NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Paper: arXiv:2601.02204 Code: ByteVisionLab/NextFlow Code reference:
main@31870c2(2026-01-09)
1. Motivation (研究动机)
现有多模态系统在“理解”和“生成”之间仍然割裂:扩散模型擅长像素级生成,但缺少 LLM 式推理和 in-context learning;多模态 LLM 多数只做感知;Transfusion、BAGEL 等 AR-Diffusion 混合路线又引入离散文本/连续视觉两套表示,跨图文交错任务需要反复 re-encode。
纯自回归视觉生成也有两个硬瓶颈:第一,raster-scan next-token 会让高分辨率视觉序列长度随分辨率二次增长,论文指出 1024×1024 图像用 raster-scan AR 可能超过 10 分钟;第二,传统重建导向 VQ tokenizer 的离散码语义密度不足,理解任务和生成任务无法共用足够好的视觉表示。
本文要解决的问题是:能否用一个 decoder-only Transformer、一个统一视觉离散表示,同时激活 multimodal understanding、text-to-image、editing、interleaved generation 和 video-like interleaved 生成,并把 1024×1024 生成速度降到交互可用级别。
2. Idea (核心思想)
核心洞察:图像不是像文本那样严格一维顺序结构,而是天然层级结构;因此文本继续做 next-token prediction,视觉生成改成从粗到细的 next-scale prediction。这样把“下一 token”问题改成“下一尺度的一组视觉 token”问题,早期尺度决定全局布局,后期尺度补局部细节。
NextFlow 的本质创新不是简单把图像 token 塞进 LLM,而是把 TokenFlow 式 dual-codebook tokenizer、next-scale AR、scale reweight/self-correction、prefix-tuning GRPO 组合成一个可扩展训练配方。相比 EMU3/Chameleon 的 raster-scan AR,它直接降低高分辨率推理成本;相比 Transfusion/BAGEL 的混合扩散架构,它保留单一 decoder-only AR 目标,图文交错和 RL 可以在同一离散序列空间内完成。
3. Method (方法)
3.1 Overall framework
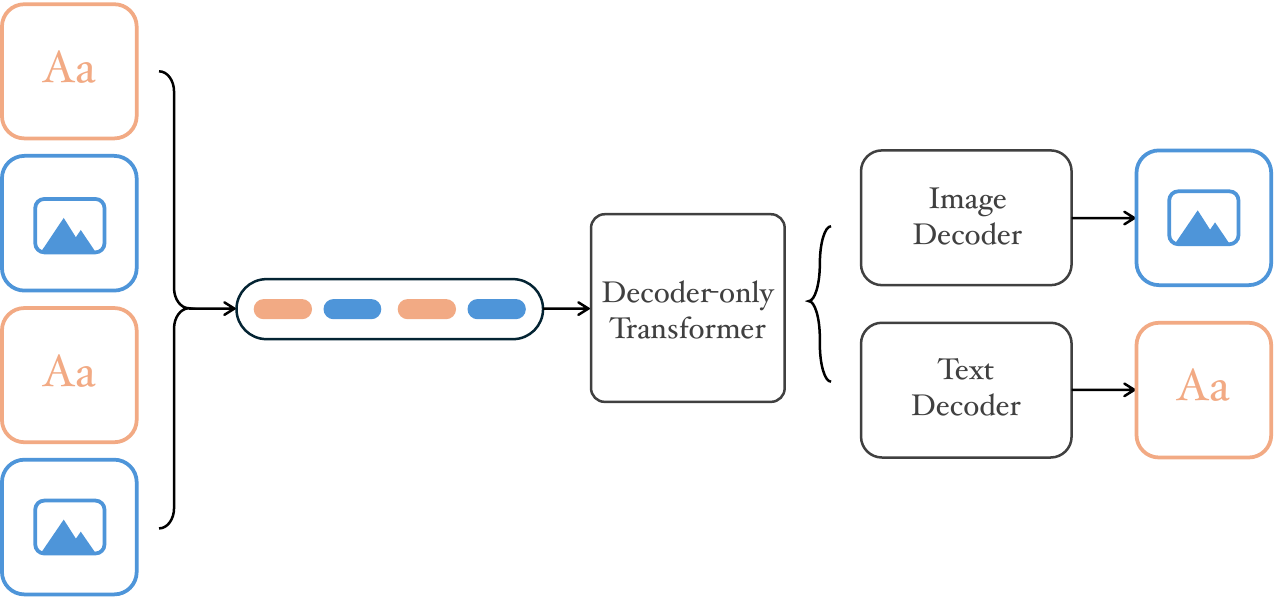
Figure 1 解读:NextFlow 把文本 token、图像边界 token 与多尺度视觉离散 token 放入同一个 decoder-only Transformer。文本仍按 next-token 训练;图像先由统一 tokenizer 编码为多尺度 codebook indices,再在 AR 过程中逐尺度预测视觉 token,输出可以是单图、编辑结果、图文交错内容或视频式连续帧。
3.2 Unified tokenizer:dual-codebook + dynamic resolution
Tokenizer 基于 TokenFlow 的 dual-codebook 设计:semantic branch 提供高层语义,pixel branch 保留细粒度重建。codebook lookup 不只最小化像素距离,而是对 semantic distance 与 pixel-level distance 做加权联合约束,使离散码同时包含语义和纹理信息。
为了支持动态分辨率,语义 encoder 从 siglip-so400m-patch14-384 升级到 siglip2-so400m-naflex-patch16,再结合 CNN pixel branch,让模型可在 native resolution/aspect ratio 上训练。论文还采用 multi-scale VQ;具体 scale schedule 放在 appendix。
3.3 Decoder-only Transformer:next-token + next-scale
主干初始化自 Qwen2.5-VL-7B,并新增视觉 codebook embedding;新增 embedding 直接用 tokenizer codebook embedding 初始化。论文比较了 shared head 与 separate heads,最终采用单一输出 head:统一 vocabulary 上用 cross-entropy 同时预测文本 token 和视觉 codebook index,结构更简单且 alignment/SFT 损失更优。
文本序列按普通自回归逐 token 预测;图像序列按尺度预测。设第 s 个尺度大小为 h_s × w_s,模型在前序文本、条件图像与更粗尺度视觉 token 条件下预测当前尺度所有 codebook indices。直觉上,早期低分辨率尺度承担 layout/semantic planning,后期高分辨率尺度承担 texture/detail refinement。
3.4 Multi-Scale 3D RoPE

Figure 3 解读:文本 token 用对角坐标,例如位置 3 映射到 [3,3,3];视觉 token 用 normalized spatial coordinates,并额外加入 scale index。这样同一 Transformer 可以区分“文本顺序位置”和“视觉尺度-二维空间位置”。论文还加入 learnable scale embedding 与 scale-length sinusoidal positional embedding,使模型知道目标输出分辨率对应的尺度路径。
3.5 Training recipe:alignment → 6T pretraining → CT/SFT → RL
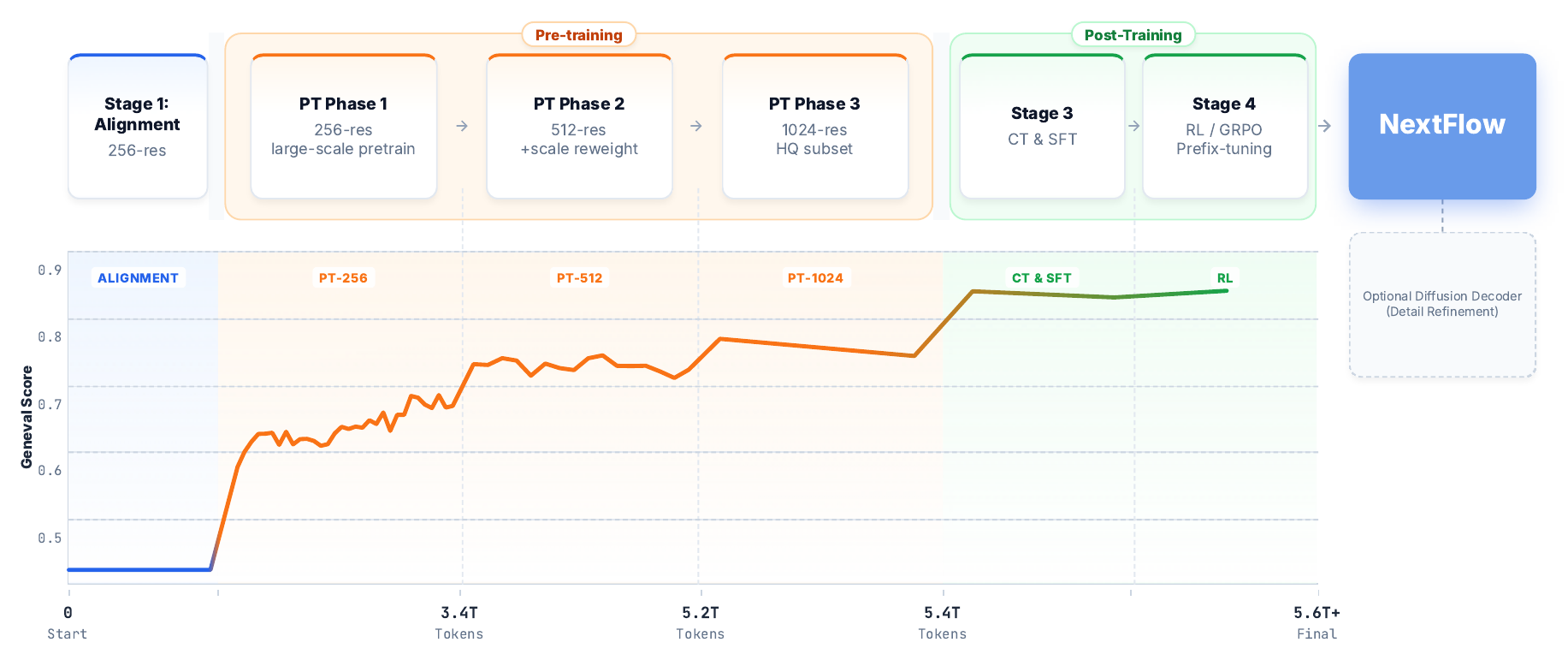
Figure 2 解读:训练不是一次性端到端完成,而是先 tokenizer 训练,再进行 Qwen2.5-VL 替换视觉 tokenizer 后的 alignment,随后按 256-level、512-level、1024-level 逐级 pretraining,最后用 CT/SFT 与 RL 提升审美、交互和偏好对齐。图中 Geneval 随累计 token 增长变化,强调 512/1024 高分辨率阶段需要额外稳定化技巧。
训练配方来自论文 Table 2,而非代码配置(公开仓库未发布训练脚本):
| Stage | Resolution | Epochs | LR | Text | T2I | I2T | Editing | Interleaved | Train tokens |
|---|---|---|---|---|---|---|---|---|---|
| Alignment | 256-level | 1 | 1e-3 | - | 5M | 5M | - | - | 0.01T |
| Pretrain | 256-level | 1 | 1e-4 | 662M | 1891M | 520M | - | 147M | 3.4T |
| Pretrain | 512-level | 1 | 1e-4 | 700M | 345M | - | 20M | 5M | 1.8T |
| Pretrain | 1024-level | 1 | 1e-4 | 47M | 10M | - | 2M | 0.5M | 0.2T |
| CT | 1024-level | 1 | 5e-5 | 47M | 9M | - | 2M | - | 0.2T |
| SFT | 1024-level | 1 | 1e-5 | 5M | 1M | - | 0.1M | - | 0.02T |
关键稳定化来自两个观察:512-level 切换后 token 数显著增加,低尺度 loss 反而上升,Geneval 从 0.67 降到 0.57;同时每个尺度内独立 top-k/top-p sampling 会引入局部冲突和 exposure bias。
3.6 Scale reweight 与 self-correction
Scale reweight 让早期粗尺度获得更大损失权重,同时保持总 vision loss 常量。论文给出的尺度权重为:
其中 是尺度 的空间分辨率, 控制重加权强度;512-level 训练中采用 。直觉是:低尺度 token 少但决定全局构图,若按 token 均匀加权,高尺度细节 token 会淹没 layout 学习信号。
Self-correction 的做法是在 tokenizer/训练输入侧不总是选最近 codebook index,而是在 top-k nearest indices 上做 multinomial sampling,同时 target 仍是 top-1 index。模型因此学习“从稍差的前一尺度选择中恢复到正确细节”。论文还发现原 VAR 的 accumulated features 在 decoder-only 架构中会放大输入空间复杂度,因此改用 residual features:每个尺度直接从 codebook 独立取特征,需要时再上采样。
3.7 Prefix-tuning GRPO
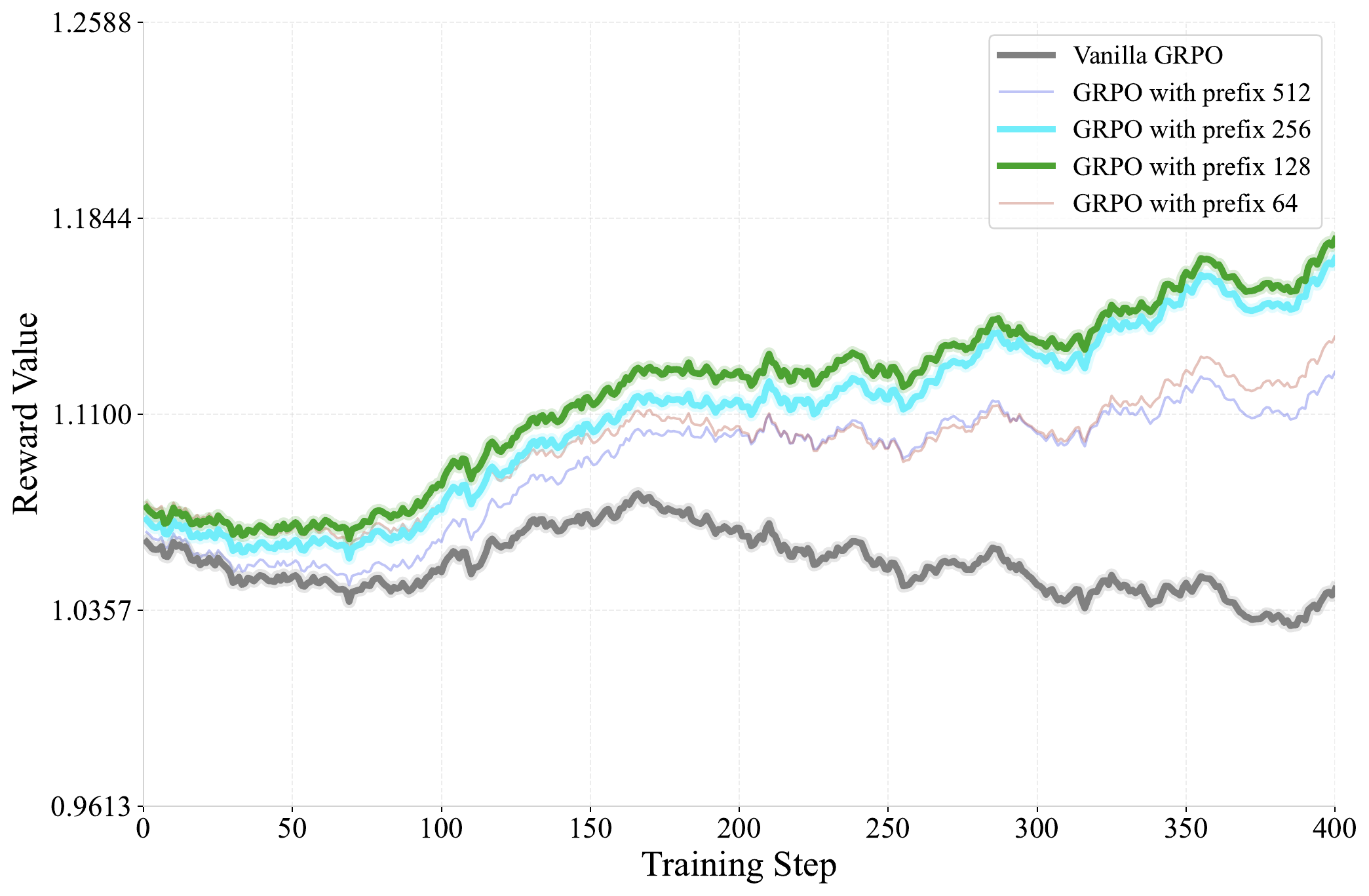
Figure 4 解读:RL 只更新前 m 个粗尺度 policy,后面的 T-m 个细尺度 policy 冻结。图像生成的高层布局在 coarse prefixes 中确定,高方差 RL 信号若直接作用到所有细尺度,会破坏预训练视觉质量;prefix-tuning 把偏好对齐集中在更语义、更结构化的阶段。
给定条件 ,采样一组图像 token 序列 并解码为图像 ,组内 advantage 为:
GRPO 目标只对 的 prefix scales 求和,并包含 clipping 与 KL 正则:
其中 。论文示例用 ,即只调前 8 个尺度。
3.8 Optional diffusion decoder
默认 VQ decoder 推理快,但离散量化会损失高频细节。可选 diffusion decoder 用 semantic embedding、pixel embedding、semantic decoder 输出的高维语义特征拼接后线性投影为视觉条件,同时文本分支注入 caption。论文探索 1B UNet、12B Transformer、18B Transformer;1B 全参微调,12B/18B 用 LoRA,并用 base resolution → 2× upsampling 的两阶段训练来增强局部细节。
3.9 Paper-level pseudocode(公开仓库未含实现代码)
公开 GitHub 仓库 ByteVisionLab/NextFlow 在 main@31870c2 只包含 README、LICENSE 与 assets/* 展示图,未发布 .py、训练脚本或配置文件。因此下面伪代码是按论文方法重建的 paper-level 伪代码,不声称逐行对应开源实现。
# 1) next-scale visual generation
@torch.no_grad()
def generate_image_tokens(model, tokenizer, text_tokens, scale_schedule, top_k, top_p):
# scale_schedule: [(h1,w1), ..., (hT,wT)], e.g. progressive coarse-to-fine grids
context = [text_tokens, BOI]
visual_by_scale = []
kv_cache = None
for s, (h, w) in enumerate(scale_schedule):
pos = multiscale_3d_rope_positions(scale=s, height=h, width=w)
logits, kv_cache = model(context, positions=pos, kv_cache=kv_cache)
# current scale tokens are sampled in parallel from the scale logits
code_ids = sample_topk_topp(logits.visual_codebook[-h * w:], top_k=top_k, top_p=top_p)
visual_by_scale.append(code_ids.reshape(h, w))
context.append(codebook_embed(code_ids, scale=s))
return tokenizer.decode_multiscale(visual_by_scale)# 2) scale-reweighted CE loss for visual codebook prediction
def scale_reweighted_loss(logits_by_scale, targets_by_scale, alpha=0.9):
losses, weights = [], []
for logits, target in zip(logits_by_scale, targets_by_scale):
h, w = target.shape[-2:]
k_s = 1.0 / ((h * w) ** alpha)
ce = F.cross_entropy(logits.flatten(0, -2), target.flatten(), reduction="mean")
losses.append(k_s * ce)
weights.append(k_s)
# keep total vision-loss scale stable
return sum(losses) / sum(weights)# 3) self-correction with residual features
class SelfCorrectionTokenizerInput(nn.Module):
def forward(self, image_features, codebook, top_k=8):
# target remains nearest code; input may use sampled near-neighbor code
dist = torch.cdist(image_features, codebook.weight)
nearest = dist.argmin(dim=-1)
candidate = dist.topk(k=top_k, largest=False).indices
sampled = candidate.gather(-1, torch.multinomial(torch.ones_like(candidate, dtype=torch.float), 1))
residual_features = codebook(sampled.squeeze(-1)) # no accumulated VAR features
return residual_features, nearest# 4) prefix-tuning GRPO over coarse scales only
for prompts in dataloader:
samples = rollout_group(policy, prompts, group_size=G)
rewards = reward_model(samples.images, prompts)
adv = (rewards - rewards.mean(dim=1, keepdim=True)) / (rewards.std(dim=1, keepdim=True) + 1e-6)
loss = 0.0
for t in range(m): # e.g. m = 8 coarse scales
ratio = policy.prob(samples.tokens[t + 1], samples.prefix[t]) / old_policy.prob(samples.tokens[t + 1], samples.prefix[t])
clipped = ratio.clamp(1 - eps, 1 + eps)
loss += scale_weight[t] * torch.min(ratio * adv, clipped * adv).mean()
loss = -loss + beta * kl(policy, ref_policy, samples.prefix[:m])
loss.backward()
optimizer.step()3.10 Code mapping
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Official project metadata / public code search target | README.md | README-only description of architecture, training, benchmarks |
| Framework illustration | assets/framework.jpg | figure asset only |
| Training pipeline illustration | assets/training_pipeline.jpg | figure asset only |
| Implementation code | 论文未详细说明;GitHub repo at main@31870c2 contains no source implementation | Not released |
| Training config / launch scripts | 论文未详细说明;repo contains no configs/, scripts/, .py, or .yaml implementation files | Not released |
4. Experimental Setup (实验设置)
Datasets. 预训练覆盖 text、image-text pairs、editing、interleaved multimodal data,总计约 6T tokens。视觉理解数据来自开源 image-text 数据并补充 OCR/文档/世界知识图像,caption 经 VLM 重写。T2I 数据是 billion-scale,来源包括开源数据、Megalith、CommonCatalog 与内部图库,经 heuristic filters、aesthetic model、SigLIP2 zero-shot topic classifier 重采样,并用 VLM 生成详细 caption。编辑数据分 traditional editing 与 subject-driven generation:传统编辑从 UniWorld-V1、RealEdit、ShareGPT-4o-Image 过滤后再合成补齐长尾任务;subject-driven 用互联网共现图像和 VLM 匹配同主体图像对。Interleaved generation 使用 OmniCorpus-CC、OmniCorpus-YT、Koala36M 等 video-text 数据,把 clip 视为图文交错帧序列,并过滤 >20s、低美学、低清晰度和低 motion 样本。
Baselines. 图像生成比较 SDXL、DALL-E 3、SD3、FLUX.1-dev、GPT Image 1、HiDream、Seedream 3.0、Qwen-Image、TokenFlow-XL、Emu3-Gen、Janus-Pro-7B、EMU3.5、NextStep-1 等;编辑比较 GPT Image 1、Qwen-Image、Emu3.5、BAGEL、HiDream、OmniGen2、Flux Kontext、Step1X-Edit 等;理解比较 LLaVA-1.5 与不同 SFT 数据规模的 NextFlow。
Metrics. 文生图使用 GenEval、DPG、WISE、PRISM;编辑使用 ImgEdit、OmniContext、GEdit-Bench、EditCanvas;重建使用 PSNR/SSIM;多模态理解使用 MMStar、ChartQA、OCRBench、MME、MME-P、MMB、MMMU、TextVQA;效率用 per-GPU throughput 与 1024² 推理 FLOPs 分析。
Training config. 公开仓库未提供 launch config;可记录的训练超参来自论文 Table 2:alignment 用 10M bidirectional image-text pairs、256-level、LR 1e-3;pretraining 256/512/1024-level 对应 3.4T/1.8T/0.2T tokens、LR 1e-4;CT 用 1024-level、LR 5e-5、0.2T tokens;SFT 用 1024-level、LR 1e-5、0.02T tokens。512-level scale reweight 采用 ;RL prefix-tuning 示例更新前 个尺度。
5. Experimental Results (实验结果)

Figure 5 解读:该图对比有无 reasoning 的 text-to-image 生成。NextFlow 的 decoder-only 统一序列建模使其可以先生成/利用文本推理步骤,再生成图像;这类“Thinking with Images”能力是混合扩散系统较难直接统一优化的部分。
Text-to-image. GenEval 上,NextFlow† 为 0.83,NextFlow-RL† 为 0.84;论文正文还报告 NextFlow-RL 在 DPG 上达到 88.32。WISE 上 NextFlow-RL 的 Cultural/Time/Space/Bio/Phys/Chem/Overall 分别为 0.63/0.63/0.77/0.58/0.67/0.39/0.62,整体追平 Qwen-Image 的 0.62。PRISM 上 NextFlow-RL 的 Imag./Entity/Text Rend./Style/Affect./Comp./Long Text/Overall 为 87.1/79.3/49.8/83.8/88.8/90.5/72.4/78.8。
Image editing. ImgEdit 上 NextFlow-RL overall 4.49,高于 Qwen-Image 4.27 与 Emu3.5 4.41;GEdit-Bench 上 NextFlow-RL 的 G_SC/G_PQ/G_O 为 8.37/8.10/7.87,高于 Qwen-Image 8.00/7.86/7.56 与 Emu3.5 8.11/7.70/7.59。EditCanvas 上 NextFlow-RL overall 8.04,NextFlow 为 7.93;GPT-Image-1 仍有 8.67,说明专门或闭源强模型在该 benchmark 上仍更强。
Interleaved / CoT / in-context. 论文定性展示了 interleaved image-text generation、CoT prompt refinement 和 in-context editing:统一 AR 结构不需要在理解/生成之间 re-encode,天然支持把前面的图文示例作为上下文并迁移编辑模式。
Image reconstruction. 相比 Original TokenFlow,NextFlow tokenizer 在 ImageNet 512² 上 PSNR/SSIM 从 23.147/0.761 提升到 25.228/0.820;1024² 为 27.410/0.884。内部 benchmark 上,Original TokenFlow 512² 为 23.320/0.760,NextFlow 512² 为 26.472/0.870,1024² 为 28.038/0.900。
Multimodal understanding. 只用 0.7M LLaVA-1.5 SFT 数据时,NextFlow 7B 在 MMStar 上 44.0,高于 LLaVA-1.5 13B 的 36.7,但 TextVQA 49.5 低于 LLaVA-1.5 的 61.3。扩大到 40M composite data 后,NextFlow 7B 达到 MMStar 53.0、ChartQA 57.7、OCRBench 55.1、MME 1897.7、MMB 66.7、MMMU 37.1、TextVQA 58.9,说明统一生成模型也可通过更高质量理解数据提升 VLM benchmarks。
Efficiency and ablations. 512-level pretraining 的 packing 对比显示:Batch Padding 620.3 tokens/s/GPU;Fixed Length Packing 2109.5(3.4×);Fixed computation budget packing 2517.4(4.1×)。Appendix FLOPs 分析中,1024² MMDiT 约为 ,NextFlow 约为 ,论文概括为约 6× 更少 FLOPs。文本混入消融显示 25% text 在 24M/36M iter 时 Geneval 从 0.384/0.441 提升到 0.404/0.454,但 48M 时为 0.499,略低于 pure T2I 的 0.505。
Limitations. 作者明确指出:离散 VQ 仍存在相对连续 latent 的信息瓶颈,高保真细节有时需要可选 diffusion decoder;同时在共享参数空间里平衡 text generation 与 visual synthesis 仍困难,低参数量模型尤其明显。未来方向包括更密集高质量理解数据、MoE 扩容、下一代 tokenizer,以及原生 multimodal CoT + unified RL。