DDRL: Data-regularized Reinforcement Learning for Diffusion Models at Scale
Authors: Haotian Ye, Kaiwen Zheng, Jiashu Xu, Puheng Li, Huayu Chen, Jiaqi Han, Sheng Liu, Qinsheng Zhang, Hanzi Mao, Zekun Hao, Prithvijit Chattopadhyay, Dinghao Yang, Liang Feng, Maosheng Liao, Junjie Bai, Ming-Yu Liu, James Zou, Stefano Ermon Affiliations: Stanford University, NVIDIA, Tsinghua University arXiv: 2512.04332 Project Page: research.nvidia.com/labs/dir/ddrl GitHub: nvidia-cosmos/cosmos-rl Year: 2025
1. Motivation(研究动机)
将扩散模型与人类偏好对齐是生成模型领域的核心挑战。现有的 RL 后训练方法(如 DanceGRPO、FlowGRPO)普遍存在 reward hacking 问题:模型获得更高的奖励分数,但生成质量反而下降(过度风格化、失真、多样性降低)。
本文深入分析发现,reward hacking 的根本原因在于 on-policy 正则化的内在缺陷:
-
Reverse KL 正则化失效:现有方法使用 reverse KL 散度 约束策略不偏离参考模型。但由于 KL 是在 的 on-policy 样本上计算的,当策略被 reward 驱动偏离数据流形时,中间状态 进入参考模型未充分训练的 OOD 区域,正则化信号变得不可靠。
-
多步马尔可夫采样放大偏移:扩散模型的去噪过程是多步马尔可夫链,虽然单步 KL 偏移可能很小,但累积的轨迹偏移非常显著,使得 reverse KL 无法有效约束策略。
-
奖励模型的不可验证性:视觉领域的 reward model 大多是在训练数据流形邻域内学习的近似模型,不是真实偏好 的精确表示。高 reward 并不一定意味着更好的样本。
核心洞察:问题的根源是 on-policy 采样——应该使用 off-policy 数据分布 来锚定正则化,即用 forward KL 散度 替代 reverse KL,从而将正则化从不可靠的 on-policy 计算转换为可靠的 off-policy diffusion loss 计算。

Figure 1 解读:对比了从同一 Cosmos2.5-2B checkpoint 出发,使用不同 RL 算法后训练的视频生成效果。DDRL 生成的视频在提升 reward 的同时保持了 prompt 对齐和视觉真实性。DanceGRPO 虽然 reward 最高(如 1.19),但出现过度上色、静态化、不遵循 prompt 等 hacking 现象。FlowGRPO 则产生模糊、网格伪影等质量问题。DDRL 是唯一同时提升 reward 且不出现 hacking 的方法。

Figure 2 解读:左图展示训练过程中的 reward 变化曲线——DanceGRPO 和 FlowGRPO 的 reward 持续攀升但发生 hacking,DDRL()稳定提升且无 hacking。右图展示双盲人类投票结果:DDRL 的视频更受人类偏好(超过 50% 胜率),而 DanceGRPO 和 FlowGRPO 甚至不如 base model(胜率低于 50%),说明高 reward 并不等于高人类偏好。
2. Idea(核心思想)
DDRL 的核心思想可以用一句话概括:用 diffusion loss(即 forward KL 散度)替代 reverse KL 散度来正则化 RL 训练,将 on-policy 奖励最大化与 off-policy 数据正则化优雅结合。
具体而言:
Forward KL 替代 Reverse KL:传统方法在 的 on-policy 样本上计算 ,DDRL 改为在 off-policy 数据上计算 ,其中 是参考模型的 forward 过程分布。这等价于标准 diffusion training loss,天然不依赖 on-policy 采样。
理论保证:DDRL 的最优策略满足 ,与经典 RL 理论中的最优分布一致,但正则化项基于数据分布而非参考模型的 on-policy 分布。
SFT + RL 统一:DDRL 的目标函数自然地将 SFT(diffusion loss 最小化)与 RL(reward 最大化)统一到同一个框架中,可以替代传统的 SFT-then-RL 两阶段 pipeline。
无需参考模型推理:由于正则化通过 diffusion loss 在数据上计算,DDRL 不需要在训练时维护或推理参考模型,节省显存和计算。
3. Method(方法)
3.1 背景:扩散模型的 RL 后训练
扩散模型学习条件数据分布 ,前向过程定义为:
模型通过最小化以下 diffusion loss 训练:
RL 后训练的目标是最大化:
现有方法使用 reverse KL 约束,其中 reverse KL 通过 on-policy 样本估计:
3.2 Reverse KL 失效的理论分析

Figure 3 解读:即使将 FlowGRPO 的正则化系数 设为非常大的值 0.1,KL 散度在训练中保持稳定,但生成的视频仍然出现噪声纹理等 hacking 现象。这证明了 reverse KL 正则化在根本上无法阻止 reward hacking——因为 KL 的计算依赖 on-policy 样本,当 移至 OOD 区域时, 无法提供有效的惩罚信号。
3.3 DDRL 目标函数
DDRL 最大化以下目标:
其中:
- 是单调变换函数
- 是归一化常数(“平均奖励”,将绝对奖励转换为相对优势)
- 是参考模型的 forward 过程分布(而非 denoised 过程),定义为:
关键等价变换:通过 Theorem 3.1,DDRL 的目标等价于:
即 奖励最大化 + diffusion loss 最小化。 等价于标准 diffusion loss ,其中数据从 采样(可以是真实数据或合成数据)。
Theorem 3.1:最优策略满足
3.4 Algorithm 1: DDRL 伪代码
def ddrl_training(theta, p_data, reward_model, T_steps: set, beta: float, N: int):
"""Data-regularized Diffusion Reinforcement Learning (DDRL) - Algorithm 1"""
for iteration in training_iterations:
# Sample condition and clean data from off-policy distribution
c = sample_condition()
x0_clean = p_data.sample(c)
# On-policy rollouts and reward computation
rollouts = [p_theta.rollout(c) for _ in range(N)] # {x0^n}_{n=1}^N
rewards = [reward_model(x0_n, c) for x0_n in rollouts]
# GRPO-style group-normalized advantage
advantages = [(r - mean(rewards)) / (beta * std(rewards)) for r in rewards]
loss = 0.0
for t in T_steps:
for n in range(N):
eps_n = sample_noise() # eps^n ~ N(0, I)
x_t_n = add_noise(x0_clean, eps_n, t) # noisy data
# Diffusion loss (off-policy data regularization)
L_diff = norm(eps_theta(x_t_n, t, c) - eps_n)
# RL reward term (on-policy policy gradient)
L_rl = -advantages[n] * log_prob(p_theta, x_t_n, t, c)
loss += L_diff + L_rl
# Gradient descent update
theta = gradient_step(theta, loss)3.5 实践细节
时间步选择:使用 表示 DDRL 优化的时间步集合。类似 DanceGRPO 的观察,优化一半时间步即可获得足够效果,DDRL 每隔一步优化一次(,共 步)。
Guidance:DDRL 不使用 classifier-free guidance(CFG),遵循 diffusion training 标准做法,以 20% 概率丢弃 condition 来计算 diffusion loss。
优势计算:使用 GRPO 风格的组内归一化优势 ,其中 mean 和 std 在 rollout 组内计算。
高效 diffusion loss 计算:vanilla 实现中每个数据点需计算 次 diffusion loss。论文发现可以随机采样 仅计算一次(“Reduced” 版本),NFE 从 降到 ,性能几乎不变。
3.6 内存与效率优势
| 特性 | DDRL | DanceGRPO | FlowGRPO |
|---|---|---|---|
| 需要参考模型 | ✗ | ✗ | ✓ |
| 需要旧模型 | ✗ | ✗ | ✓ |
| 与 SFT 统一 | ✓ | ✗ | ✗ |
| NFE / 数据点 | ~$N(1+ | \mathcal{T} | )$ |
4. Experimental Setup(实验设置)
4.1 视频生成实验
基础模型:
- Cosmos2.5-2B 和 Cosmos2.5-14B(dense transformer-based diffusion model)
- 使用 Wan-2.1 VAE 编解码,输出分辨率 (1280, 720) 或 (720, 1280)
- 视频长度 93 帧(24 latent frames,FPS=16)
- 文本编码器:Cosmos-Reason1
奖励模型:
- VideoAlign [21]:微调 Qwen2-vl,评估视觉质量、运动质量、文本对齐三项均分
- VBench [16]:包含 subject consistency、background consistency、motion smoothness、aesthetic quality、imaging quality 五项均分
训练配置:
| 参数 | Cosmos2.5-2B | Cosmos2.5-14B |
|---|---|---|
| GPU 数量 | 256 H100 | 1024 H100 |
| Batch size(unique conditions) | 16 | 16 |
| Rollout size | 8 | 8 |
| CP 并行(GPU / data copy) | 2 | 8 |
| 优化器 | AdamW () | 同左 |
| 学习率 | 1e-5 | 3e-6 |
| 总 GPU 时数 | >1M H100 GPU hours | (包含在内) |
Baseline 超参数对比:
| Method | | | | 使用 ? | |--------|-----|---------|---------|---------| | DanceGRPO | 20 | 12 | 0 | ✗ | | FlowGRPO | 10 | 10 | [0.001, 0.1] | ✓ | | DDRL | 20 | 10 | 0.01 | ✗ |
数据:T2V 和 I2V 按 1:1 混合;使用高质量 SFT 数据集的子集(<8000 unique data points);训练 ≤1000 iterations。
评估:
- 测试集:PAI-Bench(1044 prompts,覆盖 human/industry/robotics/driving/others 五类)
- 35 denoising steps,guidance strength 7(2B)/ 3(14B)
- 核心指标:大规模双盲人类投票(15 位评估者,~9600 比较对,~10000 投票结果)
- 报告 -Vote = DDRL 胜率 - 对手胜率
4.2 图像生成实验
- 基础模型:SD3.5-Medium(512×512)
- 设置与 FlowGRPO 对齐,使用 OCR reward(edit distance)
- LoRA 微调()
- 使用 base model 合成数据做 diffusion loss 正则化(无需真实数据)
- 训练约 300 iterations
5. Results(实验结果)
5.1 主实验:DDRL 全面优于 Baseline
Table 1 核心结果:在两个模型(2B, 14B)× 两种奖励(VideoAlign, VBench)× 两种设置(T2V, I2V)共 8 个配置下:
| Base Model | Method | VA T2V -Vote↑ | VA T2V Reward | VA I2V -Vote↑ | VA I2V Reward | VB T2V -Vote↑ | VB I2V -Vote↑ |
|---|---|---|---|---|---|---|---|
| Cosmos2.5-2B | w/o RL | -22.9 | 0.408 | -4.2 | 0.079 | -8.9 | -15.7 |
| DanceGRPO | -10.5 | 0.715 | -6.4 | 0.254 | -6.9 | -8.0 | |
| FlowGRPO | -6.7 | 0.408 | -13.0 | 0.069 | -4.2 | -9.6 | |
| DDRL | 0 | 0.604 | 0 | 0.177 | 0 | 0 | |
| Cosmos2.5-14B | w/o RL | -8.4 | 0.359 | -12.5 | 0.058 | -4.5 | -4.5 |
| DanceGRPO | -4.9 | 0.494 | -5.9 | 0.160 | -3.1 | -4.2 | |
| FlowGRPO | -6.7 | 0.476 | -11.6 | 0.128 | -7.3 | -5.4 | |
| DDRL | 0 | 0.555 | 0 | 0.134 | 0 | 0 |
关键发现:
- DDRL 在所有 8 个配置中人类投票均为第一(-Vote 定义为相对 DDRL,故 DDRL 始终为 0,其他方法均为负数)
- DanceGRPO reward 最高但人类不喜欢(reward hacking),标记为斜体的 reward 值表示 hacking
- FlowGRPO 有时甚至无法提升 reward(如 VA T2V 2B: 0.408 = base model)
- DDRL 是唯一能同时提升 reward 和人类偏好的方法(“Pareto improvement”)
5.2 Reward Hacking 分析

Figure 4 解读:雷达图展示了 2B 模型 post-training 后在 text alignment (TA)、visual quality (VQ)、motion quality (MQ) 三个维度上的变化。DanceGRPO 在 T2V 上 TA 下降 16%,I2V 上下降 28%,说明它以牺牲文本对齐来获取高平均 reward。DDRL 在三个维度上实现均衡提升,是唯一实现 “Pareto improvement” 的方法。
5.3 Ablation: 训练迭代数与时间步调度
Table 3 消融实验:
| schedule | Iteration | NFEs per | T2V Reward | I2V Reward |
|---|---|---|---|---|
| DDRL | 128 | $2N | \mathcal{T} | $ |
| DDRL | 256 | $2N | \mathcal{T} | $ |
| Reduced | 256 | $N(1+ | \mathcal{T} | )$ |
- DDRL 可以安全地训练更长时间(256 iterations)而不 hacking,reward 持续提升
- “Reduced” 版本以约一半的 NFE 达到接近的效果
5.4 SFT-RL 一体化

Figure 5 解读:对比两种训练策略:(1) 先 SFT 20K iterations 再 DDRL;(2) 直接从 pretrained model 用 DDRL。两者在 T2V 上达到几乎相同的 reward(~0.48),但直接 DDRL 的数据效率显著更高(在 时已接近 SFT+DDRL 在 时的效果)。I2V 上直接 DDRL 也能达到可比的效果。这证明 DDRL 有潜力统一 SFT 和 RL 为一个阶段。
5.5 使用合成数据做正则化(图像生成)

Figure 6 解读:在 SD3.5-Medium 上进行 text-to-image OCR 任务的对比。DDRL 在获得与其他方法相当的 OCR 准确率的同时,保持了与 base model 一致的风格和真实感。DanceGRPO 和 FlowGRPO 则生成过度简化、卡通化的图像来”hack” OCR reward。
Table 4 图像生成定量结果:
| Method | -Vote↑ (%) | OCR↑ | ClipScore↓ | PickScore↓ | ImageReward↓ |
|---|---|---|---|---|---|
| w/o RL | — | 0.566 | 0.321 | 0.865 | 1.13 |
| DanceGRPO | -53.0 | 0.846 | 0.309 | 0.837 | 0.80 |
| FlowGRPO | -22.1 | 0.845 | 0.313 | 0.855 | 1.03 |
| DDRL | 0 | 0.823 | 0.320 | 0.865 | 1.14 |
- DanceGRPO 人类偏好暴跌 53%,严重 hacking
- DDRL OCR 提升且 OOD 指标(ClipScore, PickScore, ImageReward)保持与 base model 一致
- DDRL 甚至使用合成数据做正则化即可有效,无需访问原始训练数据
5.6 Reward Server 架构
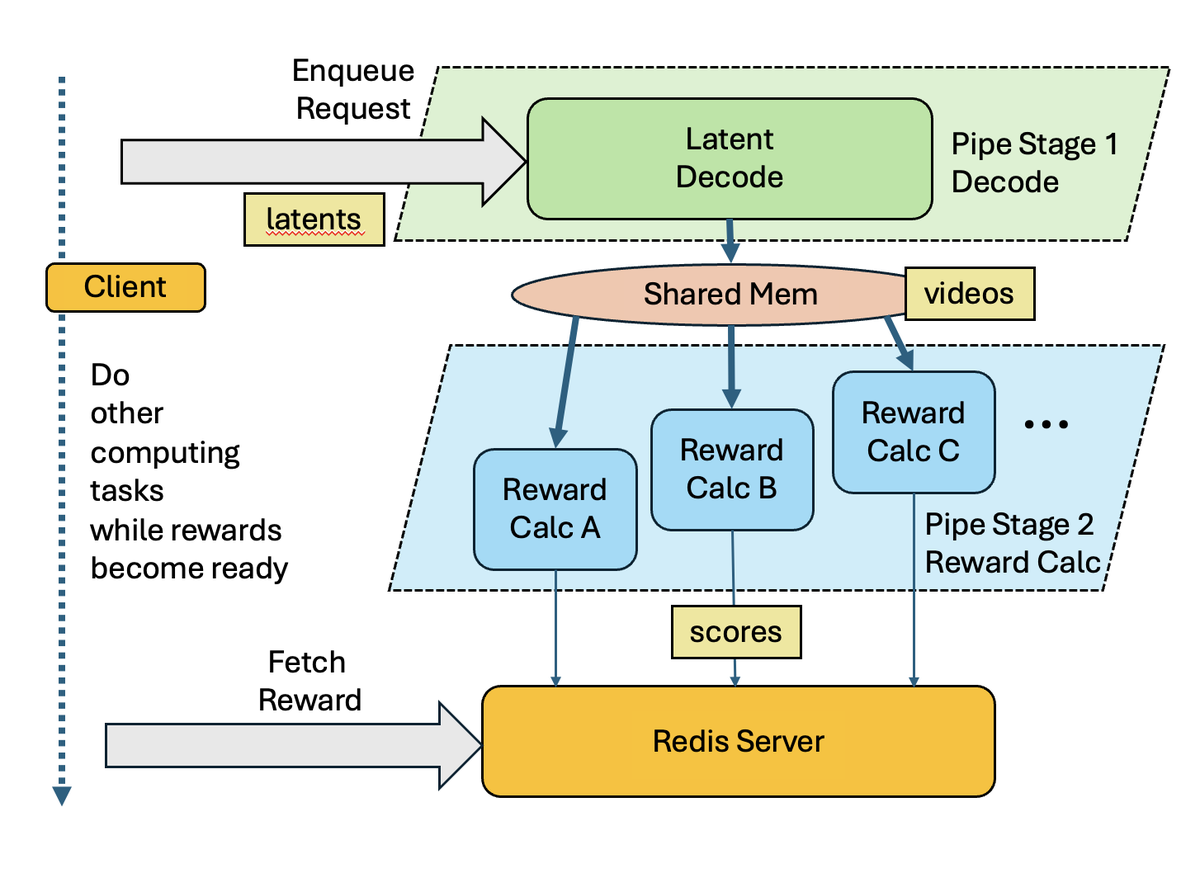
Figure 7 解读:NVIDIA 设计了高吞吐异步 reward 计算服务架构。训练端发送 latent 到 reward server,经过 latent decode → video 重建 → 多个 reward model 并行计算(VBench、VideoAlign、Cosmos-Reason1-7B-Reward 等)。使用 CUDA IPC 实现 GPU 间零拷贝共享,Redis 存储奖励结果。训练端在等待 reward 期间可计算 diffusion loss,避免阻塞。
代码与论文映射表
| 论文概念 | cosmos-rl 代码位置 | 说明 |
|---|---|---|
| DDRL 目标函数 Eq. (9) | cosmos_rl/policy/config/wfm/__init__.py | RLConfig class 定义核心超参数 |
data_beta = 0.01 | 配置文件 configs/cosmos-predict2-5/ | 对应论文中 系数 |
num_rollout = 8 | RLConfig.num_rollout | 对应 rollout size |
sample_steps = 20 | RLConfig.sample_steps | 对应总去噪步数 |
clip_ratio = 0.0001 | RLConfig.clip_ratio | PPO-style clipping(论文中使用非常小的值) |
kl_beta = 0.0 | RLConfig.kl_beta | DDRL 不使用 reverse KL(设为 0) |
solver_option = “2ab” | RLConfig.solver_option | 采样器选择 |
s_churn = 1.0 | RLConfig.s_churn | 采样随机性控制 |
| Reward server | 独立服务,环境变量配置 | 异步计算,512 GPU |
| 2B 配置 | cosmos-predict2-5-2b-720-reason-embedding-ddrl.toml | 256 GPU,CP=2 |
| 14B 配置 | cosmos-predict2-5-14b-720-reason-embedding-ddrl.toml | 1024 GPU,CP=8 |