Context Unrolling in Omni Models
1. Motivation (研究动机)
Omni 要解决的是当前”统一多模态模型”普遍只做能力聚合、却没有建立起跨模态推理机制这一结构性缺陷。
-
现有方法的问题:现今的 unified multimodal 模型(BAGEL、Emu3.5、AnyGPT、4M、UniVAL、Ming-Omni 等)把多个模态塞进一个共享的 backbone,更多只做到了”multi-task container”——在一个网络里同时支持 understanding、image gen、edit,但各任务彼此独立,预测一般是直接的 映射。这种做法有两个明显短板:
- 单模态输出忽略了其他模态携带的互补信息。例如做 T2I 生成时如果只依赖 text prompt,GenEval-2 上的 compositionality 分数会在 prompt 复杂度上升时急剧下滑(Omni baseline 在 GenEval-2 上只有 29.25 分,短 text thinking 加进来即提升到 37.35)。
- 空间/几何推理能力严重不足。纯 text-only CoT 做 3D spatial 问题时,对 viewpoint 变换、遮挡等几何歧义束手无策(MMSI-Bench 上 Omni 直接预测只有 27.14 分;Motion 类别甚至是 0.0)。
-
论文要解决的问题:提出 Context Unrolling 这一显式的推理机制——让 unified model 在产生最终输出之前,主动调用若干原子原语(atomic primitives),把它们产生的中间结果(text CoT、visual tokens、camera pose、novel views、depth map)作为异构 context 写入共享 workspace,再基于这个扩展后的 context 做条件推理。同时配套发布 Omni——一个原生训练在 text/image/video/3D geometry/hidden representation 上的 MoE 统一模型(3B active parameters),证明 context unrolling 可以作为涌现能力被利用。
-
为什么值得研究:Context Unrolling 统一了两条以往并行发展的思路:multimodal CoT(文本链式思维)和 chain-of-visual-tokens(视觉展开)。它把 unification 从”多任务共用骨干”升级为**“多模态原子能力的可组合推理系统”**,为未来 RL 训练(学习何时/如何构建 context)、world model、multimodal agent 都打开了接口。作者以 GenEval-2 / MMSI-Bench / depth estimation 等多个基准为证据显示:同样的模型权重,通过给定更多 context,性能可以从 29.25 涨到 53.44(GenEval-2),从 27.14 涨到 34.17(MMSI),深度 δ₁ 从 83.21% 涨到 84.01%。
2. Idea (核心思想)
核心洞察:一个 unified multimodal model 的真正价值不是把 understanding/generation/3D 打包进同一个 backbone,而是让每种能力变成一个可被调用、可被组合、可被写回 context 的原子 primitive,从而把”直接推理”升级为”上下文构造后再推理”(context-conditioned inference)。
形式化地,作者把推理建模为两阶段——迭代的 context 构造 + context 条件解码(论文 Eq. 1):
其中 是多模态输入, 是某种原子原语(如 “describe”、“predict pose”、“roll out visual tokens”、“synthesize novel view”、“estimate depth”), 是 context composition, 是 T 步展开后的终态 context,最后由解码函数 基于 产生输出 。
与现有方法的根本区别:
- 与 BAGEL(Omni 的直接前身)相比:BAGEL 把 understanding/gen/edit 放在同一个 MoT 架构里共享 backbone,支持 “think before generation”;Omni 则把训练模态扩展到 3D geometry(camera pose、depth)和 hidden representation,并把 context 构造本身当成一个可度量的能力轴——在 4 类任务上分别做 context ablation(baseline vs +thinking vs +textual context vs +visual context),验证 context 长度和结构的贡献远大于单纯的参数共享。
- 与 Emu3.5/Ming-Omni/AnyGPT 这类 “tokenize everything” 的 autoregressive 统一模型相比:它们把多模态塞进同一 token 序列,但从不显式建立”先产生中间模态、再产生最终答案”的 pipeline;Omni 通过 chain-of-thought 风格的 rollout 显式让 text-thinking、depth-caption、novel-view-synthesis 成为可插拔的 intermediate context。
- 与 Qwen3-VL/InternVL3.5 这类 VLM 相比:VLM 主要是 I→T 的单向理解模型,做不了 visual rollout;Omni 在相近参数规模(3B active)下能够兼顾 VLM 级的理解能力(AI2D 91.5、DocVQA 92.8)和专家级的生成能力(GenEval-2 54.12 超过 Z-Image 41.83)和 3D 几何能力(RealEstate10K pose AUC@30 达到 88.32,打平 VGGT 的 88.23)。
3. Method (方法)
3.1 Overall framework(整体框架)
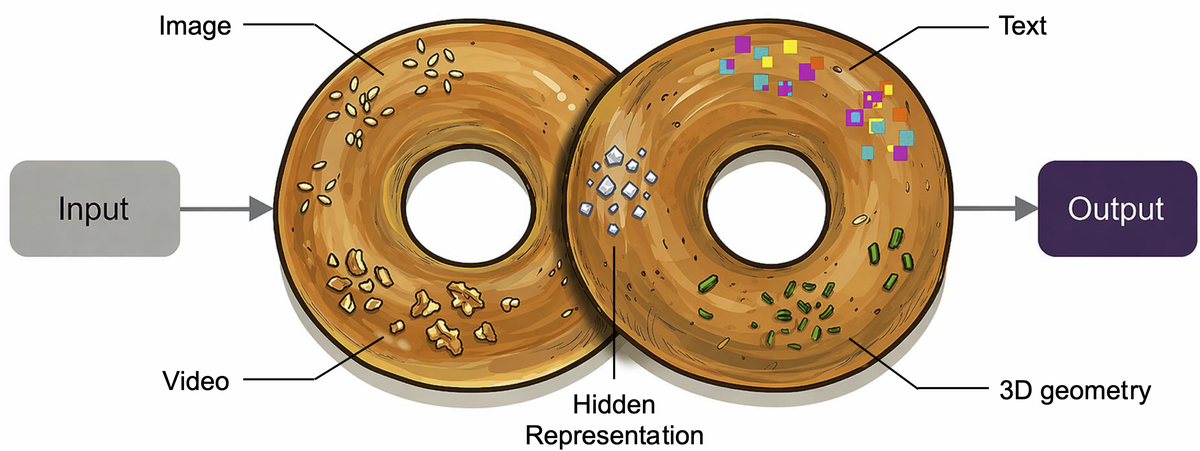
Figure 1 解读:图像化比喻——Omni 是一个”双贝果”结构:左侧贝果代表输入端包含 Image、Video 两大原始模态;右侧贝果代表输出端包含 Text、3D geometry 等结构化模态;连接两者的中间枢纽是”Hidden Representation”——这是 Omni 独有的latent reasoning space,用来承载跨模态的潜变量推理。整个模型把所有这些模态统一成一个原生多模态训练目标(natively trained),任务-agnostic 地学习 shared multimodal knowledge manifold。
Omni 的架构沿用 BAGEL 的设计哲学——Mixture-of-Transformer-Experts (MoE),但在以下几个维度做了扩展:
| 维度 | BAGEL | Omni |
|---|---|---|
| 激活参数 | 7B active / 14B total | 3B active(MoE) |
| 训练模态 | text + image | text + image + video + 3D geometry + hidden representation |
| 能力范围 | und, gen, edit(单图场景) | + video gen/edit, 3D pose/depth, spatial reasoning |
| Context types | text CoT | text CoT + visual tokens + depth caption + camera pose + novel view synthesis |
| 推理方式 | 直接预测 or text-think 预测 | Context Unrolling: |
训练数据在 BAGEL 的 interleaved image-text 基础上加入reasoning-oriented multimodal content(长结构化描述、dense attributes、spatial grounding、depth maps、camera transformations),并引入 hidden reasoning space 作为专门的 latent 推理空间。
3.2 Key components(关键组件:4 个原子原语在 4 个任务上的效果)
Omni 的核心贡献是把 context unrolling 机制在四个不同任务上做了详细的逐级消融,每一个 ablation 都直接量化了每种 context primitive 对最终指标的贡献。
3.2.1 Visual Understanding — Text CoT as Context
对一个标准的 VLM 任务,允许模型先做 text-thinking(spontaneous CoT-style text rollout)再作答:
Table 1 (downsampled 理解 benchmark):
| Context | BLINK↑ | MMStar↑ | MMBench-V11↑ | SimpleVQA↑ | AI2D↑ | Chartqa↑ | Docvqa↑ | HallusionBench↑ | Erqa↑ | MMSI↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| Omni (direct) | 60.8 | 59.4 | 76.2 | 50.4 | 90.2 | 85.5 | 93.5 | 69.6 | 41.5 | 31.5 |
| + thinking | 61.6 | 66.5 | 77.1 | 51.4 | 92.3 | 88.0 | 94.0 | 71.3 | 44.5 | 32.6 |
直觉:text-think 在 composition reasoning 最重要的 MMStar 上提升 +7.1 分、Chartqa +2.5、Erqa +3.0——CoT 并不是”装饰性文字”,它通过显式的 fine-grained 语义分解降低了推理歧义。但对 OCR-heavy 的 DocVQA,thinking 只带来 +0.5,说明 context 的贡献取决于任务是否有 composition 不确定性。
3.2.2 Visual Generation — Text + Visual Tokens as Context
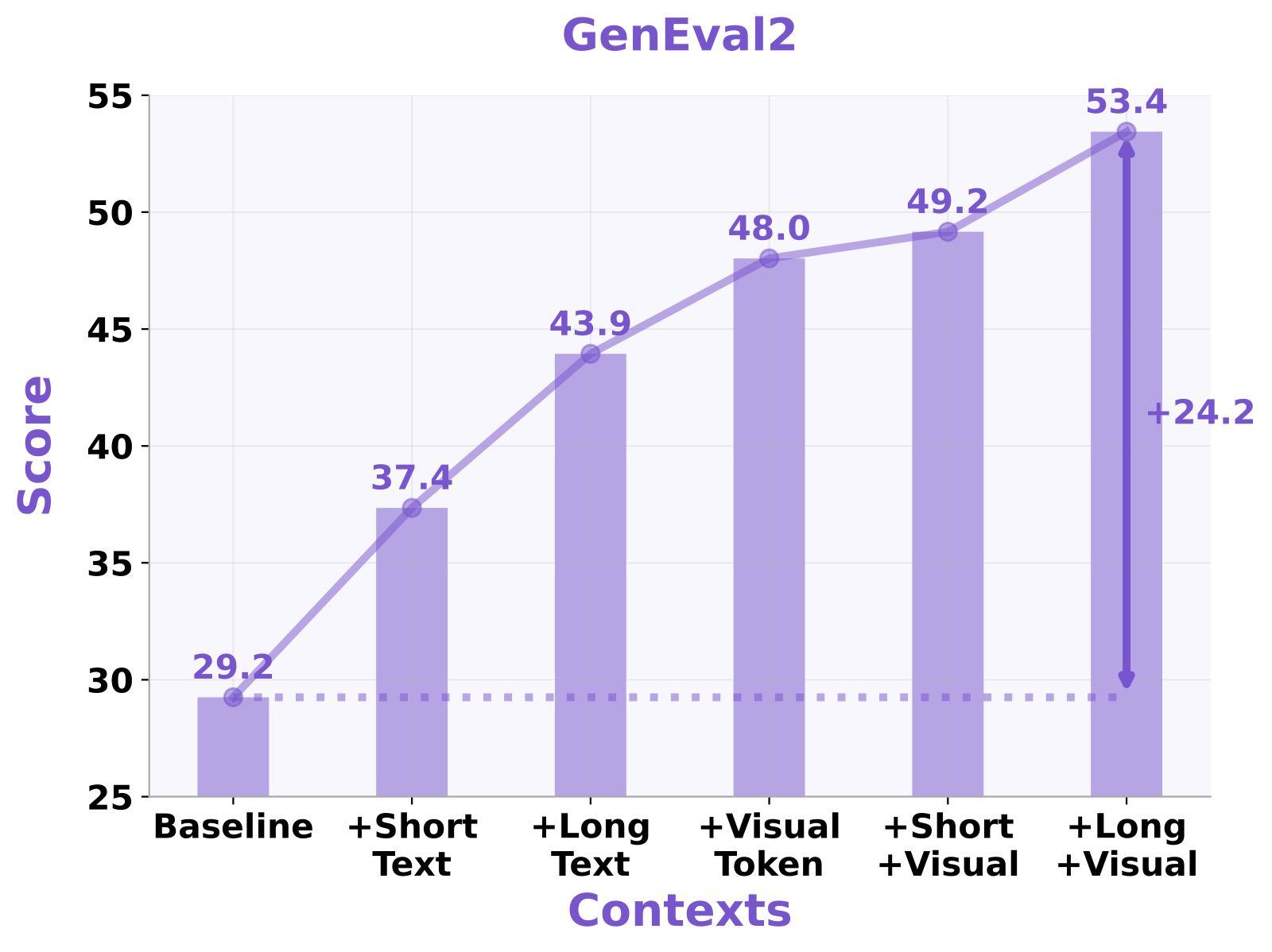
GenEval2 解读:横轴是 context 类型的累加(Baseline → +Short Text → +Long Text → +Visual Token → +Short+Visual → +Long+Visual),纵轴是 GenEval2 总分。从 29.2 一路涨到 53.4,单点总增益 +24.2 分。关键观察:纯 text(+37.4 / +43.9)与纯 visual token(+48.0)已经各有可观贡献,而二者组合(+Long+Visual = 53.4)最强——说明textual 和 visual context 提供的是非冗余的、互补的约束。
Table 2 (GenEval-2 主结果):
| Context | TIFAGM | Object | Attribute | Count | Position | Verb |
|---|---|---|---|---|---|---|
| Omni | 29.25 | 91.64 | 90.00 | 52.03 | 77.67 | 26.25 |
| + short text | 37.35 | 93.18 | 92.45 | 60.14 | 76.92 | 38.83 |
| + long text | 43.94 | 91.86 | 91.13 | 67.03 | 77.03 | 38.31 |
| + visual | 48.02 | 94.42 | 92.96 | 66.92 | 79.28 | 53.96 |
| + short + visual | 49.16 | 93.13 | 92.68 | 68.36 | 76.83 | 43.34 |
| + long + visual | 53.44 | 92.34 | 92.32 | 72.98 | 80.23 | 42.81 |
| + oracle text (Gemini-3 Pro) | 52.20 | 95.72 | 87.35 | 67.91 | 91.69 | 43.31 |
| + oracle text + visual | 57.21 | 94.77 | 97.89 | 69.47 | 90.64 | 56.00 |
Atomicity 子表(inhouse evaluation,衡量不同 compositional 复杂度下的鲁棒性):
| Context | Overall | Object | Attribute | Relation |
|---|---|---|---|---|
| Omni | 0.56 | 0.60 | 0.58 | 0.53 |
| + short | 0.59 | 0.68 | 0.61 | 0.58 |
| + long | 0.61 | 0.72 | 0.64 | 0.57 |
| + visual | 0.61 | 0.70 | 0.65 | 0.62 |
| + short + visual | 0.64 | 0.74 | 0.65 | 0.62 |
| + long + visual | 0.66 | 0.74 | 0.69 | 0.64 |
| + oracle | 0.71 | 0.75 | 0.73 | 0.74 |
| + oracle + visual | 0.73 | 0.79 | 0.76 | 0.73 |
重要发现:
- Oracle 上限分析:当把 textual context 换成 Gemini-3 Pro 产生的高质量 rewrite,TIFAGM 直接到 52.20;再加 self-rollout 的 visual tokens 继续升到 57.21。即使在 oracle text 已经非常强的情况下,visual token context 仍然贡献 +5.0 分,证明两者的正交性。
- Atomicity under compositional stress:在复杂度更高的 atomicity 测试中(prompt 要求多个原子约束),Overall atomicity 从 baseline 的 0.56 单调升到 +long + visual 的 0.66;若使用 Gemini-3 Pro oracle text 再叠加 visual tokens,继续涨到 0.73。Relation 子项增益最显著(0.53 → 0.64 → 0.73),说明 context unrolling 对空间/语义关系约束最敏感。
做法:short thinking 平均消耗 100 tokens,long thinking 消耗 250 tokens;visual tokens 是 Omni 自己 rollout 的 discrete visual tokens,携带显式的结构/布局信号。
3.2.3 Spatial Understanding — Geometry as Context
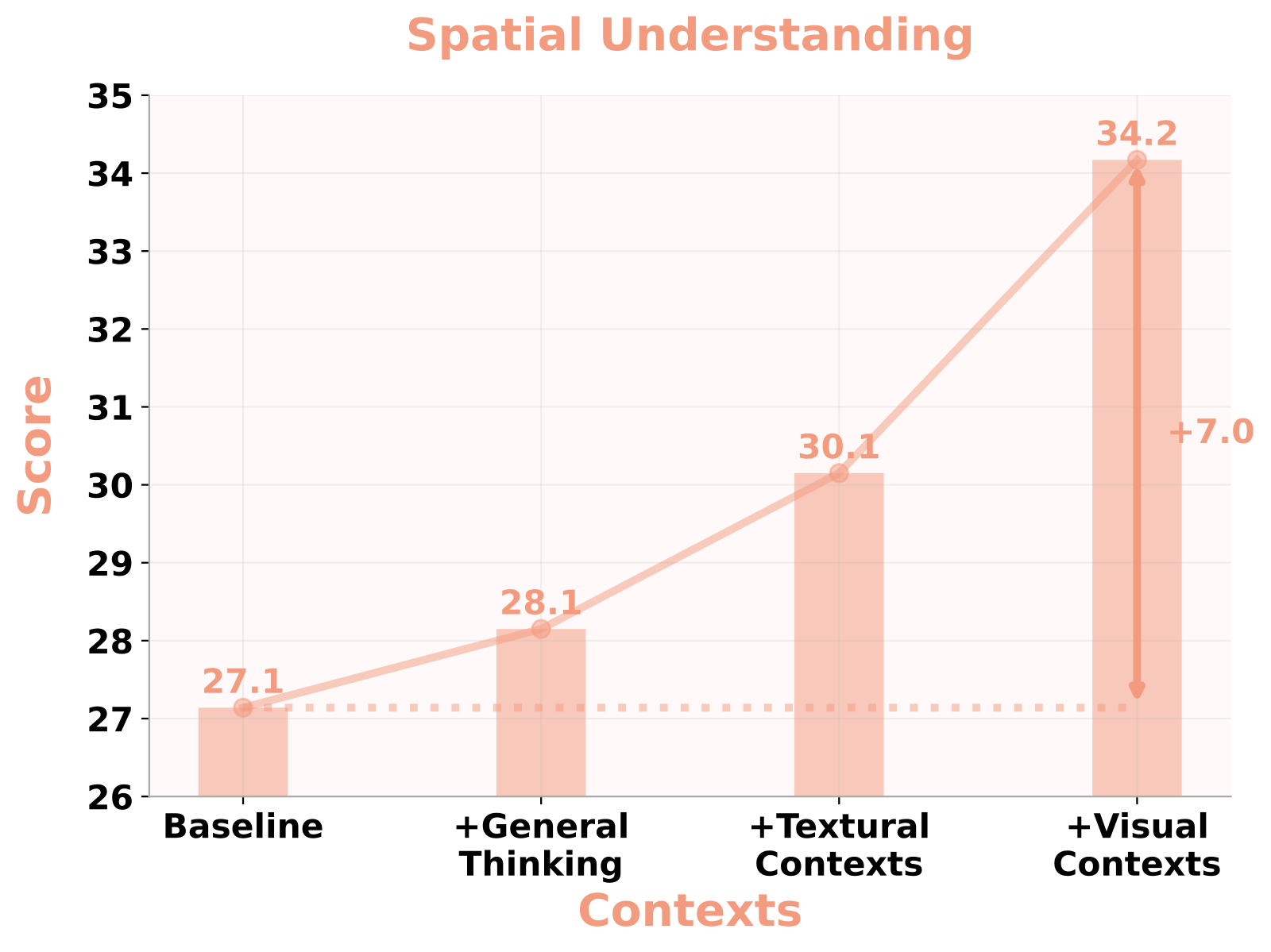
Figure (mmsi) 解读:MMSI spatial understanding 得分随 context 增强的单调上升。Baseline 27.1 → +General Thinking 28.1 → +Textual Contexts(camera pose)30.1 → +Visual Contexts(novel view synthesis)34.2。从 textual 到 visual 的一跳单独贡献 +4.1 分,是所有阶段里单步收益最大的。
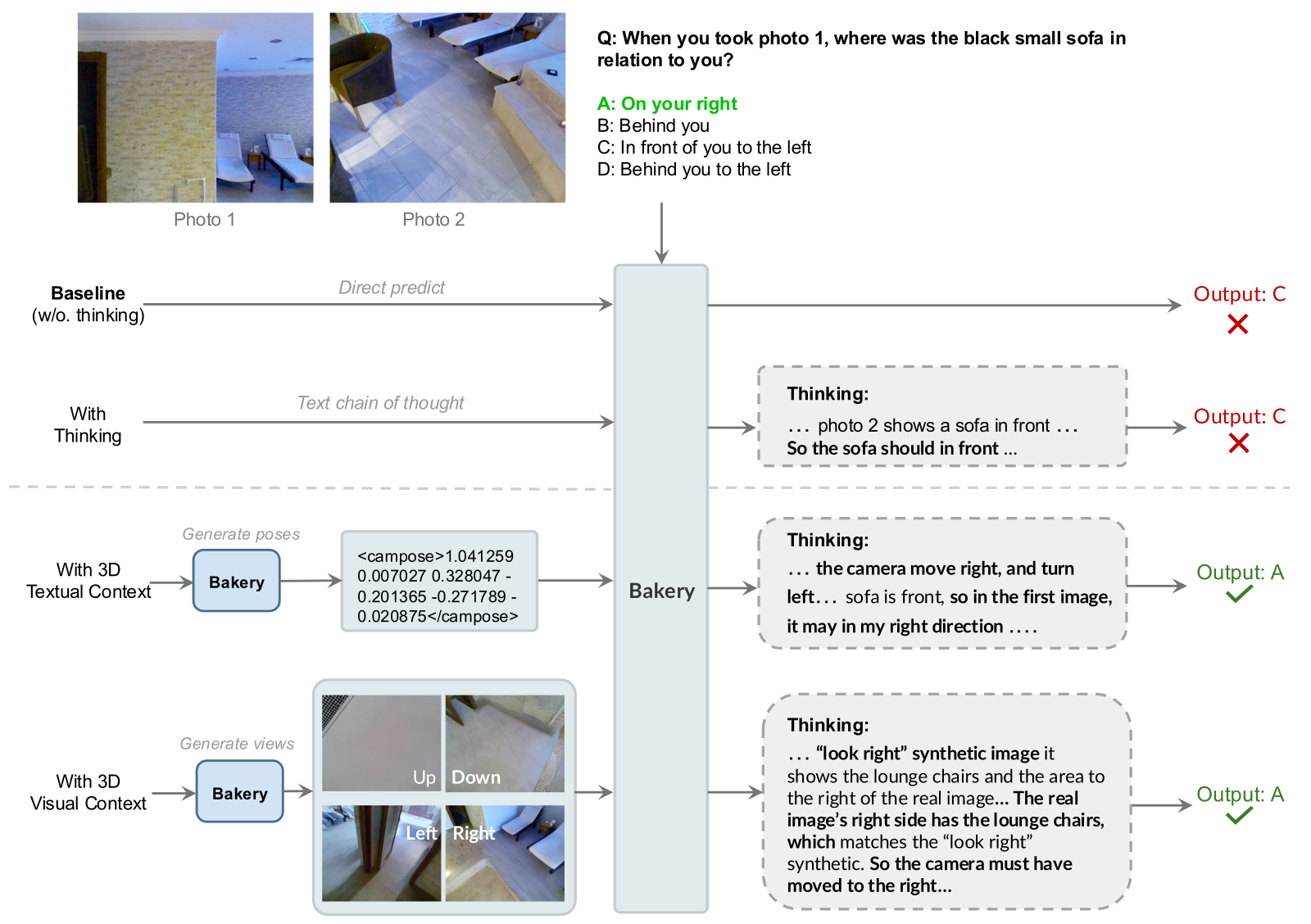
Figure 3 解读:给定两张室内照片和问题”拍 photo1 时,黑色小沙发相对于我在哪里?“(正确答案 A: On your right),展示 4 种推理路径:
- Baseline(direct predict):错答 C
- With Thinking(text CoT):推理说 “photo 2 shows a sofa in front…” 最终仍错答 C——纯文本 CoT 无法解决视角变换歧义
- With 3D Textual Context(relative camera pose):先调用 “Bakery” 原语生成
<campose>1.041259 0.007027 0.328047 -0.201365 -0.271789 -0.020875</campose>相机相对运动,再 CoT “camera move right and turn left, so in the first image, it may in my right direction…” → 正确答 A - With 3D Visual Context(NVS):调用”Bakery”从 photo1 合成 Up/Down/Left/Right 四个方向的 novel views,CoT 基于“‘look right’ synthetic image shows the lounge chairs matching the real photo2’s right side” → 正确答 A
两种 3D context 都能把 baseline 失败的 case 救回来——几何信息通过文本(pose)或视觉(synthesized view)两种形式注入都有效,但 visual context 更强(34.17 vs 30.15)。
Table 3 (MMSI-Bench 200 题子集):
| Context | Overall | MSR | Motion | Positional Relationship |
|---|---|---|---|---|
| Omni | 27.14 | 17.65 | 0.0 | 19.63 |
| + thinking | 28.15 | 17.65 | 33.33 | 30.25 |
| + textural contexts (camera pose) | 30.15 | 11.76 | 33.33 | 33.95 |
| + visual contexts (novel views) | 34.17 | 26.47 | 33.33 | 35.80 |
3.2.4 3D Geometry — Depth Caption + Visual Tokens as Context
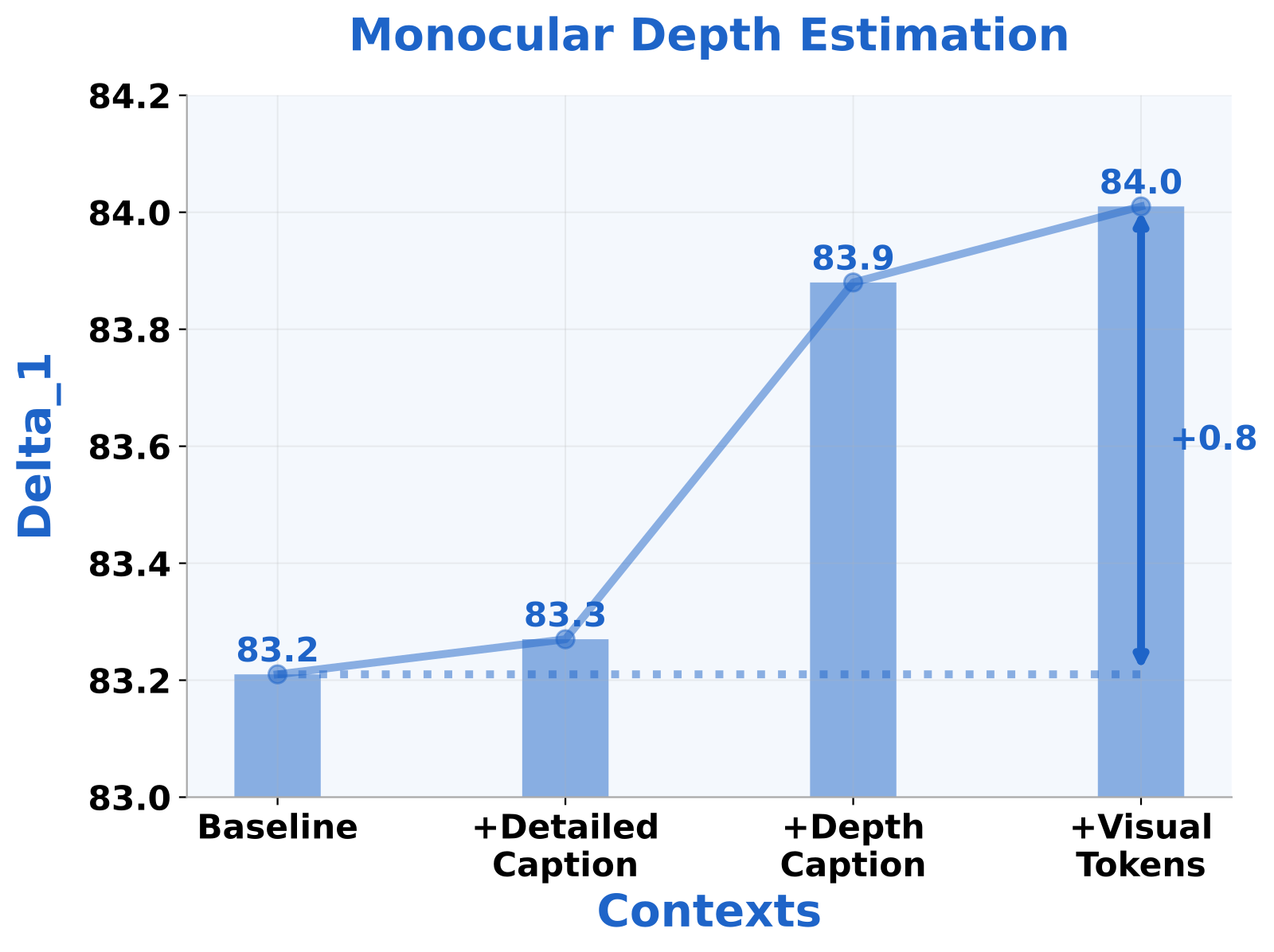
Figure (depth) 解读:δ₁ accuracy 从 83.2(baseline) → 83.3(+detailed caption,几乎无增益) → 83.9(+depth caption) → 84.0(+visual tokens)。注意 detailed caption(通用描述)不能帮到深度估计,只有task-relevant 的 “depth caption”(关注前后顺序、遮挡、支撑关系等空间线索)才有效。
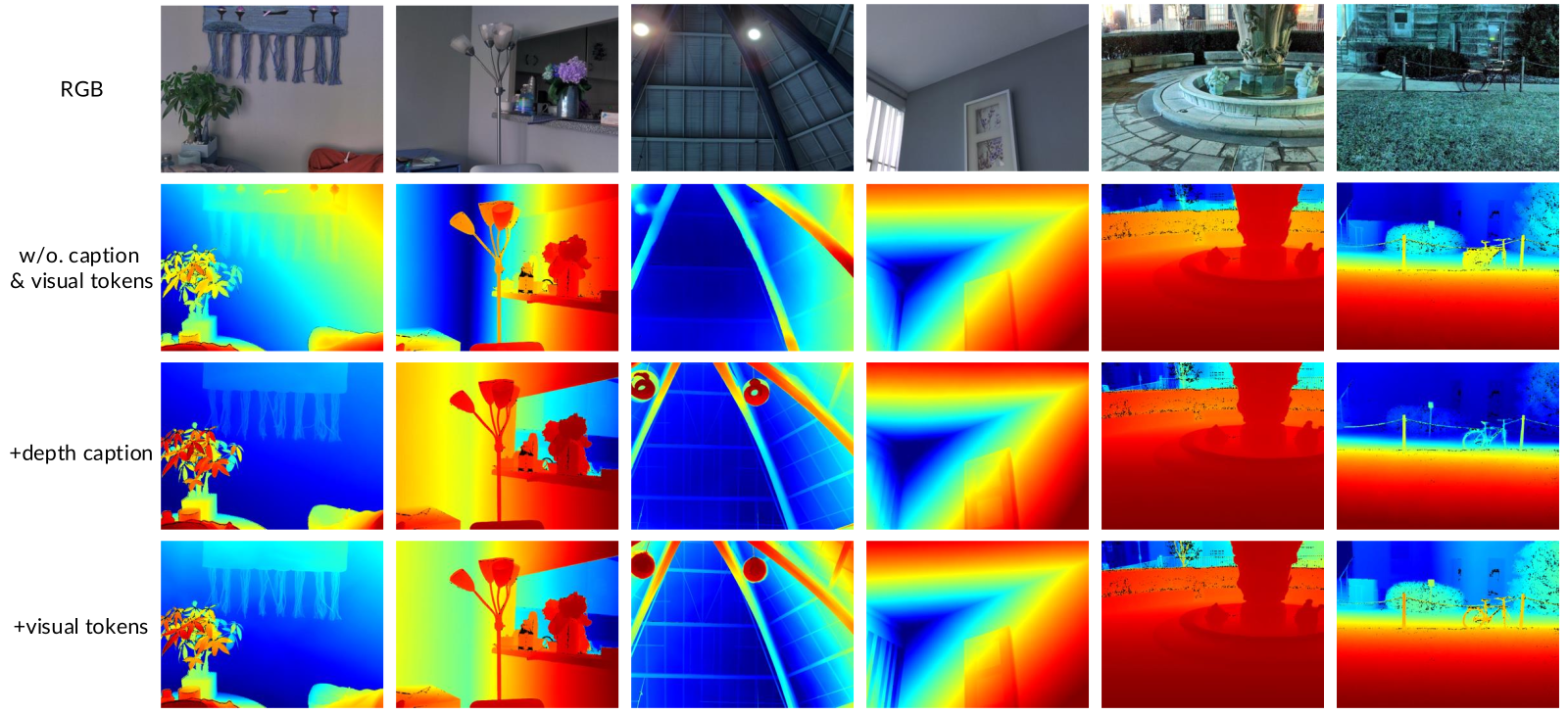
Figure 4 解读:每一列展示一张 RGB 输入下的深度估计对比。第二行 “w/o. caption & visual tokens” 的 baseline 错估植物叶片(第一列)、遗漏天花板灯(第三列);第三行 “+depth caption” 帮助识别物体但仍然把灯光面和灯具误放在同一深度;第四行 “+visual tokens” 进一步分辨墙面前后关系,把照亮区域正确归到墙面深度。
Table 4:
| Context | δ1↑ | AbsRel↓ |
|---|---|---|
| Omni | 83.21% | 0.2028 |
| + detailed caption | 83.27% | 0.2029 |
| + depth caption | 83.88% | 0.1988 |
| + visual contexts | 84.01% | 0.1970 |
关键教训:context unrolling 最有效时,context 必须task-relevant、constraint-like,而不是”啰嗦的描述”。verbose 不等于 useful。
3.3 Key formulas 总览
| 机制 | 公式 | 作用 |
|---|---|---|
| Context Unrolling 迭代 | 逐步累积 context | |
| Context-conditioned decoding | 最终输出基于终态 context | |
| Depth formulation | 深度估计从 I→D 直接映射变成 context 条件推理 |
3.4 Pseudocode(伪代码)
关于代码可用性:Omni 本身尚未单独开源(截至论文发布仅为 Seed 内部 technical report),但作者明确声明 “following the design philosophy of BAGEL”;BAGEL 完整开源在 ByteDance-Seed/BAGEL。以下伪代码主体参考 BAGEL 的结构,Omni 扩展部分(3D geometry context、visual token rollout、hidden reasoning space)按论文描述补全。
Context Unrolling 推理主循环(基于论文 Eq. 1 的具体实现):
import torch
import torch.nn as nn
class OmniContextUnroller:
"""Implements C_{t+1} = C_t ⊕ φ_t(x, C_t) then y = ψ(x | C_T)."""
def __init__(self, model, primitives: dict, tokenizer):
self.model = model
self.primitives = primitives
self.tokenizer = tokenizer
def unroll(self, x: dict, task: str, max_steps: int = 4):
"""
x: multimodal input dict, e.g., {"image": [...], "question": "..."}
task: 'understanding' | 'generation' | 'spatial' | 'depth'
Returns: final output y
"""
context = {"text": [], "visual": [], "pose": None, "views": None,
"depth_caption": None}
plan = self._plan_for_task(task, x)
for t, phi_name in enumerate(plan[:max_steps]):
phi = self.primitives[phi_name]
result = phi(x, context, self.model)
context = self._compose(context, phi_name, result)
y = self._decode(x, context)
return y, context
def _plan_for_task(self, task, x):
"""Omni's heuristic context schedule per paper Section 2."""
if task == "understanding":
return ["text_think"]
elif task == "generation":
return ["text_think_long", "visual_token_rollout"]
elif task == "spatial":
return ["camera_pose_estimate", "novel_view_synthesis", "text_think"]
elif task == "depth":
return ["depth_caption", "visual_token_rollout"]
else:
raise ValueError(f"Unknown task: {task}")
def _compose(self, context, phi_name, result):
if phi_name in ("text_think", "text_think_long", "depth_caption"):
context["text"].append(result)
elif phi_name == "visual_token_rollout":
context["visual"].append(result)
elif phi_name == "camera_pose_estimate":
context["pose"] = result
context["text"].append(f"<campose>{result}</campose>")
elif phi_name == "novel_view_synthesis":
context["views"] = result
context["visual"].append(result)
return context
def _decode(self, x, context):
merged_prompt = self._merge_context_into_prompt(x, context)
return self.model.generate(merged_prompt)
def _merge_context_into_prompt(self, x, context):
pieces = [x.get("question", "")]
for txt in context["text"]:
pieces.append(f"<think>{txt}</think>")
for vis in context["visual"]:
pieces.append(f"<visual_tokens>{vis}</visual_tokens>")
return " ".join(pieces)Atomic primitives(论文提到的 5 个):
def text_think(x, context, model, max_new_tokens=100):
"""Short thinking (~100 tokens) for understanding / generation."""
prompt = f"{x['question']}\nThink step by step:"
return model.generate_text(prompt, max_new_tokens=max_new_tokens)
def text_think_long(x, context, model, max_new_tokens=250):
"""Long thinking (~250 tokens) with structural layout for T2I."""
prompt = (f"Describe the target image in detail including attributes, "
f"counts, spatial relations, and coarse layout:\n{x['prompt']}")
return model.generate_text(prompt, max_new_tokens=max_new_tokens)
def visual_token_rollout(x, context, model, n_tokens=1024):
"""Roll out discrete visual tokens that carry structural cues.
These are Omni's self-predicted visual representations used as additional
conditioning for downstream decoding."""
visual_tokens = model.rollout_visual_tokens(
prompt=x.get("prompt") or x.get("question"),
text_context=context["text"],
n_tokens=n_tokens,
)
return visual_tokens
def camera_pose_estimate(x, context, model):
"""3D textual context: estimate relative camera pose from two images."""
assert len(x["image"]) >= 2
pose = model.predict_camera_pose(x["image"])
return pose
def novel_view_synthesis(x, context, model):
"""3D visual context: synthesize up/down/left/right views from input."""
directions = ["up", "down", "left", "right"]
views = {}
for d in directions:
views[d] = model.synthesize_view(x["image"][0], direction=d)
return views
def depth_caption(x, context, model, max_new_tokens=150):
"""Task-relevant geometric caption: front/back ordering, occlusion, support."""
prompt = (f"Describe only the spatial/depth structure of this image: "
f"front/back ordering of objects, occlusion, support/contact.")
return model.generate_text(prompt, image=x["image"][0],
max_new_tokens=max_new_tokens)Context-conditioned generation(基于 BAGEL 的 flow-matching 生成主流程):
def context_conditioned_generate_image(model, prompt, text_context_list,
visual_token_context, n_steps=50):
"""Unified flow-matching generation with text + visual context.
Follows BAGEL's generation pipeline, but conditioned on multiple context
streams in the transformer cross-attention."""
text_ids = model.tokenize(prompt + " " + " ".join(text_context_list))
text_emb = model.embed_text(text_ids)
if visual_token_context is not None:
vis_emb = model.embed_visual_tokens(visual_token_context)
cond_emb = torch.cat([text_emb, vis_emb], dim=1)
else:
cond_emb = text_emb
latent = torch.randn(model.latent_shape, device=model.device)
for t in torch.linspace(0, 1, n_steps):
velocity = model.dit(latent, timestep=t, condition=cond_emb)
latent = latent + (1 / n_steps) * velocity
image = model.vae_decode(latent)
return imageTraining objective(Omni 扩展 BAGEL 的联合目标,按论文描述):
def omni_training_step(model, batch, config):
"""Omni training mixes text CE, image/video MSE (flow matching), and
3D geometry objectives. Based on BAGEL's pretrain_unified_navit.py."""
loss_dict = model(**batch)
ce_loss = loss_dict["ce"]
loss = 0.0
if ce_loss is not None:
loss = loss + config.ce_weight * ce_loss
mse_loss = loss_dict["mse"]
if mse_loss is not None:
loss = loss + config.mse_weight * mse_loss
if "pose_loss" in loss_dict:
loss = loss + config.pose_weight * loss_dict["pose_loss"]
if "depth_loss" in loss_dict:
loss = loss + config.depth_weight * loss_dict["depth_loss"]
return loss, loss_dict3.5 Code-to-paper mapping table
Code reference:
main@056b5fd5(2025-10-27) — 伪代码与映射基于 BAGEL 仓库此次 commit;Omni 本身未单独开源,其扩展部分(3D primitives、hidden reasoning space、context unrolling 推理流)以论文描述为准。
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| 统一 MoE backbone(Omni 继承 BAGEL) | modeling/bagel/bagel.py | Bagel |
| Qwen2 NaViT 语言+视觉混合 backbone | modeling/bagel/qwen2_navit.py | Qwen2ForCausalLM / Qwen2Model(含 Qwen2MoTDecoderLayer、Qwen2MoEDecoderLayer、PackedAttention(MoT)) |
| SigLIP NaViT 视觉编码器 | modeling/bagel/siglip_navit.py | SiglipVisionModel(内部 SiglipVisionTransformer + RotaryEmbedding2D) |
| 统一训练目标(CE + MSE) | train/pretrain_unified_navit.py | main()(训练循环中的 loss_dict["ce"] + loss_dict["mse"]) |
| VAE autoencoder | modeling/autoencoder.py | AutoEncoder |
| Inference pipeline | inferencer.py | 主入口 |
| 缓存/Taylorseer | modeling/cache_utils/taylorseer.py | Taylorseer |
| Context Unrolling 主流程(Omni 新增) | 论文 Section 2,未开源 | Eq. 1 的迭代实现 |
| 3D primitives(pose、NVS、depth)(Omni 新增) | 论文 Section 3.4,未开源 | 参见 VGGT、Depth-Anything-3 作为能力对标 |
4. Experimental Setup (实验设置)
-
数据集(论文 Section 3 分维度评测):
- Multimodal Understanding: BLINK、MMStar、MMBench-v11、VlmsAreBlind、SimpleVQA、RealWorldQA、TextVQA、AI2D、ChartQA、DocVQA、HallusionBench、MuirBench、ERQA、MMSI-Bench、MVBench、Video-MME
- Image Generation: GenEval-2、DPG、LongText-EN、LongText-CN、Inhouse eval;Editing 用 GEdit-Bench-EN
- Video Generation: VBench1.0(T2V)、FiVE Benchmark(video editing)
- 3D Geometry: RealEstate10K、CO3Dv2(camera pose)、NYU/KITTI/SINTEL/ETH3D/DIODE(monocular depth)
- Context Unrolling 消融(Tables 1–4): downsampled understanding benchmark、200 题 MMSI 子集、深度估计 benchmark
-
Baseline 方法:
- 理解 VLM: Qwen3-VL-30B-A3B-Instruct、InternVL3.5-30B-A3B(均用同一 Qwen3-30A3 LLM 骨干,便于公平对比)
- T2I: Qwen-Image、Z-Image、Flux.2-klein-9B
- Image Editing: Flux-Kontext-dev、Step1X-Edit-v1.1/v1.2、Emu-3.5、Z-Image-Edit、Qwen-Image-Edit
- T2V: Wan2.1、Hunyuan Video
- Video Editing: TokenFlow、DMT、VidToMe、AnyV2V、VideoGrain、Pyramid-Edit、Wan-Edit
- Camera pose: Flare、Cut3r、VGGT
- Depth: Marigold、Cut3r、Depth-Anything-3(DA3 giant)、VGGT
- Oracle text context: Gemini-3 Pro(zero-shot rewriting)
-
评估指标:
- 理解: 各 benchmark 的 accuracy 或 F1 分数
- 生成: GenEval-2 TIFAGM、DPG 总分、LongText-EN/CN 分数、GEdit-Bench-EN 的 G_SC(语义一致性)、G_PQ(感知质量)、G_O(总体)
- 视频: VBench Total/Quality/Semantic score;FiVE 的 Structure dist、PSNR、LPIPS、SSIM、CLIPS、Fid S、YN/MC 偏好、∪/∩ 准确
- 3D pose: AUC@30、RPE trans、RPE rot(越低越好)
- 深度: δ₁(越高越好)、AbsRel(越低越好)
-
训练配置:论文未公布完整训练细节。已知:
- 架构: MoE,3B active parameters(总参数未公开,预期 > 14B)
- 设计哲学基于 BAGEL(7B active / 14B total),继承其 MoT + NaViT 结构
- 原生训练数据跨 text / image / video / 3D geometry / hidden representation
- 输出分辨率: video 仅支持 480×640, 12s duration(作者承认离 SOTA 视频生成模型仍有差距)
5. Experimental Results (实验结果)
5.1 Multimodal Understanding (Table 5)
| Benchmark | Qwen3-VL-30B-A3B | InternVL3.5-30B-A3B | Omni |
|---|---|---|---|
| BLINK | 67.7 | 60.4 | 63.0 |
| MMStar | 78.4 | 72.0 | 63.8 |
| MMBench-v11 | 78.4 | 84.8 | 75.3 |
| VlmsAreBlind | 67.5 | - | 76.4 |
| SimpleVQA | 52.7 | - | 53.3 |
| RealWorldQA | 73.7 | 72.3 | 76.0 |
| TextVQA | - | 80.5 | 81.0 |
| AI2D | 85.0 | 86.8 | 91.5 |
| ChartQA | 86.8 | 87.4 | 86.9 |
| DocVQA | 95.0 | 94.2 | 92.8 |
| HallusionBench | 61.5 | 53.8 | 70.1 |
| MuirBench | 73.0 | 53.1 | 64.2 |
| ERQA | 51.3 | 41.5 | 45.0 |
| MMSI-Bench | 30.3 | 27.5 | 31.5 |
| MVBench | 72.3 | 72.1 | 68.4 |
| Video-MME (w/o sub) | 74.5 | 68.7 | 67.2 |
关键观察:Omni 在 AI2D、HallusionBench、RealWorldQA、VlmsAreBlind、MMSI-Bench 这五个”需要真实世界 / 空间推理”的 benchmark 上超过 Qwen3-VL(同 LLM backbone、同激活量级),其中 HallusionBench +8.6、VlmsAreBlind +8.9、AI2D +6.5。但在纯文本密集型 benchmark(MMStar、MMBench、DocVQA)上落后于经过重型 post-training 的 Qwen3-VL,作者归因于”no heavy post-training and distillation”。
5.2 Image Generation (Table 6)
| Model | GenEval2↑ | DPG↑ | LongText-EN↑ | LongText-CN↑ | Inhouse↑ |
|---|---|---|---|---|---|
| Qwen-Image | 30.67 | 88.32 | 94.3 | 94.6 | 55.16 |
| Z-Image | 41.83 | 88.14 | 93.5 | 93.6 | 55.19 |
| Flux.2 | 34.59 | 83.84 | 60.7 | 0.5 | 49.91 |
| Omni | 54.12 | 88.55 | 97.5 | 96.8 | 63.87 |
GenEval2 54.12 vs Z-Image 41.83 的优势达 +12.3 分,这是论文最大的生成侧亮点。
Image Editing (GEdit-Bench-EN):
| Model | G_SC | G_PQ | G_O |
|---|---|---|---|
| Flux-Kontext-dev | 7.16 | 7.37 | 6.51 |
| Step1X-Edit-v1.1 | 7.66 | 7.35 | 6.97 |
| Step1X-Edit-v1.2 | 7.77 | 7.65 | 7.24 |
| Emu-3.5 | 8.11 | 7.70 | 7.59 |
| Z-Image-Edit | 8.11 | 7.72 | 7.57 |
| Qwen-Image-Edit | 8.15 | 7.86 | 7.54 |
| Omni | 8.42 | 7.85 | 7.75 |
5.3 Video Generation (Tables 7 & 8)
T2V on VBench1.0:
| Model | Total↑ | Quality↑ | Semantic↑ |
|---|---|---|---|
| Wan2.1 | 83.69 | 85.59 | 76.11 |
| Hunyuan Video | 83.43 | 85.07 | 76.88 |
| Omni | 83.35 | 83.11 | 84.29 |
Omni 在 Semantic score 上压倒性领先(+8.18 比 Wan2.1、+7.41 比 Hunyuan),但 Quality score 落后——作者坦承这是因为 Omni 分辨率限制在 480×640、只支持 12 秒。
Video Editing on FiVE Benchmark(Table 8,完整列展示,符号含义:Struct Dist ↓ 越小越好,PSNR ↑ 越大越好,LPIPS ↓,SSIM ↑,CLIPS ↑,CLIPS.edit ↑,Fid S ↑,YN ↑,MC ↑,∪ ↑,∩ ↑,Acc ↑):
| Method | Struct Dist ×10³ ↓ | PSNR ↑ | LPIPS ×10³ ↓ | SSIM ×10² ↑ | CLIPS ↑ | CLIPS.edit ↑ | Fid S ×10² ↑ | YN ↑ | MC ↑ | ∪ ↑ | ∩ ↑ | FiVE Acc ↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TokenFlow | 35.62 | 19.06 | 263.61 | 72.51 | 26.46 | 21.15 | 89.00 | 19.36 | 35.51 | 36.68 | 18.18 | 27.43 |
| DMT | 85.95 | 14.71 | 404.60 | 51.64 | 26.66 | 21.44 | 82.30 | 34.78 | 62.06 | 62.98 | 33.86 | 48.42 |
| VidToMe | 22.37 | 21.15 | 263.91 | 70.69 | 26.84 | 21.05 | 90.06 | 20.03 | 33.50 | 36.20 | 17.34 | 26.77 |
| AnyV2V | 71.36 | 15.90 | 348.59 | 50.77 | 24.89 | 19.72 | 60.36 | 30.62 | 45.42 | 48.96 | 27.09 | 38.02 |
| VideoGrain | 12.40 | 27.05 | 185.21 | 79.13 | 25.69 | 20.31 | 88.57 | 30.50 | 43.97 | 44.30 | 30.17 | 37.23 |
| Pyramid-Edit | 28.65 | 20.84 | 276.59 | 71.72 | 26.82 | 20.20 | 80.59 | 33.67 | 54.01 | 56.36 | 31.31 | 43.84 |
| Wan-Edit | 12.53 | 25.57 | 94.61 | 82.55 | 26.39 | 21.23 | 89.43 | 41.41 | 52.53 | 55.72 | 38.22 | 46.97 |
| Omni | 34.94 | 22.95 | 217.55 | 73.78 | 26.92 | 21.19 | 84.22 | 62.83 | 81.81 | 84.33 | 60.23 | 72.41 |
视频编辑上 Omni 以 FiVE 总 accuracy 72.41 明显超过所有 baseline(次好 DMT 48.42 领先 +23.99 分),尤其在偏语义的 YN / MC / ∪ / ∩ 四个 instruction-following 维度上压倒所有 baseline(例如 ∩ 从 Wan-Edit 的 38.22 提到 60.23,绝对值几乎翻倍);而在纯结构保真的 Struct Dist / PSNR / LPIPS / SSIM 上 Wan-Edit 仍领先,说明 Omni 更偏向”按指令做正确编辑”而非”最大保留原视频像素”。
5.4 3D Geometry (Tables 9 & 10)
Camera Pose Estimation:
| Method | RealEstate10K AUC@30↑ | CO3Dv2 AUC@30↑ |
|---|---|---|
| Flare | 84.42 | 72.23 |
| Cut3r | 85.32 | 75.62 |
| VGGT | 88.23 | 86.23 |
| Omni | 88.32 | 75.21 |
Monocular Depth (δ₁):
| Method | NYU | KITTI | SINTEL | ETH3D | DIODE |
|---|---|---|---|---|---|
| Marigold | 92.75 | 87.87 | 62.24 | 97.12 | 81.64 |
| Cut3r | 91.64 | 86.42 | 55.64 | 95.34 | 75.21 |
| DA3 giant | 94.78 | 93.96 | 66.54 | 98.79 | 82.69 |
| VGGT | 96.10 | 94.29 | 66.11 | 98.35 | 82.15 |
| Omni | 96.22 | 96.92 | 74.27 | 98.91 | 83.83 |
Omni 在深度估计上5 个 benchmark 全部 SOTA,其中 KITTI +2.63、SINTEL +7.73 是显著提升。作者的解读是:depth prediction 不再是独立回归任务,而是”context-conditioned inference”——视觉 token rollout 提供的结构先验 + depth caption 的空间约束,让 unified model 在小参数规模下超过专门模型。
5.5 Ablation: Context Unrolling 的系统性收益
把 Tables 1–4 的 context unrolling 消融汇总成下表(取每个任务上 baseline 到最佳 context 的总增益):
| 任务 | Baseline → 最佳 context | 提升幅度 |
|---|---|---|
| Visual Understanding (MMStar) | 59.4 → 66.5 | +7.1 |
| Visual Generation (GenEval-2) | 29.25 → 53.44 | +24.19 |
| Spatial Understanding (MMSI) | 27.14 → 34.17 | +7.03 |
| 3D Geometry (δ₁) | 83.21 → 84.01 | +0.80 |
可视化 context unrolling 的收益曲线:
三张图共同证明了论文主张:context 的累积是单调贡献的,且 text 与 visual context 互补。特别是生成任务上 +24 分的增益比模型参数从 3B 到 7B 带来的收益大很多——这是支持”unified model 的价值在于 context unrolling 而非参数聚合”这一主张的最强证据。
5.6 作者自述的局限性
- 视频生成侧:当前 Omni 只能产生 480×640 分辨率、12 秒时长的视频,落后于 Wan2.1 / Hunyuan 的 720p+ 能力。作者认为这是算力预算限制,未来 scale up 会改善
- Oracle gap:GenEval-2 上 self-rollout context(53.44)仍低于 oracle text + visual(57.21),说明当前模型 rollout 出来的 context 本身存在 noise 和 hallucination,限制了 context unrolling 的上限
- Object-centric 3D 场景:CO3Dv2 的 pose estimation 上 Omni 落后 VGGT(75.21 vs 86.23),作者归因于 3D 训练数据未充分覆盖 object-centric 场景
- Post-training 尚未做:当前实验都是 supervised/standard evaluation,RL-style 训练(学习”何时调用哪个 primitive”的 policy)留作 future work
5.7 总体结论
Omni 的实验矩阵得出了三条一致的论断:
- “Unified ≠ Multi-task Container”:跨 4 个任务的 context ablation 共同说明,一个 unified model 的增量价值来自把各项能力作为原子 primitive 动态组装到 shared workspace 中,而不是单纯”一个骨干做多个事”。GenEval-2 +24 分、MMSI +7 分、MMStar +7 分,这些绝非仅靠参数共享能解释。
- Textual & Visual Context 是正交的:无论是 T2I 生成(Table 2 的 oracle + visual 比 oracle 单独再涨 +5)、spatial reasoning(+visual contexts 比 +textual contexts 再涨 +4)、还是 depth 估计(+visual tokens 对 +depth caption 的边际增益),都一致显示两者提供非冗余约束。
- Native multimodal pretraining 会涌现 context unrolling:这是一种 emergent capability——模型在训练中未被显式教”何时 think、何时 rollout visual tokens”,但自然学到了在合适任务上调用合适 primitive。这意味着未来 RL post-training 有巨大空间——学习一个”context-construction policy”,根据输入难度和任务类型自适应决定何时及如何展开 context。