Qwen-Image-2.0 Technical Report
Paper: arXiv:2605.10730 Code: QwenLM/Qwen-Image — 当前公开 repo 只有 Qwen-Image 系列公告与 inference examples;未找到 Qwen-Image-2.0 的训练代码、MMDiT 实现或 RL/DMD 配置。 Code reference:
main@6b5e1f5c(2026-02-10)
1. Motivation (研究动机)
现有 image generation foundation models 已经能做高质量 aesthetic generation 和基础 text rendering,但在真实创作工作流里仍有几个硬瓶颈:长文本和多语言 typography 容易出错,高分辨率 photorealism 的纹理/材质/光照不稳定,复杂 prompt 的 instruction following 会遗漏概念或产生 hallucination,而 generation 与 editing 往往要切换不同 pipeline。
这篇报告要解决的是:把 text-to-image generation 与 instruction-based image editing 合并到一个统一 backbone 里,同时提升 1K-token 长 prompt、复杂中文/多语言文本、2K-resolution photorealistic generation、身份保持与编辑精度。它不是只追求单一 benchmark,而是把「专业文本视觉内容」如 slides、posters、infographics、comics 与通用图像生成/编辑放到同一个模型能力面上。
问题值得研究的原因在于:如果模型能同时保真文字、遵循复杂 layout、保持 photorealism,并用同一个模型处理 generation/editing,用户就可以直接生成可用的商业视觉资产,而不是在 OCR 修字、局部重绘、分辨率放大、编辑模型切换之间反复补救。
2. Idea (核心思想)
核心 insight 是:把强 multimodal understanding 的 Qwen3-VL 冻结为 condition encoder,再用 MMDiT 在 image latent space 中做 joint condition-target modeling,可以把 prompt 语义、输入图像上下文和目标图像生成统一到同一 denoising 流程里。相比把「理解」和「生成/编辑」拆成多个 pipeline,Qwen-Image-2.0 把长文本、多语言、编辑指令和高分辨率视觉细节都压到一个联合训练框架中。
关键创新可以概括为三层:第一,Qwen3-VL + VAE + MMDiT 的统一架构;第二,覆盖 T2I/TI2I、多分辨率、文本密集数据和错误归因的 data flywheel;第三,在 base model 之后用 adapted GRPO 做 reward alignment,并用 DMD 把 40-step teacher 蒸馏成 4-NFE student。
与 prior Qwen-Image 系列或很多 diffusion baselines 的根本差异在于:它不再把 image generation、editing、prompt enhancement、long-text rendering 视作分散功能,而是把它们作为同一 multimodal diffusion transformer 的训练分布;与 purely qualitative image models 相比,它显式把 typographic correctness、multilingual rendering、layout coherence 和 deployment efficiency 纳入设计目标。
3. Method (方法)
3.1 Overall framework:Qwen3-VL 条件编码 + VAE latent + MMDiT denoising

Figure 8 解读:整体框架由三块组成:frozen Qwen3-VL 读取 system prompt、user prompt 和可选 input image,输出 multimodal condition representations;VAE encoder 把 input/target image 放入 latent space;MMDiT 在 joint stream 中执行 denoising。图中 TI2I 示例把「把两棵椰子树替换为凤凰木」作为 editing condition,说明 generation 与 editing 共用同一 latent denoising backbone。论文还说明 QK-Norm 用 RMSNorm,其余 normalization 用 LayerNorm,joint stream 使用 Qwen-Image 的 MSRoPE positional encoding,MLP 用 SwiGLU。
直觉上,Qwen3-VL 提供的是「理解侧」的强语义与图文对齐能力,MMDiT 提供的是「生成侧」的可扩展 latent denoising 能力。把二者直接耦合后,模型不必先把 prompt 简化成短 caption,也不必在 editing 时另走一个控制网络;复杂文本、布局、参考图像和目标图像都在同一个条件分布里被建模。
3.2 Data curation:从数据分布到闭环 flywheel

Figure 5 解读:图展示 Qwen-Image-2.0 训练数据覆盖的 image categories,目标是避免只在单一审美或单一场景上过拟合。该图对 Method 的意义在于:后续 2K photorealism、portrait、slide、text-rich rendering 的提升不是单靠模型结构,而是依赖更宽的数据分布。

Figure 6 解读:data pipeline 分为六个 progressive filtering/training stages:早期 256p T2I 用基础过滤建立语义;随后加入 editing data 与 synthetic data;后期扩展到 512/1024/2048p,并用更严格的 resolution/filtering rules 支撑高分辨率训练。关键不是一次性清洗数据,而是让数据质量、分辨率和 T2I/TI2I 比例随训练阶段逐步变化。

Figure 7 解读:closed-loop data flywheel 包含 signal collection、case routing & targeted optimization、model update 三个环节。它把用户或评测中暴露的 failure cases 分配到特定 capability track,例如 typography、identity preservation 或 instruction following,再用 targeted data/model update 形成下一轮训练输入。
3.3 Prompt enhancement 与高分辨率训练

Figure 9 解读:prompt-enhanced captions 相比原始 captions 更具体,能把场景布局、物体属性、文字内容和风格要求显式化。图中多例说明,模型在复杂自然场景、诗词文字和 sudoku 结构上更依赖明确、可执行的 prompt 表达。
训练分三阶段:pre-training、continual pre-training、supervised fine-tuning。paper Table 2 给出的关键配置是:pre-training 700K steps,resolution 256/512,batch size 32K/16K,T2I/TI2I=0.9/0.1,LR ;continual pre-training 250K steps,resolution 512/1024/2048,batch size 16K/8K/4K,T2I/TI2I=0.7/0.3,LR ;SFT 10K steps,resolution 512/1024/2048,batch size 16K/8K/4K,T2I/TI2I=0.7/0.3,LR 。三阶段 optimizer 均为 Adam,weight decay 0.001,gradient norm clip 1.0,unconditional dropout 0.1。论文未给 GPU type/count;公开 repo 也没有训练 launch script,因此这些 training numbers 来自 paper Table 2,而不是 released code。
3.4 Reward fine-tuning:adapted GRPO + hybrid CFG

Figure 10 解读:图比较 Qwen-Image-2.0-Base 与 Qwen-Image-2.0-RL,在 T2I 和 TI2I 场景下 RL 后的纹理、真实感和视觉一致性更好。paper 的关键实现选择是 hybrid CFG:rollout sampling 时使用 CFG 以生成更高质量 candidates 供 reward models 评分,但 policy optimization 时不优化 unconditional branch,从而保留样本质量并降低训练开销。
该 RLHF pipeline 的 reward model 权重和 prompt distribution 会动态调整。论文没有公开 reward model 列表、训练脚本或 config 文件;因此笔记只能记录 paper-level 机制,不能把它误写成 released code 行为。
3.5 DMD distillation:40-step teacher 到 4-NFE student

Figure 11 解读:上排是 Qwen-Image-2.0-RL 40 sampling steps teacher,下排是 Qwen-Image-2.0-Distillation 4 NFEs student。图的重点不是 claim 完全无损,而是展示 student 在 portraits、landscapes、natural scenes 上保持视觉质量、semantic alignment 和 composition coherence,同时把 inference cost 大幅压低。
DMD 目标的 gradient 在论文中写为:
其中 ,并用线性插值得到
是 student-induced distribution 的 score,由 auxiliary fake score model 估计; 是 teacher diffusion model 的 target score。直觉是让 few-step student 生成的分布,在带噪 intermediate states 上向 teacher 的真实 score field 靠拢。
3.6 Pseudocode
下面的第一段 pseudocode 只对应公开 repo 中能验证的 inference path;后两段是 paper-level algorithmic pseudocode,因为 released repo 未公开 Qwen-Image-2.0 的训练/RL/DMD 源码。
@torch.no_grad()
def public_repo_t2i_inference(prompt, model_repo_id="Qwen/Qwen-Image", seed=42,
width=1664, height=928, num_steps=50, true_cfg_scale=4.0):
# Based on QwenLM/Qwen-Image src/examples/demo.py and generate_w_prompt_enhance.py
pipe = DiffusionPipeline.from_pretrained(model_repo_id, torch_dtype=torch.bfloat16).to("cuda")
prompt = rewrite(prompt) # optional prompt enhancement from tools/prompt_utils.py
generator = torch.Generator(device="cuda").manual_seed(seed)
images = pipe(
prompt=prompt,
negative_prompt="",
width=width,
height=height,
num_inference_steps=num_steps,
true_cfg_scale=true_cfg_scale,
generator=generator,
).images
return images@torch.no_grad()
def public_repo_edit_inference(input_image, edit_prompt, seed=42, rewrite_prompt=True,
true_guidance_scale=1.0, num_images_per_prompt=1):
# Based on QwenLM/Qwen-Image src/examples/edit_demo.py
pipe = QwenImageEditPipeline.from_pretrained(
"Qwen/Qwen-Image-Edit", torch_dtype=torch.bfloat16
).to("cuda")
prompt = polish_edit_prompt(edit_prompt, input_image) if rewrite_prompt else edit_prompt
generator = torch.Generator(device="cuda").manual_seed(seed)
return pipe(
input_image,
prompt=prompt,
negative_prompt=" ",
generator=generator,
true_cfg_scale=true_guidance_scale,
num_images_per_prompt=num_images_per_prompt,
).imagesdef paper_level_dmd_step(student, fake_score_model, teacher_score_model, condition, optimizer):
# Conceptual pseudocode from Equations (4)-(5); no released implementation found.
eps = torch.randn_like_latent(condition)
xi = torch.randn_like_latent(condition)
t = sample_logit_normal_time(batch_size=condition.size(0)).view(-1, 1, 1, 1)
x_theta = student.generate_clean_state(eps, condition)
x_t = (1 - t) * x_theta + t * xi
s_fake = fake_score_model.score(x_t, t, condition)
s_real = teacher_score_model.score(x_t, t, condition)
proxy_loss = ((s_fake - s_real).detach() * x_theta).sum()
optimizer.zero_grad()
proxy_loss.backward()
optimizer.step()
return proxy_lossdef paper_level_hybrid_cfg_grpo(prompts, policy, reward_models, optimizer):
# Conceptual pseudocode from §4.2; reward weights/configs are not released.
samples = policy.sample_with_cfg(prompts, use_cfg=True)
rewards = weighted_reward_sum(samples, prompts, reward_models)
advantages = normalize_within_prompt_group(rewards)
logprob_cond = policy.conditional_logprob(samples, prompts)
# Unconditional branch is deliberately excluded from optimization.
loss = -(advantages.detach() * logprob_cond).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss, rewards论文公式与 released code 实现差异:paper 描述了 Qwen3-VL + MMDiT + VAE、GRPO-RLHF、DMD distillation 和 Table 2 training schedule;QwenLM/Qwen-Image @ 6b5e1f5c 只公开 README announcement 与 Qwen-Image/Qwen-Image-Edit inference examples,未公开 Qwen-Image-2.0 model/training/RL/distillation 实现。因此本笔记的 code-derived pseudocode 只覆盖 inference examples,训练相关 pseudocode 明确标注为 paper-level。
Code reference:
main@6b5e1f5c(2026-02-10) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Public Qwen-Image series inference | src/examples/demo.py | GPUWorker, MultiGPUManager, infer |
| Image editing inference | src/examples/edit_demo.py | QwenImageEditPipeline.from_pretrained, infer |
| Prompt enhancement | src/examples/generate_w_prompt_enhance.py | rewrite(prompt) |
| Prompt utilities | src/examples/tools/prompt_utils.py | prompt rewrite helpers |
| Qwen-Image-2.0 training/RL/DMD | Not released | 代码搜索未找到开源实现 |
4. Experimental Setup (实验设置)
Datasets
- Generation/editing training data: T2I/TI2I mixture;paper 未给总样本数。Table 2 给出 ratios:pre-training 0.9/0.1,continual pre-training 与 SFT 均为 0.7/0.3。
- Text-rich and high-resolution data: real-world documents、slides、posters、infographics、synthetic text data、高分辨率 2048p samples;具体 sample count 未详细说明。
- VAE evaluation corpus in Table 1: ImageNet 256×256 与 internal Text 256×256 corpus,后者包括 PDFs、presentation slides、posters、synthetic paragraphs,覆盖 English 与 Chinese。
- Human preference benchmark: LMArena T2I leaderboard,accessed April 22, 2026。
Baselines
Table 1 VAE baselines 包括 SD-3.5、Cosmos-CI8x8、Wan2.1、HunyuanVideo、FLUX.1-dev、Qwen-Image、HunyuanImage-3.0、Wan2.2、Stepvideo-T2V。Qualitative baselines 包括 GPT-Image-2、NanoBanana Pro、Qwen-Image-2512、Wan2.7 Pro、Seedream 5.0 Lite。Distillation 对比是 Qwen-Image-2.0-RL 40-step teacher vs Qwen-Image-2.0-Distillation 4-NFE student。
Evaluation metrics
- LMArena ELO: blind human pairwise preference ranking。
- PSNR / SSIM: VAE reconstruction fidelity;PSNR 衡量像素误差,SSIM 衡量结构相似度。
- Qualitative criteria: text rendering correctness、portrait realism、identity preservation、instruction following、multilingual rendering、slide generation。
Training config
- Pre-training: 700K steps;resolution 256/512;batch size 32K/16K;T2I/TI2I=0.9/0.1;Adam;weight decay 0.001;grad norm clip 1.0;uncond dropout 0.1;LR 。
- Continual pre-training: 250K steps;resolution 512/1024/2048;batch size 16K/8K/4K;T2I/TI2I=0.7/0.3;LR 。
- SFT: 10K steps;resolution 512/1024/2048;batch size 16K/8K/4K;T2I/TI2I=0.7/0.3;LR 。
- Hardware: 论文未详细说明 GPU type/count;released repo 未提供训练 config。
5. Experimental Results (实验结果)

Figure 1 解读:LMArena 各能力维度显示 Qwen-Image-2.0 相比 Qwen-Image-2512 有明显提升,尤其在 photorealism 与 portrait generation 相关维度上更强。该图是全文的主结果入口,说明 2.0 不是单点能力修补,而是多个真实用户偏好维度同步提升。
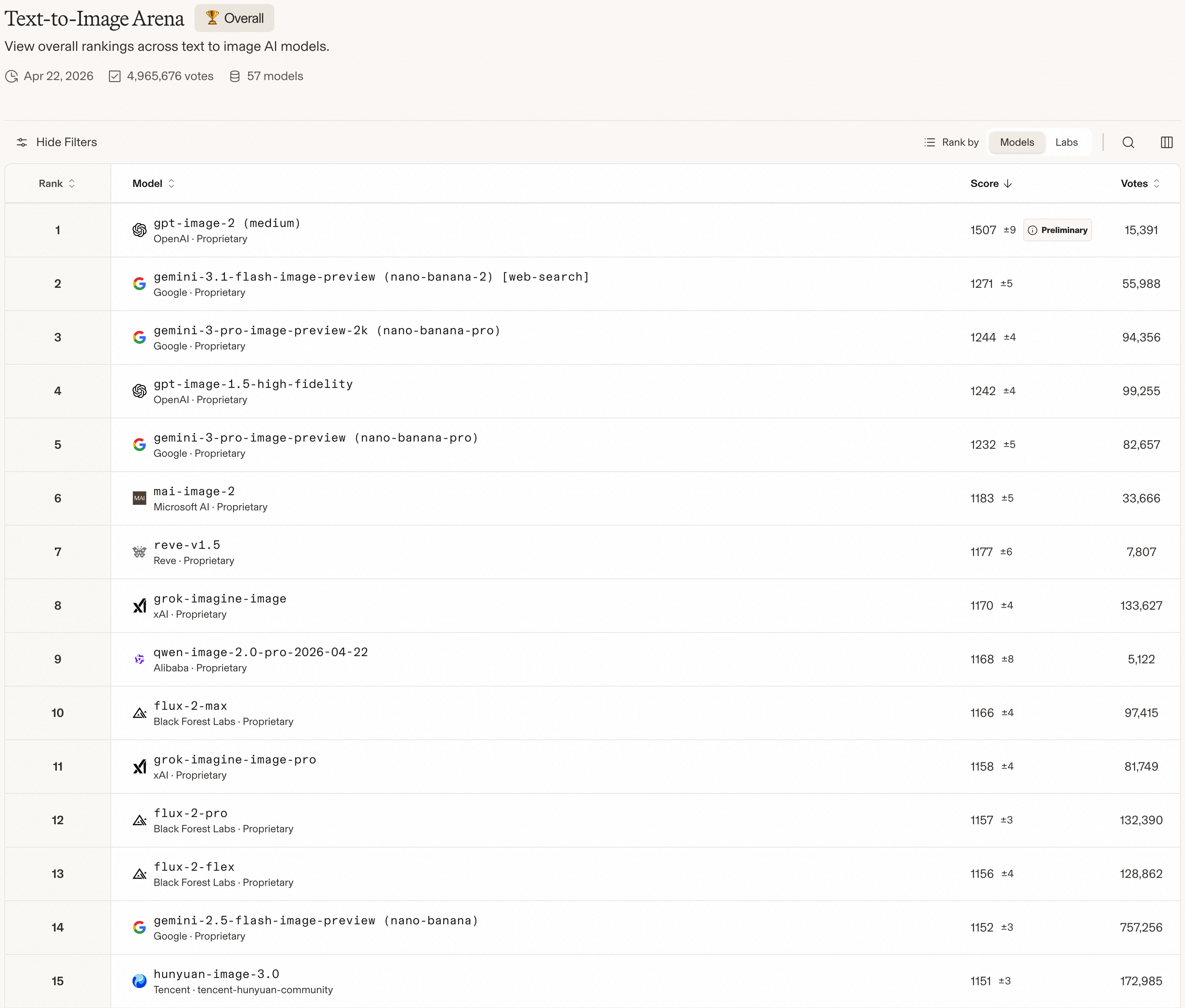
Figure 12 解读:LMArena T2I leaderboard 上,Qwen-Image-2.0 排名全球 #9、中国模型 #1,ELO score 为 1168,并超过 Nano Banana。这个结果强调其在人类偏好场景中的综合竞争力,而不是只在内部自动指标上提升。
VAE reconstruction results (Table 1)
| Model | Setting | Enc/Dec Params | ImageNet PSNR / SSIM | Text PSNR / SSIM |
|---|---|---|---|---|
| FLUX.1-dev | f8c16 | 34M / 50M | 32.84 / 0.9155 | 32.65 / 0.9792 |
| Qwen-Image | f8c16 | 54M / 73M | 33.42 / 0.9159 | 36.63 / 0.9839 |
| Stepvideo-T2V | f16c64 | 110M / 389M | 31.54 / 0.8973 | 29.62 / 0.9641 |
| Qwen-Image-2.0 | f16c64 | 79M / 259M | 33.42 / 0.9225 | 32.81 / 0.9795 |
关键结论:Qwen-Image-2.0 VAE 在 f16c64 compression 下,ImageNet SSIM 达 0.9225,高于 Qwen-Image 的 0.9159;Text 256×256 上 SSIM 达 0.9795,接近 FLUX.1-dev 的 0.9792,但在更高 spatial compression 下完成。

Figure 2 解读:photo-realistic showcase 展示模型在人物、自然场景、建筑和材质上的细节恢复。它对应 paper claim 的 native high-resolution photorealism:局部纹理、光照一致性和材质真实感更稳定。

Figure 3 解读:complex text rendering showcase 覆盖长文本、排版和复杂文字图形。它支撑论文关于 1K-token prompt、professional text-rich visual content 的核心 claim。

Figure 4 解读:image editing showcase 说明同一模型可以处理 instruction-based editing,不需要切换到独立 editing pipeline;这正是 unified generation and editing 的实验展示。

Figure 13 解读:中文 text rendering 对比中,其他模型常出现字符太小、缺字、重复、拼写错误或布局不完整;Qwen-Image-2.0 更能保持完整可读文字与整体美观。

Figure 14 解读:portrait generation 对比强调材质与文字同时约束的场景。Qwen-Image-2.0 在 signboard text、stone wall texture、lighting consistency 上更少出现过度平滑或文字 hallucination。

Figure 15 解读:另一组 portrait/scene 对比说明,模型不仅要把人脸做真实,还要遵守运动模糊、背景文字和物理一致性等细节约束;这是 instruction following 与 photorealism 的联合考验。

Figure 16 解读:复杂中文 text editing 任务中,Qwen-Image-2.0 被描述为唯一能完整渲染《黄鹤楼》古诗文本、同时保持 aesthetic quality 的模型。该结果直接对应 image editing 中的 long Chinese typography challenge。

Figure 17 解读:identity preservation 比较 single-image 和 multi-image editing。Qwen-Image-2.0 在遵循编辑指令时保持面部表情、object identity 和细粒度细节,说明 TI2I 数据与统一架构没有牺牲 reference consistency。

Figure 18 解读:multilingual rendering 可视化展示多语言文字的可读性与排版效果。它补足了只看中文或英文无法覆盖的问题:不同 writing systems 的 stroke density 和 typography rules 不同。

Figure 19 解读:slide generation 展示模型直接生成 professional presentation-like layouts 的能力,验证「从 prompt 直接生成可用 text-rich visual content」这一应用目标。
Ablation / component findings
- Data pipeline 的核心发现是 progressive filtering + resolution curriculum + T2I/TI2I ratio shift 能同时支撑 generation 与 editing。
- RLHF 的 qualitative result 显示 texture fidelity、overall realism、visual consistency 有提升,但论文未给自动指标 ablation 数字。
- Distillation 显示 4-NFE student 在视觉上接近 40-step teacher,主要收益是 inference cost 降低。
Limitations
论文未单列 limitations。可确认的边界是:训练数据总规模、GPU 硬件、reward model details、RL/DMD hyperparameters 和 Qwen-Image-2.0 训练代码未公开;很多能力以 qualitative comparisons 和 LMArena 为主,缺少针对 typography/editing 的完整自动指标表。