SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
Paper: arXiv:2605.12500 Code: OpenSenseNova/SenseNova-U1 Code reference:
main@e2f1b47a(2026-05-15)
1. Motivation (研究动机)
当前 VLM 与图像生成模型通常把“理解”和“生成”拆成两套系统:理解侧依赖 vision encoder,把图像压成语义 token;生成侧依赖 VAE / diffusion latent,把图像当作另一个 latent 空间里的连续信号。这种拆分带来三个具体问题:表示空间不一致,理解结果很难原生反哺生成;级联系统需要额外适配器和调度逻辑;预训练 encoder / VAE 的固定表示会限制像素级细节、文字渲染、空间推理和 interleaved image-text generation 的共同扩展。
本文要解决的是 native unified multimodal modeling:在同一个 backbone 内同时处理文字、干净图像 token、噪声图像 token,并让模型直接在 pixel patch 空间做 flow matching,而不是在“理解 encoder + 生成 VAE”之间转换。目标不是单独提升 T2I 或 VQA,而是证明同一套 NEO-unify / MoT 架构能同时覆盖 image understanding、text understanding、X2I generation、image editing、interleaved generation、VLA 和 world modeling。
这个问题值得研究,因为一旦理解与生成共用原生表示,模型可以把空间、文字、知识、视觉细节和动作/世界预测放到同一套推理链路里:例如先理解多图上下文,再生成下一张图;或者从机器人视频中预测世界状态。论文的核心价值是把“多模态系统集成”推进到“单一模型内的能力涌现”。
2. Idea (核心思想)
核心 insight:不要先把图像压到 pretrained VE/VAE 的语义 latent,再让 LLM 学会对齐;而是用近乎无损的轻量 patch interface 把 pixel patch 和 text token 放进同一个 native Transformer,让 clean image / text token 与 noisy image token 在共享注意力结构里交互。
关键创新可以概括为三点:1) 32×32 patch 的 near-lossless visual interface,encoder 只用两层卷积,decoder 直接预测 pixel patch;2) Native Mixture-of-Transformers (MoT),understanding stream 和 generation stream 参数解耦但在统一序列和 self-attention 里协作;3) resolution-adaptive noise scale 和 pixel-space flow matching,使不同分辨率下的信噪比更稳定。
与 BAGEL / Ovis-U1 / UniFlow 等 unified 或 tokenizer-based 方法相比,SenseNova-U1 的根本差异是更彻底地绕开 VAE / separate visual tokenizer,把 generation 也还原为同一个 native token 序列上的 pixel-space denoising。它不是把 LLM 外接一个图像生成器,而是把生成路径作为同一 backbone 的另一个 stream。
3. Method (方法)
3.1 Overall framework
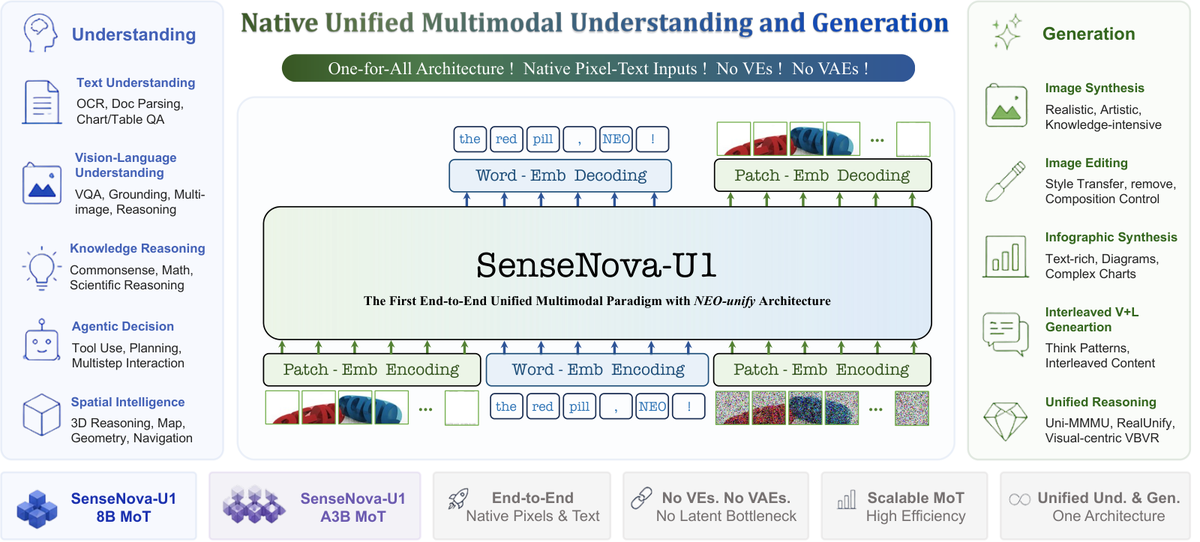
Figure 1 解读:这张 overview 展示 SenseNova-U1 的整体定位:模型输入可以是 text、image 或 interleaved context,输出可以是 text、image、editing result、multi-step interleaved content,甚至 VLA/world-modeling 形式的视觉预测。它强调的不是单任务 SOTA,而是同一 native backbone 支撑多类理解与生成任务。
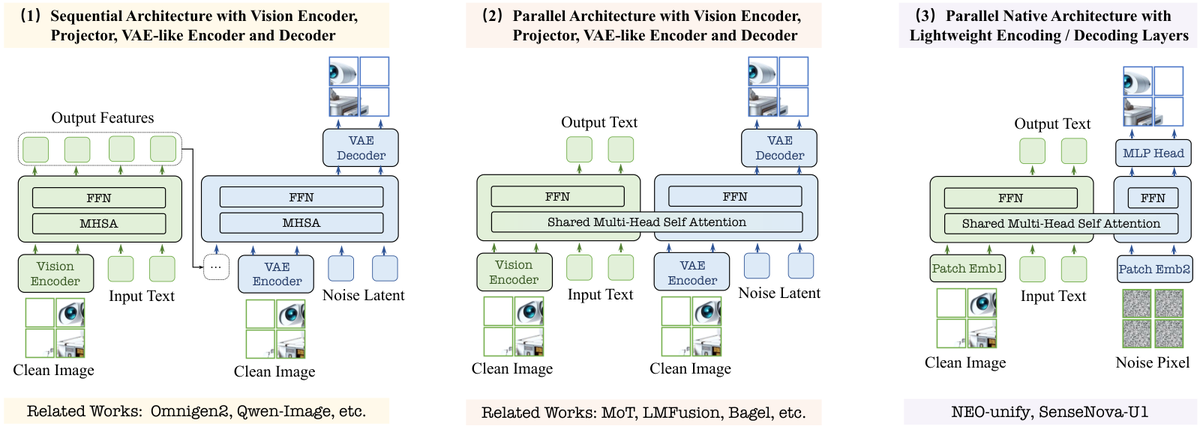
Figure 2 解读:架构由三块组成。左侧 near-lossless visual interface 把图像或噪声通过两层 convolution 编成 visual tokens,每个 token 对应 pixel patch;中间 NEO-unify / MoT backbone 在同一序列里处理 text、clean image 和 noise image token;右侧理解分支用 linear head 预测文本,生成分支用 MLP-like / flow matching head 直接预测 pixel patch,省掉 VAE decoder。
直觉上,这个设计把“图像理解”和“图像生成”变成同一序列建模问题的两个视角。clean image tokens 提供感知和上下文,noise image tokens 负责逐步变成目标像素;二者在 attention 里接触,但通过 token-type routing 进入不同 stream 的 projections / FFN,避免理解能力被噪声生成目标破坏。
3.2 Key components
Near-lossless visual interface. Patch encoding layer 使用两层 convolution + GELU + 2D sinusoidal position encoding,stride 分别为 16 和 2,因此总压缩率为 32,每个 visual token 对应一个 patch。文本仍使用底层 LLM tokenizer。理解头是 vocabulary projection;生成头直接回归 pixel patch,而不是 latent VAE code。
Dynamic noise scale. 由于 generation stream 支持不同分辨率,固定 unit Gaussian 会导致同一 timestep 下高分辨率样本的有效 SNR 不一致。论文定义 token 数 ,并用
缩放终端噪声;训练表给出的实际设置为 ,当 时 。同时把 经 NSEmb 加到 timestep embedding:
Native MoT and attention mask. 文本 token 仍 causal;同一 image block 内的 clean image / noise image tokens 可以双向 attention;noise tokens 能看见之前上下文和 clean inputs,而 clean tokens 不能看见 noise tokens。understanding 与 generation stream 的 projections、normalization、FFN 独立,由 token type 动态路由。
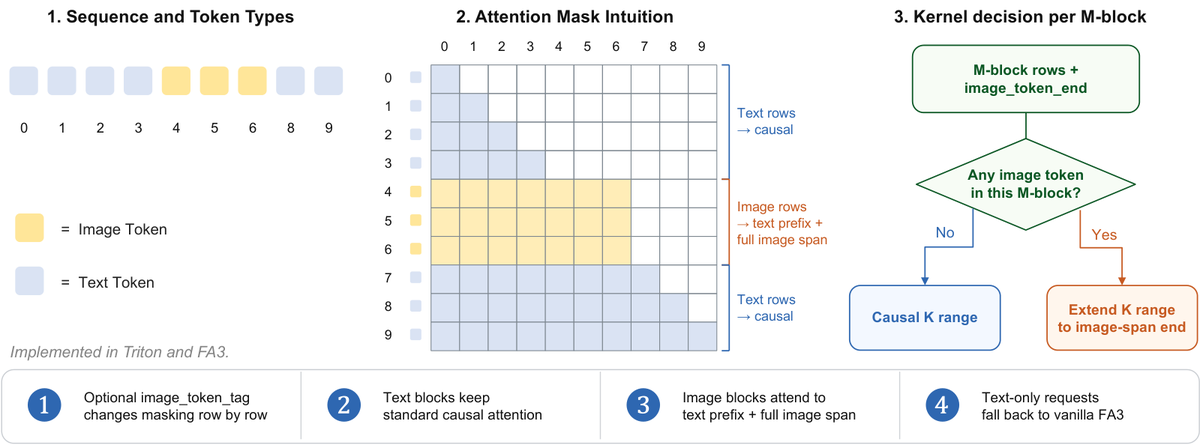
Figure 3 解读:hybrid attention kernel 是 serving 侧的关键:纯文本行保持 causal fast path,image token 所在 block 才扩展 key range 到完整 image span。这样不牺牲 LLM prefill 的常规效率,又允许图像 token 在空间维度内双向通信。
Pixel-space flow matching. 给定 clean image 和 ,论文使用 rectified-flow interpolant:
模型先预测 clean signal ,再转换为 velocity:
并最小化
总目标是
其中理解损失为 next-token CE。Stage 3/4 的实际 loss weight 是 CE:MSE = 。
Classifier-Free Guidance. 训练时以 10% 概率 drop text condition,并额外以 10% 概率同时 drop text 和 image condition。推理时用 text guidance 与 image-context guidance 分解条件影响;经验上 。
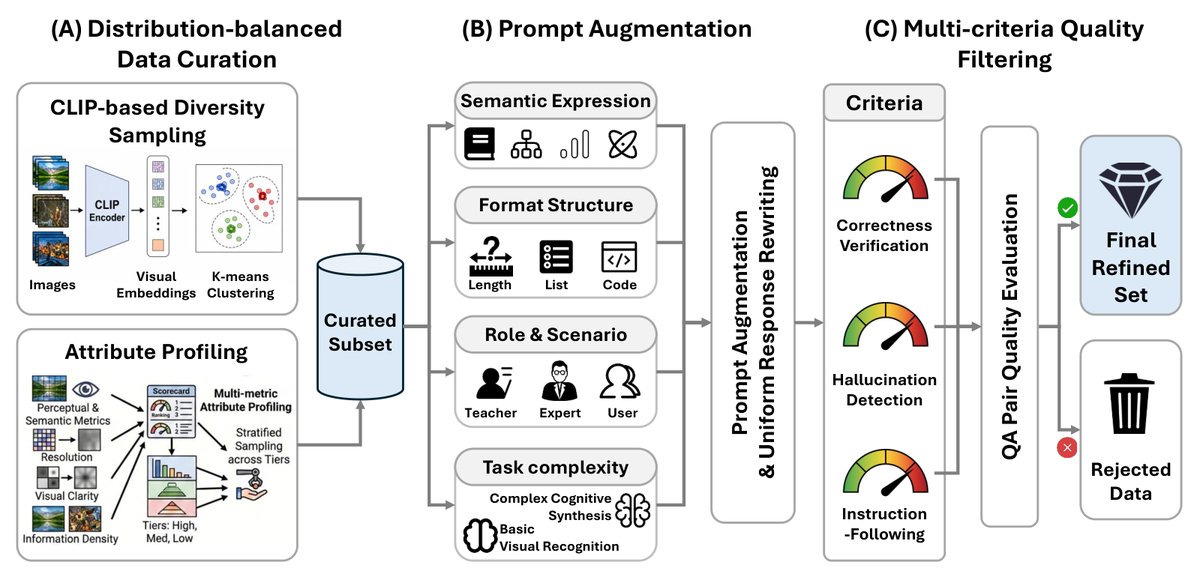
Figure 4 解读:理解数据的 mid-training pipeline 先做 distribution-balanced sampling,覆盖长尾视觉/语义属性;再做 prompt augmentation,把问答扩展到语义表达、格式约束、角色场景和任务复杂度;最后用多维 quality filtering 检查 correctness、hallucination 和 instruction following。
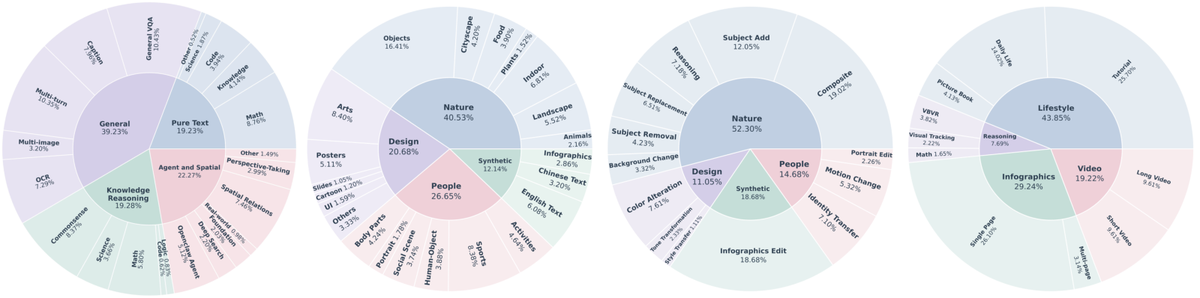
Figure 5 解读:四个 sunburst 分别展示 understanding、text-to-image、editing、interleaved corpus 的层级构成。训练目标不是单一图像生成分布,而是让模型同时见到自然图像、设计/infographic、人像、合成数据、editing 操作和 interleaved narrative。
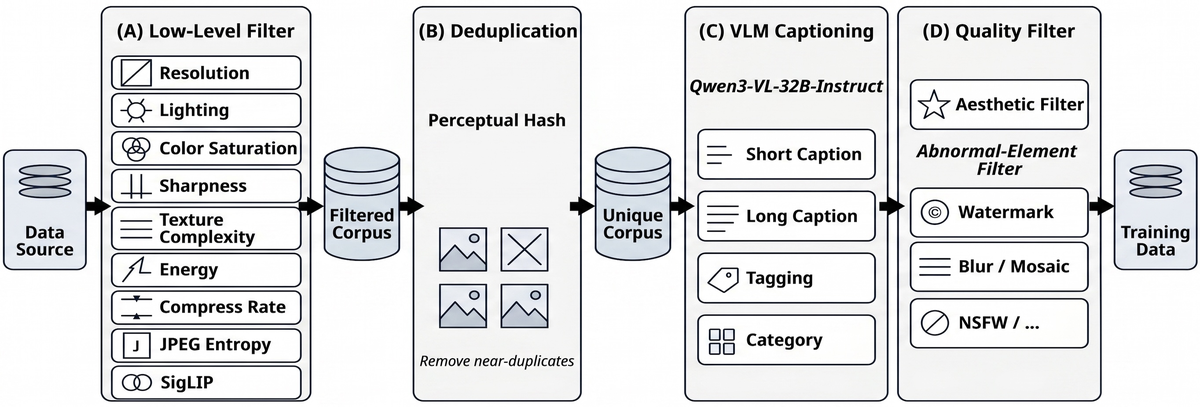
Figure 6 解读:generation corpus 统一经过 low-level filtering、deduplication、VLM captioning 和 quality filtering。对 editing 数据,论文还会把指令拆成 dynamic objectives 与 static consistency constraints,以保证“该变的变、不该变的不变”。
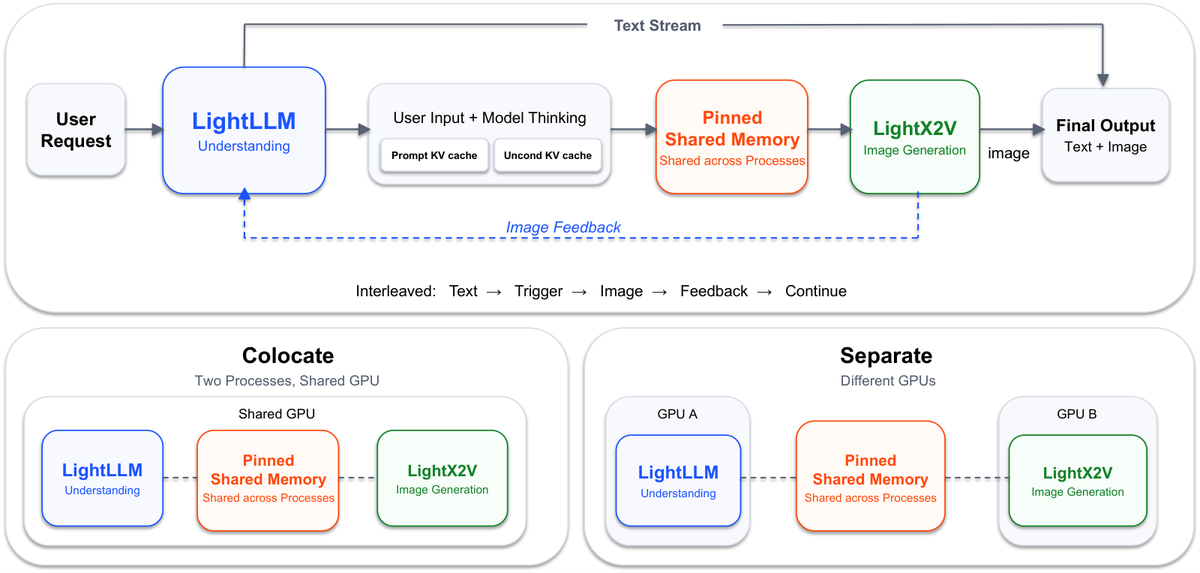
Figure 7 解读:serving 虽然对外是统一模型,但实现上把 understanding/text streaming/control flow 交给 LightLLM,把 iterative image denoising 交给 LightX2V。两者通过 pinned shared memory 交换 generation state,使 text-heavy 和 image-heavy traffic 可以分开扩缩容。
3.3 Pseudocode based on released code
Code reference:
main@e2f1b47a(2026-05-15) — pseudocode and mapping based on this commit
Released repo 主要是 inference / evaluation / serving 代码,不包含论文 Stage 1–6 的训练 launch scripts。因此下面 pseudocode 对应 released inference path;训练超参来自论文 LaTeX sec/3_model.tex 的 training table,而不是代码默认值。
import math
import torch
def sensenova_patchify(images: torch.Tensor, patch_size: int = 32) -> torch.Tensor:
# Mirrors NEOChatModel.patchify: [B, 3, H, W] -> [B, L, patch_size**2 * 3]
b, c, h_img, w_img = images.shape
h, w = h_img // patch_size, w_img // patch_size
x = images.reshape(b, 3, h, patch_size, w, patch_size)
x = torch.einsum("bchpwq->bhwpqc", x)
return x.reshape(b, h * w, patch_size * patch_size * 3)
def sensenova_unpatchify(tokens: torch.Tensor, patch_size: int, h_img: int, w_img: int) -> torch.Tensor:
h, w = h_img // patch_size, w_img // patch_size
x = tokens.reshape(tokens.shape[0], h, w, patch_size, patch_size, 3)
x = torch.einsum("bhwpqc->bchpwq", x)
return x.reshape(tokens.shape[0], 3, h_img, w_img)def t2i_flow_loop(model, prompt_embeds, image_size, num_steps, cfg_scale, seed):
# Condensed from NEOChatModel.t2i_generate / _t2i_predict_v.
token_h = image_size[1] // model.patch_size
token_w = image_size[0] // model.patch_size
grid_h, grid_w = image_size[1] // model.patch_size, image_size[0] // model.patch_size
noise_scale = model.noise_scale
if model.noise_scale_mode in {"resolution", "dynamic", "dynamic_sqrt"}:
scale = math.sqrt((grid_h * grid_w) / model.noise_scale_base_image_seq_len)
noise_scale = min(scale * model.noise_scale, model.noise_scale_max_value)
g = torch.Generator(prompt_embeds.device).manual_seed(seed)
image = noise_scale * torch.randn(1, 3, image_size[1], image_size[0], generator=g)
z = sensenova_patchify(image, model.patch_size)
timesteps = torch.linspace(0.0, 1.0, num_steps + 1, device=z.device)
timesteps = model._apply_time_schedule(timesteps, token_h * token_w, model.timestep_shift)
for t, t_next in zip(timesteps[:-1], timesteps[1:]):
v_pos = model._t2i_predict_v(prompt_embeds, t=t, z=z, image_size=image_size)
if cfg_scale > 1:
v_neg = model._t2i_predict_v(model.empty_prompt_embeds, t=t, z=z, image_size=image_size)
v = v_neg + cfg_scale * (v_pos - v_neg)
else:
v = v_pos
z = z + (t_next - t) * v
return sensenova_unpatchify(z, model.patch_size, image_size[1], image_size[0])def hybrid_attention_range(row_is_image: bool, causal_end: int, image_span_end: int) -> int:
# Condensed from docs/inference_infra.md and the hybrid attention figure.
# Pure-text blocks keep causal range; blocks containing image tokens extend to full image span.
if not row_is_image:
return causal_end
return max(causal_end, image_span_end)论文公式与 released code 实现差异:论文完整描述了 RL post-training、Flow-GRPO reward、DMD2 distillation 和 Stage 1–6 training recipe;released repo at e2f1b47a 暂未提供这些训练脚本,只提供 model / inference / evaluation / serving 实现。代码中的 t2i_generate 还暴露了 dynamic_sqrt noise mode、cfg_zero_star / global / channel CFG normalization 等工程选项,论文正文没有逐一展开。
3.4 Code-to-paper mapping
Code reference:
main@e2f1b47a(2026-05-15) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| NEO-unify chat/generation backbone | src/sensenova_u1/models/neo_unify/modeling_neo_chat.py | NEOChatModel, t2i_generate, it2i_generate, interleave_gen |
| Pixel patch interface | src/sensenova_u1/models/neo_unify/modeling_neo_chat.py | patchify, unpatchify |
| Flow matching head / pixel decoder modules | src/sensenova_u1/models/neo_unify/modeling_fm_modules.py | FlowMatchingHead, PatchDecoder_*, ConvDecoder |
| Vision embeddings / 2D RoPE | src/sensenova_u1/models/neo_unify/modeling_neo_vit.py | NEOVisionEmbeddings, apply_2d_rotary_pos_emb |
| MoT / MoE config knobs | src/sensenova_u1/models/neo_unify/configuration_neo_chat.py | NEOMoELLMConfig, NEOChatConfig |
| T2I / editing / interleaved inference | examples/t2i/inference.py, examples/editing/inference.py, examples/interleave/inference.py | SenseNovaU1T2I.generate, SenseNovaU1Editing.edit, SenseNovaU1Interleave.generate |
| Disaggregated serving design | docs/inference_infra.md | LightLLM + LightX2V deployment notes |
4. Experimental Setup (实验设置)
Datasets and scale. Understanding pre-training corpus contains image-text pairs 32%, captions 17%, infographic understanding 14%, pure text 37%。Mid-training corpus 来自 SenseNova V6.5:General 39.2%, Agent and Spatial 22.3%, Knowledge Reasoning 19.3%, Pure Text 19.2%。SFT corpus 覆盖 spatial intelligence ~15%, general multimodal understanding ~13%, reasoning ~12%, NLP ~11%, OCR/document ~11%, agentic function calling ~10%, long-context conversation ~8%, code ~6%, multi-turn ~4%, compositional understanding ~4%。Generation corpus 覆盖 T2I、editing、interleaved:T2I 中 Nature ~40.5%, People ~26.7%, Design ~20.7%;editing 中 natural scenes ~52.3%, human subjects ~14.7%;interleaved 中 Lifestyle ~44%, Infographics ~29%, Video ~19%, Reasoning ~8%。
Baselines. Understanding 对比 Qwen3VL / Qwen3.5 / Gemma4 / LongCat-Next 等;image generation 对比 Qwen-Image、Ovis-U1、Z-Image-Turbo、FLUX.1-dev、closed-source Nano-Banana / GPT-Image 等;editing 对比 Qwen-Image-Edit 系列、Ovis-U1;interleaved generation 对比 GPT-4o+DALL-E3、Gemini+Flux、Ovis-U1。
Metrics. VQA/OCR/math benchmarks 使用 benchmark accuracy;DPG-Bench 报 Global / Entity / Attribute / Relation / Other / Overall;GenEval 报 object/counting/color/position/binding overall;GEdit-Bench 与 ImgEdit 报人评/模型评 overall;TIIF、LongText、CVTG、IGenBench 关注 text rendering / chart / infographic correctness;RISEBench、WISE 关注 reasoning image generation/editing。
Training config. 这些数字来自论文源文件 sec/3_model.tex 的 training recipe table,而 released repo 没有训练 launch config。Stage 1 understanding warmup: 120K steps, peak LR , seq length 32768, 0.75T training tokens。Stage 2 generation pre-training: Phase I 120K steps, LR , gen resolution , seq length 8192, 0.25T tokens;Phase II 60K steps, LR , gen resolution , seq length 16384, 0.25T tokens;Phase III 120K steps, cosine , seq length 16384, 0.88T tokens。Stage 3 unified mid-training: 84K steps, LR , seq length 32768, 1.19T tokens, data ratio understanding:generation:editing:interleave = 0.33:0.37:0.24:0.06。Stage 4 unified SFT: 9K steps, cosine , seq length 32768, 0.13T tokens。Optimizer 为 AdamW ,weight decay 0,gradient clip 1.0。
Post-training for T2I includes text-rendering RL: 600 epochs, LR , KL , per epoch prompts × images, 10-step flow matching, CFG 4.0, noise level 0.7, dynamic-resolution warmup 200 epochs。Unified general RL: 8B variant 1600 epochs, A3B variant 200 epochs, 。DMD2 distillation reduces NFE from 100 to 8; generator LR , fake flow LR , AdamW betas , weight decay 0.01, timestep shift 3.0, CFG 4.0。
5. Experimental Results (实验结果)
Understanding and text. SenseNova-U1-8B-Think 在 MMMU 74.78、MMMU-Pro 67.69、MathVista-mini 84.20、MathVision 75.82;30BA3B-Think 分别为 80.55、72.83、85.30、79.63。空间智能上,8B-Think 在 VSI-Bench 62.66、ViewSpatial 56.19、MindCube-Tiny 62.01、3DSR-Bench 64.88;30BA3B-Think 在 MindCube-Tiny 达到 70.86。纯文本方面,8B-Think 在 IFEval 91.13、Tau2 71.70、Claw eval 58.90;30BA3B-Think 在 MMLU-Pro 84.04、IFEval 92.39、Tau2 75.39。
Generation / editing / interleaved main numbers. DPG-Bench Overall: SenseNova-U1 8BA3B 88.14, 8B 87.78, Qwen-Image 88.32, Ovis-U1 83.72。GenEval Overall: 8BA3B 0.91, 8B 0.91, Qwen-Image 0.87。IGenBench open-source Overall Q-ACC/I-ACC: 8B 0.51/0.04, 8BA3B 0.42/0.02, Qwen-Image 0.36/0.01。BizGenEval hard/easy Average: 8B 39.7/61.7, 8BA3B 28.2/51.9, Qwen-Image-2512 6.3/41.0。TIIF testmini short Overall: 8B 89.74, 8BA3B 89.25, Qwen-Image 86.14;long Overall: 8B 89.17, 8BA3B 87.36, Qwen-Image 86.83。Image editing ImgEdit Overall: Qwen-Image-Edit-2511 4.51, SenseNova-U1 8BA3B 3.91, 8B 3.90。GEdit-Bench Overall: Qwen-Image-Edit-2511 7.88, SenseNova-U1 8B 7.47, 8BA3B 7.32。OpenING Overall: SenseNova-U1-SFT w/ CoT 8BA3B 9.16, 8B 9.07, GPT-4o+DALL-E3 8.20, Gemini+Flux 7.23。RealUnify Avg: 8B 52.4, 8BA3B 50.5, Ovis-U1 35.4。
Ablations and visual analyses. Reconstruction with frozen understanding branch: Neo-unify 2B at downsampling ratio 32 and resolution 512 reaches PSNR 31.56 / SSIM 0.85, matching FLUX.1-dev VAE PSNR 31.56 but with lower SSIM. RL curves show text/rendering/reasoning-oriented post-training generally improves DPG-Bench、WISE、GEdit-Bench、RISEBench scores, while paper notes A3B still has room for further improvement after only 200 epochs。VLA/world-modeling qualitative figures show U1 can infer robot manipulation behavior and predict arm-view future states, but these are preliminary evidence rather than full robotics benchmarks。
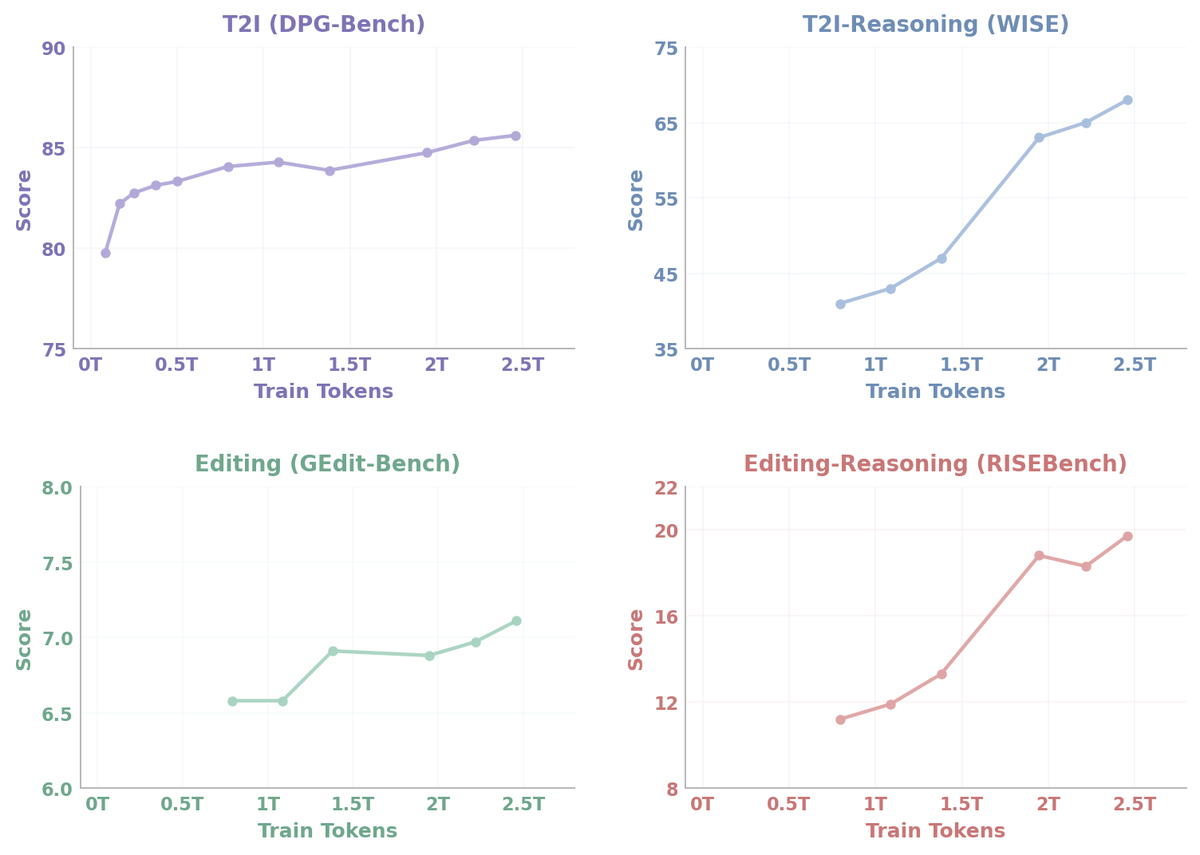
Figure 8a–8d 解读:四个训练曲线分别对应 DPG-Bench、WISE、GEdit-Bench、RISEBench。它们展示 post-training/RL 对通用生成、reasoning generation、editing 和 reasoning editing 的收益;曲线不是单一 reward 变好,而是多个任务分布下的综合改善。

Figure 9 解读:reconstruction case 验证 frozen understanding branch 下,2B NEO-unify 仍能重建 out-domain images。它支撑 near-lossless patch interface 的论点:即使压缩率到 32,pixel-space path 仍保留足够视觉细节。

Figure 10 解读:ImgEdit case 展示模型在 frozen understanding branch 下对 editing prompt 的执行能力,重点不是单张图质量,而是验证理解条件能有效进入 generation stream。
Figure 11 解读:co-training ablation 展示 understanding 与 generation 共同训练时的冲突和收益。它对应本文最关键的风险:统一模型可能互相干扰,因此需要 MoT stream decoupling、loss ratio 和 staged recipe 来稳定联合优化。

Figure 12 解读:VLA visualization 说明模型能把机器人视频中的状态变化、动作意图和语言描述关联起来。这不是本文主评测,但支持作者关于 native multimodal model 可自然扩展到 action reasoning 的论点。

Figure 13 解读:world-modeling 结果展示从 robotic arm view 预测后续视觉状态。它说明 pixel-space generation stream 不只适用于静态图像,也能作为世界动态预测的候选接口。
Limitations. 论文明确提到的一个工程限制是 generation branch 最后 FFN 与 MLP head 独立建模 pixel patches,可能导致 grid artifacts;作者冻结 generation branch 最后三层和 MLP head 以缓解,并提出未来用 PixelShuffle + two convolution layers 替换 MLP head。另一个实际限制是 released code 暂未覆盖完整训练/RL/DMD2 pipeline,复现实验训练 recipe 还依赖论文描述而非公开 launch scripts。
Conclusion. 结果证明 SenseNova-U1 能在不依赖 VAE/VE 分裂架构的情况下,把理解、生成、editing、interleaved generation 和初步 VLA/world-modeling 放入同一 native MoT 框架;其优势最明显在 text-rich / infographic / interleaved / reasoning-heavy 生成场景,而传统 image editing overall 仍落后于最新 Qwen-Image-Edit 系列。