UniGRPO: Unified Policy Optimization for Reasoning-Driven Visual Generation
Authors: Jie Liu, Zilyu Ye, Linxiao Yuan, Shenhan Zhu, Yu Gao, Jie Wu, Kunchang Li, Xionghui Wang, Xiaonan Nie, Weilin Huang, Wanli Ouyang Affiliations: The Chinese University of Hong Kong, ByteDance Seed arXiv: 2603.23500 GitHub: ByteDance-Seed/Bagel Venue: arXiv Note: 目前未检索到 UniGRPO 官方开源实现;这里记录的是论文链接与相关公开底座。
1. Motivation(研究动机)
当前 unified multimodal generation 模型正在往 interleaved generation 演化,即模型不再只做单轮 text-to-image,而是能在文本推理、图像生成、再推理、再编辑之间交错运行。论文指出,这类模型一个关键潜力是能够利用 test-time compute:先思考、再生成、再反思,从而在复杂视觉任务上得到更好的结果。
但现有方法有两个明显断裂点。第一,语言侧和视觉侧的后训练通常是分开的:LLM 侧用 GRPO/PPO 一类方法提升 reasoning,图像侧则在 diffusion / flow matching 上单独做 reward optimization。这样会导致 reasoning 与 image synthesis 之间的 credit assignment 被切断,模型无法真正学会“为了生成更好图像而思考”。第二,面向 flow matching 的 RL 方法虽然已经出现,但大多围绕单模态图像生成设计,没有直接覆盖 unified model 中“离散文本动作 + 连续视觉动作”的联合优化问题。
因此,这篇论文试图解决的问题是:能否把 Prompt → Thinking → Image 整个过程统一成一个 Markov Decision Process,再用一个统一的 RL 目标同时更新文本推理策略和图像生成策略?这个问题值得研究,因为它决定了未来 fully interleaved multimodal model 的 post-training 是否能自然扩展到多轮编辑、视觉对话和长程 multimodal interaction,而不只是停留在“先写 prompt,再单次出图”的浅层 pipeline。
2. Idea(核心思想)
UniGRPO 的核心思想是:把 unified multimodal generation 中的文本推理 token 生成和 flow matching 图像去噪步骤,都视为同一个 MDP 里的 action,然后基于最终生成图像得到的 sparse terminal reward,统一计算 group-relative advantage,同时优化两种策略。
更具体地说,作者没有重新设计一整套全新 RL 算法,而是采取极简路线:文本部分沿用标准 GRPO,图像部分建立在 FlowGRPO 上,再用统一目标
把两者绑定起来。与已有方法最根本的不同在于:它不是“先优化图像、再补一个 text GRPO stage”的 two-stage 方案,也不是为语言模型和 diffusion backbone 分别构造两套 RL 回路,而是对同一个 unified model 里的离散 token policy 与连续 flow policy 做 end-to-end 联合优化。
3. Method(方法)
3.1 Overall framework
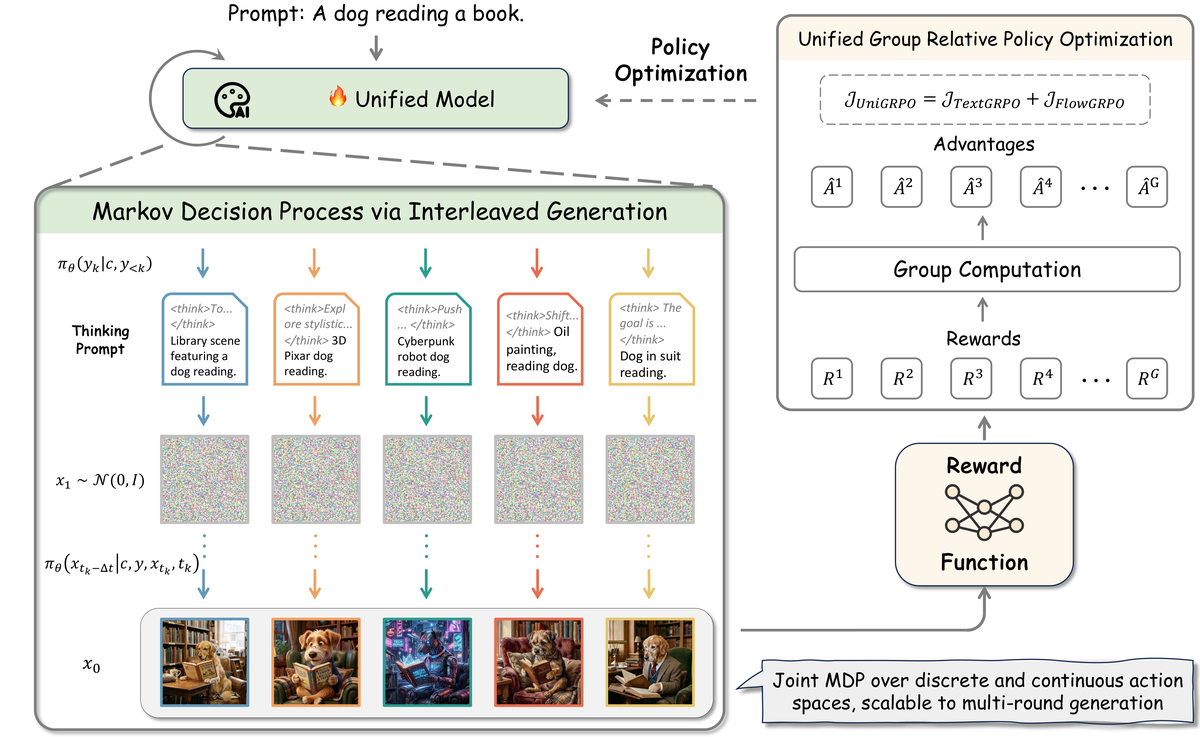
Figure 1 解读:该图对应论文中的总览示意,展示了 UniGRPO 如何把“用户 prompt → reasoning → image generation”串成一个联合优化过程。图中上半部分表示 unified model 先对输入 prompt 采样多条 thinking chain,再基于这些 reasoning 条件生成多张图像;中间位置的 Reward Function 对完整轨迹给出 terminal reward;下半部分的 Group Computation 则把同一组样本的 reward 转成相对 advantage。最重要的信息是,图里同时出现了离散文本动作 与连续视觉动作 ,说明作者不是只在图像侧做 RL,而是把两种 action space 一起纳入 MDP。
论文把 interleaved generation 建模为一个序列决策过程 。对于单轮 reasoning-driven image generation:
- 在文本阶段,状态是 ,其中 是用户 prompt, 是已生成 reasoning token。
- 在图像阶段,状态是 ,包含 prompt、完整 reasoning trace、当前 noisy latent 以及时间步。
- 文本动作是离散 token 。
- 图像动作是连续 latent 更新 。
- 中间步骤没有 reward,直到最终图像 latent 完全去噪为 后,才由 reward model 给出 sparse terminal reward 。
给定 unified model 后,UniGRPO 对每个 prompt 先采样 条 reasoning chain,再基于每条 chain 生成对应图像轨迹,最终在组内比较 reward,得到相对 advantage,用于同时更新 text 与 image policy。
统一目标为:
其中论文所有实验都设定 ,即显式把 reasoning 与 synthesis 两个目标等权处理。
3.2 Key component 1: Text GRPO
文本部分直接采用标准 GRPO。对于 prompt ,策略 采样一组输出 ,每个样本的 advantage 用组内 reward 标准化得到:
随后对每个 token 位置做 clipped importance ratio 更新。论文给出的文本目标是:
其中
这里的关键点在于:reasoning token 并不是单独追求语言质量,而是通过最终图像 reward 反向赋值。因此模型学到的 thinking trace 更偏向“服务视觉生成”的 task-oriented reasoning,而不是冗长但无效的 CoT。
3.3 Key component 2: Flow GRPO for visual synthesis
视觉部分基于 FlowGRPO。作者把原本 deterministic 的 flow matching ODE 重写为带噪 SDE,以便在 RL 中产生 exploration:
其中 。
作者使用的是 FlowGRPO-Fast 变体:只在连续时间窗口中的部分 denoising step 上走 SDE 并保留梯度,其余时间步采用普通 ODE 采样且不跟踪梯度,以降低计算成本。图像部分的 importance ratio 定义为:
但论文指出 diffusion / flow 模型里的 ratio 分布通常左移且方差随 timestep 变化明显,直接做 clipping 会失效,容易产生 reward hacking。于是作者引入 GRPO-Guard 中的 RatioNorm:
其中
最终视觉目标只在 SDE 子集 上计算:
3.4 Key component 3: CFG-free linear rollout

Figure 2 解读:该图对应论文 Figure 4 的 CFG ablation。图中比较了训练时使用 CFG 与不使用 CFG 的 reward 曲线。作者强调,虽然训练时加 CFG 可能在某些阶段拿到更高 reward,但最终评测时,No-CFG 训练可以达到可比甚至更优的结果。这说明 CFG 不是 RL-based alignment 的必要条件,反而会让 rollout 变成分叉结构,显著增加多条件、多轮场景下的计算和梯度估计复杂度。
论文最重要的工程决策之一,是训练阶段完全移除 Classifier-Free Guidance。原因不是单纯为了省算力,而是为了未来扩展到 multi-round interleaved generation。标准 CFG 每个 step 至少要做 conditional / unconditional 两次前向;若进入 editing 等多条件场景,分支数还会继续增加。对于 RL 而言,这会带来:
- 每个 rollout 的函数评估数乘倍增长;
- 上下文条件分叉,难以维护线性轨迹;
- 计算图分支化后,梯度估计与 credit assignment 变复杂。
因此 UniGRPO 强制使用 linear, unbranched rollout。作者认为,去掉 CFG 后 prompt adherence 的下降,可以通过 reward maximization 在训练中“内化”回模型权重,而不是依赖外部 guidance 在推理时强行拉回。
3.5 Key component 4: Velocity-based regularization

Figure 3 解读:该图对应论文 Figure 5 的 regularization ablation,左到右分别给出 training reward、validation reward,以及不同正则策略下生成图像的视觉表现。图中可以看到:无正则时训练 reward 上升但验证 reward 回落,同时图像出现明显的 reward hacking 痕迹;latent KL 虽然施加了约束,但仍然较早出现网格状 artifact;直接在 velocity field 上加 MSE 能得到最稳定的训练曲线和最自然的视觉结果。这张图直接支撑了作者把标准 latent KL 改成 velocity MSE 的核心论点。
在 flow matching RL 中,reward hacking 是主要风险。论文指出,在 SDE 形式下,latent transition 的局部 KL 实际上可以解析计算,并自然带有 的噪声方差权重。这会导致不同 timestep 的约束强弱不均:高噪声区域的 KL 惩罚过弱,给策略留下可乘之机。
因此作者不再使用 timestep-dependent latent KL,而是直接在 velocity field 上加未加权 MSE:
这相当于把 RL 后的 vector field 在所有噪声水平上都压回 reference model 附近。论文的结论是,这种 uniform regularization 比标准 latent KL 更能抑制 reward hacking,同时保留 base model 的 generative priors。
3.6 Key component 5: Training dynamics and reasoning behavior

Figure 4 解读:该图对应论文 Figure 3,展示 UniGRPO 在 finetuned Bagel 底座上的 train / val reward 曲线。曲线整体平稳上升,说明 unified objective 没有因为同时优化文本和图像而导致训练崩溃;相反,它说明 terminal reward 可以稳定驱动 reasoning 与 synthesis 联合改进。作者借此证明,联合 RL 至少在单轮 reasoning-driven generation 上是可训练的。

Figure 5 解读:该图对应论文 Figure 6,展示 UniGRPO 生成的 reasoning text 与最终图像。图中最值得注意的是,thinking trace 不再是宽泛的 prompt embellishment,而是更聚焦于完成视觉任务的关键约束,例如数量、关系、位置和风格转写;对应的生成图像也更贴近用户要求。作者据此认为,联合 RL 能把 thought process 与最终 visual reward 绑得更紧。
此外,论文附录还给出 Bagel 原始 reasoning(Figure 7)和 SFT 后 reasoning(Figure 8)的对比,说明仅靠 SFT 虽能让 thinking 更长、更像 LLM 风格,但 reasoning 到视觉细节的转译依然较弱;而 UniGRPO 则通过最终图像 reward 让 reasoning 变得更“有用”。

Figure 6 解读:这张图对应论文附录 Figure 7,展示原始 Bagel 的 reasoning trace 与生成图像。可以看到它会写出较长的解释性文本,但这些文本更像在扩写 prompt,而不是在提炼真正决定视觉结果的关键约束;因此 reasoning 的存在并没有稳定转化成更高质量的图像控制。

Figure 7 解读:这张图对应论文附录 Figure 8,展示 SFT 后模型的 reasoning trace 与生成图像。相比 Figure 7,SFT 版本的 thinking 更像标准 LLM 风格,表达更完整、形式更规范;但作者想说明的是,仅靠 SFT 仍不足以保证“更好的思考一定导向更好的视觉结果”,所以后续还需要 UniGRPO 用 terminal reward 将 reasoning 与 image quality 显式绑定。
3.7 Pseudocode(基于论文方法与已公开 Bagel 项目结构整理)
代码搜索结果:未找到 UniGRPO 官方仓库。下述伪代码严格依据论文公式与公开 Bagel 仓库的项目结构、模型职责描述以及 inferencer 入口整理,用来说明“这类 unified model 可能如何承载 UniGRPO 训练逻辑”。其中函数名是说明性接口,不代表 Bagel 仓库已经公开了完全同名 API,更不代表 UniGRPO 官方实现细节已经开源。
(a) 组内采样与联合 advantage 计算
import torch
def compute_group_advantages(rewards: torch.Tensor, eps: float = 1e-6) -> torch.Tensor:
mean = rewards.mean()
std = rewards.std(unbiased=False).clamp_min(eps)
return (rewards - mean) / std
def rollout_group(unified_model, prompts, group_size, image_sampler, reward_fn):
group_outputs = []
for prompt in prompts:
samples = []
for _ in range(group_size):
reasoning_tokens = unified_model.generate_text(prompt)
image_traj, final_image = image_sampler.sample(
model=unified_model,
prompt=prompt,
reasoning_tokens=reasoning_tokens,
)
reward = reward_fn(prompt, final_image)
samples.append({
"prompt": prompt,
"reasoning_tokens": reasoning_tokens,
"image_traj": image_traj,
"final_image": final_image,
"reward": reward,
})
rewards = torch.tensor([s["reward"] for s in samples], dtype=torch.float32)
advantages = compute_group_advantages(rewards)
for s, adv in zip(samples, advantages):
s["advantage"] = adv
group_outputs.append(samples)
return group_outputs(b) Text GRPO 更新
import torch
def text_grpo_loss(logprobs, old_logprobs, advantages, kl_to_ref, epsilon, beta_txt):
ratio = torch.exp(logprobs - old_logprobs)
unclipped = ratio * advantages[:, None]
clipped = torch.clamp(ratio, 1.0 - epsilon, 1.0 + epsilon) * advantages[:, None]
policy_term = torch.minimum(unclipped, clipped).mean()
return -(policy_term - beta_txt * kl_to_ref.mean())
def compute_text_branch(unified_model, prompt_batch, reasoning_batch, old_policy, ref_policy,
advantages, epsilon, beta_txt):
logprobs = unified_model.score_reasoning_tokens(prompt_batch, reasoning_batch)
old_logprobs = old_policy.score_reasoning_tokens(prompt_batch, reasoning_batch)
ref_kl = unified_model.kl_with_reference_on_text(prompt_batch, reasoning_batch, ref_policy)
return text_grpo_loss(logprobs, old_logprobs, advantages, ref_kl, epsilon, beta_txt)(c) Flow rollout 与 RatioNorm
import torch
def flow_sde_step(v_pred, x_t, sigma_t, t, dt):
noise = torch.randn_like(x_t)
drift = v_pred + (sigma_t ** 2 / (2.0 * t)) * (x_t + (1.0 - t) * v_pred)
x_next = x_t + drift * dt + sigma_t * (dt ** 0.5) * noise
return x_next, noise
def ratio_norm(log_ratio, delta_mu_norm_sq, sigma_t, dt):
return sigma_t * (dt ** 0.5) * (log_ratio + delta_mu_norm_sq / (2.0 * sigma_t ** 2 * dt))
def sample_flow_trajectory(unified_model, prompt, reasoning_tokens, timesteps, sigma_schedule):
x_t = unified_model.prepare_vae_latent(prompt, reasoning_tokens)
traj = []
for idx, t in enumerate(timesteps[:-1]):
dt = timesteps[idx] - timesteps[idx + 1]
v_pred = unified_model.predict_velocity(prompt, reasoning_tokens, x_t, t)
x_next, noise = flow_sde_step(v_pred, x_t, sigma_schedule[idx], t, dt)
traj.append({"x_t": x_t, "t": t, "dt": dt, "v_pred": v_pred, "noise": noise})
x_t = x_next
final_image = unified_model.decode_latent(x_t)
return traj, final_image(d) Velocity MSE 正则与联合优化
import torch
def velocity_mse_loss(v_pred, v_ref):
return ((v_pred - v_ref) ** 2).mean()
def training_step(unified_model, old_policy, ref_policy, batch, reward_fn,
epsilon=0.2, beta_txt=0.01, beta_img=0.01, lam=1.0):
group_rollouts = rollout_group(
unified_model=unified_model,
prompts=batch,
group_size=8,
image_sampler=unified_model,
reward_fn=reward_fn,
)
total_text_loss = 0.0
total_flow_loss = 0.0
total_reg_loss = 0.0
for samples in group_rollouts:
prompt_batch = [s["prompt"] for s in samples]
reasoning_batch = [s["reasoning_tokens"] for s in samples]
advantages = torch.stack([s["advantage"] for s in samples])
total_text_loss = total_text_loss + compute_text_branch(
unified_model, prompt_batch, reasoning_batch,
old_policy, ref_policy, advantages, epsilon, beta_txt
)
for sample in samples:
for step in sample["image_traj"]:
log_ratio = unified_model.flow_logprob_ratio(step, old_policy, sample["prompt"], sample["reasoning_tokens"])
delta_mu_norm_sq = unified_model.delta_mu_norm_sq(step, old_policy, sample["prompt"], sample["reasoning_tokens"])
normalized_ratio = ratio_norm(log_ratio, delta_mu_norm_sq, sigma_t=1.0, dt=step["dt"])
clipped = torch.clamp(normalized_ratio.exp(), 1.0 - epsilon, 1.0 + epsilon)
flow_obj = torch.minimum(normalized_ratio.exp() * sample["advantage"], clipped * sample["advantage"])
total_flow_loss = total_flow_loss - flow_obj.mean()
v_pred = unified_model.predict_velocity(sample["prompt"], sample["reasoning_tokens"], step["x_t"], step["t"])
v_ref = ref_policy.predict_velocity(sample["prompt"], sample["reasoning_tokens"], step["x_t"], step["t"])
total_reg_loss = total_reg_loss + beta_img * velocity_mse_loss(v_pred, v_ref)
loss = total_text_loss + lam * total_flow_loss + total_reg_loss
loss.backward()
return {"loss": float(loss.detach())}3.8 Code-to-paper mapping table
说明:下表区分“已直接核验”和“基于公开说明推断”。由于 UniGRPO 官方代码未公开,且当前只可靠读取到 Bagel 的仓库树、
inferencer.py、TRAIN.md与项目说明,因此凡是未直接逐行核验的函数名,一律按“推断”处理,不把其写成确定事实。
| Paper Concept | Public Source | Key Class/Function | 核验状态 | 说明 |
|---|---|---|---|---|
| Unified model backbone | https://github.com/ByteDance-Seed/Bagel | Bagel unified multimodal model | 推断 | 论文明确以 Bagel 为底座;公开仓库树中存在 modeling/bagel/,可确认有对应模块,但此处未逐行核验具体 API |
| Thinking-first inference pipeline | https://github.com/ByteDance-Seed/Bagel/blob/main/inferencer.py | InterleaveInferencer, text-first then image generation flow | 已直接核验 | 从公开 inferencer.py 的内容概括得到,说明 Bagel 公开推理入口确实支持 interleaved context 处理 |
| CFG-related inference path | https://github.com/ByteDance-Seed/Bagel/blob/main/inferencer.py | CFG-related image generation logic | 已直接核验 | 公开 inferencer.py 中可见 cfg_text_scale、cfg_img_scale 等逻辑,因此论文“训练时去掉 CFG”与公开底座推理结构能对上 |
| Image decoding stage | https://github.com/ByteDance-Seed/Bagel/blob/main/inferencer.py | latent-to-image decode flow | 已直接核验 | 可从 inferencer.py 的解码流程概括出 latent 最终会被 VAE decode 为图像 |
| Unified training entry for Bagel base model | https://github.com/ByteDance-Seed/Bagel/blob/main/TRAIN.md | train/pretrain_unified_navit.py | 已直接核验 | 这是公开底座训练入口,不是 UniGRPO RL 训练脚本,但可作为底座背景 |
| Text GRPO branch in UniGRPO | Paper Eq. (1)(2) + Bagel public project structure | reasoning token policy optimization | 推断 | 论文方法明确,但未见官方代码;这里只能说明它应绑定在 unified model 的 text generation branch 上 |
| Flow GRPO branch in UniGRPO | Paper Eq. (3)(6) + Bagel public project structure | flow-based image policy optimization | 推断 | 论文方法明确,但未见官方代码;这里只能说明它应绑定在 Bagel 的 visual generation / latent rollout branch 上 |
| Velocity MSE regularization | Paper Eq. (8) | velocity-field regularizer | 已直接核验(论文) | 这是论文中明确提出的关键改动,不依赖开源代码即可确认 |
4. Experimental Setup(实验设置)
4.1 Datasets and benchmarks
论文主实验使用两个评测集合:
- TA Benchmark(Text Alignment):作者内部构建的 150 条 diverse prompts。每个 prompt 生成 4 张图,由 VLM 按每条 prompt 预定义的多个 exam points 做二值判定,单图得分为所有 exam point 的平均值,最终报告所有图像的平均分。
- GenEval:标准 text-to-image benchmark,评测 compositional generation,覆盖 object counting、spatial relations、attribute binding 等能力。
论文没有公开训练数据的具体规模,只说明为了建立更强基线,作者用 curated internal dataset 对 Bagel 做了 SFT。这里需要明确写出:训练集规模、样本数和清洗细节,论文未详细说明。
4.2 Pretrained model and reward model
- Backbone:Bagel。作者把它视为具有 interleaved generation 潜力的 unified model。
- Starting checkpoint:除非特别说明,所有 RL baseline 和 UniGRPO 都从 SFT 后的 Bagel checkpoint 出发。
- Reward model:与 RewardDance 相同的 differentiable reward model,基于 InternVL 并在 user preference data 上微调,用于评估 image-prompt consistency。
作者专门说明,虽然 UniGRPO 理论上可以兼容 black-box verifier 或 VLM reward,但为了与 ReFL 这类必须依赖可微 reward 的 baseline 公平比较,主实验采用了可微 reward 设定。
4.3 Baselines
论文比较的 baseline 包括:
- Bagel(是否显式 thinking 两种设置)
- SFT(是否显式 thinking)
- ReFL
- FPO
- FlowGRPO
- TextGRPO
- ReFL (w/ Thinking)
- ReFL (w/ Thinking) + TextGRPO
- UniFPO
- UniGRPO
这些 baseline 覆盖了:
- 只优化图像 policy 的方法;
- 只优化文本 reasoning 的方法;
- 分阶段优化 text 和 image 的 hybrid 方法;
- 用 FPO 替代 FlowGRPO 的 unified 版本。
因此实验设计的重点不是只证明“RL 比 SFT 强”,而是验证“联合优化 text + image 是否优于只做单侧优化或分阶段优化”。
4.4 Metrics
- TA Score:内部 VLM-based alignment score。
- GenEval Overall:标准总分。
- GenEval category breakdown:Single Object、Two Objects、Counting、Colors、Position、Attribute Binding。
- Training / Validation reward curves:用于观察训练稳定性和是否发生 reward hacking。
4.5 Training config
根据论文正文与附录可提取的信息:
- 图 3 明确说明 UniGRPO 主实验是在 finetuned Bagel base model, resolution 1024 上进行。
- CFG ablation 图 4 使用的是 original Bagel, resolution 512,因此与主实验曲线不可直接横向比较。
- 论文正文未给出完整 batch size、学习率、GPU 数量等 RL 超参数,作者说明“详细超参数在 Appendix 3 / Appendix B”。但当前可读取文本中并未包含完整表格内容,因此这部分只能保留已知事实,不能臆造。
4.6 公开底座 Bagel 的训练背景(非 UniGRPO RL 超参)
为了帮助理解论文的 base model 来源,可以参考公开 Bagel TRAIN.md 中的训练背景信息,但这部分不是 UniGRPO 论文已经披露的 RL 训练配置:
- 训练脚本入口:
train/pretrain_unified_navit.py - 示例分布式配置:
torchrun --nproc_per_node=8 max_latent_size在 Bagel 微调示例中建议设为64- 示例学习率包括
1e-4(默认训练)与2e-5(微调示例) warmup_steps=2000、ema=0.9999、max_grad_norm=1.0
因此,这些参数只能作为底座背景,不应被误读为 UniGRPO 本文的完整 RL 超参数表。
5. Experimental Results(实验结果)
5.1 Main benchmark results
论文 Table 1 的主结果如下:
说明:下表数值根据论文 Table 1 手工转录,并与 PDF 提取文本逐项核对。
| Model / Method | Thinking | TA Score | GenEval |
|---|---|---|---|
| Bagel | × | 0.6810 | 0.78 |
| Bagel | ✓ | 0.7132 | 0.79 |
| SFT | × | 0.7486 | 0.83 |
| SFT | ✓ | 0.7769 | 0.82 |
| ReFL | × | 0.7786 | 0.85 |
| ReFL | ✓ | 0.8120 | 0.84 |
| FPO | × | 0.7893 | 0.87 |
| FPO | ✓ | 0.8159 | 0.85 |
| FlowGRPO | × | 0.8112 | 0.88 |
| FlowGRPO | ✓ | 0.8208 | 0.86 |
| TextGRPO | ✓ | 0.8078 | 0.88 |
| ReFL (w/ Thinking) | ✓ | 0.7804 | 0.83 |
| ReFL (w/ Thinking) + TextGRPO | ✓ | 0.7987 | 0.87 |
| UniFPO | ✓ | − | − |
| UniGRPO (Ours) | ✓ | 0.8381 | 0.90 |
核心结论有三点:
- SFT 对 Bagel 的提升很明显,说明底座原始 instruction-following 和 generation quality 仍不足。
- UniGRPO 在 TA 与 GenEval 上都达到最佳,优于只做图像侧 RL 的 FlowGRPO,也优于只做文本侧 RL 的 TextGRPO。
- UniFPO 训练直接崩掉,论文主表中用
−表示无有效结果,附录表中用×表示 training collapse;两者表达的是同一语义:该设置没有得到可报告结果。这也说明 unified setting 下,GRPO-based formulation 的稳定性优于 FPO 路线。
5.2 Detailed GenEval breakdown
附录 Table 2 给出了更细粒度结果。这里同样是根据论文 Table 2 手工转录,并与 PDF 文本逐项核对:
| Method | Overall | Single Obj. | Two Obj. | Counting | Colors | Position | Attr. Binding |
|---|---|---|---|---|---|---|---|
| Bagel × | 0.78 | 0.98 | 0.96 | 0.78 | 0.84 | 0.52 | 0.58 |
| Bagel ✓ | 0.79 | 0.99 | 0.92 | 0.77 | 0.88 | 0.56 | 0.62 |
| SFT × | 0.83 | 0.99 | 0.95 | 0.83 | 0.89 | 0.58 | 0.75 |
| SFT ✓ | 0.82 | 0.98 | 0.93 | 0.63 | 0.91 | 0.68 | 0.79 |
| ReFL × | 0.85 | 1.00 | 0.97 | 0.86 | 0.92 | 0.57 | 0.81 |
| ReFL ✓ | 0.84 | 0.99 | 0.96 | 0.63 | 0.94 | 0.70 | 0.82 |
| FPO × | 0.87 | 0.99 | 0.99 | 0.90 | 0.93 | 0.59 | 0.86 |
| FPO ✓ | 0.85 | 0.99 | 0.97 | 0.69 | 0.91 | 0.69 | 0.81 |
| FlowGRPO × | 0.88 | 0.99 | 0.98 | 0.93 | 0.94 | 0.60 | 0.86 |
| FlowGRPO ✓ | 0.86 | 0.99 | 0.96 | 0.76 | 0.90 | 0.71 | 0.84 |
| TextGRPO ✓ | 0.88 | 0.99 | 0.96 | 0.87 | 0.91 | 0.76 | 0.84 |
| ReFL (w/ Thinking) ✓ | 0.83 | 0.99 | 0.94 | 0.64 | 0.92 | 0.70 | 0.81 |
| ReFL (w/ Thinking) + TextGRPO ✓ | 0.87 | 0.98 | 0.97 | 0.84 | 0.91 | 0.75 | 0.80 |
| UniFPO ✓ | × | × | × | × | × | × | × |
| UniGRPO ✓ | 0.90 | 0.99 | 0.99 | 0.91 | 0.91 | 0.73 | 0.86 |
从这个表可以看出,UniGRPO 的提升主要集中在:
- Counting:0.91,接近最优,说明 reasoning 对组合性约束建模有帮助;
- Position:0.73,虽然不是该列最高,但明显优于很多图像侧-only baseline;
- Attribute Binding:0.86,与最强基线持平,说明联合优化没有牺牲属性绑定能力。
5.3 Qualitative findings

Figure 8 解读:该图对应论文 Figure 2 的 T2I qualitative comparison,比较了 Bagel、SFT 与 UniGRPO 在多种 prompt 下的出图结果。图中能直接看到,Bagel 容易产生过饱和和 synthetic artifact;SFT 虽然减轻了伪影,但有时图像偏糊;UniGRPO 则在细节真实性、风格完成度以及对复杂 prompt 的服从性上更好。这一图和 Table 1 一起表明,UniGRPO 的优势不只是 reward 分数更高,而是视觉上也更可信。
论文还指出,Bagel 与 SFT 版本虽然也能生成较长 reasoning text,但这些 reasoning 往往不够聚焦,甚至和最终视觉任务脱节;UniGRPO 则把 thought process 与图像 reward 显式绑定,因此 reasoning 更像是“为生成服务的中间计划”。
5.4 Ablation findings
- 去掉 CFG 是成立的:训练中不使用 CFG,最终评测表现仍可比甚至更优,说明可以不依赖 branched rollout。
- Velocity MSE 明显优于 latent KL:无正则会 reward hack;latent KL 会出现网格 artifact;velocity MSE 最稳。
- 联合训练优于单侧训练:与 FlowGRPO、TextGRPO 对比可见,只优化一个分支不如同时优化 reasoning 与 synthesis。
5.5 Limitations
论文也有几个明确局限:
- 目前只验证了 single-round generation,尚未真正扩展到 multi-round editing / storytelling。
- reward 仍然是 sparse terminal reward,没有对 reasoning 过程做细粒度监督,存在 credit assignment 效率不足的问题。
- 训练数据、SFT 数据与完整 RL 超参数未在正文中充分披露,可复现性仍依赖后续开源。
- 代码层面,UniGRPO 官方实现尚未公开检索到,现阶段更像是算法方向验证而不是可直接复现的开源 recipe。
5.6 Overall conclusion
这篇论文最有价值的地方,不是提出了一个特别复杂的新 RL 算法,而是给出了一个非常清晰的 unified post-training 视角:
- 文本 reasoning 和图像 flow matching 可以被放进同一个 MDP;
- sparse terminal reward 足以驱动两者联合改进;
- 若想把这一路线扩展到未来 multi-round interleaved generation,训练时必须尽量保持 rollout 线性、无分叉、可扩展。
因此,UniGRPO 可以看作是 interleaved multimodal model 的一个强 baseline:它证明了“reasoning-driven visual generation”不一定要靠两阶段 pipeline,也可以在 unified model 内通过单一 RL 循环联合优化。