Astrolabe: Steering Forward-Process Reinforcement Learning for Distilled Autoregressive Video Models
Authors: Songchun Zhang, Zeyue Xue, Siming Fu, Jie Huang, Xianghao Kong, Yue Ma, Haoyang Huang, Nan Duan, Anyi Rao Affiliations: HKUST, JD Explore Academy, HKU arXiv: 2603.17051 Project Page: franklinz233.github.io/projects/astrolabe GitHub: franklinz233/Astrolabe Venue: arXiv 2026
1. Motivation (研究动机)
这篇论文讨论的不是“如何让视频模型更强”,而是一个更具体的问题:如何在不破坏 distilled autoregressive (AR) streaming video model 实时推理优势的前提下,用 online RL 把它们对齐到人类视觉偏好。
当前背景是:
-
视频 diffusion teacher 很强,但很慢
双向视频 diffusion model 质量高,但需要多步去噪,而且通常以全序列 joint denoising 的方式工作,不适合 real-time streaming generation。 -
distilled AR video model 很快,但偏好对齐不足
Self-Forcing、Causal Forcing、LongLive 这类 distilled AR model 通过 DMD 从双向 teacher 蒸馏出单步 / 少步、可 KV-cache streaming 的高效模型,能支持实时和长视频生成;但 distillation 只保证 student 拟合 teacher 分布,并不直接优化 human preference,所以生成结果经常出现:- 纹理不够讨喜
- 动作不自然
- temporal consistency 不稳
- artifact 和 flicker 较多
-
现有 RL 方法不天然适合 distilled AR video model
- reward-guided distillation / Reward Forcing:只是让高 reward 样本权重更大,本质仍偏向 supervised distillation,没有显式压制坏样本,也缺少有效 exploration
- reverse-process RL(如 Flow-GRPO / Dance-GRPO 一类):要在 reverse trajectory 上估计 log-prob,并依赖 solver unrolling;这和 distilled AR model 的快推理范式相冲突,会引入明显的 memory / compute overhead
- 长视频 RL 更难:如果直接对长 rollout 全反传,KV cache 和计算图会迅速爆炸
因此,本文要解决的核心问题是:
能否设计一个 trajectory-free、solver-agnostic、memory-efficient 的 RL 框架,专门用于 distilled AR video model 的偏好对齐,并且还能扩展到 long video?
这个问题值得研究,因为 distilled AR video model 的真正价值就在于“快”。如果对齐方法本身把这种速度优势吃掉,那么整个 streaming video 路线就会失去工程意义。
2. Idea (核心思想)
Astrolabe 的核心思想可以概括为四点:
-
不用 reverse-process RL,而改做 forward-process RL
它直接在 clean inference endpoint 上构造 implicit positive / negative policies,对比好样本和坏样本的目标方向,而不去存整条 denoising trajectory。 -
不用 sequence-level 全局 rollout,而是做 clip-level streaming rollout
利用 rolling KV cache + frame sinks,只保留必要上下文,把 RL credit assignment 压缩到局部 clip。 -
长视频训练时只对当前 window 反传,历史上下文全部 detach
这样既能模拟 test-time long-horizon generation 的误差积累,又不会因为长序列反传而 OOM。 -
不用单一 reward,而是 VQ + MQ + TA 多奖励联合优化,再配 selective KL regularization
这样既提升视觉美学,也抑制 reward hacking。
一句话总结就是:
Astrolabe 把 DiffusionNFT 式的 forward-process RL 迁移到 distilled AR video model,并用 streaming rollout + multi-reward regularization 让它真正适用于长视频。
和现有方法的根本区别在于:
- 它不重蒸馏 teacher;
- 它不走 reverse-process trajectory log-prob;
- 它不需要保存完整采样轨迹;
- 它把 RL 训练设计成和 streaming inference 结构匹配。
3. Method (方法)
3.1 整体框架
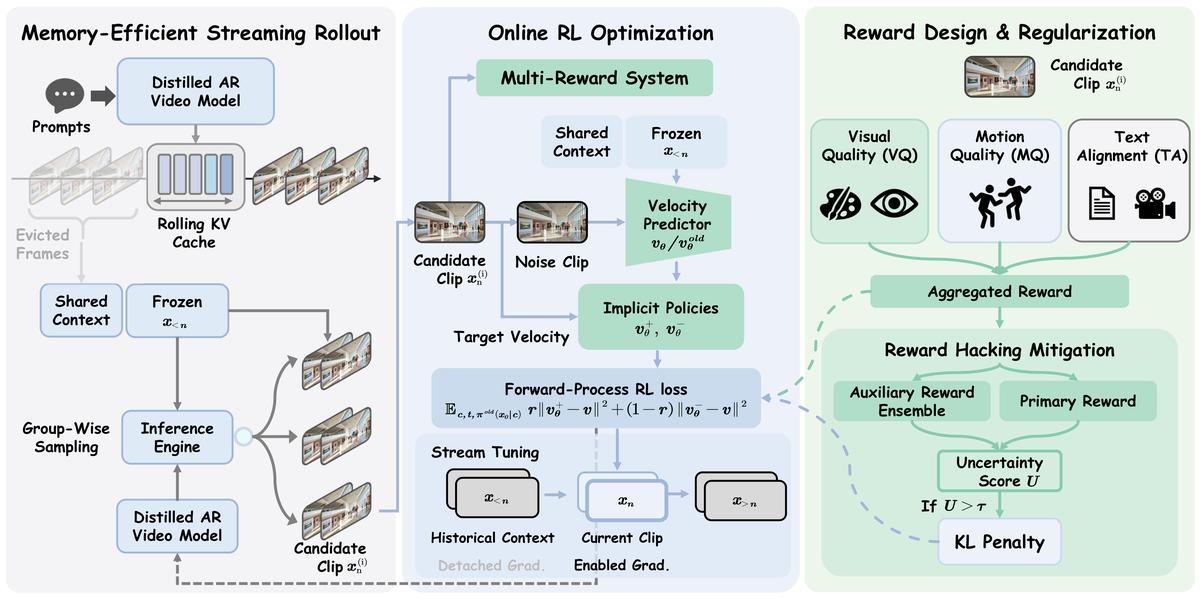
Figure 1 解读:这张图是整篇论文最重要的架构图。左边是 Memory-Efficient Streaming Rollout:用 rolling KV cache 和 shared context 做 group-wise candidate sampling;中间是 Online RL Optimization:对当前 clip 做 forward-process RL,并在 long video 情况下只对 local window 反传;右边是 Reward Design & Regularization:把 Visual Quality、Motion Quality、Text Alignment 三种 reward 聚合起来,再通过 uncertainty score 决定是否施加 KL penalty。整张图要表达的核心是:Astrolabe 不是单一 loss,而是 rollout、局部优化、奖励设计和稳定化机制的完整系统。

Figure 2 解读:这张 teaser 图展示了 Astrolabe 在三种场景上的效果:single-prompt short video、single-prompt long video、multi-prompt long video。无论是 Causal Forcing、LongLive 还是 Infinite-RoPE 风格的长视频 setting,加上 Astrolabe 后都能明显减轻 artifact、提升 temporal consistency,并让结果更接近“人看起来舒服”的分布。这也说明 Astrolabe 更像是一个通用 post-training 对齐层,而不是只绑定某个 base model 的 trick。
3.2 预备知识:AR video diffusion 与 forward-process RL
AR video model 将联合分布分解为:
沿用 flow matching 视角,每一帧或一段 clip 的 noisy path 写成:
Teacher Forcing / Diffusion Forcing 都会最小化 frame-wise MSE,但它们的训练上下文和测试时自回归生成上下文不一致,因此仍有 exposure bias。Self-Forcing 通过自回归 rollout 来缩小这个 gap,但并没有做偏好对齐。
Astrolabe 的 RL 起点来自 DiffusionNFT。给定 old velocity predictor 和 current predictor ,构造两个 implicit policies:
再用归一化 reward 去形成 policy loss:
直觉上:
- 高 reward 样本推动当前策略往 positive direction 移动;
- 低 reward 样本推动当前策略远离 negative direction;
- 全过程只需要 clean endpoint 与 forward noise,不需要 reverse trajectory。
3.3 Memory-Efficient Streaming Rollout
AR long video RL 的第一个难点是:如果直接做 sequence-level rollout,再对完整长视频反传,KV cache 和显存会迅速爆炸。Astrolabe 用两招解决:
3.3.1 Rolling KV Cache with Frame Sinks
在第 个生成步骤,模型不会缓存全部历史 ,而只保留一个受限上下文 :
- frame sink:固定保留的 帧,负责提供长期语义锚点
- rolling window:最近的 帧,负责局部细粒度条件
因此 resident KV memory 与总视频长度 解耦,只和 有关。论文附录 Table S1 中默认:
- frame sink size
- rolling window size (Self-Forcing)或 (LongLive)
3.3.2 Clip-level Group-wise Sampling
给定共享上下文 和文本条件 ,在第 步并行采样 个候选 clip:
论文的关键点是:不是生成 G 条完整长视频轨迹,而是把 prefix 历史 rollout 一次后冻结,然后只在当前 clip 上做 group-wise sampling。这样 rollout 的额外代价只发生在当前 local chunk,而不是整个序列。
从代码实现看:
pipeline/causal_inference.py维护 rolling KV cache;scripts/train_nft_wan.py/train_nft_wan_streaming.py使用 group-wise prompts 采样;- 当前 repo 中 long-video training 脚本会固定一个
epoch_window_start,整个 epoch 只采样到该 window 结尾所需的最短历史长度,从而进一步节省 rollout 代价。
3.4 Online RL Optimization
3.4.1 Clip-level Advantage
对每个候选 clip 计算 reward 后,用 group-wise mean-centering 得到优势:
然后归一化成:
这里的含义是:同一上下文下,当前 clip 只需要比同组其他候选更好即可获得正优势,因此 credit assignment 比 sequence-level 全局分数更精细。
3.4.2 去掉 adaptive weighting,直接做 x0-level forward-process RL
论文指出,DiffusionNFT 的 adaptive loss weighting 在 distilled AR setting 下会引发 gradient explosion,因此 Astrolabe 直接丢掉这部分。
在实际代码里,训练并不是直接回归 velocity,而是先把前向过程预测统一转成 x0 prediction,然后构造:
最终 policy loss 等价于:
这个实现与论文中的 implicit positive / negative policy 一致,只是落地成更直接的 x0 regression。
3.4.3 Streaming Long Tuning
长视频训练时,Astrolabe 先完整前向到目标训练窗口之前,累积历史 KV cache;当到达当前 active window 时:
- 历史上下文 的 cache 显式 detach
- 只对当前窗口做梯度反传
这样训练时:
- 前向动态 与 test-time 长视频生成一致;
- 梯度路径 只覆盖 local window;
- 峰值显存随视频总长度保持常数级。
这正是 Table 4(a) 里 “Clip+Detach” 同时得到最好 HPSv3/MQ 和最低显存的原因。
3.5 Reward Design and Regularization
3.5.1 Multi-reward Formulation
Astrolabe 不使用单一 scalar reward,而是拆成三种:
-
Visual Quality (VQ)
由 HPSv3 提供。代码里不是简单平均所有帧,而是取 top-30% frames 的均值,以减少瞬时 motion blur 对视觉美学分数的干扰。 -
Motion Quality (MQ)
由 VideoAlign 提供,但输入先转成 grayscale,强制模型把注意力放在 motion dynamics,而不是纹理或颜色。 -
Text Alignment (TA)
同样由 VideoAlign 提供,但保留 RGB,用来衡量语义一致性。
这一点在 astrolabe/rewards.py 里体现得很清楚:
video_hpsv3_localvideoalign_mq_scorevideoalign_ta_score
并且 reward 可以按权重自由组合。
3.5.2 Uncertainty-aware Selective KL Penalty
作者不希望对所有样本一刀切地加 KL penalty,因为这会压制高质量探索。论文提出用 reward rank disagreement 做 uncertainty 估计,只对高风险样本施加 KL。
附录算法里定义的总体目标是:
其中 selective KL 只在 high-uncertainty samples 上激活。
从代码看,实际做法是:
- 引入
old_refadapter 作为 lagging KL reference - 用主 reward 与 auxiliary rewards 的 rank difference 形成
reward_std_mask - 只对 mask 为真的样本计算 KL
- reference 用 EMA / 周期性 reset 动态更新
这和论文的 “selective trust region” 设计是对应的。
3.6 基于开源代码的伪代码
下面的伪代码基于实际仓库实现,而不是只复述论文文字。
def rolling_kv_groupwise_sampling(
pipeline,
prompts: list[str],
old_generator,
latent_h: int,
latent_w: int,
required_latent_frames: int,
group_size: int,
device: torch.device,
dtype: torch.dtype,
):
old_generator.model.set_adapter("old")
noise = torch.randn(
len(prompts),
required_latent_frames,
16,
latent_h,
latent_w,
device=device,
dtype=dtype,
)
with torch.no_grad():
# pipeline internally maintains rolling KV cache with frame sinks + recent window
video, latents = pipeline.inference(
noise=noise,
text_prompts=prompts,
return_latents=True,
)
# shared history is rolled out once; group-wise sampling cost is paid only on local clips
candidate_clips = []
for _ in range(group_size):
candidate_clips.append(latents.detach().clone())
old_generator.model.set_adapter("default")
return candidate_clips, video.detach(), latents.detach()def forward_process_policy_update(
model,
text_encoder,
prompts: list[str],
latents_x0: torch.Tensor,
advantages: torch.Tensor,
denoising_steps: list[int],
adv_clip_max: float,
beta: float,
):
t_idx = random.randint(0, len(denoising_steps) - 1)
current_t = denoising_steps[t_idx]
t_val = current_t / 1000.0
noise = torch.randn_like(latents_x0)
x_t = (1.0 - t_val) * latents_x0 + t_val * noise
with torch.no_grad():
cond_dict = text_encoder(text_prompts=prompts)
model.model.set_adapter("old")
with torch.no_grad():
_, old_pred_x0 = model(
noisy_image_or_video=x_t,
timestep=torch.ones(len(prompts), x_t.shape[1], device=x_t.device, dtype=torch.long) * current_t,
conditional_dict=cond_dict,
)
model.model.set_adapter("default")
_, pred_x0 = model(
noisy_image_or_video=x_t,
timestep=torch.ones(len(prompts), x_t.shape[1], device=x_t.device, dtype=torch.long) * current_t,
conditional_dict=cond_dict,
)
adv = torch.clamp(advantages, -adv_clip_max, adv_clip_max)
reward_weight = torch.clamp((adv / adv_clip_max) / 2.0 + 0.5, 0.0, 1.0)
pos_pred_x0 = beta * pred_x0 + (1.0 - beta) * old_pred_x0.detach()
neg_pred_x0 = (1.0 + beta) * old_pred_x0.detach() - beta * pred_x0
loss_pos = ((pos_pred_x0 - latents_x0) ** 2).mean(dim=tuple(range(1, latents_x0.ndim)))
loss_neg = ((neg_pred_x0 - latents_x0) ** 2).mean(dim=tuple(range(1, latents_x0.ndim)))
policy_loss = (reward_weight * loss_pos + (1.0 - reward_weight) * loss_neg).mean()
return policy_loss, pred_x0, old_pred_x0def streaming_long_tuning(
sampling_pipeline,
streaming_pipeline,
prompts: list[str],
latents_clean: torch.Tensor,
reward_fn,
total_frames: int,
window_size: int,
window_choices: list[int] | None,
):
window_start = select_window_start(
total_frames=total_frames,
window_size=window_size,
selection_mode="random",
num_frame_per_block=3,
device=latents_clean.device,
choices=window_choices,
)
required_latent_frames = window_start + window_size
# sample only up to the active window end instead of the full long video
with torch.no_grad():
full_video, full_latents = sampling_pipeline.inference(
noise=torch.randn_like(latents_clean[:, :required_latent_frames]),
text_prompts=prompts,
return_latents=True,
)
window_pixel_start = window_start * 4
window_pixel_end = (window_start + window_size) * 4
window_video = full_video[:, window_pixel_start:window_pixel_end]
rewards, _ = reward_fn(window_video, prompts, metadata=None, only_strict=True)
# inside compute_streaming_nft_loss, history cache is detached and only local window keeps gradients
old_pred, pred_x0, ref_pred_x0, window_latents, _ = streaming_pipeline.compute_streaming_nft_loss(
latents_clean=full_latents,
conditional_dict=None,
window_start=window_start,
timestep=None,
)
return rewards, old_pred, pred_x0, ref_pred_x0, window_latents, window_startdef multi_reward_selective_kl(
rewards_dict: dict[str, np.ndarray],
main_reward: str,
dynamic_controller,
pred_x0: torch.Tensor,
ref_pred_x0: torch.Tensor,
policy_loss: torch.Tensor,
kl_weight: float,
):
reward_std = []
reward_keys = [k for k in rewards_dict.keys() if k not in ["avg", main_reward]][:2]
reward_keys.append(main_reward)
for key in reward_keys:
scores = torch.tensor(rewards_dict[key])
_, indices = torch.sort(scores, descending=True)
ranks = torch.empty_like(scores).long()
ranks[indices] = torch.arange(1, len(scores) + 1)
reward_std.append(ranks.float())
if len(reward_std) >= 2:
rank_diff = reward_std[-1] - sum(reward_std[:-1]) / len(reward_std[:-1])
positive_rank_diff = np.array([x for x in rank_diff.cpu().numpy() if x >= 0])
dynamic_controller.update(positive_rank_diff)
threshold = np.percentile(positive_rank_diff, 100 - dynamic_controller.beta * 100)
reward_std_mask = rank_diff > threshold
else:
reward_std_mask = torch.ones(len(rewards_dict["avg"]), dtype=torch.bool, device=pred_x0.device)
if reward_std_mask.any():
kl_loss = ((pred_x0[reward_std_mask] - ref_pred_x0[reward_std_mask]) ** 2).mean(
dim=tuple(range(1, pred_x0.ndim))
).mean()
else:
kl_loss = ((pred_x0 - ref_pred_x0) ** 2).mean() * 0.0
total_loss = policy_loss + kl_weight * kl_loss
return total_loss, kl_loss, reward_std_mask3.7 Code-to-paper mapping table
| Paper Concept | Source File | Key Class / Function | 说明 |
|---|---|---|---|
| 训练主入口(短视频 RL) | scripts/train_nft_wan.py | main training loop | 实现 default / old / old_ref adapter、advantage、policy loss、selective KL |
| 训练主入口(长视频 streaming RL) | scripts/train_nft_wan_streaming.py | epoch_window_start, streaming loop | 只采样到 active window 结束所需帧,并在窗口级别计算 reward |
| Rolling KV cache streaming inference | pipeline/causal_inference.py | CausalInferencePipeline.inference | 维护 causal KV cache,逐 block 去噪并更新 clean context |
| Wan backbone 封装 | utils/wan_wrapper.py | WanDiffusionWrapper, WanTextEncoder, WanVAEWrapper | 封装 Wan2.1 / causal inference / x0 conversion |
| Reward 聚合 | astrolabe/rewards.py | multi_score | 聚合 VQ / MQ / TA,多奖励加权 |
| HPSv3 VQ reward | astrolabe/scorers/video/hpsv3.py | HPSv3RewardInferencer | 对 top-30% 帧均值打分 |
| VideoAlign MQ / TA reward | astrolabe/scorers/video/videoalign.py | VideoAlignScorer | MQ 用 grayscale,TA 用 RGB |
| Reward uncertainty & prompt-wise stats | astrolabe/stat_tracking.py, scripts/train_nft_wan.py | PerPromptStatTracker, RiskCompensator | 做 per-prompt 标准化、rank disagreement 风险控制 |
| GPU / rollout 配置 | configs/_base_clean.py, configs/nft_*.py | GPU presets / config builders | 管理不同 baseline、GPU 数、reward 组合 |
| 显存与动态 swap 工具 | utils/memory.py | DynamicSwapInstaller, memory helpers | 支持显存约束下的推理与训练 |
代码完整性备注:当前主仓库已经公开主要训练 / 推理脚本,但
scripts/train_nft_wan_streaming.py引用了pipeline.streaming_rl_training,该辅助文件未在当前 repo tree 中出现。因此关于 streaming long tuning 的最细节实现,我主要依据论文正文、附录算法和脚本调用接口进行交叉还原。
4. Experimental Setup (实验设置)
4.1 模型与训练设置
论文主要基于 distilled autoregressive Wan2.1 系列 做实验,核心 baseline 包括:
- Self-Forcing
- Causal Forcing
- LongLive
训练方面:
- prompts 来自 VidProM 的过滤子集(与 DanceGRPO 一致)
- 使用 LoRA 做 parameter-efficient fine-tuning
- rank
- scaling factor
- 优化器:AdamW
- 训练硬件:48 × NVIDIA H200
- 精度:bf16 mixed precision

Table S1 解读:附录超参数表把工程设置写得很清楚。最关键的配置包括:Wan2.1 Causal backbone、480×832 分辨率、LoRA rank/alpha=256、bf16、AdamW、learning rate 、distillation timesteps 为 4(从 [1000, 750, 500, 250] 采样)、forward noise level 0.7、、advantage clip max=5、EMA decay 0.9,以及 rolling window / frame sink 的 streaming rollout 参数。
需要注意的一点是:
- 论文附录默认 给出 interpolation strength
- 但当前开源 repo 的部分具体 config(例如某些 Causal Forcing 配置)把
config.beta设成了0.1
这说明 release code 对不同 baseline / reward setting 做了额外调参,不能机械地把论文默认值当成所有实验配置。
4.2 评测协议
4.2.1 Short-video single-prompt
- 按 VBench 协议评测
- 使用 946 个 standard prompts
- 指标包括:
- Total
- Quality
- Semantic
- HPSv3
- MQ
- Throughput
4.2.2 Long-video single-prompt
- 按 VBench-Long 协议评测
- 每个 prompt 生成 30 秒视频
- 对于 Self-Forcing / Causal Forcing,这些模型原本只训练在 5 秒序列上,因此作者用 Infinity-RoPE 做 positional extrapolation
- 对比开源 long-video 方案:
- SkyReels-V2
- FramePack
4.2.3 Long-video multi-prompt
- 采用 100 组 narrative scripts
- 每组有 6 个连续 10 秒 prompt,最终得到 60 秒 long-form video
- 在 10 秒边界切分,评测:
- Quality Score
- Consistency Score
- Aesthetic Score
- CLIP Score(0–10, 10–20, …, 50–60)
4.3 Reward 设计
训练时用的三个 reward 为:
- VQ:HPSv3(top-30% frame mean)
- MQ:VideoAlign on grayscale video
- TA:VideoAlign on RGB video
附加稳定化组件:
- per-prompt reward normalization(
PerPromptStatTracker) - selective KL regularization
- lagging KL reference + EMA update
5. Experimental Results (实验结果)
5.1 Short-video:在不降低吞吐的前提下提升偏好质量

Figure 3 解读:在短视频单 prompt 设置下,Astrolabe 相比 Self-Forcing、Reward-Forcing、CausVid 等 baseline 更稳定地改善纹理细节和动作自然性。特别是左上电吉他、右上喷泉、左下发光人物、右下龙等案例中,+Ours 版本在主体清晰度、轮廓稳定性和视觉吸引力上都明显更好,而 baseline 更容易出现模糊、漂移或不自然的光效。
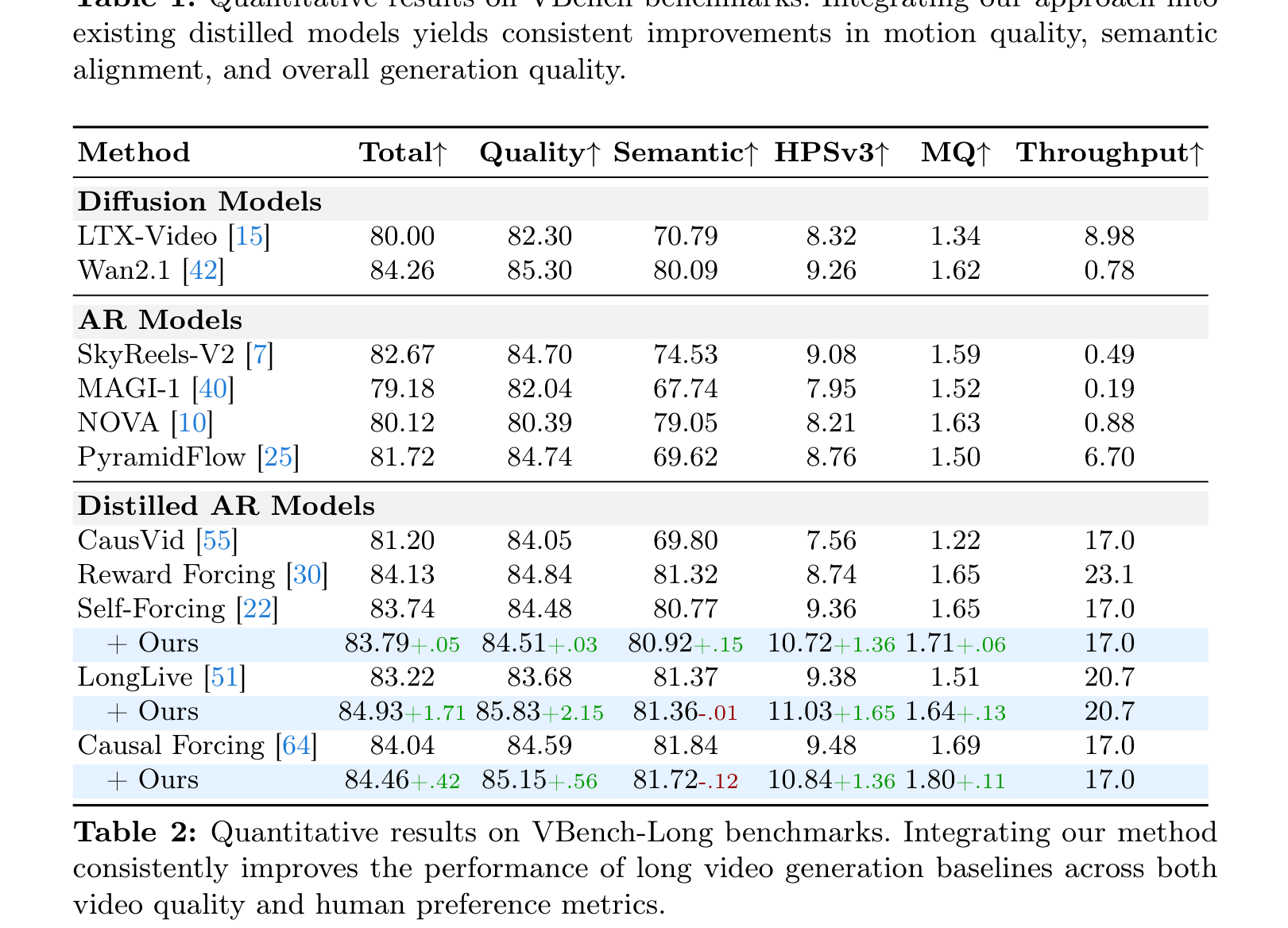
Table 1 解读:短视频 VBench 结果显示,Astrolabe 对不同 distilled AR model 都能带来稳定增益,而且推理吞吐完全不变。例如:
- Self-Forcing
- Total: 83.74 → 83.79
- HPSv3: 9.36 → 10.72
- MQ: 1.65 → 1.71
- Throughput: 17.0 不变
- LongLive
- Total: 83.22 → 84.93
- Quality: 83.68 → 85.83
- HPSv3: 9.38 → 11.03
- MQ: 1.51 → 1.64
- Throughput: 20.7 不变
- Causal Forcing
- Total: 84.04 → 84.46
- Quality: 84.59 → 85.15
- HPSv3: 9.48 → 10.84
- MQ: 1.69 → 1.80
- Throughput: 17.0 不变
值得注意的是,Semantic 分数并不是每次都升,例如 LongLive 与 Causal Forcing 的 +Ours 分别有轻微下降(-0.01 / -0.12)。这意味着 Astrolabe 的主要收益更集中在人类偏好相关的美学与动态质量,而不是全面提高所有 benchmark 维度。
5.2 Long-video single-prompt:短视频对齐可外推到长视频

Figure 4 解读:在单 prompt 长视频设置下,+Ours 版本能明显改善长程稳定性。例如高空飞行、机器人城市、海底钢琴等案例里,LongLive 基线在序列推进中更容易出现主体变形、视角漂移或细节塌缩,而 Astrolabe 版本保持了更稳定的主体结构与纹理连续性。这说明它不是只优化短时局部帧,而是确实改善了长时间 rollout 下的误差积累。
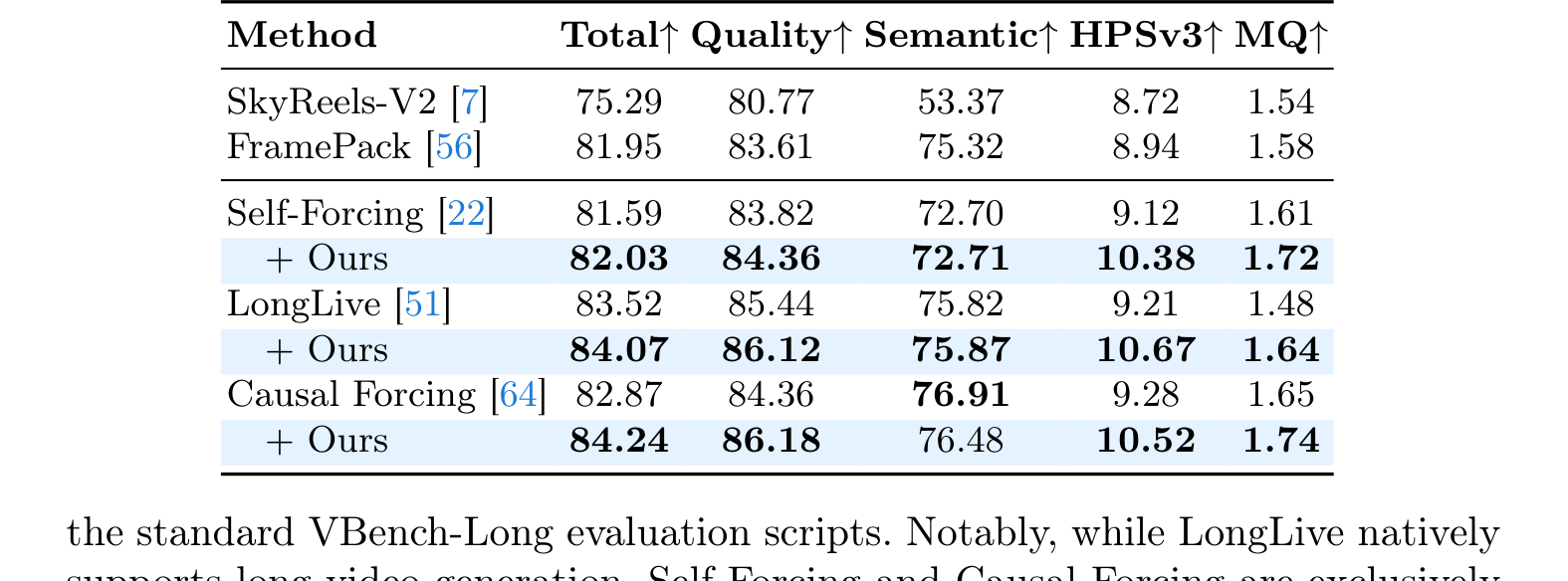
Table 2 解读:VBench-Long 上,Astrolabe 对三种 long-video baseline 都有效:
- Self-Forcing
- Total: 81.59 → 82.03
- Quality: 83.82 → 84.36
- HPSv3: 9.12 → 10.38
- MQ: 1.61 → 1.72
- LongLive
- Total: 83.52 → 84.07
- Quality: 85.44 → 86.12
- Semantic: 75.82 → 75.87
- HPSv3: 9.21 → 10.67
- MQ: 1.48 → 1.64
- Causal Forcing
- Total: 82.87 → 84.24
- Quality: 84.36 → 86.18
- HPSv3: 9.28 → 10.52
- MQ: 1.65 → 1.74
- 但 Semantic: 76.91 → 76.48,略有下降
因此,论文的一个重要结论是:
在短视频上做的 RL 对齐,并不会局限在短序列,而可以外推到长视频 generation。
5.3 Long-video multi-prompt:复杂叙事切换下也有收益
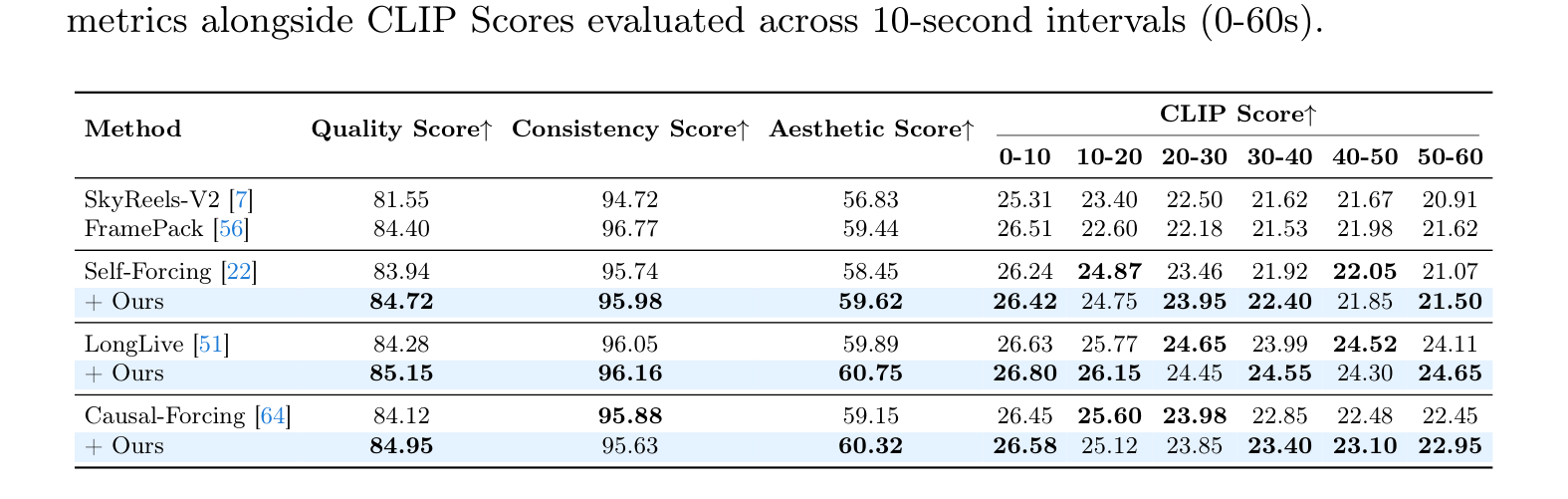
Table 3 解读:多 prompt 长视频结果更能体现 Astrolabe 对“叙事连续性”的帮助。对三种 baseline,+Ours 基本都提高了 Quality / Consistency / Aesthetic,并在大多数 10 秒区间上的 CLIP score 更稳。举例:
- Self-Forcing
- Quality: 83.94 → 84.72
- Consistency: 95.74 → 95.98
- Aesthetic: 58.45 → 59.62
- LongLive
- Quality: 84.28 → 85.15
- Consistency: 96.05 → 96.16
- Aesthetic: 59.89 → 60.75
- Causal-Forcing
- Quality: 84.12 → 84.95
- Consistency: 95.88 → 95.63(轻微下降)
- Aesthetic: 59.15 → 60.32
这说明 Astrolabe 的确提升了长视频 narrative setting 下的总体人类偏好,但不同基座模型在 consistency / alignment 上的收益并不完全一致。
5.4 Ablation:四个组件各有作用
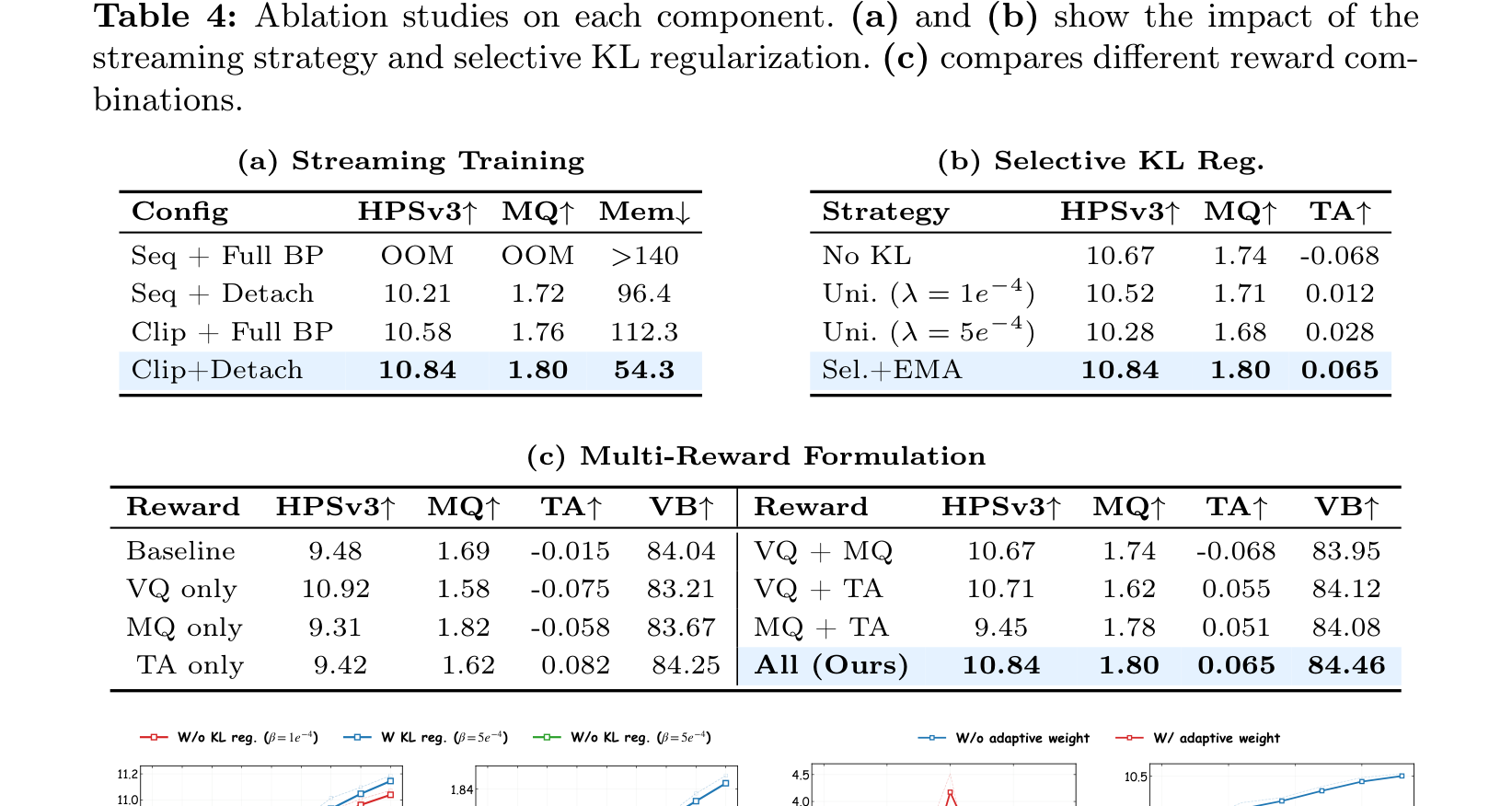
Table 4 解读:这是理解 Astrolabe 为什么有效的关键表。它分三部分:
(a) Streaming Training
- Seq + Full BP:OOM
- Seq + Detach:HPSv3 10.21,MQ 1.72,Mem > 96.4
- Clip + Full BP:HPSv3 10.58,MQ 1.76,Mem > 112.3
- Clip + Detach:HPSv3 10.84,MQ 1.80,Mem 54.3
结论:clip-level + detached history 是最优 trade-off;既省显存,又最好训。
(b) Selective KL Reg.
- No KL:HPSv3 10.67,MQ 1.74,TA -0.068
- Uniform KL ():10.52 / 1.71 / 0.012
- Uniform KL ():10.28 / 1.68 / 0.028
- Selective + EMA:10.84 / 1.80 / 0.065
结论:一刀切 KL 会过约束,不加 KL 又容易 reward hacking;selective KL + lagging reference 才能两头兼顾。
(c) Multi-Reward Formulation
- Baseline:HPSv3 9.48, MQ 1.69, TA -0.015
- VQ only:HPSv3 最强 10.92,但 MQ 降到 1.58,TA 变负
- MQ only:MQ 高 1.82,但 HPSv3 掉到 9.31
- TA only:TA 高 0.082,但 HPSv3/MQ 不好
- All (Ours):HPSv3 10.84, MQ 1.80, TA 0.065, VB 84.46
这组消融很说明问题:单 reward 会直接诱发 reward hacking。比如只优化 VQ,模型更容易走向“静态但好看”的方向;而多奖励联合才是均衡解。
5.5 代码实现层面的额外观察
从开源代码还能看出几件正文没那么显式强调、但很关键的工程事实:
-
训练主要是 LoRA 层,而不是整模型 full finetune
scripts/train_nft_wan.py通过peft给CausalWanAttentionBlock内的线性层加 LoRA- current / old / old_ref policy 共用同一个 frozen base model,只切换不同 adapter
-
行为策略与当前策略解耦
default:当前待优化策略old:behavior policyold_ref:KL reference
-
reward 风险控制是“排序差异驱动”
- 代码里确实按多个 reward 的 rank difference 来近似 uncertainty,再动态调整阈值
-
长视频训练是明显更工程化的
- 先选
epoch_window_start - 只生成到该 window 结尾所需的最短历史
- 用一个单独的 sampling model 和 training model 分工
- 先选
这些实现细节说明 Astrolabe 不只是提出新 loss,而是相当完整地把“如何在大模型显存约束下做 streaming video RL”做了一轮系统工程。
5.6 局限性与总体结论
论文最后明确提到两类限制:
-
reward model 本身仍有限
- HPSv3 和 VideoAlign 更擅长评估短期 aesthetics / motion / text alignment
- 对长时物理一致性、复杂交互、多实体因果结构仍不足
-
RL 无法凭空创造 base model 没有的能力
- 如果原始 distilled AR base model 对复杂几何、稀有知识或长时稳定性本来就弱,Astrolabe 只能“改善展示质量”,不能突破 base architecture 的能力上限
我的总体判断是:
Astrolabe 的贡献不是提出一个更强的 reward model,也不是发明一个新视频 backbone,而是第一次比较完整地回答了“如何对 distilled AR streaming video model 做高效在线 RL”这个问题。
它最有价值的地方在于:
- 把 RL 从 reverse-process 拉回到更适合 distilled AR model 的 forward-process;
- 用 clip-level + detached history 解决 long video RL 的显存瓶颈;
- 用 multi-reward + selective KL 避免 reward hacking;
- 而且所有这些改动都不牺牲原有 throughput。
所以如果你关心的是 实时视频生成 / streaming video / distilled AR video model 的 post-training 对齐,这篇论文是非常值得读的。