Diffusion Model Alignment Using Direct Preference Optimization
Authors: Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, Nikhil Naik Affiliations: Salesforce AI, Stanford University arXiv: 2311.12908 GitHub: SalesforceAIResearch/DiffusionDPO Venue: CVPR 2024
1. 研究动机 (Motivation)
大型语言模型(LLM)已通过 RLHF 方法成功与人类偏好对齐,但文本到图像扩散模型领域的对齐方法远未成熟。现有最好的方案是对精心筛选的高质量图像和文字对进行监督微调(SFT),以提升视觉吸引力和文本对齐度。这一方案存在若干局限:
- 开放词表泛化能力差:基于 RL 的方法(如 DPOK、DDPO)在有限 prompt 集合上有效,但随着 prompt 数量增加性能快速退化;
- 模式崩溃与不稳定:直接使用 reward 模型梯度微调(DRaFT、AlignProp)面临模式崩溃,且只能优化可微分 reward;
- 推理代价高昂:推理时优化方法(DOODL)将推理代价提高一个数量级以上;
- 无分布控制保证:SFT 缺乏通过 KL 散度约束的分布保证。
本文首次提出将 DPO(Direct Preference Optimization)直接应用于扩散模型,在开放词表场景下实现稳定、有分布保证的人类偏好对齐,同时维持等推理代价。
2. 核心思想 (Idea)
Diffusion-DPO 将 LLM 领域的 DPO 范式推广到扩散模型:
- 利用扩散模型的 ELBO 来定义图像在模型下的数据似然,从而规避扩散模型路径上不可解的边缘化问题;
- 将成对人类偏好数据中的 Bradley-Terry 偏好模型与扩散的 ELBO 推导相结合,得到一个可直接用 MSE 损失计算的闭合形式训练目标;
- 不需要单独训练 reward 模型,policy 本身隐式地参数化了 reward 函数;
- 同样支持 AI 反馈(PickScore、HPS 等模型产生的伪标签偏好对)替代人类标注,为扩散对齐方法的规模扩展打开大门。
核心方程(Eq. 14,最终 MSE loss):
3. 方法 (Method)
3.1 背景
扩散模型的 ELBO 训练目标
给定数据分布 ,噪声调度函数 和 ,扩散模型 通过最小化 ELBO 训练:
其中 ,,, 为信噪比, 为预指定的权重函数(实践中通常取常数)。
RLHF 目标
RLHF 旨在优化条件分布 ,使 reward 模型 最大化,同时以 KL 散度约束偏离参考分布的程度:
其中超参数 控制正则化强度。
DPO 重参数化(LLM 中的做法)
Eq. (5) 的最优解为:
反解 reward:
代入 Bradley-Terry 模型得到 DPO 目标(LLM 版本,Eq. 8):
此式直接避免了训练独立的 reward 模型,而是通过对比 policy 与 reference 的对数似然比来隐式建模 reward。
3.2 将 DPO 推广到扩散模型的完整推导
步骤一:路径级目标(Path-level Objective,Eq. 9–11)
扩散模型中 需要对所有扩散路径 进行边缘化,这是不可解的。引入潜变量路径 ,将链式奖励定义为:
为处理 KL 正则项,利用联合 KL 散度上界代替边际 KL:
代入后得到路径级优化目标(Eq. 10):
通过 Eq. (6)–(8) 的类比重参数化,得到路径级 DPO-Diffusion 目标(Eq. 11):
此目标需要从 采样路径,计算既低效( 步)又不可解( 含可训练参数)。
步骤二:Jensen 不等式 → ELBO 上界(Eq. 12)
将 的凸性结合 Jensen 不等式,把期望移出 :
此时从可训练的 采样改为从前向加噪过程 采样,计算变为可行。
步骤三:KL 散度展开(Eq. 13)
将每步的对数似然比展开为相邻时刻的 KL 散度差(利用高斯参数化,Eq. 1):
步骤四:高斯参数化 → 最终 MSE 损失(Eq. 14)
利用高斯 KL 散度的解析形式,每个 KL 项可简化为噪声预测误差的 MSE。最终损失为(Eq. 14):
其中 , 为从 中的采样(Eq. 2)。 为信噪比,实践中权重 取常数,将常数 折入 。
直观解释:损失驱动模型在 winner 图像上的去噪误差小于 reference,同时在 loser 图像上的去噪误差大于 reference。 越大,loss surface 曲率越大(见 Figure 2),对偏离 reference 的惩罚越强。
3.3 图示

Figure 1 解读:展示 Diffusion-DPO 在 SDXL-1.0 base 模型上微调后的生成样例。DPO 微调后的模型能够生成视觉吸引力极强、色彩鲜明、构图精良、细节丰富的图像,显著优于原始 base 模型。这些样例涵盖了从写实人像、动物到奇幻场景的多种类型,体现了方法在开放词表下的泛化能力。
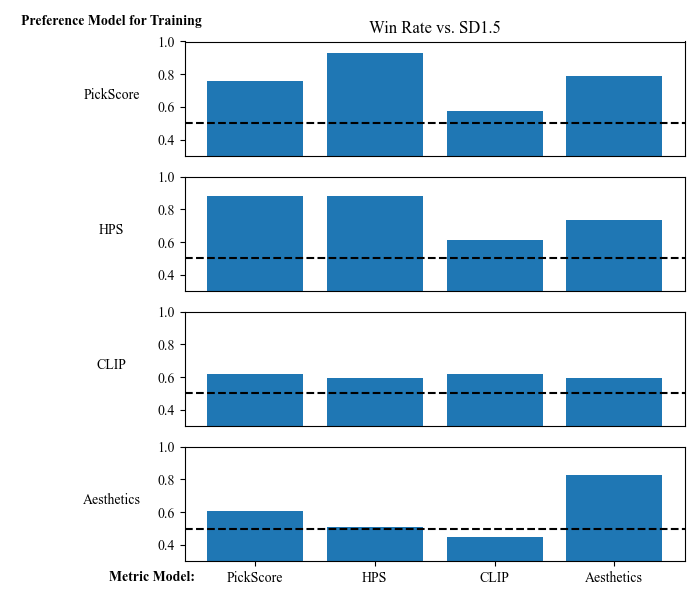
Figure 1(方法示意)解读:展示 Diffusion-DPO 的整体训练流程。给定一对 winner/loser 图像 和对应 prompt ,随机采样时间步 和噪声 ,对两张图像进行前向加噪得到 和 。可训练模型与冻结 reference 模型分别对两张加噪图像预测噪声,计算各自的 MSE 误差,再通过对比差值得到 DPO logit,最终用 logsigmoid 损失更新模型。
3.4 权重函数
是基于信噪比 定义的权重函数。在 DDPM 和 EDM 等工作中,实践上常令 (常数),即对所有时间步同等权重。本文延续这一惯例。这个常数被折入超参数 中,等价于只需调整 即可控制整体正则化强度。
3.5 与多步 RL 的关联
Eq. (14) 还可以从多步 RL(MDP)角度推导(附录 S3)。将 diffusion 去噪过程建模为 MDP:
- 状态
- 动作 (每步生成的去噪图)
- 稀疏 reward:,其余时间步 reward 为 0
通过逆 soft Bellman 算子和望远镜求和,可以得到与 Eq. (11) 等价的目标,证明 Diffusion-DPO 是与 DDPO、DPOK 在相同 MDP 框架下的 off-policy 算法,这也为 Eq. (13) 中的采样选择(用 替代 )提供了正当性。
3.6 Loss Surface 可视化
Figure 2 解读:可视化了 Eq. (14) 的 loss surface,横轴为 winner 图像的去噪误差变化量 ,纵轴为 loser 图像的去噪误差变化量,竖轴为 loss 值。Loss 可以通过提升 winner 的去噪精度(向左移动)或降低 loser 的去噪精度(向右移动)来减小。较大的 会增加 loss surface 的曲率,使模型对偏离 reference 更加敏感。
3.7 伪代码
伪代码 1:数据集构建(Winner/Loser Pair 构造)
# Pick-a-Pic v2 数据集:851,293 对,58,960 个唯一 prompt
# 每条记录包含:prompt c, winner image x_w, loser image x_l
# 预处理:
# 1. 过滤掉 tie(~12% 的数据)
# 2. 图像编码为 VAE latent(在 SDXL 中)
def build_dataset(raw_pickapic_data, vae, resolution=1024):
"""
raw_pickapic_data: 原始 Pick-a-Pic 数据集
returns: List of (prompt, x_w_latent, x_l_latent)
"""
pairs = []
for item in raw_pickapic_data:
if item['label'] == 'tie':
continue # 过滤平局
prompt = item['caption']
x_w = item['jpg_0'] if item['label'] == 0 else item['jpg_1']
x_l = item['jpg_1'] if item['label'] == 0 else item['jpg_0']
# 编码为 latent(SDXL 使用 VAE latent,SD1.5 使用 pixel)
x_w_latent = vae.encode(x_w).latent_dist.sample() * vae.config.scaling_factor
x_l_latent = vae.encode(x_l).latent_dist.sample() * vae.config.scaling_factor
pairs.append((prompt, x_w_latent, x_l_latent))
return pairs # 约 851,293 对伪代码 2:前向加噪(Winner 和 Loser 同步加噪)
def add_noise_paired(x_w, x_l, noise_scheduler, device):
"""
对 winner 和 loser 使用相同时间步和噪声(关键设计!)
x_w, x_l: [B, C, H, W] latent tensors
"""
# 将 winner 和 loser 沿 batch 维度拼接
feed_pixel_values = torch.cat([x_w, x_l], dim=0) # [2B, C, H, W]
# 采样时间步:为整个 batch 采样,然后 winner/loser 共享同一个 t
bsz = x_w.shape[0]
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps,
(bsz,), device=device)
timesteps = timesteps.repeat(2) # winner 和 loser 使用相同 t:[2B]
# 采样噪声:winner 和 loser 共享同一份噪声 ε
noise = torch.randn_like(feed_pixel_values[:bsz])
noise = noise.repeat(2, 1, 1, 1) # [2B, C, H, W]
# 前向加噪:x_t = α_t * x_0 + σ_t * ε
noisy_latents = noise_scheduler.add_noise(feed_pixel_values, noise, timesteps)
# noisy_latents[:B] = x_t^w, noisy_latents[B:] = x_t^l
return noisy_latents, noise, timesteps伪代码 3:DPO Loss 计算(模型 MSE vs Ref MSE → logit → logsigmoid)
def diffusion_dpo_loss(model, ref_model, x_w, x_l, prompt_embeds,
noise_scheduler, beta, device):
"""
完整的 Diffusion-DPO 损失计算(对应论文 Eq. 14 / 附录 S9 伪代码)
"""
# 步骤 1:前向加噪
noisy_latents, noise, timesteps = add_noise_paired(x_w, x_l, noise_scheduler, device)
bsz = x_w.shape[0]
# 步骤 2:模型前向传播(可训练模型)
model_pred = model(noisy_latents, timesteps, prompt_embeds).sample
# 步骤 3:Reference 模型前向传播(冻结,不参与梯度)
with torch.no_grad():
ref_pred = ref_model(noisy_latents, timesteps, prompt_embeds).sample.detach()
# 步骤 4:分割 winner/loser 预测
model_pred_w, model_pred_l = model_pred.chunk(2) # 各 [B, C, H, W]
ref_pred_w, ref_pred_l = ref_pred.chunk(2)
noise_w, noise_l = noise.chunk(2)
# 步骤 5:计算各自 MSE(对应论文 ‖ε - ε_θ(x_t, t)‖²)
# 对空间维度取平均
model_losses_w = (model_pred_w - noise_w).pow(2).mean(dim=[1, 2, 3]) # [B]
model_losses_l = (model_pred_l - noise_l).pow(2).mean(dim=[1, 2, 3]) # [B]
ref_losses_w = (ref_pred_w - noise_w).pow(2).mean(dim=[1, 2, 3]) # [B]
ref_losses_l = (ref_pred_l - noise_l).pow(2).mean(dim=[1, 2, 3]) # [B]
# 步骤 6:计算相对误差差值
# model_diff = (model_w_err - model_l_err):正值表示模型对 winner 误差更大
model_diff = model_losses_w - model_losses_l
ref_diff = ref_losses_w - ref_losses_l
# 步骤 7:DPO logit(inside_term)
# 对应论文 -βTω(λ_t)(‖ε^w - ε_θ(x_t^w,t)‖² - ‖ε^w - ε_ref(x_t^w,t)‖²
# -(‖ε^l - ε_θ(x_t^l,t)‖² - ‖ε^l - ε_ref(x_t^l,t)‖²))
# 等价于 -β*(model_diff - ref_diff),系数 -0.5 吸收了 T
scale_term = -0.5 * beta
inside_term = scale_term * (model_diff - ref_diff) # [B]
# 步骤 8:最终损失:-logsigmoid(inside_term)
loss = -F.logsigmoid(inside_term).mean()
# 隐式准确率:inside_term > 0 表示模型对 winner 的相对去噪更好
implicit_acc = (inside_term > 0).float().mean()
return loss, implicit_acc注意:论文附录 S9 的伪代码使用 norm().pow(2) 计算误差的 L2 norm 的平方,实现代码 train.py 中则使用 .pow(2).mean(dim=[1,2,3])(空间平均),两者等价(只差一个常数因子,被 吸收)。
伪代码 4:Beta 超参数搜索与验证
def beta_sweep_and_validate(train_dataset, val_prompts, beta_candidates,
base_model, ref_model, pickscore_model,
num_train_steps=1000):
"""
Beta 超参数搜索:在 Pick-a-Pic v2 验证集上自动选择最佳 beta
论文发现 SD1.5 最优 β ∈ [2000, 5000],SDXL 最优 β = 5000
"""
results = {}
for beta in beta_candidates: # e.g. [1000, 2000, 5000, 10000]
# 训练 DPO 模型(指定步数)
dpo_model = train_dpo(base_model, ref_model, train_dataset,
beta=beta, steps=num_train_steps)
# 在验证集上生成图像
val_images = []
for prompt in val_prompts: # 500 unique Pick-a-Pic v2 val prompts
img = dpo_model.generate(prompt)
val_images.append(img)
# 计算 median PickScore(自动评估指标)
scores = [pickscore_model.score(prompt, img)
for prompt, img in zip(val_prompts, val_images)]
median_score = np.median(scores)
results[beta] = median_score
print(f"β={beta}: Median PickScore={median_score:.4f}")
best_beta = max(results, key=results.get)
print(f"Best β: {best_beta}")
return best_beta, results
# 论文结果(见 Figure S2):
# SD1.5: β=1000 → 0.207, β=2000 → 0.212, β=5000 → 0.211, β=10000 → 0.208
# 最优 β=2000(SD1.5),β=5000(SDXL)3.8 代码-论文对应表
| 论文符号 | 代码变量 | 含义 |
|---|---|---|
model_pred_w | 可训练模型对 winner 的噪声预测 | |
ref_pred_w | 冻结 reference 对 winner 的噪声预测 | |
model_pred_l | 可训练模型对 loser 的噪声预测 | |
ref_pred_l | 冻结 reference 对 loser 的噪声预测 | |
model_losses_w | Winner 的模型 MSE | |
model_losses_l | Loser 的模型 MSE | |
ref_losses_w | Winner 的 reference MSE | |
ref_losses_l | Loser 的 reference MSE | |
scale_term = -0.5 * beta | 正则化强度(T 折入 , 为符号调整) | |
inside_term | DPO logit | |
-F.logsigmoid(inside_term) | 最终损失 | |
implicit_acc | 隐式偏好准确率 | |
args.beta_dpo | 散度惩罚超参数(SD1.5: 2000,SDXL: 5000) |
4. 实验设置 (Experimental Setup)
模型与数据集
- 基础模型:SD1.5(
runwayml/stable-diffusion-v1-5)和 SDXL-1.0 base(stabilityai/stable-diffusion-xl-base-1.0) - 训练数据:Pick-a-Pic v2 数据集,851,293 对成对偏好数据,58,960 个唯一 prompt(过滤约 12% 的平局对后)
- 数据来源:Pick-a-Pic 网页应用,由用户对 SDXL-beta 和 Dreamlike(SD1.5 的精调版本)的生成图像进行偏好标注
超参数
- 优化器:SD1.5 使用 AdamW;SDXL 使用 Adafactor(节省显存)
- Batch size:有效 batch size 2048 对(16 张 A100 GPU,local batch size 1 对,梯度累积 128 步)
- 学习率:,带 25% linear warmup(学习率与 成反比,对应 DPO 目标梯度范数正比于 的设计)
- 分辨率:正方形分辨率,多尺度训练
- :SD1.5: 2000,SDXL: 5000(通过 PickScore 在验证集上 sweep 选定)
评估设置
自动评估:在 Pick-a-Pic v2 验证集的 500 个唯一 prompt 上生成,计算 median PickScore 作为 checkpoint 选择依据。
最终人类评估:在两个 benchmark 上生成图像,部署到 Amazon Mechanical Turk:
- PartiPrompts(1632 个 caption)
- HPSv2(3200 个 caption)
每次比较收集 5 名标注员的回答,多数票()作为最终决策。三个评估维度:
- Q1 General Preference:总体偏好哪张图?
- Q2 Visual Appeal:哪张视觉上更吸引人?(不考虑 prompt)
- Q3 Prompt Alignment:哪张更符合文字描述?
5. 实验结果 (Experimental Results)
5.1 主要结果:人类评估
Figure 3 解读:上方条形图对比了 DPO-SDXL 与 SDXL base 的人类评估胜率(50% 为平局基准线)。DPO-SDXL 在 PartiPrompts 上的 General Preference (Q1) 胜率达到 70.0%,Visual Appeal (Q2) 为 64.3%,Prompt Alignment (Q3) 为 64.9%。在 HPSv2 上,General Preference 为 64.7%,Visual Appeal 为 61.9%,Prompt Alignment 为 64.9%。

Figure 3 解读:下方定性对比展示 DPO-SDXL 生成图像具有更鲜明的色彩、更戏剧化的光照、更好的构图和更真实的人物/动物解剖结构,同时对 prompt 细节(如服装颜色、场景描述)的忠实度也更高。
HPSv2 Reward Model 评分:DPO-SDXL 在 HPSv2 reward model 上的平均奖励为 28.16,位居当时开源模型排行榜榜首。
5.2 DPO-SDXL vs 完整 SDXL Pipeline(Base + Refiner)
Figure 4 解读:对比 DPO-SDXL(仅 base,3.5B 参数)与完整 SDXL pipeline(base + refinement model,6.6B 参数)的人类评估结果。DPO-SDXL 在 PartiPrompts General Preference (Q1) 上胜率 69.0%,在 HPSv2 General Preference 上为 64.0%,显著击败了参数量是其两倍的完整 SDXL pipeline。DPO-SDXL 尤其擅长生成高质量的解剖细节(牙齿、手、眼镜),这些特征通常需要 refinement model 才能完善,但 DPO 训练已将此能力内化。
People 类别:在 PartiPrompts 的 People 类别中,DPO-SDXL 相对于 SDXL base + refiner 的胜率仍达 67.2%(相对 SDXL base 为 73.4%),体现了在人物细节生成上的卓越性能。
5.3 图像到图像编辑(Image-to-Image)
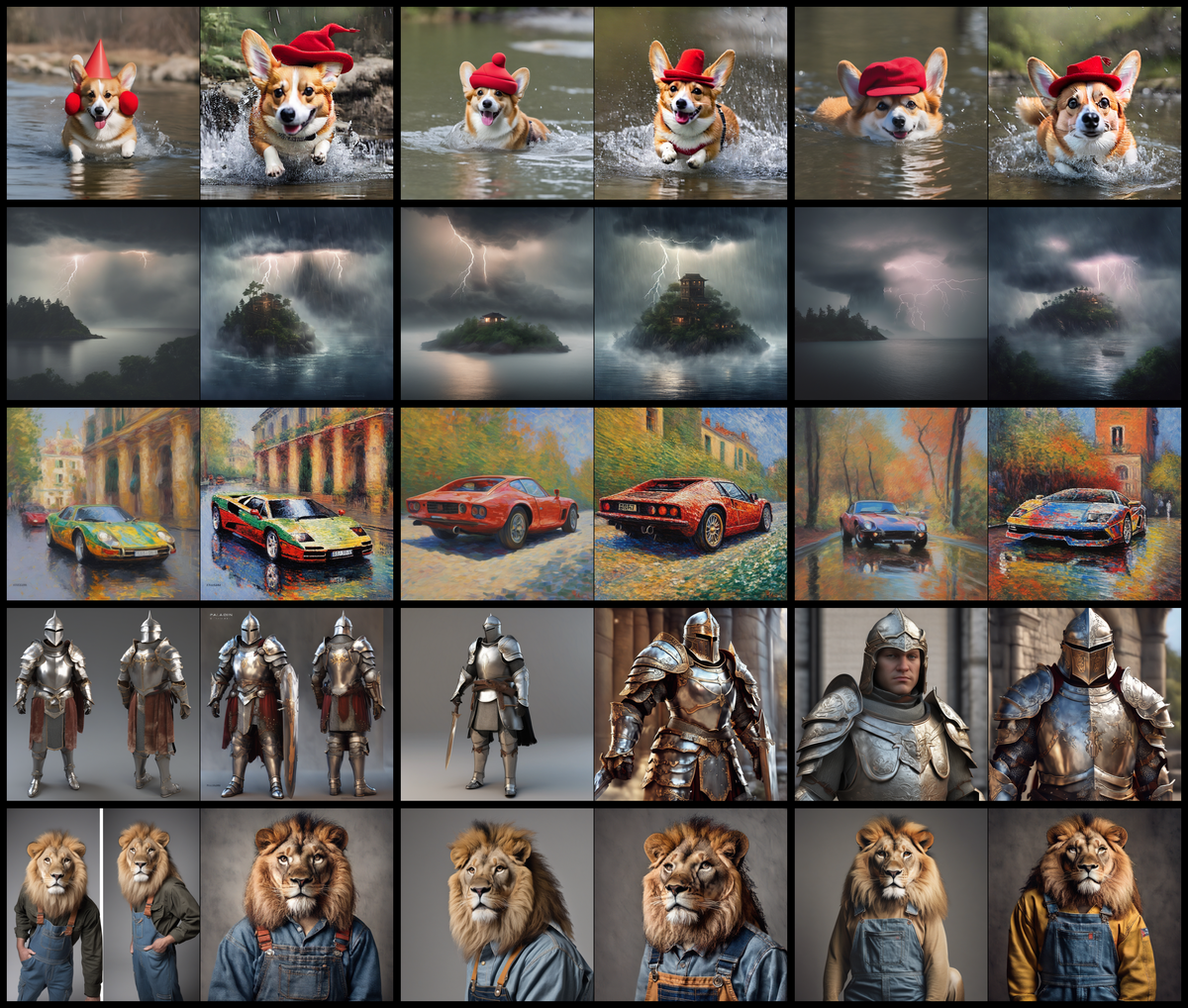
Figure 5 解读:展示 DPO-SDXL 在图像到图像翻译任务(使用 SDEdit,strength=0.98)上的改进效果,测试于 TEd-Bench 的 100 个真实图像-文本对。左列为原始图像,中列为 SDXL 生成结果,右列为 DPO-SDXL 生成结果。DPO-SDXL 生成的图像视觉细节更丰富,色彩更生动,同时更好地遵循文本描述。人类评估中,DPO-SDXL 在 65% 的情况下被偏好(SDXL 为 24%,11% 平局)。
5.4 AI 反馈学习
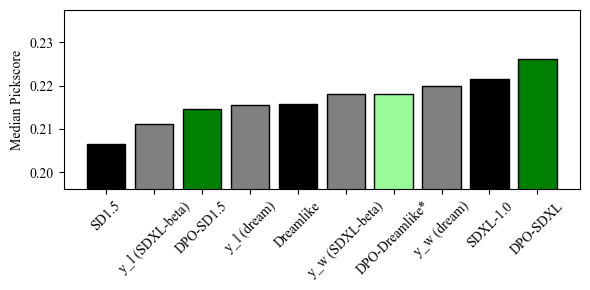
Figure 6 解读:自动 head-to-head 胜率(y 轴为不同 reward model,x 轴为不同 AI 反馈类型训练的 SD1.5 DPO 模型)。用 PickScore 伪标签训练的 DPO 模型在 PickScore 和 HPS 两个指标上的胜率均高于 baseline,而 Aesthetics 训练只在美学方面提升,以 CLIP 文本对齐为代价。PickScore 反馈对原始 Pick-a-Pic 数据集是一种”伪标签”形式的数据清洗,General Preference 胜率从 59.8% 提升到 63.3%。
AI 反馈实验具体结果(SD1.5,,1000 steps):
- PickScore 伪标签训练:General Preference 胜率 63.3%(vs 人工标注 baseline 59.8%)
- HPS 偏好训练:同时提升 Raw Visual Appeal 和 Prompt Alignment
Preference Accuracy on Pick-a-Pic v2 Validation Set(Table 2):
| 模型 | PS | HPS | CLIP | Aesthetics |
|---|---|---|---|---|
| PickScore | 64.2 | 59.3 | 57.1 | 51.4 |
| DPO-SD1.5 | 60.8 | — | — | — |
| DPO-SDXL | 72.0 | — | — | — |
DPO-SDXL 在偏好分类准确率上超越所有现有 reward 模型,验证了 Diffusion-DPO 隐式 reward 参数化的有效性。
5.5 Beta 消融分析
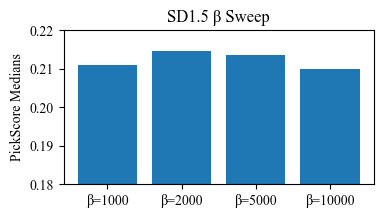
Figure S2 解读:SD1.5 上不同 值的 PickScore 中位数对比(Pick-a-Pic v2 验证集)。 和 表现最佳,约为 0.211-0.212。 时模型退化为近似纯 reward 评分模型(丢失分布约束), 时 KL 惩罚过强,限制了有效学习。
5.6 Rejection Sampling 对比(附录 S8)
PickScore 拒绝采样(rejection sampling)是推理时强力基线:100 次采样选最高 PickScore。测试结果:
- PickScore 拒绝采样的 human-preferred 比例为 71.4%(100 次采样取最高分)
- 需要约 10× 推理代价 才能与单次 DPO 生成持平(SD1.5 和 SDXL 均如此)
- 对于 7%(SDXL)和 16%(SD1.5)的 prompt,即使 100 次采样仍不足以超过单次 DPO 生成
这表明 Diffusion-DPO 训练的质量增益无法仅靠推理时计算复制,体现了 DPO 微调的内在价值。
5.7 Supervised Fine-Tuning (SFT) 对比
对 Pick-a-Pic 中 preferred 图像 进行 SFT,结果:
- SFT 对原始 SD1.5 有改善(55.5% 胜率)
- 但任意学习率下 SFT 均会损害 SDXL 性能
原因:SDXL base 质量已远优于 Pick-a-Pic 训练数据(由 SDXL-beta 和 Dreamlike 生成),SFT 相当于用低质量数据微调高质量模型。DPO 则通过相对对比学习,不依赖 winner 图像的绝对质量。
5.8 训练数据质量分析
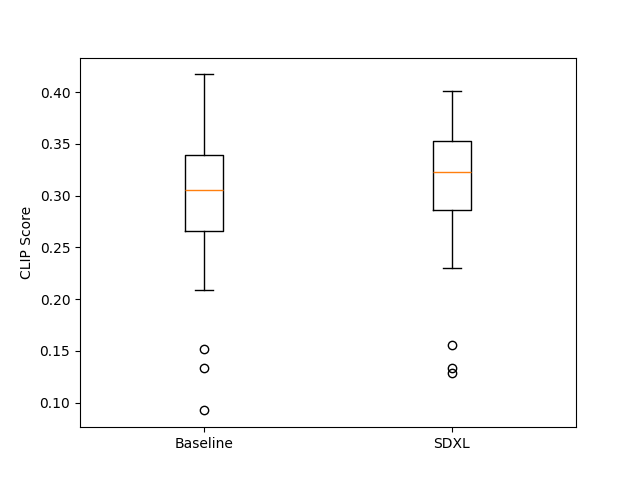
Figure 7 解读:展示 DPO 在 in-distribution(Dreamlike)和 out-of-distribution(SDXL)数据上的改进效果,以 Pickscore 的 Median 为指标。尽管 SDXL 生成的图像质量(包括 winner )已经高于训练数据,DPO 训练仍能将 SDXL 的性能提升(out-of-distribution generalization)。 和 分别表示 loser 和 winner 样本的 PickScore。DPO-Dreamlike 相对于 Dreamlike baseline 有温和但一致的提升;DPO-SDXL 的提升最为显著。