Breaking Dual Bottlenecks: Evolving Unified Multimodal Models into Self-Adaptive Interleaved Visual Reasoners
Paper: arXiv:2605.14709 Code: WeChatCV/Interleaved_Visual_Reasoner Code reference:
main@c94ffed0(2026-05-14) — released repo includes data construction, SFT conversion, and framework-agnostic reward code; exact paper-scale launch configs are not released.
1. Motivation (研究动机)
当前 unified multimodal model 已经能把图像理解、文本推理、图像生成放到同一个框架里,但在 X2I(anything-to-image:文生图、图像编辑、多图组合等)任务上仍有一个关键断层:模型可能“读懂”了用户意图,却无法稳定地把语义理解落到像素级操作。论文把这个断层拆成两个瓶颈:
- attention entanglement bottleneck:复杂、多意图、多对象指令如果一次性生成,模型容易把不同对象、属性、空间关系纠缠在一起,表现为身份混合、数量错误、局部编辑影响无关区域。
- visual refinement bottleneck:生成结果出错后,普通模型缺少结构化的自检与修正机制;即使能生成 textual critique,也未必能把 critique 转成下一次可执行的视觉编辑。
- 本文目标:让统一模型根据任务复杂度和自身生成结果,自适应选择 direct generation、self-reflection 或 multi-step planning,而不是固定使用单步生成或纯文本 CoT。
直觉上,本文不是把“推理”当成额外提示词,而是把推理路径变成训练目标:简单任务少想快做;结果有缺陷时先诊断再修;复杂任务先拆成可执行子任务再逐步生成。这把 test-time scaling 的思想搬到 X2I 生成里,但约束是每一步都必须有视觉产物或视觉反馈。
2. Idea (核心思想)
核心贡献可以概括为 Self-Adaptive Interleaved Visual Reasoner:模型输出序列不只包含最终图像,而是交替包含文本 reasoning 与中间图像,从而形成“生成—评价—反思/规划—再生成”的闭环。

Figure 1 解读:左侧对比了常规 single-step X2I、固定 CoT/plan-and-generate 与本文的 adaptive interleaving。本文关键不是永远多步,而是先判断任务或结果需要哪种路径:direct mode 直接输出,reflection mode 针对失败样例做视觉修正,multi-step mode 针对复杂组合任务先拆解再逐步执行。这样同时缓解 blind planning 的注意力纠缠,以及 unstructured feedback 的低效修正。
论文的 pipeline 有两个层次:
- 数据层:用 Analyzer(Qwen-235B)和 Generator(Gemini-3-Pro-Image)自动构造三类轨迹:direct、reflection、multi-step,并用人工校验保证质量。
- 训练层:先用 selective loss masking 做 SFT,让模型学习哪些文本/图像片段该预测;再用 GRPO 做 RL,用 outcome、format、step-wise reasoning reward 与 intra-group complexity penalty 共同约束质量和效率。
3. Method (方法)
3.1 层级数据构造:把失败类型转成训练轨迹
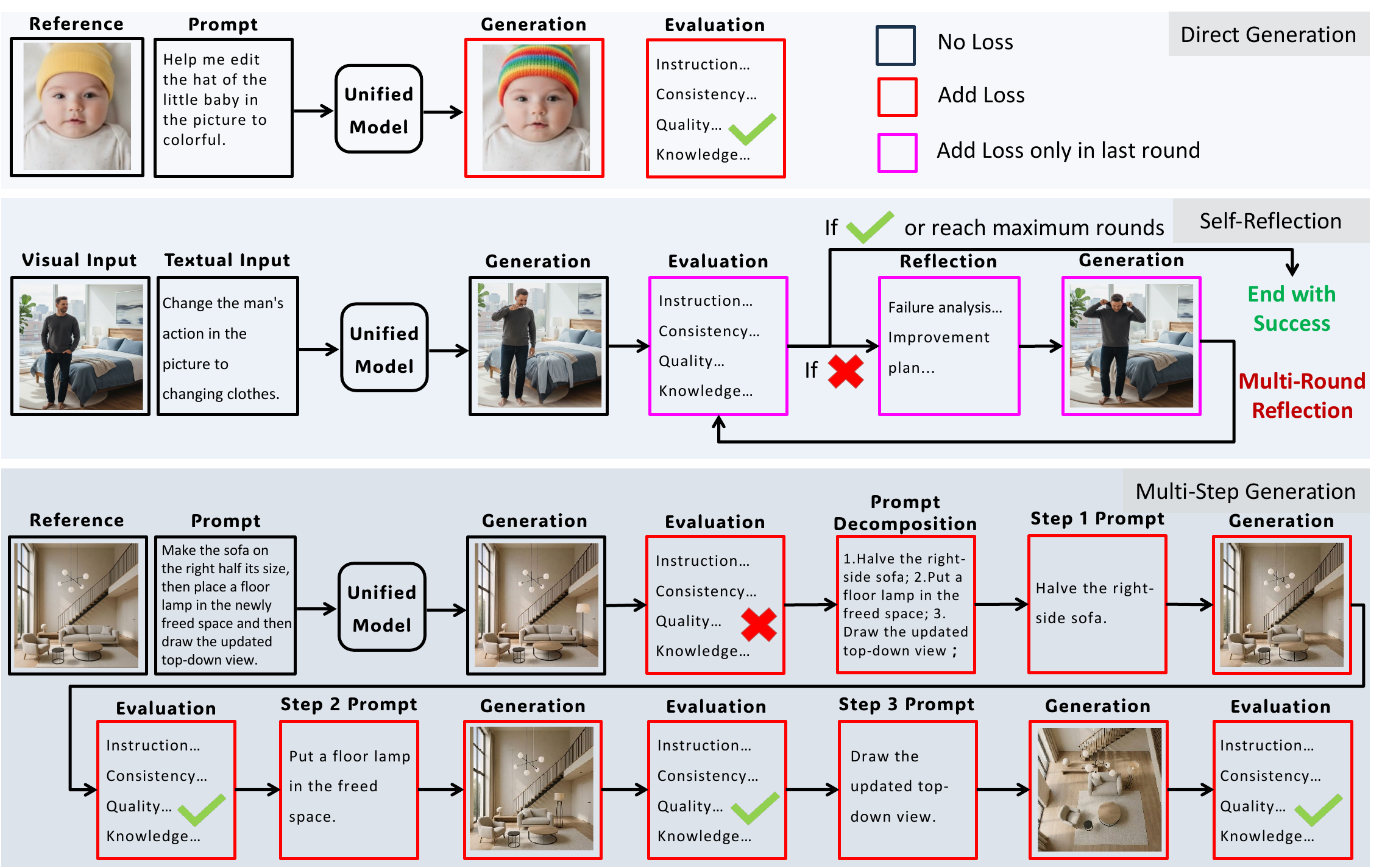
Figure 2 解读:这张图同时展示三类数据与 SFT loss mask。Direct 样例只监督最终生成和评价;Reflection 样例不监督早期失败图像,而监督最后一次失败诊断、reflection prompt 和成功修正图;Multi-step 样例保留任务拆解后的子指令、子图像和子步骤评价。这里的 mask 很关键:模型要学“怎样从失败走向修复”,而不是模仿失败图像本身。
数据构造流程如下:
- Direct Generation:先让 baseline unified model 直接生成,再由 Analyzer 从 instruction、consistency、quality、knowledge 四个维度打分;全部达标即作为 direct 样例。
- Self-Reflection:若 direct 失败,Analyzer 生成失败诊断与 reflection prompt,Generator 基于该 prompt 重新编辑;最多 3 轮,成功后保存 reflection 轨迹。
- Multi-step Generation:若 3 轮 reflection 仍失败,Analyzer 判断失败原因;只有当根因是 prompt complexity 时才升级为显式任务分解,其它如领域知识不足的样例会被过滤。
- Human Verification:自动管线得到的成功样例还需要人工验证,避免错误轨迹污染后续 SFT/RL。
数据规模:总计 50,000 个样例,其中 Direct 10,000、Reflection 20,000、Multi-step 20,000;覆盖 6 个一级维度和 21 个子类,包括对象增删替换、属性修改、空间视角、全局风格、动态逻辑、多图操作等。
3.2 SFT:只监督“有效推理路径”
SFT 目标是标准自回归 NLL,但只对选定输出 token 集合 计算损失:
三种模式对应不同的 :
- Direct:。
- Reflection:对于第 轮才成功的轨迹,mask 掉 等失败生成,只监督最后失败诊断 、reflection prompt 、成功图 与最终评价 。
- Multi-step:监督每个子任务的 ,让模型学会把复杂目标拆成可执行视觉步骤。
实现对应 sft/prepare_sft_data.py:_collect_trajectory() 从 result.json 收集 direct/reflection/multi-step 的 thoughts 与 images,convert_one() 再输出 sharegpt / messages / chatml 三种格式。伪代码如下:
# grounded in sft/prepare_sft_data.py: _collect_trajectory, convert_one, _emit_sharegpt
result = load_json(sample_dir / "result.json")
thoughts, assistant_images = [], []
thoughts.append(_build_initial_plan(result))
assistant_images.append(result["direct_edit_image_path"])
for round in result.get("reflect", [])[:max_reflect]:
thoughts.append(_build_reflection_text(round))
assistant_images.append(round["reflect_image_path"])
for step in result.get("multi_step", []):
thoughts.append(step["step_instruction"])
assistant_images.append(step["step_image_path"])
example = emit_sharegpt(
user_text=result["edit_prompt"],
user_images=norm_src(result.get("original_image_path")),
thoughts=thoughts,
asst_images=assistant_images,
image_token="<image>",
think_open="<think>",
think_close="</think>",
)3.3 RL:把质量、结构、过程和效率一起纳入 reward
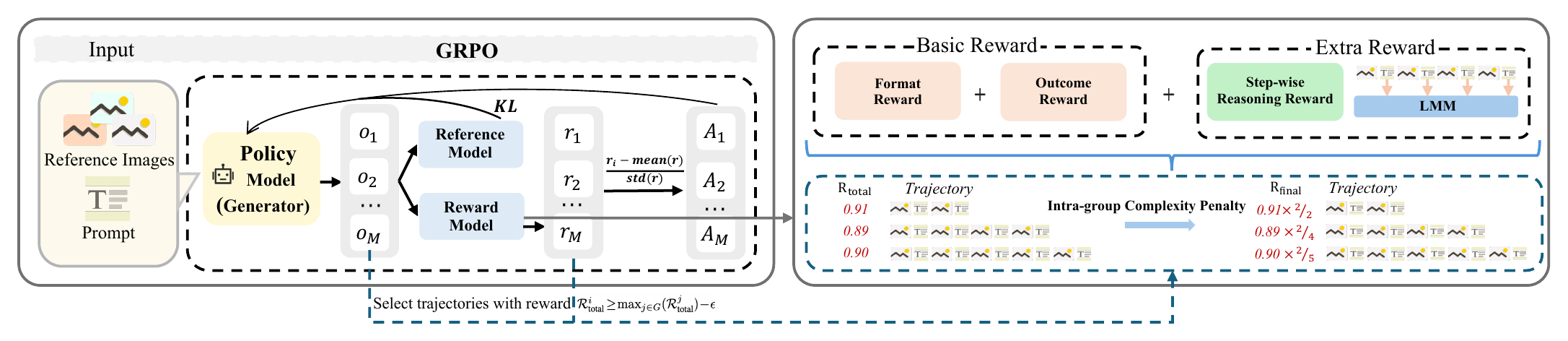
Figure 3 解读:RL 阶段以同一个 instruction/reference 采样多条 interleaved trajectory。Analyzer 既评价最终图像,也评价中间 textual reasoning 的逻辑有效性;GRPO 在一组候选里比较 reward,同时 complexity penalty 让同等高质量路径偏向更少生成次数,避免模型为了刷分而无限反思/多步。
论文中的 outcome reward:
格式 reward 是二值结构检查:
step-wise reasoning reward 对 个中间文本步骤求平均:
总 reward 与组内复杂度修正为:
直觉上,outcome reward 管最终质量,format reward 防止模型乱输出,step-wise reward 给长轨迹中间步骤提供 dense signal,complexity penalty 则解决“多生成几张图更容易碰巧高分”的过推理问题。
released code 中的 reward 入口是 rl/rewards/compose.py::compute_total_reward(),它组合 final_reward、step_reward、format_reward、reflection_reward:
# grounded in rl/rewards/compose.py and rl/rewards/*.py
DEFAULT_WEIGHTS = {"final": 0.40, "step": 0.30, "format": 0.10, "reflection": 0.20}
final_r, final_info = final_reward(rollout, judge) # final image, 4 axes
step_r, step_info = step_reward(rollout, judge) # per intermediate step
format_r, format_info = format_reward(rollout) # <think>/<image> protocol
refl_r, refl_info = reflection_reward(rollout, judge) # diagnosis improves next image
if skip_empty:
drop_empty_step_or_reflection_terms_and_renormalize_weights()
total = (
w["final"] * final_r
+ w["step"] * step_r
+ w["format"] * format_r
+ w["reflection"] * refl_r
)Paper-vs-code gap:论文 appendix 给出的训练超参是 ;released repo 的 compute_total_reward() 是框架无关 reward suite,默认权重为 final/step/format/reflection = 0.40/0.30/0.10/0.20,并未直接实现论文公式中的 intra-group complexity penalty。因此笔记中的训练数值来自论文 Appendix Table,而不是 repo launch config;repo 目前也没有完整 paper-scale GRPO launch script。
3.4 数据管线源码映射
| 论文组件 | released code | 作用 | 注意点 |
|---|---|---|---|
| Direct generation + evaluation | data_pipeline/main.py::single_date_processing, GeminiImageGenerator, evaluate_image_pair | 生成 direct edit / T2I 候选并按四维指标打分 | 阈值在 Config 中:direct/reflection 要求 instruction=5、quality=3;multi-step 要求 quality=4 |
| Reflection | data_pipeline/reflect.py::reflect_on_editing_failure | 读取失败图与评分,生成 structured reflection,再调用 generator 修复 | Config.reflection_attempt = 3 |
| Multi-step fallback | data_pipeline/multi_step.py::generate_editing_steps | 当 reflection 不足以解决复杂 prompt 时拆成子步骤 | Config.use_multi_step = True, multi_step_attempt = 3 |
| SFT conversion | sft/prepare_sft_data.py::convert_one | 把 pipeline outputs 转为 ShareGPT/messages/ChatML | image token 和 think token 可配置 |
| RL reward | rl/rewards/compose.py, final_reward.py, step_reward.py, format_reward.py, reflection_reward.py | 框架无关 reward callable | 与论文 exact GRPO/complexity penalty 有实现差异 |
4. Experimental Setup (实验设置)
- Backbone / infrastructure:论文称主实验模型初始化自 EUM/Emu 3.5,并使用内部分布式基础设施完成两阶段训练与推理。
- 训练规模:SFT 与 RL 均在 分辨率训练,batch size 128,epoch 1;RL rollout size 8。
- 优化器与学习率:SFT 使用
adamw_bf16,学习率从 cosine decay 到 ;RL 学习率 ,KL 系数 ,temperature 1,warm-up ratio 0.1。 - RL 权重:论文表中 outcome / format / step-wise reasoning reward 权重为 0.7 / 0.1 / 0.2,复杂度阈值 。
- 评测集:GenEval 测 T2I 组合泛化;KRIS-Bench 测知识、概念、程序性指令能力;OmniContext 测单/多对象与 scene composition 的上下文一致性。
- Baselines:包括 FLUX.1-dev、Emu3.5、VACoT、GPT-4o、Gemini 2.5 Flash、Qwen-Image-Edit、ReasonEdit-Q 等。
5. Experimental Results (实验结果)
5.1 主结果
- GenEval:Ours 总分 0.89,高于 Emu3.5 0.86、VACoT 0.84、FLUX.1-dev 0.82;在 Counting 0.90、Position 0.79、Color Attribution 0.81 上体现了 interleaved reasoning 对组合约束的帮助。
- KRIS-Bench:Ours Overall 80.18,略高于 GPT-4o 80.09,并明显高于 Emu3.5 73.75;Procedural Knowledge 从 Emu3.5 的 71.14 提升到 85.53,是最能体现多步执行与语义修正的维度。
- OmniContext:Ours Average 9.35,高于 Emu3.5 8.82、GPT-4o 8.80、VACoT 8.26、Gemini 2.5 Flash 7.84;尤其在 Multiple / Scene 类别中更强,说明 multi-step planning 能缓解多主体身份混合与属性泄漏。
5.2 消融实验
| Setting | GenEval | KRIS | Omni | Avg. Imgs | 结论 |
|---|---|---|---|---|---|
| Direct Only | 0.86 | 75.16 | 8.89 | - | 数据量不足以替代结构化推理 |
| w/o Multi-step | 0.87 | 77.24 | 8.95 | - | 去掉任务分解会明显伤害复杂场景 |
| w/o Reflection | 0.86 | 75.21 | 9.03 | - | 去掉自我修正会伤害视觉 refinement |
| Full Mix (30k) | 0.88 | 78.24 | 9.15 | - | planning 与 reflection 互补 |
| SFT Only | 0.86 | 79.16 | 9.12 | 2.45 | SFT 已有效,但生成次数偏多 |
| w/o Step-wise Reward | 0.88 | 79.65 | 9.25 | 1.62 | 中间 reasoning reward 对逻辑一致性有贡献 |
| w/o Complexity Penalty | 0.89 | 80.25 | 9.38 | 2.73 | 分数略高但靠更多图像尝试,成本显著上升 |
| SFT + RL (Ours) | 0.89 | 80.18 | 9.35 | 1.56 | 最好地平衡质量和效率 |
5.3 Case study

Figure 4 解读:上半部分展示 reflection mode 如何纠正视觉谜题中的逻辑错误;下半部分展示 multi-step mode 如何在复杂合成任务中逐步避免对象不一致和不合理布局。它说明本文方法的收益不是单纯来自更多采样,而是来自“错误可诊断、步骤可拆解”的结构化轨迹。
5.4 局限与可复现性
- 论文主训练依赖内部基础设施、Qwen-235B Analyzer、Gemini-3-Pro-Image Generator 和人工校验流程;开源仓库提供了 pipeline / SFT / reward 代码,但没有完整训练脚本、模型权重或 paper-scale dataset。
- released reward code 与论文公式不完全一一对应,尤其是 intra-group complexity penalty 未在
compute_total_reward()中直接出现;复现论文数值时需要额外实现组内复杂度重排/奖励修正。 - 方法依赖强 evaluator 的评分质量;如果 Analyzer 对知识、空间关系或身份一致性的判断不稳定,reflection/multi-step 轨迹会把 evaluator bias 放大到训练数据中。
Appendix Figures (补充图)
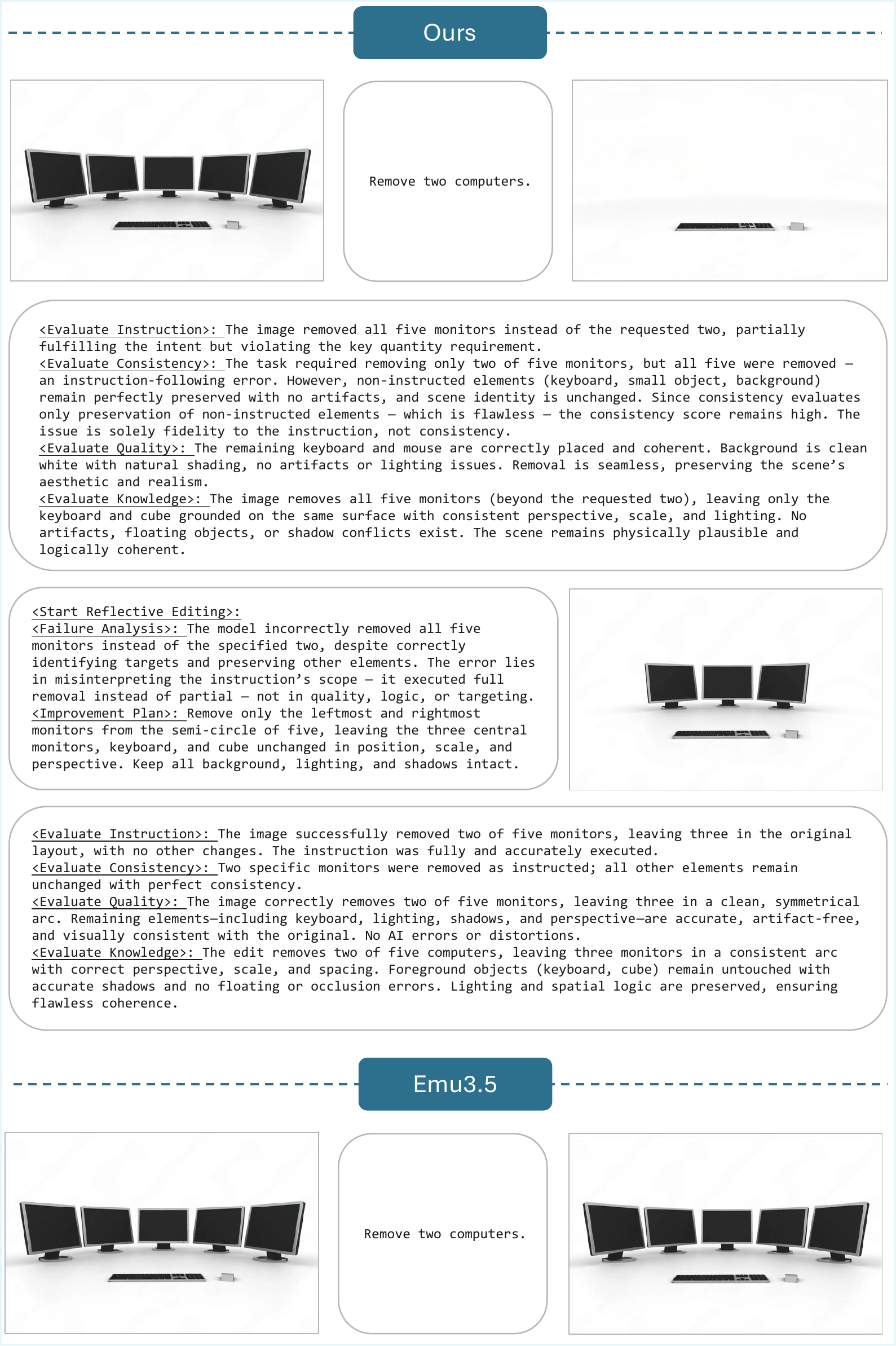
Figure A1 解读:该例展示 reflection mode 对数量/定量约束的修正:模型先出现过度编辑或数量错误,随后通过 structured reflection 把错误定位为指令执行偏差,并在下一轮生成中收敛到更符合 prompt 的结果。
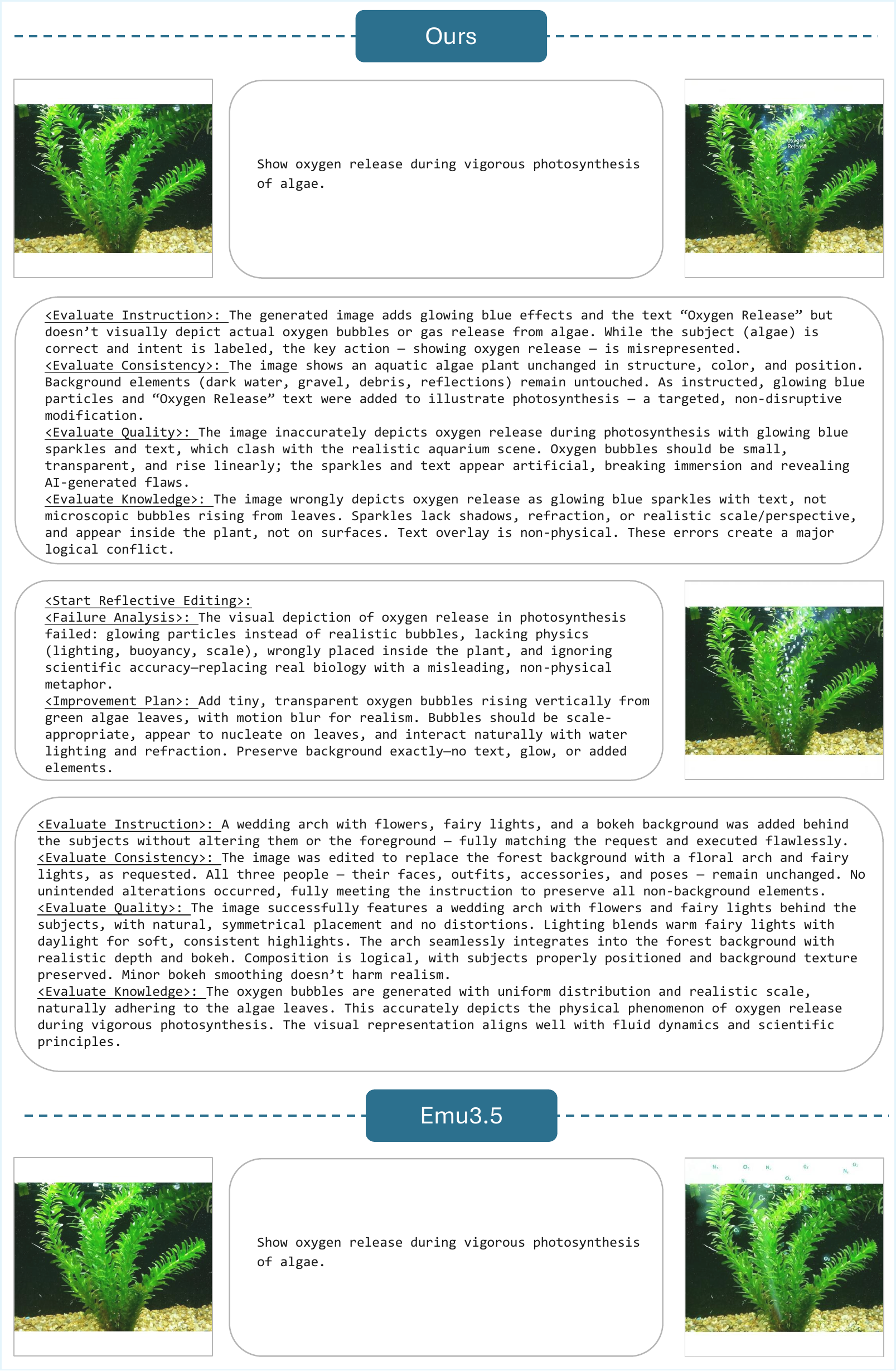
Figure A2 解读:该例强调 knowledge score 的必要性。初始图像可能形式上美观,但对科学常识或物理过程表达错误;reflection 不是只提高画质,而是把“知识不一致”转成下一次编辑提示。

Figure A3 解读:多参考图合成任务中,single-step 生成容易把多个人物身份混合或丢失主体;multi-step mode 通过分阶段引入人物和场景,降低一次性 attention entanglement。
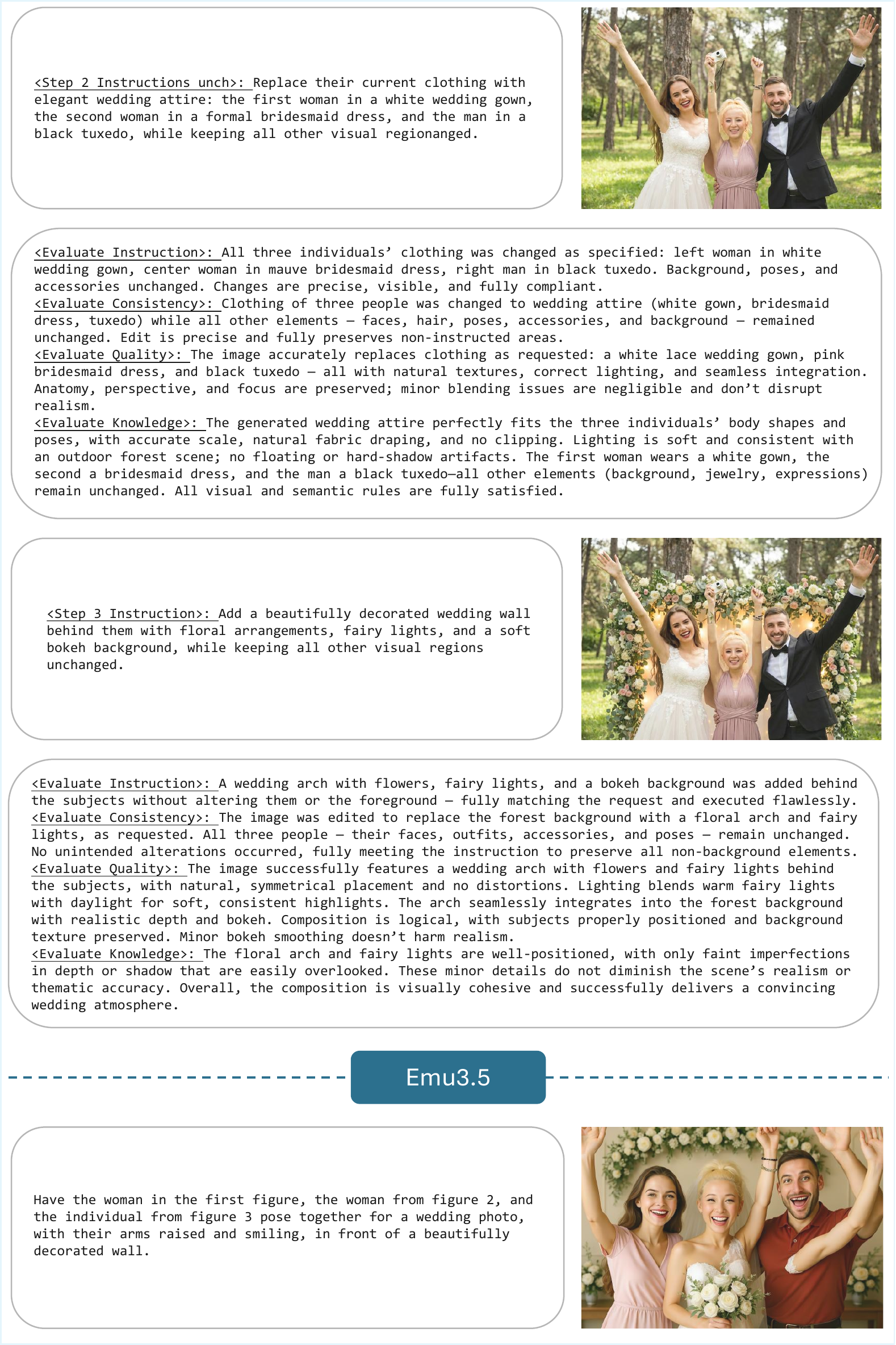
Figure A4 解读:这是多参考图合成的后续结果,重点显示逐步合成在身份保持和主体数量上的收益。它对应 OmniContext 中 Multiple 类别的实验优势。

Figure A5 解读:空间布局任务要求模型理解“距离”“相对位置”等关系;single-step baseline 往往把对象放得太近或关系颠倒,多步规划则先确定布局,再执行局部生成。

Figure A6 解读:该图继续展示 spatial layout correction 的结果,说明 multi-step 并非只对多主体有效,对几何约束和可见性约束也有帮助。

Figure A7 解读:这是 instruction score 与 consistency score 的 evaluator prompt。Instruction 关注目标是否被执行,Consistency 关注原图无关区域、身份和属性是否被保留;二者共同决定最终图像是否既“改对”又“不乱改”。

Figure A8 解读:Quality score 负责视觉保真和伪影,Knowledge score 负责常识、物理和领域知识。这两个维度解释了为什么论文不只用 CLIP/HPS 之类偏偏好或相似度的 reward。

Figure A9 解读:reflection prompt 把失败分析组织为可执行修正指令,避免只有笼统 critique。它是 visual refinement bottleneck 的关键缓解机制。

Figure A10 解读:multi-step prompt 要求 Analyzer 把复杂目标拆为顺序子任务,并让每一步生成后接受局部评价。这个 prompt 直接对应 multi-step data 与 step-wise reasoning reward。