Wan-R1: Verifiable-Reinforcement Learning for Video Reasoning
1. Motivation(研究动机)
视频生成模型(如 Sora、Wan 系列)能产生视觉连贯的内容,但在空间推理和多步规划任务上表现很差。现有方法的核心问题有两个:
SFT 的泛化瓶颈
- Supervised Fine-Tuning (SFT) 在演示视频上训练的模型倾向于记忆训练模式而非学习可迁移推理策略
- 在简单迷宫上训练的模型无法迁移到复杂迷宫或不同视觉纹理
RL 奖励设计的难题 视频生成的 RL 面临独特挑战,使得简单地引入 RL 并不够:
- 输出空间高维连续:无法像文本 RL 那样直接枚举答案空间
- 奖励函数难以设计:成功标准通常是空间和时序相关的
- 奖励黑客问题严重:多模态奖励模型(VLM)极易被 exploit——模型学会生成视觉上令人信服但逻辑上错误的视频
如图 1 所示,使用 Qwen2.5-VL 作为奖励模型时,尽管生成视频存在可见的走错路径等问题,VLM 仍能给出满分(1.0),因为它响应的是高层视觉语义线索(可见的 agent、识别到的迷宫结构、表观的目标导向运动),而非真正的路径正确性。
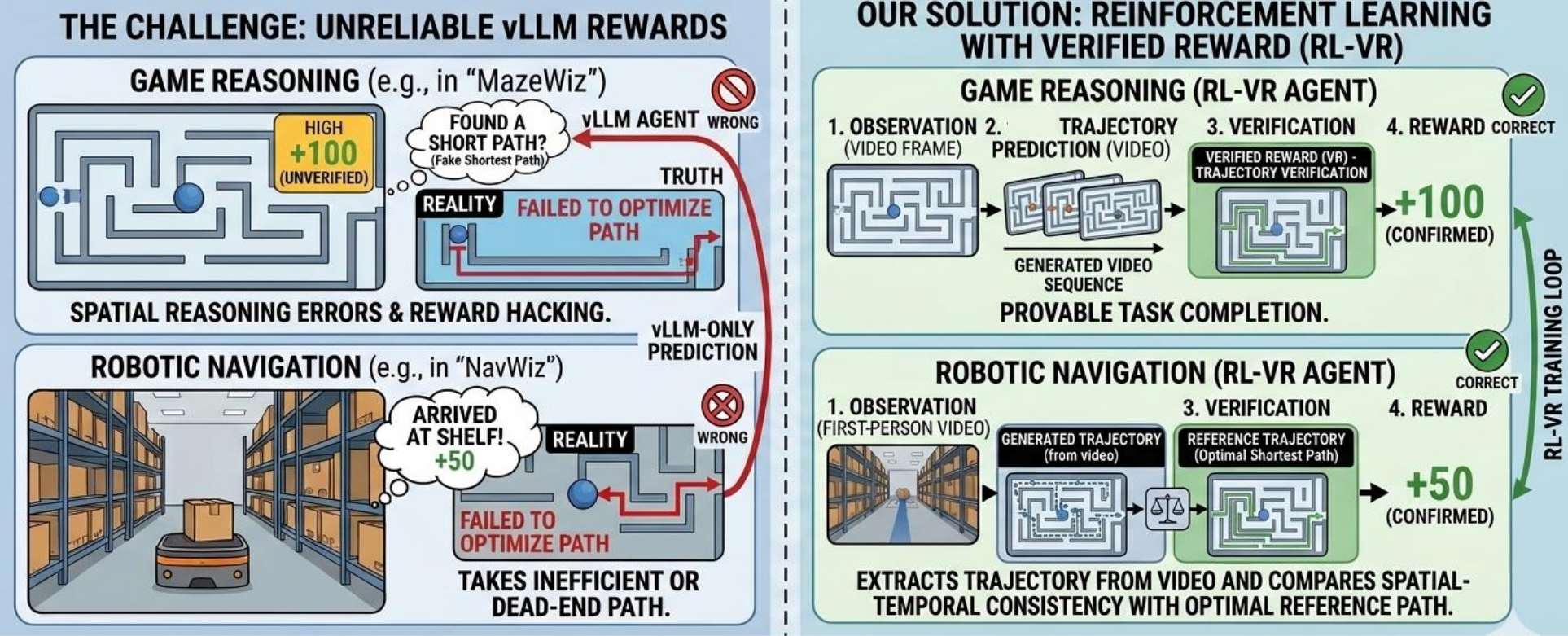
Figure 1 解读:左侧展示 vLLM reward 的失败案例——游戏场景中,agent 生成死路仍得高分(+100);机器人导航中,取到物品的路径低效也得正奖励。右侧是本文方案:通过可验证奖励(RL-VR Agent)提供正确的训练信号,分别针对游戏(轨迹级别奖励)和机器人导航(嵌入级别奖励)设计。
为什么值得研究:RL 通过探索多样化解决策略,有潜力让模型学习可泛化的推理技能而非表面启发式。但如何设计可靠的视频奖励函数是一个系统性挑战,此前几乎没有人深入研究。
2. Idea(核心思想)
核心洞察:可验证奖励(Verifiable Reward)是视频推理 RL 稳定训练的关键。
相比使用容易被 exploit 的 VLM 奖励模型,本文设计的奖励函数直接锚定客观任务指标:
- 游戏环境:从生成视频中提取 agent 轨迹,与 ground-truth 最优路径对比,计算多组件轨迹奖励
- 机器人导航:在嵌入空间中将生成 rollout 与参考 rollout 视频对比,计算帧相似度、时序一致性和终点保真度
与现有方法的根本差异:Flow-GRPO 将 GRPO 适配到 flow-based 视频模型,不需要单独的 value network;奖励完全基于客观可验证的任务完成度,而非 VLM 的主观判断。
3. Method(方法)
3.1 整体框架
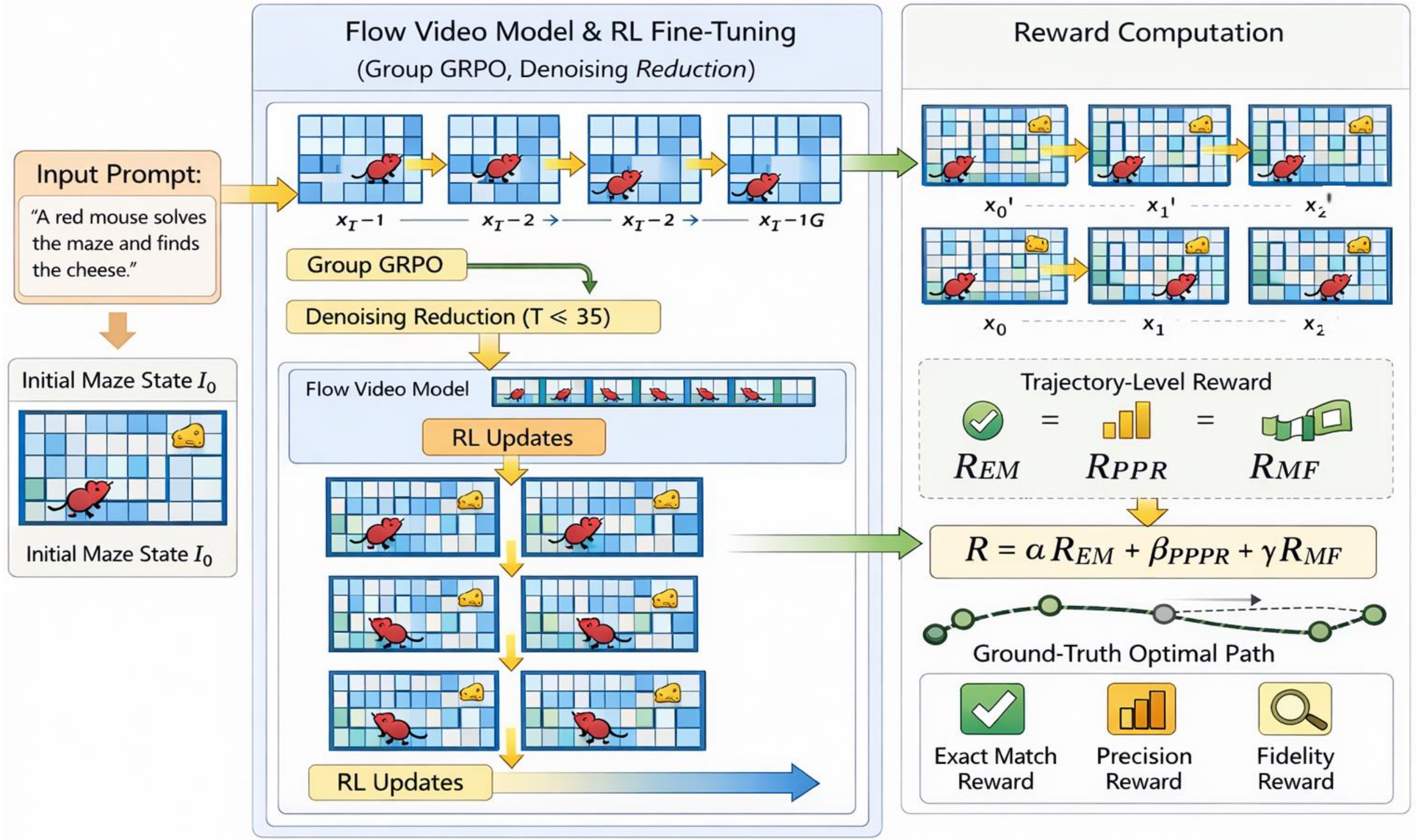
Figure 2 解读:左侧为 Flow-GRPO 训练流程——给定输入 prompt 和初始迷宫图像 I₀,Group GRPO 采样 G 组视频序列(x₀→x_{T-1}),通过 Denoising Reduction(T < 35 步训练)降低计算开销,Flow Video Model 在 RL Updates 下迭代更新。右侧为奖励计算——从生成视频中解码出 x₀、x₁、x₂ 等帧,对比 Ground-Truth Optimal Path,计算三组件奖励( 精确匹配、 精度奖励、 保真度奖励),加权求和 。
3.2 任务定义(Visual Trace Reasoning, VTR)
模型接收文本提示 和初始迷宫图像 ,需要生成视频 ,展示 agent(如彩色小球)从起点导航到终点的过程。任务要求模型:
- 从初始图像中感知迷宫结构
- 规划避开障碍的有效路径
- 生成时序一致的运动视频
3.3 背景:Flow Matching
Flow Matching 模型 19, 23 通过速度场 定义噪声到数据的连续变换。前向过程在数据 和噪声 之间插值:
通过最小化速度场预测误差训练模型:
推理时通过求解 ODE 生成样本:
3.4 将 GRPO 适配到 Flow Matching
ODE 到 SDE 转换
GRPO 需要随机探索,而 ODE 采样是确定性的。Flow-GRPO 21 将 ODE 转换为等价 SDE,在保持边际分布的同时引入随机性:
其中 控制噪声水平, 为 Wiener 过程增量。对 rectified flow 的离散化更新为:
其中 , 包含 score correction 项。
Group Relative Advantage 估计
给定 prompt-image pair ,通过 SDE 采样一组 个视频 。每个视频的优势值通过组内奖励归一化计算:
策略优化目标
GRPO 目标函数最大化:
其中 是 clipped surrogate 目标, 控制对参考策略的 KL 正则化强度。
Denoising Reduction(去噪步数缩减)
视频生成计算代价高昂。采用去噪步数缩减策略:训练时 rollout collection 使用 步,推理时保留完整 步,显著加速训练同时不损失最终性能。
3.5 游戏场景的可验证奖励设计
有效视频 RL 奖励的三个关键性质:
- 可验证性(Verifiability):奖励必须反映真实任务成功,而非视觉质量
- 密度性(Density):奖励应在 binary success/failure 之外提供梯度信号
- 可分解性(Decomposability):奖励应分离任务性能的不同方面,防止混淆
轨迹提取
给定生成视频,使用目标跟踪 45 提取 agent 轨迹。在第一帧初始化跟踪器的 bounding box,跨帧追踪中心位置,得到预测轨迹 。
Exact Match Reward(精确匹配奖励 )
度量生成轨迹是否完全匹配最优路径:
这是严格的 binary 奖励,任何一步偏差均得零分,提供目标完成的完整正确性信号。
Precision Reward(精度奖励 )
量化沿最优路径的连续正确步数比例,提供比精确匹配更软的度量:
这一奖励反映模型沿完整路径做出持续正确进展的能力,是最关键的密集信号来源。
Fidelity Reward(保真度奖励 )
度量视频帧间迷宫布局的结构一致性,惩罚墙体消失等不真实行为:
其中 为采样帧数, 和 分别为第一帧和第 帧的背景区域, 为像素差阈值, 为有效重叠像素数。
综合奖励
实验中取 ,,,优先考虑能提供更密集学习信号的精度奖励,同时鼓励精确解和物理合理性。
3.6 机器人导航的嵌入级可验证奖励
对于 Target-Bench 机器人任务,监督信号来自参考 rollout 视频 (而非离散动作序列),因此奖励设计不同。
嵌入计算
使用冻结视觉编码器 (DINOv2 29 或 CLIP 32)计算逐帧嵌入并 归一化:
由于生成视频长度 和参考视频 可能不同,线性插值较短序列到公共长度 。
三组件嵌入奖励
其中 为归一化累积位移(衡量时序运动一致性)。
加权综合嵌入奖励:
实验取 。
3.7 训练算法
def video_grpo_training(sft_model, ref_model, dataset, G=8, S_train=30):
"""
Algorithm 1: Video-GRPO Training
Args:
sft_model: π_θ, initialized from SFT checkpoint
ref_model: π_ref, fixed reference policy
dataset: D containing (c, I, τ*) tuples
G: group size for advantage estimation
S_train: denoising steps during training rollout
"""
for iteration in range(num_iterations):
# Sample batch
batch = sample_batch(dataset) # {(c, I, τ*)}
all_advantages = []
all_videos = []
for c, I0, tau_star in batch:
# Step 4: Sample G videos via SDE with reduced denoising steps
videos = []
for i in range(G):
noise = torch.randn_like(I0)
v = sde_sample(sft_model, c, I0, noise, steps=S_train)
videos.append(v)
# Step 5: Extract trajectories via object tracking
pred_trajs = [extract_trajectory_via_tracking(v) for v in videos]
# Step 6: Compute rewards against ground-truth τ*
rewards = []
for i, tau_pred in enumerate(pred_trajs):
r_em = exact_match_reward(tau_pred, tau_star) # Eq. 8
r_pr = precision_reward(tau_pred, tau_star) # Eq. 9
r_mf = maze_fidelity_reward(videos[i], I0) # Eq. 10
r = 0.3 * r_em + 0.5 * r_pr + 0.2 * r_mf # Eq. 11
rewards.append(r)
# Step 7: Compute group-relative advantages (Eq. 6)
rewards_tensor = torch.tensor(rewards)
advantages = (rewards_tensor - rewards_tensor.mean()) / \
(rewards_tensor.std() + 1e-8)
all_advantages.extend(advantages.tolist())
all_videos.extend(videos)
# Step 9: Update θ by maximizing J(θ) (Eq. 7)
loss = grpo_objective(
policy=sft_model,
ref_policy=ref_model,
videos=all_videos,
advantages=all_advantages,
beta_kl=0.04,
clip_eps=0.2
)
loss.backward()
optimizer.step()
return sft_model # trained π_θdef exact_match_reward(tau_pred, tau_star):
"""R_EM: binary reward, all steps must match (Eq. 8)"""
return float(all(p == s for p, s in zip(tau_pred, tau_star)))
def precision_reward(tau_pred, tau_star):
"""R_PR: proportion of consecutively correct prefix steps (Eq. 9)"""
n = len(tau_star)
total = 0.0
for j in range(n):
prefix_correct = all(tau_pred[k] == tau_star[k] for k in range(j + 1))
total += float(prefix_correct)
return total / n
def maze_fidelity_reward(video_frames, I0, tau=10, M=5):
"""R_MF: structural consistency of maze across frames (Eq. 10)"""
sampled = random.sample(video_frames[1:], min(M, len(video_frames) - 1))
scores = []
for Im in sampled:
bg0 = extract_background(I0)
bgm = extract_background(Im)
diff = torch.abs(bg0.float() - bgm.float())
changed = (diff > tau).float().sum()
Nm = (bg0 > 0).float().sum()
scores.append(1.0 - changed / (Nm + 1e-8))
return float(torch.tensor(scores).mean())
def embedding_reward(gen_frames, ref_frames, encoder, alpha=0.5, beta=0.2, gamma=0.3):
"""R_emb: embedding-level verifiable reward for robotics (Eq. 12-15)"""
# Encode and normalize
e = F.normalize(torch.stack([encoder(f) for f in gen_frames]), dim=-1)
e_star = F.normalize(torch.stack([encoder(f) for f in ref_frames]), dim=-1)
# Interpolate to common length
Tc = max(len(gen_frames), len(ref_frames))
e = interpolate_sequence(e, Tc)
e_star = interpolate_sequence(e_star, Tc)
# R_cos: mean frame cosine similarity
R_cos = (e * e_star).sum(dim=-1).mean().item()
# R_end: endpoint fidelity (first + last frame)
R_end = 0.5 * ((e[0] * e_star[0]).sum() + (e[-1] * e_star[-1]).sum()).item()
# R_temp: temporal order consistency via normalized cumulative displacement
def cumulative_disp(seq):
diffs = torch.norm(seq[1:] - seq[:-1], dim=-1)
cumsum = torch.cumsum(diffs, dim=0)
return cumsum / (cumsum[-1] + 1e-8)
c_bar = cumulative_disp(e)
c_bar_star = cumulative_disp(e_star)
R_temp = 1.0 - torch.abs(c_bar - c_bar_star).mean().item()
return alpha * R_cos + beta * R_temp + gamma * R_end代码-论文概念对应表
| 论文概念 | 对应实现 | 关键说明 |
|---|---|---|
| Flow-GRPO | sde_sample() + grpo_objective() | ODE→SDE 转换引入随机探索 |
| Denoising Reduction | steps=S_train (30 vs 50) | 训练时减少步数加速 rollout |
| Group Relative Advantage | (rewards - mean) / std | 组内归一化,无需 value network |
| Exact Match | exact_match_reward() | 严格 binary,所有步都对才得分 |
| Precision | precision_reward() | 最关键的密集信号,β=0.5 权重最高 |
| Fidelity | maze_fidelity_reward() | 防止模型”删墙”作弊 |
| Embedding | embedding_reward() | DINOv2/CLIP 嵌入比较,无需离散动作 |
| Trajectory Extraction | extract_trajectory_via_tracking() | 基于目标跟踪,非直接标注 |
注:论文说”代码将公开”,当前搜索未找到开源实现,上述伪代码基于论文公式和算法描述重建。
4. Experimental Setup(实验设置)
数据集
VR-Bench 45:程序化生成的迷宫,五种类型,每种三个难度(Easy/Medium/Hard)和多种视觉纹理:
- Regular Maze:网格布局,测试基础寻路
- Irregular Maze:曲线路径,防止坐标捷径
- 3D Maze:立体结构,需要深度感知
- Trapfield:包含陷阱区域的障碍规避
- Sokoban:箱子推动谜题,需要规则理解

Figure VR-Bench 解读:展示 VR-Bench 的五种迷宫类型(Regular、Irregular、3D、Trapfield、Sokoban),每种类型显示不同视觉纹理(Raw、Skin2、Skin3)。每行展示同一难度下的不同视觉外观变体,用于测试模型的纹理不变性。
Target-Bench 37:真实世界机器人导航基准,mapless 路径规划任务。每个样本包含:
- 自视角 RGB 观测 (第一人称视角)
- 语义目标提示 (显式或隐式)
- 四足机器人的参考 rollout 视频 (SLAM 验证的 ground-truth 轨迹)
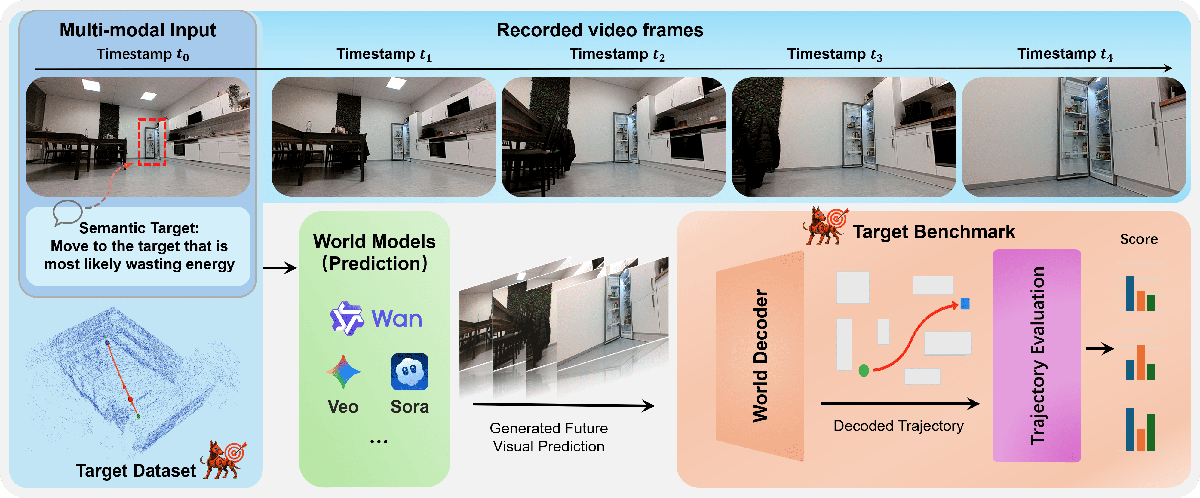
Figure Target-Bench 解读:展示 Target-Bench 评估 pipeline——左侧输入为第一人称 RGB 观测和文字目标,中间为生成的视频规划,右侧通过 VGGT world decoder 解码轨迹并与 ground-truth 轨迹对比,计算 ADE/FDE/SE/AC 等指标。
基线模型
闭源视频模型(6 个):Veo-3.1-fast、Veo-3.1-pro、Sora-2、Kling-v1、Seedance-1.0-pro、MiniMax-Hailuo-2.3
开源视频模型(3 个):Wan2.5-i2v-preview、Wan2.2-TI2V-5B(基础模型)、Wan-SFT 45(SFT 微调模型,关键对比基线)
评估指标
VR-Bench 指标:
- **Exact Match (EM)**↑:生成轨迹是否与最优路径完全匹配
- **Success Rate (SR)**↑:agent 是否到达目标
- **Precision Rate (PR)**↑:沿最优路径的连续正确步数比例
- **Step Deviation (SD)**↓:相对路径长度冗余度(越低越好)
Target-Bench 指标:ADE(平均位移误差)↓、FDE(终点位移误差)↓、MR(Miss Rate)↓、SE(Soft Endpoint)↑、AC(Approach Consistency)↑,综合分 (AC 和 SE 共占 65% 权重)
训练配置
| 超参数 | 值 |
|---|---|
| 基础模型 | Wan2.2-TI2V-5B(flow-matching I2V) |
| 微调方法 | LoRA() |
| Group 大小 | 8 |
| 视频帧数 | 193 |
| 训练 Epoch | 1 |
| 训练去噪步数 | 30 |
| 推理去噪步数 | 50 |
| KL 系数 | 0.04 |
| Clipping 参数 | 0.2 |
| SDE 噪声尺度 | 0.5 |
| 学习率 | |
| 硬件 | H200 GPU |
5. Experimental Results(实验结果)
5.1 VR-Bench 主要结果
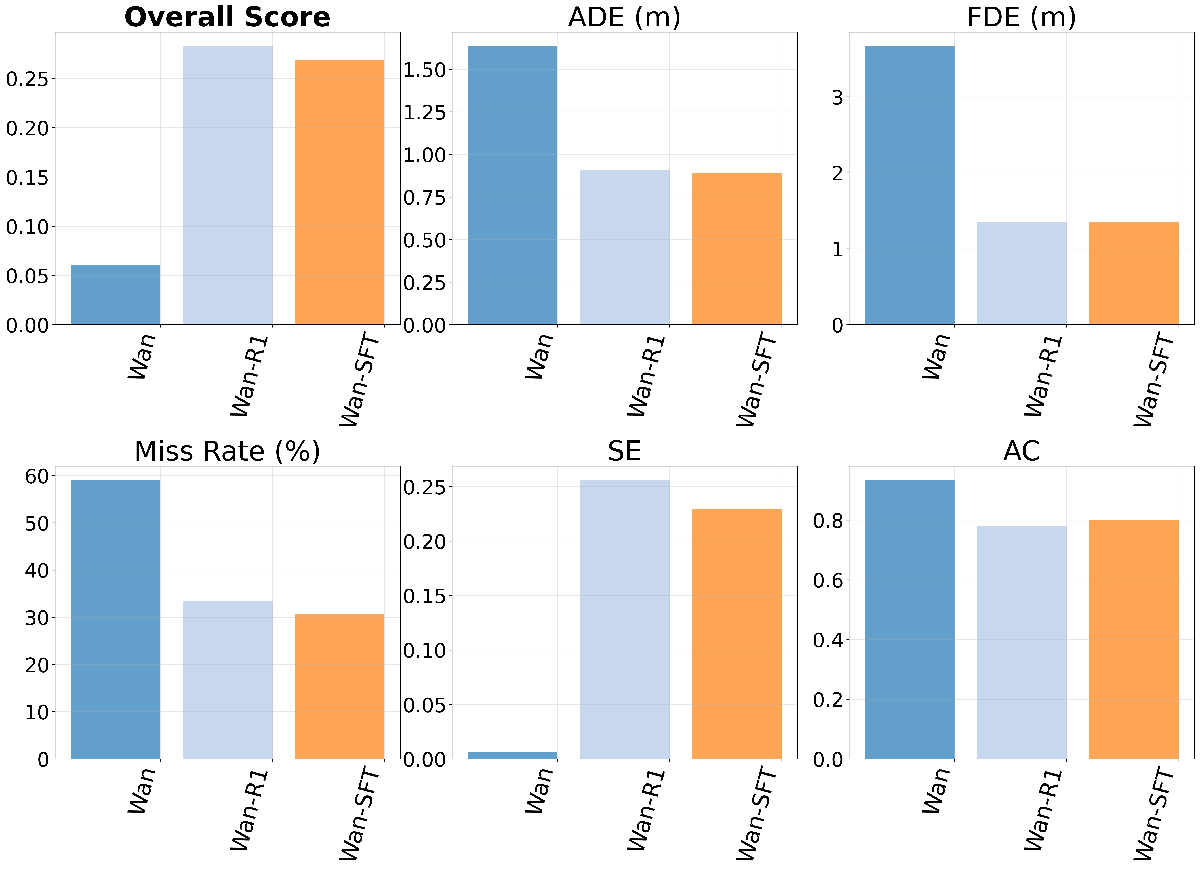
Figure 模型对比解读:展示 Wan-R1 与各基线模型在 VR-Bench 上的综合性能对比。Wan-R1 在所有迷宫类型上均显著优于开源基线和多个闭源模型。
RL 微调后(Wan-R1)在所有迷宫类型上一致优于 SFT 基线(Wan-SFT):
| 迷宫类型 | 指标 | Wan-SFT | Wan-R1 | 提升 |
|---|---|---|---|---|
| Regular (Base) | EM ↑ | 33.3 | 61.1 | +27.8pp |
| Irregular | EM ↑ | 56.9 | 47.9 | +(-9.0)* |
| 3D Maze | EM ↑ | 65.3 | 94.4 | +29.1pp |
| Trapfield | EM ↑ | 38.9 | 90.3 | +51.4pp |
| Sokoban | EM ↑ | 4.2 | 30.6 | +26.4pp |
(*Irregular Maze EM 下降,PR 也从 71.6 下降到 68.4,但难度泛化分析中 Wan-R1 在 Hard 难度的 PR 远优于 SFT,整体泛化策略更强)
关键观察:
- Trapfield(陷阱规避)提升最显著(+51.4pp),说明 RL 特别有助于避免特定危险区域
- 3D Maze 提升 29.1pp,从 65.3% 到 94.4%,几乎完美
- Step Deviation 在 Regular(10.3→5.2)和 3D(3.9→1.9)上大幅下降,表明 RL 训练产生更高效的路径
5.2 泛化能力
难度泛化(仅在 Easy 级别训练,在 Medium/Hard 上测试):
| 任务 | 指标 | SFT (Hard) | Wan-R1 (Hard) |
|---|---|---|---|
| Regular Maze | PR | 6.0% | 57.2% |
| Irregular Maze | PR | 5.8% | 68.4% |
| 3D Maze | PR | 15.2% | 96.2% |
SFT 从 Easy 到 Hard 严重退化(如 Regular PR:40.1%→6.0%),而 Wan-R1 保持高性能(97.0%→57.2%)。
纹理泛化(在 Raw 纹理训练,在 Skin2/Skin3 上测试):
- Regular Maze:Wan-R1 在 Skin2/Skin3 上 31.9% EM,vs Wan-SFT 的 1.4%/23.6%
- 3D Maze:Wan-R1 79.2% EM(未见纹理)vs SFT 43.1%
5.3 Target-Bench 机器人导航
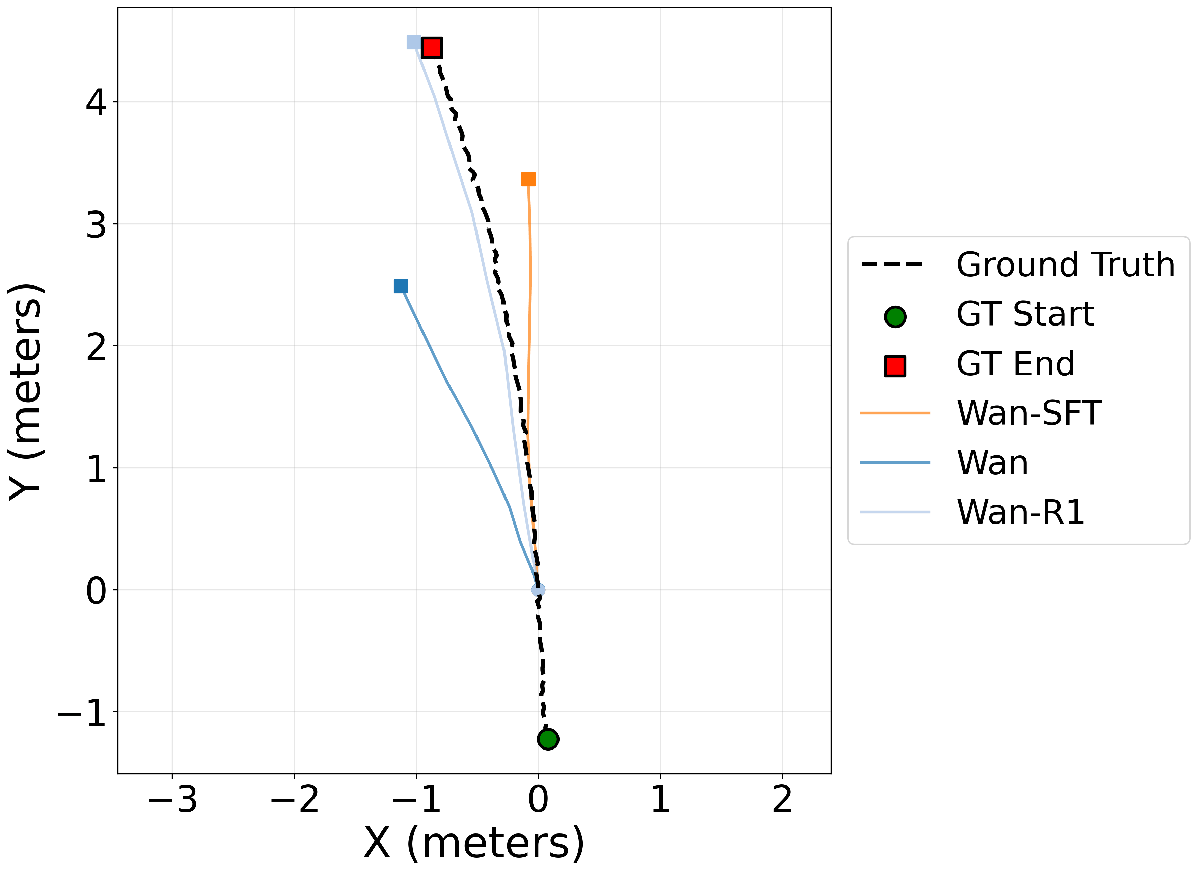
Figure 机器人轨迹解读:展示 Wan-R1 在 Target-Bench 上生成的视频规划轨迹样本,第一行为 Wan-R1 生成结果,第二行为对应参考轨迹(teleoperated robot),可见 Wan-R1 的路径与参考更接近。
Wan-R1 在 Target-Bench 上取得最佳总分,相比基础模型将 ADE 和 FDE 降低约一半,SE 和 AC 也有提升,说明嵌入级可验证奖励能有效迁移到真实世界机器人导航任务。
5.4 消融分析
KL 正则化效果(Table 3a):
| EM | SR | PR | SD | |
|---|---|---|---|---|
| 0(无正则) | 62.5 | 75.0 | 79.0 | 6.7 |
| 0.04 | 61.1 | 75.0 | 78.6 | 5.2 |
| 0.1 | 66.7 | 75.0 | 81.5 | 3.7 |
更强 KL 正则化鼓励策略靠近参考分布,产生更高效且结构一致的轨迹。
去噪步数缩减效果(Table 3b):
| EM | SR | PR | SD | |
|---|---|---|---|---|
| 5(过激) | 59.7 | 70.8 | 77.5 | 4.0 |
| 30(推荐) | 61.1 | 75.0 | 78.6 | 5.2 |
| 50(完整) | 62.5 | 73.6 | 79.7 | 2.9 |
以极小代价恢复完整步数的大部分性能,且 SR 最高(75.0%),适度随机性可能作为轻度正则化。
Cold Start 实验(Table 8a):
| 初始化 | EM | SR | PR | SD |
|---|---|---|---|---|
| 无 SFT 直接 RL | 0.0 | 2.8 | 4.0 | 41.1 |
| 有 SFT 初始化 | 61.1 | 75.0 | 78.6 | 5.2 |
直接在基础模型上应用 Flow-GRPO 几乎完全失败(近零 EM)。SFT 作为必要的 bootstrap,将模型置于奖励景观中有意义梯度更新存在的区域。
奖励函数设计分析(Table 8b):
Figure 5 解读:展示 Qwen2.5-VL-7B-Instruct 作为奖励模型的失败案例。给定生成视频(有可见故障和降质)+ 评估提示,模型给出”red circle slides smoothly… no glitches, noise, or artifacts present”的描述,并给出满分 1.0。这证明 VLM 对高层语义线索(可见 agent + 迷宫结构 + 表观目标导向运动)产生响应,而无法检测实际的视觉伪影。
| 奖励类型 | EM | SR | PR | SD |
|---|---|---|---|---|
| Qwen2.5-VL(VLM 奖励) | 11.1 | 55.6 | 42.4 | 2.2 |
| 仅精确匹配 | 58.3 | 75.0 | 79.3 | 4.4 |
| (本文) | 61.1 | 75.0 | 78.6 | 5.2 |
- VLM 奖励导致严重退化(11.1% EM),属于 reward hacking
- 单独用稀疏 EM 奖励效果已不错(58.3%),但密集的 提供了关键的早期学习信号
- 防止了”删墙”作弊,维护视频的物理合理性
Test-Time Scaling:
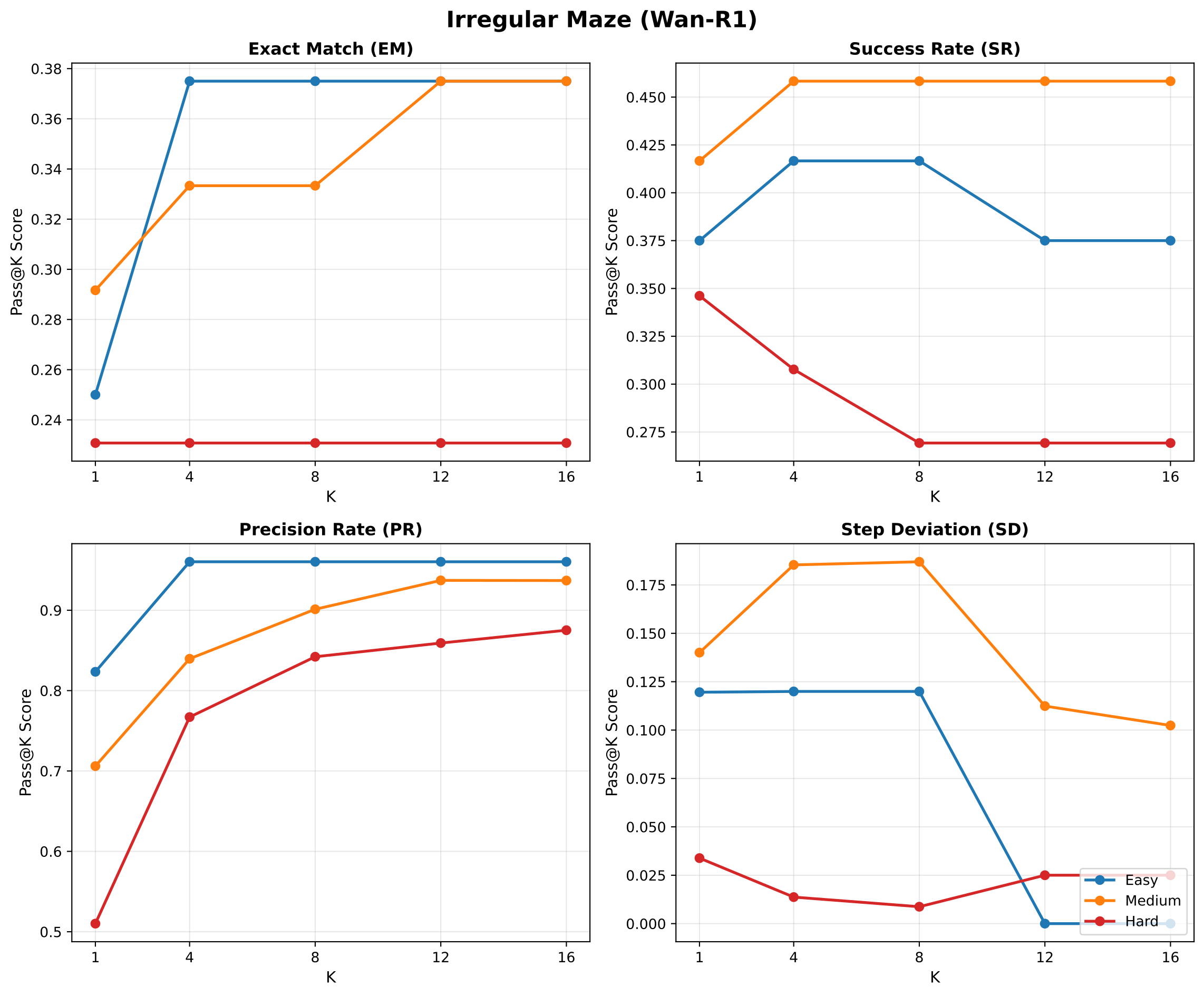
Figure 4 解读:在 Irregular Maze 上,评估不同采样数量 下的 Best-of-K 性能(Easy/Medium/Hard 三难度)。随 K 增大,EM、SR、PR 持续提升,SD 降低,说明模型在多次采样中保持有意义的多样性。即使 K=1 时,Wan-R1 也显著优于 SFT 基线,证明 RL 改善的是底层策略能力而非仅靠运气。K=8 之后边际收益递减,建议作为实用推理预算。
5.5 局限性
- 任务范围:仅适用于有严格定义成功标准的任务(ground-truth 最优路径 / 参考 rollout 视频)。对开放式生成任务,可验证奖励的设计原则上更具挑战性
- 奖励权重固定:固定的 在不同复杂度环境下可能并非最优,未来应探索自适应或课程化奖励加权
- Cold Start 依赖:必须从 SFT 检查点出发,不能直接对基础模型应用 RL,限制了适用范围
- VLM 奖励的根本缺陷:由于视频输出的高维连续性,VLM 奖励模型比文本 RL 更容易被 exploit,这一问题在更复杂视频任务中可能更严重