Reinforce Adjoint Matching: Scaling RL Post-Training of Diffusion and Flow-Matching Models
Paper: arXiv:2605.10759 Code: AndreasBergmeister/ram Code reference:
main@d92efb9a(2026-05-13)
1. Motivation (研究动机)
现有 Diffusion / Flow Matching 模型的 pretraining 很容易扩展,因为训练目标本质上是 supervised regression:先把 clean sample 解析加噪,再让模型回归 closed-form velocity / score target。但进入 RL post-training 后,常见做法会丢掉这种结构:Flow-GRPO 需要在生成轨迹上做 policy-gradient 式更新,Adjoint Matching / ELEGANT 类方法依赖 SDE rollout、reward gradient 或 backward adjoint sweep,DiffusionNFT / AWM 这类效率导向方法又往往使用 surrogate loss,容易牺牲 CFG 兼容性或图像质量。
本文要解决的具体问题是:如何把 text-to-image diffusion / flow model 对齐到不可微 reward(compositional correctness、OCR text rendering、human preference),同时保留 pretraining 那种“解析加噪 + 回归 target”的可扩展训练形式。关键目标不是提出一个新的 reward,而是让 RL fine-tuning 的训练单元仍像 Flow Matching pretraining 一样简单、并行、稳定。
这个问题值得研究,因为如果 RL post-training 能回到 regression-style objective,就可以避免昂贵 SDE rollout 和 reward-gradient dependency;对大规模 T2I 模型而言,这直接转化为更少训练步数、更低 wall-clock 成本,并且能在 GenEval、OCR、PickScore 这类实际 reward 上快速提升生成能力。
2. Idea (核心思想)
核心洞察:在 KL-regularized reward maximization 下,最优生成过程只需要把 clean endpoint 分布从 tilt 到 ,而给定 clean endpoint 后的 noising law 不变。因此训练时可以先从当前模型采样 clean endpoint ,对它打 reward,再按 pretraining kernel 解析加噪得到 ,最后回归一个 reward-corrected velocity target。
RAM 的创新点是把 Adjoint Matching 的 optimality condition 与 REINFORCE identity 结合起来:reward gradient 被替换成 reward-weighted bridge score;bridge score 又能用 Bayes rule 写成 velocity field 与 pretraining target 的 closed form。因此 RAM 不需要 reward 可微、不需要 SDE rollout,也不需要 backward adjoint sweep。
与 Flow-GRPO 的根本差异在于:Flow-GRPO 沿采样轨迹做 RL-style update,需要大量生成 steps 才达到高 reward;RAM 每个 clean endpoint 可复用 个解析加噪 training states,把 RL signal 变成 MSE regression target。与 Adjoint Matching 的差异在于:RAM 明确丢弃 path-cost correction,以换取低方差和可扩展性,而不是追求带 pathwise adjoint 的 exact estimator。
3. Method (方法)
3.1 Overall framework
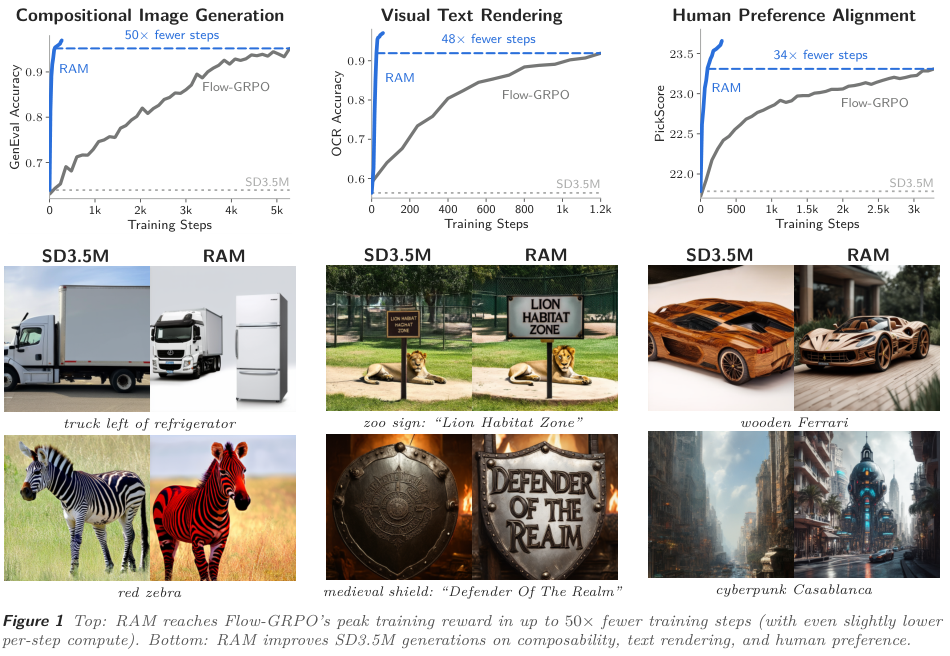
Figure 1 解读:上排三条曲线展示 RAM 在 GenEval、OCR、PickScore 上用远少于 Flow-GRPO 的训练步数达到或超过其 peak reward;下排展示 SD3.5M baseline 与 RAM post-trained model 的 paired samples。图中最重要的信息是:RAM 的收益不是只体现在 reward 曲线上,也能在 compositional relation、可读文字、偏好对齐样例中直观看到。

Figure 2 解读:RAM 的训练循环先用当前 policy / EMA policy 采样 clean endpoint ,用 reward model 得到 ,再用与 pretraining 相同的解析 kernel 生成多个 noisy states 。每个 endpoint 共享一次采样和 reward 查询成本,却产生 个 loss targets;这正是 RAM 相比 rollout-based RL 更快的来源。
直觉上,pretraining 学的是“给定 noisy state,往 clean data 方向走”的 velocity;RL post-training 则应该让这个 velocity 更偏向高 reward endpoint。RAM 没有显式改变加噪过程,而是在 regression target 中加入 reward-weighted correction:高 reward endpoint 让 target 更靠近从 回到该 endpoint 的方向,低于组均值的 endpoint 则相反。这样 reward signal 被嵌入到每个 noisy training state 的 supervised target 中。
3.2 从 optimal control 到 RAM target
Flow Matching 的 pretraining kernel 与 loss 为:
KL-regularized reward maximization 的 endpoint target 是 tilted distribution:
Theorem 3.1 说明最优 controlled process 满足:
也就是说,最优解只 tilt clean endpoint distribution,不改变 conditional noising law。这使得“sample endpoint + analytic noising”成为合理训练估计器。
Adjoint Matching 的 optimality condition 是:
其中 。RAM 对 adjoint 做分解:
RAM 的可扩展版本丢弃第二项 path-cost correction,得到 reward proxy:
Bayes bridge score 给出 closed-form:
再用 control 与 velocity 的关系
得到 RAM velocity loss:
其中 ,, 表示 stop-gradient。
**论文公式与 released code 实现差异:**论文公式写的是 raw reward 与当前 ;released code 在 scripts/training_sd3.py::compute_loss 中使用 group/epoch-normalized advantages,再乘 reward_multiplier,并把 target 中的当前 policy velocity 替换为 lagged old LoRA adapter 的 old_v:target_velocity = base_v + reward_multiplier * advantage * ((noise - latent) - old_v)。此外,论文 Appendix D 报告的若干 hyperparameter 与 released configs 不完全一致:论文写 OCR/PickScore reward coefficient 为 、training CFG 为 、PickScore eval CFG 为 、AdamW weight decay 为 、;configs/*.yaml 在 main@d92efb9a 中分别是 OCR/PickScore reward_multiplier=50/100、GenEval/OCR training CFG 为 1.0、PickScore eval CFG 为 4.5、weight_decay=1.e-4、beta2=0.99。
3.3 Path-cost correction 为什么被丢弃

Figure 3 解读:二维 toy experiment 中,各 estimator 都能恢复 tilted target density,但右图显示 target variance 差异很大。RAM 因为直接丢弃 path-cost gradient,regression target 方差最低;random jump / local estimator 虽更接近 exact correction,但高方差会在高维图像模型中被放大。作者的结论是:对 image-scale training,低方差和无需 adjoint sweep 比 exact path-cost correction 更重要。
Estimator landscape 可以概括为:RAM 使用 endpoint + analytic noising,代价是 biased;random jump 同样便宜但 high variance;full-horizon estimator 需要 SDE rollout 和 pathwise VJP;Malliavin 版本更 exact 但还需要 score VJP;local estimator 便宜一些但 high variance。RAM 的取舍是 intentionally biased but scalable。
3.4 Released code 伪代码
Code reference:
main@d92efb9a(2026-05-13) — pseudocode and mapping based on this commit
组件 A:采样 endpoint、reward、group-relative advantage
import torch
@torch.no_grad()
def sample_epoch_pseudocode(pipe, reward_fns, prompts, config, accelerator):
latents, images = [], []
for prompt_batch in batched(prompts, config.sampling_batch_size):
prompt_embeds, pooled = encode_prompts(pipe, prompt_batch)
terminal_latent = pipe(
prompt_embeds=prompt_embeds,
pooled_prompt_embeds=pooled,
num_inference_steps=config.num_train_inference_steps,
guidance_scale=config.train_guidance_scale,
output_type="latent",
).images
decoded = pipe.vae.decode(terminal_latent)
images.append(pipe.image_processor.postprocess(decoded, output_type="pt"))
latents.append(terminal_latent)
latents = torch.cat(latents)
images = torch.cat(images)
rewards = sum(fn(images, prompts) for _, fn in reward_fns)
if config.scale_rewards == "epoch":
epoch_std = accelerator.gather(rewards).std(correction=0) + 1e-4
advantages = torch.zeros_like(rewards)
for start in range(0, len(rewards), config.num_samples_per_prompt):
group = rewards[start:start + config.num_samples_per_prompt]
adv = group - group.mean()
if config.scale_rewards == "group":
adv = adv / (group.std(correction=0) + 1e-4)
elif config.scale_rewards == "epoch":
adv = adv / epoch_std
advantages[start:start + config.num_samples_per_prompt] = adv
return latents.detach(), advantages组件 B:为每个 endpoint 构造 个解析加噪 target states
def tile_latents_and_sample_timesteps(latents, embeds, pooled, advantages, scheduler, config, device):
K = config.num_loss_targets_per_sample
if K > 1:
latents = latents.repeat_interleave(K, dim=0)
embeds = embeds.repeat_interleave(K, dim=0)
pooled = pooled.repeat_interleave(K, dim=0)
advantages = advantages.repeat_interleave(K, dim=0)
timesteps = sample_timesteps(
scheduler,
config,
num_samples=len(latents) // K,
num_targets_per_sample=K,
device=device,
)
return latents, embeds, pooled, advantages, timesteps组件 C:RAM loss(released code 版本)
def ram_loss(transformer, latent, prompt_embeds, pooled_embeds, advantages, timestep, config, accelerator):
host = adapter_host(transformer)
sigma = (timestep / 1000).view(-1, 1, 1, 1)
noise = torch.randn_like(latent)
x_t = (1.0 - sigma) * latent + sigma * noise
with torch.no_grad():
with host.disable_adapter():
base_v = model_forward(transformer, x_t, timestep, prompt_embeds, pooled_embeds, accelerator)
host.set_adapter("old")
old_v = model_forward(transformer, x_t, timestep, prompt_embeds, pooled_embeds, accelerator)
host.set_adapter("default")
velocity = model_forward(transformer, x_t, timestep, prompt_embeds, pooled_embeds, accelerator)
reward_direction = noise - latent
scaled_adv = config.reward_multiplier * advantages.view(-1, 1, 1, 1)
target_velocity = base_v + scaled_adv * (reward_direction - old_v)
per_sample = ((velocity - target_velocity.detach()) ** 2).mean(dim=(1, 2, 3))
K = config.num_loss_targets_per_sample
if K > 1:
per_sample = per_sample.view(-1, K).mean(dim=1)
return per_sample.mean()组件 D:三个 LoRA adapters 与 EMA policy
def build_sd3_with_ram_adapters(config, accelerator):
pipe = StableDiffusion3Pipeline.from_pretrained(config.model_name, cache_dir="models")
for module in [pipe.vae, pipe.text_encoder, pipe.text_encoder_2, pipe.text_encoder_3, pipe.transformer]:
module.requires_grad_(False)
lora_config = LoraConfig(
r=config.lora_rank,
lora_alpha=config.lora_alpha,
init_lora_weights="gaussian",
target_modules=[
"attn.add_k_proj", "attn.add_q_proj", "attn.add_v_proj", "attn.to_add_out",
"attn.to_k", "attn.to_out.0", "attn.to_q", "attn.to_v",
],
)
pipe.transformer = get_peft_model(pipe.transformer, lora_config)
pipe.transformer.add_adapter("old", lora_config)
pipe.transformer.add_adapter("evaluation", lora_config)
return pipe
@torch.no_grad()
def update_lagged_params(default_params, old_params, step, ema_decay, warmup_rate):
decay = ema_decay if warmup_rate is None else min(ema_decay, 1.0 - 1.0 / (step * warmup_rate + 1.0))
for src, dst in zip(default_params, old_params):
dst.data.mul_(decay).add_(src.data, alpha=1.0 - decay)3.5 Code-to-paper mapping
Code reference:
main@d92efb9a(2026-05-13) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Algorithm 1 RAM training loop | scripts/training_sd3.py | main, sample_epoch, train_one_epoch |
| Analytic noising | scripts/training_sd3.py | compute_loss (sigma=timestep/1000, sample=(1-sigma)*latent+sigma*noise) |
| RAM target / velocity MSE | scripts/training_sd3.py | compute_loss |
| loss targets per endpoint | scripts/training_sd3.py | main repeat-interleave block, sample_timesteps |
| Group-relative reward normalization | scripts/training_sd3.py | sample_epoch advantage block |
| SD3.5M + LoRA adapters | scripts/training_sd3.py | build_pipeline, LORA_TARGET_MODULES, update_lagged_params |
| GenEval / OCR / PickScore rewards | reward_models/__init__.py, reward_models/gen_eval.py, reward_models/ocr.py | Geneval, OCR, PickScore |
| Repro configs for three tasks | configs/geneval_sd3.yaml, configs/ocr_sd3.yaml, configs/pickscore_sd3.yaml | task-specific reward, CFG, batch, optimizer settings |
| Held-out reward + DrawBench evaluation | scripts/evaluate.py | evaluation entry point loading checkpoint config |
4. Experimental Setup (实验设置)
Datasets / prompts. 论文训练三个 text-to-image reward objectives;released repo 中对应 prompt scale 为:GenEval prompts/geneval/train.txt 50,000 条、test.txt 2,212 条,并有 metadata.jsonl 52,212 条;OCR train.txt 19,652 条、test.txt 1,017 条;PickScore train.txt 25,432 条、test.txt 2,048 条;DrawBench prompts/drawbench/test.txt 999 条用于 independent image-quality metrics。
Baselines. 主表比较 pretrained SD3.5M、Flow-GRPO、AWM、DiffusionNFT、RAM。Flow-GRPO 数字主要来自原论文,HPSv2 由作者用 released checkpoints 重新计算;DiffusionNFT 和 AWM 由作者重训。
Metrics. Training reward 包括 GenEval accuracy(对象、属性、空间关系等 compositional correctness)、OCR accuracy(prompt 中目标文字是否可读)、PickScore(human preference reward)。独立 DrawBench quality metrics 包括 Aesthetic、DeQA、ImageReward、HPSv2、PickScore;这些用于检查 reward hacking / image quality collapse。
Training config(paper/README + released configs 分开记录). 模型是 stabilityai/stable-diffusion-3.5-medium;论文称其为 2.5B-parameter rectified-flow transformer。论文 Appendix D 与 README 报告硬件为 NVIDIA H100 96GB;这个 GPU count 不写在 YAML 里,released code 在 scripts/training_sd3.py::derive_local_sizes 按实际 num_processes / WORLD_SIZE 派生 per-process sizes。每个 parameter update 使用 48 prompts、每 prompt 24 samples、每 image noisy targets,即 effective batch。configs/*.yaml 设置 LoRA rank 、lora_alpha=64、mixed_precision=fp16、resolution=512、scale_rewards=epoch、loss_batch_size=24、sampling_batch_size=48、reward_batch_size=12、lr=3.e-4、weight_decay=1.e-4、beta1=0.9、beta2=0.99、ema_decay=0.9、ema_warmup_rate=0.01。任务差异:GenEval reward_multiplier=100、train/eval steps 20/40、train/eval CFG 1.0/4.5;OCR reward_multiplier=50、steps 40/40、CFG 1.0/4.5;PickScore reward_multiplier=100、steps 40/40、CFG 2.0/4.5。
5. Experimental Results (实验结果)
5.1 主结果:SD3.5M post-training
| Task | Model | # Steps | Training Reward | Aesthetic | DeQA | ImgRwd | HPSv2 | PickScore quality |
|---|---|---|---|---|---|---|---|---|
| Baseline | SD3.5M | 0 | GenEval 0.64 / OCR 0.56 / PickScore 21.79 | 5.41 | 4.08 | 0.82 | 0.28 | 22.40 |
| GenEval | Flow-GRPO | k | 0.95 | 5.25 | 4.01 | 1.03 | 0.27 | 22.37 |
| GenEval | AWM | 300 | 0.83 | 5.14 | 3.75 | 0.67 | 0.24 | 22.04 |
| GenEval | DiffusionNFT | 900 | 0.95 | 4.98 | 4.10 | 0.30 | 0.24 | 21.59 |
| GenEval | RAM | 270 | 0.97 | 5.38 | 4.09 | 1.19 | 0.29 | 22.52 |
| OCR | Flow-GRPO | k | 0.92 | 5.32 | 4.06 | 0.95 | 0.28 | 22.44 |
| OCR | AWM | 200 | 0.97 | 5.01 | 2.83 | -0.85 | 0.18 | 20.56 |
| OCR | DiffusionNFT | 100 | 0.96 | 4.87 | 3.01 | -0.97 | 0.18 | 20.26 |
| OCR | RAM | 60 | 0.97 | 5.23 | 3.90 | 0.44 | 0.26 | 21.83 |
| PickScore | Flow-GRPO | k | 23.31 | 5.92 | 4.22 | 1.28 | 0.32 | 23.53 |
| PickScore | AWM | k | 23.39 | 6.31 | 4.10 | 1.27 | 0.31 | 23.76 |
| PickScore | DiffusionNFT | k | 23.29 | 6.16 | 4.13 | 1.23 | 0.31 | 23.65 |
| PickScore | RAM | 300 | 23.67 | 6.11 | 4.17 | 1.36 | 0.32 | 23.95 |
RAM 在三个 training reward 上均为最高:GenEval 0.97、OCR 0.97、PickScore 23.67。GenEval 和 PickScore 上,RAM 同时保持或提升 DrawBench quality metrics;OCR 上,AWM/DiffusionNFT 虽也能达到很高 OCR reward,但 ImageReward / HPSv2 / PickScore quality 明显崩塌,RAM 的质量下降较小。
5.2 Training efficiency 与 per-step compute

Figure 4 解读:这里比较的是 RAM 与 DiffusionNFT / AWM 两个效率导向 baseline 的 training-reward curves。浅色 companion curves 表示 DiffusionNFT / AWM 在 CFG 下重新评估后 reward 下降,而 RAM post-training 后仍能使用 CFG;这说明 RAM 不只是 step-efficient,还保留了 SD3.5M 推理时常用的 guidance behavior。
| Method | GenEval GPU-hours/step | PickScore GPU-hours/step | OCR GPU-hours/step |
|---|---|---|---|
| Flow-GRPO | 0.701 | 0.431 | 0.498 |
| AWM | 0.653 | 0.329 | 0.370 |
| DiffusionNFT | 0.566 | 0.254 | 0.304 |
| RAM | 0.666 | 0.399 | 0.426 |
Per-step compute 与 baseline 同量级,因此 RAM 的主要优势来自 step-count efficiency:Figure 1 报告在达到 Flow-GRPO peak training reward 时,GenEval 最多约 fewer steps,OCR 约 fewer steps,PickScore 约 fewer steps。
5.3 Ablation / caveats / conclusion
作者没有单列 Limitations section;正文明确体现的 caveats 是:RAM 丢弃 path-cost correction,因此 estimator 是 biased;reward coefficient 需要按任务调节;OCR reward 会推动模型牺牲 aesthetic quality 来换取文字可读性,早停或较小 reward coefficient 可提升 quality 但会降低 OCR reward。Released code 与论文 Appendix D 的 config 差异也意味着复现实验时应以当前 configs/*.yaml 为准并记录 commit。
总体结论:RAM 证明了 diffusion / flow model 的 RL post-training 可以保持 pretraining-like regression 结构。它把 reward alignment 写成 endpoint reward + analytic noising + velocity MSE target,避免 SDE rollout、reward gradient 和 backward adjoint sweep;在 SD3.5M 上,它以同量级 per-step 成本取得更高 reward 和显著更少训练步数。