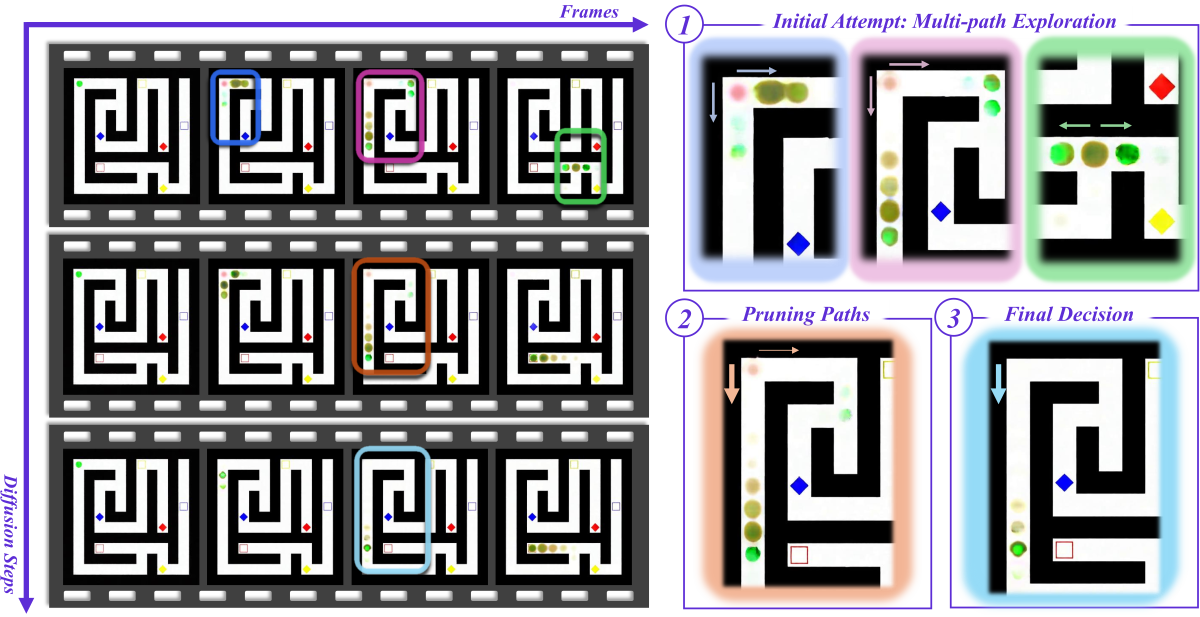
Figure 1 解读:图中的迷宫任务给出了 CoS 的直观画面——Frames 轴对应视频帧(x 方向),Diffusion Steps 轴对应去噪步骤(y 方向)。在 Step 0(最底行)模型同时描绘了两条到达红框的路径(Multi-path exploration),中间步骤(middle rows)抑制错误分支(Pruning Paths),最终步骤(顶行)只剩下一条正确路径(Final Decision)。关键的是,这些探索与剪枝是跨所有帧同时发生的,而不是沿帧序逐帧展开。
3.2 CoS:Diffusion Steps 作为主要推理轴
Flow matching 中间态的解读公式。作者基于 flow matching 推理框架分析 diffusion 中间态。连续传输路径:
模型学习速度场 。每一步估计的干净 latent(clean latent)为:
通过在每个 step 解码 ,可以直接”看”模型此时对最终视频的预估——这就是观察 CoS 动态的核心工具。
两种 Step-wise Reasoning 模式。作者把观察到的 CoS 分为两类:
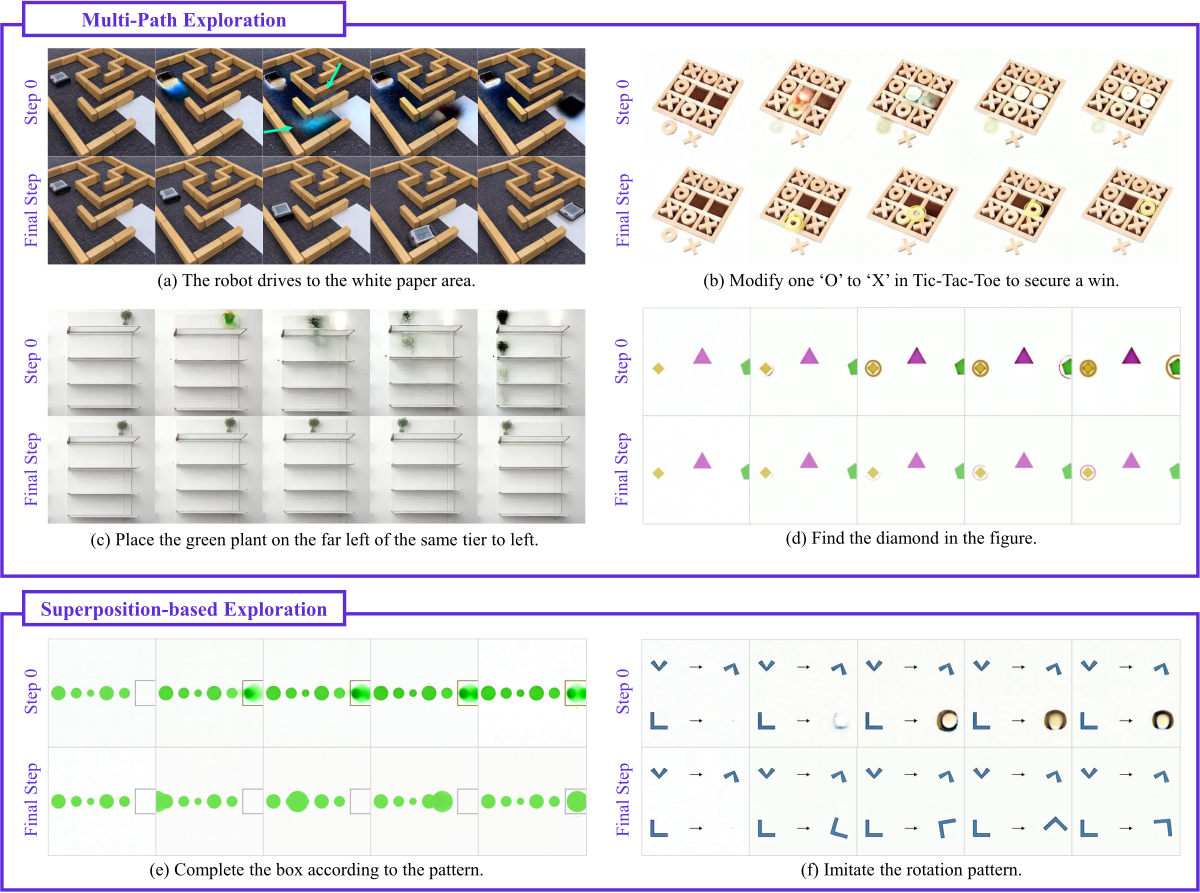
Figure 2 解读:上半行展示 Multi-Path Exploration:(a) 机器人在迷宫里同时探索上下两条路;(b) Tic-Tac-Toe 任务里同时标亮多个可落”O”的格子;(c) 绿植同时对准货架的多层;(d) 同时圈选两个候选钻石。下半行展示 Superposition-based Exploration:(e) 不同大小圆圈叠加(猜下一 item 的尺寸规律);(f) L 形对象以多角度旋转的”模糊”形态叠加存在。两种模式分别对应 BFS 式离散候选 vs. 连续叠加态,都只出现在早期 diffusion step 中,后期步骤会收敛到单一答案。
Noise perturbation & information flow。作者设计了两种噪声注入实验来因果验证 CoS:
- Noise at Step:在某一 diffusion step 把所有帧的 latent 替换成 。
- Noise at Frame:在某一帧上,所有 diffusion step 的 latent 替换成 。
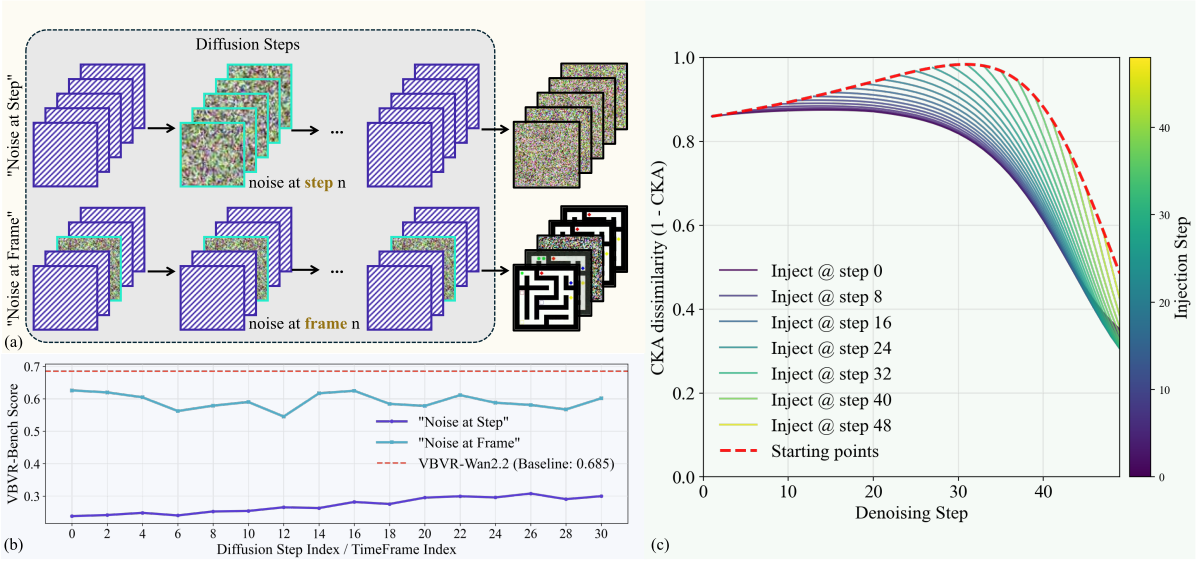
Figure 3 解读:(a) 两种注入方案示意;(b) 两种方案对性能的破坏力对比:Noise at Step 把模型得分从 0.685 砸到 0.3 以下,而 Noise at Frame 只造成轻微下降。(c) 用 CKA dissimilarity 度量信息传播:1.0 表示完全破坏,0.0 表示无影响。可见在早期 step 注入的噪声会贯穿整条轨迹且几乎不恢复,而到 step 20–30 之间敏感度最高(红色虚线峰值)——这刚好对应模型”已基本剪枝完毕、即将定案”的阶段。该实验从因果角度证明推理主要走 step 轴而非 frame 轴。
3.3 Emergent Reasoning Behaviors
作者进一步观察到三类 emergent 行为,直接类比 LLM 的”涌现”特性。
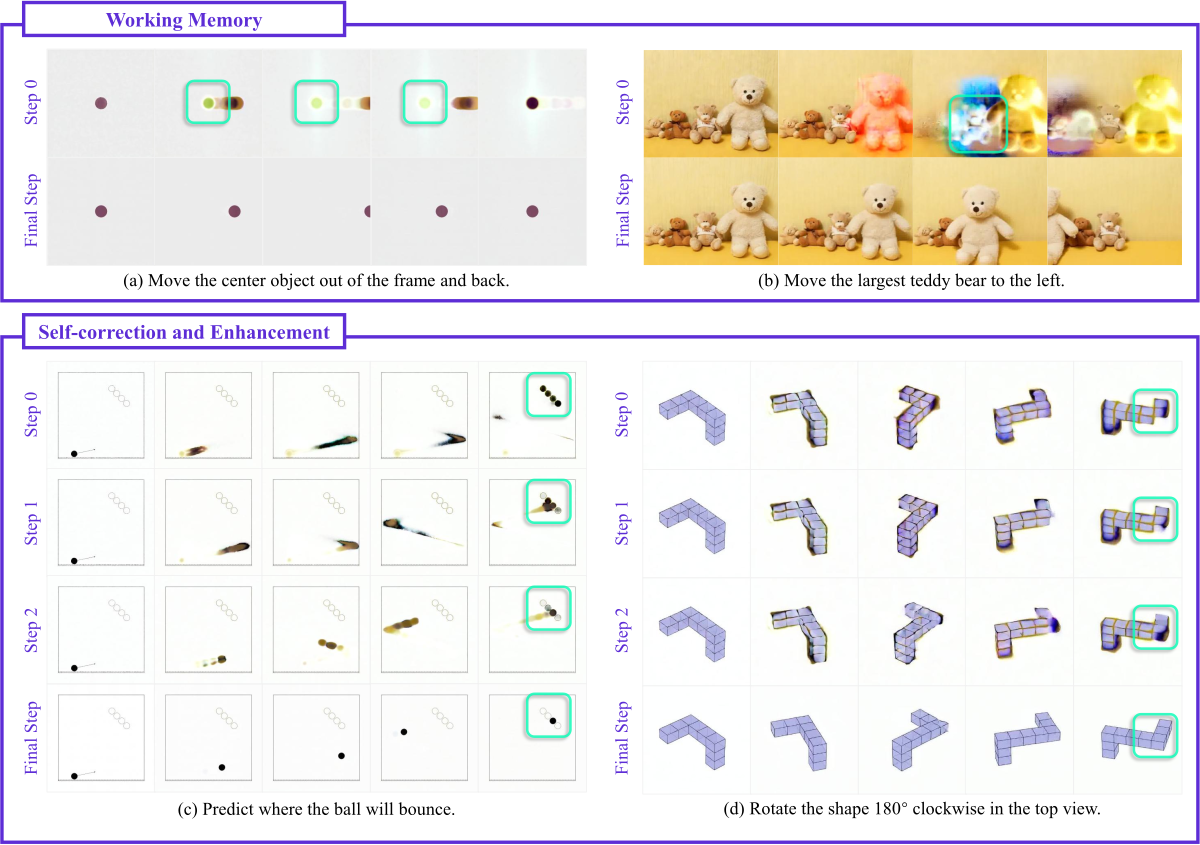
Figure 4 解读:
- (a) Working memory:中心点在物体离框又回来的过程中被保留,保证物体能回到原位;
- (b) 大泰迪熊遮挡小泰迪熊时,早期步骤仍保留小熊的轮廓,体现 object permanence;
- (c) Self-correction:小球轨迹初期残缺不全、末步自动补全;
- (d) 3D 形状旋转时,缺失的立方体直到后期 step 才出现,说明模型可修正早期错误配置。
Perception before Action(Sec. 4.3)体现第三种行为:
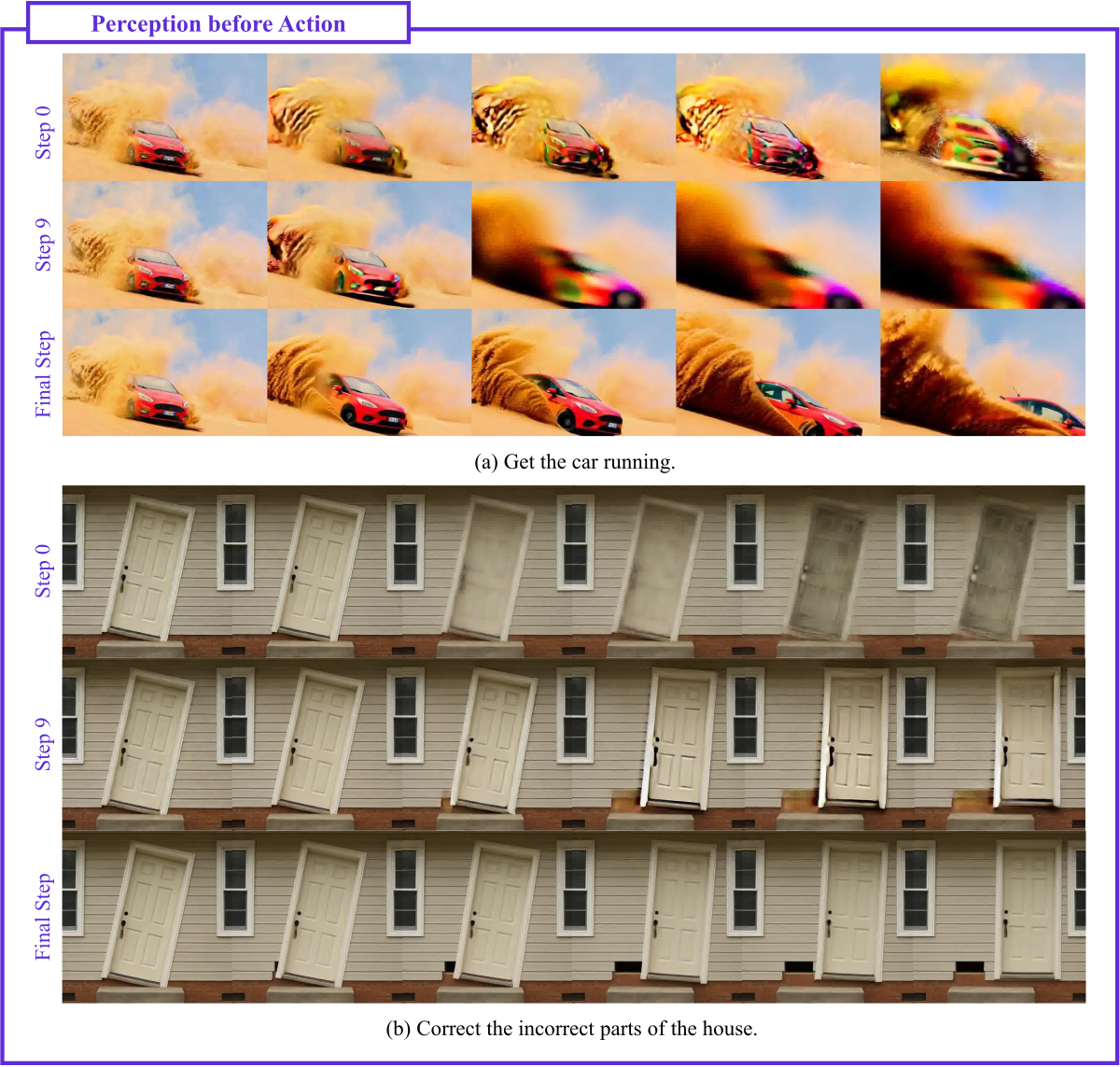
Figure 5 解读:(a) 早期 step 先把”车”这一前景对象在所有帧里定位,晚期 step 才引入运动与物理交互;(b) 早期 step 先识别”门”,晚期 step 再进行操作。这说明 diffusion 步骤内部呈现”先认物、再做事”的分工,与 5.1 节的层级分析呼应。
3.4 Layer-wise Mechanistic Analysis
Layer-wise token-level visualization。对每个 step 的每一层 block(Wan2.2-I2V-A14B 有 40 层,),通过 forward hook 抓取各 block 的输出 token 特征 ,再利用 patch_embedding 的 grid 维度 reshape 回 ,最后沿通道维求 L2 能量:
将每一 (layer, frame) 的 以 heatmap 展示,可以看到”前景—背景—推理目标”的能量在层间迁移。实现位于 tools/token_visualization.py 的 FeatureCapture 类。
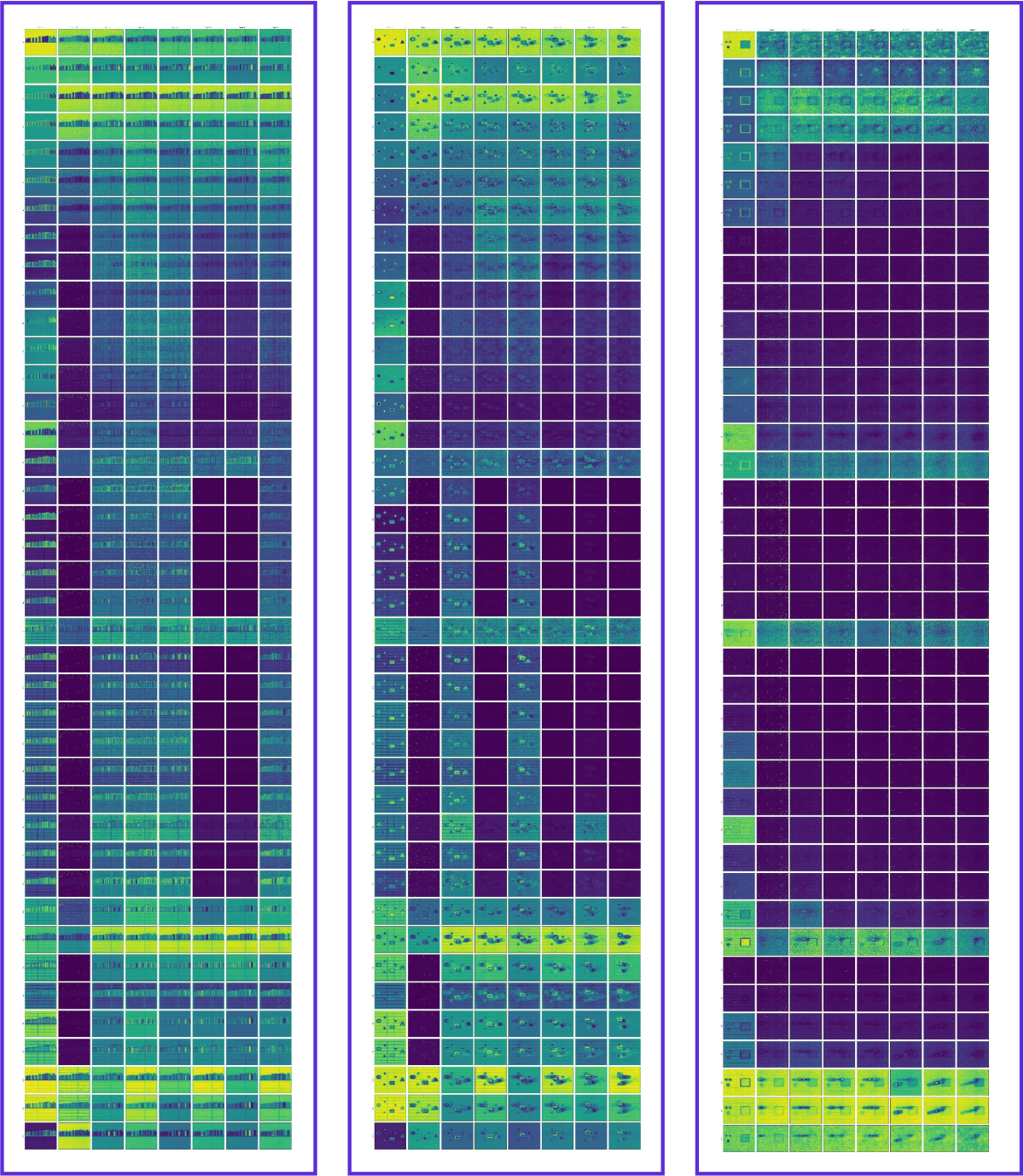
Figure 6(a) 解读:图的行为 DiT 层(),列为视频帧。可见前几层( 附近)主要激活在背景、全局结构上;从约第 9 层起,激活开始集中到文本提示对应的前景实体(如 “cats”、“bicycles”);中层还开始显式编码对象运动/交互所需的特征,是 reasoning 最活跃的区段。
Layer-wise latent swapping。为因果验证中间层是否真的决定推理结果,作者在 step 0 对”圈出 cats / 圈出 bicycles”两条配对推断做 latent 替换:
仅替换某一层 的 latent 令其他层保持不变,观察最终输出是否翻转。结果:只有替换到第 20 层附近时,模型识别目标会发生类别翻转——从而定位到 DiT 的 reasoning-active layer 主要集中在中-中后段(约 20–29 层)。
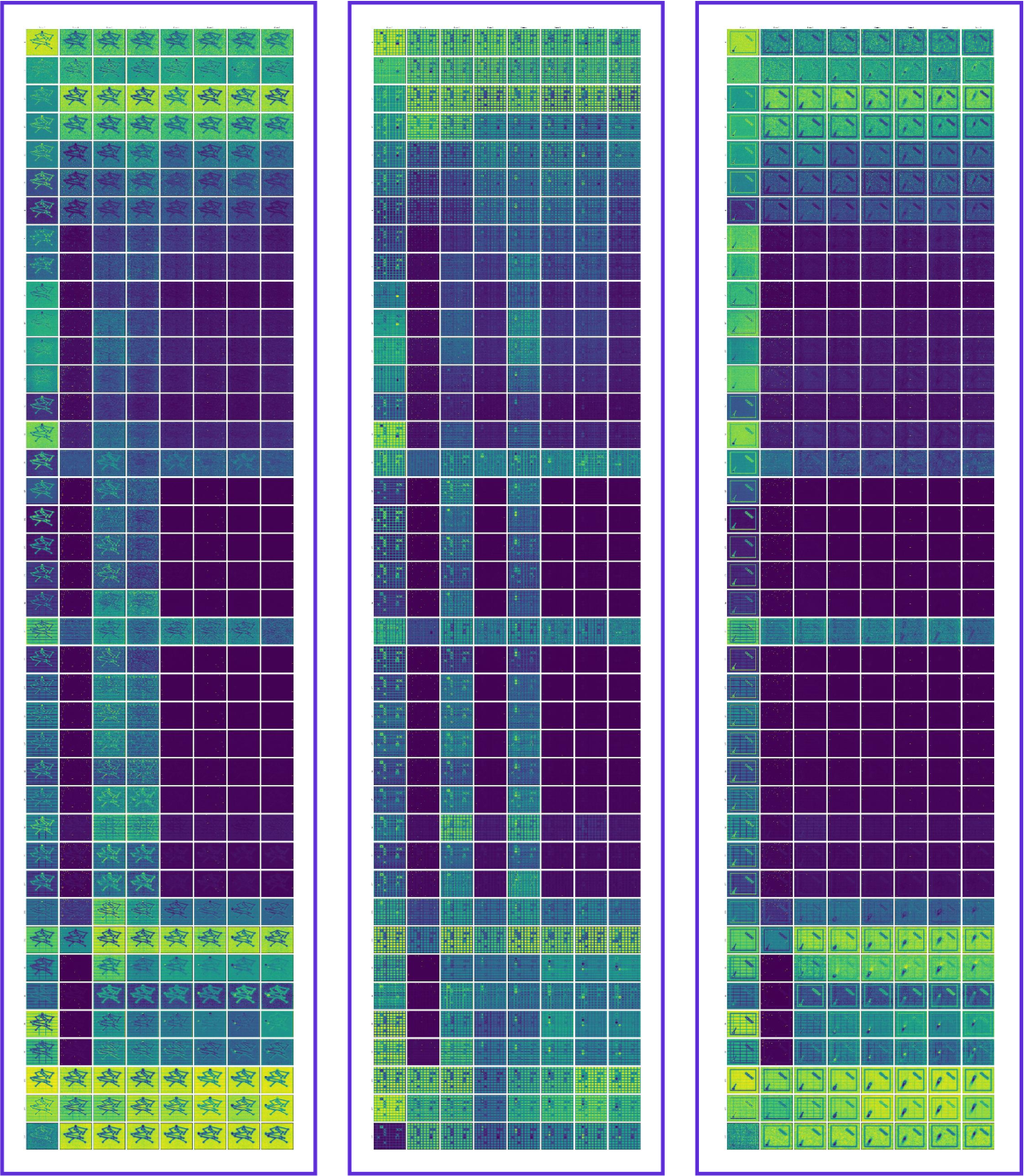
Figure 6(b) 解读:左图显示原始条件下模型圈出”cats”;替换中间层(例如 Layer 21)的 latent 后,最终输出翻转为”bicycles”,证明该层确实编码了因果性的语义决策信息。
3.5 Training-Free Latent Ensemble
基于以上发现,作者在不做任何训练的前提下提出 latent ensemble:
- 用 个不同随机种子()并行跑同一条 prompt;
- 在 first diffusion step () 提取各自 DiT 的中间层 latent ;
- 只对 layer 20–29(即 reasoning-active 窗口)做 spatial-temporal 平均:
- 把平均后的 latent 作为 step 0 的新中间表示继续完成剩余 denoise 过程。
该策略在 Perception-before-Action 窗口内融合多随机路径,抑制 seed 方差偏置,将模型隐式偏置到”正确答案”manifold 上。
DiT 层 token 能量抓取(Sec. 5.1 的 tooling,与 tools/token_visualization.py 对齐):
import torch
from einops import rearrange
class FeatureCapture:
"""Registers forward hooks on DiT blocks to record per-token features (Sec. 5.1).
Mirrors tools/token_visualization.py::FeatureCapture in the repo.
"""
def __init__(self, models_dict, layer_ids, blocks_attr="blocks"):
self.models = {k: v for k, v in models_dict.items() if v is not None}
self.layer_ids = sorted(layer_ids)
self.blocks_attr = blocks_attr
self._hooks = []
self._features = {}
self._grid_size = None
def _block_hook(self, layer_id):
def hook(module, inp, out):
if layer_id not in self._features:
self._features[layer_id] = out.detach().cpu().float()
return hook
def _grid_hook(self):
def hook(module, inp, out):
if self._grid_size is None:
self._grid_size = (out.shape[2], out.shape[3], out.shape[4])
return hook
def enable(self):
for model in self.models.values():
if hasattr(model, "patch_embedding"):
self._hooks.append(
model.patch_embedding.register_forward_hook(self._grid_hook())
)
blocks = getattr(model, self.blocks_attr, None)
if blocks is None:
continue
for lid in self.layer_ids:
if lid < len(blocks):
self._hooks.append(
blocks[lid].register_forward_hook(self._block_hook(lid))
)
def disable(self):
for h in self._hooks:
h.remove()
self._hooks.clear()
def reshape_to_spatial(feat, f, h, w):
B, N, D = feat.shape
if N != f * h * w:
feat = feat[:, N - f * h * w:]
return feat.reshape(B, f, h, w, D)
def channel_norm_energy(feat_sp: torch.Tensor) -> torch.Tensor:
"""E(b, f, h, w) = ||feat(b, f, h, w, :)||_2 (Sec. 5.1)."""
return feat_sp.norm(p=2, dim=-1)Step-wise 解码回调(Sec. 3 的可视化工具,与 tools/step_visualization.py 对齐)。
实际仓库里 的计算与 VAE 解码发生在 diffsynth/pipelines/wan_video.py::WanVideoPipeline.__call__ 内部(约 343–357 行):
if step_callback is not None and (vis_steps is None or progress_id in vis_steps):
x0_hat = self.scheduler.step(
noise_pred, self.scheduler.timesteps[progress_id],
latents_before_step, to_final=True,
)
if first_frame_latents is not None:
x0_hat[:, :, 0:1] = inputs_shared["first_frame_latents"]
x0_hat = x0_hat[:, :, f_offset:]
step_video = self.vae.decode(
x0_hat, device=self.device, tiled=tiled,
tile_size=tile_size, tile_stride=tile_stride,
)
step_callback(progress_id, num_inference_steps, step_video)tools/step_visualization.py 里给到的回调只负责把已经解码好的 step_video 落盘:
import os
from diffsynth.utils.data import save_video
def make_step_callback(step_output_dir: str, fps: int = 16):
"""Mirrors tools/step_visualization.py::make_step_callback verbatim.
The pipeline itself computes x_hat via FlowMatchScheduler.step(..., to_final=True)
and decodes it via self.vae.decode(...); this callback only persists the result.
"""
os.makedirs(step_output_dir, exist_ok=True)
def step_callback(step_idx: int, total_steps: int, step_video):
step_path = os.path.join(step_output_dir, f"step_{step_idx:03d}.mp4")
save_video(step_video, step_path, fps=fps, quality=5)
print(f" Saved intermediate step {step_idx}/{total_steps}: {step_path}")
return step_callback
def run_step_visualization(pipe, image, prompt, num_frames: int,
step_output_dir: str, vis_steps=None):
"""Mirrors tools/step_visualization.py::run_wan invocation pattern."""
callback = make_step_callback(step_output_dir)
return pipe(
prompt=prompt,
input_image=image,
num_frames=num_frames,
# Pipeline handles x0_hat = scheduler.step(..., to_final=True) and vae.decode internally.
step_callback=callback,
vis_steps=vis_steps, # None => decode at every step; otherwise an iterable of step ids.
)Noise perturbation 实验(Sec. 3 的两种对照,示意 WanVideoPipeline 内 denoise loop 中的注入位置):
import torch
@torch.no_grad()
def run_with_noise_injection(
pipe, x_T: torch.Tensor, prompt, scheme: str,
target_step: int = 0, target_frame: int = 0,
total_steps: int = 50,
):
"""scheme in {"noise_at_step", "noise_at_frame"} (Sec. 3, Fig. 3).
Conceptual mirror of the denoise loop inside WanVideoPipeline.__call__:
inputs_shared["latents"] -> model_fn(...) -> noise_pred ->
scheduler.step(noise_pred, timesteps[s], latents) -> next latents.
"""
latents = x_T.clone()
for s in range(total_steps):
if scheme == "noise_at_step" and s == target_step:
latents = torch.randn_like(latents)
if scheme == "noise_at_frame":
latents[:, :, target_frame] = torch.randn_like(latents[:, :, target_frame])
noise_pred = pipe.dit(latents, pipe.scheduler.timesteps[s], prompt)
latents = pipe.scheduler.step(noise_pred, pipe.scheduler.timesteps[s], latents)
return pipe.vae.decode(latents, device=pipe.device)Training-free latent ensemble(Sec. 6,多 seed 的 layer 20–29 平均)。该方法在 commit 001ed344 仓库中并未给出独立运行脚本(README 已公开 Intermediate steps decoding tool 与 Layer-wise token-level visualization tool 两个分析工具),下面伪代码是按论文 §6 描述对实现思路的概念性还原,需要在 WanVideoPipeline 内部对中间层 latent 加 forward hook 后注入:
import torch
@torch.no_grad()
def training_free_latent_ensemble(
pipe, prompt, image_cond,
num_seeds: int = 3,
ensemble_step: int = 0,
ensemble_layer_range: range = range(20, 30),
num_total_steps: int = 50,
):
"""Ensemble mid-layer (20-29) latents across T=3 random seeds at step 0 (Sec. 6).
NOTE: not a public script in commit 001ed344; conceptual reconstruction.
Intended implementation path:
1. Run T independent denoise rolls, each with FeatureCapture-style hooks
on DiT blocks 20..29 to record intermediate token features.
2. At step `ensemble_step`, average the recorded tensors across seeds.
3. Re-run that step with a forward_pre_hook that overrides each block's
input with the averaged tensor; continue normal denoise after that.
"""
states = [torch.randn_like(image_cond) for _ in range(num_seeds)]
layer_ids = list(ensemble_layer_range)
for s in range(num_total_steps):
caches = []
for x_s in states:
cap = FeatureCapture({"dit": pipe.dit}, layer_ids)
cap.enable()
_ = pipe.dit(x_s, pipe.scheduler.timesteps[s], prompt, image_cond)
cap.disable()
caches.append(cap._features)
if s == ensemble_step:
avg_cache = {
lid: torch.stack([c[lid] for c in caches], dim=0).mean(dim=0)
for lid in layer_ids
}
# Override mid-layer activations via forward_pre_hook, then take the step.
states = [
_denoise_step_with_layer_override(pipe, x_s, s, prompt,
image_cond, avg_cache)
for x_s in states
]
else:
states = [
pipe.scheduler.step(
pipe.dit(x_s, pipe.scheduler.timesteps[s], prompt, image_cond),
pipe.scheduler.timesteps[s], x_s,
)
for x_s in states
]
return pipe.vae.decode(states[0], device=pipe.device)Code-to-paper mapping table
| Paper Concept | Source File | Key Class / Function | github_ref |
|---|---|---|---|
| WanVideoPipeline backbone (VBVR-Wan2.2) | diffsynth/pipelines/wan_video.py | WanVideoPipeline.__call__(含 step_callback / vis_steps 与 x0_hat = scheduler.step(..., to_final=True) → vae.decode(...) 路径) | OpenSenseNova/Demystifying_Video_Reasoning@001ed344 |
| LTX-2 对比基线 | diffsynth/pipelines/ltx2_audio_video.py | LTX2AudioVideoPipeline | OpenSenseNova/Demystifying_Video_Reasoning@001ed344 |
| DiT 架构(40 层 Wan2.2-I2V-A14B) | diffsynth/models/wan_video_dit.py | WanModel、DiTBlock(WanModel.blocks 为 40 个 DiTBlock 的 nn.ModuleList) | OpenSenseNova/Demystifying_Video_Reasoning@001ed344 |
| Step-wise 解码 / Sec. 3 中间态可视化 | tools/step_visualization.py | build_wan22_pipeline(构建 pipeline)、make_step_callback(step_output_dir, fps)(落盘)、run_wan 透传 step_callback/vis_steps 给 pipeline | OpenSenseNova/Demystifying_Video_Reasoning@001ed344 |
| Layer-wise token 能量可视化(Sec. 5.1) | tools/token_visualization.py | FeatureCapture(_make_block_hook / _make_grid_hook / enable / disable / reset / collect)、reshape_to_spatial、viz_channel_norm | OpenSenseNova/Demystifying_Video_Reasoning@001ed344 |
| Layer-wise latent swapping(Sec. 5.2) | — | commit 001ed344 未提供独立脚本;按论文描述需在 WanModel.blocks[k] 上挂 forward_pre_hook,跨配对推断把第 层输入替换为另一条样本的 latent | OpenSenseNova/Demystifying_Video_Reasoning@001ed344 |
| Flow matching 前向 & 估计公式 | diffsynth/diffusion/flow_match.py | FlowMatchScheduler.step(..., to_final=True)(对应论文式 (1)(2)) | OpenSenseNova/Demystifying_Video_Reasoning@001ed344 |
| Training-free latent ensemble(Sec. 6) | — | 同样未提供独立脚本;在 WanVideoPipeline 上结合 FeatureCapture-风格 hook + forward_pre_hook 在 step 0 / layers 20–29 注入跨 seed 平均 latent | OpenSenseNova/Demystifying_Video_Reasoning@001ed344 |
4. Experimental Setup (实验设置)
Backbone 与基线:
- 主研究对象:VBVR-Wan2.2(基于 Wan2.2-I2V-A14B 微调的 video reasoning 模型);
- 开源视频模型基线:CogVideoX1.5-5B-I2V、HunyuanVideo-I2V、Wan2.2-I2V-A14B、LTX-2;
- 闭源视频模型基线:Runway Gen-4 Turbo、Sora 2、Kling 2.6、Veo 3.1;
- Video reasoning 基线:VBVR-Wan2.2(without ensemble)。
数据集 / Benchmark:
- 主 benchmark:VBVR-Bench,包含 In-Domain 50 与 Out-of-Domain 50 两类任务,每类覆盖 Abstract Reasoning、Knowledge、Perception、Spatial、Transformation 5 个子维度。
- 额外使用 VBench、ChronoEdit(单帧推理对照)。
配置:
- 原始 VBVR-Wan2.2 采用约 100 帧,默认 50 步 denoise;
- Training-Free Ensemble 使用 3 个不同种子,仅在 的 layers 20–29 聚合 latent,不涉及任何训练;
- 噪声扰动实验:
Noise at Step/Noise at Frame两种方案,扫过所有注入索引; - 模型分析实验围绕 40 层 DiT 的 token 激活与 layer-wise swap。
指标:Overall Score(In-Domain + Out-of-Domain 平均),各类别 avg 分数,以及 CKA dissimilarity。
5. Experimental Results (实验结果)
5.1 VBVR-Bench 主表
| Model | Overall | ID Avg. | OOD Avg. |
|---|---|---|---|
| CogVideoX1.5-5B-I2V | 0.273 | 0.283 | 0.262 |
| HunyuanVideo-I2V | 0.273 | 0.280 | 0.265 |
| Wan2.2-I2V-A14B | 0.371 | 0.412 | 0.329 |
| LTX-2 | 0.313 | 0.329 | 0.297 |
| Runway Gen-4 Turbo | 0.403 | 0.392 | 0.414 |
| Sora 2 | 0.546 | 0.569 | 0.523 |
| Kling 2.6 | 0.369 | 0.408 | 0.330 |
| Veo 3.1 | 0.480 | 0.531 | 0.429 |
| VBVR-Wan2.2 | 0.685 | 0.760 | 0.610 |
| + Training-Free Ensemble | 0.716 | 0.780 | 0.650 |
- Training-Free Ensemble 在 Overall 上提升 +3.1%(0.685→0.716),In-Domain +2.0%(0.760→0.780),Out-of-Domain +4.0%(0.610→0.650);
- 在 OOD 的 Abstract、Perception 两个最需要推理的子维度上提升最大(Abstract: 0.768→0.803,Perception: 0.572→0.705)。
5.2 Layer aggregation 窗口消融(Appendix A)
| Aggregated Layers | Overall | ID Avg | OOD Avg |
|---|---|---|---|
| baseline (VBVR-Wan2.2) | 0.685 | 0.760 | 0.610 |
| 0–9 (早期感知层) | 0.688 | 0.774 | 0.602 |
| 0–39 (全部层) | 0.690 | 0.767 | 0.613 |
| 20–29 (reasoning 窗口) | 0.716 | 0.780 | 0.650 |
仅对 reasoning-active 窗口做聚合才能得到显著收益,佐证了层级功能分工假设。
5.3 帧数消融(Appendix B)
| Configuration | Overall | ID | OOD |
|---|---|---|---|
| Chronoedit (1 帧) | 0.581 | 0.637 | 0.524 |
| 5 frames | 0.619 | 0.688 | 0.549 |
| 9 frames | 0.632 | 0.716 | 0.549 |
| 17 frames | 0.663 | 0.743 | 0.582 |
| 33 frames | 0.685 | 0.685 | 0.685 |
| 65 frames | 0.675 | 0.760 | 0.591 |
| VBVR-Wan2.2(~100 帧) | 0.685 | 0.760 | 0.610 |
说明虽然推理不沿帧展开,但仍需一定帧数作为”时空 scratchpad”;单帧设置下性能明显下降。
5.4 蒸馏对 CoS 的影响(Appendix C)
- 在 4-step distilled Wan2.2-I2V-14B 上,VBVR-Bench 从 0.685 降到 0.605;
- 大量任务中 early-step 的 multi-path exploration 被压缩但并未完全消失;
- 表明推理所需的 step 不能等比压缩;
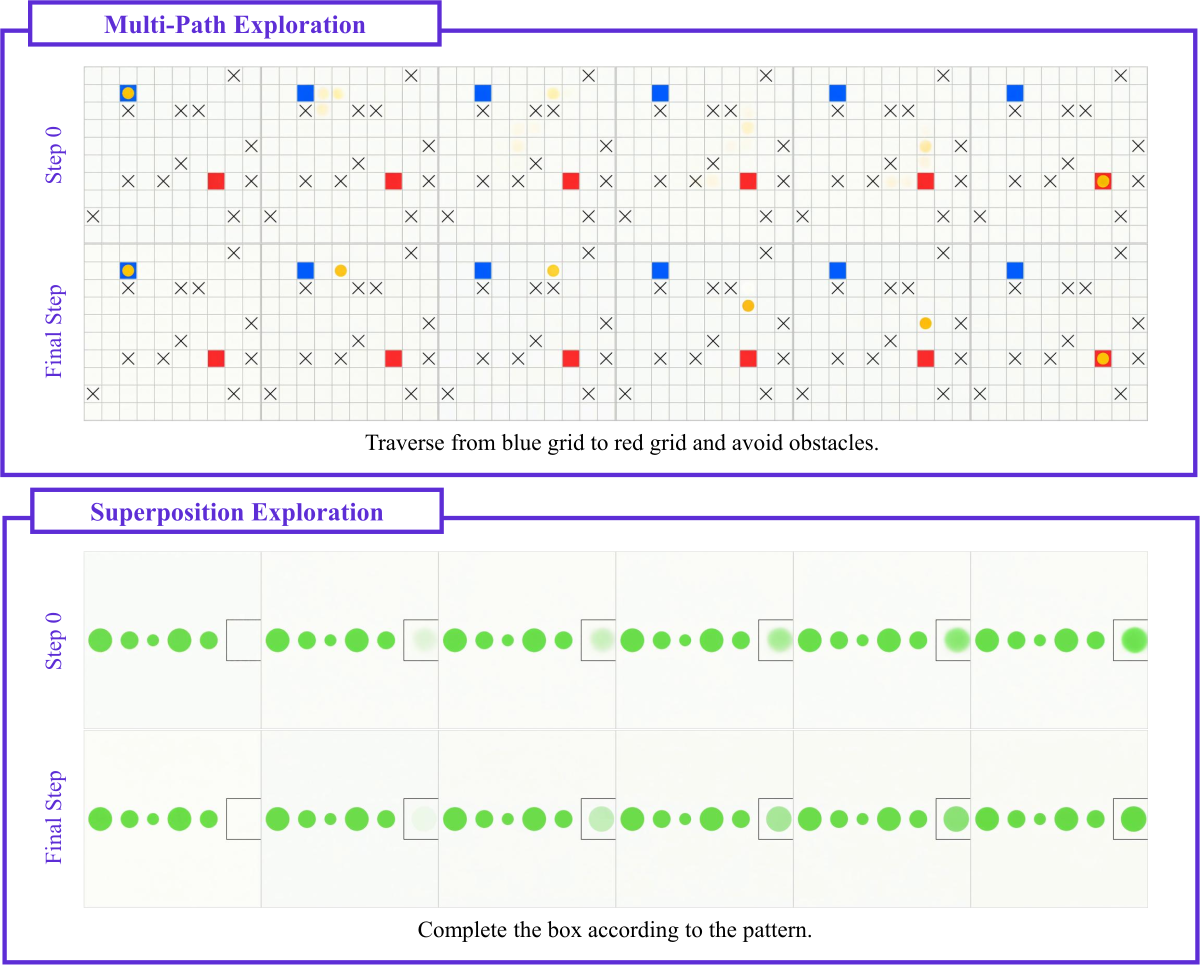
Figure 7 解读:(a)“按 pattern 补全格子”的任务中,distilled 模型的 step 0 依然呈现多候选形状共存的 superposition 现象;(b)“从蓝格走到红格”的寻路任务,distilled 模型依然能在早期 step 进行多路径尝试。尽管总 step 只剩 4 步,CoS 的基本模式仍然可观察。
5.5 更多定性证据
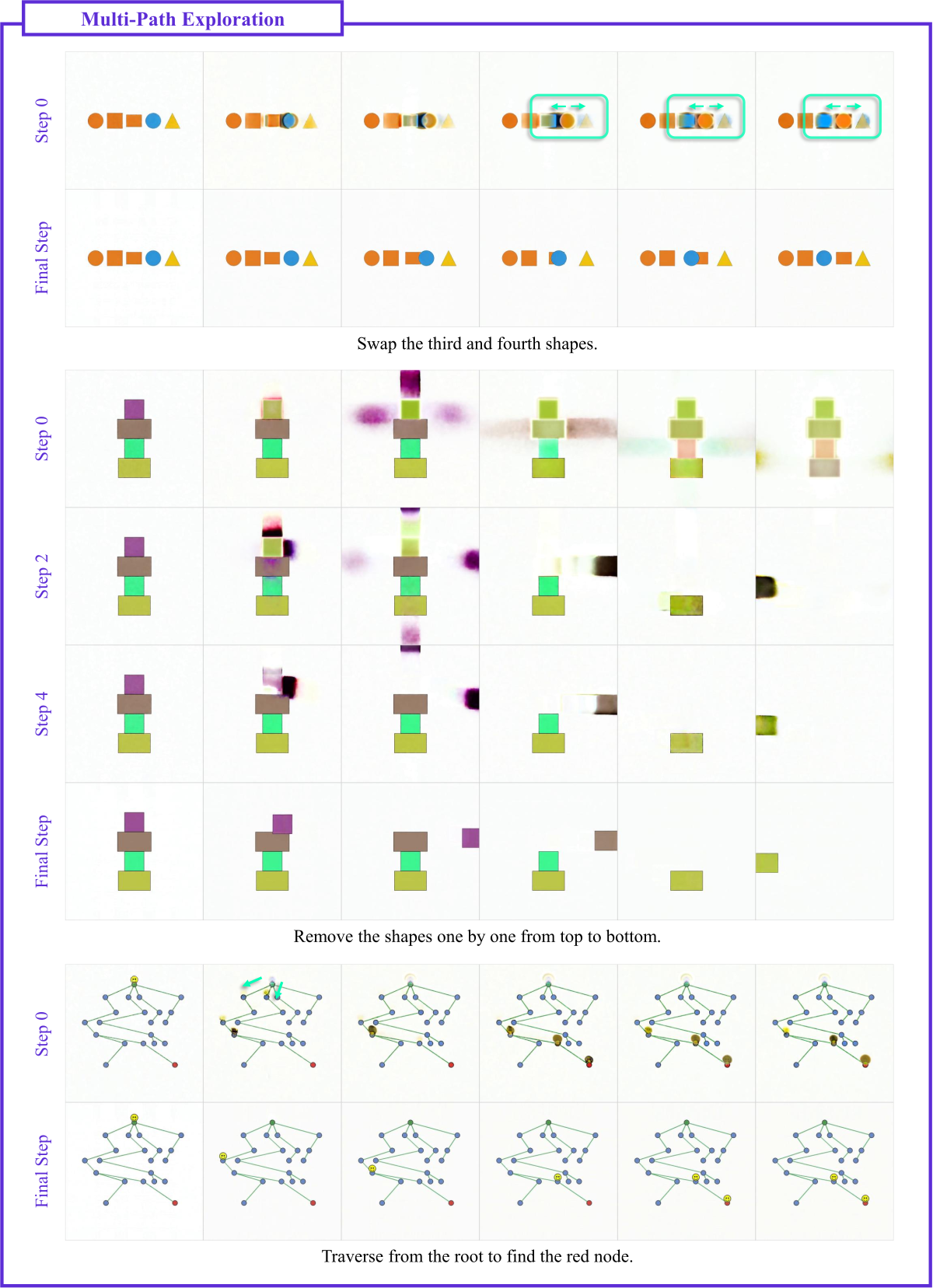
Figure 9 (a) 解读(Multi-Path Exploration 扩展):这组任务包括”交换第三个和第四个形状”、“从上到下逐个移除形状”、“从根到红节点找路径”。可以看到早期 step 都存在多条候选操作轨迹(例如多条遍历路径同时出现),后期 step 才收敛到唯一动作序列。
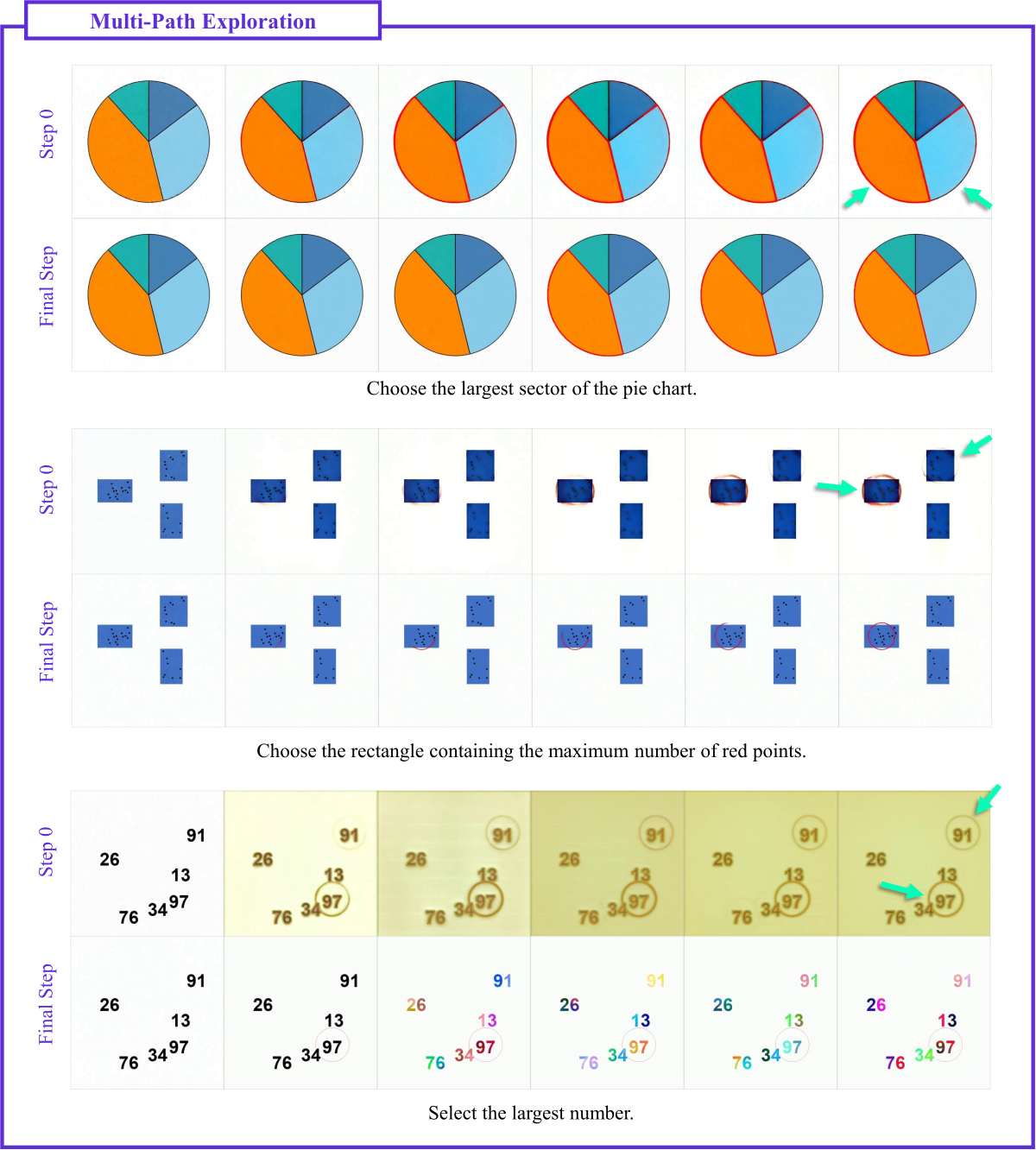
Figure 9 (b) 解读:在”选饼图最大扇区”、“选红点最多的矩形”、“选最大数字”三个判别任务中,模型同样在 step 0 同时高亮若干候选目标,随 step 推进逐步剪枝。
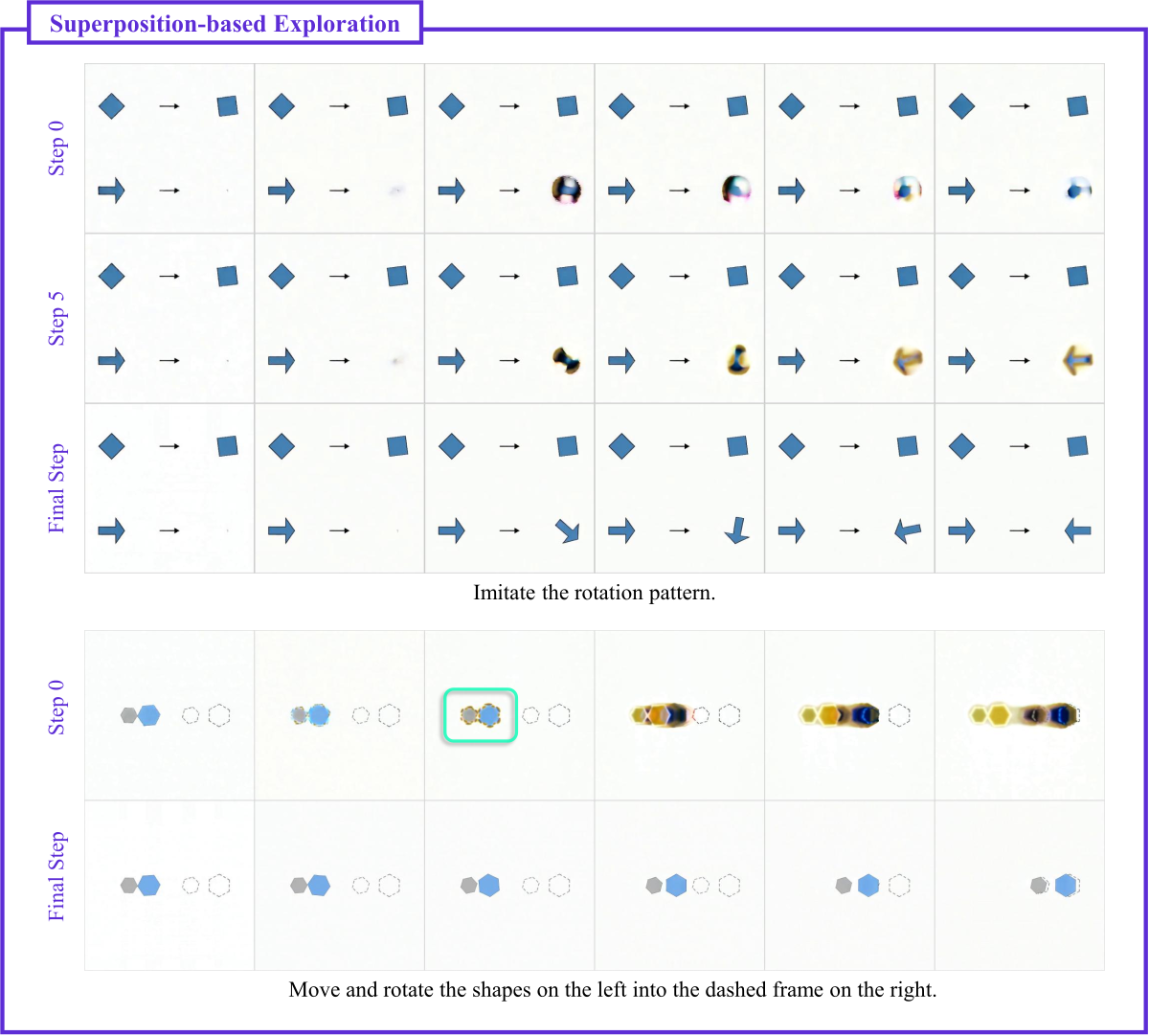
Figure 10 解读(Superposition-based Exploration 扩展):在”把左侧形状移入右侧虚线框”、“模仿旋转 pattern”两个任务中,中间步骤出现多个方向/位置的叠加态(模糊或多重形状),直到末步才锁定唯一形态。
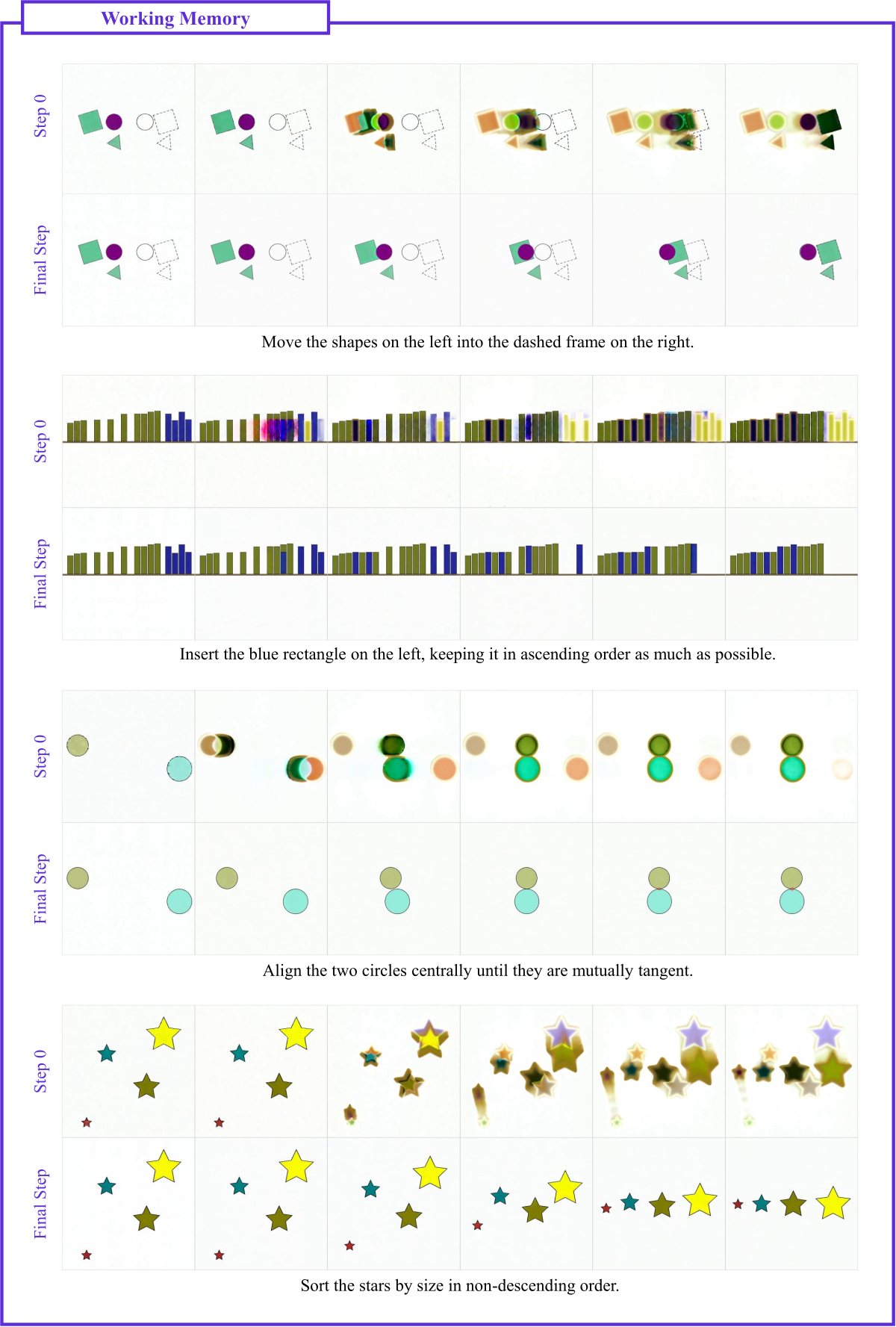
Figure 11 解读(Working Memory 扩展):包括”整理形状到右侧虚框”、“排序星星”、“中心切向圆”等任务。即使中间过程遮挡严重或对象快速移动,模型也在 step 0 即在视频各帧保持目标位置等关键上下文信息,保证最终结果与初始布局一致。
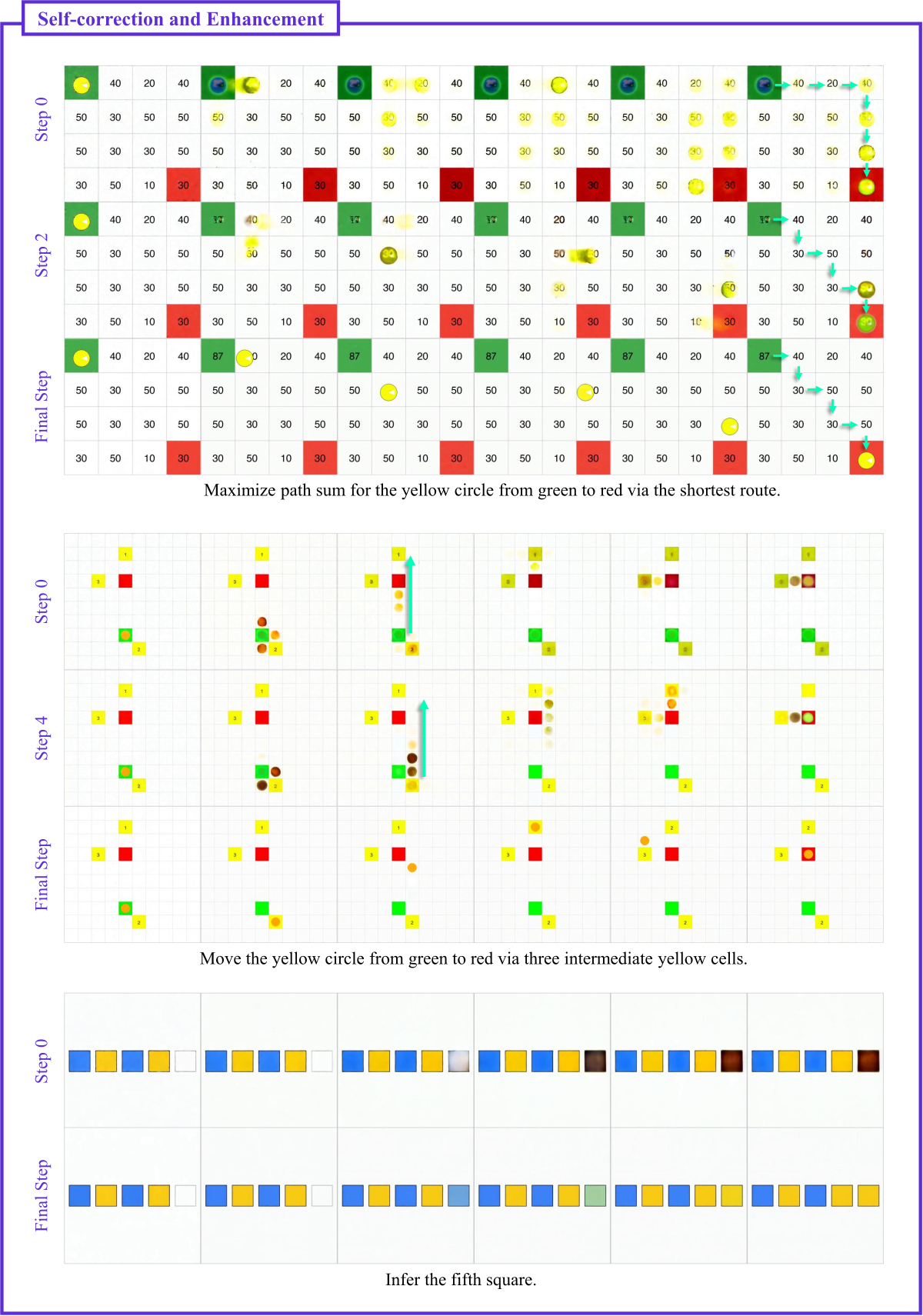
Figure 12 解读(Self-correction 第一批扩展):例如”yellow 圆从 green 走到 red 并经过 3 个 yellow 中间格”,早期步骤给出部分错误路径,中间 step 逐步纠正,末步形成完整、正确路线;“推断第 5 个方块”则先给出错误形状,最终 step 修正为正确结构。
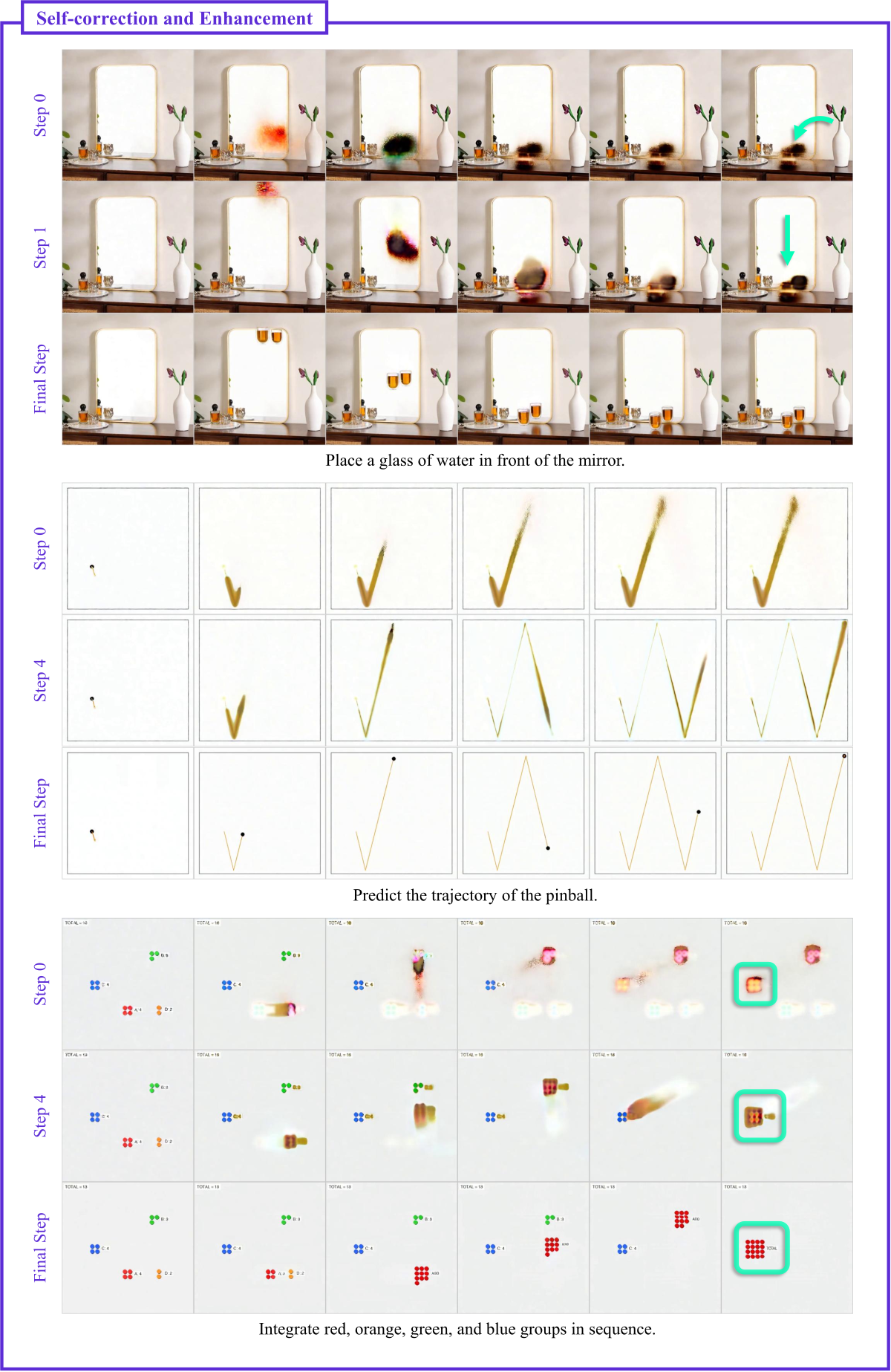
Figure 13 解读(Self-correction 第二批扩展):包括”把水杯放到镜子前”(反射效果从初始缺失修正为合理反射)、“预测弹珠轨迹”、“按红-橙-绿-蓝顺序整合小组”等任务,均展示了模型在 diffusion 过程中修正早期错误并完善结果的能力。
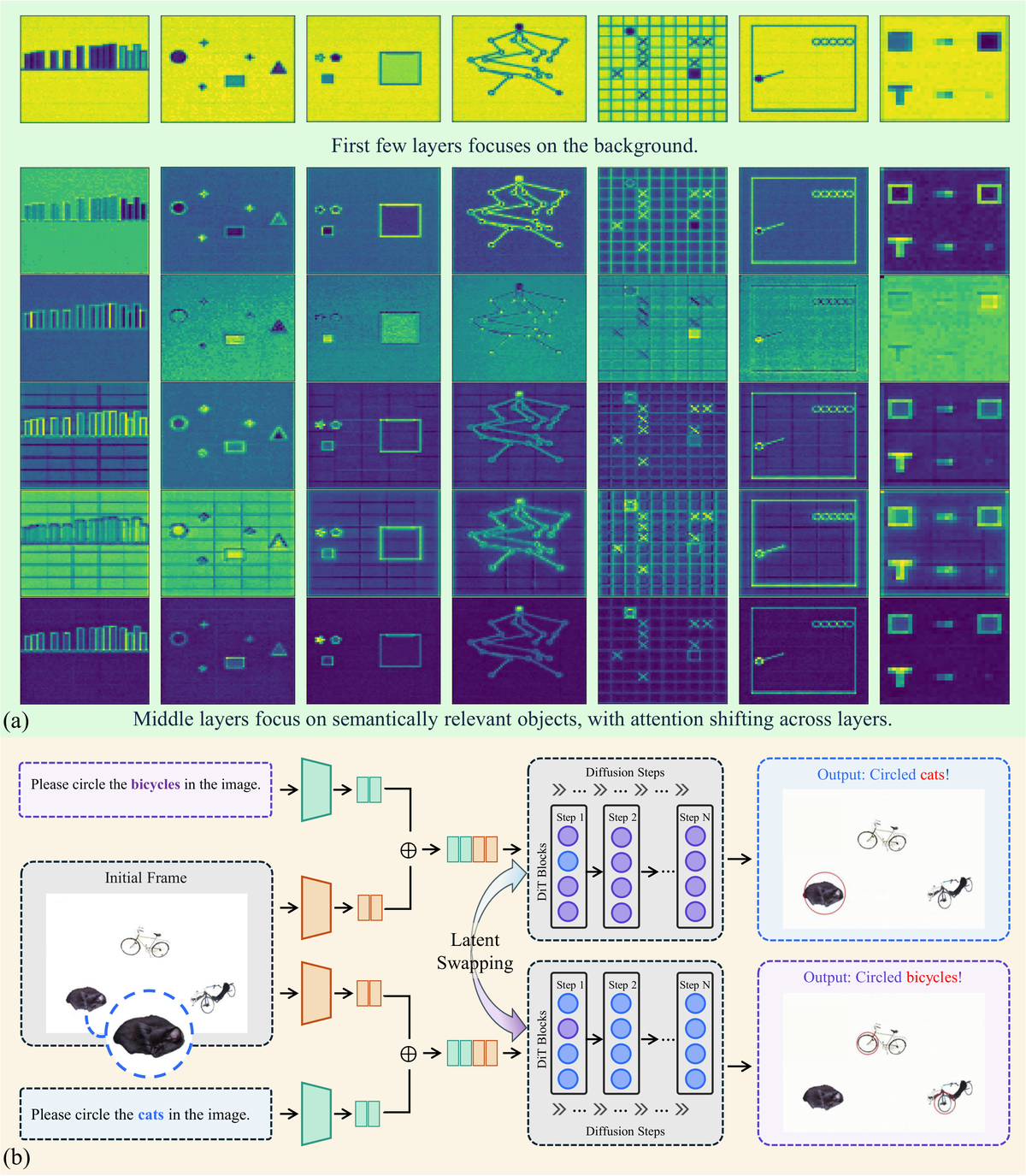
Figure 5 扩展解读:作者给出了更多”Perception before Action”的例子,早期 step 总是先明确前景物体和场景语义,再进入动作生成与物理交互;这一现象在单层范围内同样可以在 token 能量图上观察到。
5.6 小结与局限
- 结论:视频推理沿 diffusion step 展开(CoS),并在 DiT 内部表现为层级功能分工;training-free latent ensemble 是该机制的自然推论。
- 局限:
- 方法依赖能够稳定暴露中间 latent 的 DiT 架构(本文主要在 Wan2.2 / Wan2.1 / LTX-2.3 上验证);
- Training-Free Ensemble 的收益在部分子任务(如 In-Domain Perception)是负的(0.744 vs. 0.750),说明 mid-layer 聚合并非万能;
- 对分布外、更高复杂度的任务(如 OOD Spatial)甚至出现轻微下降(0.547 → 0.531);
- distilled 场景下 multi-path exploration 被压缩,CoS 信号削弱,相关性能下降 8%。