Self-Supervised Flow Matching for Scalable Multi-Modal Synthesis
Authors: Hila Chefer, Patrick Esser, Dominik Lorenz, Dustin Podell, Vikash Raja, Vinh Tong, Antonio Torralba, Robin Rombach Affiliations: Black Forest Labs, MIT arXiv: 2603.06507 Project Page: bfl.ai/research/self-flow GitHub: black-forest-labs/Self-Flow
1. Motivation(研究动机)
这篇工作针对一个非常具体但又很关键的问题:为什么 diffusion / flow model 在生成上很强,却往往学不到足够强的 semantic representation,必须依赖外部 encoder(如 DINO)来加速训练和提升质量?
作者指出,现有 external alignment 方法虽然有效,但有三个根本问题:
- 目标不一致:外部 encoder 是为判别或对比学习训练的,不是为生成训练的,因此其表征未必和 generative objective 对齐。
- 扩展性反常:更强的外部 encoder 不一定更好。论文在 REPA 上直接展示了 DINO 从 v2-B 扩到 v3-H+ 后,生成质量反而下降。
- 跨模态泛化差:图像上有效的 external alignment,在视频和音频上未必有效,甚至会伤害性能,因此不适合 image / video / audio 的统一 multi-modal 框架。
因此,作者希望把 representation learning 直接并入 flow matching 本身,让模型在学会生成的同时,被迫学习可泛化的内部语义表征,而不是依赖外部 teacher encoder。

Figure 1 解读:左半部分展示 text-to-image 训练曲线,Self-Flow 在不借助外部 encoder 的情况下,FID 收敛速度明显快于 REPA,文中给出的结论是约快 。右半部分给出 image/video qualitative case,可以看到 Self-Flow 改善了结构一致性、文本渲染以及视频的时间一致性。这个 figure 直接把论文的核心 claim 摆出来:作者不是只想“替代 DINO”,而是想证明 internal self-supervision 本身可以比 external alignment 更 scalable、更 general。
2. Idea(核心思想)
核心思想:作者提出 Self-Flow,在标准 flow matching 中加入一个自监督 representation reconstruction objective。它的关键不是额外加一个外部 teacher,而是通过 Dual-Timestep Scheduling 在同一样本的不同 token 上施加不同噪声强度,制造信息不对称,让 student 必须依赖较干净 token 去推断较脏 token 的语义表示。
可以把它概括成两句话:
- 用 heterogeneous noising 代替传统的 homogeneous noising,显式制造“上下文 token vs 被破坏 token”的关系;
- 用 EMA teacher 在更干净视图上产生特征,再让 student 在更难视图上同时完成 flow denoising 与 feature reconstruction。
与已有方法最本质的区别在于:
- 相比 REPA,这个方法不依赖外部 encoder;
- 相比 SRA / LayerSync,这个方法不是被动利用不同层天然的 semantic gap,而是主动通过 masking + dual timestep 逼迫模型形成全局语义关系。
3. Method(方法)
3.1 整体框架
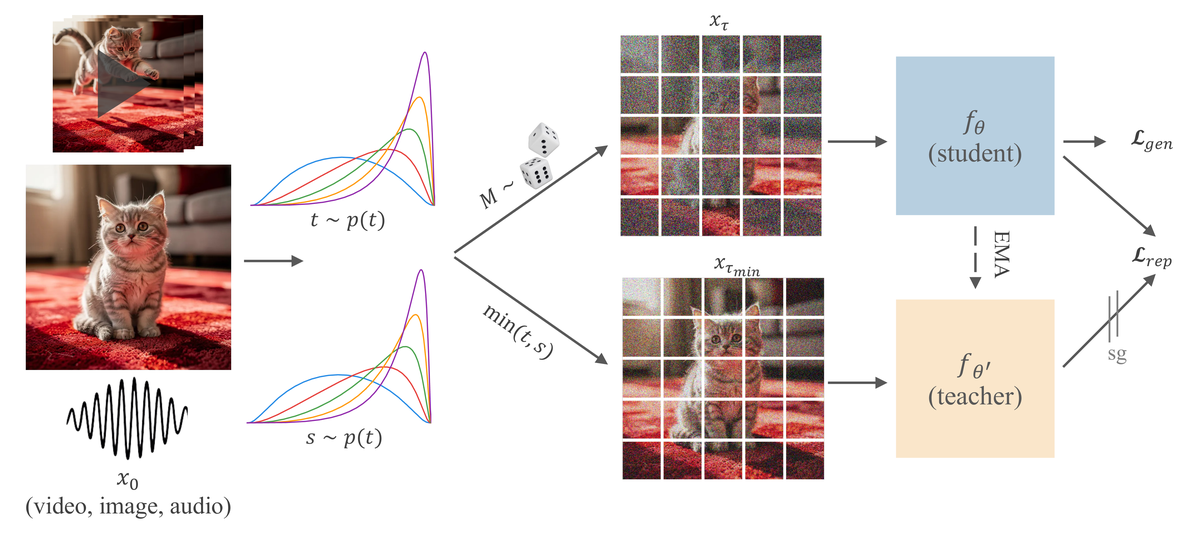
Figure 3 解读:Figure 3 是整篇论文最关键的结构图。输入 clean latent 后,先采样两个 timestep 和一个随机 mask 。student 分支看到的是按 token 级别混合噪声后的 ,其中一部分 token 用 ,其余用 ;teacher 分支看到的是更干净的统一视图 ,其中 。student 一方面输出 velocity 做 flow matching,另一方面在较浅层通过 projection head 对齐 teacher 在较深层产生的 feature。这个设计把“生成目标”和“表征目标”放到了同一个 backbone 内联合优化。
3.2 关键组件 1:Flow Matching 预备定义
论文建立在 rectified flow 上。给定 clean token sequence 与 Gaussian noise ,定义线性路径:
对应 velocity 为:
标准 flow matching loss:
这部分本身并不会显式鼓励 semantic abstraction,作者认为这正是 generative model 需要 external representation 的根源。
3.3 关键组件 2:Dual-Timestep Scheduling
作者对每个 token 不再使用统一 timestep,而是采样两个时间步 ,再采样 token mask:
随后定义 token-wise dual timestep:
对应输入为:
这个设计的关键不只是“masking”,而是两种噪声强度都来自相同的 timestep distribution,因此每个 token 的 marginal timestep distribution 仍然与原 flow matching 保持一致。作者在 Figure 2 中说明,直接 full masking 或 diffusion forcing 都会造成 train-inference gap,而 Dual-Timestep Scheduling 在不破坏推理行为的前提下引入了信息不对称。
3.4 关键组件 3:Self-Flow 自监督目标
teacher 使用 EMA 权重 ,并观察更干净的输入:
representation alignment loss 为:
其中 student 在第 层经过 projector ,teacher 使用第 层表征,且论文遵循 prior work 的经验设置 。
最终训练目标:
其中论文固定 。直观上,这个目标让 student 不仅要会“像普通 flow 一样去噪”,还要会“从更坏视图恢复出更好视图下的内部语义特征”。
3.5 关键组件 4:Per-token timestep conditioning 与 multi-modal 兼容性
论文在 architecture appendix 中强调:一旦采用 Dual-Timestep Scheduling,模型的 timestep conditioning 就从标量 扩展为 token-wise 向量 。这使得同一个 transformer 能统一处理 image patches、video latents、audio segments 等不同 token 序列。
在 mixed multi-modal setting 中,作者只为不同模态保留各自的 input/output projection,其余 backbone 权重共享。因此 Self-Flow 的真正野心不是单模态上的一个 trick,而是构造一个统一的 representation-generative backbone。
3.6 伪代码(结合论文与公开实现)
说明:官方仓库当前只公开了 ImageNet inference code,没有公开完整 training script。下面前两个伪代码来自论文公式与 appendix 超参数,后两个伪代码直接对应公开仓库
black-forest-labs/Self-Flow的实现。
# Pseudocode 1: Dual-Timestep Scheduling
def dual_timestep_schedule(x0, p_t, mask_ratio):
x1 = randn_like(x0)
t = sample_from(p_t)
s = sample_from(p_t)
M = bernoulli_mask(num_tokens=x0.shape[0], prob=mask_ratio)
tau = where(M, s, t) # token-wise timestep
x_tau = (1 - tau) * x0 + tau * x1 # student input
tau_min = min(t, s)
x_tau_min = (1 - tau_min) * x0 + tau_min * x1 # teacher input
return x1, tau, x_tau, tau_min, x_tau_min, M# Pseudocode 2: Self-Flow training step
def self_flow_step(x0, cond, student, teacher_ema, p_t, gamma, l, k, mask_ratio):
x1, tau, x_tau, tau_min, x_tau_min, _ = dual_timestep_schedule(x0, p_t, mask_ratio)
v_pred, student_feat = student(x_tau, tau, cond, return_features=l)
with no_grad():
_, teacher_feat = teacher_ema(x_tau_min, tau_min, cond, return_raw_features=k)
L_gen = mse(v_pred, x1 - x0)
L_rep = -cosine_similarity(project(student_feat), teacher_feat.detach()).mean()
loss = L_gen + gamma * L_rep
optimize(student, loss)
ema_update(teacher_ema, student, decay=0.9999)# Pseudocode 3: Public code - SelfFlowPerTokenDiT.forward (src/model.py)
def per_token_forward(tokens, timesteps, class_labels):
x = patch_embed(tokens) + pos_embed
if timesteps.ndim == 1:
t_emb = timestep_embed(timesteps).broadcast_to_all_tokens()
else:
t_emb = timestep_embed(timesteps.flatten()).reshape_as_token_grid()
y_emb = label_embed(class_labels).broadcast_to_all_tokens()
c = t_emb + y_emb
for block in per_token_dit_blocks:
x = block(x, c) # adaLN modulation is token-wise
out = per_token_final_layer(x, c)
return shufflechannel_and_negate(out)# Pseudocode 4: Public code - ImageNet sampling (sample.py + src/sampling.py)
def sample_batch(model, vae, class_labels, batch_size, num_steps, cfg_scale):
noise = randn(batch_size, 4, 32, 32)
patched = patchify_2x2(noise)
x, x_ids = batched_prc_img(patched)
if cfg_scale > 1:
x, x_ids, class_labels = duplicate_for_cfg(x, x_ids, class_labels)
latents = denoise_loop(
model=model,
x=x,
x_ids=x_ids,
vector=class_labels,
num_steps=num_steps,
mode="SDE",
)
latents = scattercat(latents, x_ids)
latents = unpatchify_2x2(latents)
images = vae.decode(latents / 0.18215)
return to_uint8(images)3.7 Code-to-paper mapping table
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Per-token timestep conditioning | src/model.py | SelfFlowPerTokenDiT._forward |
| Token-wise adaLN modulation | src/model.py | PerTokenDiTBlock.forward |
| Self-distillation projector | src/model.py | SimpleHead |
| ImageNet backbone construction | sample.py | load_model |
| Sampling / denoising loop | src/sampling.py | denoise_loop, FixedSampler.sample_sde |
| Latent patchify / scatter back | src/utils.py | batched_prc_img, scattercat |
| Dual-Timestep Scheduling training logic | 训练代码未公开 | 论文 Eq. (4)-(5) |
| Student-teacher representation loss | 训练代码未公开 | 论文 Eq. (representation loss) |
4. Experimental Setup(实验设置)
4.1 数据集与规模
- ImageNet-1K:1.28M train / 50k val,用于 class-to-image。
- 内部图像数据:200M images;其中 text-to-image 主实验使用 20M text-image pairs,50k validation images。
- 内部视频数据:6M videos,5k validation videos;训练分辨率 192p,使用 45 帧输入。
- 音频数据:1M 个 10 秒音频样本,来自 CC-licensed FMA;20k validation samples。
- Robotics finetuning:RT-1,73.5k episodes;在 SIMPLER simulator 上评估 joint video-action prediction。
4.2 模型与训练配置
- ImageNet backbone:SiT-XL(与 REPA setup 对齐),约 675M 参数。
- 其余实验 backbone:FLUX.2-style transformer,约 625M 参数。
- 关键结构超参数:
hidden_size=1152,mlp_ratio=4,num_heads=16,7个 double MMBlocks,14个 single Blocks,3D RoPE 每维 24 channels。 - 额外 projector 参数量约 10M。
- EMA decay:
0.9999。 - loss 权重:
\gamma=0.8。 - layer 选择:student 层 ,teacher 层 。
- mask ratio:image
\mathcal{R}_M=0.25,audio0.5,video0.1。
4.3 Autoencoder 与 timestep 分布
- ImageNet / T2I(SD-VAE):采用 uniform timestep 分布,便于与 prior work 对齐。
- RAE 实验:plateau-logit-normal + trainshift 。
- Multi-modal image:FLUX.2 AE + logit-normal,trainshift 。
- Video:Wan2.2 AE,logit-normal,作者通过搜索确定 trainshift 。
- Audio:Songbloom AE;最佳主结果对应 trainshift 、sampleshift 、mask ratio 。
4.4 对比方法与评测指标
Baselines:Vanilla Flow Matching、REPA、SRA;并根据模态替换 external encoder:SigLIP 2(图像)、DINOv2 / Depth Anything 3 / V-JEPA2(视频)、MERT(音频)。
Metrics:
- ImageNet:FID / sFID / IS / Precision / Recall
- T2I:FID / sFID / IS / Precision / Recall / FD-DINO / CLIP
- Video:FVD / framewise FID
- Audio:FAD(CLAP / CLAP-M / CLAP-A)
- Robotics:SIMPLER success rate
4.5 采样与 multi-modal 训练细节
- ImageNet SD-VAE:250 SDE steps。
- 非 ImageNet 主实验:50 ODE steps。
- 定性采样 CFG:image 为 3.5,video/audio 为 5;所有定量指标都不使用 CFG。
- mixed multi-modal 训练中,单步 mini-batch 只包含一种模态;batch size 分别为 image
38、video8、audio16;采样概率分别为57% / 30% / 13%。
5. Experimental Results(实验结果)
5.1 主结果:单模态 benchmark
ImageNet 256×256
| Model | Steps | FID↓ | sFID↓ | IS↑ | Pre.↑ | Rec.↑ |
|---|---|---|---|---|---|---|
| SiT-XL/2 | 7M | 8.30 | 6.30 | 130.57 | 0.69 | 0.67 |
| SRA | 4M | 7.27 | 5.87 | 143.06 | 0.69 | 0.68 |
| Self-Flow | 4M | 5.70 | 4.97 | 151.40 | 0.72 | 0.67 |
| REPA | 4M | 5.89 | 5.73 | 157.66 | 0.70 | 0.69 |
| RAE | 1M | 3.24 | 6.73 | 218.53 | 0.83 | 0.54 |
| RAE + Self-Flow | 1M | 2.95 | 5.50 | 222.34 | 0.84 | 0.56 |
结论:在 ImageNet 上,Self-Flow 首次在不依赖 external encoder 的前提下超过 REPA;在 RAE 这种语义 latent space 上也继续获益,说明它不是“只在普通 VAE latent 上成立”的 trick。
Text-to-Image / Video / Audio
| Task | Method | Key Result |
|---|---|---|
| T2I | Self-Flow | FID 3.61,优于 SRA 3.70、REPA 3.92、SigLIP2 3.97;FD-DINO 167.98 也优于 REPA 的 173.35 |
| T2V | Self-Flow | FVD 47.81、FID 8.92;优于 SRA(49.75/9.02)和 REPA-DINOv2(49.59/9.39) |
| T2A | Self-Flow | CLAP 145.645、CLAP-M 0.1634、CLAP-A 0.1001;优于 SRA 和 MERT 对齐 |
作者最强的论点是:在视频和音频上,external alignment 往往不但不帮忙,反而伤害性能。这直接支持论文的动机:外部 encoder 的表征目标并不天然适合 generative training。
5.2 Scaling law 与 multi-modal 结果
- 模型规模从 290M → 420M → 625M → 1B 时,Self-Flow 与 REPA 的差距持续扩大。
- 作者明确给出:625M 的 Self-Flow 已超过 1B 的 REPA。
- 在 mixed multi-modal training 中,Self-Flow 在所有 tested weighting 下都能同时提升 image / video / audio 三个模态的指标。
例如,在权重 下:
| Metric | FM | Self-Flow | Relative Change |
|---|---|---|---|
| Image FID↓ | 3.51 | 3.25 | -7.34% |
| Framewise Video FID↓ | 10.9 | 10.2 | -6.60% |
| Video FVD↓ | 64.8 | 61.0 | -5.85% |
| Audio FAD↓ | 155.4 | 154.2 | -0.75% |
这说明 Self-Flow 不只是“分别训练 image/video/audio 都有效”,而是在共享 backbone 的情况下也能更好地协调跨模态表示。

Figure 7 解读:Figure 7 展示了将 mixed-modality 模型继续 finetune 到 robotics 任务后的 SIMPLER rollout。上半部分是 Move Near,下半部分是 Open and Place。这张图强调的不是单纯生成质量,而是 learned representation 对 embodied prediction / planning 类任务的迁移价值:Self-Flow 初始化在复杂、多阶段任务上显著更稳,说明它学到的不只是更“像照片”的外观,而是对动作相关视觉结构更友好的语义表征。
5.3 定性结果

Figure 9 解读:Figure 9 专门展示 typography rendering。普通 flow matching 在字形、拼写和字符排列上容易出错,而 Self-Flow 在多组案例里都显著更稳定。作者把这当成 representation 变强的一个直接迹象:文本渲染不是简单的 low-level denoising,而要求模型形成更可靠的全局结构与局部字符约束。
作者还在 Figure 10 的 image/video qualitative comparison 中展示:
- 图像结构更稳定,尤其是人脸、手部、复杂物体布局;
- 视频时间一致性更强,基线常出现 limbs 消失、形体漂移;
- 在只用 6M 视频训练数据、且模型仅约 625M 参数时,Self-Flow 仍能给出明显优势。
5.4 Ablation study
作者的 ablation 结论非常清晰:
- 去掉 representation loss,性能下降最大,ImageNet 上 FID 恶化超过 4 点;
- 去掉 masking / Dual-Timestep Scheduling,即便保留 representation loss,也会恶化超过 1 点;
- 把第二个 timestep 限制为只比主 timestep 稍微干净一些(),效果几乎和“去掉 masking”一样差;
- 用 替代 cosine similarity 会导致 feature norm 随训练增大而数值不稳定。
这说明论文并不是“EMA teacher + feature loss”这么简单,真正起作用的是:
- Dual-Timestep Scheduling 提供了有效的信息不对称;
- cosine-based self-distillation 让这种不对称转化成 semantic learning signal。
5.5 局限性
论文明确承认两点局限:
- 训练额外开销:teacher 分支需要额外 forward pass;
- noise scheduler 需要调参:不同 autoencoder / 模态下,最佳 timestep distribution 与 shift 不同,scheduler 选择会显著影响最终效果。
不过作者认为,这些代价换来的是更好的收敛速度、更强的 scaling behavior,以及对 multi-modal / world-model-like 任务更好的泛化潜力。