1. Motivation (研究动机)
当前 native unified multimodal models (UMMs) 的核心矛盾是:理解任务通常依赖 CLIP/SigLIP 这类 pretrained representation encoder,生成任务又依赖 VAE/VQ-VAE 这类 reconstruction-oriented encoder;即使后续方法尝试用 shared vision encoder 做统一表征,模型仍然不是从 raw pixels 到语言/图像的完全 end-to-end 优化。这个设计会带来两类瓶颈:一是 understanding 与 generation 的视觉表征目标不一致,二是 pretrained vision encoder 自带固定分辨率、语义偏置、低层细节访问不足等 inductive bias。
本文要解决的具体问题是:是否可以彻底移除 VAE 与 representation encoder,只用简单 patch embedding 把 raw RGB pixels 转成 visual tokens,再由单个 LLM decoder 和 flow matching head 同时完成视觉理解、图像生成与编辑。换句话说,论文不是单纯提出一个更强 UMM,而是在验证一个结构性问题:pretrained vision encoders 对统一多模态建模是否必要。
这个问题值得研究,因为如果答案成立,UMM 的结构会明显简化:视觉输入不再需要外部 encoder/tokenizer 的预训练和对齐阶段,理解与生成可以在同一 pixel-space representation 上端到端学习。更重要的是,pixel-space training 可能保留更多 fine-grained visual details,从而改善 OCR、计数、小目标、反常识视觉定位等对低层细节敏感的理解任务。
2. Idea (核心思想)
核心 insight:在足够大规模的统一多模态预训练下,简单的 pixel patch embeddings 可以替代 pretrained vision encoders;encoder-free 架构早期收敛较慢,但在理解任务上最终超过 encoder-based 变体,尤其是 fine-grained perception。Tuna-2 的关键不是换一个 encoder,而是把视觉 encoder 模块整体退化为 Conv2d patchify,并把视觉表征学习压力转移到 unified LLM decoder + pixel-space flow head。
方法上,作者按“逐步拆掉视觉编码模块”的路线做 controlled comparison:Tuna 保留 VAE + representation encoder,Tuna-R 去掉 VAE 但保留 SigLIP 2 representation encoder,Tuna-2 则连 representation encoder 也去掉,只保留 raw-pixel patch embedding。生成侧不再采用 latent diffusion,而是在 pixel space 上使用 JiT 风格的 -prediction + -loss;训练侧再加入 masking-based feature learning,迫使模型在遮挡 patch 的情况下同时学习重建和理解。
与 Show-o2、Tuna、Janus-Pro 等 native UMM 的根本区别在于:这些方法仍然显式依赖视觉 tokenizer/encoder 或 latent-space 表征;Tuna-2 则把“视觉编码”压缩为一个非重叠 patchify 层,让同一个 Transformer 在 pixel tokens 与 text tokens 上联合建模。因此它测试的是更激进的假设:视觉语义表征可以在统一多模态训练中从像素端自然涌现,而不是必须从外部 vision encoder 继承。
3. Method (方法)
3.1 Overall framework:从 Tuna 到 Tuna-R 再到 Tuna-2

Figure 1 解读:图中从左到右展示三种架构。Tuna 使用 VAE Encoder/Decoder 与 Representation Encoder,理解和生成都经过较重的视觉编码模块;Tuna-R 去掉 VAE,保留 Representation Encoder,并把生成迁移到 pixel-space;Tuna-2 进一步去掉 Representation Encoder,只用 Patchify Layer 把 raw image 变成 visual tokens。这个图的重点不是性能柱状图本身,而是架构归因:随着视觉 encoder 模块被移除,Tuna-2 仍能在一组理解与生成指标上超过 Tuna/Tuna-R,说明性能提升不是来自更复杂的视觉前端。
Tuna-2 的主干由三部分组成:第一,text tokenizer 把 prompt/answer 转成 text tokens;第二,SimplePatchEmbedding 把 RGB image 切成 non-overlapping patches 并映射到 LLM hidden size;第三,Qwen2.5-7B-Instruct decoder 对 text tokens 与 image tokens 联合建模,输出同时接 language modeling head 与 diffusion/flow matching head。理解任务走 autoregressive next-token prediction,生成/编辑任务走 pixel-space flow matching。
直觉上,Tuna-2 把“从局部像素到可推理视觉语义”的学习交给大规模 unified pretraining,而不是让 SigLIP/VAE 预先决定哪些视觉信息应该保留。这个选择会提高训练难度,因为 pixel space 比 latent space 冗余得多;但一旦数据规模足够,模型可以直接访问细粒度纹理、文字、小物体和空间关系,因此在 OCRBench、CountBench、V*、VisuLogic 等 pixel-centric benchmarks 上更有优势。

Figure 2 解读:图中给出 Tuna-2 在 text-to-image generation 与 image editing 上的 qualitative examples。它用于支持一个关键论点:即使完全 encoder-free,pixel-space UMM 仍能生成高保真图像,并能根据编辑指令保留主体、修改局部属性或改变风格。该图不能替代定量评测,但说明“去掉 VAE/encoder”并不等于只能做低质量重建。
3.2 Pixel-space flow matching
Tuna-2 去掉 VAE 后,不能沿用 latent diffusion 的设计,因此在 RGB pixel space 直接做 rectified flow。给定 clean image 、Gaussian noise 与 timestep ,线性 schedule 构造 noisy sample:
模型直接预测 clean image:
其中 包含 vision-language backbone 与 flow matching head, 是条件信号:text-to-image 时是文本,image editing 时是文本加源图像。虽然网络输出是 ,训练目标仍转换为 velocity regression:
推理时使用 Euler solver,从较 noisy 的 走到更 denoised 的 :
开源实现中,jit_x0_prediction_loss 直接对 做 MSE,并乘以 ;这与论文中的 -loss 等价,因为 。因此实现层面的 loss 可写成:
3.3 Masking-based feature learning
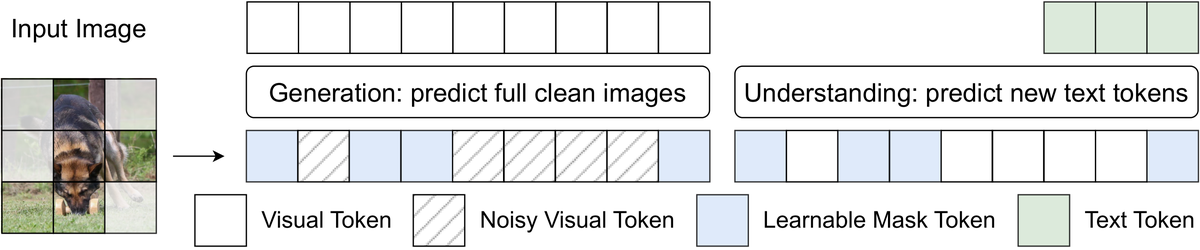
Figure 3 解读:图中橙色是 normal visual tokens,红色是 noisy visual tokens,灰色是 learnable mask token,蓝色是 text tokens。对于 generation examples,模型要在 masked 与 unmasked 区域都预测完整 clean image,这会提高 denoising 难度;对于 understanding examples,模型需要在部分视觉 patch 被 mask 的条件下生成 text answer,这相当于对视觉理解进行 regularization。
masking 的作用不是简单的数据增强,而是缓解 pixel-space 的冗余问题。raw pixels 中有大量局部相关和表面纹理,模型可能通过低级 shortcut 完成重建,却没有学到对理解和生成都稳健的视觉表征。随机替换 patch embedding 后,生成任务必须利用可见上下文恢复被遮挡区域,理解任务必须在不完整视觉证据下完成推理;这促使 LLM decoder 内部形成更 robust 的 visual representation。
3.4 Training pipeline
Tuna-2 的训练是两阶段 end-to-end pipeline。Stage 1 full model pretraining 同时训练 image captioning 与 text-to-image generation,用于建立 flow matching head 的初始化,并让 pixel-space 输入适配统一理解/生成。Stage 2 supervised finetuning 使用 image instruction-following、image editing 与 high-quality image generation 数据,以更低学习率增强指令跟随、编辑与高质量生成。Tuna-R 因为有 representation encoder 与 LLM decoder 之间的 connector,额外增加一个 connector alignment stage;Tuna-2 没有该阶段。
3.5 Pseudocode from official implementation
以下伪代码基于官方 repo 的 main@f08f15b9,只保留与论文机制对应的核心逻辑。
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimplePatchEmbedding(nn.Module):
def __init__(self, patch_size: int = 16, hidden_size: int = 3584, in_channels: int = 3):
super().__init__()
self.patch_embedding = nn.Conv2d(
in_channels=in_channels,
out_channels=hidden_size,
kernel_size=patch_size,
stride=patch_size,
bias=True,
)
self.norm = nn.RMSNorm(hidden_size)
def forward(self, pixel_values: torch.Tensor) -> torch.Tensor:
# pixel_values: [B, 3, H, W]
x = self.patch_embedding(pixel_values) # [B, D, H / p, W / p]
b, d, h, w = x.shape
x = x.reshape(b, d, h * w).transpose(1, 2) # [B, N, D]
return self.norm(x)def prepare_jit_training_batch(pixel_values, noise_scheduler, max_t0=None):
# pixel_values is clean RGB image x_1; returned z_t is the model input.
t = noise_scheduler.sample_timesteps(pixel_values.size(0), pixel_values.device)
if max_t0 is not None:
t = torch.full_like(t, max_t0)
noise = torch.randn_like(pixel_values) * noise_scheduler.noise_scale
z_t = t.view(-1, 1, 1, 1, 1) * pixel_values + (1 - t).view(-1, 1, 1, 1, 1) * noise
return z_t, t, pixel_valuesdef apply_mask_token(image_embeds, mask_token, ratio_min: float, ratio_max: float, training: bool):
if not training:
return image_embeds
bsz, num_patches, _ = image_embeds.shape
for b in range(bsz):
ratio = float(torch.empty(()).uniform_(ratio_min, ratio_max).clamp(min=0.0, max=1.0))
k = int(num_patches * ratio)
if k > 0:
idx = torch.randperm(num_patches, device=image_embeds.device)[:k]
image_embeds[b, idx] = mask_token
return image_embedsdef tuna2_training_forward(wrapper, batch):
text_tokens = batch["text_tokens"]
text_labels = batch["text_labels"]
pixel_values = batch["images"]
image_masks = batch["image_masks"]
x_t, t, x_1, image_masks, _ = wrapper.prepare_latents_and_labels(
pixel_values, batch["data_type"], image_masks
)
block_mask, diffhead_mask = wrapper.create_attention_mask(
text_tokens.size(0), text_tokens.size(1), batch["modality_positions"], text_tokens.device, torch.bfloat16
)
logits, loss_ntp, loss_flow, loss_disp = wrapper.tuna_model(
text_tokens=text_tokens,
image_latents=x_t,
t=t.to(torch.bfloat16),
attention_mask=block_mask,
diffhead_attention_mask=diffhead_mask,
text_labels=text_labels,
image_labels=x_1,
image_masks=image_masks,
modality_positions=batch["modality_positions"],
max_seq_len=text_tokens.size(1),
)
return wrapper.flow_coeff * loss_flow + wrapper.ntp_coeff * loss_ntpdef jit_x0_loss_and_euler_step(x0_pred, x0_target, z_t, t, t_next, mask=None):
mse = F.mse_loss(x0_pred, x0_target, reduction="none")
weight = 1.0 / (1.0 - t.view(-1, *([1] * (mse.ndim - 1)))).clamp(min=5e-2).pow(2)
loss = mse * weight
loss = loss[mask.bool()].mean() if mask is not None else loss.mean()
v_pred = (x0_pred - z_t) / (1.0 - t).clamp(min=5e-2)
z_next = z_t + (t_next - t) * v_pred
return loss, z_nextCode reference:
main@f08f15b9(2026-04-27) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Encoder-free Tuna-2 主体:无 SigLIP/VAE,Conv2d patchify + Qwen2.5 decoder + diffusion head | models/tuna_2_pixel.py | Tuna2Pixel, Tuna2PixelModel |
| Raw pixel patch embedding | models/vision/patch_embed.py | SimplePatchEmbedding |
| JiT/rectified-flow pixel noise construction | models/_wrapper_base.py, models/jit_utils.py | JiTWrapperMixin.prepare_latents_and_labels, JiTNoiseScheduler.add_noise |
| -prediction loss 与 weighting | models/jit_utils.py, models/misc.py | jit_x0_prediction_loss re-export |
| Masking-based feature learning | models/tuna_2_pixel.py, configs/model/tuna_2_pixel_7b.yaml | _prepare_embeds, enable_mask_token, masked_image_ratio |
| 推理 pipeline 与 pixel-space decoding | pipelines/tuna_2_pixel_pipeline.py, models/jit_utils.py | Tuna2PixelPipeline, JiTSampler.sample_ode |
| 训练 step/loss logging | training/unit.py | TunaUnit, wrapper output dict |
| Encoder-based pixel variant Tuna-R | models/tuna_2r_pixel.py, configs/model/tuna_2r_pixel_7b.yaml | Tuna2RPixelModel |
4. Experimental Setup (实验设置)
Datasets and scale. Stage 1 pretraining 使用 550M in-house image-text pairs,其中 70% 为 image captioning/multimodal understanding,30% 为 text-to-image generation;额外加入 Nemotron text-only data,占总 pretraining data 的 20%。Stage 2 SFT 使用 curated corpus,覆盖 image instruction-following、image editing 与 high-quality image generation;其中 image instruction-following 包含 FineVision 的 13M conversational examples,image editing 使用约 2M OmniEdit examples。Image reconstruction 在 ImageNet validation set 上评估。
Baselines. 理解侧包括 understanding-only LMMs:LLaVA-1.5、Qwen-VL-Chat、LLaVA-OV、Qwen2.5-VL;composite UMMs:TokenFlow-XL、BLIP3-o、Tar、X-Omni;native UMMs:BAGEL、Ming-UniVision、Harmon、JanusFlow、Emu3、VILA-U、Janus-Pro、Show-o2、OneCat、Tuna、Tuna-R、Tuna-2。生成侧还比较 SD3-M、FLUX.1[dev]、LongCat-Image、Qwen-Image、Seedream 3.0、Z-Image-Turbo、UniWorld-V1、OmniGen2、HBridge、Mogao 等。
Evaluation metrics. 理解评测包括 GQA、RealWorldQA、MMVet、MMMU、MMVP、SEED-Bench2+、AI2D、ChartQA、OCRBench,以及 pixel-centric 的 V*、CountBench、VisuLogic。生成评测包括 GenEval(object/count/color/position/color-attribute alignment)与 DPG-Bench(Global/Entity/Attribute/Relation/Other/Overall)。额外的 LLM-judge evaluation 采样 1.5K text prompts,每个模型每个 prompt 生成 4 张图,使用 GPT-5.4 与 Claude Opus 4.7 分别评估 Quality 与 Diversity。编辑使用 ImgEdit,重建使用 rFID、PSNR、SSIM。
Training config. Tuna-2 使用 Qwen2.5-7B-Instruct 作为 LLM decoder,Stage 1 end-to-end 训练 300k steps,AdamW,learning rate ,64 nodes;Stage 2 SFT 训练 50k steps,AdamW,learning rate ;所有阶段把 input sequence length pad 到每 GPU 16k tokens。Tuna-R 使用相同 Qwen2.5-7B-Instruct,并采用 SigLIP 2 So400M 作为 representation encoder;connector alignment stage 训练 3k steps,AdamW,learning rate 。论文未详细说明每个 node 的 GPU 型号和 GPU 数。
5. Experimental Results (实验结果)
5.1 Multimodal understanding
| Model | Size | GQA | RealWorldQA | MMVet | MMMU | MMVP | SEED-Bench2+ | AI2D | ChartQA | OCRBench | V* | CountBench | VisuLogic |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Show-o2 | 7B | 63.1 | 64.7 | 39.6 | 48.9 | 76.7 | 61.3 | 78.6 | 52.3 | 32.4 | 44.5 | 63.5 | 26.9 |
| OneCat | 9B | 63.1 | 65.2 | 52.2 | 41.9 | 71.3 | 61.6 | 77.8 | 81.2 | 79.0 | 63.4 | 34.2 | 24.9 |
| Tuna | 7B | 63.9 | 66.1 | 42.9 | 49.8 | 70.7 | 52.7 | 79.3 | 85.8 | 74.3 | 52.4 | 73.5 | 22.4 |
| Tuna-R | 7B | 63.5 | 67.9 | 46.7 | 51.1 | 74.7 | 58.4 | 79.4 | 85.6 | 78.3 | 57.6 | 77.8 | 26.2 |
| Tuna-2 | 7B | 65.0 | 67.7 | 51.7 | 50.7 | 77.3 | 61.1 | 79.6 | 85.6 | 79.7 | 59.2 | 81.7 | 28.8 |
Tuna-2 在 7B-scale native UMM 中拿到最强或接近最强的理解结果:相对 Tuna-R,它在 GQA、MMVet、MMVP、SEED-Bench2+、AI2D、OCRBench、V*、CountBench、VisuLogic 上更高;相对原始 Tuna,它在除 ChartQA 外所有列都更高或相当。尤其是 pixel-centric 三项上,Tuna-2 为 V* 59.2、CountBench 81.7、VisuLogic 28.8,说明 raw-pixel patch embedding 对细粒度视觉信息更友好。
5.2 Image generation and editing
| Model | Size | GenEval Overall | DPG Overall | GenEval Count | GenEval Position | DPG Attribute | DPG Relation |
|---|---|---|---|---|---|---|---|
| Show-o2 | 7B | 0.76 | 86.14 | 0.58 | 0.52 | 89.96 | 91.81 |
| Janus-Pro | 7B | 0.80 | 84.19 | 0.59 | 0.79 | 89.40 | 89.32 |
| HBridge† | 7B | 0.87 | 85.23 | 0.80 | 0.77 | 90.23 | 90.06 |
| Mogao | 7B | 0.89 | 84.33 | 0.83 | 0.84 | 88.26 | 93.18 |
| Tuna | 7B | 0.90 | 86.76 | 0.81 | 0.88 | 90.94 | 91.87 |
| Tuna-R | 7B | 0.88 | 86.35 | 0.82 | 0.86 | 91.03 | 93.48 |
| Tuna-2 | 7B | 0.87 | 86.54 | 0.80 | 0.84 | 92.07 | 91.91 |
Tuna-2 的生成结果非常接近 Tuna/Tuna-R:GenEval Overall 为 0.87,DPG Overall 为 86.54;DPG Attribute 92.07 甚至高于 Tuna 与 Tuna-R。作者的结论比较克制:encoder-free 对生成是 competitive,但 Tuna-R 的 representation encoder semantic prior 在 GenEval 等指标上仍略有帮助。
| Model | GPT-5.4 Quality | GPT-5.4 Diversity | Claude Opus 4.7 Quality | Claude Opus 4.7 Diversity |
|---|---|---|---|---|
| Tuna | 22.3% | 20.6% | 28.1% | 28.2% |
| Tuna-R | 35.7% | 30.9% | 37.2% | 29.9% |
| Tuna-2 | 32.1% | 48.4% | 34.8% | 41.9% |
LLM-judge 结果显示,Tuna-2 的 Quality 低于 Tuna-R 但高于 Tuna,而 Diversity 明显最高:GPT-5.4 Diversity 48.4%,Claude Opus 4.7 Diversity 41.9%。这支持作者关于 encoder-free design 能生成更丰富视觉变化的论点。
| Model | Add | Adj. | Ext. | Rep. | Rm. | Bg. | Sty. | Hyb. | Act. | Total |
|---|---|---|---|---|---|---|---|---|---|---|
| FLUX.1 | 4.25 | 4.15 | 2.35 | 4.56 | 3.57 | 4.26 | 4.57 | 3.68 | 4.63 | 4.00 |
| Qwen-Image | 4.38 | 4.16 | 3.43 | 4.66 | 4.14 | 4.38 | 4.81 | 3.82 | 4.69 | 4.27 |
| Tuna | 4.43 | 4.48 | 2.46 | 4.65 | 4.55 | 4.52 | 4.69 | 4.22 | 4.76 | 4.31 |
| Tuna-R | 4.46 | 4.27 | 2.38 | 4.61 | 4.48 | 4.44 | 4.54 | 4.06 | 4.43 | 4.18 |
| Tuna-2 | 4.34 | 4.13 | 2.22 | 4.53 | 4.42 | 4.36 | 4.58 | 3.91 | 4.28 | 4.09 |
编辑上 Tuna-2 Total=4.09,强于早期 unified baselines,但落后于 Tuna/Tuna-R 与 Qwen-Image。作者据此指出,pretrained visual priors 对 fine-grained editing fidelity 仍有帮助。
5.3 Reconstruction and qualitative analysis

Figure 4 解读:图中比较不同 visual tokenizers 的 reconstruction quality。Tuna-R 与 Tuna-2 的重建明显比部分 non-KL-regularized VAE/RAE 类方法更保真,尤其在纹理和局部结构上更稳定。这个图对应的定量结论是:pixel-space unified representation 不只适合理解,也能支撑接近专用 tokenizer 的图像重建。
| Tokenizer | Res. | rFID↓ | PSNR↑ | SSIM↑ |
|---|---|---|---|---|
| SD-VAE | 256 | 1.06 | 28.62 | 0.86 |
| FLUX.1[dev]-VAE† | 512 | 0.06 | 33.65 | 0.93 |
| TokenFlow | 384 | 0.63 | 22.77 | 0.73 |
| X-Omni† | 512 | 8.30 | 15.66 | 0.38 |
| RAE | 256 | 0.61 | 19.20 | 0.44 |
| Tuna-R | 512 | 0.12 | 32.22 | 0.93 |
| Tuna-2 | 512 | 0.15 | 32.80 | 0.93 |
Tuna-R/Tuna-2 在 unified tokenizers 中最强:Tuna-R rFID=0.12,Tuna-2 rFID=0.15;Tuna-2 的 PSNR=32.80 高于 Tuna-R 的 32.22,SSIM 都是 0.93。与 FLUX.1[dev]-VAE 相比仍有 rFID 差距,但已远优于多数 unified tokenizers。

Figure 5 解读:图中展示关键词对图像区域的 attention maps,红色为高 attention,蓝色为低 attention。Tuna-2 在 “shining window”“purple object”等基础定位场景中更集中;在 “dog cafe” 与 “football match” 这类包含误导性语言先验或显著视觉干扰物的场景中,Tuna-2 更能关注真正与问题语义一致的目标区域。它解释了为什么 encoder-free pixel representation 在 fine-grained perception 上更有优势。
5.4 Ablation: data ratio, masking, and training dynamics
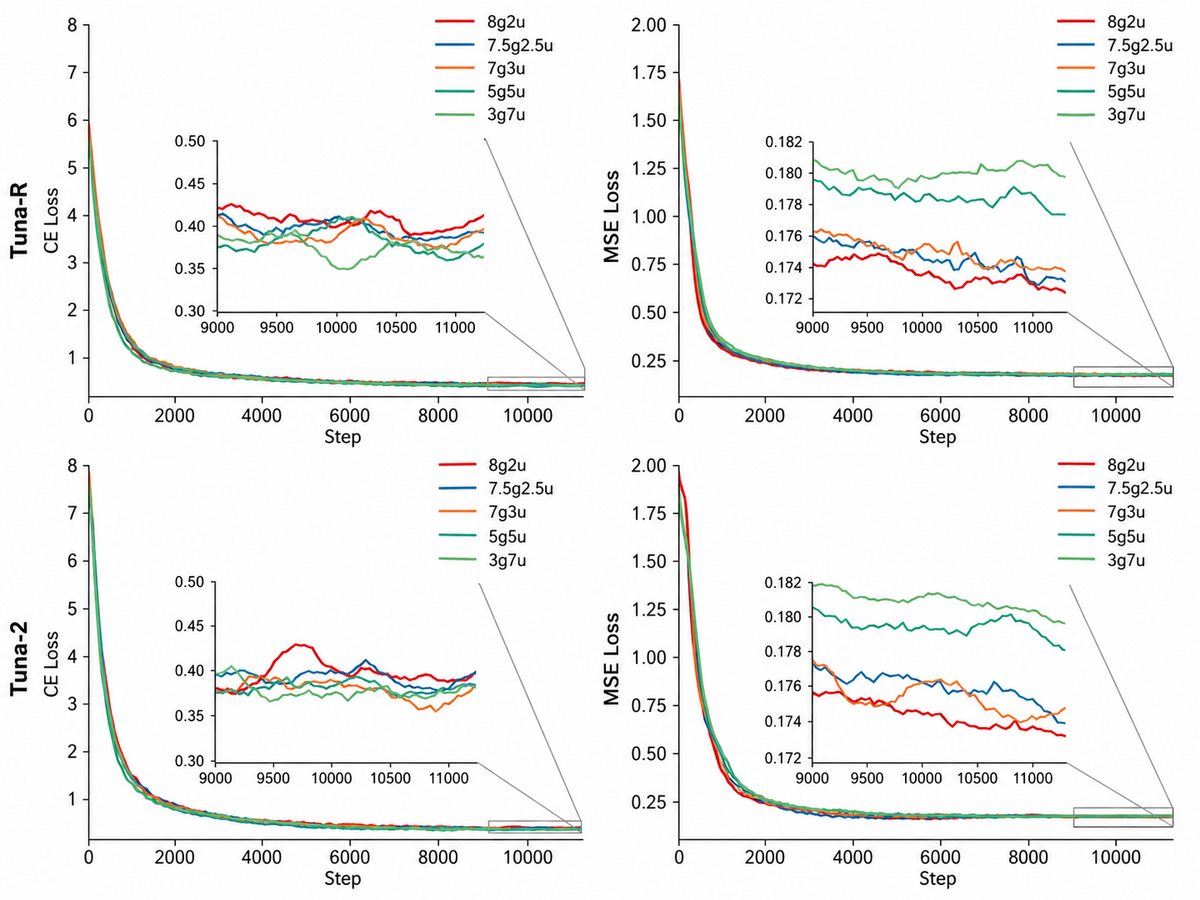
Figure 6 解读:图中比较不同 generation-to-understanding sampling ratio 下的 MSE 与 CE loss。增加 generation 数据比例会明显降低 flow matching MSE,增加 understanding 数据比例会降低 language modeling CE;MSE 对采样比例更敏感。作者最终采用 7g3u,因为它在生成与理解目标之间给出较好的 trade-off。
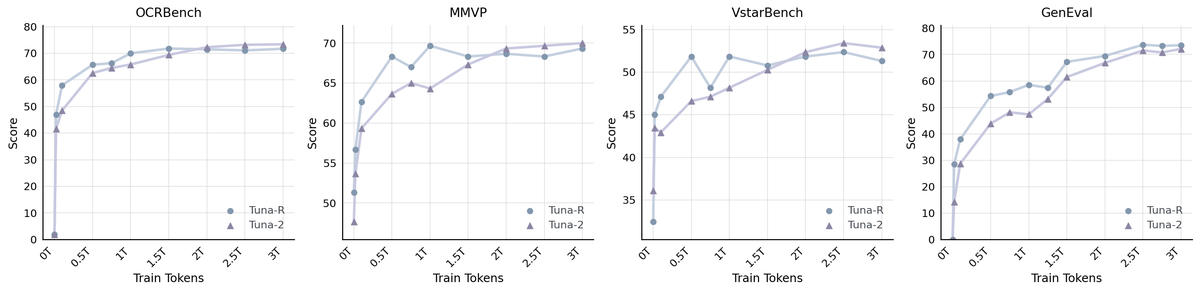
Figure 7 解读:图中横轴是 consumed tokens/训练数据规模,比较 Tuna-R 与 Tuna-2 的理解和生成曲线。早期 Tuna-R 更强,说明 SigLIP 2 representation encoder 的 semantic prior 有助于冷启动;后期 Tuna-2 在 OCRBench、MMVP、V* 上追上并超过 Tuna-R,说明 encoder-free monolithic architecture 更能从大规模统一训练中获益。GenEval 上 Tuna-R 持续略优,但差距在 SFT 后缩小。
| Model | OCRBench | MMVP | CountBench | GenEval |
|---|---|---|---|---|
| Tuna | 56.9 | 54.0 | 55.6 | 57.2 |
| Tuna-R w/o Masking | 58.3 | 56.7 | 57.2 | 55.7 |
| Tuna-R w/ Masking | 59.2 | 58.0 | 58.2 | 56.0 |
| Tuna-2 w/o Masking | 55.4 | 52.3 | 53.4 | 47.6 |
| Tuna-2 w/ Masking | 56.8 | 55.7 | 57.6 | 48.2 |
masking 对两个变体均有效,且 Tuna-2 受益更大:OCRBench +1.4、MMVP +3.4、CountBench +4.2、GenEval +0.6;Tuna-R 分别为 +0.9、+1.3、+1.0、+0.3。作者推测 Tuna-R 的提升较小,是因为 SigLIP 2 本身预训练时已包含类似 masked prediction objective。最终主实验在 pretraining 最后 40% 使用 masking-based feature learning。
5.5 Limitations and conclusions
论文没有单独的 Limitations section,也没有把某些失败案例正式列为 limitation。就实验边界而言,Tuna-2 并非在所有生成/编辑指标上超过 encoder-based 方案:Tuna-R 的 GenEval Overall=0.88 高于 Tuna-2 的 0.87,ImgEdit Total=4.18 高于 Tuna-2 的 4.09;这说明 representation encoder 的 semantic prior 仍能帮助生成与编辑。另一个现实边界是训练依赖 550M in-house image-text pairs、64-node 300k-step pretraining 与大规模 SFT 数据,论文未给出每节点 GPU 配置,复现成本较高。
总体结论是:Tuna-2 证明 pretrained vision encoders 对 native unified multimodal modelling 不是必要条件。pixel embeddings 在足够规模的端到端训练下可以同时支撑理解、生成、编辑与重建;encoder-free 方案在理解,尤其 fine-grained perception 上展现更强 scaling potential,而 encoder-based Tuna-R 在生成冷启动和部分编辑质量上仍有优势。