Advantage Weighted Matching: Aligning RL with Pretraining in Diffusion Models
Authors: Shuchen Xue, Chongjian Ge, Shilong Zhang, Yichen Li, Zhi-Ming Ma Affiliations: UCAS, Adobe Research, HKU, MIT arXiv: 2509.25050 GitHub: scxue/advantage_weighted_matching
1. 研究动机 (Motivation)
预训练与 RL 后训练的目标不一致问题
在大语言模型(LLM)中,预训练和 RL 后训练共享同一个 log-likelihood 目标:预训练最大化 teacher-forced 序列 log-likelihood,而 RL 则对同一个 likelihood 进行 reward-weighted 调整。两者在目标函数上高度一致,因此 RL 后训练能够自然地建立在预训练基础之上。
然而,扩散模型的 RL 后训练与预训练采用了完全不同的 likelihood 公式:
- 预训练:使用 score/flow matching 目标 ,这是通过前向过程(forward process)以干净数据 为条件的。
- RL 后训练(DDPO/Flow-GRPO/Dance-GRPO):采用 Denoising Diffusion Policy Optimization(DDPO)框架,将去噪过程建模为多步 MDP,每步反向转移 作为 policy。这实际上是通过反向过程(reverse process)以带噪中间状态 为条件的。
这一差异带来两个核心问题:
- 为什么 RL 后训练和预训练使用不同的 likelihood 公式?
- DDPO loss 实际上在优化什么目标?
本文通过理论分析揭示:DDPO 隐式地执行了以带噪数据 为条件的 Denoising Score Matching(DSM),而带噪条件化会导致 DSM 目标方差增大,从而使优化收敛变慢。
2. 核心思想 (Idea)
AWM:用预训练的 score/flow matching 目标对齐 RL
Advantage Weighted Matching(AWM) 的核心思想是:直接将 reward 信号融入到与预训练相同的 score/flow matching 目标中,用每个样本的 advantage 对该目标进行加权,从而:
- 消除带噪条件化引入的额外方差:AWM 使用干净数据 而非带噪中间状态 作为条件,直接对应预训练目标,方差更低。
- 将序列级 policy 建模为对 的条件分布:DDPO 将 state 定义为 ,action 为 ;而 AWM 将 state 直接定义为 condition ,action 为完整生成的 ,从概念上统一了 LLM 和扩散模型的 RL 框架。
- 解耦训练与采样:AWM 使用前向过程生成 对进行训练,可以使用任意 ODE/SDE sampler 生成训练样本,不依赖于特定的 Euler-Maruyama 离散化。
- 保持建模目标与预训练一致:预训练和 RL 后训练都优化同一个 DSM/FM 目标,仅权重不同(预训练均匀加权,AWM 按 advantage 加权)。
直觉上,AWM 对高奖励样本放大学习信号、对低奖励样本压制学习信号,同时保持模型的建模目标与预训练完全一致。这类似于 LLM 中 RLHF 对同一 log-likelihood 目标进行 reward-weighted 调整的方式。
3. 方法 (Method)
3.1 整体框架

Figure 1 解读:图 1 对比了 DDPO 和 AWM 的三个维度:(a) 公式对比:DDPO 最大化逐步的 per-step Gaussian log-likelihood ,以带噪中间状态 为条件;AWM 最大化 reward-weighted 的 score/flow matching loss,以干净的 为条件。(b) 目标方差:以带噪数据 为条件的 DSM(DDPO 隐式做的事)方差高于以干净数据 为条件的 DSM(AWM);(c) 收敛速度:在 GenEval 上,AWM 以最多 更少的 GPU 小时达到与 Flow-GRPO 相同的质量。
3.2 背景:扩散模型与 Flow Matching
扩散模型将干净数据 加噪为 ,其中 ,。
Flow Matching(FM)采用线性插值前向过程 ,训练 velocity 预测网络 最小化:
采样时,通过求解以下 diffusion SDE 来生成样本:
数据 的 log-likelihood 可通过 ELBO 近似:
3.3 理论分析:DDPO 隐式地在做带噪 DSM
3.3.1 DDPO 的 MDP 形式化
DDPO 将去噪建模为多步 MDP:state ,action ,policy 。
在 Euler-Maruyama 离散化下,反向 SDE 更新为:
这给出 Gaussian policy ,其 per-step log-likelihood 为:
3.3.2 Theorem 1:DDPO 隐式地在做带噪 DSM
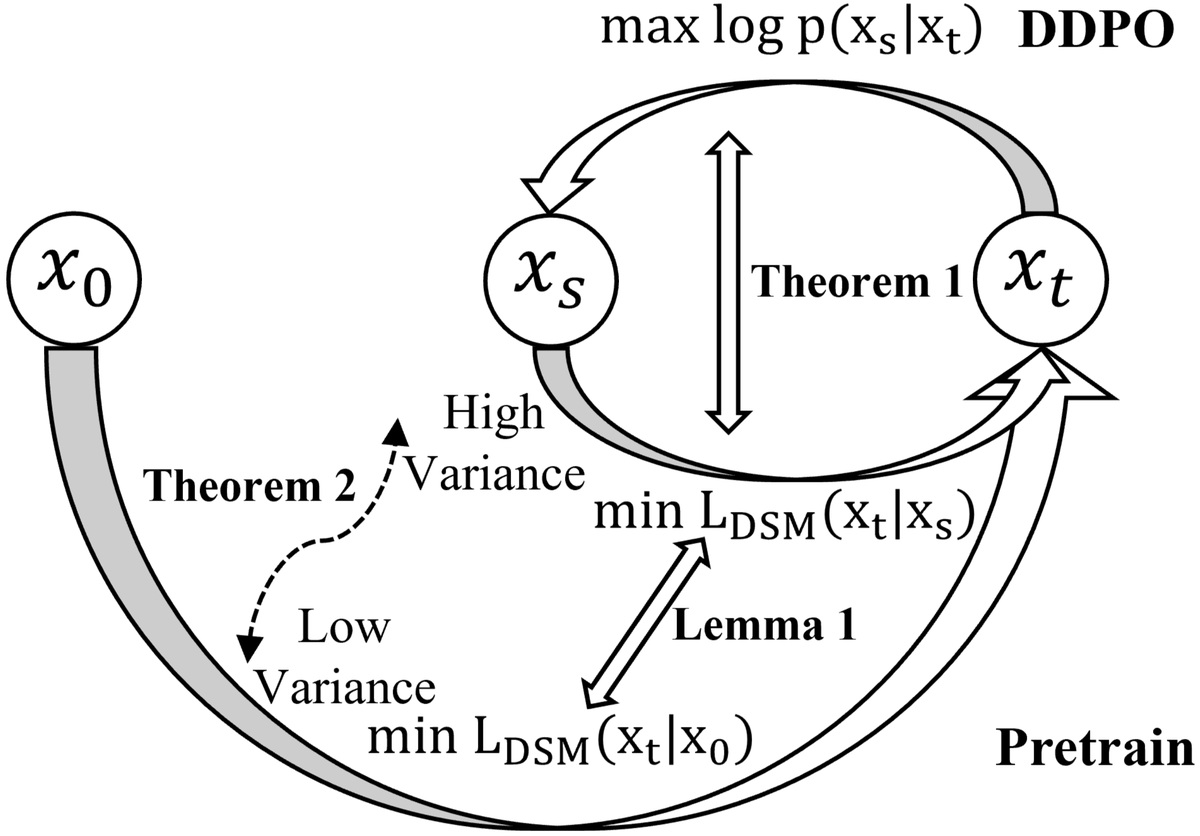
Figure 2 解读:图 2 展示了本文理论分析的概览。图中三个圆弧形箭头对应三个核心结论:(1) Theorem 1(右侧弧):DDPO 目标(最大化 )等价于以带噪数据 为条件的 DSM;(2) Lemma 1(下侧弧):以带噪数据 为条件的 DSM 与以干净数据 为条件的标准 DSM 有相同的总体最小化器(population minimizer);(3) Theorem 2(左侧弧):以带噪数据为条件会引入额外方差(High Variance),导致优化更慢,与 AWM(Low Variance)形成对比。
Theorem 1(DDPO 隐式在做带噪数据的 Denoising Score Matching):
优化 DDPO 目标(公式 4 中的逐步 log-likelihood)等价于,omitting Euler-Maruyama 离散化误差,最小化以前向过程带噪数据为条件的 Denoising Score Matching loss:
证明思路:利用 Haussmann & Pardoux (1986) 的扩散过程时间反转定理, 在反向过程中的联合分布与在前向过程中相同(忽略 Euler-Maruyama 离散化误差)。因此最大化反向过程的 log-likelihood 等价于最小化前向过程的带噪 DSM loss。
3.3.3 Lemma 1:带噪 DSM 与干净 DSM 同一总体最小化器
Lemma 1(带噪数据的 Denoising Score Matching):
对于任意时间步 和 (),以带噪数据 为条件优化 DSM 目标:
等价于优化标准 Score Matching 目标:
该引理将经典的”以干净数据为条件的 DSM 等价于 Score Matching”的结论推广到以带噪数据为条件的情形( 时退化为经典结论)。
3.3.4 Theorem 2:带噪条件化增大 DSM 目标方差
Theorem 2(带噪数据的 DSM 目标方差更大)的详细版本:
满足:
且有 (公式 26)。
两个条件得分: 和 ,对于任意固定的 和任意 ,都是真实得分 的无偏估计:
然而,其条件协方差满足:
其中额外方差项为:
特别地,,其中 是数据维度。 在 上严格递增,。
对于任意预测器 (如 ),以 为条件的目标方差满足:
因此,条件风险(conditional risk)和条件目标方差都在 时取得最小值,并在 上严格递增。
3.3.5 实验验证(CIFAR-10 和 ImageNet-64)
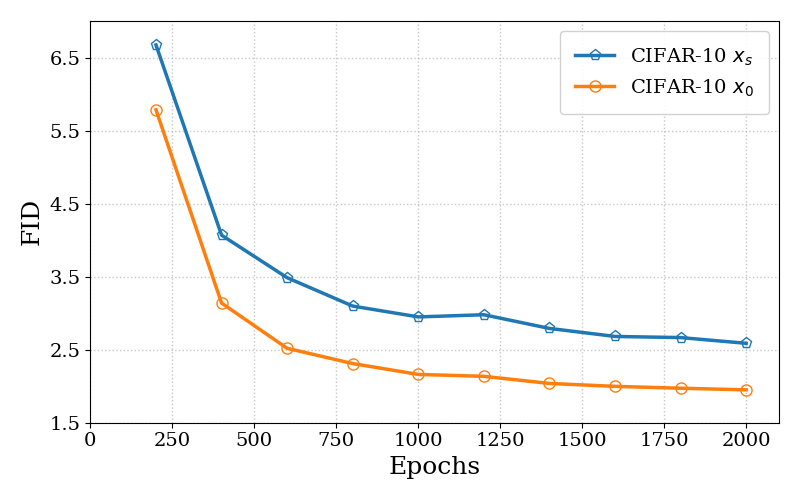 Figure 3a 解读:图 3 左图使用 EDM codebase 在 CIFAR-10 上对比以干净数据(,橙色)和带噪数据(,蓝色)为条件的 DSM 目标。带噪目标(对应 DDPO 隐式做的事)始终高于干净目标(对应 AWM),且收敛更慢,验证了 Theorem 2 的方差分析。
Figure 3a 解读:图 3 左图使用 EDM codebase 在 CIFAR-10 上对比以干净数据(,橙色)和带噪数据(,蓝色)为条件的 DSM 目标。带噪目标(对应 DDPO 隐式做的事)始终高于干净目标(对应 AWM),且收敛更慢,验证了 Theorem 2 的方差分析。
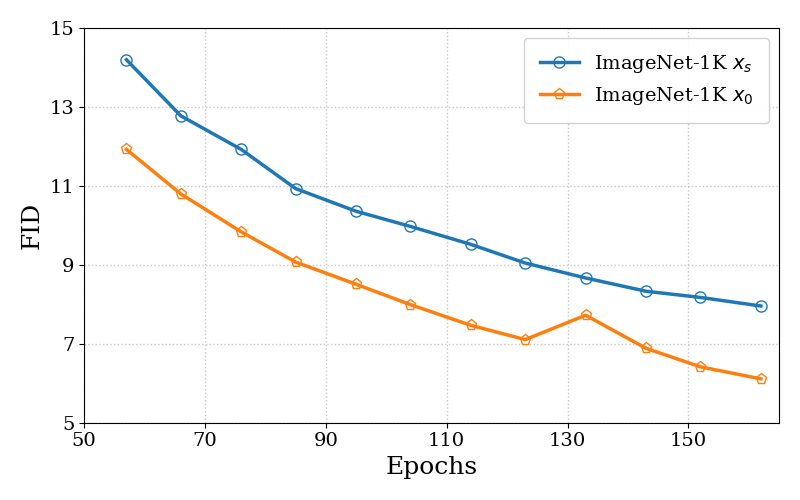
Figure 3b 解读:图 3 右图使用 EDM codebase 在 ImageNet-64 上对比以干净数据(,橙色)和带噪数据(,蓝色)为条件的 DSM 目标。带噪目标(对应 DDPO 隐式做的事)始终高于干净目标(对应 AWM),且收敛更慢,验证了 Theorem 2 的方差分析。具体实现为:
- 干净 DSM 目标(公式 7):
- 带噪 DSM 目标(公式 8,mirror DDPO):
3.4 Advantage Weighted Matching(AWM)算法

Figure 4 解读:图 4 展示了 AWM 的完整 pipeline。对于每个 prompt :(1) 使用扩散模型(任意 ODE/SDE sampler)采样一组图像 ;(2) 通过 Reward Function 计算奖励,然后通过 Advantage (group relative mean 或 value model baseline)计算 advantage;(3) 对 加噪得到 ,计算 Score Matching Loss ;(4) 用 advantage 加权的 Score Matching Loss 更新扩散模型 (trainable module,火焰图标)。关键特性:推理时可以使用任意 ODE/SDE sampler。
AWM 的问题重新定义
对比 DDPO 和 AWM 的 MDP 定义:
| DDPO | AWM | |
|---|---|---|
| State | ||
| Action | ||
| Policy | $\pi(a_t | s_t) = p_\theta(x_{t-1} |
AWM 将整个生成过程视为序列级的 policy,以条件 为输入, 为输出。
AWM 的 GRPO 目标函数
给定 prompt 和从 采样的一组样本 ,计算奖励 和 advantage (如 group relative mean)。GRPO 目标为:
ELBO 替代序列 log-likelihood
由于精确计算 不可行,AWM 使用 score/flow matching loss 作为其 ELBO 替代:
其中 是标准时间权重(如 ELBO 对应的权重)。实践中发现均匀权重 效果更好。
likelihood ratio 估计
因此,likelihood ratio 可以通过 ELBO 代理来估计(使用 LLaDA 1.5 提出的共享 timestep 和 noise 策略以降低方差):
KL 正则化项
KL 项通过速度空间(velocity space)代理来估计:
单样本梯度展开
对于单样本 ,AWM 的单步更新梯度为:
当 (高质量样本)时,梯度减小 flow matching loss,将 拉向目标 ;当 (低质量样本)时,梯度推动 远离该目标。
3.5 Algorithm 1:AWM 训练伪代码
以下是论文中 Algorithm 1 的完整伪代码(对应 train_sd3_awm.py 中的训练循环):
Algorithm 1: AWM Training Loop
for i in range(num_training_steps):
# 1. 采样:用任意 sampler 生成图像
samples = sampler(model, prompt)
# 2. 计算奖励
reward = reward_fn(samples)
# 3. 计算 advantage(如 group relative mean)
advantage = cal_adv(reward, prompt)
# 4. 前向加噪:对干净的 x0 加噪
noise = randn_like(samples)
timesteps = get_timesteps(samples)
noisy_samples = fwd_diffusion(samples, noise, timesteps)
# 5. 计算当前 policy 的 velocity 预测
velocity_pred = model(noisy_samples, timesteps, prompt)
# 6. 可选:计算参考 policy 的 velocity 预测(用于 KL loss)
velocity_ref = ref_model(noisy_samples, timesteps, prompt)
# 7. 计算 flow matching log-probability(负的 FM loss)
log_p = -((velocity_pred - (noise - samples))**2).mean()
# 8. 计算 importance ratio(on-policy 时为 1,off-policy 时用旧 log_p)
ratio = torch.exp(log_p - log_p_old.detach())
# 9. advantage-weighted policy loss(带 PPO-style clip)
policy_loss = -advantage * ratio
# 10. 速度空间 KL 正则项
kl_loss = weight(timesteps) * ((velocity_pred - velocity_ref)**2).mean()
# 11. 总 loss
loss = policy_loss + beta * kl_loss3.6 compute_log_prob_awm 详解
compute_log_prob_awm 是 AWM 的核心函数(位于 train_sd3_awm.py),直接对应论文公式 (10):
def compute_log_prob_awm(transformer, pipeline, sample, timestep,
embeds, pooled_embeds, config,
noised_latents, clean_latents, random_noise,
weighting='Uniform'):
# 1. 预测 velocity(支持 CFG)
noise_pred = transformer(
hidden_states=noised_latents, # x_t = (1-t)*x_0 + t*ε
timestep=timestep.view(-1) * 1000,
encoder_hidden_states=embeds,
pooled_projections=pooled_embeds,
return_dict=False,
)[0]
sigma = timestep # sigma = t(flow matching 中 sigma 等于 t)
# 计算 SDE 扩散系数(用于 KL loss 中的 ELBO 权重)
std_dev_t = torch.sqrt(sigma / (1 - torch.clamp(sigma, 0, 0.99))) * 0.7
# 2. 计算 AWM log-probability(flow matching loss 的负值)
# target = ε - x_0(flow matching 的 velocity 目标)
model_output = noise_pred.double()
log_prob = -(model_output - (random_noise.double() - clean_latents.double()))**2
log_prob = log_prob.mean(dim=tuple(range(1, log_prob.ndim)))
# 3. 可选的时间步权重(默认 Uniform,即 w(t)=1)
if weighting == 'Uniform':
log_prob = log_prob # w(t) = 1
elif weighting == 't':
log_prob = log_prob * timestep.view(-1)
elif weighting == 't**2':
log_prob = log_prob * timestep.view(-1)**2
elif weighting == 'huber':
log_prob = -(torch.sqrt(-log_prob + 1e-10) - 1e-5) * timestep.view(-1)
elif weighting == 'ghuber':
log_prob = -(torch.pow(-log_prob + 1e-10, config.train.ghuber_power) - ...) * timestep.view(-1) / config.train.ghuber_power
return log_prob, model_output, std_dev_t代码-论文对应关系:
| 代码变量 | 论文符号 | 含义 |
|---|---|---|
noised_latents | 前向加噪后的 latent | |
clean_latents | VAE 编码后的干净 latent | |
random_noise | 加噪用的随机噪声 | |
noise_pred / model_output | 模型预测的 velocity | |
random_noise - clean_latents | flow matching 的 velocity 目标 | |
log_prob | ELBO 代理 log-probability | |
ratio | importance ratio | |
advantage | group relative mean advantage | |
policy_loss | advantage-weighted policy loss | |
kl_loss | velocity-space KL proxy(公式 12) | |
beta | KL 正则化强度 |
3.7 采样-训练解耦的优势
AWM 通过使用前向过程(而非反向过程)来生成训练对 ,实现了采样与训练完全解耦:
- 可以使用任意 ODE/SDE sampler(如 DPM-Solver、SA-Solver)生成训练样本 ,不受限于 DDPM/Euler-Maruyama。
- 采样 timestep 和训练 timestep 可以解耦:如可以用 20 步采样,但用 4 步训练,大幅降低训练计算开销( 理论加速)。
- 允许使用 step-distilled 模型加速采样(留作未来工作)。
3.8 AWM 与 DDPO 的关键对比
| 维度 | DDPO/Flow-GRPO | AWM |
|---|---|---|
| 条件化方式 | 以带噪 为条件 | 以干净 为条件 |
| Likelihood | per-step Gaussian log-likelihood | ELBO-based score/flow matching |
| 目标方差 | 高(Theorem 2 证明额外 ) | 低(最小化方差) |
| 采样依赖 | 依赖 DDPM/Euler-Maruyama 离散化 | 支持任意 sampler |
| 与预训练对齐 | 不一致(不同 likelihood) | 完全一致(相同 loss,不同权重) |
| CFG 支持 | 训练时需要 CFG | 训练时不需要 CFG(与预训练一致) |
| 收敛速度 | 基线 | 最多 快 |
4. 实验设置 (Experimental Setup)
4.1 模型与 Benchmarks
使用两个代表性开源模型:
- SD3.5M(Stable Diffusion 3.5 Medium,Esser et al., 2024)
- FLUX(Black Forest Labs, 2024)
在三个 reward benchmarks 上评估:
- GenEval(Ghosh et al., 2023):图像-文本构图准确率,测量颜色、数量、空间关系等
- OCR(Chen et al., 2023a):视觉文字渲染准确率
- PickScore(Kirstain et al., 2023):人类偏好对齐
4.2 超参数设置
- LoRA 配置:,(SD3.5M);,(FLUX)
- Group size:
- KL ratio :GenEval 和 OCR 设为 ,PickScore 设为
- 学习率:(常数)
- 时间步权重:(均匀权重)
- 默认 sampler:Euler-Maruyama(训练时总步数 4)
- 训练步数:训练时 4 步,采样时可用更多步
4.3 Baseline
主要 baseline 为 Flow-GRPO(Liu et al., 2025),其在 SD3.5M 上的 GenEval 总体得分为 ,作为 参考加速。
5. 实验结果 (Experimental Results)
5.1 GenEval 主结果

Figure 5 解读:GenEval 性能对比,Speed-up 相对于 Flow-GRPO baseline。
| 模型 | Single Obj. | Two Obj. | Counting | Color | Position | Attr | Overall | Speed-up |
|---|---|---|---|---|---|---|---|---|
| DALLE-3 | 0.96 | 0.87 | 0.47 | 0.83 | 0.43 | 0.45 | 0.67 | – |
| GPT-4o | 0.99 | 0.92 | 0.85 | 0.92 | 0.75 | 0.61 | 0.84 | – |
| SD-XL | 0.98 | 0.74 | 0.39 | 0.85 | 0.10 | 0.23 | 0.55 | – |
| FLUX.1 Dev | 0.98 | 0.81 | 0.74 | 0.79 | 0.22 | 0.45 | 0.66 | – |
| SD3.5L | 0.98 | 0.89 | 0.73 | 0.83 | 0.34 | 0.47 | 0.71 | – |
| SD3.5M(base) | 0.98 | 0.78 | 0.50 | 0.81 | 0.24 | 0.52 | 0.63 | – |
| Flow-GRPO | 1.00 | 0.99 | 0.95 | 0.92 | 0.99 | 0.86 | 0.95 | |
| AWM (Ours) | 1.00 | 0.99 | 0.95 | 0.93 | 0.98 | 0.83 | 0.95 |
AWM 以 更少的 GPU 小时达到与 Flow-GRPO 相同的 GenEval 得分(0.95),包括 Two-Object(0.99)和 Color(0.93)等所有子任务。
5.2 OCR 和 PickScore 结果
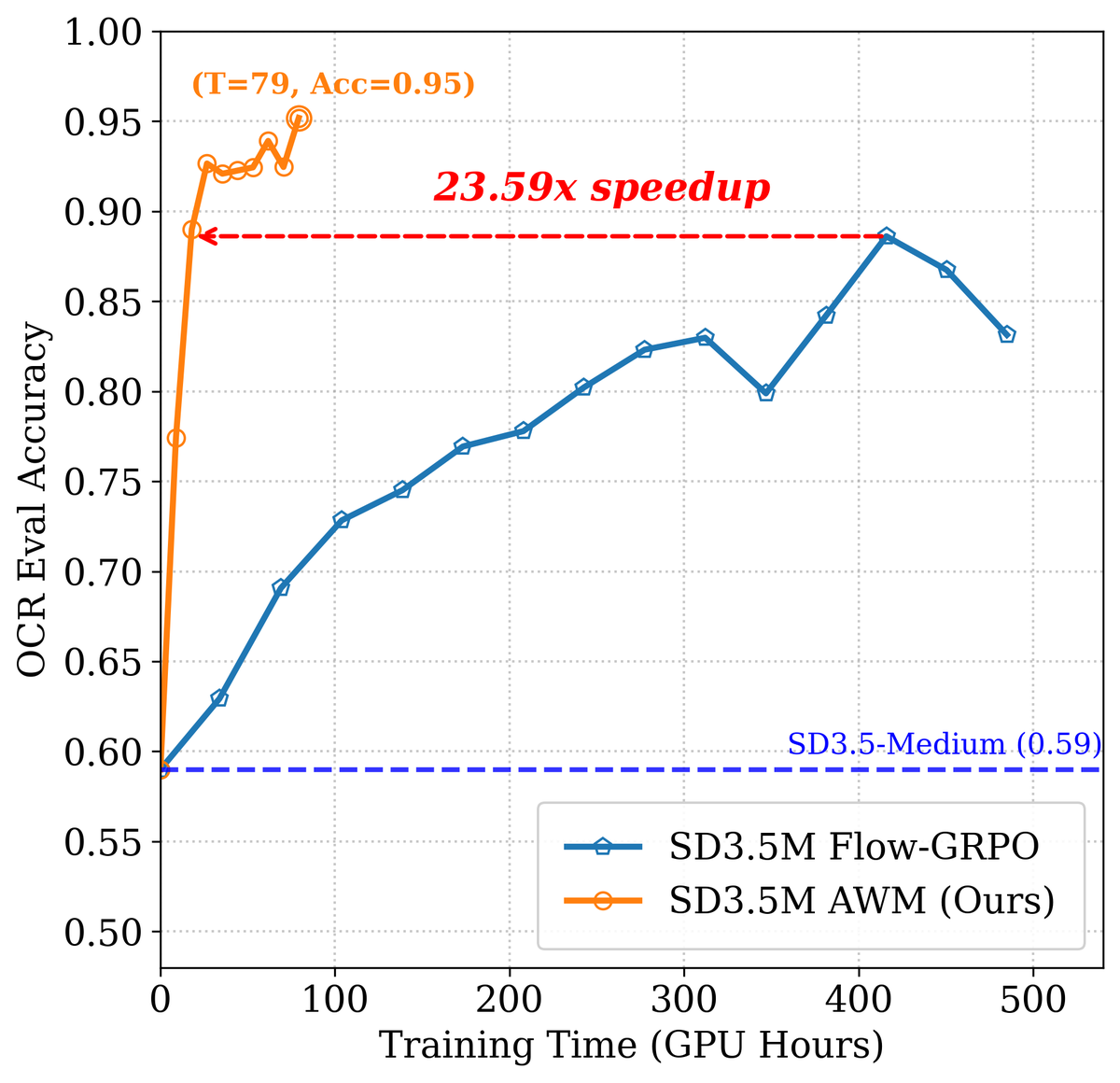 Figure 5a 解读:SD3.5M OCR 的训练效率对比(Metric vs. GPU hours)。AWM(橙色)以更少的计算量达到与 Flow-GRPO(蓝色)相同的性能,速度提升为 。
Figure 5a 解读:SD3.5M OCR 的训练效率对比(Metric vs. GPU hours)。AWM(橙色)以更少的计算量达到与 Flow-GRPO(蓝色)相同的性能,速度提升为 。
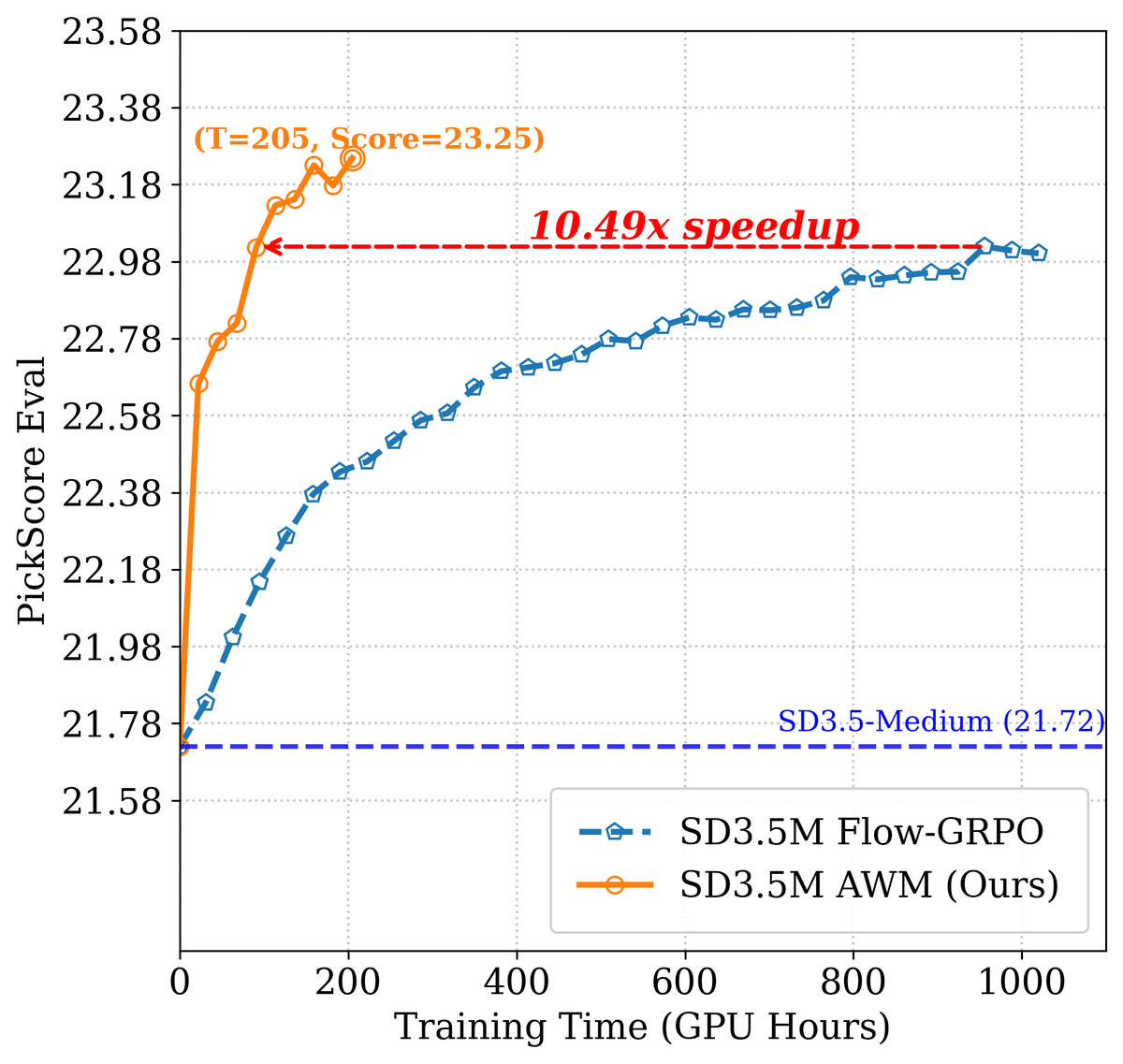 Figure 5b 解读:SD3.5M PickScore 的训练效率对比(Metric vs. GPU hours)。AWM(橙色)以更少的计算量达到与 Flow-GRPO(蓝色)相同的性能,速度提升为 。
Figure 5b 解读:SD3.5M PickScore 的训练效率对比(Metric vs. GPU hours)。AWM(橙色)以更少的计算量达到与 Flow-GRPO(蓝色)相同的性能,速度提升为 。
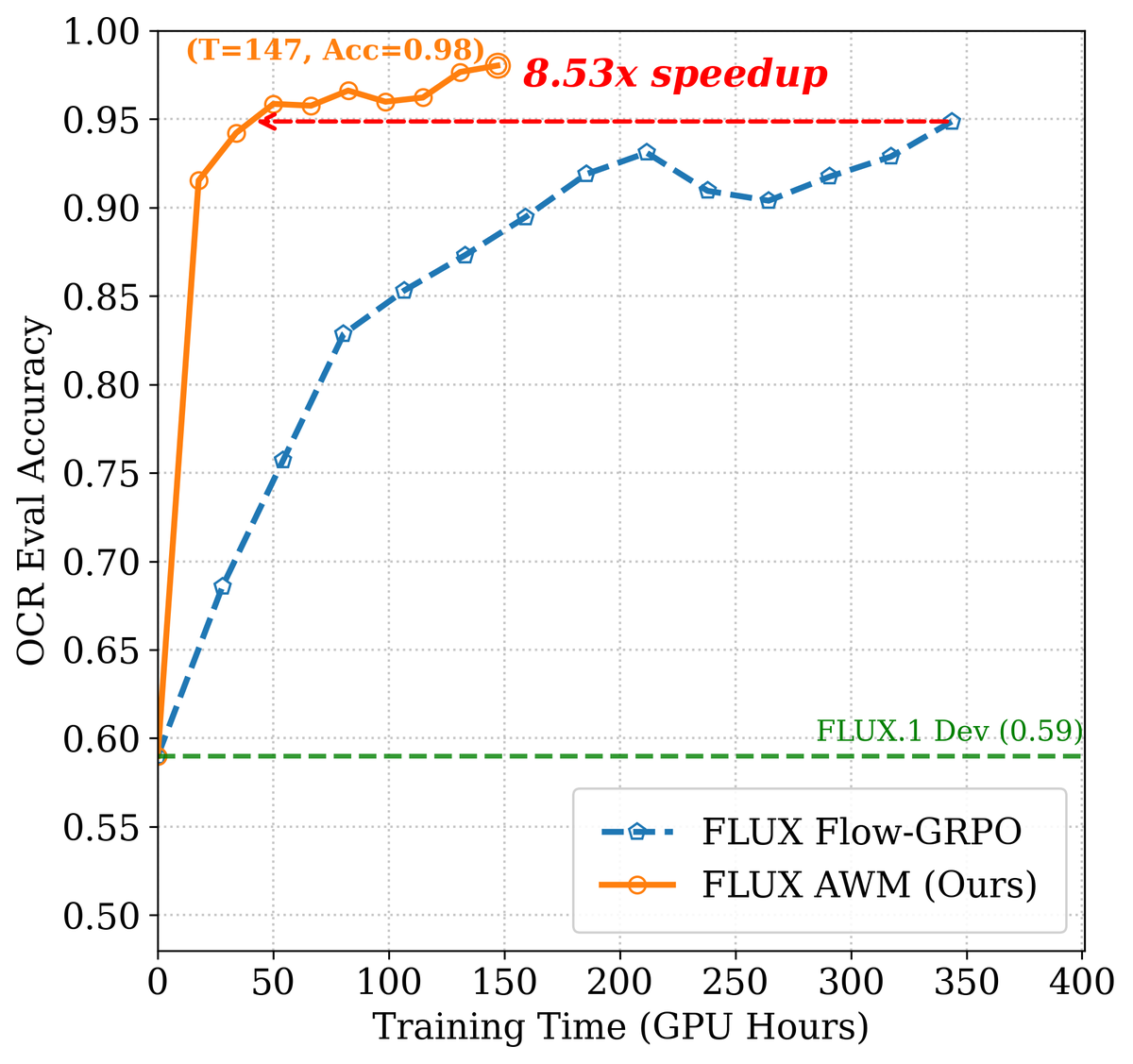 Figure 5c 解读:FLUX OCR 的训练效率对比(Metric vs. GPU hours)。AWM(橙色)以更少的计算量达到与 Flow-GRPO(蓝色)相同的性能,速度提升为 。
Figure 5c 解读:FLUX OCR 的训练效率对比(Metric vs. GPU hours)。AWM(橙色)以更少的计算量达到与 Flow-GRPO(蓝色)相同的性能,速度提升为 。
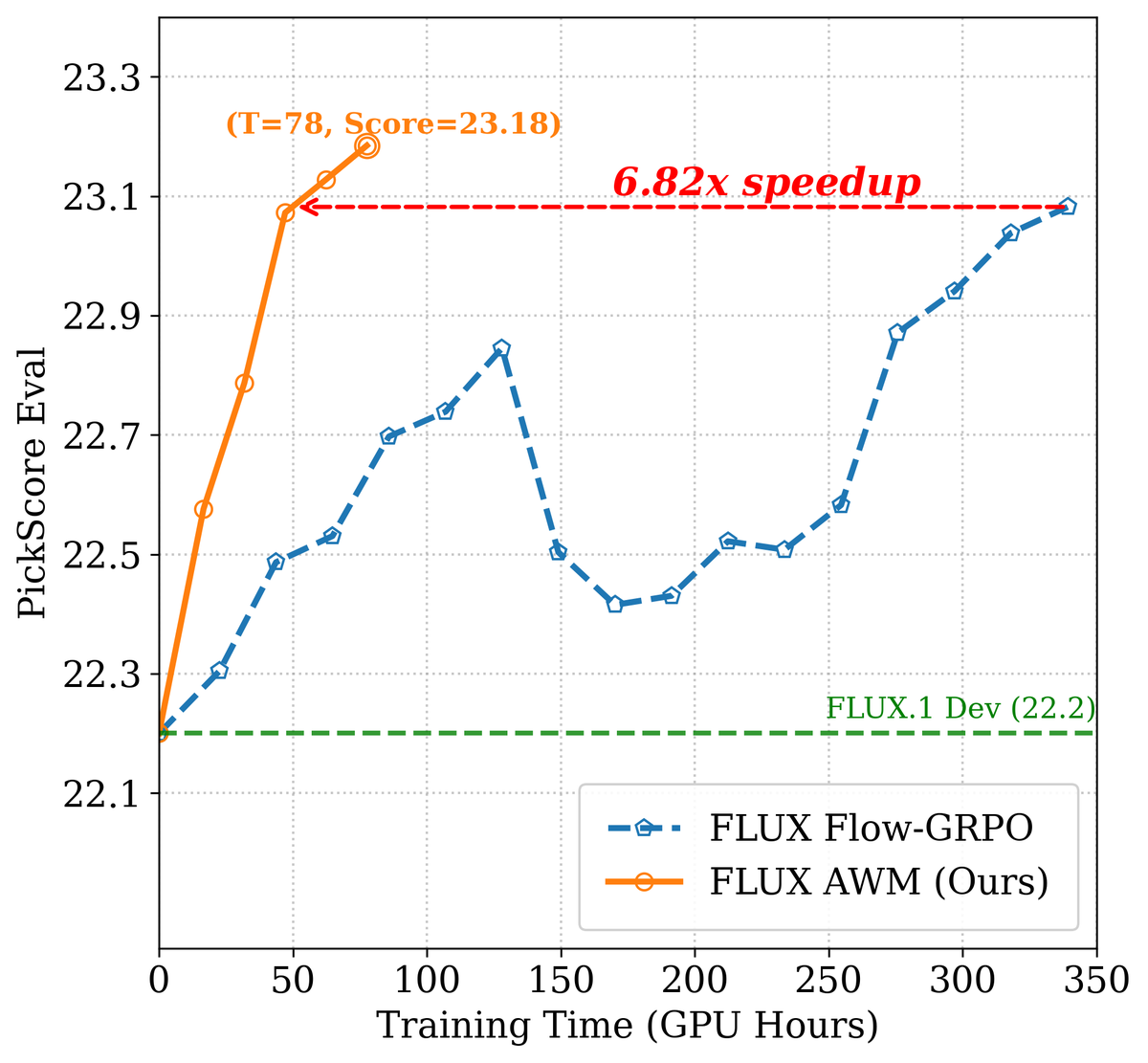 Figure 5d 解读:FLUX PickScore 的训练效率对比(Metric vs. GPU hours)。AWM(橙色)以更少的计算量达到与 Flow-GRPO(蓝色)相同的性能,速度提升为 。四个子图共同展示了 AWM 在 SD3.5M 和 FLUX 上均能以远少于 Flow-GRPO 的计算量达到相同或更高的性能水平。
Figure 5d 解读:FLUX PickScore 的训练效率对比(Metric vs. GPU hours)。AWM(橙色)以更少的计算量达到与 Flow-GRPO(蓝色)相同的性能,速度提升为 。四个子图共同展示了 AWM 在 SD3.5M 和 FLUX 上均能以远少于 Flow-GRPO 的计算量达到相同或更高的性能水平。
Table 2 精确数据(Hours 为总 GPU 小时,Speed-up 相对 Flow-GRPO baseline):
| Method | SD3.5M OCR Acc | Hours | SD3.5M PS Score | Hours | FLUX OCR Acc | Hours | FLUX PS Score | GPU hours |
|---|---|---|---|---|---|---|---|---|
| Base model | 0.59 | – | 21.72 | – | 0.59 | – | 22.20 | – |
| FlowGRPO | 0.89 | 415.9 () | 23.01 | 956.1 () | 0.95 | 343.6 () | 23.08 | 339.2 () |
| AWM (Ours) | 0.89 | 17.6 () | 23.02 | 91.1 () | 0.95 | 40.3 () | 23.08 | 49.8 () |
| AWM (Ours)† | 0.95 | (+6.74%) 79.0 | 23.25 | (+0.99%) 205.0 | 0.99 | (+4.21%) 147.0 | 23.18 | (+0.43%) 78.0 |
(†表示训练时间更长)
5.3 视觉对比
Figure 6 解读:论文 Figure 6 为 FLUX baseline(第一行)和经过 100 步 AWM 训练后(第二行)的视觉质量对比(图像网格,未单独提取为 PNG)。提示词来自 GenEval 和 OCR benchmarks,包括组合构图(“three black rabbits below one white horse”,“three purple foxes below one blue bird” 等)和文字渲染任务(“Spring Collection 2024”,“Step Goal Achieved”)。AWM 训练 100 步后,模型在数量(如 “three”、“one”)、颜色(如 “purple”、“blue”)和位置约束上均有显著改善,且文字渲染精度提高。
5.4 消融实验
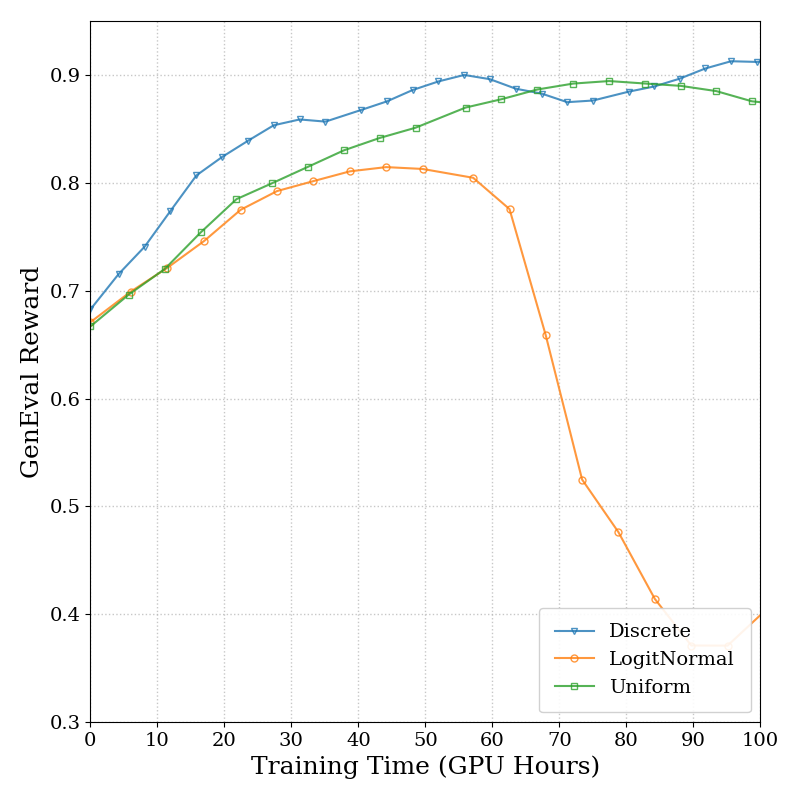 Figure 7a 解读:SD3.5M 上 GenEval reward vs. GPU hours 的消融曲线中,时间步采样 对比 discrete(离散,在推理 sampler 的时间栅格上均匀采样)、uniform(连续均匀)和 logit-normal 三种策略;discrete 和 uniform 性能相近,logit-normal 稍慢且后期退化,默认使用 discrete。
Figure 7a 解读:SD3.5M 上 GenEval reward vs. GPU hours 的消融曲线中,时间步采样 对比 discrete(离散,在推理 sampler 的时间栅格上均匀采样)、uniform(连续均匀)和 logit-normal 三种策略;discrete 和 uniform 性能相近,logit-normal 稍慢且后期退化,默认使用 discrete。
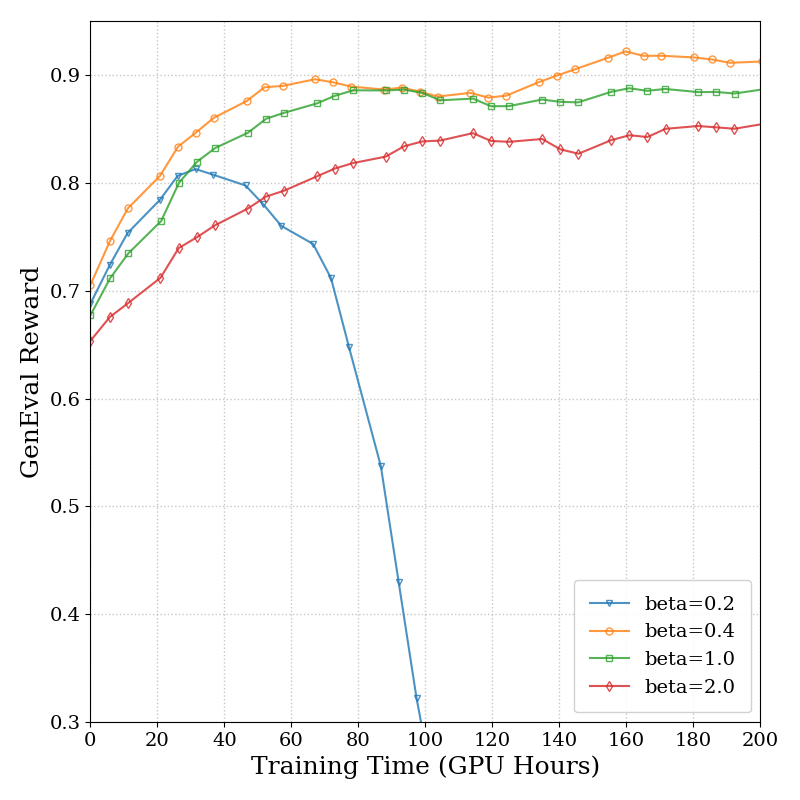 Figure 7b 解读:SD3.5M 上 GenEval reward vs. GPU hours 的消融曲线中,KL 强度 对比 ; 不稳定, 学习太慢, 稳定且快,默认 。
Figure 7b 解读:SD3.5M 上 GenEval reward vs. GPU hours 的消融曲线中,KL 强度 对比 ; 不稳定, 学习太慢, 稳定且快,默认 。
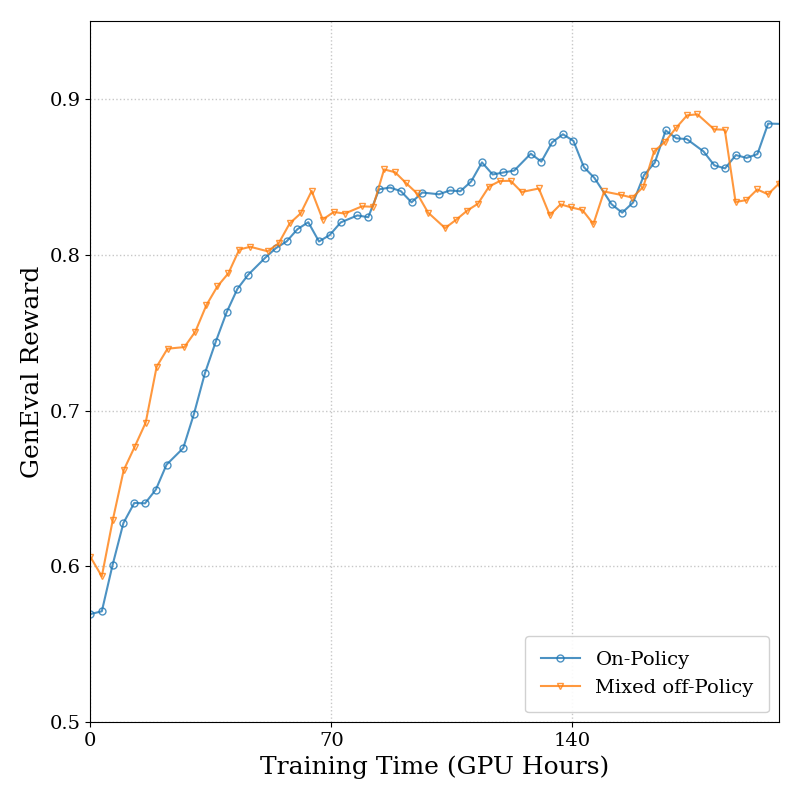 Figure 7c 解读:SD3.5M 上 GenEval reward vs. GPU hours 的消融曲线中,On-policy vs. Mixed off-policy 的对比显示,混合策略(50% 样本来自前一步 policy,使用 importance ratio)与纯 on-policy 性能几乎相同,默认使用混合策略以支持未来更深度的 off-policy 扩展。
Figure 7c 解读:SD3.5M 上 GenEval reward vs. GPU hours 的消融曲线中,On-policy vs. Mixed off-policy 的对比显示,混合策略(50% 样本来自前一步 policy,使用 importance ratio)与纯 on-policy 性能几乎相同,默认使用混合策略以支持未来更深度的 off-policy 扩展。