CollabVR: Collaborative Video Reasoning with Vision-Language and Video Generation Models
Paper: arXiv:2605.08735 Code: Joow0n-Kim/CollabVR Code reference:
main@722f59cf(2026-05-12) — official repo currently contains onlyREADME.mdandassets/; 代码搜索未找到开源实现
1. Motivation (研究动机)
现有 Thinking with Video / Chain-of-Frames 路线把 Video Generation Model (VGM) 当作可视化推理草稿本:模型从输入图像和任务 prompt 直接生成一个视频,用生成轨迹来表示推理过程。问题在于,VGM 擅长短时视觉模拟,却没有显式的任务级 reasoning controller,因此在 goal-directed video reasoning 中常见两类错误:一是多步骤任务里的 long-horizon drift,单个 prompt 把多个子动作压进一段视频后,模型容易只完成前半段或偏离目标;二是 mid-clip simulation error,一旦某个中间动作方向、对象或状态错了,后续帧会把错误继续传播。
 Figure 1 解读:图中把 VLM 和 VGM 的能力边界放在一起对比:VLM 会做逻辑规划但不擅长视觉模拟,VGM 能生成短 clip 但缺少显式推理。CollabVR 的动机正是把二者闭环耦合:让 VLM 不只在开头写计划,也不只在结尾评价整段视频,而是在每个 step 后检查生成结果并给出可修复信号。
Figure 1 解读:图中把 VLM 和 VGM 的能力边界放在一起对比:VLM 会做逻辑规划但不擅长视觉模拟,VGM 能生成短 clip 但缺少显式推理。CollabVR 的动机正是把二者闭环耦合:让 VLM 不只在开头写计划,也不只在结尾评价整段视频,而是在每个 step 后检查生成结果并给出可修复信号。
本文要解决的具体目标是:在不训练新 VGM 的前提下,把 VLM 放到 VGM 生成过程的 step-level loop 中,使其能动态决定下一步动作、判断当前 clip 是否执行了子动作,并把失败诊断反馈到下一次生成。这个问题值得研究,因为如果 step-level supervision 有效,test-time compute 就不再只是 Pass@k 式地重复抽样整段视频,而可以花在“构造一个逐步正确的视频轨迹”上。
 Figure 2 解读:该图展示 Gen-ViRe 上的 performance-cost trade-off:简单增加 Pass@k 的全视频重采样会较快进入收益递减,而 CollabVR 试图把计算预算转为局部规划、验证与修复,因此目标是在相近或更低 VGM 生成秒数下得到更高任务分数。
Figure 2 解读:该图展示 Gen-ViRe 上的 performance-cost trade-off:简单增加 Pass@k 的全视频重采样会较快进入收益递减,而 CollabVR 试图把计算预算转为局部规划、验证与修复,因此目标是在相近或更低 VGM 生成秒数下得到更高任务分数。
2. Idea (核心思想)
核心 insight:视频推理不应被看作“一次性采样一条完整视频”,而应被看作一个逐步 construction problem。VLM 的价值不在于替代 VGM 生成视频,而在于把 VGM 的短时视觉 prior 包进一个闭环:先规划当前最小动作,再让 VGM 生成短 clip,然后立即检查、修复或进入下一步。
CollabVR 的关键创新是 step-level VLM-VGM collaboration:Module 1 用 VLM-Driven Progressive Planning 动态决定下一步和总步数 ,避免 upfront plan 在看到生成结果前就锁死;Module 2 用 VLM-VGM Collaborative Reasoning 对每个 clip 输出 ,其中 , 是可执行失败诊断,并将诊断折回 prompt evolution。与 Pass@k 或 VideoTPO 的差别是粒度:Pass@k 重采样整段视频,VideoTPO 基于 full-video critique 重写 prompt;CollabVR 在错误发生的 step 当场定位并修复,避免整条轨迹被一个中间错误污染。
3. Method (方法)
3.1 Overall framework
任务由输入图像 和任务 prompt 定义,目标是生成视频 ,使其轨迹实现 要求的视觉推理。系统有两个 actor:VLM planner/verifier 与 image-to-video generator 。在第 步,planner 产生动作 ,VGM 以当前 conditioning frame 和动作 生成 clip ,verifier 判断 clip 是否执行了动作并返回诊断:
被接受的 clips 进入历史 ,当前 conditioning frame 更新为 的最后一帧,最终输出是 accepted clips 的拼接:
 Figure 3 解读:该图是 CollabVR 的主架构。上半部分是 Module 1:VLM 根据初始图像、任务和已接受历史逐步产出下一步 action,而不是一次性列出所有 milestones。下半部分是 Module 2:每个 VGM clip 都要经过 verifier;若 accept,则提交 clip 并进入下一步;若 reject,则把诊断写回 action prompt 并重采样,最多使用每步预算 。
Figure 3 解读:该图是 CollabVR 的主架构。上半部分是 Module 1:VLM 根据初始图像、任务和已接受历史逐步产出下一步 action,而不是一次性列出所有 milestones。下半部分是 Module 2:每个 VGM clip 都要经过 verifier;若 accept,则提交 clip 并进入下一步;若 reject,则把诊断写回 action prompt 并重采样,最多使用每步预算 。
直觉上,CollabVR 把“规划错误”和“执行错误”分开处理。长任务不是要求 VGM 一口气完成,而是被拆成 VGM 更擅长的短时动作;短 clip 内的对象、方向、场景坍塌等错误也不等到整段视频生成完才评价,而是在失败刚出现时修复。这样做的收益来自 localization:错误越早被定位,越少污染后续生成。
3.2 VLM-Driven Progressive Planning
Pre-planning 的做法是让 VLM 在生成前把 分解成 个 milestone prompts,然后 VGM 顺序生成每个 milestone。它的缺陷是 plan 在任何视觉结果出现前已经固定:如果第一个 clip 的实际状态和计划偏离,后续 prompts 仍然沿着旧假设继续;同时 很难只从文字 prompt 判断。CollabVR 改为 progressive planning:每次只计划 immediate next action,并在观察已生成 clip 后再决定是否继续, 只受上限 截断。
 Figure 4a–4b 解读:左侧对比 upfront pre-planning 与 progressive planning 的流程。pre-planning 在看到任何 VGM 输出前固定 Plan 1…N;progressive planning 则在每个 last frame 后重新询问 VLM 下一步。右侧显示在 Gen-ViRe + VBVR-Wan2.2 上,Module 1 的 progressive planning 在 matched cost 下相对 pre-planning 有 gain,说明动态 和状态依赖规划比固定 milestone 更稳。
Figure 4a–4b 解读:左侧对比 upfront pre-planning 与 progressive planning 的流程。pre-planning 在看到任何 VGM 输出前固定 Plan 1…N;progressive planning 则在每个 last frame 后重新询问 VLM 下一步。右侧显示在 Gen-ViRe + VBVR-Wan2.2 上,Module 1 的 progressive planning 在 matched cost 下相对 pre-planning 有 gain,说明动态 和状态依赖规划比固定 milestone 更稳。
3.3 VLM-VGM Collaborative Reasoning
每个生成 clip 都交给 verifier ,输出结构化判断 。这里 是 accept/reject, 包含文本原因和可执行修复建议。Verifier 的判定对象不是“整题是否完成”,而是“当前 planned action 是否发生”:partial-but-correct progress 可以 accept,因为是否继续由 planner 决定;wrong direction、wrong target、scene collapse 才应 reject。
若 reject,最简单的恢复是 prompt evolution:
然后固定 step 语义重新采样 VGM。论文 Appendix A.5 还加入 auxiliary failure router:当 次 within-step evolution 都失败时,router 根据 failure diagnosis 选择 regen、split 或 fallback。这不是主算法的核心公式,但解释了实现中如何处理 evolution 不足以恢复的情况。
 Figure 10 解读:这张 appendix trace 展示一个完整闭环:Step 1 中 M2 根据 verifier 诊断修正 prompt,接受后 M1 基于新 last frame 进入 Step 2。关键点是 M1 和 M2 共享同一个 per-clip verifier:它既能决定当前 clip 是否提交,也能提供下一次 action evolution 的信息。
Figure 10 解读:这张 appendix trace 展示一个完整闭环:Step 1 中 M2 根据 verifier 诊断修正 prompt,接受后 M1 基于新 last frame 进入 Step 2。关键点是 M1 和 M2 共享同一个 per-clip verifier:它既能决定当前 clip 是否提交,也能提供下一次 action evolution 的信息。
3.4 Pseudocode
公开 GitHub 搜索结果:存在 official repo Joow0n-Kim/CollabVR,但截至 main@722f59cf 只包含 README.md 与 assets/,没有 planner/verifier/VGM backend/evaluation 源码;因此以下 pseudocode 基于论文 Algorithm 1、Appendix A.5 和 README Pipeline,而非 released source implementation。
from dataclasses import dataclass
from typing import Literal
Verdict = Literal["accept", "reject"]
@dataclass
class VerifyResult:
verdict: Verdict
diagnosis: str
suggestion: str
good_fraction: float = 0.0
def progressive_plan(vlm, init_image, task_prompt, accepted_clips):
"""Module 1: plan only the immediate next action."""
state = {
"initial_image": init_image,
"task": task_prompt,
"history": [clip.last_frame for clip in accepted_clips],
}
action_prompt = vlm.plan_next_action(state)
task_complete = vlm.predict_task_complete(state)
return action_prompt, task_completedef verify_clip(vlm, init_image, task_prompt, history, candidate_clip, action_prompt):
"""Module 2: judge action execution, not final task completion."""
result = vlm.verify(
initial_image=init_image,
task=task_prompt,
history=history,
action=action_prompt,
video=candidate_clip,
)
return VerifyResult(
verdict=result["verdict"],
diagnosis=result.get("reason", ""),
suggestion=result.get("suggestion", ""),
good_fraction=float(result.get("good_fraction", 0.0)),
)
def evolve_prompt(action_prompt, verify_result):
"""Fold verifier diagnosis back into the same step."""
if verify_result.verdict == "accept":
return action_prompt
return f"{action_prompt}\nFix: {verify_result.suggestion}"def collabvr_loop(vlm, vgm, init_image, task_prompt, n_max=3, max_attempts=3):
"""Algorithm 1: closed-loop step-level video reasoning."""
accepted = []
frame = init_image
for _ in range(n_max):
action, done = progressive_plan(vlm, init_image, task_prompt, accepted)
if done:
break
last_result = None
for _attempt in range(max_attempts):
clip = vgm.generate(conditioning_frame=frame, prompt=action)
last_result = verify_clip(vlm, init_image, task_prompt, accepted, clip, action)
if last_result.verdict == "accept":
accepted.append(clip)
frame = clip.last_frame
if vlm.predict_task_complete({"task": task_prompt, "history": accepted}):
return concatenate(accepted)
break
action = evolve_prompt(action, last_result)
else:
action = failure_router(vlm, action, last_result)
return concatenate(accepted)def failure_router(vlm, action_prompt, verify_result):
"""Appendix A.5: choose regen / split / fallback after failed retries."""
route = vlm.route_failure(
action=action_prompt,
diagnosis=verify_result.diagnosis,
good_fraction=verify_result.good_fraction,
choices=["regen", "split", "fallback"],
)
if route["action"] == "regen":
return route["suggestion"]
if route["action"] == "split":
return f"Split into {route['estimated_steps']} sub-actions: {route['suggestion']}"
return "Use a simpler single-inference prompt for the residual task."3.5 Code-to-paper mapping
论文公式与 released code 实现差异:截至 main@722f59cf,released repo 没有可运行实现,因此无法比对 paper formula 与 source code;本文明确记录为“代码搜索未找到开源实现”。训练/推理配置数字也不是来自 launch script,而是来自论文 Appendix A.1;repo 中尚无 config 文件可核验。
Code reference:
main@722f59cf(2026-05-12) — pseudocode and mapping based on the official README/assets plus paper Algorithm 1 because source implementation is not released
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| CollabVR concept / motivation | README.md, assets/concept.png | No source implementation released |
| Overall pipeline | README.md, assets/pipeline.png | No source implementation released |
| VLM-Driven Progressive Planning | 代码搜索未找到开源实现 | Paper §3.2 / Algorithm 1 line 3 |
| VLM-VGM Collaborative Reasoning | 代码搜索未找到开源实现 | Paper §3.3 / Algorithm 1 lines 5–16 |
| Auxiliary failure router | 代码搜索未找到开源实现 | Appendix A.5 |
| Evaluation / VGM backends | 代码搜索未找到开源实现 | Appendix A.1 reports settings |
4. Experimental Setup (实验设置)
数据集:Gen-ViRe 含 个 samples、 个 categories,用 Gemini 2.5 Pro rubric judge 按 task correctness 评分,并报告三次独立评测平均值以降低 judge stochasticity;VBVR-Bench 含 个 test samples、 个 reasoning categories,包含 In-Domain 与 Out-of-Domain splits,并用 deterministic rule-based protocol 将生成视频与 ground-truth references 对齐比较。两个 benchmark 的互补性在于:Gen-ViRe 更偏真实/开放式视觉推理,VBVR-Bench 更偏受控 synthetic visual reasoning。
Baselines:Single Inference 是从 一次生成;Pass@ 使用 个独立 seeds,再由 Gemini 2.5 Pro 从候选中选最佳;VideoTPO 使用 full-video critique 迭代重写 prompts。本文还对 VLM choice 做 ablation:Gemini 2.5 Pro、Qwen3.5-27B、Qwen3.5-9B。
Metrics:主表报告 overall score / average category score,VBVR-Bench 还报告 ID/OOD category averages;Cost 定义为每样本由 VGM 生成的视频总秒数,因为作者认为 VLM compute 相对 VGM compute 可忽略。Human study 报告 blind side-by-side preference;VLM-supervisor benchmark 报告 D1 plan-depth exact match / MAE、D2 verifier agreement、D3 evolution quality。
训练/推理配置(来自论文 Appendix A.1,released repo 尚无 launch/config 文件):默认 planning steps、 per-step attempts;planner、verifier、failure router 使用 Gemini 2.5 Pro (gemini-2.5-pro),temperature 。VBVR-Wan2.2 使用 released 14B image-to-video checkpoint,最大面积 、保持 aspect ratio、 fps、 sampling steps、CFG scale ;Gen-ViRe 第一步生成 s / frames,后续 step 生成 s / frames,VBVR-Bench 让每个 clip 匹配 ground-truth duration,推理在单张 A100 上运行。Veo 3.1 使用 veo-3.1-fast-generate-preview API、native resolution、 fps,第一步 s、后续 s;Cosmos-Predict-2.5 使用 released 14B post-trained checkpoint、、 fps、每 step s,其余 sampling/guidance/scheduler/precision 使用 upstream defaults。
5. Experimental Results (实验结果)
5.1 Main benchmarks
Gen-ViRe (Table 1, exact values).
| VGM / Method | Cost (s) | Avg. | Abst. | Algo. | Analog. | Perc. | Plan. | Spat. |
|---|---|---|---|---|---|---|---|---|
| VBVR-Wan2.2 | 6.0 | 0.391 | 0.479 | 0.415 | 0.250 | 0.261 | 0.554 | 0.387 |
| VBVR-Wan2.2 + Pass@2 | 12.0 | 0.398 | 0.576 | 0.437 | 0.278 | 0.257 | 0.481 | 0.357 |
| VBVR-Wan2.2 + Pass@4 | 24.0 | 0.438 | 0.622 | 0.418 | 0.250 | 0.275 | 0.604 | 0.462 |
| VBVR-Wan2.2 + VideoTPO | 30.0 | 0.488 | 0.535 | 0.443 | 0.417 | 0.313 | 0.671 | 0.552 |
| VBVR-Wan2.2 + CollabVR | 17.8 | 0.531 | 0.569 | 0.606 | 0.333 | 0.367 | 0.821 | 0.488 |
| Veo 3.1 | 8.0 | 0.481 | 0.420 | 0.512 | 0.361 | 0.274 | 0.744 | 0.573 |
| Veo 3.1 + Pass@2 | 16.0 | 0.491 | 0.458 | 0.587 | 0.389 | 0.242 | 0.721 | 0.571 |
| Veo 3.1 + Pass@4 | 32.0 | 0.509 | 0.425 | 0.573 | 0.417 | 0.296 | 0.726 | 0.646 |
| Veo 3.1 + CollabVR | 21.4 | 0.550 | 0.434 | 0.641 | 0.472 | 0.325 | 0.768 | 0.657 |
VBVR-Bench (Table 2, exact overall / ID avg / OOD avg).
| VGM / Method | Cost (s) | Overall | ID Avg. | OOD Avg. |
|---|---|---|---|---|
| VBVR-Wan2.2 | 3.70 | 0.671 | 0.762 | 0.577 |
| VBVR-Wan2.2 + Pass@2 | 7.40 | 0.694 | 0.783 | 0.602 |
| VBVR-Wan2.2 + Pass@4 | 14.80 | 0.707 | 0.789 | 0.622 |
| VBVR-Wan2.2 + VideoTPO | 11.10 | 0.650 | 0.717 | 0.582 |
| VBVR-Wan2.2 + CollabVR | 10.91 | 0.757 | 0.819 | 0.696 |
| Cosmos-Predict2.5 | 3.70 | 0.308 | 0.312 | 0.304 |
| Cosmos-Predict2.5 + CollabVR | 10.91 | 0.403 | 0.406 | 0.400 |
主要结论:CollabVR 在 open-source VBVR-Wan2.2 上把 Gen-ViRe 从 提升到 ,在 Veo 3.1 上从 提升到 ;在 VBVR-Bench 上,VBVR-Wan2.2 从 到 ,Cosmos-Predict2.5 从 到 。这说明 step-level VLM supervision 不只是替代 reasoning-fine-tuned VGM,而能叠加在已有 reasoning VGM 上。
 Figure 5 解读:该 qualitative comparison 展示 CollabVR 在网格导航、对象操作和真实场景动作中如何把单次生成无法完成的任务拆成可执行子动作。上方长程任务中,baseline 容易在目标路径中漂移;下方开罐任务中,baseline 会绕过工具使用,而 CollabVR planner 产生明确 tool-use sub-actions。
Figure 5 解读:该 qualitative comparison 展示 CollabVR 在网格导航、对象操作和真实场景动作中如何把单次生成无法完成的任务拆成可执行子动作。上方长程任务中,baseline 容易在目标路径中漂移;下方开罐任务中,baseline 会绕过工具使用,而 CollabVR planner 产生明确 tool-use sub-actions。
5.2 Ablation and VLM choice
Per-module ablation (Table 3, exact values).
| Benchmark | M1 | M2 | Cost (s) | Overall | Δ |
|---|---|---|---|---|---|
| Gen-ViRe | ✗ | ✗ | 6.0 | 0.391 | — |
| Gen-ViRe | ✓ | ✗ | 10.9 | 0.511 | +0.120 |
| Gen-ViRe | ✗ | ✓ | 9.9 | 0.436 | +0.045 |
| Gen-ViRe | ✓ | ✓ | 17.8 | 0.531 | +0.140 |
| VBVR-Bench | ✗ | ✗ | 3.70 | 0.671 | — |
| VBVR-Bench | ✓ | ✗ | 6.19 | 0.706 | +0.035 |
| VBVR-Bench | ✗ | ✓ | 6.03 | 0.734 | +0.063 |
| VBVR-Bench | ✓ | ✓ | 10.91 | 0.757 | +0.086 |
 Figure 6 解读:该图显示 human-annotated step-count distribution。Gen-ViRe 中多步任务占比更高,因此 M1 progressive planning 对 Gen-ViRe 的贡献更大;VBVR-Bench 中单步/局部执行错误更多,因此 M2 verification + regeneration 的贡献更明显。
Figure 6 解读:该图显示 human-annotated step-count distribution。Gen-ViRe 中多步任务占比更高,因此 M1 progressive planning 对 Gen-ViRe 的贡献更大;VBVR-Bench 中单步/局部执行错误更多,因此 M2 verification + regeneration 的贡献更明显。
 Figure 7 解读: ablation 表明步数不是越多越好:增加到任务需要的程度会提升分数,但过度拆分会引入 step-boundary artifacts。这支持“让 VLM adaptive 选择 ”而不是固定 。
Figure 7 解读: ablation 表明步数不是越多越好:增加到任务需要的程度会提升分数,但过度拆分会引入 step-boundary artifacts。这支持“让 VLM adaptive 选择 ”而不是固定 。
Test-time scaling / VLM choice (Table 4, exact values).
| Method | VLM | Gen-ViRe | VBVR-Bench |
|---|---|---|---|
| Pass@1 | — | 0.391 | 0.671 |
| Pass@2 | Gemini 2.5 Pro | 0.398 | 0.694 |
| Pass@4 | Gemini 2.5 Pro | 0.438 | 0.707 |
| VideoTPO | Gemini 2.5 Pro | 0.488 | 0.650 |
| CollabVR | Qwen3.5-9B | 0.514 | 0.710 |
| CollabVR | Qwen3.5-27B | 0.510 | 0.717 |
| CollabVR | Gemini 2.5 Pro | 0.531 | 0.757 |
 Figure 8 解读:Gen-ViRe 的 per-category heatmap 说明不同 reasoning 类型依赖不同 module:Planning 类任务中 M1 alone gain 为 ,因为任务本质上是长链物理动作;Analogy 类任务中 M2 alone gain 为 ,因为它更像单步 symbolic transformation。Full M1+M2 在所有类别都有正增益,范围为 到 。
Figure 8 解读:Gen-ViRe 的 per-category heatmap 说明不同 reasoning 类型依赖不同 module:Planning 类任务中 M1 alone gain 为 ,因为任务本质上是长链物理动作;Analogy 类任务中 M2 alone gain 为 ,因为它更像单步 symbolic transformation。Full M1+M2 在所有类别都有正增益,范围为 到 。
 Figure 14 解读:VBVR-Bench 的 per-category heatmap 进一步说明 M1/M2 的分工不是固定模板,而与 task type 相关。若任务已有清晰单步目标,M2 的局部检测和重采样更有效;若任务需要显式中间状态,M1 的 decomposition 才是主要收益来源。
Figure 14 解读:VBVR-Bench 的 per-category heatmap 进一步说明 M1/M2 的分工不是固定模板,而与 task type 相关。若任务已有清晰单步目标,M2 的局部检测和重采样更有效;若任务需要显式中间状态,M1 的 decomposition 才是主要收益来源。
 Figure 13 解读:该图分析 per-step attempt budget 。随着 增大,M2-only 分数单调上升,但边际收益下降;论文因此选择 作为默认,兼顾修复机会和生成成本。
Figure 13 解读:该图分析 per-step attempt budget 。随着 增大,M2-only 分数单调上升,但边际收益下降;论文因此选择 作为默认,兼顾修复机会和生成成本。
5.3 Human alignment and user preference
Human-eval across 3 VLMs (Table 6, exact values).
| Axis | Gemini 2.5 Pro | Qwen3.5-27B | Qwen3.5-9B |
|---|---|---|---|
| D1 VBVR-Bench exact-match | 64.0% | 64.2% | 53.0% |
| D1 Gen-ViRe exact-match | 73.6% | 55.6% | 61.1% |
| D1 Overall | 68.0% | 58.7% | 56.4% |
| D1 MAE | 0.366 | 0.491 | 0.484 |
| D2 accept-recall | 84.8% | 82.4% | 77.6% |
| D2 reject-recall | 65.6% | 44.8% | 40.8% |
| D2 Overall | 75.2% | 63.6% | 59.2% |
| D2 Cohen’s (Gen-ViRe) | 0.676 | 0.432 | 0.304 |
| D3 Overall mean | 2.61 | 2.55 | 2.35 |
| D3 | 93.8% | 95.0% | 86.3% |
| D3 | 67.5% | 60.0% | 48.8% |
 Figure 9 解读:四个 panel 分别对应 step-count distribution、plan-depth match、verification agreement 和 evolution quality。Gemini 2.5 Pro 在 D1/D2/D3 上整体最接近 human annotators,尤其 D2 reject-recall 明显高于 Qwen models,支持论文默认使用 Gemini 作为 planner/verifier。
Figure 9 解读:四个 panel 分别对应 step-count distribution、plan-depth match、verification agreement 和 evolution quality。Gemini 2.5 Pro 在 D1/D2/D3 上整体最接近 human annotators,尤其 D2 reject-recall 明显高于 Qwen models,支持论文默认使用 Gemini 作为 planner/verifier。
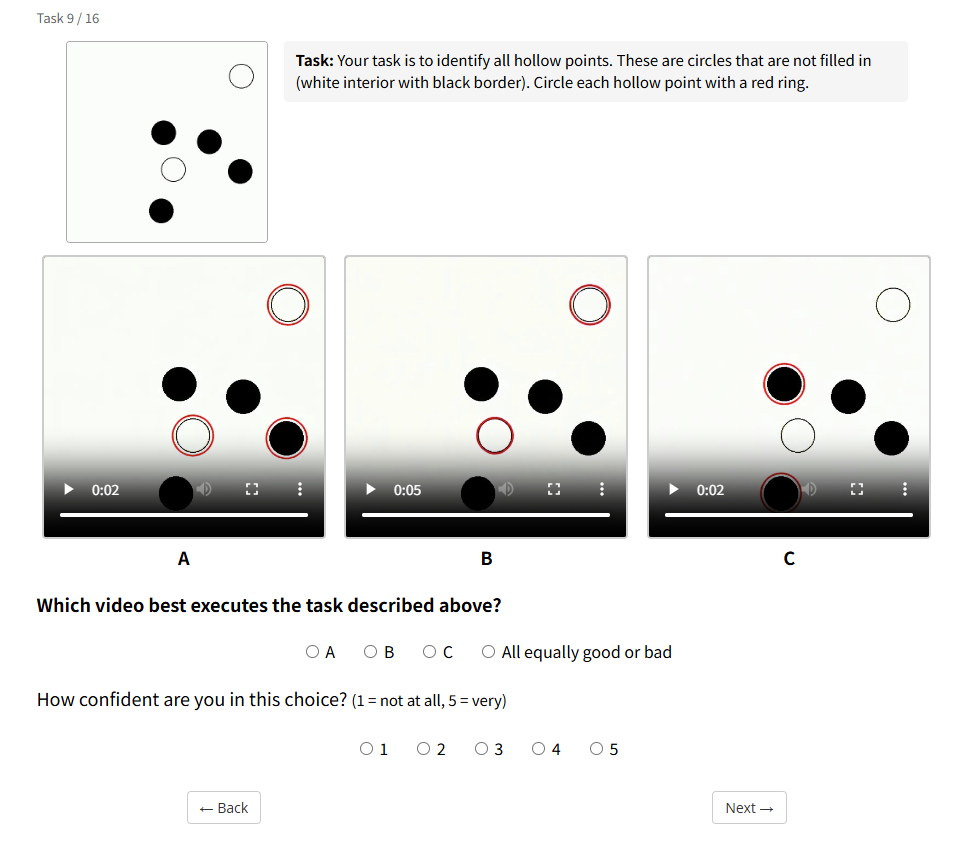 Figure 11 解读:用户研究界面采用 blinded A/B/C videos,参与者只看到任务、输入图像和三段匿名视频,再做 forced-choice preference 与 confidence rating。这避免了模型名或方法名对偏好的直接影响。
Figure 11 解读:用户研究界面采用 blinded A/B/C videos,参与者只看到任务、输入图像和三段匿名视频,再做 forced-choice preference 与 confidence rating。这避免了模型名或方法名对偏好的直接影响。
 Figure 12 解读:用户研究包含 名 participants、 个 tasks,排除 Equal responses 后 CollabVR preference share 为 ,高于 Pass@4 的 与 Pass@1 的 。这说明自动评估之外,人类也更偏好逐步修复后的输出。
Figure 12 解读:用户研究包含 名 participants、 个 tasks,排除 Equal responses 后 CollabVR preference share 为 ,高于 Pass@4 的 与 Pass@1 的 。这说明自动评估之外,人类也更偏好逐步修复后的输出。
5.4 Additional qualitative findings and limitations
 Figure 15 解读:该图按 planner-predicted step count 分组展示 VBVR-Bench 样例。 越大,任务越依赖中间状态;CollabVR 相比 single-shot 的优势也更直观,因为每个子目标都能被 VGM 单独执行并被 verifier 检查。
Figure 15 解读:该图按 planner-predicted step count 分组展示 VBVR-Bench 样例。 越大,任务越依赖中间状态;CollabVR 相比 single-shot 的优势也更直观,因为每个子目标都能被 VGM 单独执行并被 verifier 检查。
 Figure 16 解读:Cosmos-Predict-2.5 的 appendix 样例说明 CollabVR 能迁移到另一个 open-source VGM。虽然 Cosmos 本身会出现外部手/笔等 hallucination,但通过 step-level guidance,生成更接近 in-canvas action。
Figure 16 解读:Cosmos-Predict-2.5 的 appendix 样例说明 CollabVR 能迁移到另一个 open-source VGM。虽然 Cosmos 本身会出现外部手/笔等 hallucination,但通过 step-level guidance,生成更接近 in-canvas action。
 Figure 17 解读:该图覆盖 Gen-ViRe 上的 open-source VBVR-Wan2.2 与 closed-source Veo 3.1,包含 dashcam、refrigerator、mirror reflection、Raven matrices 等任务。它支持主表结论:CollabVR 的收益不是单个 VGM 特有现象。
Figure 17 解读:该图覆盖 Gen-ViRe 上的 open-source VBVR-Wan2.2 与 closed-source Veo 3.1,包含 dashcam、refrigerator、mirror reflection、Raven matrices 等任务。它支持主表结论:CollabVR 的收益不是单个 VGM 特有现象。
 Figure 18 解读:同一个 VBVR-Bench trace 在不同 verifier VLM 下产生不同恢复路径。Qwen3.5-9B 出现 false accept,Qwen3.5-27B 给出较粗的 positional cue,Gemini 2.5 Pro 能明确排除 distractor;这解释了 Table 6 中 D2/D3 差距如何传导到最终视频。
Figure 18 解读:同一个 VBVR-Bench trace 在不同 verifier VLM 下产生不同恢复路径。Qwen3.5-9B 出现 false accept,Qwen3.5-27B 给出较粗的 positional cue,Gemini 2.5 Pro 能明确排除 distractor;这解释了 Table 6 中 D2/D3 差距如何传导到最终视频。
 Figure 19 解读:final +CollabVR outputs 随 verifier 能力变化而变化,说明 CollabVR 的瓶颈不只在 VGM,也在 VLM 是否能准确 detect/reject failure 并给出可执行修复。
Figure 19 解读:final +CollabVR outputs 随 verifier 能力变化而变化,说明 CollabVR 的瓶颈不只在 VGM,也在 VLM 是否能准确 detect/reject failure 并给出可执行修复。
 Figure 20 解读:失败案例分为两类上限:Case 1 是 VLM detection failure,verifier 漏检导致错误 clip 被提交;Case 2 是 VLM 诊断正确但 VGM 仍无法执行细粒度长程控制。这表明 test-time orchestration 不能替代更强的 VGM 训练。
Figure 20 解读:失败案例分为两类上限:Case 1 是 VLM detection failure,verifier 漏检导致错误 clip 被提交;Case 2 是 VLM 诊断正确但 VGM 仍无法执行细粒度长程控制。这表明 test-time orchestration 不能替代更强的 VGM 训练。
 Figure 21 解读:maze case 中,partial re-generation 从失败前的 good prefix 继续,比 full re-generation 更有效。它强化了本文的核心主张:test-time compute 最有价值的使用方式不是重启整段视频,而是定位并重修 failed suffix。
Figure 21 解读:maze case 中,partial re-generation 从失败前的 good prefix 继续,比 full re-generation 更有效。它强化了本文的核心主张:test-time compute 最有价值的使用方式不是重启整段视频,而是定位并重修 failed suffix。
作者明确提到的限制是:CollabVR 的收益受限于 VGM 的 per-step instruction-following reliability。若 VGM 对单个短动作也不稳定,decomposition 会把错误暴露得更多而不是解决问题;若任务是 symbolic/atomic transformation,强行拆分还可能制造 contrived intermediates。未来方向包括 reasoning-oriented VGM training、physics-aware fine-tuning、symbolic-transformation pretraining 与更细粒度 failure localization。
整体结论:CollabVR 把 VLM 放进 video generation 的 step-level control loop,使 test-time scaling 从“多采样整段视频”转向“构造、检查、修复一条视频轨迹”。实验表明它能同时提升 open-source 与 closed-source VGMs,在 Gen-ViRe、VBVR-Bench、human preference 与 VLM-human alignment 上均提供支持,但其上限仍由 verifier 可靠性和 VGM 局部执行能力共同决定。