ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
Authors: Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong Affiliations: Tsinghua University, Zhipu AI, Beijing University of Posts and Telecommunications arXiv: 2304.05977 Project Page: huggingface.co/THUDM/ImageReward GitHub: zai-org/ImageReward Venue: NeurIPS 2023
1. Motivation (研究动机)
1.1 为什么 text-to-image 需要 human preference reward model
text-to-image 模型虽然已经能生成高保真图像,但和真实用户偏好之间仍然存在系统性偏差。论文在引言里把这类偏差概括为四类:
- Text-image Alignment:数字、属性、对象关系、语义约束经常对不齐。
- Body Problem:人物/动物肢体容易畸形、重复或缺失。
- Human Aesthetic:模型生成结果和主流审美并不总是匹配。
- Toxicity and Biases:会出现有害、歧视、暴力或引发不适的内容。
这些问题的根源在于:预训练数据分布 noisy,且与真实用户 prompt 分布并不一致。仅靠改架构或扩充预训练数据,难以直接把模型往“更符合人类偏好”的方向推。
1.2 现有自动评价指标为什么不够
论文强调,现有主流自动指标并不适合作为 text-to-image 的“人类偏好代理”:
- CLIP / BLIP / Aesthetic 更像相关性或审美 proxy,不等价于整体 human preference。
- FID 依赖和真实图像分布的统计距离,忽略了 prompt-conditioned human preference;而且更适合数据集层面平均评估,不适合单样本筛选。
- 对真实用户使用场景而言,模型往往是 zero-shot 使用,MS-COCO/FID 这类评估设置和真实应用存在偏差。
因此论文要解决两个问题:
- 能否训练一个真正对齐 human preference 的通用 reward model?
- 能否把 reward model 不仅用于后验筛选,还直接用于优化 diffusion model?
1.3 这篇论文要做什么
论文提出两部分贡献:
- ImageReward:第一个通用 text-to-image human preference reward model。
- ReFL (Reward Feedback Learning):把 ImageReward 作为反馈信号,直接优化 text-to-image diffusion model。
核心价值在于:把“人更喜欢什么图”从模糊直觉,变成可训练、可评估、可反向传播的标量信号。
2. Idea (核心思想)
论文的核心思想可以概括成两句话:
- 先学一个对 prompt-image pair 打分的偏好模型:这个模型不是判断图像是否“像真图”,而是判断“给定 prompt,人会不会更喜欢这张图”。
- 再把这个偏好模型作为 reward:不仅用于从多张候选图中挑图,也用于在 diffusion 生成过程中给梯度反馈,直接改善生成器。
与已有方法相比,它的本质差异有两点:
- 相比 CLIP / Aesthetic / BLIP,这篇工作直接用专家排序数据学习 human preference,而不是依赖自监督 proxy。
- 相比 Dataset Filtering、Reward Weighted、RAFT 这类通过筛数据或改样本权重来间接优化模型的方法,ReFL 是直接把 reward 回传给 diffusion model,更接近视觉领域的 RLHF 方向。
更具体地说,ImageReward 做了三件事:
- 设计了一套针对 text-to-image 偏好的 annotation pipeline;
- 用 BLIP backbone + cross-attention + MLP 学习 pairwise preference;
- 把 learned reward 用作 metric 和 training signal。
而 ReFL 的关键 insight 是:在 diffusion 的后期 denoising steps,图像最终质量已经足够可辨认,这使得 reward model 可以在这些 later denoising steps 上提供有效反馈,从而绕开“diffusion generation 没有完整 generation likelihood”这一障碍。
3. Method (方法)
3.1 Overall framework
Figure 1 解读:这张图给出了整篇论文的总览。上半部分是 ImageReward 的构建流程:从真实用户 prompt 和多模型生成图像出发,经由 prompt annotation、text-image rating、image ranking,得到偏好训练数据,再训练 reward model。下半部分是 ReFL:把训练好的 ImageReward 当作 scorer,在 diffusion model 的后期 denoising step 上对当前预测图像打分,并把 reward 作为优化信号回传给生成器。也就是说,ImageReward 既是评估器,也是训练器。
整个方法可以拆成两个模块:
- ImageReward:从 human ranking 数据学一个 reward function 。
- ReFL:把 施加到 latent diffusion model 上,直接优化生成过程。
3.2 Annotation pipeline
论文的数据构建不是简单众包打分,而是一整套面向偏好学习的 annotation pipeline。
- Prompt 来自 DiffusionDB。
- 为了保证 prompt 多样性,作者先做 graph-based prompt selection,最终选出 10,000 个候选 prompts。
- 每个 prompt 配置 4 到 9 张候选图像,总共得到 177,304 个候选 pairs 用于标注。
- 经过约 2 个月标注,最后得到 8,878 个 prompts 和 136,892 个有效 comparison pairs。
标注流程分 3 个阶段:
- Prompt Annotation:标记 prompt 的类别和问题属性。
- Text-Image Rating:从
alignment、fidelity、harmlessness三个维度给图像打分。 - Image Ranking:综合三维评分与整体偏好,给同一 prompt 下的多张图排序。
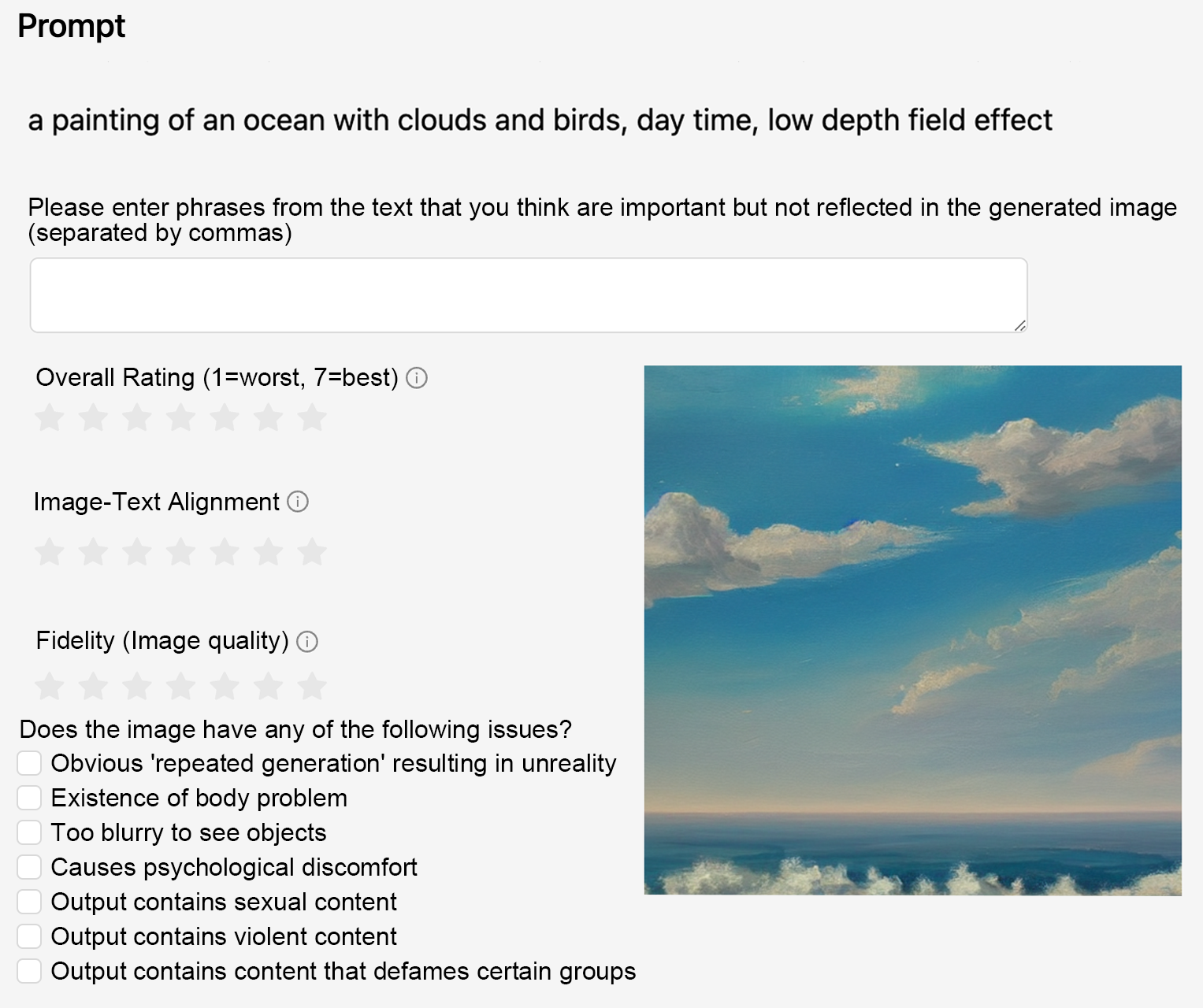
Figure 2 解读:这是 text-image rating 界面。标注员不是直接“凭感觉选最好”,而是先对图像进行维度化评估,例如图文一致性、细节保真度以及是否包含有害内容。这样做的好处是把人类偏好的来源拆开,有助于统一标注标准,并为后续 ranking 提供解释性基础。

Figure 3 解读:这是 image ranking 界面。标注员需要在同一 prompt 下对多张生成图做整体偏好排序。与简单二分类相比,ranking 更适合导出大量 pairwise preference data,因为对 张图排序后可以得到最多 个比较对。ImageReward 最终正是利用这些 better/worse pair 做 reward learning。
3.3 ImageReward reward model
论文把 reward learning 形式化为 pairwise ranking。对同一个 prompt ,若 比 更好,则优化目标是:
其中 是 reward model 对 prompt-image pair 的标量偏好分数。
论文在架构上使用 BLIP 作为 backbone,理由是它在 prelim experiments 中优于 CLIP。具体做法是:
- 图像经 BLIP visual encoder 编码;
- 文本经 BLIP text encoder 编码,并通过 cross-attention 接入图像特征;
- 取 text encoder 的
[CLS]表征; - 送入 MLP 输出单一 reward scalar。
从开源代码看,推理版实现位于 ImageReward/ImageReward.py,有几个关键实现细节:
- 输入图像统一 resize + center crop 到 224;
- tokenizer 最大长度是 35;
- MLP 结构是
768 -> 1024 -> 128 -> 64 -> 16 -> 1,带 dropout; - 最终 reward 还会做一次标准化:
其中代码中固定了 mean = 0.1671736283 和 std = 1.0333394966。
伪代码 1:ImageReward 推理/排序(基于开源实现)
# from ImageReward/ImageReward.py
def inference_rank(prompt, image_list):
text = blip.tokenizer(prompt, max_length=35)
features = []
for image in image_list:
image_tensor = preprocess_224(image)
image_embeds = blip.visual_encoder(image_tensor)
image_atts = ones_like(image_embeds)
text_output = blip.text_encoder(
text.input_ids,
attention_mask=text.attention_mask,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
)
cls_feature = text_output.last_hidden_state[:, 0, :]
features.append(cls_feature)
features = concat(features)
rewards = mlp(features)
rewards = (rewards - mean) / std
ranking = argsort_descending(rewards)
return ranking, rewards伪代码 2:ImageReward pairwise 训练(基于开源实现)
# from train/src/rank_pair_dataset.py + train/src/ImageReward.py + train/src/train.py
def build_pair_dataset(ranked_samples):
pairs = []
for sample in ranked_samples:
prompt = sample["prompt"]
images = load_all_images(sample["generations"])
ranking = sample["ranking"]
for i in range(len(ranking)):
for j in range(i + 1, len(ranking)):
if ranking[i] == ranking[j]:
continue
better, worse = select_better_worse(images[i], images[j], ranking[i], ranking[j])
pairs.append((prompt, better, worse))
return pairs
def reward_model_forward(prompt, better_img, worse_img):
emb_better = encode_with_blip_cross_attention(prompt, better_img)
emb_worse = encode_with_blip_cross_attention(prompt, worse_img)
reward_better = mlp(emb_better)
reward_worse = mlp(emb_worse)
return concat([reward_better, reward_worse], dim=1)
def pairwise_loss(reward_pair):
# better image should be class 0
target = zeros(batch_size, dtype=long)
return cross_entropy(reward_pair, target)3.4 ImageReward 作为自动 metric
论文不是把 ImageReward 只当成一个 selector,而是进一步论证它可作为 text-to-image 的自动评估指标。
做法是:
- 在 6 个高分辨率 text-to-image 模型(CogView 2, Versatile Diffusion, SD 1.4, SD 2.1-base, DALL-E 2, Openjourney)上做人类排序;
- 同时比较
ImageReward,CLIP,zero-shot FID与 human ranking 的一致性。
结果显示:
- 在 real-user prompts 上,ImageReward 的模型排序与 human ranking 完全一致;
- 与 human ranking 的 Spearman 相关性达到 1.00;
- CLIP 只有 0.60;
- zero-shot FID 只有 0.09。
这说明它不仅能做 sample-level selection,也能做 model-level comparison。
3.5 ReFL: Reward Feedback Learning
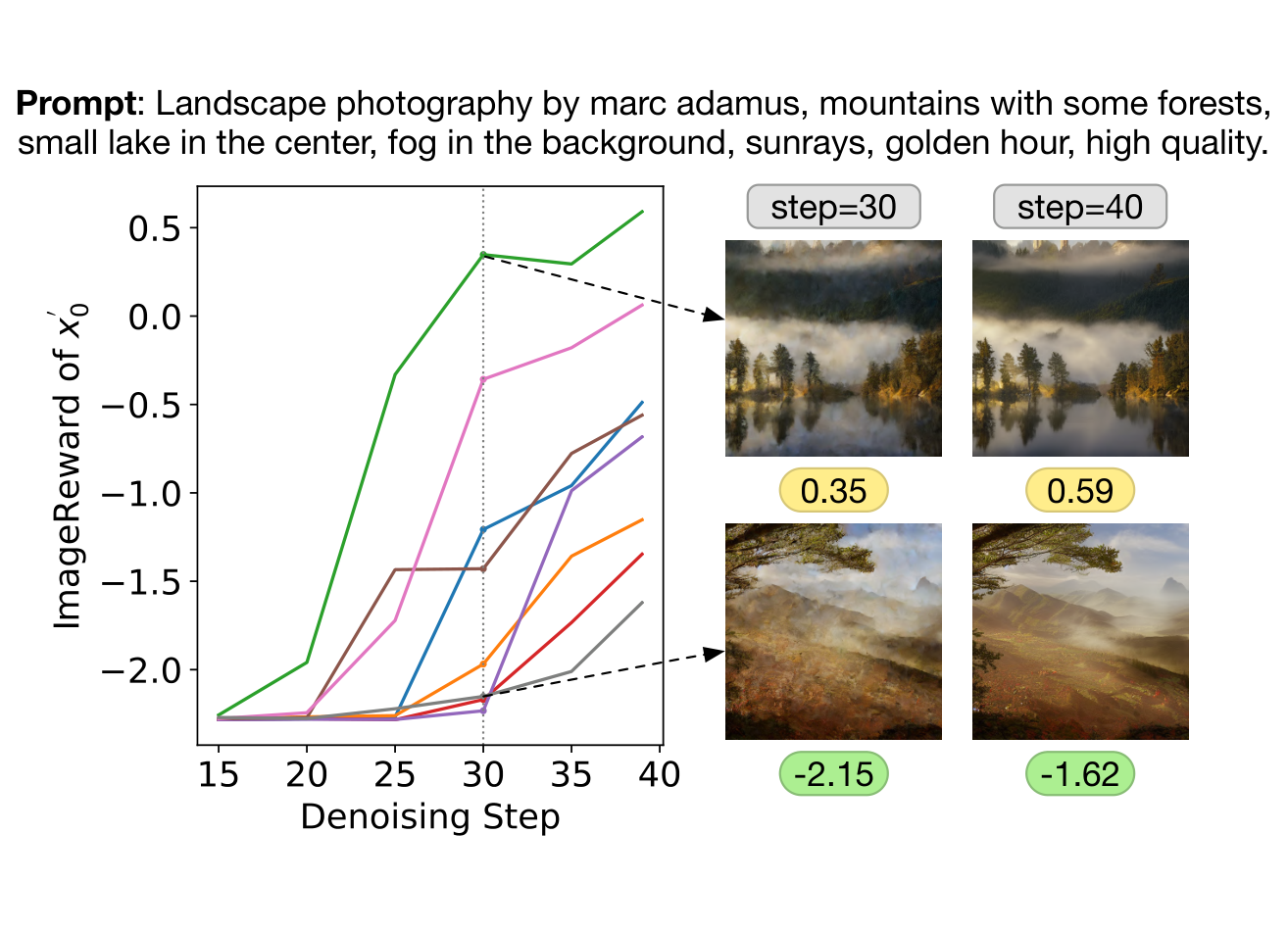
Figure 4 解读:这张图展示了 ReFL 的关键洞察:在 40-step denoising 中,越靠后的 step,ImageReward 对不同 generation seed 的质量区分越明显。论文据此认为,不必等到完整生成结束才给 reward,只要在 sufficiently late 的 denoising steps 上,reward 就已经足够可靠,可以作为训练反馈。
ReFL 要解决的问题是:diffusion model 不像 language model 那样有整句 generation likelihood,不能直接照搬 NLP 里的 PPO/RLHF。论文的方案是:
- 从随机选择的后期 denoising step 开始保留梯度;
- 将当前 step 预测出的 decode 成图像;
- 用 ImageReward 评分;
- 把 reward 映射成 loss,对 diffusion model 反传。
论文写出的最终目标包括 reward loss 和 pre-training regularization:
其中:
- 是 ImageReward;
- 是 diffusion model 的生成结果;
- 是 reward-to-loss map;
- 是原始 diffusion pretraining loss,用来 regularize 训练。
但需要注意:开源代码和论文公式并不完全一致。在当前 GitHub release 的 ImageReward/ReFL.py 中,最核心的实现是:
mid_timestep = random.randint(30, 39),即在 40-step scheduler 的后 10 步中采样;- 前面若干 denoising step 用
torch.no_grad(); - 只在选中的一个后期 step 上保留梯度;
- decode
pred_original_sample得到图像; - 用
reward_model.score_gard(...)计算 reward; - 实际 loss 写成:
即代码里能明确看到:
loss = F.relu(-rewards + 2)
loss = loss.mean() * args.grad_scale所以更准确地说:论文中的 ReFL 是“reward loss + regularization”的完整方法,而公开代码更像一个简化版的 later-step reward backprop 实现。这一点在读论文和复现时必须区分。
伪代码 3:ReFL 训练(基于开源实现)
# from ImageReward/ReFL.py
def refl_train_step(batch_prompts):
encoder_hidden_states = text_encoder(batch_prompts)
latents = sample_gaussian_noise(shape=(B, 4, 64, 64))
noise_scheduler.set_timesteps(40)
timesteps = noise_scheduler.timesteps
mid_timestep = random.randint(30, 39)
# no-grad denoising before the selected late step
for t in timesteps[:mid_timestep]:
with no_grad():
latent_input = noise_scheduler.scale_model_input(latents, t)
noise_pred = unet(latent_input, t, encoder_hidden_states).sample
latents = noise_scheduler.step(noise_pred, t, latents).prev_sample
# keep gradient only at the selected late step
latent_input = noise_scheduler.scale_model_input(latents, timesteps[mid_timestep])
noise_pred = unet(latent_input, timesteps[mid_timestep], encoder_hidden_states).sample
pred_x0 = noise_scheduler.step(noise_pred, timesteps[mid_timestep], latents).pred_original_sample
image = vae.decode(pred_x0 / vae.scaling_factor).sample
image = clamp((image / 2 + 0.5), 0, 1)
image = resize_center_crop_normalize_for_imagereward(image)
rewards = reward_model.score_gard(prompt_ids, prompt_attention_mask, image)
loss = mean(relu(2 - rewards)) * grad_scale
loss.backward()
optimizer.step()
optimizer.zero_grad()3.6 Code-to-paper mapping table
| Paper Concept | Source File | Key Class / Function |
|---|---|---|
| ImageReward 推理接口 | ImageReward/ImageReward.py | ImageReward, score, inference_rank |
| reward head / 标量打分 | ImageReward/ImageReward.py | MLP |
| pairwise ranking dataset 构造 | train/src/rank_pair_dataset.py | rank_pair_dataset.make_data |
| ImageReward 训练模型 | train/src/ImageReward.py | ImageReward.forward, encode_pair |
| pairwise cross-entropy 训练目标 | train/src/train.py | loss_func |
| ReFL 训练 | ImageReward/ReFL.py | Trainer.train |
| pip 包入口 | ImageReward/__init__.py | from .ReFL import * |
| 最小推理示例 | example.py | RM.load, inference_rank, score |
4. Experimental Setup (实验设置)
4.1 ImageReward 训练设置
- 训练数据:8,878 prompts,136,892 image comparison pairs。
- 测试集:466 prompts,对应 6,399 comparisons。
- 另一组 selection 测试:371 prompts,每个 prompt 有 8 张图。
- Backbone:BLIP(ViT-L image encoder + 12-layer text encoder)。
- 最优设置:固定 70% backbone transformer layers,学习率 1e-5,总 batch size 64。
- 训练硬件:4 × 40GB NVIDIA A100,每卡 batch size 16。
4.2 作为 metric 的评测设置
- 比较模型:CogView 2, Versatile Diffusion, Stable Diffusion 1.4, Stable Diffusion 2.1-base, DALL-E 2, Openjourney。
- 数据:100 real-user test prompts,每个模型每个 prompt 生成 10 张图。
- 自动指标:ImageReward, CLIP, zero-shot FID。
- 目标:比较自动指标和 human ranking 的一致性。
4.3 ReFL 训练与评测设置
- baseline 生成模型:Stable Diffusion v1.4。
- pre-training regularization 数据:LAION-5B 的 625k aesthetic-selected subset。
- ReFL prompt set:从 DiffusionDB 采样。
- 训练硬件:8 × 40GB NVIDIA A100。
- 总 batch size:128(文中写 64 for pre-training + 64 for ReFL)。
- 学习率:1e-5。
- 论文设置:, , 。
- 评测数据:466 real-user prompts + 90 MT Bench challenging prompts。
- 对比方法:Dataset Filtering, Reward Weighted, RAFT, baseline SD v1.4。
4.4 评价指标
- Preference Accuracy:在两张图中选择和 human 一致的更优图。
- Recall@k / Filter@k:从多张候选图中 recall 最优图或过滤低质量图的能力。
- Human Eval. WinRate:人类偏好评测中的胜率。
- Spearman :自动指标与 human ranking 的相关性。
5. Experimental Results (实验结果)
5.1 ImageReward 明显优于传统 scorer
主结果表显示,在 human preference prediction 上,ImageReward 全面优于 CLIP / Aesthetic / BLIP:
- Preference Accuracy:ImageReward 65.14,CLIP 54.82,Aesthetic 57.35,BLIP 57.76。
- Recall@1:ImageReward 39.62,优于 Aesthetic 30.73 / BLIP 30.73。
- Recall@2:ImageReward 63.07。
- Recall@4:ImageReward 90.84。
- Filter@1/2/4:分别达到 49.06 / 70.89 / 88.95。
从 agreement analysis 看,ImageReward 和 researcher / annotator ensemble 的一致性也最高:
- 对 researcher:64.5% ± 2.5%,高于 CLIP 57.8% ± 3.6%。
- 对 annotator ensemble:70.5% ± 18.6%,高于 BLIP 62.0% ± 16.1%。
同时,ablation 说明两个结论:
- BLIP backbone 明显优于 CLIP backbone。
- 数据越多越好:BLIP 从 1k → 8k prompts,Preference Accuracy 从 63.07 提升到 65.14。
5.2 作为 automatic metric,ImageReward 比 CLIP / FID 更像 human
在 6 个生成模型的 model ranking 上:
- human ranking 前三名是:Openjourney > SD 2.1-base > DALL-E 2。
- ImageReward 的 real-user prompt 排名与 human ranking 完全一致。
- Spearman 相关:ImageReward 1.00,CLIP 0.60,zero-shot FID 0.09。
这说明 ImageReward 不是“另一个相关性分数”,而是更接近 human evaluation 的偏好度量。
5.3 ReFL 在 human eval 上优于其他 diffusion 优化方法
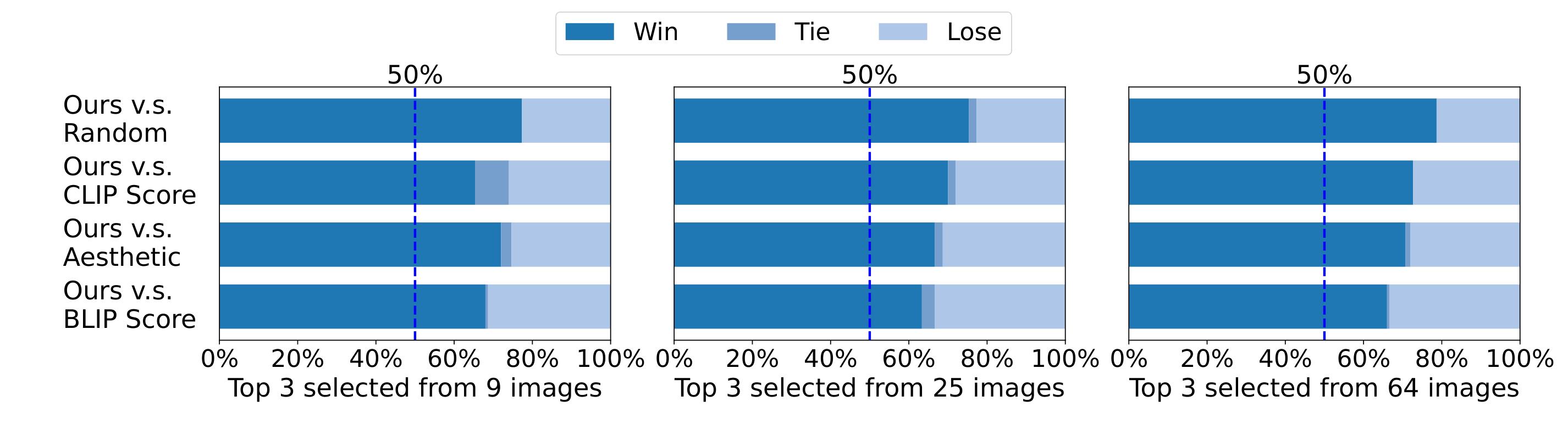
Figure 5 解读:这张图展示了不同 selector 在 human evaluation 中选到更优图像的胜率。ImageReward 相对 random、CLIP、Aesthetic、BLIP 都有明显优势,说明它不仅能输出更高分,而且这些更高分确实对应更高的人类偏好。
ReFL 的 human evaluation 结果如下:
- 对 real-user prompts:ReFL 的 win count 1508,WinRate 58.79%,优于 Dataset Filtering 55.17%,显著优于 Reward Weighted 39.52% 和 RAFT。
- 对 MT Bench:ReFL 的 WinRate 58.49%,也优于其它对比方法。
论文进一步指出:
- RAFT 容易随着迭代增加而 overfit;
- Reward Weighted 因为把非偏好图也保留了正权重,难以完全消除差图干扰;
- Dataset Filtering 虽然能减轻问题,但本质仍是间接优化;
- ReFL 通过 reward 直接回传梯度,因此更有效。
5.4 与其他 reward model 对比
在 reward model 的横向比较中,ImageReward 也优于 HPS 和 PickScore:
- Bo64 设置,real-user prompts:ImageReward WinRate 73.33%,HPS 67.24%,PickScore 72.16%。
- ReFL 设置,real-user prompts:ImageReward WinRate 58.38%,高于 HPS 52.86% 和 PickScore 56.91%。
这说明 ReFL 的收益并不仅仅来自“有一个 reward”,而和 reward 的质量本身密切相关。
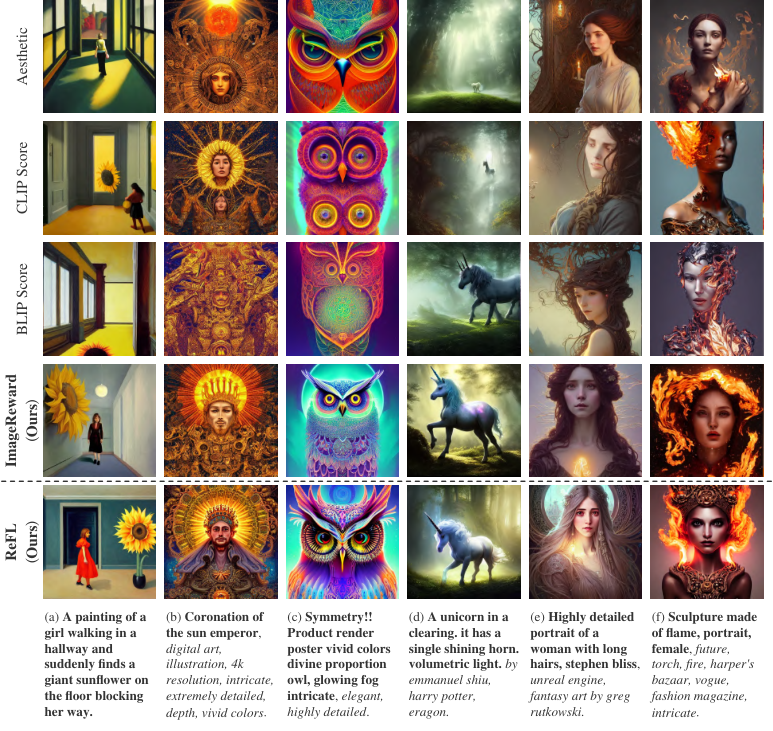
Figure 6 解读:这张图同时展示了两种收益。上半部分是“先生成很多张,再用 ImageReward 选 Top-1”;下半部分是“直接用 ReFL 训练后单次生成”。可以看到,ImageReward 一方面能把多候选中的更优图选出来,另一方面 ReFL 又能把这种偏好直接蒸馏进生成器本身,减少依赖多次采样和后验筛选。
5.5 局限性
论文明确提了三类限制:
- 标注规模与分布仍有限:当前约 9k prompts / 137k pairs,且 prompt 主要来自 DiffusionDB,仍可能有分布偏差。
- reward model 训练仍有 overfitting 问题:需要固定部分 backbone 层才能稳定训练,说明方法对 training technique 依赖较强。
- ReFL 还只是视觉领域 RLHF 的近似方案:虽然有效,但距离“理论上更无偏、更高效的 feedback learning”还有空间。
5.6 总结
我对这篇论文的判断是:它的重要性不只在于提出了一个分数更高的 reward model,而在于把视觉生成里的“人类偏好”第一次系统化为:
- 可规模化采集的数据;
- 可训练的 reward function;
- 可直接优化 diffusion model 的反馈信号。
如果把 RLHF 在文本领域的关键中间件拆成“偏好数据 → reward model → policy optimization”,那么这篇工作基本给 text-to-image 领域补齐了这条链路里的前两环半,并用 ReFL 往第三环迈出了很实的一步。