Manifold-Aware Exploration for Reinforcement Learning in Video Generation
1. Motivation(研究动机)
这篇论文关注的是 RL-based video post-training 里一个非常具体但很关键的问题:为什么同样是 GRPO,到了 video generation 上就明显没有在 LLM 或 image generation 上稳定?作者认为根源不只是 reward noisy,而是 video generation 的解空间更复杂、时序约束更强、rollout 对采样路径更敏感。现有视频 GRPO 方法如 DanceGRPO、FlowGRPO,会把原本 deterministic 的 ODE sampler 转成 SDE sampler 来制造 exploration,但这种 ODE-to-SDE 转换常常采用 Euler-style 的一阶近似,导致在高噪声区间注入了过量噪声,破坏 rollout 质量,使 reward 估计不可靠,最后让 post-training 不稳定。
作者进一步把这个问题提升到几何视角:预训练视频生成模型本身定义了一个“合法视频数据流形” 。如果 RL 探索步子迈得太大、噪声注入不精确,采样轨迹就会偏离流形,表现为 temporal jitter、artifact、motion collapse 甚至 reward hacking。也就是说,问题不只是“探索不够”或“探索太强”,而是探索没有尊重数据流形结构。
因此,这篇论文要解决的问题是:如何在 video GRPO 中设计既能保持 plasticity、又能避免 off-manifold drift 的 exploration 机制。这个问题值得研究,因为如果不能稳定做 RL post-training,text-to-video 模型很难真正通过 reward 学到更强的视觉质量、运动质量和文本对齐能力;而一旦这个环节稳定下来,视频模型的 alignment、可控性和长期时序一致性都可能显著改善。
2. Idea(核心思想)
论文的核心思想可以概括成一句话:把视频生成中的 GRPO 重新理解为“受流形约束的探索问题”,并同时在 micro-level 和 macro-level 上约束 exploration。
具体来说,SAGE-GRPO(Stable Alignment via Exploration)做了两层改进:
- Micro-level:改进 ODE-to-SDE 的噪声注入方式,提出精确的 Manifold-Aware SDE,并用 Gradient Norm Equalizer 解决不同 diffusion timestep 梯度尺度严重失衡的问题。
- Macro-level:提出 Dual Trust Region,把 periodical moving anchor 和 step-wise KL 结合起来,分别对应“位置约束”和“速度约束”,避免长期 drift,同时保留优化弹性。
与现有方法最大的区别在于:以往方法大多只是在既有 GRPO 框架中调 sampler 或调 KL,而这篇论文把流形邻域保持作为主原则,把精确噪声、梯度平衡和 dual KL 统一为一个稳定性设计。它不是简单地“加更多正则”,而是从采样几何和长期优化动态两方面同时控制探索。
3. Method(方法)
3.1 Overall framework
SAGE-GRPO 的整体框架围绕三个耦合模块展开:
- Precise Manifold-Aware SDE:让采样噪声沿着更接近 flow trajectory / video manifold 的方向扩散;
- Temporal Gradient Equalizer:平衡不同 timestep 的梯度尺度,避免低噪声阶段梯度爆炸、高噪声阶段梯度消失;
- Dual Trust Region:通过 moving anchor + step-wise KL 共同控制长期位置漂移和短期更新速度。

Figure 1 解读:图 1 用定性和几何示意说明 SAGE-GRPO 的动机。左侧展示在高噪声区间,Euler-style 一阶离散化会引入额外“紫色噪声能量”,即超出真实积分的离散化误差;作者的方法只保留真实积分区域对应的噪声,从而减少不必要 exploration。右侧展示与 DanceGRPO、FlowGRPO、CPS 的可视化对比,说明更精确的 exploration 能带来更稳定且更对齐的生成结果。
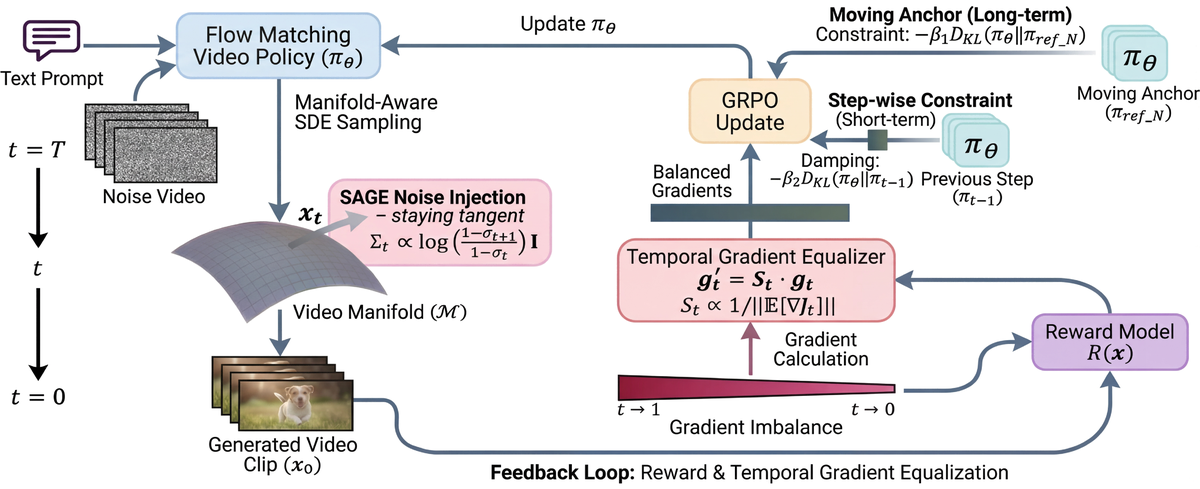
Figure 2 解读:图 2 给出了 SAGE-GRPO 的主流程图。输入 text prompt 后,策略模型通过 manifold-aware GRPO 进行 rollout;一条支路是 SDE Sampling 与 SAGE noise injection,另一条支路是 Temporal Gradient Equalizer 对各 timestep 的梯度进行缩放;生成视频送入 reward model 计算回报;更新阶段同时受 moving anchor 和 step-wise constraint 约束。整张图强调:SAGE-GRPO 不是单点修补,而是从采样、优化到 trust region 的一体化稳定机制。
3.2 Key components
3.2.1 Preliminaries: Flow Matching and GRPO
论文基于 Flow Matching / Rectified Flow 框架。生成过程被写成一个 ODE:
其中 是 neural velocity field。对于 Rectified Flow,采用线性插值路径:
因此有:
GRPO 部分,给定 prompt ,采样一组大小为 的 rollouts,并使用组归一化 advantage 优化 diffusion policy:
这个公式对应论文第 (4) 式,是后续所有改进的基础。
3.2.2 Micro-level exploration: Precise Manifold-Aware SDE
现有方法的关键问题,是将 ODE sampler 转成 SDE sampler 时对噪声标准差使用了一阶近似。论文认为这会系统性高估 exploration noise,尤其在高噪声区间更严重。因此作者对 marginal-preserving SDE 的 diffusion coefficient 进行精确积分。
对于
在区间 上积分方差,得到:
于是噪声标准差为:
这就是论文第 (5)(6) 式的核心,也是 Table 1 中相较 DanceGRPO / FlowGRPO 的主要区别。这里的 logarithmic curvature correction 捕捉了信号系数 的几何收缩,而这正是一阶近似忽略的部分。
随后,作者用 Euler-Maruyama 离散化得到更新式:
其中 ,且 score 近似为
这里很关键的一点是:由于 已经是区间积分后的 variance,所以 stochastic term 直接用 ,不再额外乘 。同时, 是 Itô correction,用于保持与 Rectified Flow marginal 一致。

Figure 3 解读:图 3 以几何方式解释不同噪声注入策略。红色的 conventional linear SDE 会形成更大的球形 exploration 区域,并且更容易偏离数据流形;蓝色的 manifold-aware SDE 通过对数修正项,把探索压缩到更接近 flow trajectory 的椭球邻域中。图的重点不只是“噪声更小”,而是“噪声方向和尺度都更贴近合法视频流形”。
3.2.3 Temporal Gradient Equalizer
即使噪声注入更精确,diffusion 过程仍存在跨 timestep 的 signal-to-noise imbalance。论文指出,对于 Gaussian transition
其梯度范数满足:
这意味着:
- 高噪声阶段()梯度趋于消失;
- 低噪声阶段()梯度趋于爆炸。
训练因此会偏向少数 timestep,造成优化不稳定。
作者通过从 SDE 参数估计每个 timestep 的梯度尺度 ,定义 robust normalization:
并用它缩放各 timestep 的梯度。直观上,这一步是在做 temporal balancing,让结构性更新和纹理性更新都能有效贡献。这里的梯度图与 reward curve 图表明,不用 equalizer 时 reward 容易抖动或平台化,而使用后 reward 曲线更平滑、梯度尺度变化也从一个数量级以上收缩到常数量级。

Figure 4 解读:图 4 展示不同噪声水平下的经验梯度范数。蓝线是观察值,红线是理论关系 。图中清楚显示高噪声区域梯度过小、低噪声区域梯度过大,这正是为什么单纯改 sampler 还不够,必须再加 temporal gradient equalization。
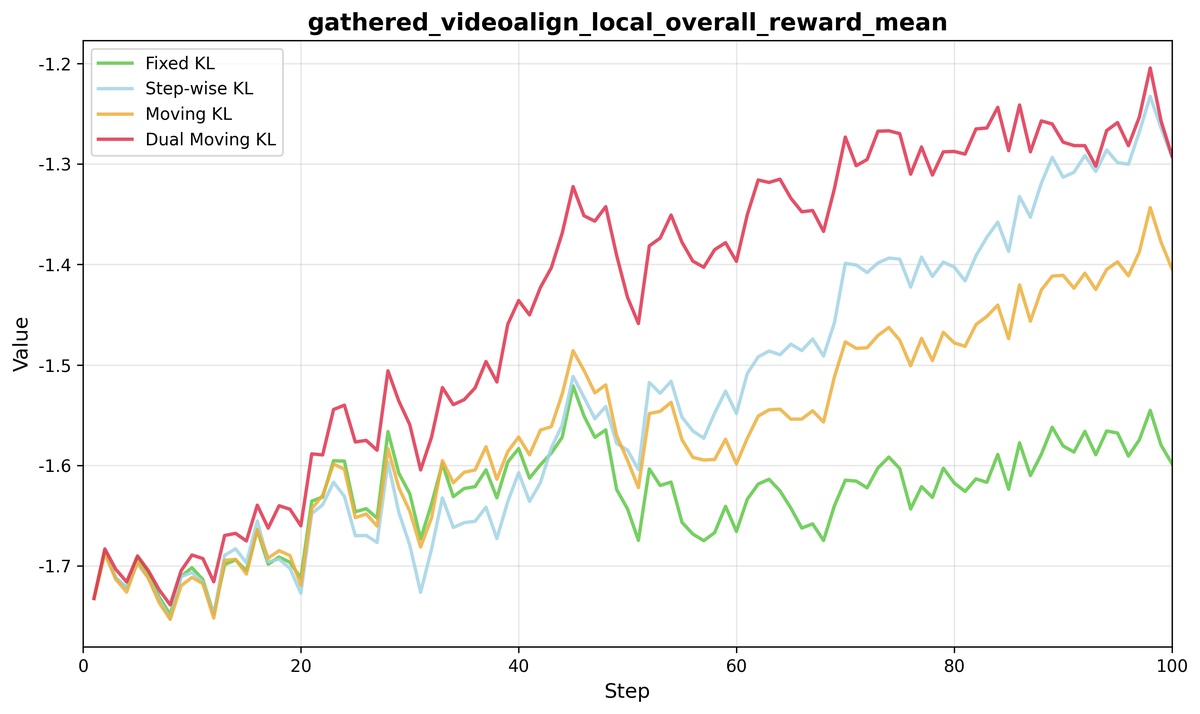
Figure 5 解读:这张图对应 temporal gradient equalizer 的 reward curve ablation。横向比较不同 SDE 公式和 CPS,可以看到“不做 balancing”时 reward 曲线更容易震荡、停滞甚至塌陷;加入 balancing 后,尤其在作者方法上,整体 reward 提升更平稳。这说明 equalizer 的价值不只是理论上的梯度归一,而是直接体现在 RL 训练动态的稳定性上。
3.2.4 GRPO with composite reward
论文将每个 rollout 的回报写成 composite reward ,并采用 group-normalized advantage:
其中
实验中 reward oracle 使用 VideoAlign,评估三个维度:Visual Quality (VQ)、Motion Quality (MQ)、Text Alignment (TA),整体奖励为
这部分本身不是新算法,但它和后面的 KL 策略耦合得很紧,因为如果 exploration 太 aggressive,VideoAlign 的 reward 估计就会不可靠。
3.2.5 Macro-level exploration: Dual Trust Region Optimization
Micro-level 解决的是“单步采样与梯度”的问题,而 Macro-level 解决的是“多步优化的长期漂移”问题。作者把 KL divergence 解释成一种 dynamic anchoring mechanism。
对 Gaussian policy,当前策略与参考策略之间的 KL 为:
作者依次分析了三种约束:
- Fixed KL:始终锚定到初始预训练模型 。这能强约束不偏离初始分布,但长期来看太保守,阻止策略逼近真正的最优策略 。
- Step-wise KL:锚定到上一步策略 。这相当于“速度约束”,限制单步更新量:
但它只管局部速度,不控制累计位移,因此可能慢慢 drift 出流形。
- Periodical Moving KL:每隔 个优化 step,把参考模型更新成最近 checkpoint,即 。这相当于“位置控制”,让 trust region 周期性移动,既允许局部探索,又不会与合法分布脱节:
最终,论文把 position control 与 velocity control 合并成 Dual KL:
其中第一个项防止长期 drift,第二个项抑制瞬时过激更新。论文还给出 step-wise KL 的 rollout-phase 近似:
这是论文第 (15) 式,与 rollout-phase log-probability difference 的常见实现形式一致,也与仓库暴露的 kl_compute_mode="rollout_phase" 参数命名相吻合。
3.2.6 Repository-informed pseudocode
我按要求搜索了代码仓库,并找到公开实现:https://github.com/Tencent-Hunyuan/SAGE-GRPO。结合 README、根目录入口文件、公开目录结构以及进一步代码读取结果,公开仓库很强地表明以下文件承担这些职责:
post_train.py:post-training 主入口,包含sde_type、reward、KL、moving reference、dual KL、grad balancing 等核心参数;generate.py:生成与采样入口;scripts/post_train/train_grpo.sh、run_post_train.sh:训练启动脚本;hyvideo/pipelines/hunyuan_video_grpo_pipeline.py:GRPO rollout pipeline,返回视频、各 timestep latent 与每步 log-prob;hyvideo/schedulers/scheduling_flow_match_discrete.py:sage_grpo/dance_grpo/flow_grpo/cps的 SDE step 与 log-prob 计算;hyvideo/utils/grpo_utils.py:online rollout、reward 聚合、group-normalized advantage、reference statistics 预计算;hyvideo/commons/grpo_commons.py:group normalize、并行分组、Adaptive KL controller;hyvideo/models/reward_models/rewards.py:VideoAlign reward 入口与多子指标加权;download_weights.sh、checkpoints-download.md:checkpoint / reward model 准备流程。
除根目录入口文件外,上述子模块级对应关系主要依据公开仓库命名、README、公开代码读取结果和论文方法结构综合判断;这里不声称已完成对整个仓库所有子文件的逐文件逐函数核验。下面的伪代码属于基于公开仓库代码线索与论文公式重建的近实现语义版本,并不是对官方源码的逐行转录。
(a) GRPO rollout with selectable SDE type
import torch
def sample_rollouts_with_sde(model, prompts, latents, sigmas, sde_type="sage_grpo", eta=1.0):
trajectories = []
x_t = latents
for t in range(len(sigmas) - 1):
sigma_t = sigmas[t]
sigma_next = sigmas[t + 1]
dt = sigma_t - sigma_next
v_theta, x0_hat = model.predict_velocity_and_x0(x_t, sigma_t, prompts)
score = -(x_t - x0_hat) / (sigma_t ** 2 + 1e-8)
if sde_type == "sage_grpo":
sigma_var = eta ** 2 * (
-(sigma_t - sigma_next)
+ torch.log((1 - sigma_next) / (1 - sigma_t))
)
elif sde_type == "dance_grpo":
sigma_var = eta ** 2 * (sigma_t - sigma_next)
elif sde_type == "flow_grpo":
sigma_var = eta ** 2 * (sigma_t / (1 - sigma_t)) * (sigma_t - sigma_next)
else:
sigma_var = eta ** 2 * (sigma_t - sigma_next)
sigma_std = torch.sqrt(torch.clamp(sigma_var, min=1e-8))
noise = torch.randn_like(x_t)
x_t = x_t + v_theta * dt + 0.5 * sigma_var * score + sigma_std * noise
trajectories.append(x_t)
return trajectories(b) Temporal Gradient Equalizer
import torch
def apply_temporal_gradient_equalizer(per_timestep_grads, estimated_norms, eps=1e-6):
median_norm = torch.median(estimated_norms)
balanced_grads = []
scales = []
for g_t, n_t in zip(per_timestep_grads, estimated_norms):
scale_t = median_norm / (n_t + eps)
balanced_grads.append(scale_t * g_t)
scales.append(scale_t)
return balanced_grads, scales(c) Moving-anchor KL update
@torch.no_grad()
def maybe_update_ref_model_for_kl(model, ref_model, update_steps, use_moving_kl=True, update_ref_model_step=10):
if not use_moving_kl:
return ref_model
if update_ref_model_step <= 0:
return ref_model
if update_steps <= 0 or (update_steps % update_ref_model_step) != 0:
return ref_model
ref_model.load_state_dict(model.state_dict(), strict=True)
ref_model.eval()
return ref_model(d) Dual KL objective
import torch
def compute_dual_kl_loss(current_logprob, prev_logprob, current_mu, moving_ref_mu, sigma_t,
use_dual_kl=True, beta_pos=1.0, beta_vel=0.1):
pos_kl = ((current_mu - moving_ref_mu) ** 2 / (2 * (sigma_t ** 2 + 1e-8))).mean()
vel_kl = (prev_logprob - current_logprob).mean()
if use_dual_kl:
return beta_pos * pos_kl + beta_vel * vel_kl, pos_kl, vel_kl
return pos_kl, pos_kl, vel_kl(e) Post-training step with composite reward
import torch
def grpo_train_step(batch, model, ref_model, reward_fn, optimizer, cfg):
rollouts = sample_rollouts_with_sde(
model=model,
prompts=batch["prompts"],
latents=batch["latents"],
sigmas=batch["sigmas"],
sde_type=cfg.sde_type,
eta=cfg.sde_eta,
)
videos = model.decode_rollouts(rollouts)
reward_dict, _ = reward_fn(videos, batch["prompts"])
rewards = (
cfg.w_vq * reward_dict["visual_quality"]
+ cfg.w_mq * reward_dict["motion_quality"]
+ cfg.w_ta * reward_dict["text_alignment"]
)
adv = (rewards - rewards.mean()) / (rewards.std() + 1e-6)
current_logprob, prev_logprob, current_mu = model.compute_policy_stats(batch, rollouts)
moving_ref_mu = ref_model.compute_reference_mu(batch, rollouts)
policy_loss = -(adv.detach() * current_logprob).mean()
kl_loss, pos_kl, vel_kl = compute_dual_kl_loss(
current_logprob=current_logprob,
prev_logprob=prev_logprob,
current_mu=current_mu,
moving_ref_mu=moving_ref_mu,
sigma_t=batch["sigma_t"],
use_dual_kl=cfg.use_dual_kl,
beta_pos=cfg.dual_kl_moving_weight,
beta_vel=cfg.dual_kl_step_weight,
)
loss = policy_loss + cfg.kl_coef * kl_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
return {
"loss": loss.item(),
"policy_loss": policy_loss.item(),
"kl_loss": kl_loss.item(),
"reward_mean": rewards.mean().item(),
"pos_kl": pos_kl.item(),
"vel_kl": vel_kl.item(),
}3.3 Repository-informed code-to-paper mapping (partially verified)
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Post-training 主入口与核心超参 | post_train.py | config dataclass / sde_type, use_moving_KL, use_dual_kl, dual_kl_moving_weight, dual_kl_step_weight |
| 周期性 moving anchor 更新 | post_train.py | maybe_update_ref_model_for_kl(...) |
| Reward model 接入 | hyvideo/models/reward_models/rewards.py, post_train.py | get_reward_fn(...), videoalign_local_score(...) |
| 生成/采样入口 | generate.py, hyvideo/pipelines/hunyuan_video_grpo_pipeline.py | generation / rollout pipeline |
| 训练脚本 | run_post_train.sh, scripts/post_train/train_grpo.sh | torchrun ... post_train.py |
| Reward 实现 | hyvideo/models/reward_models/rewards.py | multi_video_score(...), videoalign_local_score(...) |
| 权重准备与 checkpoint 说明 | download_weights.sh, checkpoints-download.md | reward/base model setup |
4. Experimental Setup(实验设置)
4.1 Datasets / model / reward
- 基础模型:HunyuanVideo 1.5。
- reward oracle:VideoAlign。
- 评测维度:Visual Quality (VQ)、Motion Quality (MQ)、Text Alignment (TA),以及视觉指标 CLIPScore、PickScore。
- 对比方法:DanceGRPO、FlowGRPO、CPS,以及 HunyuanVideo 1.5 原始模型。
4.2 Training config
按论文正文报告的主要实现设置如下:
- per-GPU batch size: 2
- gradient accumulation steps: 4
- effective batch size: 8
- frames per video: 81
- GRPO update frequency: every 20 sampling steps along the diffusion trajectory
- KL weight schedule:
这些数值主要依据论文正文记录,而不是由当前公开仓库页面逐项直接核实。实现层面,公开仓库还暴露出一组与论文强相关的参数:
sde_type:sage_grpo,dance_grpo,flow_grpo,cpsuse_grad_balancing=Trueenable_timestep_permutation=Trueuse_moving_KL=Trueupdate_ref_model_step=10use_dual_kl=Truedual_kl_moving_weight=1.0dual_kl_step_weight=0.1kl_compute_mode="rollout_phase"reward_modelreward_weightsreference_mode_offload=True
4.3 Reward settings
论文主要报告两种 reward setting:
- Setting A: Averaged Rewards
- Setting B: Alignment-Focused
作者强调所有方法都使用冻结的原始 VideoAlign 作为 evaluator,不做 reward-model fine-tuning,以保证比较公平。
5. Experimental Results(实验结果)
5.1 Main benchmark results
论文 Table 2 给出的关键结果如下。
Setting A: Averaged Rewards
| Method | Config | VQ | MQ | TA | CLIPScore | PickScore | Overall |
|---|---|---|---|---|---|---|---|
| HunyuanVideo 1.5 | Original | 0.0654 | -0.7539 | -0.5870 | 1.4063 | 0.5409 | 0.7397 |
| DanceGRPO | w/o KL | 0.2768 | -0.7589 | -0.3852 | 1.4209 | 0.5386 | 0.7378 |
| DanceGRPO | w/ Fixed KL | 0.0979 | -0.8077 | -0.5091 | 1.4147 | 0.5403 | 0.7355 |
| FlowGRPO | w/o KL | 0.2733 | -0.7151 | -0.5286 | 1.5170 | 0.5443 | 0.7394 |
| FlowGRPO | w/ Fixed KL | 0.1880 | -0.6771 | -0.5912 | 1.4563 | 0.5431 | 0.7407 |
| CPS | w/o KL | 0.6343 | -0.4855 | -0.4021 | 1.5219 | 0.5479 | 0.7412 |
| CPS | w/ Fixed KL | 0.0928 | -0.7156 | -0.5825 | 1.3908 | 0.5479 | 0.7369 |
| SAGE-GRPO | w/o KL | 0.4859 | -0.6104 | -0.4141 | 1.5104 | 0.5423 | 0.7360 |
| SAGE-GRPO | w/ Fixed KL | 0.2244 | -0.7438 | -0.5320 | 1.5001 | 0.5446 | 0.7382 |
| SAGE-GRPO | w/ Dual Mov KL | 0.2173 | -0.7881 | -0.4249 | 1.4303 | 0.5430 | 0.7452 |
Setting B: Alignment-Focused
| Method | Config | VQ | MQ | TA | CLIPScore | PickScore | Overall |
|---|---|---|---|---|---|---|---|
| DanceGRPO | w/o KL | -0.2172 | -0.8854 | -0.6218 | 1.2901 | 0.5439 | 0.7352 |
| DanceGRPO | w/ Fixed KL | 0.1290 | -0.7739 | -0.5083 | 1.4112 | 0.5452 | 0.7276 |
| FlowGRPO | w/o KL | 0.4773 | -0.5671 | -0.4731 | 1.5175 | 0.5403 | 0.7349 |
| FlowGRPO | w/ Fixed KL | 0.2103 | -0.6654 | -0.5506 | 1.4263 | 0.5427 | 0.7408 |
| CPS | w/o KL | 0.3694 | -0.6650 | -0.5325 | 1.5669 | 0.5479 | 0.7311 |
| CPS | w/ Fixed KL | 0.3705 | -0.6121 | -0.4787 | 1.4613 | 0.5458 | 0.7364 |
| SAGE-GRPO | w/o KL | -0.1222 | -0.8720 | -0.6046 | 1.3544 | 0.5404 | 0.7357 |
| SAGE-GRPO | w/ Fixed KL | 0.2857 | -0.7062 | -0.4425 | 1.4344 | 0.5414 | 0.7377 |
| SAGE-GRPO | w/ Dual Mov KL | 0.8066 | -0.4765 | -0.2384 | 1.5216 | 0.5484 | 0.7420 |
最核心的结论有三点:
- Setting B 下的 SAGE-GRPO + Dual Moving KL 是最强组合。它在 Overall、VQ、MQ、CLIPScore 上都取得最佳结果,同时 TA 也接近最优,说明“强调 alignment 的 reward + dual trust region”比平均权重设定更稳。
- 仅靠 Fixed KL 不够。对很多基线来说,Fixed KL 往往提升部分视觉指标,但 reward behavior 反而变差;论文把这解释为 reward hacking 与过强保守约束的共同结果。
- Dual Moving KL 比单纯 no-KL / fixed-KL 更平衡。SAGE-GRPO 在无 KL 时能探索,但不稳定;有 Fixed KL 时太保守;Dual Moving KL 同时保留 plasticity 和 stability。
5.2 Qualitative analysis and user study

Figure 6 解读:图 6 展示了作者方法与基线在三个 prompt 上的定性对比。可以看到作者方法在长程运动、复杂遮挡、光照变化以及 object interaction 上更稳定,尤其能减少 temporal jitter,同时更准确匹配 prompt 语义。它补充说明了 Table 2 中 reward 与视觉指标提升背后的真实视觉效果。
论文还做了 user study:
- 29 位评估者
- 32 个 prompts
- 在 iter 100、sampling step 40、Setting B 下比较
Table 3 中,SAGE-GRPO 对各 baseline 的胜率为:
| SAGE-GRPO vs. | Visual Quality | Motion Quality | Semantic Alignment |
|---|---|---|---|
| DanceGRPO | 85.9% | 75.8% | 79.2% |
| FlowGRPO | 83.8% | 79.2% | 71.9% |
| CPS | 80.2% | 70.8% | 67.9% |
这说明自动指标并不是“自嗨”,人类偏好也明显支持作者方法,尤其在 Motion Quality 上优势突出。
5.3 Ablation studies
Temporal Gradient Equalizer
论文在 Figure 3 中比较了不同 SDE 配方和 CPS 在“是否使用 per-timestep balancing”下的训练动态。结论是:
- 不使用 balancing 时,reward 曲线更容易震荡、停滞;
- 使用 balancing 后,曲线更平滑,改进更持续;
- 说明梯度不平衡确实是 RL for video generation 的重要稳定性瓶颈。
KL strategy ablation
论文 Figure 8 比较四种 KL 策略的 mean reward 与 std:
- Dual Moving KL 在收敛速度和最终 reward 上都最好;
- aggressive 的 step-wise update 容易 collapse;
- Moving KL 前期探索快,但后期 exploration 会衰减;
- Dual Moving KL 能在更长时间里维持高且稳定的 exploration。
KL weight sensitivity
论文 Figure 7 比较三种 KL schedule:
- fixed
- two-stage
- milder
结果显示 two-stage 在 VQ、MQ、TA 上都更稳更强,支持“先松后紧”的 trust-region 设计,即先给 exploration 足够空间,再逐步收紧约束。
5.4 Limitations
论文虽然结果很强,但也有几个局限:
- 方法目前主要验证在 HunyuanVideo 1.5 + VideoAlign 组合上,跨 backbone、跨 reward model 的泛化尚未充分证明。
- 它本质上仍依赖 reward model 的质量;虽然作者试图用 alignment-focused setting 减少 reward hacking,但这个问题并没有被彻底解决。
- user study 规模仍然有限(29 evaluators, 32 prompts),足以说明趋势,但还不足以完全覆盖开放域 video generation 的全部场景。
- Dual Trust Region 引入了更多超参和工程复杂度,例如
update_ref_model_step、dual KL 权重、KL schedule 等,训练成本和调参成本都更高。
5.5 Overall conclusion
总体来看,这篇论文的贡献非常清晰:它不是简单提出“一个更强的 video GRPO baseline”,而是把 探索稳定性 作为视频 RL post-training 的核心矛盾,提出了一套从采样几何、梯度平衡到长期 trust region 的系统解法。Precise Manifold-Aware SDE 解决“探索噪声不准”,Gradient Norm Equalizer 解决“时间步梯度失衡”,Dual Trust Region 解决“长期 drift vs plasticity”矛盾。这三者组合起来,构成了 SAGE-GRPO 的真正价值。
如果把这篇论文放在 RL for Visual Generation 的脉络里看,它的重要性在于:它明确指出 video RL 的难点不只是 reward design,而是 exploration must stay near the video manifold。这为后续所有视频生成 RL 方法提供了一个很强的设计原则。