DiffusionOPD: A Unified Perspective of On-Policy Distillation in Diffusion Models
Paper: arXiv:2605.15055v1 Project: quanhaol.github.io/DiffusionOPD-site Code: 代码搜索未找到开源实现;未设置
github_ref
1. Motivation (研究动机)
现有 diffusion RL 已能显著提升单一奖励(如 GenEval、OCR、美学偏好),但单任务优化得到的是“专家模型”而不是一个能同时满足多种用户目标的统一模型。直接把多个 reward 混在一起联合训练,会遇到目标冲突、任务难度不平衡和训练互相干扰;级联式训练虽然能逐步学不同任务,但流程笨重且容易遗忘前一阶段能力。
本文要解决的具体问题是:如何把多个单任务 diffusion RL teacher 的能力整合进一个 student,同时避免 student 从零同时探索所有任务。这个问题值得研究,因为真实文生图系统需要同时满足构图、文字渲染、美学、人类偏好等异质目标;如果每个目标都需要单独模型或级联流程,部署和迭代成本都会很高。
2. Idea (核心思想)
核心洞察:多任务 diffusion RL 不一定要让一个模型在所有 reward 上同时探索;可以先让每个 teacher 在自己的任务上独立探索,再让统一 student 沿自己的 denoising rollout 去匹配相应 teacher 的一步转移。这样把“单任务探索”和“多任务能力整合”拆开,避免 joint RL 的跨任务干扰,也比 cascade RL 更少遗忘风险。
DiffusionOPD 的关键创新是把 LLM 中的 On-Policy Distillation 从离散 token 条件分布推广到 diffusion 的连续状态 Markov 链:student 和 teacher 在同一个 student rollout state 上定义一步 Gaussian transition kernel;因为协方差相同,reverse-KL 有闭式解,最终变成逐步 transition mean matching。相对 Multi-Task GRPO/NFT,它不是直接优化多个 reward;相对 SFT/DMD/TDM,它强调 student on-policy 轨迹上的 teacher supervision。
3. Method (方法)
3.1 总体框架
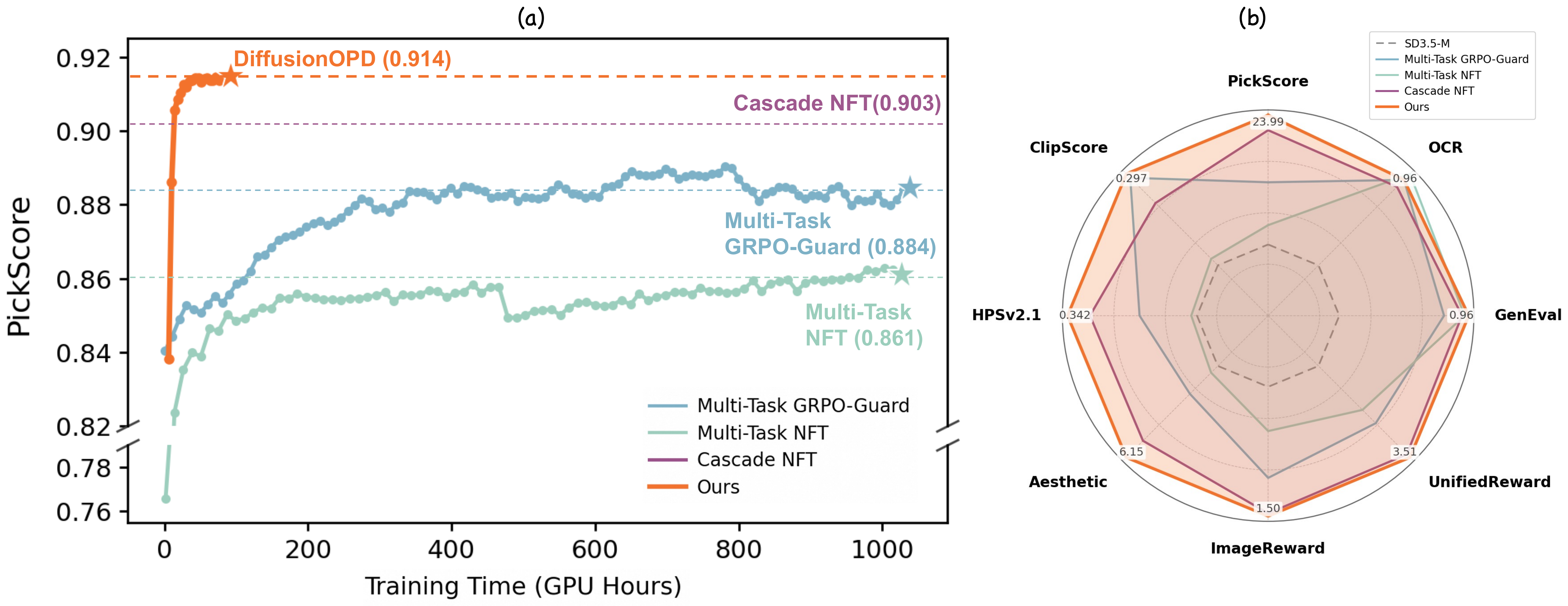
Figure 1 解读:左侧曲线强调 DiffusionOPD 比 multi-task RL baselines 收敛更快且上限更高;右侧雷达/柱状对比展示它不是只优化某一个 reward,而是在 GenEval、OCR、美学相关指标上同时取得更均衡的提升。图中的核心信息是:先训练 task-specific teachers,再用 OPD 整合到 unified student,比直接联合 RL 更适合异质目标。
方法分两阶段:第一阶段为每个任务 训练一个 task-specific teacher ;第二阶段初始化 student ,按任务轮询采样 prompts,让当前 student 生成 on-policy denoising trajectory,再用对应 teacher 在这些状态上提供逐步监督。一个完整 round-robin 访问所有任务后再做一次 optimizer step,使每次参数更新都包含完整任务集合的监督。
3.2 从 LLM OPD 到 diffusion Markov chain
LLM OPD 在 student 自己生成的 prefix 上最小化 teacher/student next-token 分布的逐步 KL:
DiffusionOPD 把“prefix 上的 next-token distribution”替换成 denoising Markov chain 中 state 上的一步 transition kernel:
直觉上,student 不需要模仿 teacher 离线生成的最终图片,而是在自己实际会访问的 noisy latent states 上学习“下一步该怎么走”。这减少了离线蒸馏的 distribution mismatch,也让 teacher 的能力以 dense per-step supervision 进入 student。
3.3 闭式 KL 与 ODE 特例
对 flow-matching latent ,论文沿用 Flow-GRPO 的 reverse-time SDE 离散化。student 和 teacher 使用相同 scheduler 与 noise level,只把 velocity 从 换成 ,因此一步 kernel 都是同协方差 Gaussian:
同协方差 Gaussian 的 reverse-KL 只剩 mean mismatch:
当 sampler 退化为 deterministic ODE 时,下一状态由当前 latent 唯一决定,distribution matching 可直接写成 transition mean 的 matching:
这也是作者默认采用的训练目标。与 PPO-style policy gradient 相比,闭式 KL 可以直接对 transition mean 反传,避免 score-function term 带来的采样方差;论文的 ablation 显示同样 noise level 下闭式 KL 更快、更高。
3.4 训练伪代码
代码搜索未找到开源实现;以下伪代码根据 arXiv source 中 sec/method.tex 的 Algorithm 1、Eq. (generic OPD / diffusion OPD / ODE OPD) 和 sec/expr.tex 的实验设置重构,未设置 github_ref。
def train_task_teachers(tasks, base_policy, rl_algorithms):
teachers = {}
for task in tasks:
# OCR/Aesthetics: GRPO-Guard; GenEval: DiffusionNFT(论文实验设置)
alg = rl_algorithms[task.name]
teachers[task.name] = alg.finetune(
model=base_policy,
prompts=task.prompts,
reward_fn=task.reward_fn,
)
return teachersimport torch
import torch.nn.functional as F
def opd_ode_loss(student, teacher, prompts, scheduler):
# Student rollout is on-policy; paper marks rollout as no_grad.
with torch.no_grad():
trajectory = student.rollout(prompts, scheduler=scheduler)
total = 0.0
for x_t, t in trajectory.states[:-1]:
mu_s = student.transition_mean(x_t, t, scheduler=scheduler)
with torch.no_grad():
mu_t = teacher.transition_mean(x_t, t, scheduler=scheduler)
total = total + 0.5 * F.mse_loss(mu_s, mu_t, reduction="mean")
return total / max(1, len(trajectory.states) - 1)def train_diffusion_opd(student, teachers, task_loaders, optimizer, scheduler):
# Gradient accumulation factor G = M: update after one full task round.
for _round in range(num_rounds):
total_loss = 0.0
for task_name, loader in task_loaders.items():
prompts = next(loader)
teacher = teachers[task_name]
total_loss = total_loss + opd_ode_loss(student, teacher, prompts, scheduler)
loss = total_loss / len(task_loaders)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()Source reference: arXiv source
2605.15055v1-src.tardownloaded to/Users/bytedance/ai-skills/papers/2605.15055v1-src.tar; no released GitHub code was found.
| Paper Concept | Source File | Key Element |
|---|---|---|
| OPD lifted to continuous-state Markov chain | sec/method.tex | DiffusionOPD, Eq. opd-generic |
| Same-covariance Gaussian transition KL | sec/method.tex | Eq. student-kernel, teacher-kernel, gauss-kl-iso |
| ODE transition mean matching objective | sec/method.tex | Eq. opd-ode |
| Two-stage teacher/student training | sec/method.tex | Algorithm DiffusionOPD, Training Recipe |
| Experiment setup and baselines | sec/expr.tex | Implementation Details, Single-Task Teachers, Baselines |
4. Experimental Setup (实验设置)
基础模型与训练配置:作者沿用 DiffusionNFT 的实验设置,以 SD3.5-Medium 作为 base model,在 分辨率训练;使用 LoRA,、rank ;评估使用 40-step first-order ODE sampler。论文未报告 GPU 型号/数量、learning rate、batch size、训练步数和 prompt split 的样本量,因此这些项不能从公开文本中精确填写。
数据与 reward:GenEval 和 OCR 使用 FlowGRPO splits;model-based reward 在 Pick-a-Pic 上训练,并在 DrawBench 上评估。规则奖励包括 GenEval(组合式指令生成)和 OCR(视觉文字渲染);模型奖励包括 PickScore、ClipScore、HPSv2.1、Aesthetics、ImageReward、UnifiedReward。
Teacher 选择:OCR 与 Aesthetics teacher 使用 GRPO-Guard;其中 Aesthetics teacher 优化 PickScore:ClipScore:HPSv2.1 = 1:1:1 的混合目标。GenEval teacher 使用 DiffusionNFT,因为作者观察到它在该任务上收敛更快且上限更高;DiffusionNFT 在 OCR 上容易 reward hacking,导致文字 reward 高但图像质量明显退化。
Baselines:单任务 teachers;Multi-Task GRPO-Guard;Multi-Task NFT;Cascade NFT;蒸馏 ablation 中还比较 DMD、TDM、SFT。SFT 使用 teacher 在线生成图像后让 student 模仿;DMD/TDM 与 DiffusionOPD 一样在 student on-policy samples 上蒸馏相同 teachers。
5. Experimental Results (实验结果)
5.1 主结果
| Model | Time | GenEval | OCR | PickScore | ClipScore | HPSv2.1 | Aesthetic | ImgRwd | UniRwd | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| SD-XL‡ | — | 0.55 | 0.14 | 22.42 | 0.287 | 0.280 | 5.60 | 0.76 | 2.93 | 0.390 |
| SD3.5-L‡ | — | 0.71 | 0.68 | 22.91 | 0.289 | 0.288 | 5.50 | 0.96 | 3.25 | 0.601 |
| FLUX.1-Dev | — | 0.66 | 0.59 | 22.84 | 0.295 | 0.274 | 5.71 | 0.96 | 3.27 | 0.599 |
| SD3.5-M w/o CFG | — | 0.24 | 0.12 | 20.51 | 0.237 | 0.204 | 5.13 | -0.58 | 2.02 | 0.000 |
| SD3.5-M + CFG | — | 0.63 | 0.59 | 22.34 | 0.285 | 0.279 | 5.36 | 0.85 | 3.03 | 0.484 |
| GenEval Teacher | 46.92 | 0.96 | 0.40 | 22.04 | 0.274 | 0.248 | 5.24 | 0.59 | 2.97 | 0.473 |
| OCR Teacher | 33.17 | 0.65 | 0.93 | 22.27 | 0.290 | 0.272 | 5.26 | 0.90 | 3.09 | 0.550 |
| Aes Teacher | 85.75 | 0.49 | 0.59 | 24.02 | 0.295 | 0.346 | 6.22 | 1.498 | 3.48 | 0.698 |
| Multi-Task GRPO-Guard | 129.86 | 0.89 | 0.94 | 23.12 | 0.296 | 0.307 | 5.61 | 1.31 | 3.33 | 0.763 |
| Multi-Task NFT | 128.42 | 0.95 | 0.96 | 22.59 | 0.288 | 0.282 | 5.41 | 1.08 | 3.23 | 0.715 |
| Cascade NFT | 148.49* | 0.94 | 0.91 | 23.80 | 0.293 | 0.331 | 6.01 | 1.49 | 3.49 | 0.851 |
| DiffusionOPD | 85.75+11.26† | 0.96 | 0.94 | 23.99 | 0.297 | 0.342 | 6.15 | 1.50 | 3.50 | 0.929 |
DiffusionOPD 在 Average 上达到 0.929,高于 Cascade NFT 的 0.851、Multi-Task GRPO-Guard 的 0.763 和 Multi-Task NFT 的 0.715;训练时间按作者定义为最大 teacher time 85.75 小时加 OPD 11.26 小时,低于两个 multi-task RL baseline 的约 128–130 小时,也低于 Cascade NFT 的 148.49 小时。

Figure 2 解读:每个 case 两行展示,第一行比较 DiffusionOPD、Multi-Task GRPO-Guard、Multi-Task NFT、Cascade NFT,第二行展示 prompt 和三个 single-task teachers。图中 DiffusionOPD 的作用不是在某个单项 reward 上替代 teacher,而是把不同 teacher 的能力组合到同一个 student 中,减少 multi-task RL 的冲突和 cascade 的遗忘。

Figure 3 解读:曲线显示 multi-task RL baselines 收敛更慢,说明异质 reward 的联合优化存在明显干扰;DiffusionOPD 通过 teacher-first、student-distillation 的拆解方式,以更短 OPD 阶段达到更高性能上限。
5.2 Ablation

Figure 4 解读:该图比较 DiffusionOPD、DMD、TDM、SFT 的 qualitative outputs。SFT 模仿 teacher 生成样本但不是 student on-policy state 上的逐步监督;DMD/TDM 在相同 teachers 与交替数据设置下仍不如 DiffusionOPD,说明 OPD-style transition matching 对多 teacher 整合更有效。
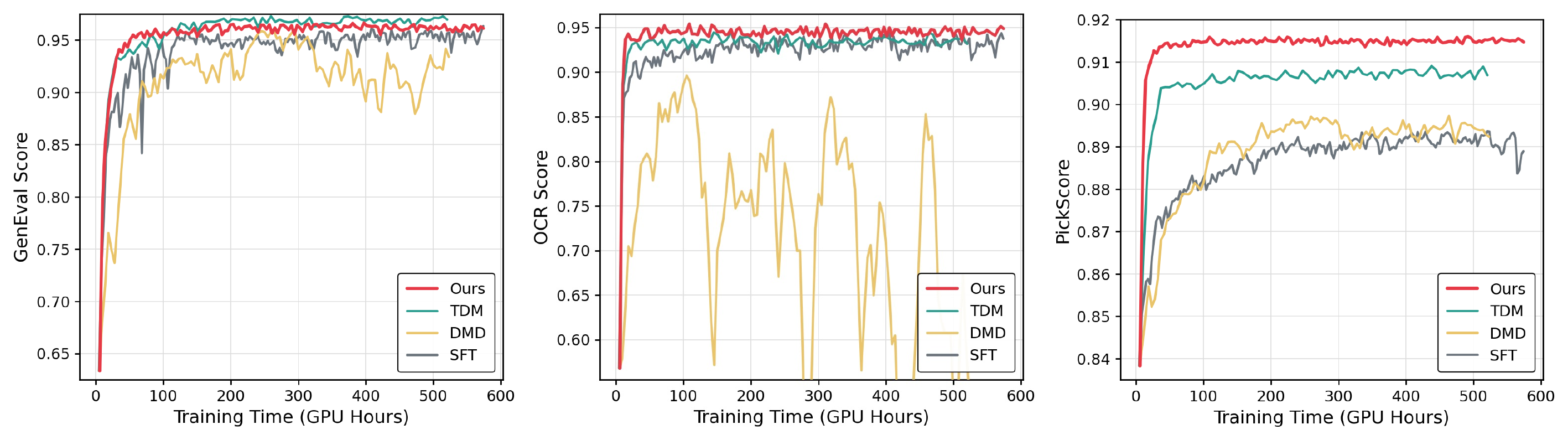
Figure 5 解读:SFT、DMD、TDM 都从同一组 specialized teachers 蒸馏,并按数据集交替训练;DiffusionOPD 的曲线最快且最终分数最高,支持“on-policy rollout + teacher transition supervision”是主要贡献,而不是单纯 teacher ensemble。
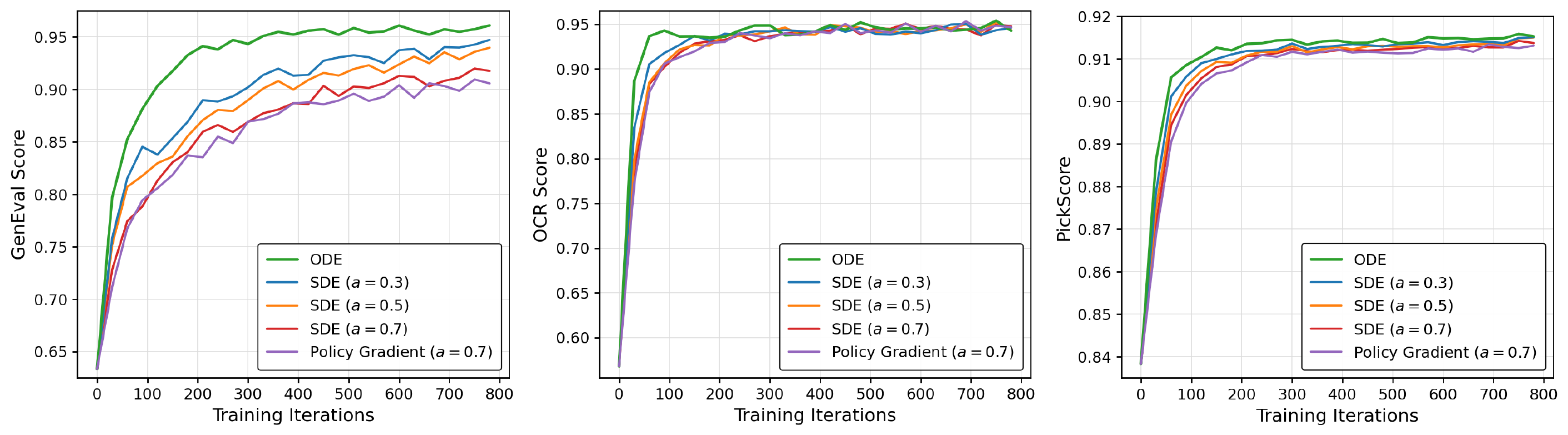
Figure 6 解读:左侧/中间验证闭式 KL 比 PPO-style policy gradient 更好;右侧显示 sampler noise 越低,student 收敛越快、上限越高。当 noise level 为 0 时 SDE 退化为 ODE,作者报告 ODE sampler 相比 noise level = 0.7 的 SDE sampler 最高可提升约 5× 效率。
作者未单列 limitations;从公开论文可见的边界是:未发布可核对代码,样本量、硬件、LR、batch size、训练步数未披露;实验集中在 SD3.5-Medium、、GenEval/OCR/美学/偏好类 reward,尚未证明在更大模型、视频生成或更复杂 reward 组合中同样成立。