Auto-Rubric as Reward: From Implicit Preferences to Explicit Multimodal Generative Criteria
Paper: arXiv:2605.08354 Code: OpenEnvision/AutoRubric-as-Reward Code reference:
main@3c5661f4(2026-05-12)
1. Motivation (研究动机)
当前 multimodal generative alignment 的核心问题不是模型完全“不懂”人类偏好,而是 reward interface 太粗糙:PickScore、ImageReward、HPSv3 等 pointwise reward model 把多维偏好压成一个 scalar;pairwise reward / direct preference objective 只保留二元胜负;VLM-as-a-judge 虽有更强感知能力,但仍有明显 positional bias 和 symmetry bias。结果是,语义一致性、空间关系、美学、局部纹理、编辑忠实度等判断维度被缠在一个黑盒分数里,优化时容易 reward hacking,也难以解释为什么某个输出更好。
论文要解决的具体目标是:把 VLM 内部隐含的偏好知识显式化为 prompt-conditioned rubric,并把这些 rubric 直接转成可用于 Text-to-Image / Image Editing online policy optimization 的 reward。它不是再训练一个 reward model,而是让 frozen VLM 先生成、验证、结构化可读的评价标准,再用 rubric-conditioned binary preference 给生成模型做 RPO。
这个问题值得研究,因为视觉生成的偏好天然是 compositional 和 multi-dimensional 的。若 reward 能保持这种结构,训练信号就能同时约束 prompt following、object relation、aesthetic quality、artifact control 和 editing faithfulness;这会把 alignment 从“追一个黑盒分数”变成“满足一组可检查的标准”,从而减少 reward hacking,并让低监督/zero-shot 评价更可靠。
2. Idea (核心思想)
核心洞见:强 VLM 已经内化了大量人类偏好知识,但直接让它做 A/B choice 会把判断藏在 latent decision boundary 里;ARR 先要求 VLM 把判断依据外化为可读 rubric,再用这些 rubric 约束 judge 和 policy gradient。换言之,论文把 reward modeling 从“学习一个隐式分数函数”改成“构造一个显式的评价接口”。
关键创新有两点。第一,Auto-Rubric as Reward (ARR) 用 generate-verify-refine-structure 流程把少量 preference pairs 转为结构化 rubric。第二,Rubric Policy Optimization (RPO) 在线生成两个候选图像,用 frozen ARR judge 判定胜负,把 winner 赋 、loser 赋 ,再用 PPO-style clipped objective 和 KL regularization 更新生成模型。
与现有方法的根本差异:HPSv3 / ImageReward / PickScore 依赖大量 preference data 学一个 opaque scalar reward;direct VLM judge 虽然 zero-shot,但判断标准隐式且有位置偏置;ARR 则在比较前先生成显式标准,评估时让 VLM 依据这些标准做 holistic pairwise decision。相比传统 Rubrics-as-Reward 中固定/人工 rubric,ARR 的 rubric 是 prompt-conditioned、可验证、可复用的。
3. Method (方法)
3.1 Overall framework
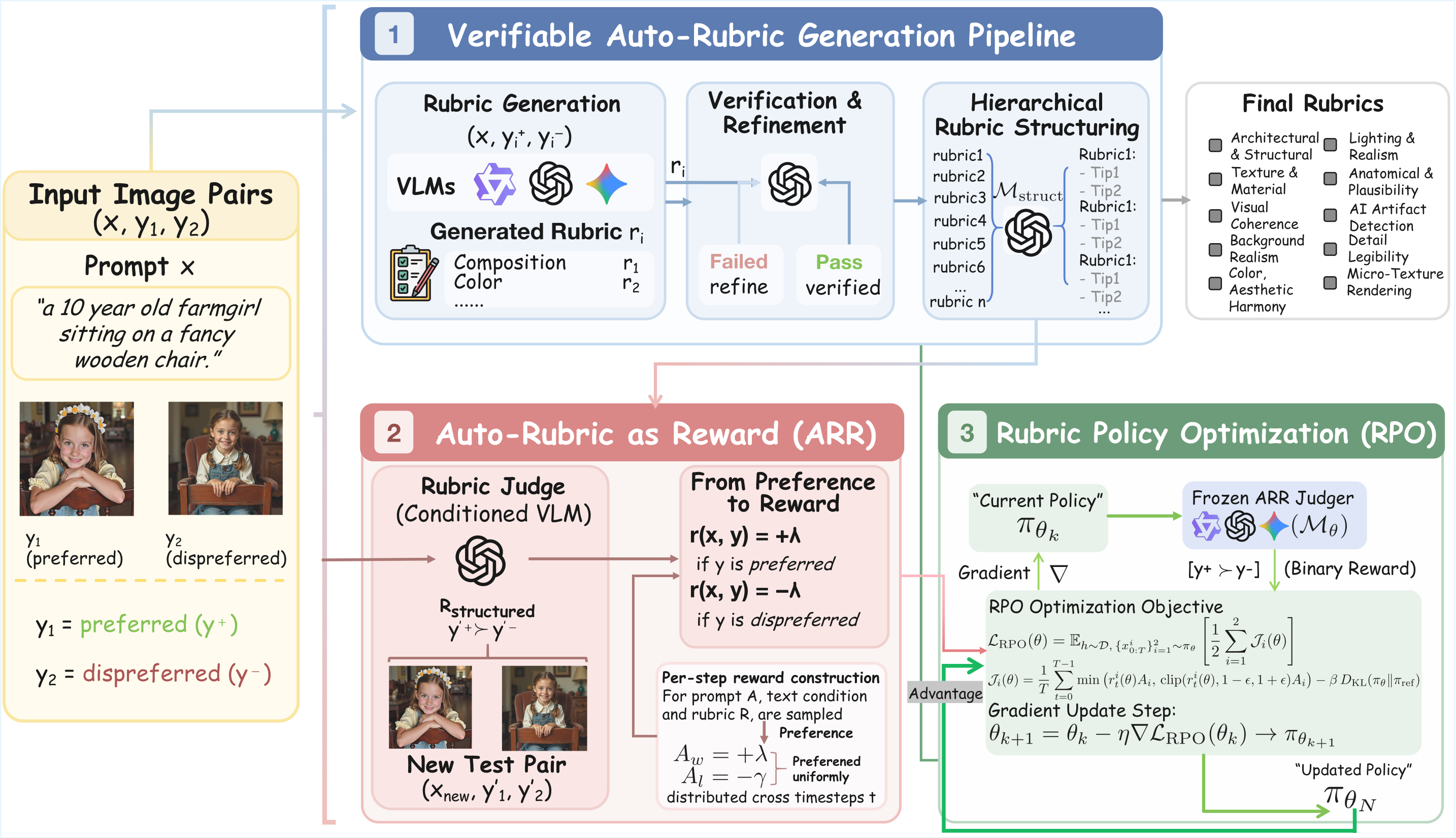
Figure 1 解读:图中左侧是 ARR 的 rubric induction:从少量 labeled preference pairs 出发,VLM generator 为每个样本产生候选评价标准;verifier 检查该标准是否能支持原始偏好;失败样本进入 refinement;通过验证的 rubrics 被结构化为层级评价协议。右侧是 RPO:生成模型对同一 prompt 采样两个候选图像,ARR judge 在 rubric 条件下做 pairwise preference,winner / loser 的二元 reward 被送入 PPO-style diffusion policy update。整体设计把“偏好解释”放在 reward 之前,而不是从训练数据中拟合一个不可解释分数。
直觉上,ARR 有效是因为它把一个难题拆成两个更稳定的子问题:先让 VLM 用自然语言列出“应该看什么”,再让 VLM 在这些标准下判断“哪个更好”。这减少了直接 A/B judge 对位置、风格或偶然视觉显著性的依赖,也让 policy optimization 的目标更接近 human evaluation protocol。
3.2 Preference formulation:从 implicit scalar 到 explicit rubric
传统 implicit preference modeling 用 Bradley-Terry 形式把人类偏好写成 scalar reward 的差:
训练 reward model 的常见目标是:
ARR 的 explicit preference modeling 则把 rubric 放进 VLM judge:
这里的关键不是 作为附加 prompt 的表面形式,而是 将审美、语义、空间、编辑保真等维度变成 judge 必须显式遵循的评价接口。
3.3 Auto-Rubric as Reward (ARR)
ARR 目标是在巨大、离散的 rubric space 中选择最能近似人类偏好的 rubric set:
由于直接搜索 不可行,论文把目标近似成从候选集合 中选择能让 VLM judge 判对 preference pair 的 rubric:
具体流程:
- Generation:给定 pairwise preference dataset ,用 generator VLM 为每个 pair 生成自然语言 rubric:。meta-prompt 要求 rubric 拆成 independent / verifiable quality axes,避免只写“整体更好”。
- Verification and refinement:verifier 判断 是否能确认原始 preference:。若失败,则用 critique 做最多 次 refinement:。论文报告约 初始 rubrics 无需 refinement 即通过,少于 最终被丢弃。
- Hierarchical structuring:把通过验证的 聚合为 ,按 overall alignment、compositional structure、fine-grained fidelity 等维度组织成可直接注入 judge prompt 的层级列表。
从 rubric 到 reward 的转换很简单:给定 prompt 和两个候选 ,若 rubric-conditioned judge 偏好 ,则给 正 reward;否则给负 reward:
论文公式与 released code 实现差异:论文正文与算法描述强调 rubrics 可针对 prompt-output pair 动态 synthesize/retrieve;released code 中 Judger.initialize() 是在训练前从 rubrics_file 读取 rubrics,或从 seed_dataset 生成一次 rubrics 后构造 LLMGrader。训练循环中的 get_reward_single() 只对当前图像 pair 做 rubric-conditioned ranking,并不在每个 RPO step 重新生成新 rubrics。reward 数值实现与论文 Table 3 一致:二候选 pair 中 rank 1 得 1.0,rank 2 得 -0.1。

Figure 7 解读:这张图展示 T2I 场景下自动生成的 rubric 示例,评价维度覆盖建筑/物体 fidelity、光照一致性、纹理真实感、AI artifact detection 等。它说明 ARR 的输出不是单个宽泛评分句子,而是一组可执行、可检查的 criteria。

Figure 8 解读:这张图展示 T2I pairwise evaluation prompt。prompt 明确要求 judge 基于 rubric 比较两个生成图,输出固定格式,并提醒避免 position bias;这对应方法中的“把评价标准前置到判断之前”。

Figure 9 解读:这张图展示 image editing 场景的 rubrics,重点从生成质量转向 source-image preservation、material integrity、lighting consistency、artifact elimination 等编辑保真维度。它体现 ARR 会随任务类型改变评价轴。

Figure 10 解读:这张图展示 image editing judge prompt;与 T2I 不同,prompt 显式提供 Image BASE 作为原始参考图,要求 judge 同时检查 edit instruction 是否满足、无关内容是否保持、是否引入 artifact。
3.4 Rubric Policy Optimization (RPO)
RPO 是在线 policy gradient:每次从训练 prompt distribution 采样 prompt,当前 policy 生成两个候选轨迹,ARR judge 给出 rubric-conditioned preference,然后对 denoising policy 做 PPO-style clipped update。论文 objective:
其中 timestep-level importance ratio 为:
winner trajectory 的 advantage 是 ,loser trajectory 是 ;同一个 trajectory-level reward 会均匀作用到所有 denoising timesteps。released code 中这对应 fastvideo/train_rpo_flux.py / fastvideo/train_rpo_qwen_edit.py:先保存两个候选图像,调用 Judger.get_reward_single() 得到 [1.0,-0.1] 或 [-0.1,1.0],然后在每个训练 timestep 用同一个 sample["advantages"] 计算 clipped loss。
论文公式与 released code 实现差异:论文目标写的是最大化形式的 ;released code 用 optimizer 最小化 torch.maximum(-advantages * ratio, -advantages * clipped_ratio) + kl_beta * kl_term,这是同一 PPO clipped surrogate 的 loss 形式。code 中 KL 近似为 LoRA-enabled policy 和 LoRA-disabled reference 的 log-prob 差 new_log_probs - ref_log_probs。
3.5 Pseudocode(基于 released code)
Component A:初始化 ARR judge / 生成或读取 rubrics
async def initialize_arr_judger(config_path, seed_dataset=None, rubrics_file=None):
cfg = load_yaml_or_json(config_path)
model = OpenAIChatModel(
model=cfg["model_name"],
base_url=cfg.get("base_url"),
api_key=cfg.get("api_key", "EMPTY"),
)
if rubrics_file is not None:
rubrics = Path(rubrics_file).read_text()
elif cfg.get("rubrics"):
rubrics = cfg["rubrics"]
else:
seed_pairs = load_yaml_or_json(seed_dataset or cfg["seed_dataset"])
generator = IterativeRubricsGenerator(
grader_name=cfg["grader_name"],
model=model,
grader_mode="pairwise",
query_specific_generate_number=cfg.get("query_specific_generate_number", 5),
enable_categorization=cfg.get("enable_categorization", True),
categories_number=cfg.get("categories_number", 5),
task_type=cfg["task_type"],
max_retries=cfg.get("max_retries", 5),
max_epochs=cfg.get("max_epochs", 5),
)
generated = await generator.generate(seed_pairs)
rubrics = generated.kwargs["rubrics"]
return LLMGrader(
name=cfg["grader_name"],
model=model,
mode="listwise",
rubrics=rubrics,
template=get_evaluation_template("listwise", cfg["task_type"]),
task_type=cfg["task_type"],
)Component B:pairwise ARR reward tensor
async def get_reward_single(judger, item, task_type, device):
image_paths = extract_image_paths(item, task_type)
result = await judger.aevaluate(
image_paths=image_paths,
has_base_image=has_base_image(item, task_type),
sample_content=format_sample_content(item, task_type),
)
rank = result.rank # e.g. [1, 2] or [2, 1]
if len(rank) == 2:
rewards = [1.0 if value == 1 else -0.1 for value in rank]
else:
worst = max(rank)
rewards = [1.0 - ((value - 1) / (worst - 1)) * 1.1 for value in rank]
return torch.tensor(rewards, device=device)Component C:T2I / editing RPO step
def rpo_train_one_step(policy, reference_policy, vae, arr_judge, batch, optimizer, args):
prompts = repeat_each_prompt(batch.prompts, repeats=args.num_generations) # must be 2
latents, old_log_probs, decoded_images = sample_two_candidates(policy, vae, prompts, args)
pair_items = []
for j in range(0, len(decoded_images), 2):
item = {
"query": prompts[j],
"response": [save_png(decoded_images[j]), save_png(decoded_images[j + 1])],
}
if batch.is_editing:
item["source_image"] = batch.source_images[j]
pair_items.append(item)
rewards = []
for item in pair_items:
rewards.append(asyncio.run(arr_judge.get_reward_single(item, device=latents.device)))
rewards = torch.cat(rewards).float()
advantages = rewards.clamp(-args.adv_clip_max, args.adv_clip_max)
total_loss = 0.0
for t in shuffled_denoising_timesteps(args.sampling_steps):
new_log_probs = policy.log_prob(latents[:, t], latents[:, t + 1], prompts)
with torch.no_grad(), disable_lora(policy):
ref_log_probs = reference_policy.log_prob(latents[:, t], latents[:, t + 1], prompts)
ratio = torch.exp(new_log_probs - old_log_probs[:, t])
clipped_ratio = ratio.clamp(1.0 - args.clip_range, 1.0 + args.clip_range)
kl_term = new_log_probs - ref_log_probs
loss = torch.maximum(-advantages * ratio, -advantages * clipped_ratio)
loss = (loss + args.kl_beta * kl_term).mean()
total_loss = total_loss + loss / args.gradient_accumulation_steps
total_loss.backward()
torch.nn.utils.clip_grad_norm_(policy.parameters(), args.max_grad_norm)
optimizer.step()
optimizer.zero_grad()
return total_loss.item(), rewards.mean().item()Component D:image editing 的 base-image-aware pair construction
def build_edit_pair_item(instruction, source_image, candidate_a, candidate_b):
return {
"query": instruction,
"source_image": source_image,
"response": [candidate_a, candidate_b],
}Code reference:
main@3c5661f4(2026-05-12) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| ARR CLI / judge entrypoint | judger.py | Judger.initialize, Judger._evaluate_item, Judger._rank_to_rewards, Judger.get_reward_single |
| Rubric generation / verification / refinement | rubric_pipeline/generator/iterative_rubric/generator.py, query_rubric_generator.py | IterativeRubricsGenerator, QuerySpecificRubricGenerator.generate, aevaluate, validate |
| Rubric categorization / hierarchy | rubric_pipeline/generator/iterative_rubric/categorizer.py | LLMRubricCategorizer.categorize_rubrics |
| Rubric-conditioned VLM judge | rubric_pipeline/graders/llm_grader.py | LLMGrader.aevaluate, listwise GraderRank parsing |
| Image path / base image handling | rubric_pipeline/utils/vision.py | extract_image_paths, has_base_image, count_outputs |
| FLUX T2I RPO | fastvideo/train_rpo_flux.py | sample_reference_model, get_arr_reward_sync, train_one_step, grpo_one_step |
| Qwen-Image-Edit RPO | fastvideo/train_rpo_qwen_edit.py | sample_reference_model, compute_rpo_advantages, train_one_step, grpo_one_step |
| Paper-aligned launch defaults | scripts/finetune/finetune_flux_rpo_8gpus.sh, scripts/finetune/finetune_qwen_image_edit_rpo_8gpus.sh | LR, sampling steps, KL, LoRA rank, clip range, generation count |
| ARR config | rubric_pipeline/config/qwen3vl_8B_instruct_t2i.yaml, qwen3vl_8B_instruct_edit.yaml | query_specific_generate_number: 5, enable_categorization: true, categories_number: 5 |
4. Experimental Setup (实验设置)
Datasets / benchmarks and scale. Preference evaluation uses HPDv3 with 1.17M T2I pairwise human comparisons, MM-RewardBench2 with 4,000 expert-annotated pairwise instances over T2I/Edit/VQA/compositional splits, and EditReward-Bench with 13 instruction-guided editing subtasks. Generative evaluation uses GenEval, DPG-Bench, TIIF, UniGenBench++ Short/Long for T2I, and GEdit-Bench / ImgEdit for editing;这些生成评测集的样本数论文未详细说明。RPO training prompts are sampled from ShareGPT-4o-Image, containing around 92K high-quality GPT-4o-synthesized T2I/editing samples.
Baselines. Preference evaluator baselines include PickScore, ImageReward, UnifiedReward, UnifiedReward-Thinking, HPSv3, EditReward, and direct VLM judges Qwen3-VL-8B, GPT-5, Gemini 3.1 Pro. Generative baselines include Emu3, JanusFlow, FLUX.1-Dev, DALLE-3, Show-o2, OmniGen2, BAGEL for T2I, and Instruct-Pix2Pix, AnyEdit, Step1X-Edit, Qwen-Image-Edit-2509, UniWorldv2 for editing; appendix additionally reports SDXL, BLIP3o-4B, Janus-Pro-7B, and BAGEL ARR-RPO variants.
Metrics. Preference Accuracy 是预测偏好与 human label 一致的比例。GenEval 衡量 T2I compositional object accuracy;DPG-Bench 衡量 dense paragraph prompt alignment;TIIF 衡量 instruction fidelity;UniGenBench++ Short/Long 衡量短/长 prompt semantic consistency;GEdit-Bench 用 GPT-5 以 1–10 分评价 instruction adherence、image quality、preservation;ImgEdit 报告单轮/多轮编辑的 composite score。
Training config. 论文称所有实验在 8 NVIDIA H100 80GB SXM5 GPUs 上完成。论文 Table 3 报告:T2I uses FLUX.1.dev, LR , batch size 32, 2 candidates/prompt, clip , KL , reward , 8 denoising steps, AdamW, grad clip 1.0, LoRA rank 16;editing uses Qwen-Image-Edit-2509, LR , batch size 16, 10 denoising steps, KL , LoRA rank 32,其余相同。Released launch scripts provide the concrete runnable overrides: scripts/finetune/finetune_flux_rpo_8gpus.sh uses --learning_rate 5e-5, --gradient_accumulation_steps 8, --max_train_steps 300, --weight_decay 0.0001, --sampling_steps 8, --lora_rank 16, --lora_alpha 32; scripts/finetune/finetune_qwen_image_edit_rpo_8gpus.sh uses --learning_rate 1e-5, --gradient_accumulation_steps 4, --max_train_steps 300, --sampling_steps 10, --lora_rank 32, --lora_alpha 64.
论文公式与 released code 实现差异:paper Table 3 的 “Batch size 32 / 16” 与 released 8-GPU launch scripts 中 train_batch_size=1、num_generations=2、gradient_accumulation_steps=8/4 的可执行设置不完全同名;代码没有说明 Table 中 batch size 与 launch script micro-batch/effective-batch 的换算方式。因此本笔记在训练配置中同时记录 paper table 数值和实际 launch script 参数。
5. Experimental Results (实验结果)
5.1 Preference evaluator quality
| Method | HPDv3 | MM-RewardBench2 T2I | MM-RewardBench2 Edit | EditReward-Bench |
|---|---|---|---|---|
| PickScore | 65.6 | 58.6 | — | — |
| ImageReward | 58.6 | 54.0 | — | — |
| UnifiedReward | 66.0 | 59.8 | — | — |
| UnifiedReward-Thinking | 68.1 | 66.0 | — | — |
| HPSv3 | 76.9 | 60.2 | — | — |
| EditReward | — | — | 67.2 | 56.45 |
| Qwen3-VL-8B | 67.2 | 57.6 | 59.2 | 54.01 |
| Qwen3-VL-8B + ARR | 70.2 ± 0.2 (+3.0) | 62.7 ± 0.2 (+5.1) | 65.5 ± 0.3 (+6.3) | 57.22 ± 0.1 (+3.21) |
| GPT-5 | 72.4 | 70.5 | 73.8 | 57.53 |
| GPT-5 + ARR | 76.1 ± 0.2 (+3.7) | 74.7 ± 0.4 (+4.2) | 77.5 ± 0.3 (+3.7) | 61.01 ± 0.1 (+3.48) |
| Gemini 3.1 Pro | 76.6 | 75.1 | 77.4 | 61.23 |
| Gemini 3.1 Pro + ARR | 78.3 ± 0.1 (+1.7) | 78.9 ± 0.2 (+3.8) | 79.2 ± 0.2 (+1.8) | 63.27 ± 0.2 (+2.04) |
ARR 对所有 VLM judge 都带来稳定增益:Qwen3-VL-8B 提升 3.0–6.3 points,GPT-5 提升 3.7–4.2 points,Gemini 3.1 Pro 提升 1.7–3.8 points,并在四个 preference benchmark 中达到表内最优。它也显示出跨任务泛化:相比 HPSv3 在 HPDv3 上 76.9 但 MM-RewardBench2 T2I 只有 60.2,ARR-augmented VLM 更均衡。
5.2 Generative performance after ARR-RPO

Figure 2 解读:上半部分比较 T2I benchmark,下半部分比较 image editing benchmark。图中蓝色 ARR-RPO variants 相比 FLUX.1-Dev / Qwen-Image-Edit-2509 baseline 在多数指标上提升;Gemini 3.1 Pro ARR 版本通常最强,说明更强 VLM 产生的 rubrics 能提供更有效的 reward。
| Method | GenEval | DPG-Bench | TIIF | UniGenBench++ Short | UniGenBench++ Long | GEdit-Bench | ImgEdit |
|---|---|---|---|---|---|---|---|
| Emu3 | 0.54 | 80.60 | — | 45.42 | 50.59 | — | — |
| JanusFlow | 0.63 | 79.68 | — | 47.10 | 54.80 | — | — |
| FLUX.1-Dev | 0.66 | 83.84 | 71.09 | 60.97 | 69.42 | — | — |
| DALLE-3 | 0.67 | 83.50 | 74.96 | 68.85 | 70.82 | — | — |
| Show-o2 | 0.76 | 86.14 | — | 61.90 | 70.33 | — | — |
| OmniGen2 | 0.80 | 83.57 | — | 63.09 | 71.39 | — | — |
| BAGEL | 0.82 | 85.07 | 71.50 | 59.91 | 71.26 | — | — |
| RPO-Qwen3vl-8B-ARR | 0.74 (+0.08) | 85.03 (+1.19) | 74.92 (+3.83) | 64.17 (+3.20) | 71.82 (+2.40) | — | — |
| RPO-GPT-5-ARR | 0.78 (+0.12) | 85.41 (+1.57) | 76.18 (+5.09) | 65.36 (+4.39) | 72.41 (+2.99) | — | — |
| RPO-Gemini 3.1 Pro-ARR | 0.80 (+0.14) | 85.76 (+1.92) | 76.85 (+5.76) | 65.89 (+4.92) | 72.93 (+3.51) | — | — |
| Method | GEdit-Bench | ImgEdit |
|---|---|---|
| Instruct-Pix2Pix | 3.68 | 1.88 |
| AnyEdit | 3.21 | 2.45 |
| Step1X-Edit | 6.97 | 3.06 |
| Qwen-Image-Edit-2509 | 7.54 | 4.35 |
| UniWorldv2 | 7.76 | 4.48 |
| RPO-Qwen3vl-8B-ARR | 7.66 (+0.12) | 4.38 (+0.03) |
| RPO-GPT-5-ARR | 7.72 (+0.18) | 4.40 (+0.05) |
| RPO-Gemini 3.1 Pro-ARR | 7.85 (+0.31) | 4.43 (+0.08) |
关键结论:在 FLUX.1-Dev 上,ARR-RPO-Gemini 把 GenEval 从 0.66 提升到 0.80、DPG-Bench 从 83.84 到 85.76、TIIF 从 71.09 到 76.85、UniGenBench++ Short 从 60.97 到 65.89;在 Qwen-Image-Edit-2509 上,GEdit-Bench 从 7.54 到 7.85、ImgEdit 从 4.35 到 4.43。T2I 的提升幅度明显大于 editing,说明结构化 rubric reward 对 compositional prompt alignment 尤其有效。

Figure 3 解读:这张图给出 ARR-RPO Gemini 3.1 Pro 的 T2I 和 editing qualitative examples。可见改进主要集中在复杂指令遵循、局部细节、材质和光照一致性;这与 rubrics 中的 explicit criteria 对应。

Figure 5 解读:该图补充更多 T2I examples,用于观察 ARR-RPO 在多对象关系、风格约束、场景细节和 artifact control 上的表现。它支持 quantitative results 中 TIIF / UniGenBench++ 的提升。

Figure 6 解读:该图展示 image editing examples,重点是既满足编辑指令又保留 source image 中无关区域。与 T2I 相比,editing 的提升数值较小,但 qualitative examples 展示了 preservation 与 artifact reduction 的方向。
5.3 Ablations

Figure 4a–4b 解读:左图显示 position bias:base VLM 在 forward / reverse order 上差距很大,ARR 可中等幅度缩小 gap,而 ARR w/ guide 显著降低 bias。右图显示 cross-model rubric transfer:固定 Gemini 3.1 Pro judge 时,即使用 Qwen3-VL-8B 生成 rubrics 也能提升 accuracy,说明提升不只是同模型家族的 co-adaptation。
Position bias on HPDv3.
| Method | Forward | Reverse | Avg | |
|---|---|---|---|---|
| Qwen3-VL-8B | 84.5 | 49.9 | 67.2 | 34.6 |
| Qwen3-VL-8B + ARR | 86.0 | 54.4 | 70.2 | 31.6 |
| Qwen3-VL-8B + ARR w/ guide | 90.1 | 79.8 | 85.0 | 10.3 |
| GPT-5 | 88.7 | 56.1 | 72.4 | 32.6 |
| GPT-5 + ARR | 90.2 | 62.0 | 76.1 | 28.2 |
| GPT-5 + ARR w/ guide | 93.4 | 84.1 | 88.8 | 9.3 |
| Gemini 3.1 Pro | 91.7 | 61.5 | 76.6 | 30.2 |
| Gemini 3.1 Pro + ARR | 92.2 | 64.4 | 78.3 | 27.8 |
| Gemini 3.1 Pro + ARR w/ guide | 95.2 | 86.3 | 90.8 | 8.9 |
Cross-model transfer on HPDv3. Fixed judge is Gemini 3.1 Pro: direct baseline 75.9;Qwen3-VL-8B-generated rubrics 77.5;GPT-5-generated rubrics 78.3;Gemini 3.1 Pro-generated rubrics 79.2。即使 rubric generator 较弱,也能关闭 direct→same-family gap 的大半。
Rubric cardinality on HPDv3 (Qwen3-VL-8B-Instruct, zero-shot ARR).
| Number of rubrics | Accuracy |
|---|---|
| 1 | 69.8 |
| 5 | 70.2 |
| 10 | 72.1 |
| 20 | 74.4 |
从 1 到 20 accuracy 单调提升 4.6 points,但论文选择 作为主实验默认值,因为更高 cardinality 带来线性 inference / verification cost,并可能引入冗余或噪声 criteria。
Additional BAGEL T2I ARR-RPO.
| Method | GenEval | DPG-Bench | TIIF | UniGenBench++ Short | UniGenBench++ Long |
|---|---|---|---|---|---|
| BAGEL | 0.82 | 85.07 | 71.50 | 59.91 | 71.26 |
| BAGEL + RPO-Qwen3vl-8B-ARR | 0.88 (+0.06) | 85.82 (+0.75) | 74.05 (+2.55) | 63.05 (+3.14) | 72.35 (+1.09) |
| BAGEL + RPO-GPT-5-ARR | 0.90 (+0.08) | 86.28 (+1.21) | 75.62 (+4.12) | 64.81 (+4.90) | 73.15 (+1.89) |
| BAGEL + RPO-Gemini 3.1 Pro-ARR | 0.92 (+0.10) | 86.74 (+1.67) | 76.85 (+5.35) | 65.92 (+6.01) | 73.82 (+2.56) |
5.4 Limitations and conclusions
作者明确讨论的限制包括:zero-shot ARR 只能中等幅度降低 position bias,ARR w/ guide 后仍有残余 bias(Gemini 3.1 Pro 的 ,理想无偏应为 0);rubric cardinality 增大虽提升 accuracy,但推理/验证成本线性增加,并可能加入噪声或冗余 criteria;RPO 依赖 frozen VLM judge,因此 judge 本身的系统性偏差不会被完全消除。论文未详细说明生成评测集的样本规模,也未给出 released code 与 paper table batch size 的一一换算。
总体结论:ARR 证明“显式化评价标准”比单纯换更强 reward model 更关键。它在 preference evaluation 中稳定提升 Qwen3-VL-8B、GPT-5、Gemini 3.1 Pro;在 generation 中,ARR-RPO 把 rubric-conditioned preference 变成可优化的 online reward,使 FLUX.1-Dev / Qwen-Image-Edit-2509 在 T2I 与 editing benchmarks 上获得一致提升。最有价值的 takeaway 是:multimodal preference alignment 的瓶颈不是缺少偏好知识,而是缺少一个 factorized、inspectable、可用于训练的接口。