Calibri: Enhancing Diffusion Transformers via Parameter-Efficient Calibration
Paper: arXiv:2603.24800 Code: v-gen-ai/Calibri Code reference:
main@dee7bda6(2026-04-13)
1. Motivation (研究动机)
现有 DiT / MM-DiT 文生图模型(FLUX.1-dev、SD-3.5M、Qwen-Image)质量很高,但默认推理把所有 transformer block 的残差贡献固定为训练后权重,没有显式校准每层在不同 denoising 轨迹中的贡献。论文的动机实验表明:把某些 DiT block 的输出绕过(等价于将公式中的 gate/残差贡献乘以 0)并不总是降低 ImageReward,个别 block 被削弱后反而能提升生成质量;进一步把 block 输出乘以 时,每个 block 往往存在不同的更优 scaling。

Figure 1 解读:Calibri 的核心不是重新训练整套 DiT,而是在原模型的 DiT block / gate 外部放少量可搜索的 scale。这样做把“模型对 reward 的偏好对齐”从百万/千万级参数微调,变成约 个校准系数的黑盒搜索问题。
这篇论文要解决的具体问题是:在不更新原始 DiT 权重的前提下,找到一组轻量 calibration coefficients,使 reward model 评价的生成质量上升,同时把推理 NFE 从原模型常用的 30/80/100 降到 15/30 左右。这个问题值得研究,因为它把偏好对齐和推理加速合并成一个离线、小参数搜索过程;如果成立,模型发布方可以只发布少量 JSON scale,而不是完整 LoRA/finetuned checkpoint。
2. Idea (核心思想)
Calibri 的核心洞察是:DiT block 的输出贡献不是“训练后就不可动”的常数,而更像推理时可以调节的音量旋钮。只要对 attention、MLP、MM-DiT text/visual gates 或整个 block 的输出加标量系数,就能改变 denoising trajectory 的质量;由于可调维度只有几十到几百,直接用 reward model + CMA-ES 做黑盒优化比通过 diffusion/RL 反传更简单。
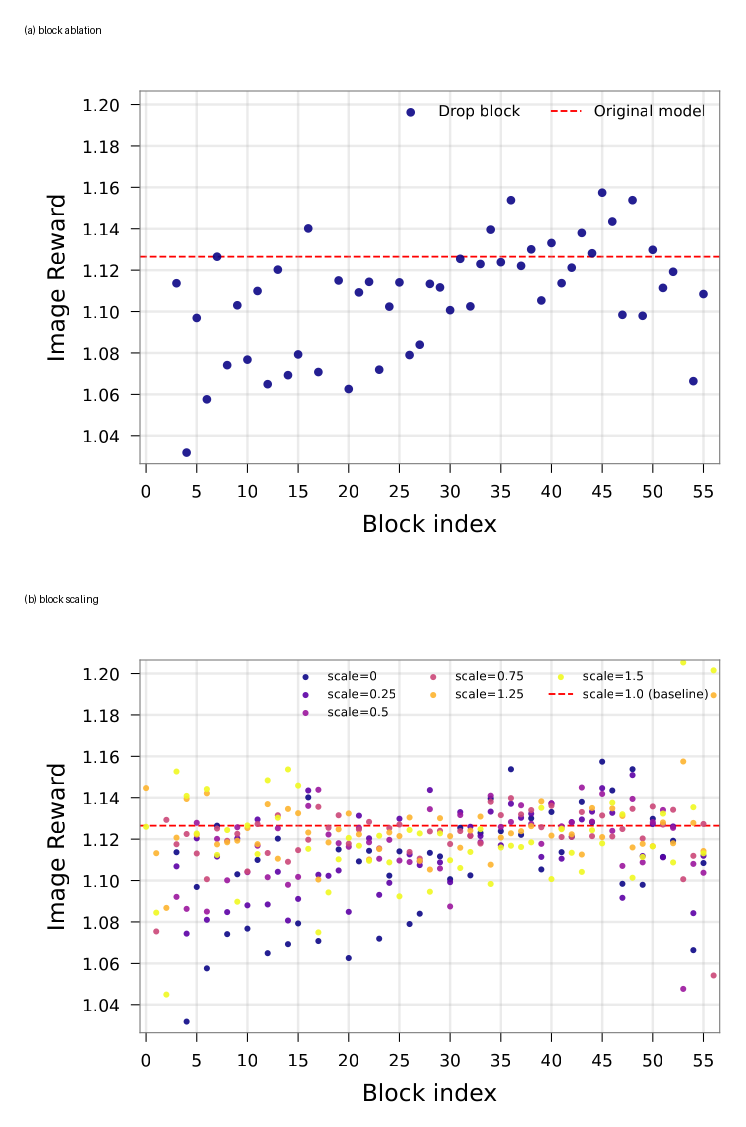
Figure 3 解读:上半部分展示 block ablation 时不同层对 ImageReward 的影响并不均匀;下半部分展示同一层在不同 scaling 下的 reward 曲线。它支撑了 Calibri 的前提:不是所有层都应该按默认残差强度参与推理,逐层 scale 有实际可优化空间。
和 Flow-GRPO / DDPO 这类 reward-driven finetuning 不同,Calibri 不把 diffusion process 改写成可训练策略,也不更新 LoRA 或 backbone 权重;它只搜索推理时插入的 scale vector 。和 Skip Layer Guidance / Autoguidance 相比,Calibri 不是手工选层或固定 guidance 规则,而是把 block/layer/gate scale 与 ensemble 权重一起作为 reward objective 的优化变量。
3. Method (方法)
3.1 DiT / MM-DiT 被校准的位置
标准 DiT block 的两个残差分支可写为:
MM-DiT 则分别对 visual/text tokens 使用 和 ,attention 层负责跨模态通信。Calibri 的 scale 实际作用在这些 residual/gate 输出上:block scaling 用一个系数统一调节同一 block 内 attention+MLP;layer scaling 分别调 attention 与 MLP;gate scaling 进一步区分 MM-DiT 中 visual/text 或 context/main gates。
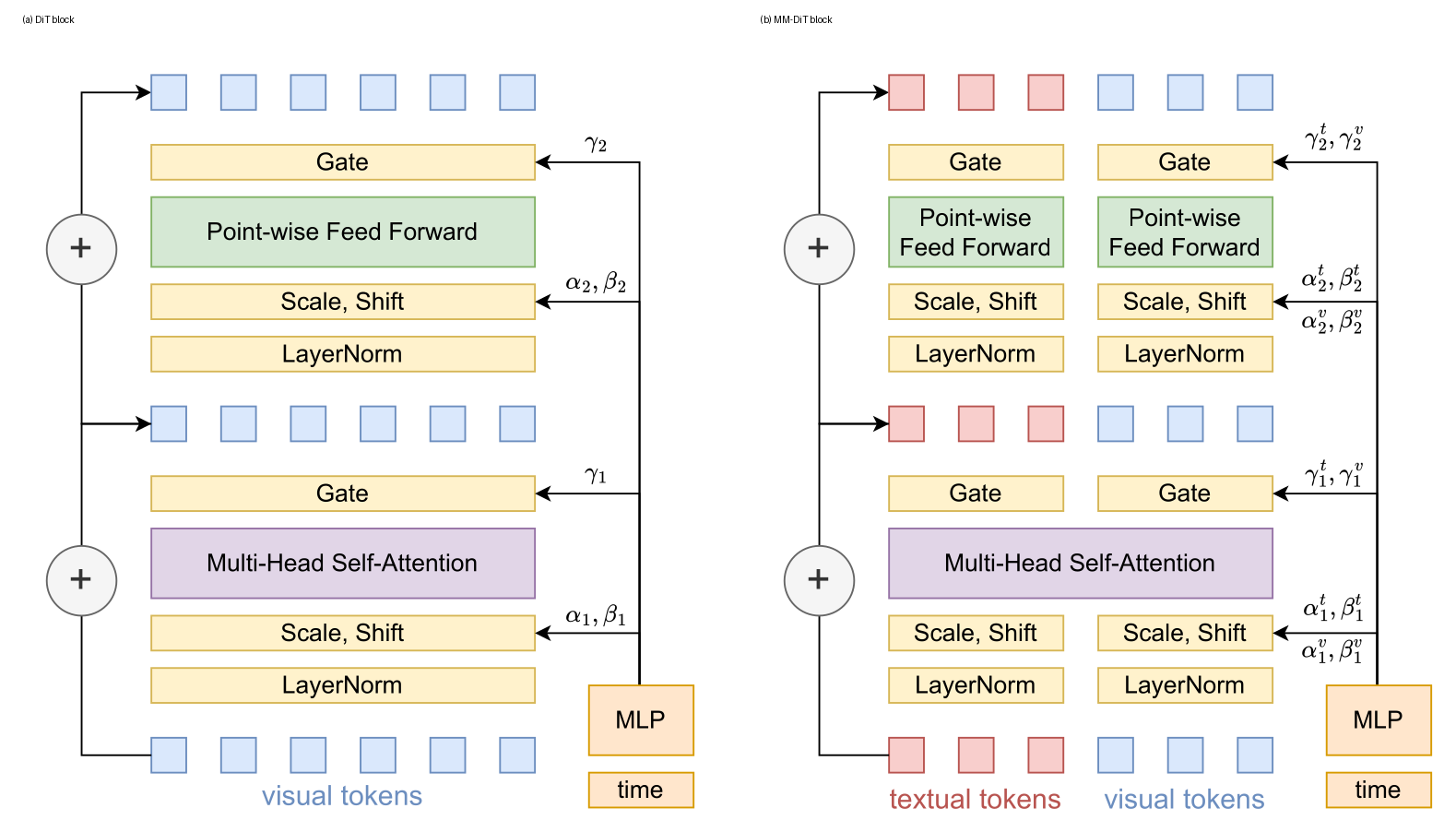
Figure 2 解读:左图是标准 DiT block,右图是 MM-DiT block。Calibri 关注的不是重写 attention/MLP 本身,而是在这些模块的 gated residual output 上乘可搜索系数;这解释了为什么参数数可以保持在 57/76/114 这种量级。
3.2 优化目标与搜索空间
论文把 calibration 写成:
其中 是对当前 calibrated model 生成图像的 reward score。对 DiT/flow model ,搜索向量包含输出级 ensemble 权重 与内部层 scale ,calibrated output 记作 。Calibri Ensemble 把多个 calibrated model 同时组合:
并优化 的整体 reward。直觉上,单模型 Calibri 是“找一套更好的层音量”,ensemble Calibri 则是“找多套层音量并学习怎么混合它们”。当 且处在 CFG setting 时,它可以看作对 conditional/unconditional 或多路模型输出的可学习 generalization。
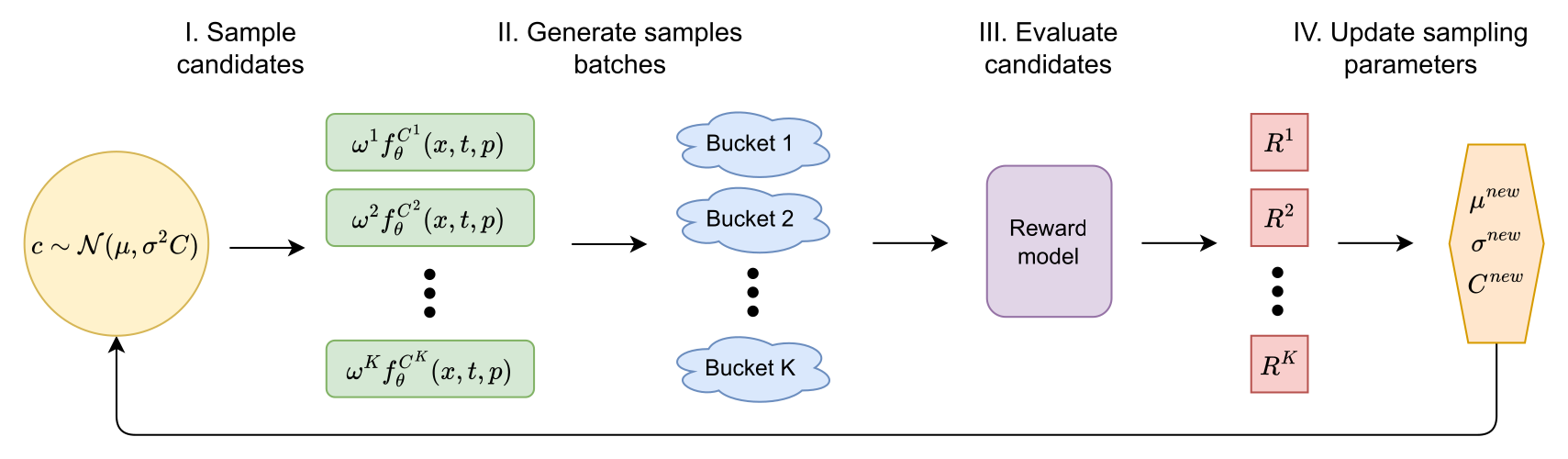
Figure 4 解读:CMA-ES 每轮从高斯分布 采样候选 scale vector;每个候选都会生成一批图像,用 HPSv3 / PickScore / Q-Align / ImageReward 等 reward 打分;rank 0 聚合 fitness 后更新 CMA-ES 分布。这里没有通过 reward model 对 latent 或 DiT 反传梯度。
3.3 Released code 伪代码(基于实际实现)
Code reference:
main@dee7bda6(2026-04-13) — pseudocode and mapping based on this commit
Pipeline 选择与训练入口(scripts/train.py, src/models/__init__.py):
def train_calibri(cfg):
accelerator = Accelerator()
set_seed(cfg.experiment.seed)
pipe_cls = get_pipeline_by_name(cfg.model.model_name)
pipeline = pipe_cls(
device=accelerator.device,
dtype=torch.bfloat16 if cfg.model.dtype == "bf16" else torch.float16,
model_name=cfg.model.model_name,
num_models=cfg.scaleguidance.num_models,
)
reward_fn = multi_score(cfg.device, cfg.reward_fn)
eval_reward_fn = multi_score(cfg.device, cfg.reward_fn_eval)
train_loader = make_loader(cfg.data.train_dataset, cfg.optimize.bucket_size, infinite=True)
val_loader = make_loader(cfg.data.val_dataset, cfg.data.batch_size_val, infinite=False)
trainer = CMAESTrainer(cfg, pipeline, reward_fn, eval_reward_fn, train_loader, val_loader)
return trainer.train()FLUX gate/layer/block scale 注入(src/models/flux_sg.py, flux_sg_block.py, flux_sg_mlp_attn.py):
def extend_flux_transformer(transformer, num_models):
freeze_all_parameters(transformer)
transformer._original_forward = transformer.forward
transformer_gate_scales_main = nn.ModuleList() # double-block main gates
transformer_gate_scales_ctx = nn.ModuleList() # double-block context gates
single_gate_scales = nn.ModuleList() # single transformer blocks
models_scales = nn.Parameter(torch.tensor([1.0] + [0.0] * (num_models - 1)))
def norm_hook(block_idx, model_idx, is_context):
def hook(module, args, kwargs, output):
out = list(output)
w_attn, w_mlp = select_gate_scales(block_idx, model_idx, is_context)
out[1] = out[1] * w_attn # gate_msa
out[4] = out[4] * w_mlp # gate_mlp
return tuple(out)
return hook
def new_forward(*args, **kwargs):
result = None
for model_idx, omega in enumerate(models_scales):
register_gate_hooks(model_idx)
y = transformer._original_forward(*args, **kwargs)
remove_gate_hooks()
result = omega * y if result is None else result + omega * y
return result
transformer.forward = new_forward
return transformerCMA-ES 搜索循环(src/optim/cmaes.py):
def cmaes_train(cfg, pipeline, reward_fn):
x0 = pipeline.flatten_coefficients()
es = cma.CMAEvolutionStrategy(
x0=x0,
sigma0=cfg.optimize.initial_sigma,
inopts={"seed": cfg.experiment.seed, "popsize": cfg.optimize.population_size},
)
es.inject([es.gp.geno(x0)], force=True)
for generation in range(cfg.optimize.max_generations if cfg.optimize.max_generations > 0 else INF):
prompts = next_bucket(cfg.optimize.bucket_size)
candidates = es.ask()
scores = []
for x in shard_by_rank(candidates):
pipeline.apply_coefficients(x)
images = pipeline(prompts, num_inference_steps=cfg.gen.num_inference_steps,
guidance_scale=cfg.gen.guidance_scale, height=512, width=512)
reward = reward_fn(images, prompts, metadata={})["avg"]
scores.append(reward)
fitnesses = [-score for score in gather(scores)]
es.tell(candidates, fitnesses)
validate_and_checkpoint_best_candidate()Code-to-paper mapping:
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| 训练入口、pipeline/reward/data loader 组装 | /Users/bytedance/ai-skills/papers/Calibri/scripts/train.py | main, CMAESTrainer(...) |
| 模型名到 wrapper 的分派 | /Users/bytedance/ai-skills/papers/Calibri/src/models/__init__.py | get_pipeline_by_name |
| FLUX gate scaling(main/context/single gates) | /Users/bytedance/ai-skills/papers/Calibri/src/models/flux_sg.py | extend_transformer_with_sg, SGFluxPipeline |
| FLUX block scaling | /Users/bytedance/ai-skills/papers/Calibri/src/models/flux_sg_block.py | SGFluxPipelineBlock.get_coefficient_shapes |
| FLUX layer scaling(attention/MLP) | /Users/bytedance/ai-skills/papers/Calibri/src/models/flux_sg_mlp_attn.py | SGFluxPipeline_MlpAttn.get_coefficient_shapes |
| SD-3.5M / Flow-GRPO checkpoints | /Users/bytedance/ai-skills/papers/Calibri/src/models/sd3_sg.py, sd3_lora_sg.py | extend_sd3_transformer, SGSD3PipelineLORA |
| Qwen-Image CFG/ensemble wrapper | /Users/bytedance/ai-skills/papers/Calibri/src/models/qwen_sg.py | extend_qwen_transformer_with_sg, SGQwenPipelineCFG |
| CMA-ES optimizer loop | /Users/bytedance/ai-skills/papers/Calibri/src/optim/cmaes.py | CMAESTrainer, train, es.ask, es.tell |
| Reward aggregation | /Users/bytedance/ai-skills/papers/Calibri/src/metrics/rewards.py | multi_score, hpsv3_remote, qalign_remote, pickscore, imagereward |
| 实验配置 | /Users/bytedance/ai-skills/papers/Calibri/configs/base.py, /Users/bytedance/ai-skills/papers/Calibri/configs/calibri.py | initial_sigma=0.25, bucket_size=16, cmaes_hpsv3_flux_*, cmaes_qwen_* |
论文公式与 released code 实现差异:论文表中报告的 FLUX block/layer/gate scale 参数数是 57/76/114;released code 的 flatten_coefficients() 还把 models_scales(每个 ensemble model 的 )拼进 CMA-ES 向量。因此实际搜索向量在单模型 FLUX wrapper 中通常比表中 internal scale 数多 1(block 58、layer 77、gate 115),表格数字更像只统计内部 calibration scale,而不是输出混合权重。
4. Experimental Setup (实验设置)
数据集与规模。 训练/中间验证使用 T2I-CompBench++ prompts:论文说 train prompts 用于 CMA-ES candidate bucket evaluation,test prompts 用于中间 reward evaluation;released code 中对应 /data/t2i_compbench_train.txt 有 5,601 行,/data/t2i_compbench_val.txt 有 2,402 行,/data/t2i_compbench_val_random_crop.txt 有 499 行。最终指标使用 HPDv3 test prompts;论文未给出 HPDv3 全量规模,但 human study 明确使用 150 个 HPDv3 test prompts、200 名用户、5,600 次 assessment。
模型与 baseline。 主实验覆盖 FLUX.1-dev、Stable Diffusion 3.5 Medium、Qwen-Image;alignment 组合实验覆盖 SD-3.5M 原始模型、Flow-GRPO-PickScore checkpoint、Flow-GRPO-GenEval checkpoint。对比对象包括原模型、Flow-GRPO、Flow-GRPO + Calibri、不同 Calibri granularity(block/layer/gate)与 Calibri Ensemble。
指标。 HPSv3 衡量人类偏好分数;ImageReward/IR 是图像偏好 reward;Q-Align 是 MLLM 视觉质量评估;PickScore 是 CLIP-based preference score;DINO Diversity 衡量生成多样性;human evaluation 分 Overall Preference 和 Text Alignment win rate。
训练/搜索配置。 论文配置:CMA-ES 初始 ;候选数 ;bucket size 16;图像分辨率 512;训练 NFE=15;HPSv3/Q-Align 用于训练期间 tracking,HPSv3/Q-Align/ImageReward 用于最终评估。released code 对应 configs/base.py 中 initial_sigma=0.25、bucket_size=16、num_inference_steps=15、image_size=512;configs/calibri.py 为 FLUX/SD3/Qwen 分别设置模型、reward、val_every_steps=10、train/val 文件路径。硬件成本按论文 Table 5 用 NVIDIA H100 GPU-hours 报告,而不是给出固定 GPU 数:Flux Block 32、Layer 64、Gate 150;SD-3.5M Gate 356;Qwen-Image Gate 286。
5. Experimental Results (实验结果)
主结果。 Calibri 在三个 backbone 上同时提升质量指标并降低 NFE:
| Model | Calibri | HPSv3 | IR | Q-Align | NFE |
|---|---|---|---|---|---|
| FLUX | ✗ | 11.41 | 1.15 | 4.85 | 30 |
| FLUX | ✓ | 13.48 | 1.18 | 4.88 | 15 |
| SD-3.5M | ✗ | 11.15 | 1.10 | 4.74 | 80 |
| SD-3.5M | ✓ | 14.10 | 1.17 | 4.91 | 30 |
| Qwen Image | ✗ | 11.26 | 1.16 | 4.55 | 100 |
| Qwen Image | ✓ | 12.95 | 1.18 | 4.73 | 30 |
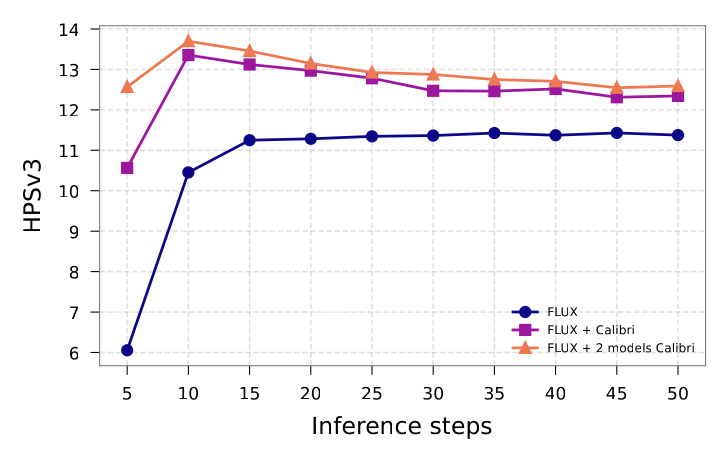
Figure 6 解读:Calibri Ensemble 把 FLUX 的最优采样步数从 baseline 的 30–50 NFE 移到 10–15 NFE,说明它不是只在固定步数上刷 reward,而是改变了低步数区域的质量-计算折中。
Granularity ablation。 FLUX 上 block/layer/gate 的 HPSv3 分别是 13.29/13.41/13.48;IR 分别是 1.17/1.24/1.18;Q-Align 分别是 4.91/4.90/4.88。Gate scaling 目标 reward 最高,但 layer scaling 在非目标 reward 上更稳;三者质量差距不大,训练速度差异更关键:block 57 params/200 iters/32 H100 hours,layer 76 params/410 iters/64 H100 hours,gate 114 params/960 iters/150 H100 hours。

Figure 5 解读:不同 granularity 的曲线说明参数越细并不总是所有指标更好。Gate 能更贴合 HPSv3 objective,但 layer 在 IR/Q-Align 等指标上更均衡,因此实际选择取决于目标 reward、预算和是否需要更快 convergence。
Human evaluation。 在 200 users、5,600 assessments、150 HPDv3 prompts 上,Flux 的 Overall Preference 为 Calibri 51.87 / Equal 7.33 / Original 40.80,Text Alignment 为 38.71 / 37.68 / 23.61;Qwen-Image 的 Overall Preference 为 54.62 / 7.91 / 37.47,Text Alignment 为 40.29 / 37.65 / 22.06。这说明提升不只来自自动 reward 的偏置,用户偏好也更倾向 calibrated model。
与 Flow-GRPO 组合。 在 SD-3.5M 上,Calibri 可以替代一部分昂贵 finetuning,也能叠加在 Flow-GRPO checkpoint 之后:base SD-3.5M 从 HPSv3/PickScore/Q-Align = 11.15/22.40/4.74 提升到 12.47/23.13/4.91,NFE 80→30;Flow-GRPO PickScore checkpoint 再加 Calibri 后从 12.67/23.78/4.92 到 12.96/23.93/4.85;Flow-GRPO GenEval checkpoint 用 Calibri-HPSv3 后 HPSv3 从 10.16 到 14.18,Q-Align 从 4.69 到 4.88,NFE 80→30。论文强调:对 base SD-3.5M 用 PickScore 目标的 Calibri 只更新 216 个参数,而 Flow-GRPO 更新 18.78M 参数。

Figure 7 解读:定性图展示 Calibri 可以作为 Flow-GRPO 之后的后处理式校准层:它不覆盖原有对齐,而是在保持相同/更低 NFE 的情况下进一步改善构图、细节与 prompt adherence。
多样性与局限。 作者指出 Calibri 依赖 reward model 作为 objective;如果 reward model 对多手指、额外肢体等解剖伪影不敏感,CMA-ES 可能选择到 suboptimal coefficients。多样性实验显示,SD-3.5M 原始 80 NFE 的 Dino Diversity 为 ,Calibri PickScore 30 NFE 仍为 ;相比之下 Flow-GRPO PickScore 降到 ,Flow-GRPO + Calibri 约 。因此 Calibri 本身在该实验中没有进一步损害多样性,但它的上限仍受 reward model 覆盖能力约束。