Video Generation Models Are Good Latent Reward Models
Authors: Xiaoyue Mi, Wenqing Yu, Jiesong Lian, Shibo Jie, Ruizhe Zhong, Zijun Liu, Guozhen Zhang, Zixiang Zhou, Zhiyong Xu, Yuan Zhou, Qinglin Lu, Fan Tang Affiliations: University of Chinese Academy of Sciences, Tencent Hunyuan, Huazhong University of Science and Technology, Peking University, Shanghai Jiao Tong University, Tsinghua University, Nanjing University arXiv: 2511.21541 Project Page: hy-video-prfl.github.io/HY-VIDEO-PRFL GitHub: Tencent-Hunyuan/HY-Video-PRFL
1. Motivation (研究动机)

Figure 1 解读: PRFL 在 image-to-video(不同尺寸首帧)和 text-to-video(相同尺寸帧)任务上生成的高质量视频代表帧。展示了沙漠行走、钢琴演奏、粉衣舞者等场景,视频具有流畅的运动过渡和准确的人体解剖结构,体现了 PRFL 在 motion quality 上的显著改善。
现有 Reward Feedback Learning (ReFL) 在 image generation 中已经证明有效,但直接迁移到 video generation 会遇到三个核心瓶颈:
- reward model 处在 RGB / pixel space:主流 video reward model 依赖 VLM,只能看经过 VAE 解码后的近干净帧,导致每次 reward 评估都要承担昂贵的解码开销。
- 监督太晚:RGB reward 通常只在接近 的后期去噪阶段生效,因此它更像是在“修补最终画质”,很难真正干预 motion planning、structure formation 这类在早期去噪中决定的视频属性。
- 显存与训练时间不可接受:长视频、高分辨率视频在全帧解码并反传时非常容易 OOM,实际系统往往只能退化成“只看第一帧”或“少量帧”的近似训练。
这篇论文要解决的问题是:能否在 latent space 里直接做 reward modeling 和 reward optimization,从而让 video post-training 同时兼顾 motion quality、训练效率与显存成本?
这个问题值得研究,因为 video generation 与 image generation 的最大差别就在于时间维度;如果 reward 仍然只能在像素空间末端给信号,那么模型最关键的时序建模能力就很难被有效对齐。
2. Idea (核心思想)
论文的核心洞见是:Video Generation Model (VGM) 本身就是最适合 noisy latent 的“过程感知”特征提取器。因为它天生就是在不同 timestep 的 noisy latent 上做时空建模,所以比 VLM 更适合担当 latent reward model。
基于这个观察,作者提出两部分:
- PAVRM (Process-Aware Video Reward Model):把预训练 VGM 的前几层 DiT block 改造成 latent reward model,在任意 timestep 上直接给 noisy video latent 打分。
- PRFL (Process Reward Feedback Learning):训练时随机采样一个中间 timestep,只做一次带梯度的 denoising step,再让冻结的 PAVRM 给 reward 并反传,从而把 reward 信号分布到整个 denoising trajectory。
和现有方法相比,根本区别在于:它不是对“最终 RGB 视频结果”做 outcome-level 打分,而是对“生成过程中的 latent 状态”做 process-level 打分与优化。
3. Method (方法)
3.1 Overall framework
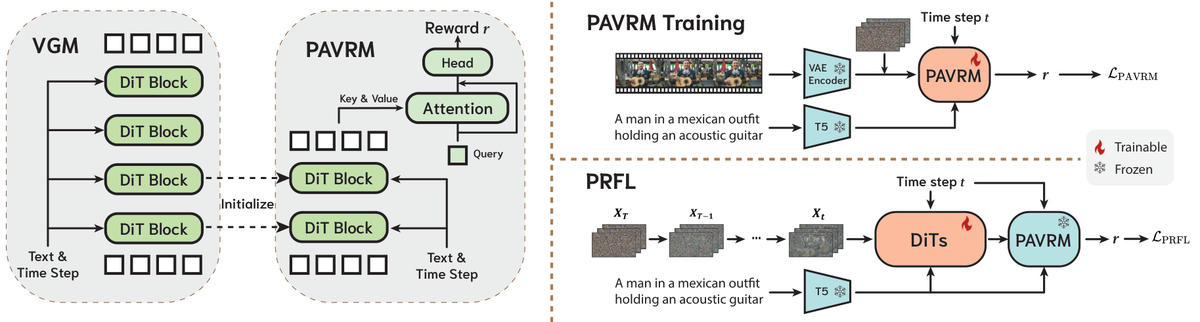
Figure 3 解读: 左侧展示了从 VGM 初始化 PAVRM 的方式:作者保留 video generation backbone 的前几层 DiT block 作为时空特征提取器,再接一个 query-based aggregation 和一个 MLP head 输出 reward。右上是 PAVRM 训练:真实/生成视频先经 VAE encoder 变成 latent,再与 timestep 和文本条件一起送入 PAVRM 学习二分类 reward。右下是 PRFL:生成模型从噪声逐步去噪到某个随机中间状态后,只做一步带梯度更新,并直接用 PAVRM 在 latent space 上给 reward,无需 VAE decode 到 RGB。

Figure 2 解读: Figure 2 对比了 RGB ReFL 和 PRFL 的训练路径。上半部分的 RGB ReFL 必须先把 latent 几乎完全去噪,再经过 VAE decoder 变成 RGB,最后才能交给 reward model,这带来 evaluation delay、显存压力和“只监督末期步骤”的问题。下半部分的 PRFL 则直接在 latent 上建 reward,并允许随机 timestep 采样,因此 reward 可以更早、更均匀地作用于整个 denoising process。
3.2 Feasibility analysis:为什么 VGM 能做 latent reward model

Figure 4 解读: Figure 4(a) 表明 VLM-based reward model(VideoAlign-MQ)在不同 timestep 上分数波动很大,说明它对 noisy latent 的泛化很差;Figure 4(b) 表明即使只做简单 linear probe,VGM 不同 DiT layer 的特征也都能稳定达到约 accuracy,说明 motion quality 信息在网络早中层已经存在;Figure 4(c) 则说明当训练方式从“只训 MLP”升级为“随机 timestep + full fine-tuning”后,accuracy 可提升到 ,从而支撑了 PAVRM 的设计。
3.3 PAVRM:过程感知 latent reward model
给定 noisy latent video 、timestep 和 prompt ,PAVRM 用 VGM 的前 8 个 DiT blocks 作为时空特征提取器:
这里 是 text encoder。作者随后把时空特征 flatten 成 token 序列 ,其中 ,再用一个 learnable query 做 attention pooling:
最终表示为:
然后一个三层 MLP 输出 reward score 。
从官方实现看,diffusers_lite/utils/network.py 里的 QueryAttention 采用 nn.MultiheadAttention,并用 learnable queries 做 pooling;MLP 则是 5120 \to 1024 \to 512 \to 1 的三层感知机。configs/train_pavrm_i2v_720.yaml 还显示默认使用:
feature_layer: [8]trainable_blocks: [0,1,2,3,4,5,6,7]pool: q_attnloss: ce
也就是说,源码里的默认设置与论文的“前 8 层 DiT + query aggregation”基本一致。
3.4 PAVRM 的训练目标
Rectified Flow 的正向插值写成:
其中 是 clean latent, 是噪声。基础 flow matching / SFT loss 为:
其中 。
PAVRM 则在随机 timestep 上做二分类学习:
源码里还有一个非常关键的实现细节:在 scripts/pavrm/train_pavrm.py 中,motion_quality 标签实际被写成 physics_quality and human_quality。也就是说,作者训练 reward model 时把“物理合理性”和“人体结构正确性”同时满足的视频视为正样本,这与论文中“motion quality”不仅仅是速度大,而是兼顾 dynamics 与 structure 的叙述是吻合的。
3.5 PRFL:latent-space process reward optimization
传统 RGB ReFL 的目标是:
其中 是 VAE decoder。它的问题是必须先得到接近 clean 的 RGB 视频,计算很慢。
PRFL 改成:从噪声开始 rollout,到随机采样的中间 timestep 前都不保留梯度,只在最后一步打开梯度:
然后直接最大化 PAVRM 在该中间状态上的 reward:
同时交替做 SFT regularization:
从源码实现看,scripts/prfl/train_prfl.py 的训练循环确实是每轮先做一次 train_step(普通 flow matching),再做一次 train_step_refl(reward step)。其中 reward step 会:
- 用
FlowUniPCMultistepScheduler固定 40 个 inference steps; - 随机采样
mid_timestep \in [0, 38]; - 从纯噪声 rollout 到该中间位置前全部
no_grad; - 只对最后一步 denoising 保留梯度;
- 用冻结的
lrm_transformer + QueryAttention + MLP计算 reward; - 对生成模型反传更新。
这里还有一个代码与论文公式的细微差异:train_prfl.py 中 reward loss 实现为 0.1 * relu(2 - reward_score)。由于 reward_score = \sigma(\text{MLP}(\cdot)) \in [0,1],这在梯度上等价于“加了常数后的 reward maximization”;这个结论是我根据源码推导得到的,而不是论文原文直接写出的。
3.6 Pseudocode(基于官方实现)
组件 A:Latent 数据预处理(scripts/preprocess/gen_wanx_latent.py)
# Algorithm: Build latent cache for PAVRM/PRFL
# Input: video_path, caption, VAE, T5, CLIP
# Output: latents, text_states, image_embeds, latents_condition
def build_latent_cache(video_path, caption, vae, text_encoder, image_encoder):
frames = load_video(video_path)
frames = sample_frames_by_fps(frames, target_fps)
frames = resize_and_center_crop(frames)
video = normalize(frames)
first_frame = video[0]
masked_video = concat(first_frame, zeros_for_remaining_frames(video))
latents = vae_encode(vae, video)
latents_condition = vae_encode(vae, masked_video)
image_embeds = image_encode(image_encoder, first_frame)
text_states = prompt2states(caption, text_encoder)
return {
"latents": latents,
"latents_condition": latents_condition,
"image_embeds": image_embeds,
"text_states": text_states,
}组件 B:PAVRM 前向(QueryAttention + MLP)
# Algorithm: PAVRM forward
# Input: noisy latent x_t, timestep t, prompt states, image condition
# Output: reward score in [0, 1]
def pavrm_forward(x_t, t, text_states, image_embeds, latents_condition):
features = wan_transformer(
x=x_t,
t=t,
context=text_states,
clip_fea=image_embeds,
y=latents_condition,
output_features=True,
selected_layers=[8],
)
seq_features = flatten_spatiotemporal_tokens(features)
pooled = query_attention(seq_features) # learnable queries + multi-head attention
score = sigmoid(mlp(pooled))
return score组件 C:PAVRM 训练一步(scripts/pavrm/train_pavrm.py)
# Algorithm: Train PAVRM at random timesteps
# Input: clean latent x_0, text states, image condition, labels
# Output: BCE / BT loss
def train_pavrm_step(batch):
x_0, text_states, image_embeds, latents_condition = batch.inputs
label = int(batch.physics_quality and batch.human_quality)
noise = randn_like(x_0)
t, sigma = noise_scheduler.get_train_timestep_and_sigma(batch_size=x_0.shape[0])
x_t = noise_scheduler.add_noise(x_0, noise, sigma)
score = pavrm_forward(x_t, t, text_states, image_embeds, latents_condition)
loss = bce(score, label) # default config; repo also supports BT loss
loss.backward()
clip_grad_norm_(transformer, 1.0)
optimizer.step()
optimizer.zero_grad()组件 D:PRFL 训练一步(scripts/prfl/train_prfl.py)
# Algorithm: PRFL reward update with one-step gradient
# Input: prompt-conditioned batch, trainable VGM, frozen PAVRM
# Output: reward loss + parameter update
def train_prfl_reward_step(batch):
latent = randn_like(batch.latents) # start from pure noise
timesteps = unipc_scheduler.set_timesteps(40)
mid = random.randint(0, 38)
# rollout to mid timestep without gradients
with no_grad():
for i in range(mid):
t = timesteps[i]
v = vgm(latent, t, batch.text_states, batch.image_embeds, batch.latents_condition)
latent = unipc_scheduler.step(v, t, latent)
# one denoising step with gradients
t_mid = timesteps[mid]
v = vgm(latent, t_mid, batch.text_states, batch.image_embeds, batch.latents_condition)
latent = unipc_scheduler.step(v, t_mid, latent)
# frozen latent reward model
reward_t = timesteps[mid + 1]
reward = pavrm_forward(latent, reward_t, batch.text_states, batch.image_embeds, batch.latents_condition)
# implementation detail from repo
loss = 0.1 * relu(2.0 - reward).mean()
loss.backward()
clip_grad_norm_(vgm, 1.0)
optimizer.step()
optimizer.zero_grad()3.7 Code-to-paper mapping table
| Paper Concept | Source File | Key Class / Function |
|---|---|---|
| Latent preprocessing | scripts/preprocess/gen_wanx_latent.py | encode_video, encode_single_video, encode_caption |
| PAVRM backbone initialization | scripts/pavrm/train_pavrm.py | model_init |
| Query-based spatiotemporal aggregation | diffusers_lite/utils/network.py | QueryAttention.forward |
| Reward head | diffusers_lite/utils/network.py | MLP, forward_mlp |
| Motion-quality label construction | diffusers_lite/datasets/image2video_dataset.py, scripts/pavrm/train_pavrm.py | get_batch_lrm_ce, label = physics_quality and human_quality |
| PAVRM timestep-aware training | scripts/pavrm/train_pavrm.py | train_step |
| PRFL normal SFT update | scripts/prfl/train_prfl.py | train_step |
| PRFL reward update | scripts/prfl/train_prfl.py | train_step_refl |
| 720P I2V default experiment config | configs/train_pavrm_i2v_720.yaml, configs/train_prfl_i2v_720.yaml | feature_layer, trainable_blocks, pool, optimizer settings |
4. Experimental Setup (实验设置)
4.1 Datasets
- 内部数据集:作者先收集约 31,000 个高质量 human portrait videos,用 Wan2.1-14B-I2V 生成对应视频,再经过自动过滤与人工标注后,得到 24,000 个 video pairs。
- 划分方式:约 23,500 个训练样本、100 个验证样本、400 个测试样本。
- 用途分离:
- generated videos 用于训练 reward model;
- real videos 用于 PRFL 中的 SFT regularization。
- Open-source benchmarks:
- VBench subject consistency 子集:72 prompts(T2V)
- VBench2 human anatomy 子集:120 prompts(T2V)
- VBench-I2V / VBench++ I2V Subject 子集:246 prompts(I2V)
4.2 Baselines
- Reward model baselines:VideoAlign-MQ、VideoPhy-PC
- Post-training baselines:
- SFT
- Reward Weighted Regression (RWR)
- RGB ReFL(基于 ContentV 风格实现,只解码第一帧,用 PickScore 作为 image reward)
- Base model:Wan2.1-T2V-14B / Wan2.1-I2V-14B(480P 与 720P 设置)
4.3 Evaluation metrics
- Reward model:在 5 个 timestep 区间 上做 stratified random sampling,并汇报平均 accuracy。
- T2V metrics:Motion Smoothness (MS), Dynamic Degree (DD), Subject Consistency (SC), Human Anatomy (HA), PAVRM score。
- I2V metrics:MS, DD, SC, I2V Subject Consistency (IC), PAVRM score。
- Human study:从测试集中随机采样 25 个 prompts,30 位专业标注员共做 2,250 次 pairwise comparisons。
4.4 Training config
- Optimizer:AdamW
- Learning rates:
- PAVRM query attention + head:1e-5
- PAVRM feature extractor:1e-6
- PRFL:5e-6
- Scheduler:UniPCMultistepScheduler
- Train timesteps:1000
- Inference steps:40
- Resolution / frames:480P / 720P,81 frames
- CFG:推理阶段使用 5.5
- Batch / parallelism:附录写明 global batch size 为 30,由 batch size 6 与 gradient accumulation 5 组成,sequence parallel size 为 4。
- 硬件信息:论文没有明确给出 GPU 型号;但资源表显示 PRFL 全帧训练峰值显存约 66.81 GB,官方仓库 README 则建议使用 至少 80GB 显存 GPU。
5. Experimental Results (实验结果)
5.1 主结果:Text-to-Video
| Setting | Method | DD (Inner) | HA (Inner) | DD (VBench) | HA (VBench2) | Avg |
|---|---|---|---|---|---|---|
| 480P | Pretrain | 22.00 | 84.24 | 68.06 | 74.38 | 81.03 |
| 480P | PRFL | 68.00 | 94.73 | 76.39 | 89.84 | 89.58 |
| 720P | Pretrain | 25.00 | 78.73 | 61.11 | 68.88 | 79.32 |
| 720P | PRFL | 81.00 | 90.89 | 84.72 | 90.40 | 90.60 |
关键信息:
- 在 T2V 480P,PRFL 相比 Pretrain 把 Dynamic Degree 从 22.00 提升到 68.00,Human Anatomy 从 84.24 提升到 94.73。
- 在 T2V 720P,PRFL 把 Inner Test Set 的 DD 从 25.00 提升到 81.00,VBench2 的 HA 从 68.88 提升到 90.40。
- MS / SC 基本保持高位,说明 PRFL 并不是靠“牺牲稳定性来换动态性”,而是在 motion quality 上做了更均衡的优化。
5.2 主结果:Image-to-Video
| Setting | Method | DD (Inner) | DD (VBench-I2V) | IC (Inner) | IC (VBench-I2V) | Avg |
|---|---|---|---|---|---|---|
| 480P | Pretrain | 57.00 | 40.65 | 96.86 | 97.21 | 85.31 |
| 480P | PRFL | 87.00 | 81.30 | 97.31 | 97.79 | 93.38 |
| 720P | Pretrain | 60.00 | 35.37 | 96.65 | 97.92 | 83.53 |
| 720P | PRFL | 76.00 | 68.42 | 98.26 | 98.73 | 91.31 |
这说明 PRFL 不仅对 T2V 有效,也能迁移到 I2V;尤其在动态程度上改进非常大,而 subject consistency 与 image condition consistency 也没有崩坏。
5.3 Reward model 结果与消融
- PAVRM 架构选择:在 720P I2V 上,Attention w./ query 的平均 accuracy 为 84.18%,优于 VideoAlign (78.83%) 和 VideoPhy (77.04%)。
- 训练深度消融:全微调 16 个 DiT blocks 时最佳,平均 accuracy 85.51%;再继续增加到 40 blocks 反而降到 83.27%。
- 损失函数消融:BCE 的平均 accuracy 为 80.05%,略好于 Bradley-Terry loss 的 79.85%。
- 跨模型泛化:Wan2.1 上训练的 PAVRM 在 Veo3 + HunyuanVideo 测试集上仍有 74.40% 平均 accuracy,说明 learned latent quality signal 具备一定 transferability。
5.4 Human study 与 qualitative results

Figure 5 解读: Figure 5 用堆叠条形图汇报人工偏好比较。PRFL 对 SFT、RWR、RGB ReFL 的胜率分别为 59.33%、63.20%、67.47%;而对应 competitor wins 只有 22.13%、20.53%、18.80%。这说明 PRFL 的改进不只是自动指标上的,而是真正能被人工感知到。

Figure 6 解读: Figure 6 展示了两个困难场景下的定性对比:左边是复杂舞蹈动作与镜头推进,右边是多人同框且包含手部/面部细节的乐器演奏场景。Pretrain、SFT、RWR、RGB ReFL 都会出现环境扭曲、肢体变形、手脸异常或首帧失败等问题;PRFL 则在整段视频中保持更稳定的结构与运动连贯性,说明 process-level reward 的确改善了 motion planning 和 artifact suppression。
5.5 Timestep sampling 与效率分析
- 不同 denoising stage 的贡献:
- Early stage:Avg 82.25
- Middle stage:Avg 87.02
- Late stage:Avg 85.01
- Full stage:Avg 89.58
- 结论是:
- early / middle stage 更影响 dynamic degree;
- late stage 更影响 anatomy / detail;
- full-range timestep sampling 才能最好地兼顾 motion 与 structure。
效率方面:
| Method | VRAM (GB) | Time / step (s) | Speedup |
|---|---|---|---|
| RGB ReFL (full frames) | OOM | - | - |
| RGB ReFL (first frame) | 55.47 | 72.38 / 64.89 | 1.00 |
| PRFL (full frames) | 66.81 | 51.11 / 43.69 | 1.42 / 1.49 |
这组结果非常关键:PRFL 虽然处理的是全 81 帧视频,却仍然比“只看第一帧”的 RGB ReFL 更快,而且避免了 full-frame RGB ReFL 的 OOM。
5.6 Limitations
论文在结论中明确指出该方法目前主要针对 motion quality。它尚未统一覆盖 aesthetics、semantic alignment 等更多维度的 reward,因此未来方向包括:
- 多维 reward 的联合建模;
- 更丰富的 preference signal;
- 向 controllable generation 和 video editing 扩展。