Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Authors: SII-GAIR, Sand.ai(arXiv 页面列出 Ethan Chern 等 40+ 位作者;对应项目负责人为 Yue Cao、Pengfei Liu) Affiliations: SII-GAIR, Sand.ai arXiv: 2603.21986 GitHub: GAIR-NLP/daVinci-MagiHuman Model / Demo: Hugging Face Models, Hugging Face Space Venue: arXiv 2026
1. Motivation (研究动机)
这篇论文要解决的问题很明确:开放音视频生成模型为什么总是在“质量、架构复杂度、推理速度”三者之间难以兼得?
作者指出,当前 open-source audio-video generation 相比 closed-source 系统(如 Veo 3、Sora 2、Kling 3.0)仍存在明显差距,尤其体现在三个方面:
-
架构越来越复杂
现有开放模型为了同时处理 text、video、audio 往往采用 multi-stream 设计:文本一条路、视频一条路、音频一条路,再通过 cross-attention / fusion block 对齐。这种设计虽然直觉上“更专业”,但带来了很多额外复杂性:- 模态间路径不规则
- 工程实现更难
- 推理优化更难
- 训练基础设施更难统一
-
人类中心场景表现不够强
音视频生成真正难的场景不是风景,而是 human-centric generation:说话人面部表情、嘴型与语音同步、肢体动作自然性、情绪表达一致性。很多模型在这些方面容易出现:- lip sync 不准
- 表情和语音节奏不一致
- 身体动作僵硬
- 多语言 spoken generation 不稳定
-
高质量推理代价过高
即便质量不错,很多模型在实际推理时也非常慢。对于交互式创作或实时应用,5 秒视频如果要几分钟才能生成,工程价值就会大打折扣。
因此,论文真正想回答的是:
能否用一个更简单的统一架构,同时达到强 human-centric 质量、多语言 spoken generation和足够快的推理速度?
作者的答案是:可以,而且关键并不是继续增加结构复杂度,而是反过来追求 speed by simplicity。
2. Idea (核心思想)
这篇工作最核心的想法是:
不用 multi-stream + cross-attention,而直接用一个 single-stream Transformer,把 text、video、audio 放进统一 token 序列里,仅靠 self-attention 联合建模。
这件事的价值不只是“结构更简洁”,而是同时影响:
-
模型设计更简单
一个 backbone 同时处理三种模态,避免专门的 fusion 模块。 -
训练更容易统一
不需要为不同模态写不同的主干和路由逻辑。 -
推理和编译更友好
因为计算图更规则,更容易做 full-graph compilation、distillation、super-resolution 级联和 VAE 解码优化。
在此基础上,论文再叠加三种加速技术:
- latent-space super-resolution:先在低分辨率 latent 上生成,再在 latent space 做高分辨率精修
- Turbo VAE decoder:降低解码时延
- DMD-2 distillation:把 base model 蒸馏成 8 steps、无 CFG 的快速版本
所以它和很多系统工作的区别在于:
- 不是靠“更多模块”换质量
- 而是靠“更统一的主干 + 更高效的后处理链路”换到质量和速度的平衡
一句话概括:
daVinci-MagiHuman 不是在多模态架构上继续加功能,而是通过单流统一建模,把系统做得更简单、更快,同时仍然维持高质量。
3. Method (方法)
3.1 整体框架

Figure 1 解读:这张图给出了 daVinci-MagiHuman 的定性样例。可以看到模型重点展示的并不是通用场景生成,而是典型的 human-centric case:说话、表情变化、人物互动、舞蹈、镜头内动作连续性等。它想强调的核心不是“能生成音视频”,而是“能生成人与声音、表情、身体动作强耦合的音视频”。这与论文的定位完全一致:它是一个 human-centric audio-video generative foundation model。
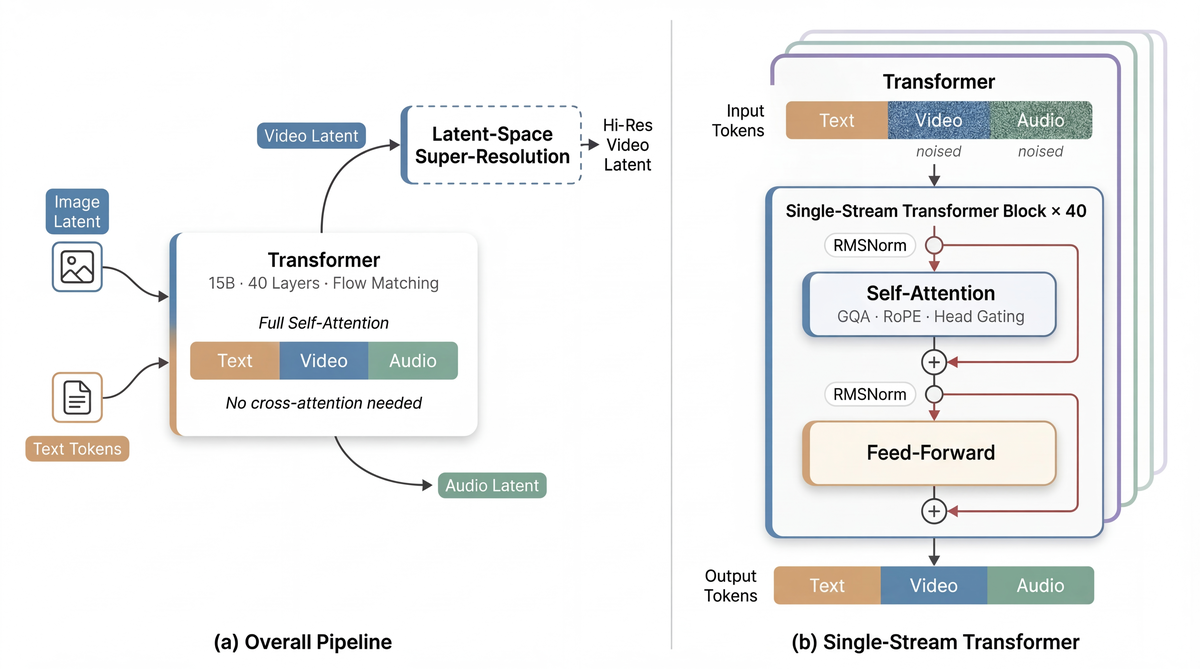
Figure 2 解读:左图展示总体 pipeline:输入包括 text tokens、reference image latent,以及 noisy video/audio latent,base generator 用一个统一 Transformer 同时去噪视频和音频;之后可选地接一个 latent-space super-resolution 模块,把低分辨率视频 latent 提升到更高输出分辨率。右图展示 single-stream Transformer block:所有模态都进入同一条 self-attention 主干,没有单独的 cross-attention / fusion 模块;block 由 RMSNorm、Self-Attention、Feed-Forward 组成,并在 attention 内加入 per-head gating。这个图最关键的信息是:文本、视频、音频不是三条路再融合,而是一开始就在一个共享序列里联合建模。
整个系统可以拆成两阶段:
- Base generator
- 在低分辨率 latent 空间联合生成视频和音频
- Latent-space super-resolution
- 对视频 latent 做高分辨率 refinement
- 音频 latent 不直接更新,但以噪声化形式作为辅助条件保留 lip-sync 一致性
3.2 Single-Stream Transformer
论文最核心的模型设计是 15B、40 层的 single-stream Transformer。相比典型的双流 / 三流架构,它把 text、video、audio token 统一进一个 backbone,用 self-attention-only 建模。
关键设计包括:
3.2.1 Sandwich Architecture
40 层 Transformer 不是完全同构的,而是:
- 前 4 层:使用 modality-specific projections 和 RMSNorm 参数
- 中间 32 层:共享主 Transformer 参数
- 后 4 层:再次使用 modality-specific projections 和 RMSNorm 参数
这样做的直觉是:
- 输入边界和输出边界保留模态敏感性
- 中间主体层尽可能在统一表示空间内做深度融合
从代码实现看:
inference/model/dit/dit_module.py中TransFormerLayer会根据layer_idx in config.mm_layers决定是否启用多模态专家参数MultiModalityRMSNorm和ModalityDispatcher用于支持这种“共享主干 + 局部模态专用”的布局
3.2.2 Timestep-Free Denoising
论文特别强调:它没有显式的 timestep embedding 通路。
不同于原始 DiT 会通过 timestep embedding 或 AdaLN 把噪声步数注入网络,daVinci-MagiHuman 直接把 noisy video/audio latents 输入模型,让模型从输入状态本身推断当前 denoising stage。
这意味着:
- 条件接口更简单
- 避免额外 timestep branch
- 更利于统一文本、视频、音频的单流结构
3.2.3 Per-Head Gating
每个 attention head 都有一个标量门控 ,其输出会先经过 sigmoid:
这个 gating 的目标主要是:
- 提高数值稳定性
- 提升表达能力
- 但几乎不增加结构复杂度
从开源实现看,在 inference/model/dit/dit_module.py 中,attention 输出后直接执行:
self_attn_out = self_attn_out * torch.sigmoid(g)因此这不是论文里的概念性点缀,而是实际实现中的关键算子。
3.2.4 Unified Conditioning
作者不为 text / image / audio / video 分别设计复杂 conditioning branch,而是使用尽量统一的 token interface:
- text 经过 T5-Gemma encoder
- 可选 reference image 转成 latent
- audio latent 与 video latent 一起进入 backbone
代码里对应:
inference/pipeline/prompt_process.py:get_padded_t5_gemma_embeddinginference/model/vae2_2/*:视频 VAEinference/model/sa_audio/*:音频表征提取
3.3 Efficient Inference Techniques
论文的方法部分有很大一部分其实是在讲系统级加速,而不仅是生成主干。
3.3.1 Latent-Space Super-Resolution
高分辨率视频直接从头生成太贵,所以作者采用两阶段:
- base model 先生成低分辨率 video/audio latent
- super-resolution model 在 latent 空间内 refine 视频
论文强调它是在 latent space 而不是 pixel space 做 SR,原因是:
- 和 diffusion latent 表示天然对齐
- 可复用同类 backbone
- 避免一次额外的 VAE decode → encode round-trip
从开源实现看,SR 阶段的关键步骤是:
- 先对 base video latent 做
trilinear上采样 - 再注入噪声
- 再用单独的 SR checkpoint 做若干步 refinement
代码级对应:
latent_video = torch.nn.functional.interpolate(
br_latent_video,
size=(latent_length, sr_latent_height, sr_latent_width),
mode="trilinear",
align_corners=True
)随后按噪声强度重新加噪:
这里公式是根据 inference/pipeline/video_generate.py 中实现整理出来的。
值得注意的是:
- 只有 video latent 被显式更新
- audio latent 在 SR 阶段以 noised auxiliary input 形式参与条件建模
这个设计是为了在 base-resolution 很粗的时候仍尽量保持 audio-video coupling,特别是 lip sync。
3.3.2 Turbo VAE Decoder
编码时使用 Wan2.2 VAE,因为其时空压缩比高;但推理解码阶段换成轻量的 Turbo VAED,降低 end-to-end latency。
代码对应:
inference/model/vae2_2/inference/model/turbo_vaed/
在 video_generate.py 中,若 config.use_turbo_vae 为真,就会优先加载 TurboVAED。
3.3.3 Full-Graph Compilation
作者集成了 MagiCompiler 做 full-graph PyTorch compilation,通过:
- 跨 Transformer layer 的 operator fusion
- 减少 collective communication
在 H100 上进一步带来约 1.2× 的加速。
3.3.4 Distillation
为了进一步降推理成本,作者对 base generator 做了 DMD-2 distillation,最终 distilled 版本只用:
- 8 denoising steps
- 不需要 CFG
就能维持较强质量。
README 与论文都明确表示,后面报的 latency 基本都来自这个 distilled model。
3.4 基于开源实现的伪代码
下面的伪代码基于当前公开仓库中的实际 inference stack,而不是只照着论文文字转述。
def single_stream_generation(
prompt: str,
image: Image.Image | None,
audio_path: str | None,
evaluator,
br_width: int,
br_height: int,
num_inference_steps: int,
):
txt_feat, txt_len = get_padded_t5_gemma_embedding(
prompt,
evaluator.txt_model_path,
evaluator.device,
evaluator.dtype,
evaluator.config.t5_gemma_target_length,
)
image_latent = evaluator.encode_image(image, br_height, br_width) if image is not None else None
if audio_path is not None:
audio_latent = load_audio_and_encode(evaluator.audio_vae, audio_path, seconds=5)
audio_latent = audio_latent.permute(0, 2, 1)
is_a2v = True
else:
num_frames = 5 * evaluator.fps + 1
audio_latent = torch.randn(1, num_frames, 64, device=evaluator.device)
is_a2v = False
latent_length = (audio_latent.shape[1] - 1) // 4 + 1
video_latent = torch.randn(
1,
evaluator.z_dim,
latent_length,
br_height // evaluator.vae_stride[1],
br_width // evaluator.vae_stride[2],
device=evaluator.device,
)
video_scheduler = FlowUniPCMultistepScheduler()
audio_scheduler = FlowUniPCMultistepScheduler()
video_scheduler.set_timesteps(num_inference_steps, device=evaluator.device, shift=evaluator.shift)
audio_scheduler.set_timesteps(num_inference_steps, device=evaluator.device, shift=evaluator.shift)
for idx, t in enumerate(video_scheduler.timesteps):
eval_input = EvalInput(
x_t=video_latent,
audio_x_t=audio_latent,
audio_feat_len=[audio_latent.shape[1]],
txt_feat=txt_feat,
txt_feat_len=[txt_len],
)
v_cond_video, v_cond_audio = evaluator.forward(eval_input, use_sr_model=False)
if evaluator.config.cfg_number == 2:
eval_input_null = EvalInput(
x_t=video_latent,
audio_x_t=audio_latent,
audio_feat_len=[audio_latent.shape[1]],
txt_feat=evaluator.context_null,
txt_feat_len=[evaluator.original_context_null_len],
)
v_uncond_video, v_uncond_audio = evaluator.forward(eval_input_null, use_sr_model=False)
v_cfg_video = v_uncond_video + evaluator.video_txt_guidance_scale * (v_cond_video - v_uncond_video)
v_cfg_audio = v_uncond_audio + evaluator.audio_txt_guidance_scale * (v_cond_audio - v_uncond_audio)
else:
v_cfg_video = v_cond_video
v_cfg_audio = v_cond_audio
video_latent, audio_latent = schedule_latent_step(
video_scheduler=video_scheduler,
audio_scheduler=audio_scheduler,
latent_video=video_latent,
latent_audio=audio_latent,
t=t,
idx=idx,
steps=num_inference_steps,
v_cfg_video=v_cfg_video,
v_cfg_audio=v_cfg_audio,
is_a2v=is_a2v,
cfg_number=evaluator.config.cfg_number,
use_sr_model=False,
using_sde_flag=evaluator.config.using_sde_flag,
)
if image_latent is not None:
video_latent[:, :, :1] = image_latent[:, :, :1]
return video_latent, audio_latentdef latent_space_super_resolution(
br_latent_video: torch.Tensor,
br_latent_audio: torch.Tensor,
sr_height: int,
sr_width: int,
evaluator,
prompt: str,
image: Image.Image | None,
sr_num_inference_steps: int,
):
txt_feat, txt_len = get_padded_t5_gemma_embedding(
prompt,
evaluator.txt_model_path,
evaluator.device,
evaluator.dtype,
evaluator.config.t5_gemma_target_length,
)
latent_length = br_latent_video.shape[2]
sr_latent_height = sr_height // evaluator.vae_stride[1]
sr_latent_width = sr_width // evaluator.vae_stride[2]
latent_video = torch.nn.functional.interpolate(
br_latent_video,
size=(latent_length, sr_latent_height, sr_latent_width),
mode="trilinear",
align_corners=True,
)
if evaluator.noise_value != 0:
noise = torch.randn_like(latent_video)
sigmas = evaluator.sigmas.to(latent_video.device)
sigma = sigmas[evaluator.noise_value]
latent_video = latent_video * sigma + noise * (1 - sigma**2).sqrt()
# audio latent is reused as noised auxiliary input rather than directly refined
sr_audio_latent = torch.randn_like(br_latent_audio) * evaluator.config.sr_audio_noise_scale
sr_audio_latent = sr_audio_latent + br_latent_audio * (1 - evaluator.config.sr_audio_noise_scale)
image_latent = evaluator.encode_image(image, sr_height, sr_width) if image is not None else None
video_scheduler = FlowUniPCMultistepScheduler()
audio_scheduler = FlowUniPCMultistepScheduler()
video_scheduler.set_timesteps(sr_num_inference_steps, device=evaluator.device, shift=evaluator.shift)
audio_scheduler.set_timesteps(sr_num_inference_steps, device=evaluator.device, shift=evaluator.shift)
for idx, t in enumerate(video_scheduler.timesteps):
eval_input = EvalInput(
x_t=latent_video,
audio_x_t=sr_audio_latent,
audio_feat_len=[sr_audio_latent.shape[1]],
txt_feat=txt_feat,
txt_feat_len=[txt_len],
)
v_cond_video, v_cond_audio = evaluator.forward(eval_input, use_sr_model=True)
if evaluator.config.sr_cfg_number == 2:
eval_input_null = EvalInput(
x_t=latent_video,
audio_x_t=sr_audio_latent,
audio_feat_len=[sr_audio_latent.shape[1]],
txt_feat=evaluator.context_null,
txt_feat_len=[evaluator.original_context_null_len],
)
v_uncond_video, v_uncond_audio = evaluator.forward(eval_input_null, use_sr_model=True)
v_cfg_video = v_uncond_video + evaluator.sr_video_txt_guidance_scale * (v_cond_video - v_uncond_video)
v_cfg_audio = v_uncond_audio
else:
v_cfg_video = v_cond_video
v_cfg_audio = v_cond_audio
latent_video, _ = schedule_latent_step(
video_scheduler=video_scheduler,
audio_scheduler=audio_scheduler,
latent_video=latent_video,
latent_audio=sr_audio_latent,
t=t,
idx=idx,
steps=sr_num_inference_steps,
v_cfg_video=v_cfg_video,
v_cfg_audio=v_cfg_audio,
is_a2v=False,
cfg_number=evaluator.config.sr_cfg_number,
use_sr_model=True,
using_sde_flag=evaluator.config.using_sde_flag,
)
if image_latent is not None:
latent_video[:, :, :1] = image_latent[:, :, :1]
return latent_videodef end_to_end_offline_inference(
prompt: str,
image: Image.Image | None,
audio_path: str | None,
pipeline,
seconds: int = 5,
br_width: int = 480,
br_height: int = 272,
sr_width: int | None = None,
sr_height: int | None = None,
):
br_latent_video, br_latent_audio = single_stream_generation(
prompt=prompt,
image=image,
audio_path=audio_path,
evaluator=pipeline.evaluator,
br_width=br_width,
br_height=br_height,
num_inference_steps=pipeline.evaluation_config.num_inference_steps,
)
if sr_width is not None and sr_height is not None and pipeline.evaluator.sr_model is not None:
final_video_latent = latent_space_super_resolution(
br_latent_video=br_latent_video,
br_latent_audio=br_latent_audio,
sr_height=sr_height,
sr_width=sr_width,
evaluator=pipeline.evaluator,
prompt=prompt,
image=image,
sr_num_inference_steps=pipeline.evaluation_config.sr_num_inference_steps,
)
else:
final_video_latent = br_latent_video
if pipeline.evaluator.config.use_turbo_vae:
video_np = pipeline.evaluator.turbo_vae.decode_video(final_video_latent)
else:
video_np = pipeline.evaluator.decode_video(final_video_latent)
audio_wave = pipeline.evaluator.audio_vae.decode(br_latent_audio.squeeze(0).T)
audio_wave = audio_wave.squeeze(0).T.cpu().numpy()
audio_wave = resample_audio_sinc(audio_wave, 441 / 512)
save_path = pipeline.run_offline(
prompt=prompt,
image=image,
audio=audio_path,
save_path_prefix="output/davinci",
seconds=seconds,
br_width=br_width,
br_height=br_height,
sr_width=sr_width,
sr_height=sr_height,
)
return save_path, video_np, audio_wave3.5 Code-to-paper mapping table
| Paper Concept | Source File | Key Class / Function | 说明 |
|---|---|---|---|
| Single-stream DiT 主干 | inference/model/dit/dit_module.py | TransFormerLayer, Attention, MultiModalityRMSNorm | 对应 Figure 2(b) 的 40-layer single-stream Transformer |
| 15B DiT 模型加载 | inference/model/dit/dit_model.py | get_dit | 构建并加载主模型 checkpoint |
| 模态统一 token / adapter | inference/model/dit/dit_module.py | Adapter, ModalityDispatcher | 文本、视频、音频在统一序列内进入 backbone |
| Per-head gating | inference/model/dit/dit_module.py | attention output gating | 实现 |
| Prompt 编码 | inference/pipeline/prompt_process.py | get_padded_t5_gemma_embedding | 文本经 T5-Gemma 编码并 pad/trim |
| 基础生成 + SR 主流程 | inference/pipeline/video_generate.py | MagiEvaluator.evaluate, evaluate_with_latent | base 生成、CFG、scheduler、SR 和后处理 |
| Offline pipeline 封装 | inference/pipeline/pipeline.py | MagiPipeline.run_offline | end-to-end 推理接口 |
| Flow scheduler | inference/pipeline/scheduler_unipc.py | FlowUniPCMultistepScheduler | UniPC 改造到 flow matching |
| 视频 VAE | inference/model/vae2_2/ | Wan2_2_VAE | 视频 latent encode/decode |
| Turbo decoder | inference/model/turbo_vaed/ | TurboVAED | 更快的视频解码 |
| 音频表征与解码 | inference/model/sa_audio/, video_generate.py | SAAudioFeatureExtractor | 音频 latent 编码与 waveform 解码 |
4. Experimental Setup (实验设置)
4.1 对比基线
论文主要与两个领先 open-source 音视频模型比较:
- OVI 1.1
- LTX 2.3
此外,文中也反复提到与其他 open / closed 系统的关系,如:
- closed-source:Veo 3, Sora 2, Kling 3.0
- open-source 相关:Wan, HunyuanVideo, MOVA, Universe-1 等
但定量主对比集中在 OVI 1.1 和 LTX 2.3。
4.2 任务与评测指标
视频质量
在 VerseBench 上,使用 VideoScore2 评测:
- Visual Quality
- Text Alignment
- Physical Consistency
音频质量
在 TalkVid-Bench 上,用 GLM-ASR 转录生成音频,再计算:
- WER(Word Error Rate)
对于中日韩语言,论文按 character-level 计算 WER,以避免分词差异带来的噪声。
人类偏好评测
- 10 位人类评审
- 每人判断 200 组随机配对
- 共 2,000 pairwise comparisons
判断维度是整体 audio-video quality、synchronization 和 naturalness。
4.3 推理速度设置
速度评测全部在:
- 单张 H100 GPU
上完成,统计 5 秒视频生成时长。论文特别把时间拆成:
- Base
- SR
- Decode
- Total
4.4 系统配置
从 README 和公开代码可见,实际运行还依赖:
- Text encoder:
t5gemma-9b-9b-ul2 - Audio model:
stable-audio-open-1.0 - VAE:
Wan2.2-TI2V-5B - PyTorch 2.9+
- Python 3.12+
- Flash Attention
- MagiCompiler
这说明 daVinci-MagiHuman 虽然“主干简单”,但系统级部署仍然相当重量级。
5. Experimental Results (实验结果)
5.1 自动评测:视觉质量、文本对齐和语音可懂度最均衡
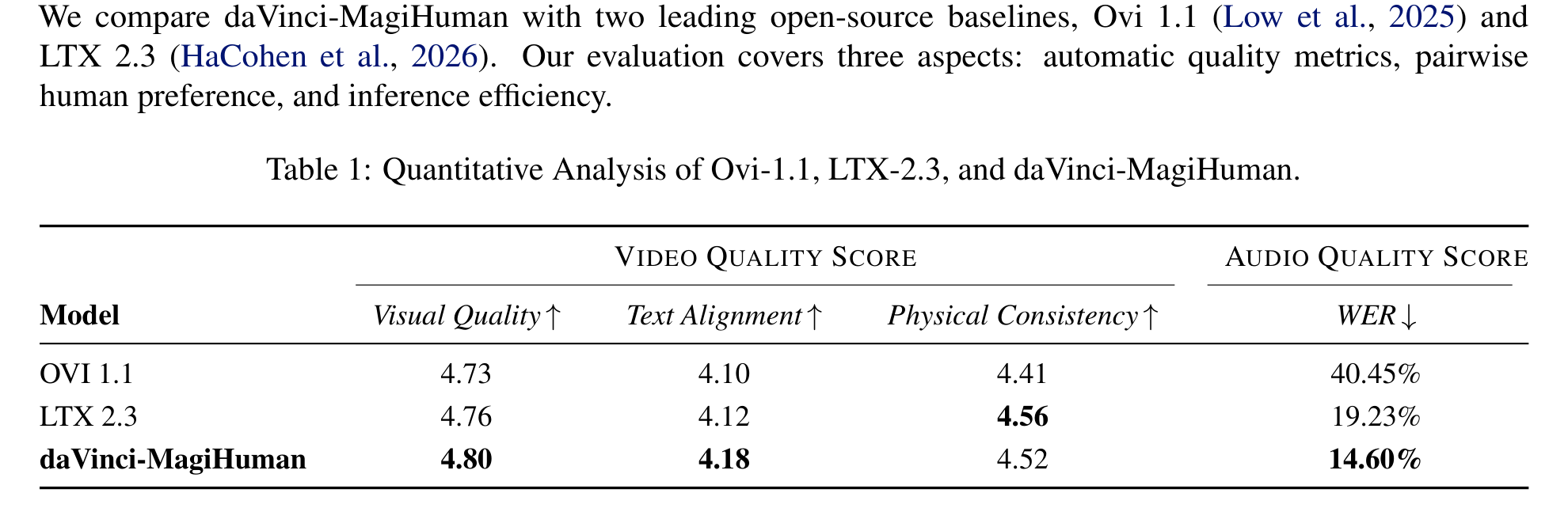
Figure/Table 3 解读:这张表是论文最核心的定量结果。和 OVI 1.1、LTX 2.3 相比,daVinci-MagiHuman 在 Visual Quality 和 Text Alignment 上都是第一,分别达到 4.80 和 4.18;在 WER 上也最好,仅 14.60%,显著优于 OVI 1.1 的 40.45% 和 LTX 2.3 的 19.23%。唯一没有第一的是 Physical Consistency,LTX 2.3 以 4.56 略高于 daVinci-MagiHuman 的 4.52。换句话说,daVinci-MagiHuman 的优势不在“单一维度碾压”,而在于它在视觉、文本、音频可懂度三个维度上给出了最强的总体平衡。
表中的具体数字:
| Model | Visual Quality ↑ | Text Alignment ↑ | Physical Consistency ↑ | WER ↓ |
|---|---|---|---|---|
| OVI 1.1 | 4.73 | 4.10 | 4.41 | 40.45% |
| LTX 2.3 | 4.76 | 4.12 | 4.56 | 19.23% |
| daVinci-MagiHuman | 4.80 | 4.18 | 4.52 | 14.60% |
5.2 人类评测:明显胜过两大开源基线
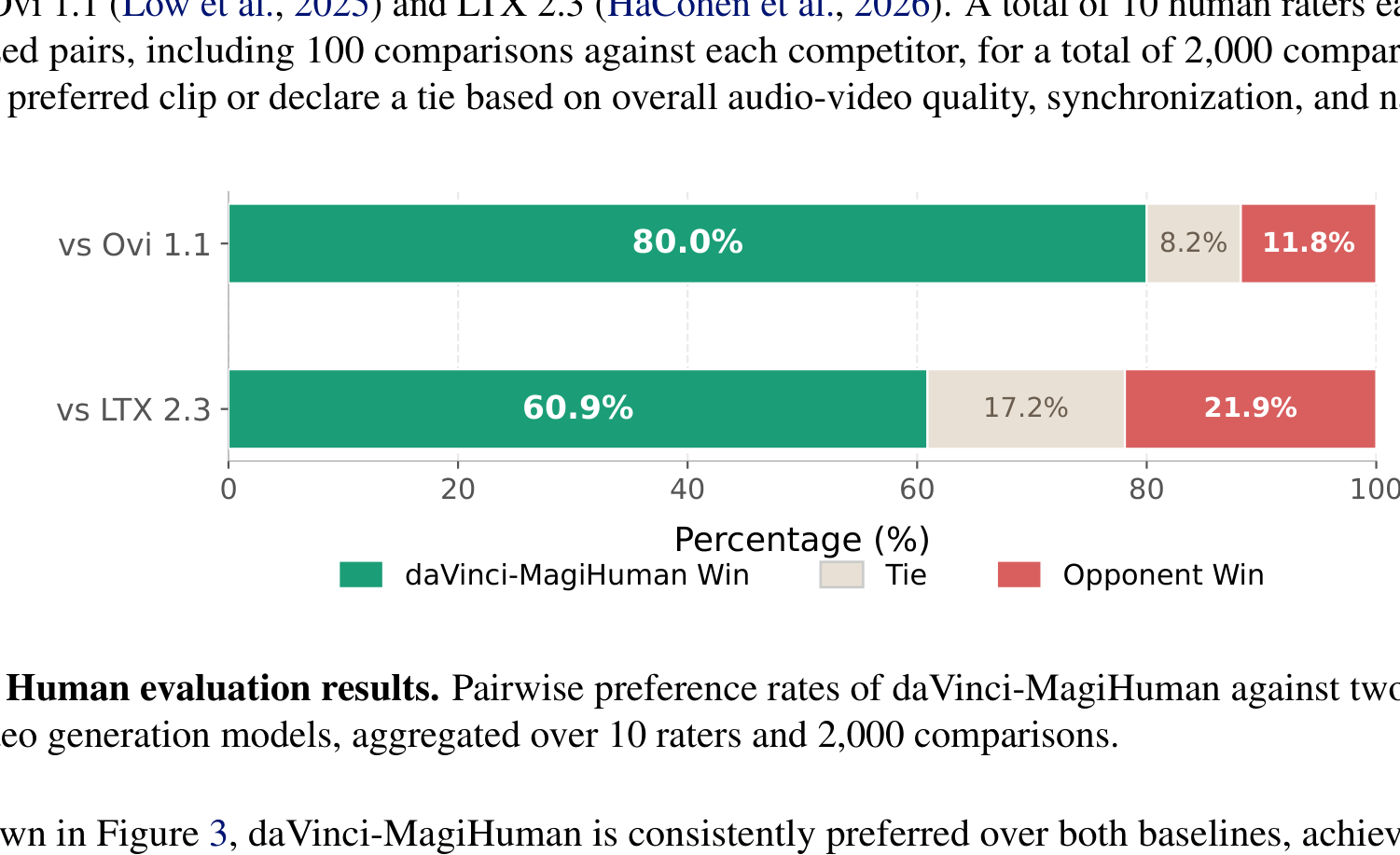
Figure 4 解读:pairwise human evaluation 的结果非常直接。面对 OVI 1.1,daVinci-MagiHuman 的 win rate 达到 80.0%;面对 LTX 2.3,也有 60.9% 的胜率。对应的 opponent win 只有 11.8% 和 21.9%,说明优势并不是“略好一点”,而是在人类观感上已经形成明显偏好。结合前面的 WER 和 text alignment,这说明它的 improvement 不是单纯的“更清晰”,而是整体音视频自然性和同步性都更强。
5.3 推理效率:5 秒 256p 只要 2 秒,1080p 也在 40 秒内
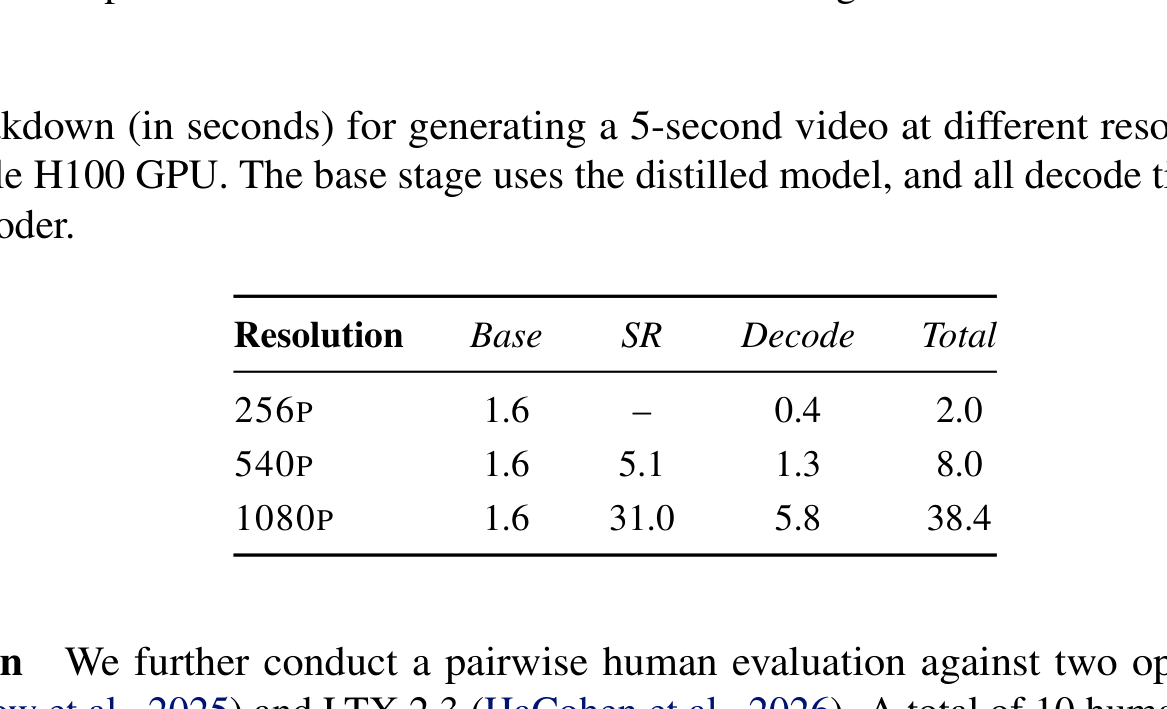
Figure/Table 5 解读:这张表解释了论文标题里 “Fast” 的含义。对于 5 秒视频:
- 256p:Base 1.6s + Decode 0.4s = 2.0s
- 540p:Base 1.6s + SR 5.1s + Decode 1.3s = 8.0s
- 1080p:Base 1.6s + SR 31.0s + Decode 5.8s = 38.4s
一个很关键的观察是:Base stage 的耗时在不同输出分辨率下保持不变(都是 1.6s)。这正说明作者的 two-stage 设计是有效的:高分辨率的额外成本主要集中在 SR 和 decode,而不是让主生成器本身随着分辨率膨胀。
5.4 定性样例:human-centric 场景确实更强
Figure 6 解读:这张 qualitative figure 覆盖了老人特写、课堂对话、宇航员、校园人物、室内人像、舞蹈、街景等多种人类相关场景。可以看到模型重点展示的是:嘴型与字幕对应、面部表情细节、镜头前人物的自然动作以及多语言 spoken generation 的适配。虽然论文没有像一些 benchmark paper 那样给出大量逐项对比图,但从样例组织方式就能看出,它的核心优势被设计在 人物表演和音视频同步 这一类任务上,而不是追求最极端的物理仿真或复杂世界建模。
5.5 局限性与整体结论
论文主文比较短,没有单列局限性章节,但从结果和描述中可以看出几个现实边界:
-
Physical Consistency 不是最强项
LTX 2.3 在 physical consistency 上略强,说明 daVinci-MagiHuman 的优势更偏 human-centric expressiveness,而不是所有物理一致性场景都最好。 -
系统仍重依赖完整工程栈
虽然主干简单,但推理速度依赖:- distillation
- latent SR
- Turbo VAE
- full-graph compilation
所以“简单”主要是指 backbone 设计,而不是整套部署完全轻量。
-
开源代码当前重点在 inference,不是训练细节复现
公开仓库完整提供了 inference stack、模型加载、调度器、SR、Turbo decoder 等,但没有看到完整训练代码。因此对于训练 recipe,更多仍需依赖论文文字。
总体来说,我认为这篇论文的价值在于:
它证明了 open-source audio-video generation 不一定要靠越来越复杂的 multi-stream 结构,单流统一 backbone 也可以在质量、语音同步和推理速度上做到非常强的平衡。
它最重要的贡献不是发明某个全新的损失函数,而是把:
- single-stream Transformer
- timestep-free denoising
- latent-space super-resolution
- Turbo decoder
- distillation
- full-graph compile
这些组件组织成了一套真正可落地的音视频基础模型系统。