Flow-OPD: On-Policy Distillation for Flow Matching Models
Paper: arXiv:2605.08063 Code: CostaliyA/Flow-OPD Code reference:
main@d5122521(2026-05-12)
1. Motivation (研究动机)
当前 Flow Matching (FM) text-to-image 模型在 post-training 阶段有两个核心瓶颈:第一,Flow-GRPO / GRPO-style RL 依赖最终图像上的 scalar reward,监督信号稀疏,无法告诉模型在每个 denoising / flow step 应该怎样修正 vector field;第二,多任务对齐时,GenEval、OCR、PickScore、DeQA 等 reward 目标对应的特征表征并不一致,联合优化会产生 gradient interference 和 “seesaw effect”。论文 toy experiment 中,SD-3.5-M 从 GenEval 0.63 / OCR 0.59 出发,单独加 GenEval 后达到 0.94 / 0.65;继续叠加 OCR 后 OCR 升到 0.91,但 GenEval 降到 0.89;再叠加 PickScore 和 DeQA 后 GenEval 依次降到 0.82、0.73,说明 scalar reward mixing 不能稳定构建 generalist policy。
本文要解决的问题是:如何把多个 single-reward specialist teacher 的能力压缩进一个 Flow Matching student,同时保留 on-policy exploration 的优势,并避免多 reward 直接相加带来的相互覆盖。目标不是再训练一个更强的单任务 T2I 模型,而是在 composition、text rendering、image quality、human preference alignment 之间同时达到高分。
这个问题值得研究,因为 T2I 的实际应用越来越需要单一模型同时满足布局、计数、文字、审美和偏好对齐。若能把 sparse scalar reward 替换为 dense trajectory-level supervision,就可以让 post-training 更接近“每一步生成动力学如何改”的监督,而不只是“最终图像得几分”的黑盒反馈。
2. Idea (核心思想)
核心 insight:不要把异构 reward 压成一个 scalar advantage,而是先用单任务 Flow-GRPO 训练出多个 domain teacher,再让 student 在自己的 on-policy 轨迹上向被路由到的 teacher vector field 对齐。这样,exploration 仍来自 student 当前 policy,credit assignment 则从终点 reward 变成 step-wise dense vector-field reward。
Flow-OPD 的创新可以概括为两阶段:第一阶段培养 GenEval / OCR / PickScore / DeQA specialist teacher;第二阶段用 Flow-based Cold Start 初始化 student,再执行 on-policy sampling、task-routing labeling、dense KL / vector-field supervision,并用 Manifold Anchor Regularization (MAR) 把生成过程锚定在高质量视觉 manifold 上。
与 GRPO-Mix 的根本差异是监督粒度和冲突处理方式。GRPO-Mix 把多个 reward 加权成同一个 scalar signal,冲突发生时只能在共享参数里折中;Flow-OPD 则用 hard routing 让每个 prompt 只接受对应 teacher 的 dense flow supervision,同时通过 MAR 保留审美/通用生成先验。
3. Method (方法)
3.1 Overall framework
 Figure 1 解读:这张结构图把论文方法拆成两层。上半部分是 expertise acquisition:用 single-reward Flow-GRPO 分别训练 GenEval、OCR、PickScore、DeQA teacher,并用 SFT trajectories 或 model merging 给 student 做 cold start。下半部分是 model unification:student 先在自己的 SDE 轨迹上采样,prompt router 选择对应 teacher,teacher 产生 dense vector-field target,最后通过 PPO-style clipped update 与 MAR 共同更新 student。
Figure 1 解读:这张结构图把论文方法拆成两层。上半部分是 expertise acquisition:用 single-reward Flow-GRPO 分别训练 GenEval、OCR、PickScore、DeQA teacher,并用 SFT trajectories 或 model merging 给 student 做 cold start。下半部分是 model unification:student 先在自己的 SDE 轨迹上采样,prompt router 选择对应 teacher,teacher 产生 dense vector-field target,最后通过 PPO-style clipped update 与 MAR 共同更新 student。
 Figure 2 解读:论文用训练曲线说明 Flow-OPD 和 vanilla GRPO 的差异。Flow-OPD 在 GenEval 与 OCR 相关平均 reward 上持续上升,峰值接近 93;vanilla GRPO 约在 78 附近过早收敛。图中也强调 DeQA 与 PickScore 被归一化到 0–1,左图使用 model merging cold-start。
Figure 2 解读:论文用训练曲线说明 Flow-OPD 和 vanilla GRPO 的差异。Flow-OPD 在 GenEval 与 OCR 相关平均 reward 上持续上升,峰值接近 93;vanilla GRPO 约在 78 附近过早收敛。图中也强调 DeQA 与 PickScore 被归一化到 0–1,左图使用 model merging cold-start。
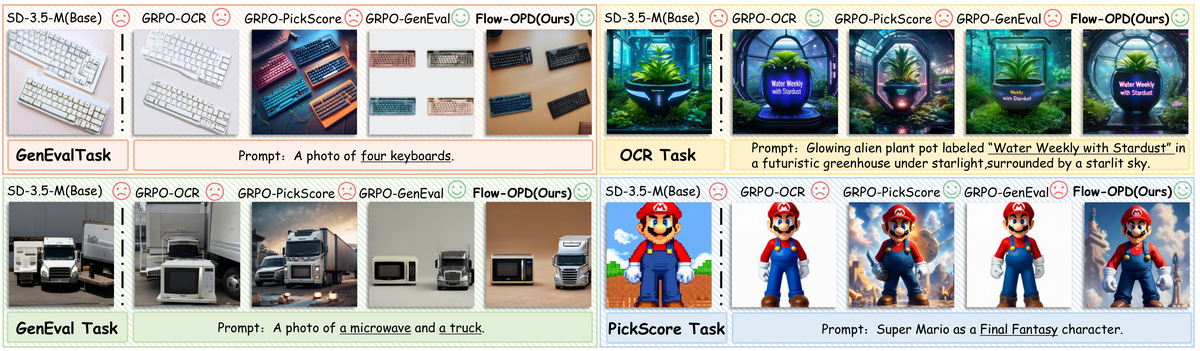 Figure 3 解读:这张图对应论文对 single-reward GRPO 的诊断:单一 reward 能提高目标指标,但会牺牲非目标能力。它支撑本文的动机——多任务失败不是因为某个 reward 不够强,而是因为 sparse scalar reward 在共享参数空间里缺少对其它能力的约束。
Figure 3 解读:这张图对应论文对 single-reward GRPO 的诊断:单一 reward 能提高目标指标,但会牺牲非目标能力。它支撑本文的动机——多任务失败不是因为某个 reward 不够强,而是因为 sparse scalar reward 在共享参数空间里缺少对其它能力的约束。
3.2 Key components
Cold Start. 为避免 student 在早期 on-policy rollout 时轨迹发散,论文尝试两种初始化:SFT-based cold start 使用 specialist teacher 采样出的 trajectories 做监督;model merging 则把多个 homogeneous teacher 的 anisotropic priors 叠加到一个 unified parameter state。released code 中,SFT 配置来自 config/sft.py:geneval_sd3 / pickscore_sd3,model merging 的具体脚本未在当前 commit 中完整公开。
Multi-Teacher On-Policy Distillation. Student 不在离线 teacher data 上回放,而是在自己的 current policy 下生成 latent trajectory 。对每个 explored state ,router 根据 prompt/task 选择 teacher ,使用 teacher vector field 作为 target。
Manifold Anchor Regularization (MAR). 纯功能 reward 容易把模型推向 reward hacking,例如文字正确但背景塌缩、多个实体共享同质外观。MAR 引入 task-agnostic / aesthetic teacher 的 vector field 作为 continuous elastic anchor,使 student 吸收功能性 expert knowledge 的同时不离开高质量视觉 manifold。
直觉上,Flow-OPD 的关键不是“teacher 更多”,而是把监督从终点标量变成 trajectory 上的局部方向场。Scalar reward 只能告诉模型最终图像好不好;teacher vector field 则告诉模型在当前 latent state 和 timestep 下应该往哪个方向移动,因此能把 composition、OCR、审美等能力拆开监督,减少不同任务在同一个 advantage 上互相抵消。
3.3 Math formulas
Flow-GRPO 的 online exploration 用 group relative advantage:
单任务更新对未监控能力 的副作用可用一阶近似表示:
Flow-OPD 把 deterministic probability flow ODE 转为 SDE 来获得 stochastic on-policy exploration:
Euler-Maruyama 离散化后,student 的局部 transition policy 是:
Task-specific teacher labeling 定义 target vector field:
由于 student 与 target transition policy 共享协方差,Reverse KL 可化为 mean / vector-field 距离:
Dense OPD reward 使用 detached student vector field:
Clipped policy gradient objective 为:
MAR 总损失为:
论文公式与 released code 实现差异:论文描述的是 multi-teacher hard routing + aesthetic teacher MAR;main@d5122521 的 README 仍标注 “Release full training code” 未完成。当前公开代码提供了 single-teacher OPD 示例(general_ocr_sd3_8gpu_opd,用 kl_ref_lora_path 做 reference LoRA)、GRPO-Mix 交替数据训练,以及 base-reference KL/MAR-like regularization;未公开完整的 multi-teacher OPD router 训练脚本。另一个数值差异是论文附录写 MAR KL ratio ,而当前 config/grpo.py 中 OPD / mix 相关配置设 config.train.beta=0.04。
3.4 Pseudocode based on released code
Component A — SDE on-policy sampling (sd3_sde_with_logprob.py, sd3_pipeline_with_logprob.py).
def sde_step_with_logprob(scheduler, model_output, timestep, sample,
noise_level=0.7, prev_sample=None):
sigma = scheduler.sigmas[index_for(timestep)]
sigma_prev = scheduler.sigmas[index_for(timestep) + 1]
dt = sigma_prev - sigma
std = torch.sqrt(sigma / (1 - torch.where(sigma == 1, scheduler.sigmas[1], sigma))) * noise_level
mean = sample * (1 + std**2 / (2 * sigma) * dt)
mean = mean + model_output * (1 + std**2 * (1 - sigma) / (2 * sigma)) * dt
if prev_sample is None:
eps = torch.randn_like(model_output)
prev_sample = mean + std * torch.sqrt(-dt) * eps
log_prob = -((prev_sample.detach() - mean) ** 2) / (2 * (std * torch.sqrt(-dt)) ** 2)
log_prob = log_prob - torch.log(std * torch.sqrt(-dt)) - torch.log(torch.sqrt(torch.tensor(2 * torch.pi)))
return prev_sample, log_prob.mean(dim=tuple(range(1, log_prob.ndim))), mean, stdComponent B — multi-score reward composition (flow_grpo/rewards.py).
def multi_score(images, prompts, metadata, score_dict):
score_functions = {
"geneval": geneval_score,
"ocr": ocr_score,
"pickscore": pickscore_score,
"deqa": deqa_score_remote,
"qwenvl": qwenvl_score_remote,
}
details = {}
for name, weight in score_dict.items():
scores, extra = score_functions[name](images, prompts, metadata)
details[name] = scores
weighted = [weight * s for s in scores]
details["avg"] = weighted if "avg" not in details else [a + b for a, b in zip(details["avg"], weighted)]
return details, {}Component C — single-teacher OPD dense KL reward (scripts/train_sd3.py).
def opd_dense_kl_advantage(policy_mean, ref_lora_mean, std_dev_t, cfg):
kl_reward = ((policy_mean - ref_lora_mean) ** 2).mean(dim=(1, 2, 3), keepdim=True)
kl_reward = kl_reward / (2 * std_dev_t**2)
kl_reward = kl_reward.squeeze(-1).squeeze(-1)
# cfg.train.kl_scale = -1 in general_ocr_sd3_8gpu_opd, matching paper's negative distance reward.
advantage = cfg.train.kl_scale * kl_reward
return torch.clamp(advantage, -cfg.train.adv_clip_max, cfg.train.adv_clip_max)Component D — clipped PPO-style update with MAR/base KL (scripts/train_sd3.py).
def train_one_step(log_prob, old_log_prob, advantage, policy_mean, base_mean, std_dev_t, cfg):
ratio = torch.exp(log_prob - old_log_prob)
unclipped = -advantage * ratio
clipped = -advantage * torch.clamp(ratio, 1.0 - cfg.train.clip_range, 1.0 + cfg.train.clip_range)
policy_loss = torch.maximum(unclipped, clipped).mean()
if cfg.train.beta > 0:
kl_loss = ((policy_mean - base_mean) ** 2).mean(dim=(1, 2, 3), keepdim=True)
kl_loss = (kl_loss / (2 * std_dev_t**2)).mean()
loss = policy_loss + cfg.train.beta * kl_loss
else:
loss = policy_loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
return lossComponent E — released GRPO-Mix alternating datasets (config/grpo.py, scripts/train_sd3_mixed.py).
def choose_dataset_for_epoch(epoch, alternate_datasets):
cycle = sum(ds["epochs_per_cycle"] for ds in alternate_datasets)
epoch_in_cycle = epoch % cycle
offset = 0
for idx, ds in enumerate(alternate_datasets):
if epoch_in_cycle < offset + ds["epochs_per_cycle"]:
return idx, ds
offset += ds["epochs_per_cycle"]
raise RuntimeError("bad cycle")
def grpo_mix_epoch(epoch, dataloaders, reward_fns, cfg):
idx, ds = choose_dataset_for_epoch(epoch, cfg.alternate_datasets)
batch = next(iter(dataloaders[ds["name"]]))
images, latents, old_log_probs = sample_with_current_policy(batch, cfg)
rewards, _ = reward_fns[ds["name"]](images, batch.prompts, batch.metadata, only_strict=True)
advantages = normalize_group_reward(rewards["avg"])
return ppo_update_from_sparse_advantage(latents, old_log_probs, advantages)Code reference:
main@d5122521(2026-05-12) — pseudocode and mapping based on this commit.
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Flow-based SDE rollout and log-prob trajectory | flow_grpo/diffusers_patch/sd3_sde_with_logprob.py; flow_grpo/diffusers_patch/sd3_pipeline_with_logprob.py | sde_step_with_logprob; pipeline_with_logprob |
| Single-teacher OPD dense KL reward | config/grpo.py; scripts/train_sd3.py | general_ocr_sd3_8gpu_opd; kl_ref_lora_path; reward_mode="kl_only"; kl_reward_level="step_wise" |
| MAR / KL anchor in released code | scripts/train_sd3.py | transformer.module.disable_adapter() base reference; loss = policy_loss + beta * kl_loss |
| GRPO-Mix baseline / alternating datasets | config/grpo.py; scripts/train_sd3_mixed.py; scripts/multi_node/sd3_mix.sh | geneval_ocr_deqa_pickscore_32gpu; get_current_dataset_idx; multi_score |
| Cold-start SFT | config/sft.py; scripts/train_sd3_sft.py | geneval_sd3; pickscore_sd3; train.algorithm='sft'; learner/ref adapter update |
| Reward models | flow_grpo/rewards.py; flow_grpo/ocr.py; scorer files | multi_score; geneval_score; ocr_score; pickscore_score; deqa_score_remote |
4. Experimental Setup (实验设置)
Datasets and scale. 论文说明训练/测试数据严格 follow Flow-GRPO splits;当前 released repo 中可核对到:GenEval train 50,000 / test 2,212;OCR train 19,653 / test 1,018;PickScore train 25,432 / test 2,048;DrawBench test 1,000;T2I-CompBench++ 的 color、shape、texture、complex、3D-spatial、numeracy、non-spatial 各 300 条 validation prompts。论文正文同时写 OCR train 19,652 / test 1,017、GenEval test 2,211;这与 repo 当前文件行数存在 1 条级别差异,笔记以 released repo 可复现计数为准,并保留论文描述差异。
Baselines. Baseline 分两类:Monolithic-Reward GRPO,即 GRPO-[reward name],包括 GRPO-GenEval、GRPO-OCR、GRPO-DeQA、GRPO-PickScore;Hybrid-Reward GRPO,即 GRPO-Mix,正文设定 GenEval : OCR : PickScore = 3 : 1 : 1,补充材料/代码的 32GPU mix 配置中每个 dataset reward 为 task reward 0.8 + DeQA 0.2,epoch cycle 为 GenEval : OCR : PickScore = 3 : 1 : 1。
Evaluation metrics. GenEval 衡量 compositional image generation(object counting、spatial relation、attribute binding 等);OCR Acc. 衡量图像中文字渲染的字符/文本准确性;DeQA 衡量 image quality;PickScore 衡量 human preference alignment;ImageReward、Aesthetic、UnifiedReward、HPS-v2.1、QwenVL Score 用于 general image quality / alignment;T2I-CompBench++ 细分 Color、Shape、Texture、Complex、3D-Spatial、Numeracy、Non-Spatial。
Training config. Foundation model 是 Stable Diffusion 3.5 Medium。论文正文写 training 使用 4 nodes,每 node 8 × H800,共 32 × H800;evaluation 使用 1 node 8 × H800。补充材料写分布式 4 nodes × 8 H800 训练约 50 小时。scripts/multi_node/sd3_mix.sh 实际以 --num_machines 4 --num_processes 32 启动 scripts/train_sd3_mixed.py --config config/grpo.py:geneval_ocr_deqa_pickscore_32gpu。该 config 设置 sample.num_steps=10、sample.eval_num_steps=40、guidance_scale=4.5、resolution=512、sample.train_batch_size=3、sample.num_image_per_prompt=24、learning_rate=1e-4、timestep_fraction=0.99、train.beta=0.04、LoRA r=32 / alpha=64。按 config 公式和 gpu_number=32,num_batches_per_epoch=int(48/(32*3/24))=12,gradient_accumulation_steps=6;代码注释“=2”与公式不一致。
5. Experimental Results (实验结果)
 Figure 4 解读:主 qualitative comparison 覆盖 composition、visual text rendering 和审美质量。图中 Flow-OPD 相比 SD3.5-M、single-reward teachers、GRPO-Mix 更稳定地同时满足 prompt fidelity 与视觉质量;论文特别指出部分 edge cases 中 student 甚至超过所有 single teacher,即 teacher-surpassing。
Figure 4 解读:主 qualitative comparison 覆盖 composition、visual text rendering 和审美质量。图中 Flow-OPD 相比 SD3.5-M、single-reward teachers、GRPO-Mix 更稳定地同时满足 prompt fidelity 与视觉质量;论文特别指出部分 edge cases 中 student 甚至超过所有 single teacher,即 teacher-surpassing。
Main quantitative results. 论文主表如下,Avg 是四个 0–1 normalized metrics 的平均,teacher models 用粗体下划线标注 performance ceiling,比较时不计入普通 baseline:
| Model | GenEval | OCR Acc. | DEQA | PickScore | Avg |
|---|---|---|---|---|---|
| SD-3.5-M | 0.63 | 0.59 | 4.07 | 21.64 | 0.7166 |
| +GRPO-GenEval | 0.94 | 0.65 | 4.01 | 21.53 | 0.8050 |
| +GRPO-OCR | 0.64 | 0.92 | 4.06 | 21.69 | 0.8016 |
| +GRPO-DeQA | 0.64 | 0.66 | 4.23 | 23.02 | 0.7578 |
| +GRPO-PickScore | 0.51 | 0.69 | 4.22 | 23.19 | 0.7340 |
| GRPO-Mix | 0.73 | 0.83 | 4.33 | 21.84 | 0.8165 |
| SFT+GRPO-Mix | 0.85 | 0.86 | 4.29 | 21.79 | 0.7166 |
| Merge+GRPO-Mix | 0.84 | 0.86 | 4.18 | 21.87 | 0.7166 |
| Ours (SFT) | 0.91 | 0.92 | 4.29 | 21.83 | 0.8819 |
| Ours (Merge) | 0.92 | 0.94 | 4.35 | 23.08 | 0.9044 |
关键结论:Ours (Merge) 在 GenEval 0.92、OCR 0.94、DEQA 4.35、PickScore 23.08、Avg 0.9044 上达到主表最佳或接近 teacher ceiling;相比 GRPO-Mix 的 Avg 0.8165,提升 0.0879;相比 base SD-3.5-M 的 Avg 0.7166,提升 0.1878。
 Figure 5 解读:Cold-start ablation 显示初始化本身能快速建立多任务基础。SFT 更通用、可从异构 teacher 提取能力;model merging 在 homogeneous teacher 可用时不需要额外训练成本,并给后续 Flow-OPD 提供更强功能对齐起点。
Figure 5 解读:Cold-start ablation 显示初始化本身能快速建立多任务基础。SFT 更通用、可从异构 teacher 提取能力;model merging 在 homogeneous teacher 可用时不需要额外训练成本,并给后续 Flow-OPD 提供更强功能对齐起点。
 Figure 6 解读:MAR ablation 展示没有 anchor 时,GRPO-style optimization 容易出现背景模式塌缩、语义冗余或多个实体特征趋同;加入 MAR 后,模型在保持文字/布局等功能性能力的同时,图像结构和多样性更稳定。
Figure 6 解读:MAR ablation 展示没有 anchor 时,GRPO-style optimization 容易出现背景模式塌缩、语义冗余或多个实体特征趋同;加入 MAR 后,模型在保持文字/布局等功能性能力的同时,图像结构和多样性更稳定。
T2I-CompBench++ OOD generalization.
| Model | Color | Shape | Texture | Complex | 3D-Spatial | Numeracy | Non-Spatial |
|---|---|---|---|---|---|---|---|
| SD3.5-M | 0.7994 | 0.5669 | 0.7338 | 0.3800 | 0.3739 | 0.5927 | 0.3146 |
| GRPO-mix | 0.7966 | 0.5803 | 0.7392 | 0.3677 | 0.3681 | 0.6388 | 0.3130 |
| Cold Start | 0.8173 | 0.6126 | 0.7342 | 0.3870 | 0.4249 | 0.6458 | 0.3145 |
| Cold Start+GRPO | 0.8031 | 0.5985 | 0.7409 | 0.3842 | 0.4017 | 0.6269 | 0.3136 |
| Ours (Merge) | 0.8298 | 0.6292 | 0.7446 | 0.3943 | 0.4565 | 0.6837 | 0.3163 |
Ours (Merge) 在全部七个 T2I-CompBench++ 维度上为表中最佳,尤其 Shape 从 GRPO-mix 0.5803 到 0.6292、3D-Spatial 从 0.3681 到 0.4565,说明 dense multi-expert supervision 对 OOD compositional generalization 有帮助。
General image quality and alignment metrics.
| Model | ImageReward | Aesthetic | UnifiedReward | HPS-v2.1 | QwenVL Score |
|---|---|---|---|---|---|
| SD-3.5-M | 1.02 | 5.87 | 3.339 | 0.2982 | 3.45 |
| GRPO-DeQA | 1.33 | 5.97 | 3.456 | 0.2846 | 3.68 |
| GRPO-mix | 1.23 | 5.93 | 3.501 | 0.3101 | 3.88 |
| w.o. MAR | 1.26 | 5.89 | 3.518 | 0.2998 | 3.82 |
| Ours (Merge) | 1.36 | 6.23 | 3.659 | 0.3302 | 4.05 |
MAR 的量化贡献很直接:相对 w.o. MAR,Ours (Merge) 的 ImageReward 从 1.26 到 1.36,Aesthetic 从 5.89 到 6.23,UnifiedReward 从 3.518 到 3.659,HPS-v2.1 从 0.2998 到 0.3302,QwenVL Score 从 3.82 到 4.05。
 Figure 7 解读:补充 PickScore qualitative results 展示 Flow-OPD 在偏好对齐任务上不只是提高打分,还能保持较好的 structural layout 和视觉细节,因此不是单纯 reward hacking 到某个偏好模型。
Figure 7 解读:补充 PickScore qualitative results 展示 Flow-OPD 在偏好对齐任务上不只是提高打分,还能保持较好的 structural layout 和视觉细节,因此不是单纯 reward hacking 到某个偏好模型。
 Figure 8 解读:补充 GenEval results 强调 composition 与 instruction following。对复杂对象、属性绑定、位置关系等 prompt,Flow-OPD 的输出更少出现漏物体或关系错误。
Figure 8 解读:补充 GenEval results 强调 composition 与 instruction following。对复杂对象、属性绑定、位置关系等 prompt,Flow-OPD 的输出更少出现漏物体或关系错误。
 Figure 9 解读:补充 OCR results 展示 text rendering 任务中的细粒度收益。相较只优化视觉偏好或 composition 的模型,Flow-OPD 更能保留字符级信息,同时不明显牺牲背景和整体画质。
Figure 9 解读:补充 OCR results 展示 text rendering 任务中的细粒度收益。相较只优化视觉偏好或 composition 的模型,Flow-OPD 更能保留字符级信息,同时不明显牺牲背景和整体画质。
 Figure 10 解读:DiffusionNFT 对比用于说明 benchmark score 之外的局部结构和审美问题。论文指出 DiffusionNFT 虽能生成目标文字和 sunset 元素,但会出现 malformed hands、多余物体和 plastic-like texture;Flow-OPD 在 Qwen-VL Score 上为 4.05,高于 DiffusionNFT 的 3.74。
Figure 10 解读:DiffusionNFT 对比用于说明 benchmark score 之外的局部结构和审美问题。论文指出 DiffusionNFT 虽能生成目标文字和 sunset 元素,但会出现 malformed hands、多余物体和 plastic-like texture;Flow-OPD 在 Qwen-VL Score 上为 4.05,高于 DiffusionNFT 的 3.74。
 Figure 11 解读:Failure cases 说明 Flow-OPD 仍受 teacher ceiling 限制:当 specialist teacher 自身生成语义错误图像时,dense supervision 会把错误方向传给 student,导致 student 难以完全超越 teacher ensemble 的错误边界。
Figure 11 解读:Failure cases 说明 Flow-OPD 仍受 teacher ceiling 限制:当 specialist teacher 自身生成语义错误图像时,dense supervision 会把错误方向传给 student,导致 student 难以完全超越 teacher ensemble 的错误边界。
Ablation findings. Cold start 的主要作用是把 student 放到可训练的高能力区域,减少早期 on-policy divergence;Flow-OPD 相比 from-scratch 或 cold-started GRPO 的优势来自 dense multi-expert supervision 对 gradient interference 的缓解;MAR 的主要作用是避免功能 reward 导致的 aesthetic collapse 和 semantic redundancy。
Limitations / 局限性. 作者明确提到两个 limitations:第一,teacher model 的性能 ceiling 会限制 student,teacher 错误可通过 dense supervision 传播;第二,teacher 与 student 需要 architectural homogeneity,才能做 fine-grained step-wise vector-field supervision。作者未来方向包括 co-evolutionary distillation、self-distillation 和 cross-vocabulary distillation。
Overall conclusion. Flow-OPD 证明了把 OPD 引入 Flow Matching post-training 是可行的:它用 dense trajectory-level teacher supervision 替代 sparse scalar reward,解决多指标 seesaw,在 SD-3.5-M 上把 GenEval 从 0.63 提到 0.92、OCR Acc. 从 0.59 提到 0.94,同时保持 PickScore 23.08 和 QwenVL Score 4.05。