Representation Fréchet Loss for Visual Generation
Paper: arXiv:2604.28190 Code: Jiawei-Yang/FD-Loss Code reference:
main@5c03b811(2026-04-27)
1. Motivation (研究动机)
现有 visual generation 的一个矛盾是:FID 已经被大量方法刷到接近甚至低于 ImageNet validation 的 FID,但肉眼质量和真实分布仍有明显差距;同时,真正的 Fréchet Distance 需要大 population 估计均值/协方差,用它直接训练会把每一步 batch 扩大到数万样本,几乎不可行。
本文想解决的具体问题是:能不能把 Fréchet Distance 从“评估指标”变成“可优化训练目标”,并且在不引入 GAN 判别器、teacher distillation 或复杂 reward model 的情况下,把已有视觉生成器继续 post-train 到更好的分布匹配状态。
这个问题值得研究,因为一旦 FD 可训练,它就提供了一个极简的 distribution matching objective:同一个目标既能改善已有 one-step generator,也能把 multi-step generator repurpose 成 1-NFE generator,还能扩展到 text-to-image post-training。
2. Idea (核心思想)
核心 insight 是把 FD 的“统计估计规模”和“梯度计算规模”解耦:用 queue 或 EMA 在大 population 上估计 generated distribution 的均值/协方差,但只让当前 mini-batch 的 feature 带梯度回传。
关键创新不是提出一个新的 perceptual metric,而是证明 Fréchet Distance 在 frozen representation space 内可以稳定优化;再用多种 representation 的 normalized FD ratio $\mathrm{FDr}^K$ 避免单一 Inception/FID 被 reward hacking。
与 GAN / DMD / reward-model post-training 不同,FD-loss 没有额外判别器、teacher network 或偏好数据;它直接把真实样本和生成样本在 representation feature distribution 上对齐,训练信号来自二阶统计而不是逐样本重构或 pairwise preference。
3. Method (方法)
3.1 Overall framework

Figure 2 解读:左侧 FD-loss 模块读取一个大 population 的 representation features 来估计 generated distribution;右侧 generator 每一步只产生 $B$ 张图,红色虚线表示梯度只穿过当前 batch。这个设计让 $N$ 可以取 50k/100k 等稳定统计规模,而反向传播仍保持常规 batch cost。
3.2 FD in representation space
给定 frozen representation model $\phi$,真实图像和生成图像的 feature statistics 为:
对应 Fréchet Distance 是:
直觉上,FD-loss 不是要求每张生成图和某张真实图对应,而是要求整个 generated feature cloud 的中心和形状接近真实 feature cloud;这尤其适合 image generation,因为生成任务的目标本来就是匹配分布,而不是一一重建。
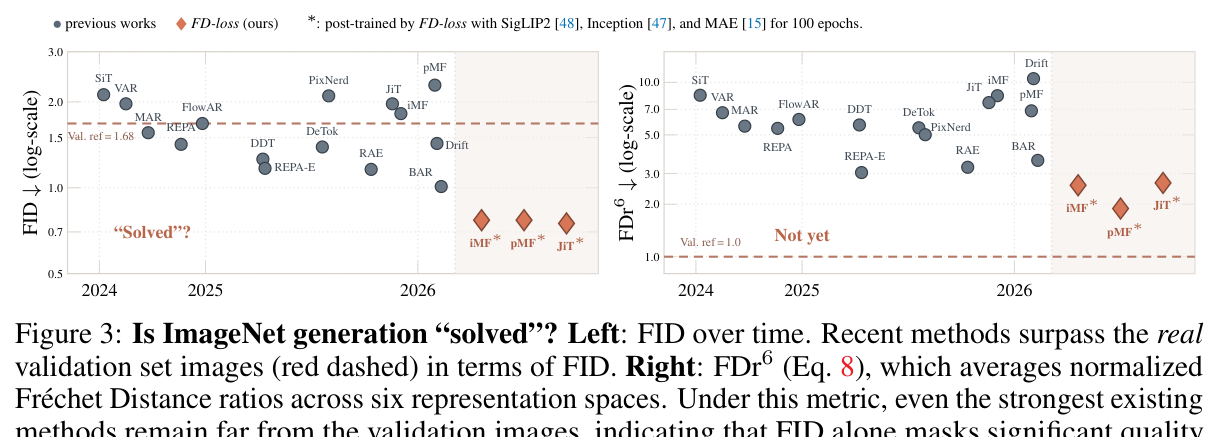
Figure 3 解读:左图显示 FID 视角下不少方法已经超过 validation set 的红色虚线,容易给出“ImageNet generation solved”的错觉;右图使用 6 个 representation 的 normalized ratio $\mathrm{FDr}^6$ 后,真实 validation 仍是基准 1.0,而 generator 与真实数据还有明显差距。FD-loss post-training 把 pMF-H 推到 $\mathrm{FDr}^6=1.89$,说明它确实缩小多表示空间中的分布差距。
3.3 Queue / EMA estimator
Queue estimator 维护一个大小为 $N$ 的 feature buffer。每步把当前 batch feature 入队、旧 feature 出队;FD 统计量在全 queue 上计算,但旧 feature 用 detach() 固定,只有当前 batch 对 generator 参数有梯度。
EMA estimator 不存全部 feature,只维护一阶和二阶矩:
3.4 Multi-representation loss and FDr
多 representation loss 使用 stop-gradient 归一化,避免某个 feature space 的 FD 尺度主导训练:
评估时使用 validation-to-training 的 normalized ratio:
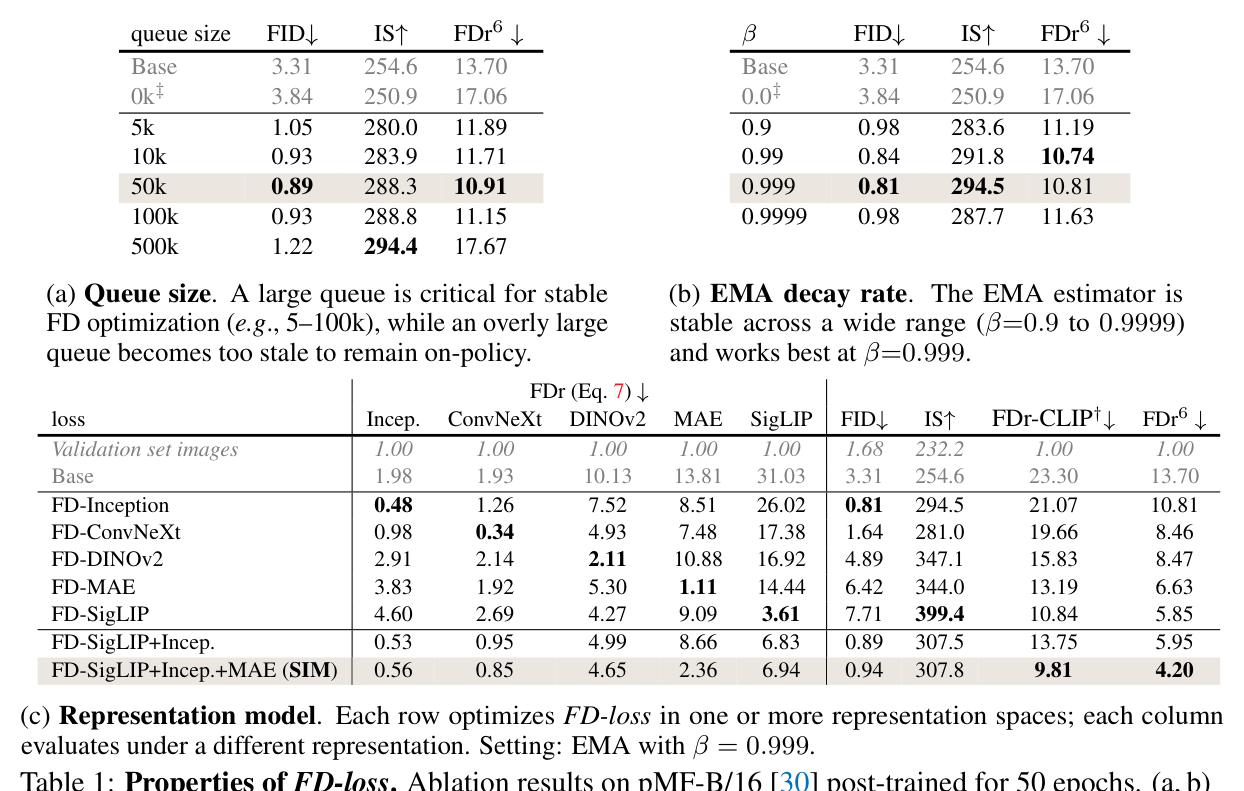
Figure 4 解读(paper Table 1):queue 太小会退化,$N=0$ 时 FID 从 base 的 3.31 变差到 3.84,$\mathrm{FDr}^6$ 从 13.70 变差到 17.06;EMA 在 $\beta=0.9\sim0.9999$ 范围内稳定,$\beta=0.999$ 达到 FID 0.81、$\mathrm{FDr}^6=10.81$。representation ablation 显示单一 Inception 会把 FID 压到 0.81 但 $\mathrm{FDr}^6$ 仍为 10.81;SIM 组合把 $\mathrm{FDr}^6$ 降到 4.20。

Figure 5 解读(paper Figure 4):不同 representation post-training 都比 base 清晰,但优化 Inception 更偏向 FID;优化 SigLIP/MAE/DINOv2 等现代 representation 时,语义和纹理更自然。图中绿色表示 FID、黄色表示 $\mathrm{FDr}^6$,说明单一指标最优不等于整体视觉质量最优。
3.5 Repurposing multi-step generators
对 multi-step generator,论文直接把它当作 1-step generator 采样,并用 FD-loss post-train。这个做法等价于让一个原本依赖 many-step denoising trajectory 的模型,在 distribution-level 目标下重新学习“单步输出的分布”。

Figure 6 解读(paper Table 2 / Figure 5):JiT-L 原始 1-step 直接失败,FID 为 21.59、$\mathrm{FDr}^6=14.75$;FD-SigLIP+Incep.+MAE 的 1-NFE 版本达到 FID 0.85、IS 319.5、$\mathrm{FDr}^6=3.29$,说明 FD-loss 能把 multi-step generator 转成可用的 one-step generator。
3.6 Source-based pseudocode
import torch
import torch.nn.functional as F
def frechet_distance_loss(mu_ref, sigma_ref, feats=None, mu=None, sigma=None, sigma_ref_sqrt=None):
if feats is not None:
mu = feats.mean(dim=0)
centered = feats - mu
sigma = centered.T @ centered / (feats.shape[0] - 1)
diff = mu - mu_ref.to(mu.dtype)
mean_term = diff.dot(diff)
if sigma_ref_sqrt is not None:
m = sigma_ref_sqrt.to(sigma.dtype) @ sigma @ sigma_ref_sqrt.to(sigma.dtype)
m = 0.5 * (m + m.T)
eig = torch.linalg.eigvalsh(m).clamp_min(0)
tr_covmean = torch.sqrt(eig).sum()
else:
eig = torch.linalg.eigvals(sigma @ sigma_ref.to(sigma.dtype)).real.clamp_min(0)
tr_covmean = torch.sqrt(eig).sum()
trace_term = torch.diagonal(sigma).sum() + torch.diagonal(sigma_ref).sum() - 2.0 * tr_covmean
return (mean_term + trace_term).float()
class FeatureStats:
def __init__(self, feat_dim, size=50000, ema_beta=0.999):
self.ema_beta = ema_beta
self.mu_ema = torch.zeros(feat_dim, dtype=torch.float64)
self.m2_ema = torch.zeros(feat_dim, feat_dim, dtype=torch.float64)
def build_ema_stats(self, new_feats):
x = new_feats.double()
beta = self.ema_beta
mu = beta * self.mu_ema.detach() + (1.0 - beta) * x.mean(0)
m2 = beta * self.m2_ema.detach() + (1.0 - beta) * (x.T @ x) / x.shape[0]
sigma = m2 - mu[:, None] @ mu[None, :]
return mu, sigma
@torch.no_grad()
def update(self, mu, m2):
self.mu_ema.copy_(mu.detach())
self.m2_ema.copy_(m2.detach())
def fd_train_step(generator, judges, optimizer, batch_size, input_shape, num_classes, eps=0.01):
z = torch.randn(batch_size, *input_shape, device="cuda")
y = torch.randint(0, num_classes, (batch_size,), device="cuda")
x = generator.sample_images_with_grad(z, y)
x = x * 0.5 + 0.5
loss = torch.zeros((), device="cuda")
all_feats = []
for judge in judges:
feat = judge.extract_features(x)
feat = diff_all_gather(feat)
all_feats.append(feat)
for judge, feat in zip(judges, all_feats):
mu, sigma = judge.queue.build_feats_stats(feat)
fd = frechet_distance_loss(judge.mu_ref, judge.sigma_ref, mu=mu, sigma=sigma, sigma_ref_sqrt=judge.sigma_ref_sqrt)
loss = loss + judge.weight * fd / (fd.detach() + eps)
loss.backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
for judge, feat in zip(judges, all_feats):
judge.queue.enqueue(feat.detach())
return lossCode reference:
main@5c03b811(2026-04-27) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Differentiable FD / matrix square root | frechet_distance/losses.py | compute_frechet_distance_loss, _compute_trace_term, precompute_sigma_ref_sqrt |
| Queue / EMA generated statistics | frechet_distance/queue.py | FeatureQueue.build_feats_stats, _build_feats_stats_ema, enqueue |
| Multi-judge FD-loss train step | main_fd.py | get_fd_train_step |
| Representation backbones | frechet_distance/repr_models.py | judge construction / feature extraction utilities |
| Actual experiment launch configs | scripts/table_1a_queue_size.sh, scripts/table_1b_ema_beta.sh, scripts/table_1c_backbone_combo.sh, scripts/table_3_pMF.sh, scripts/table_3_iMF.sh, scripts/table_3_JiT.sh | queue/EMA/backbone/scaling experiments |
论文公式与 released code 实现差异:未发现会改变算法含义的差异;code 中 fid / (fid.detach() + fd_fid_norm_eps) 对应论文 Eq. 6 的 sg(FD)+c 归一化,FeatureQueue 的 EMA 分支对应论文 Eq. 3–5。实现上若预计算 sigma_ref_sqrt,trace term 用 eigvalsh(sigma_ref_sqrt @ sigma @ sigma_ref_sqrt),否则回退到 eigvals(sigma @ sigma_ref)。
4. Experimental Setup (实验设置)
- Datasets:ImageNet class-conditional 使用 ImageNet train/val(评估中 50k validation images;FD/FID 统计对 ImageNet training distribution 计算);text-to-image 使用 BLIP3o-Pretrain-Long-3M(3M realistic photo subset)和 BLIP3o-GPT4o-60k(60k GPT-4o distilled stylized reference)。
- Baselines:VAR-d30, BAR-L, SiT-XL/2, MAR-L/MAR-H, FlowAR-H, REG, SiT-XL/2-REPA, LightningDiT, DDT-XL, REPA-E, RAE-XL, Drift-L, iMF-XL, PixNerd-XL, JiT-L/JiT-H, pMF-L/pMF-H。
- Metrics:FID(Inception Fréchet distance)、IS、Precision/Recall、
$\mathrm{FDr}_{\phi}$、$\mathrm{FDr}^6$;human preference 用 pairwise vote。 - Training config:来自 released scripts 而不是
main_fd.pydefaults:scripts/table_3_pMF.sh,table_3_iMF.sh,table_3_JiT.sh默认GPUS_PER_NODE=8,GLOBAL_BSZ=1024,per-GPUBATCH_SIZE=GLOBAL_BSZ/TOTAL_GPUS;Table 1/2 训练 50 epochs,Table 3/4 训练 100 epochs,steps_per_epoch=1250,warmup_epochs=5, AdamWβ1=0.9, β2=0.95, weight decay 0, cosine LR, bf16;pMF/iMF LR 为1e-6,JiT LR 为1e-5;FD-SIM 默认ema_beta=0.999,warm-start 50k base samples,1 NFE。论文/脚本没有明确给出 GPU 型号。
5. Experimental Results (实验结果)
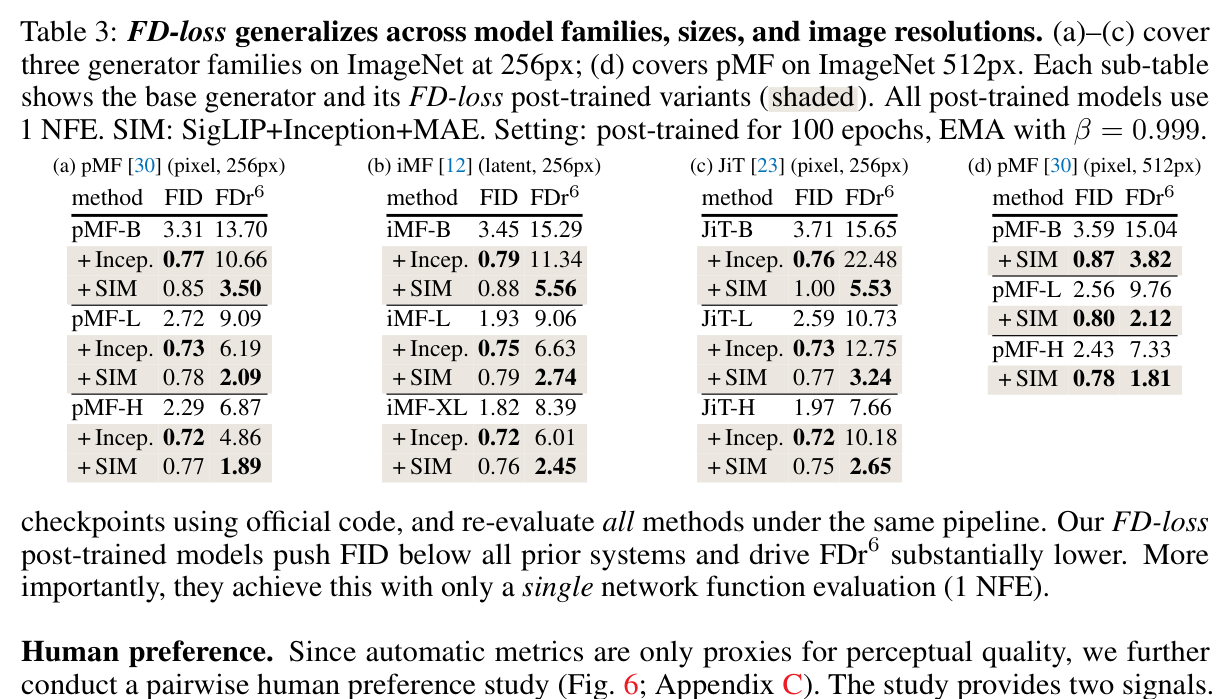
Figure 7 解读(paper Table 3):FD-loss 在 pMF、iMF、JiT 三类模型和不同尺寸上都有效。pMF-H 从 FID 2.29 / $\mathrm{FDr}^6=6.87$ 改到 FD-SIM 的 FID 0.77 / $\mathrm{FDr}^6=1.89$;iMF-XL 从 1.82 / 8.39 到 0.76 / 2.45;JiT-H 从 1.97 / 7.66 到 0.75 / 2.65。512px pMF-H 也从 2.43 / 7.33 到 0.78 / 1.81。
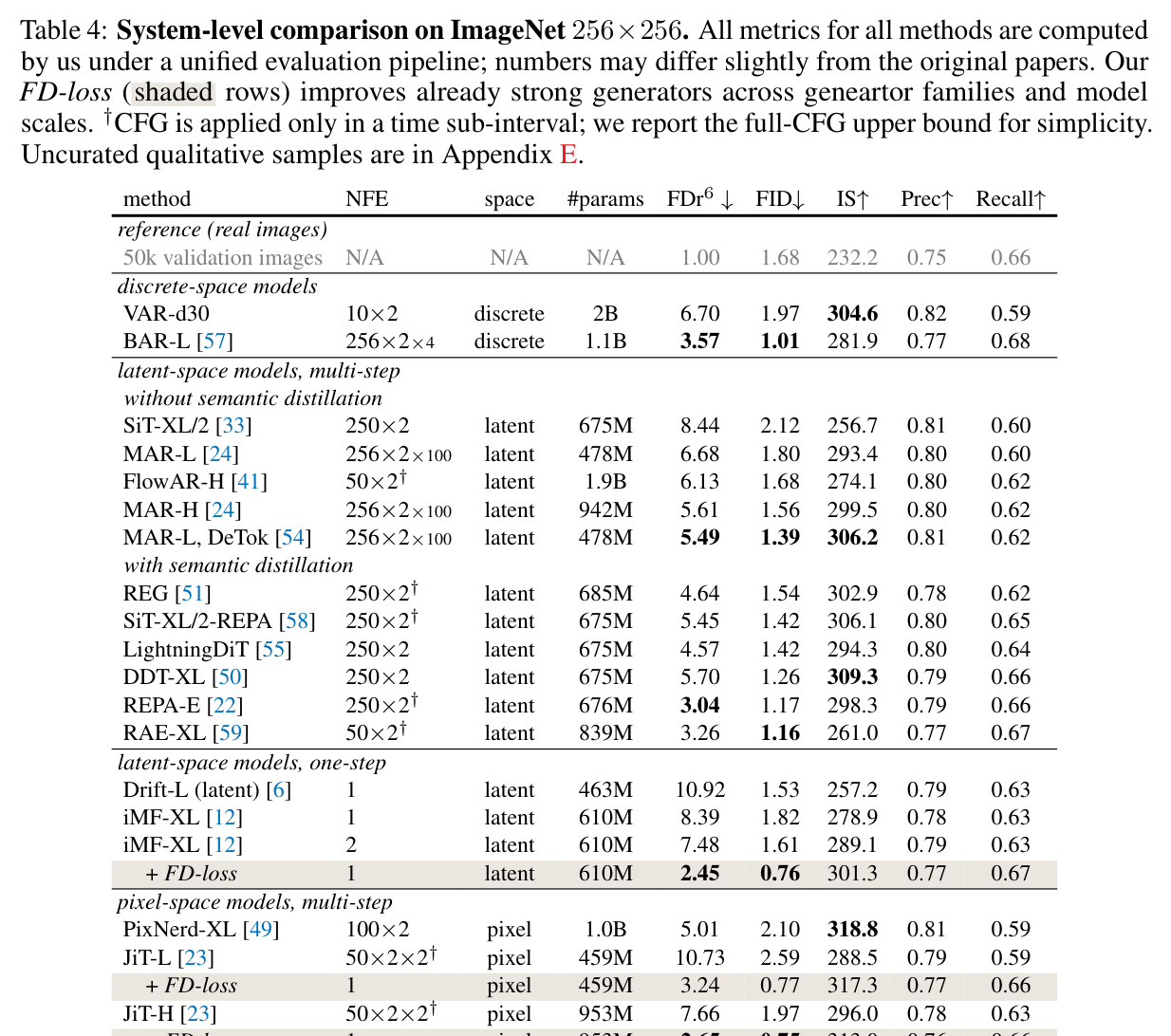
Figure 8 解读(paper Table 4):统一 pipeline 下,FD-loss post-trained pMF-H 1-NFE 达到 FID 0.77、IS 310.1、Precision 0.77、Recall 0.68、$\mathrm{FDr}^6=1.89$,显著优于 pMF-H base 的 FID 2.29 / $\mathrm{FDr}^6=6.87$;JiT-H 1-NFE FD-loss 版本达到 FID 0.75 / $\mathrm{FDr}^6=2.65$,接近或超过许多 multi-step baselines 的 distribution metrics。
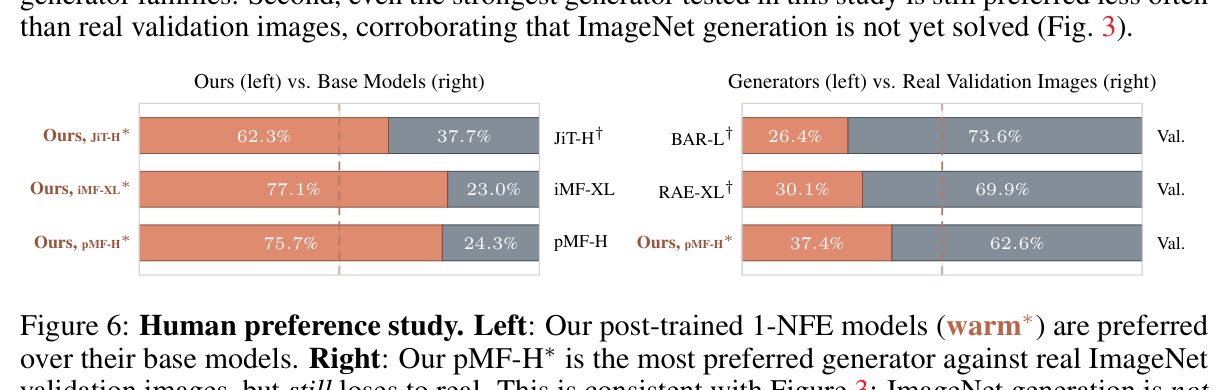
Figure 9 解读(paper Figure 6):human preference 中,post-trained 1-NFE 模型相对 base 的胜率分别为 JiT-H 62.3%、iMF-XL 77.1%、pMF-H 75.7%;与真实 validation images 对比时,pMF-H* 在几种 generator 中最好,但仍以 37.4% vs 62.6% 输给真实图像,说明 FDr 的“尚未完全 solved”判断与人类偏好一致。

Figure 10 解读(paper Figure 7):SD3.5 Medium 经过 FD-loss text-to-image post-training 后能以 1 NFE 生成更接近 reference distribution 风格的图像,展示了 FD-loss 不只适用于 ImageNet class-conditioned generation,也能迁移到 text-conditioned generation。
主要 ablation 结论:queue/EMA 的大 population 统计是必要条件;多 representation 组合优于单一 Inception;SIM 在 FID 与 $\mathrm{FDr}^6$ 之间取得更好平衡。作者提到的限制是自动指标仍是感知质量 proxy:即使 pMF-H* 在 generator 之间 human preference 最好,仍明显输给真实 validation images。