Generative Modeling via Drifting
Authors: Mingyang Deng, He Li, Tianhong Li, Yilun Du, Kaiming He Affiliations: MIT, Harvard University arXiv: 2602.04770 Project Page: lambertae.github.io/projects/drifting GitHub: lambertae/drifting Venue: arXiv 2026
1. Motivation (研究动机)
这篇论文讨论的核心不是“如何把 diffusion 采样再压几步”,而是更根本的问题:生成模型为什么一定要把“迭代”放在推理阶段?
现有主流 generative modeling,尤其是 Diffusion / Flow Matching,一般都把从噪声到数据的复杂映射拆成许多小步,在 inference 时逐步执行。这样做的优点是训练稳定、建模能力强,但缺点也非常直接:
- 推理成本高:生成一张图需要多次 network evaluation,NFE 很高。
- 一步生成很难:现有 one-step 方法通常要么做 distillation,要么仍然在训练中显式近似 diffusion / flow 的轨迹。
- 范式受限:即使是 from-scratch 的 one-step diffusion/flow,本质上依然在“逼近一个原本为多步设计的动力学过程”。
作者希望解决的问题是:
- 能否直接学习一个 single-pass generator,天然只需 1 NFE;
- 同时不依赖 SDE / ODE / reverse process 的轨迹近似;
- 并且在 ImageNet 256×256 上仍然达到接近甚至超过现有 one-step 方法的质量。
这个问题值得研究,因为如果“训练时迭代、推理时一步”真的成立,那么生成模型的效率-质量权衡会被重新定义。论文最后在 latent space 做到 FID 1.54,说明这不是一个纯理论想法,而是可以落到 SOTA 结果上的新训练范式。
2. Idea (核心思想)
论文的核心洞察可以概括成一句话:
把原本发生在 inference-time 的分布演化,改成 training-time 的分布演化。
具体来说,作者把 generator 看成一个映射 ,其输出分布是输入噪声分布 的 pushforward:
传统 diffusion / flow 会在推理阶段迭代地把 推向 ;而 Drifting Models 则直接在训练阶段让参数更新驱动 逐步靠近 。
为此,作者定义了一个 drifting field :
- 当当前生成分布 和真实分布 不一致时, 给出样本 应该往哪里移动;
- 当 时,,系统达到 equilibrium。
然后训练时不直接对 drift 求梯度,而是构造一个 drifted target:
再用一个简单的 regression loss 让 generator 输出朝这个 target 靠近。
相对于已有方法,它的根本区别有三点:
- 不同于 diffusion / flow:它不建模 inference-time trajectory,而是建模 training-time distribution evolution。
- 不同于 GAN:它没有 discriminator 和 min-max 对抗,而是用显式 drifting field 做 regression。
- 不同于 perceptual matching / MMD 直接优化:它不是仅最小化分布差异标量,而是显式构造“样本该往哪里漂”的向量场。
3. Method (方法)
3.1 整体框架:把 pushforward 的演化搬到训练阶段
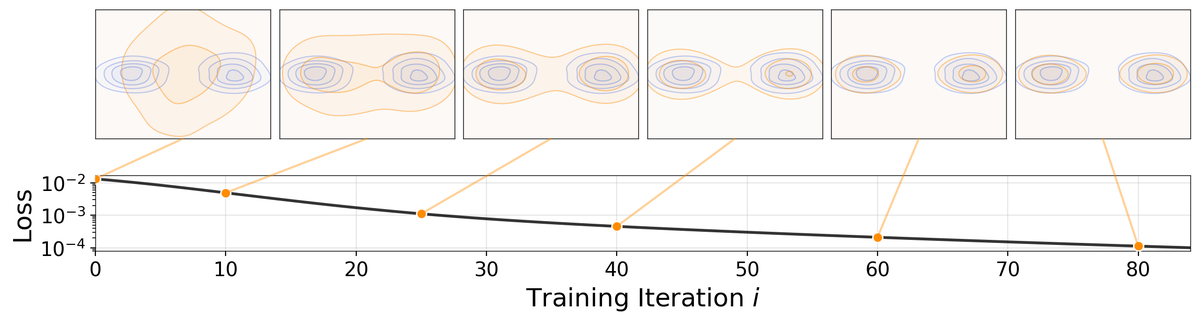
Figure 1 解读:这张图不是常见的“网络结构框图”,而是论文最关键的概念图。左到右展示了训练迭代过程中 pushforward distribution (橙色)如何逐步逼近 data distribution (蓝色)。下方曲线显示随着训练推进,drifting loss 单调下降。它强调的重点是:Drifting Models 的“迭代”发生在参数更新层面,而不是测试时的采样链上。
设 ,其中 ,则训练中的分布演化写成:
作者要求 drifting field 满足 anti-symmetry:
于是当 时有 。这给出了 equilibrium condition。
基于 fixed-point 思想,论文把目标写成:
并在实际训练中转化为 stop-gradient regression:
这个损失有两个重要含义:
- 值上:它等价于最小化 drift 的平方范数 ;
- 优化上:它避免了对分布依赖的 直接反传,而是把它当成 frozen target。

Algorithm 1 解读:论文主体给出的训练伪代码非常简洁:先从噪声得到生成样本 ,再把同一批 作为 negative samples,与 real data 的 positive samples 一起计算 drifting field ,最后让 回归到 。这段算法展示了论文最重要的“范式切换”:不再拟合去噪轨迹,而是拟合“当前样本往哪漂”。
3.2 Drifting field:吸引真实样本、排斥生成样本
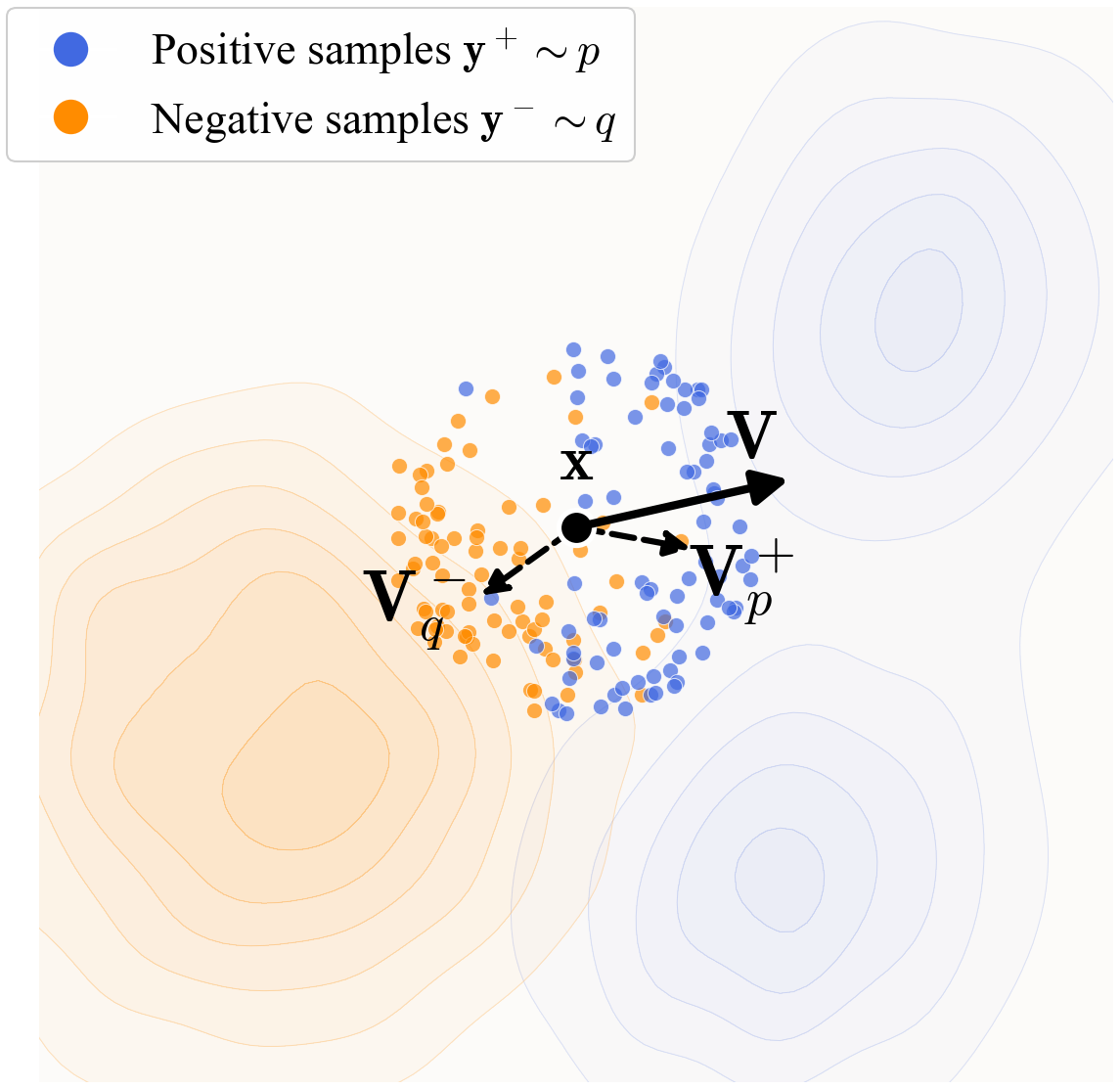
Figure 2 解读:黑点是当前生成样本 。蓝色正样本来自真实分布 ,橙色负样本来自生成分布 。 把 往真实样本密集区域拉, 把 从生成样本已经堆积的区域推开,因此总漂移方向是 。这张图很好地解释了为什么该方法天然不容易 mode collapse:如果某个 mode 被忽略,来自 的 attraction 会持续把样本拉过去。
作者把 drifting field 具体写成:
其中
把两者合并可得:
这里的 kernel 取为
几个关键理解:
- anti-symmetry 是必须的:交换 只会翻转 drift 方向,因此在匹配点可稳定归零。
- 它是 mean-shift 风格的局部几何更新:并不是全局判别器打分,而是用邻域结构决定样本移动方向。
- zero drift 并不自动严格推出 :论文在 Appendix C.1 只给了 identifiability heuristic,而不是完全一般性的严格定理。
3.3 Feature space drifting:真正起决定作用的是表征空间
高维图像空间里,直接用原像素做 kernel 很难稳定度量语义相似性,因此论文把 drifting loss 放到 feature space:
进一步还能扩展到多尺度、多位置特征:
这部分是论文真正能在 ImageNet 上跑起来的关键。作者的经验结论非常明确:没有强 feature encoder,方法在 ImageNet 上基本不起作用。论文里最终最有效的是 latent-MAE;官方代码又把这部分做得比论文伪代码更具体:
- latent 生成默认在 SD-VAE 的 32×32×4 latent space 里完成;
- feature encoder 使用
MAEResNetJAX.get_activations()提取多尺度特征; - 除了每个 stage 的 spatial tokens,还额外加入 global mean / std、patch mean / std;
- drift 不是只算一个 temperature,而是对
R_list=(0.02, 0.05, 0.2)三个温度同时算,再做归一化累加; drift_loss.py里对 affinity 同时做 row softmax 和 column softmax,再取几何平均,保证正负样本权重更稳定。
3.4 CFG、网络结构与训练细节
论文把 CFG 也改写成 training-time distribution mixing。对类别条件 ,negative distribution 被写成:
从而得到
这意味着 CFG 不是推理时额外跑 unconditional branch,而是在训练时就通过额外的 unconditional real negatives 来塑形,因此最终仍然保持 1 NFE inference。
实现层面(结合论文 Appendix 和官方 JAX 代码):
- generator 是 DiT-like Transformer;
- latent 模型输入 / 输出都是 ;
- B/2 用 hidden size 768、depth 12;L/2 用 hidden size 1024、depth 24;
- patch size 为 2;pixel-space 版本用 DiT/16;
- condition 不只包含 class embedding,还包含:
- CFG scale 的
TimestepEmbedder - 32 个随机 style token(代码里对应
noise_coords=32,noise_classes=64) - 16 个 prepended class tokens(
n_cls_tokens=16)
- CFG scale 的
- 训练 loop 使用两个 memory bank:
ArrayMemoryBank(num_classes=1000)存 per-class positive samplesArrayMemoryBank(num_classes=1)存 global negative / unconditional samples
3.5 基于官方代码的伪代码
下面的伪代码不是照抄论文文字,而是对应官方实现 lambertae/drifting 的真实逻辑。
Algorithm: ComputeDriftLoss
Input: gen[B, G, D], pos[B, P, D], neg[B, U, D], R_list
Output: scalar loss, diagnostics
1: old_gen = stopgrad(gen)
2: targets = concat(old_gen, neg, pos)
3: targets_w = concat(weight_gen, weight_neg, weight_pos)
4: dist = cdist(old_gen, targets)
5: scale = mean(dist * targets_w) / mean(targets_w)
6: old_gen_scaled = old_gen / max(scale / sqrt(D), 1e-3)
7: targets_scaled = targets / max(scale / sqrt(D), 1e-3)
8: dist_normed = dist / max(scale, 1e-3)
9: mask self-distance inside the generated block
10: force = 0
11: for R in R_list:
12: logits = -dist_normed / R
13: A_row = softmax(logits, dim=targets)
14: A_col = softmax(logits, dim=queries)
15: A = sqrt(clip(A_row * A_col, 1e-6))
16: split A into negative-part and positive-part
17: build signed coefficients for positives / negatives
18: force_R = coeff @ targets_scaled - coeff_sum * old_gen_scaled
19: force += force_R / sqrt(mean(force_R ** 2) + 1e-8)
20: goal = stopgrad(old_gen_scaled + force)
21: gen_scaled = gen / max(scale / sqrt(D), 1e-3)
22: loss = mean((gen_scaled - goal) ** 2)
23: return lossAlgorithm: BuildMultiScaleFeatures
Input: image_or_latent x
Output: dict of feature tensors
1: feats["global"] = reshape(x, [B, 1, -1])
2: feats["norm_x"] = sqrt(mean(x ** 2, axis=(H, W)) + 1e-6)
3: run MAEResNet encoder to get conv1, layer1, layer2, layer3, layer4
4: for each feature map:
5: add per-location tokens
6: add global mean if use_mean
7: add global std if use_std
8: add patch mean/std for patch sizes in [2, 4]
9: if every_k_block == 2:
10: also export every 2 residual blocks as extra features
11: if ConvNeXt-V2 is enabled:
12: decode latent to pixel, normalize with ImageNet stats, add ConvNeXt features
13: return all feature tensorsAlgorithm: GeneratorForward
Input: class labels c, cfg_scale alpha
Output: generated samples x_hat
1: sample Gaussian noise x ~ N(0, I)
2: sample 32 style indices noise_labels in [0, 63]
3: cond = class_embed(c)
4: for each style coordinate i:
5: cond += noise_embed_i(noise_labels[:, i])
6: cond += 0.02 * RMSNorm(TimestepEmbedder(alpha))
7: patchify x and project to token embeddings
8: add 2D sin-cos positional embedding
9: prepend 16 condition tokens derived from cond
10: run LightningDiT blocks
11: apply FinalLayer with adaLN-style modulation
12: remove class tokens, unpatchify tokens to image/latent
13: return x_hatAlgorithm: TrainStepWithMemoryBank
Input: current generator state, train batch
Output: updated state
1: push recent real samples into:
2: positive_bank[label]
3: negative_bank[global]
4: sample labels for this step
5: positives = positive_bank.sample(labels, pos_per_sample)
6: negatives = negative_bank.sample(global_label, neg_per_sample)
7: sample cfg scale alpha from power-law distribution
8: generate gen_per_label samples for each label
9: extract multi-scale features for real and generated samples
10: compute drift loss for every feature key and sum them
11: backprop, clip gradient by global norm
12: update params with AdamW
13: update EMA params
14: periodically evaluate FID over a list of CFG scales
15: return new_state3.6 Code-to-paper mapping
| Paper Concept | Source File | Key Class / Function | 说明 |
|---|---|---|---|
| Drifting field 与训练损失 | drift_loss.py | drift_loss, cdist | 对应 Eq. (11) / feature-space loss 的核心实现,包含多温度与双 softmax 归一化 |
| 单步 generator 封装 | models/generator.py | DitGen | 负责采样噪声、拼装 class + style + CFG conditioning |
| DiT-like 主干 | models/generator.py | LightningDiT, LightningDiTBlock, FinalLayer | 真正执行 patchify、Transformer block、unpatchify |
| CFG conditioning | models/generator.py | c_cfg_noise_to_cond, TimestepEmbedder | 对应论文的 training-time CFG |
| 多尺度 feature 提取 | models/mae_model.py | MAEResNetJAX.get_activations | 生成 per-location / mean / std / patch statistics 特征 |
| Feature encoder 组装 | models/mae_model.py | build_activation_function | 把 latent-MAE / ConvNeXt-V2 特征统一成 drift loss 输入 |
| Positive / negative sample queue | memory_bank.py | ArrayMemoryBank.add, ArrayMemoryBank.sample | 对应论文 Appendix A.8 的 sample queue |
| 训练主循环 | train.py | train_step, train_gen | CFG 采样、feature loss 汇总、EMA、FID 评测 |
| 数据与 tokenizer | dataset/dataset.py, dataset/vae.py | create_imagenet_split, vae_enc_decode | 处理 ImageNet、SD-VAE encode/decode |
| 最终超参数 | configs/gen/latent_sota_L.yaml, configs/gen/pixel_sota_L.yaml | YAML configs | 对应论文 Table 8 的 released setting |
4. Experimental Setup (实验设置)
4.1 数据集与任务
- ImageNet 256×256:主实验场景,包含 latent-space generation 和 pixel-space generation。
- Robotics Control:沿用 Diffusion Policy 的评测协议(论文中直接称 follow Diffusion Policy),包括:
- 单阶段任务:Lift, Can, ToolHang, PushT
- 多阶段任务:BlockPush, Kitchen
4.2 对比基线
论文对比了三类视觉生成基线:
- Multi-step Diffusion / Flow
- DiT-XL/2
- SiT-XL/2
- SiT-XL/2 + REPA
- LightningDiT-XL/2
- RAE + DiT
- Single-step Diffusion / Flow
- iCT
- Shortcut
- MeanFlow
- AdvFlow
- iMeanFlow
- GAN / Pixel one-step baselines
- BigGAN
- GigaGAN
- StyleGAN-XL
Robotics 部分则直接对比 Diffusion Policy (100 NFE)。
4.3 评测指标
- FID:ImageNet 主指标,统一在 50K 张生成图像上评测。
- IS:辅助衡量样本质量。
- Success Rate:Robotics 控制任务指标。
4.4 训练配置
Ablation default(latent, B/2)
- generator: DiT-B/2,hidden size 768,depth 12
- latent tokenizer: SD-VAE,latent size
- feature encoder: latent-MAE,width 256(默认)或更大
- epochs: 100
- effective batch: 4096
最终 latent SOTA(官方 release 对应 latent_sota_L.yaml)
- generator: DiT-L/2,hidden size 1024,depth 24,16 heads
gen_per_label=64pos_per_sample=64,neg_per_sample=32- effective batch
- optimizer: AdamW,
- learning rate: ,warmup 10k steps
- gradient clip: 2.0
- EMA: 0.999
- total steps: 200k(论文表述为 1280 epochs)
- CFG scale 训练范围:
- drift temperatures:
最终 pixel SOTA(pixel_sota_L.yaml)
- generator: DiT-L/16,hidden size 1024,depth 24
- patch size: 16
- feature encoder: pixel-MAE + ConvNeXt-V2
- total steps: 100k(论文表述为 640 epochs)
Feature encoder 预训练
- latent-MAE 宽度最终用到 640
- MAE 预训练 1280 epochs
- 最优配置再做 3k steps classifier fine-tuning
硬件说明
- 论文主体没有明确给出完整训练硬件表;
- 但致谢里写到使用了 Google TPU Research Cloud;
- 官方仓库在 FID 评测说明里推荐 TPU v4-8,代码也整体基于 JAX / Flax / TPU-first 设计。
5. Experimental Results (实验结果)
5.1 Toy 实验:确实在“分布层面漂移”

Figure 3 解读:三行分别对应三种初始分布:位于两个 mode 中间、远离两个 mode、以及 collapse 到单一 mode。横向看训练迭代,橙色生成分布都会逐步贴近蓝色真实分布。最重要的是第三行:即便初始已经 collapse,模型仍能被其他未覆盖 mode 的 attraction 拉回来。
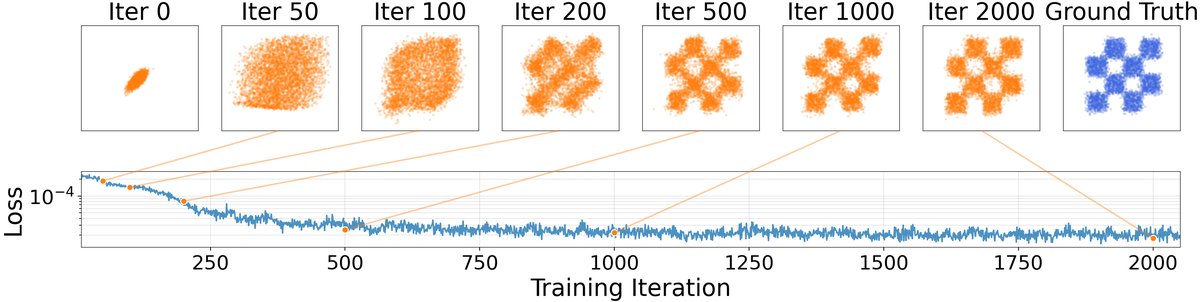
Figure 4a 解读:在 checkerboard toy task 上,生成点云从局部小团逐渐扩展成六个稳定 mode,同时下方 loss 曲线随训练明显下降。这说明论文里的 不只是形式化目标,而是真和“分布越来越像目标分布”相关。
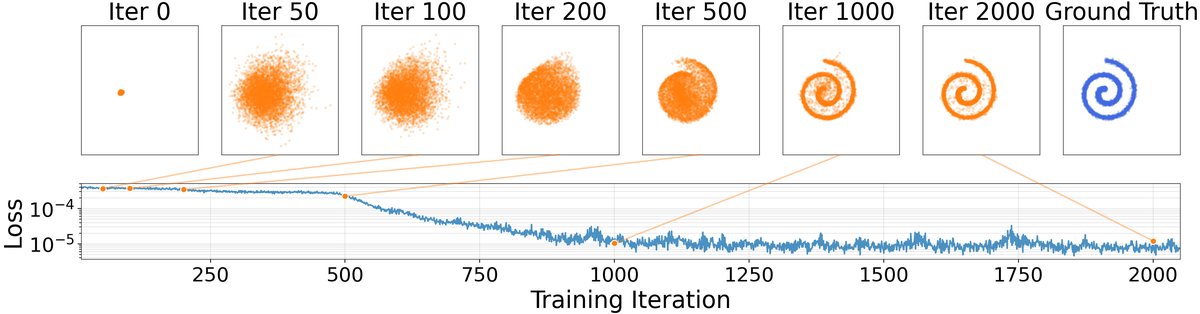
Figure 4b 解读:在 swiss roll 任务上,生成分布先变粗、再拉伸、最后卷成螺旋,说明 drifting field 不只会做局部细修,而是能驱动相当大的拓扑重排。对理解后面 ImageNet 实验很关键:作者确实在学一个 training-time transport mechanism。
5.2 ImageNet 主结果
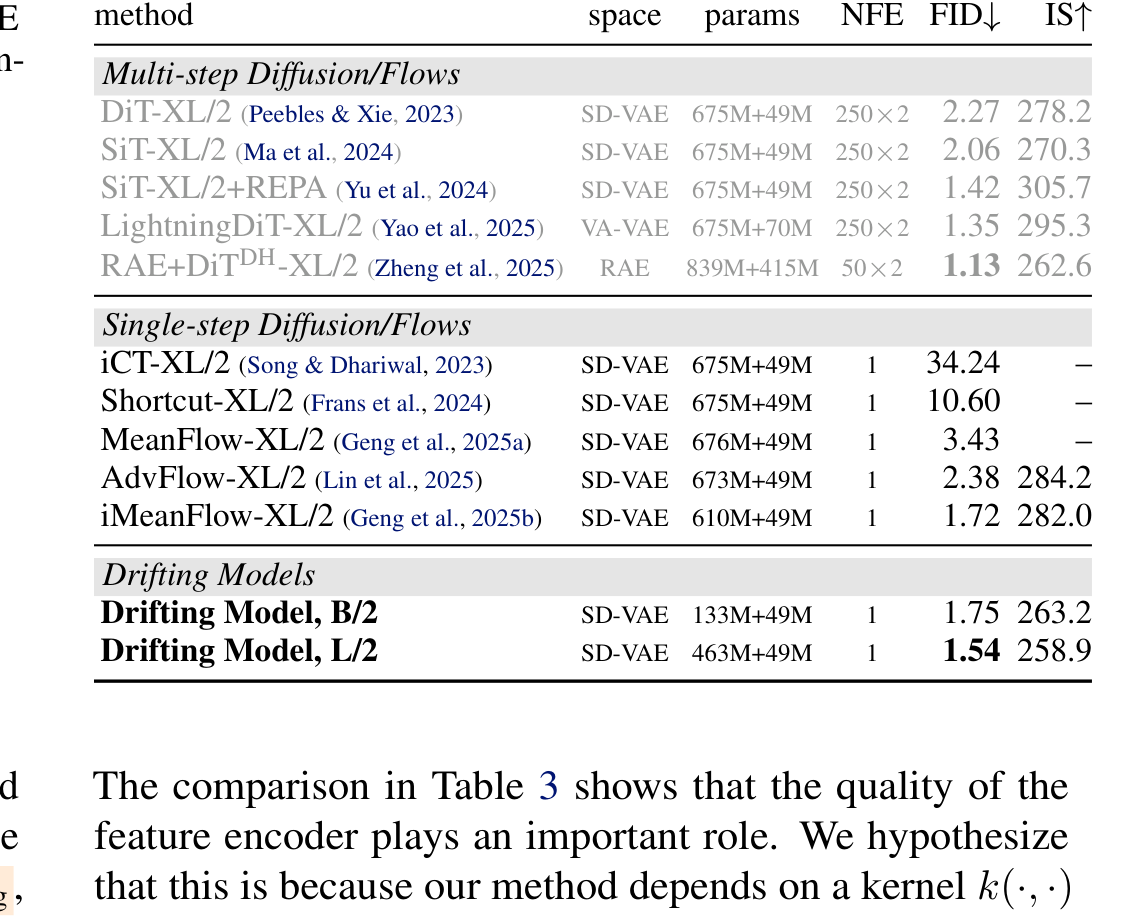
Table 5 解读:latent-space 主结果里,Drifting Model L/2 达到 FID 1.54 / IS 258.9 / 1 NFE,超过之前最强的 one-step diffusion/flow 方法 iMeanFlow-XL/2(FID 1.72),而且参数量只有 463M + 49M。需要注意的是,多步方法里最好结果仍然是 RAE+DiT 的 1.13,因此 Drifting 不是“全面碾压所有多步方法”,而是在 one-step regime 里显著领先。
![]()
Table 6 解读:pixel-space 结果更说明方法的普适性。Drifting Model L/16 在 1 NFE 下做到 FID 1.61 / IS 307.5。它显著优于已有 one-step pixel generator(如 EPG-L/16 的 8.82),也优于多数多步 pixel diffusion baseline;但若和最强多步 SiD2 UViT/1(1.38)相比,仍有差距。因此更准确的说法是:Drifting 在 pixel space 已经非常强,但并未彻底终结多步方法。
主结果可概括成:
| Setting | NFE | FID | IS | 结论 |
|---|---|---|---|---|
| Latent B/2 | 1 | 1.75 | 263.2 | 小模型就已接近 prior SOTA |
| Latent L/2 | 1 | 1.54 | 258.9 | one-step latent 新 SOTA |
| Pixel B/16 | 1 | 1.76 | 299.7 | 远好于既有 one-step pixel 方法 |
| Pixel L/16 | 1 | 1.61 | 307.5 | 与强多步方法竞争 |
5.3 关键消融
(1) Anti-symmetry 不是装饰项,而是成败关键。
- 默认 anti-symmetric drift:8.46 FID
- 1.5× attraction:41.05
- 1.5× repulsion:46.28
- attraction-only:177.14
这说明 equilibrium 的结构约束几乎是方法成立的前提。
(2) Positive / negative sample 数量越大越好。
- 固定 , 从 1 增加到 64,FID 从 20.43 → 8.46
- 固定计算预算下增加 ,FID 从 11.82 → 8.46
本质上这是在提高 drift estimate 的 Monte Carlo 精度。
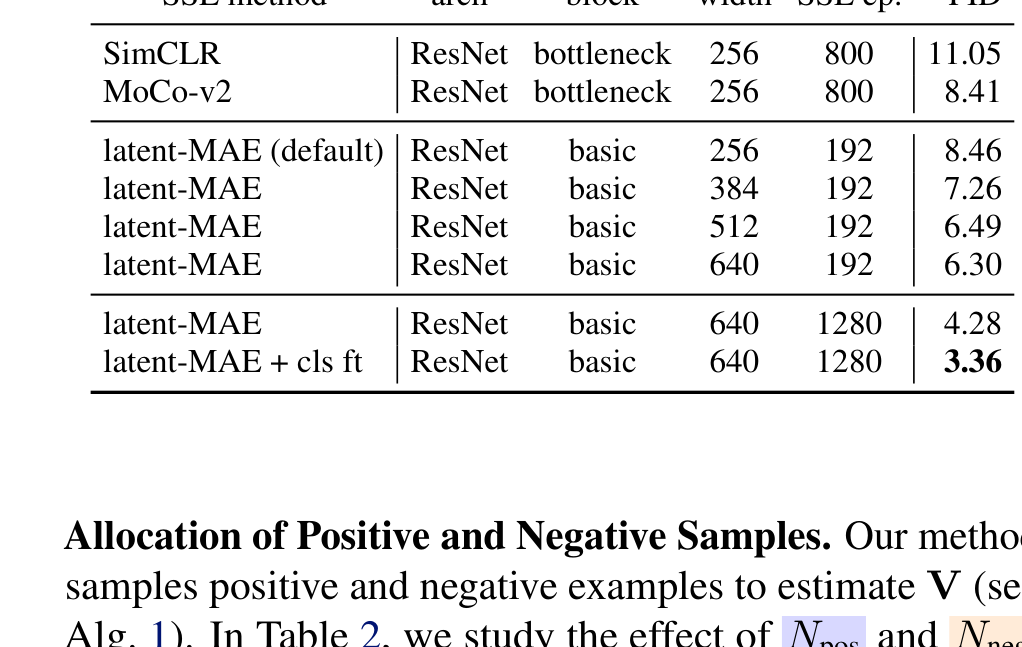
Table 3 解读:feature encoder 质量极其关键。SimCLR 只能做到 11.05,MoCo-v2 是 8.41,而 latent-MAE 宽度增大、训练更久后能到 4.28,再加上 classifier fine-tuning 到 3.36。作者还明确说:在 ImageNet 上不使用 feature encoder,他们没能把方法跑通。
(3) 从 ablation 配置到最终结果的增益链条非常清楚。
- baseline:3.36
- longer training:2.51
- longer + hyper-param:1.75
- larger model(L/2):1.54
这说明该方法不是只在小规模 toy / ablation setting 有效,而是能随着模型规模和训练时长继续吃到 scaling benefit。
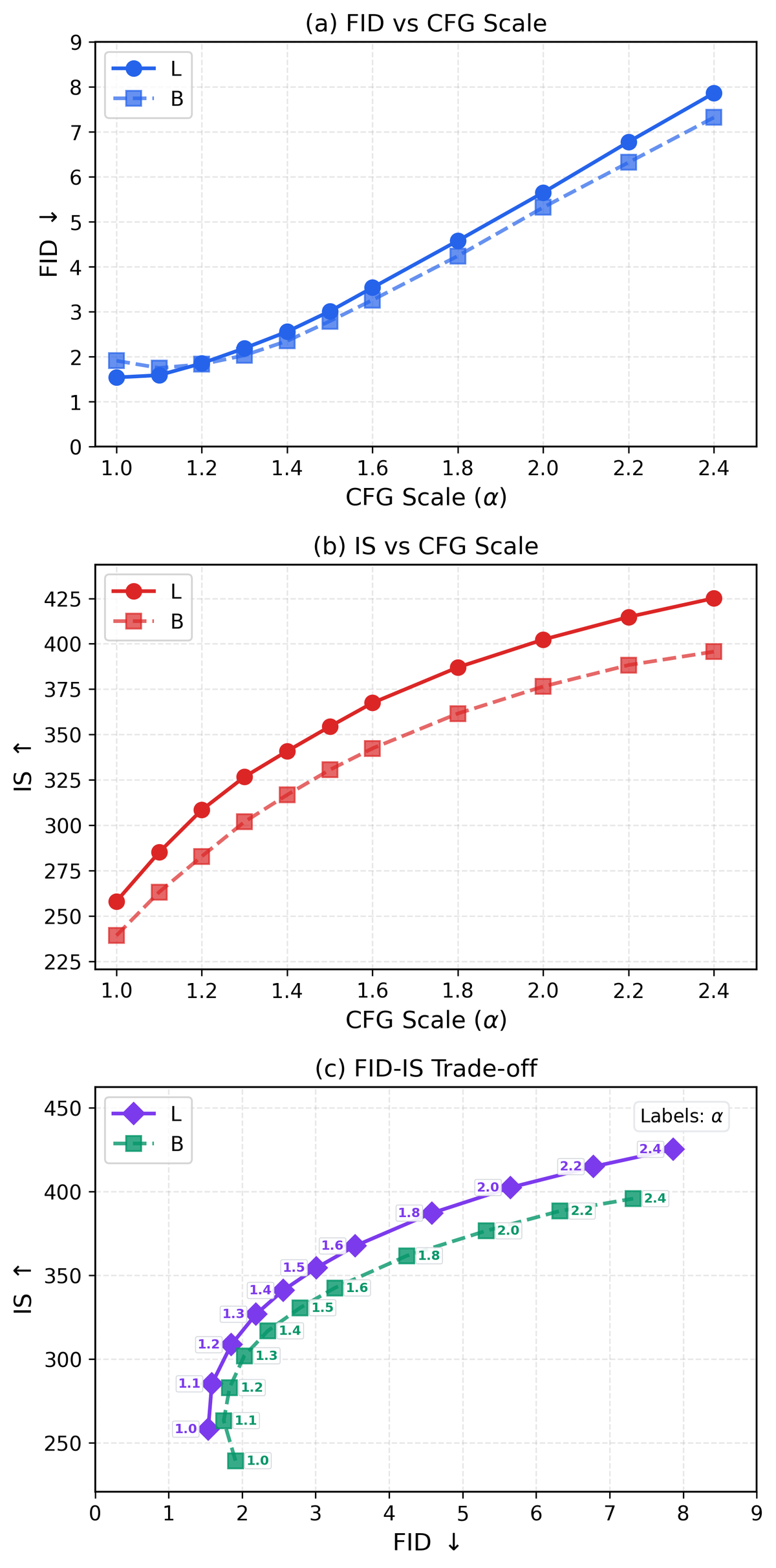
Figure 5 解读:CFG 在 Drifting Models 里也体现出和 diffusion 类似的 trade-off:增大 会提升 IS,但会恶化 FID。一个很有意思的现象是,L/2 的最优 FID 恰好出现在 ,也就是“看起来像 no-CFG”的位置。这说明它的 CFG 主要已经在 training-time negative mixture 中发挥作用,而不是靠测试时强行拉条件。
5.4 Robotics:从图像生成迁移到控制也成立
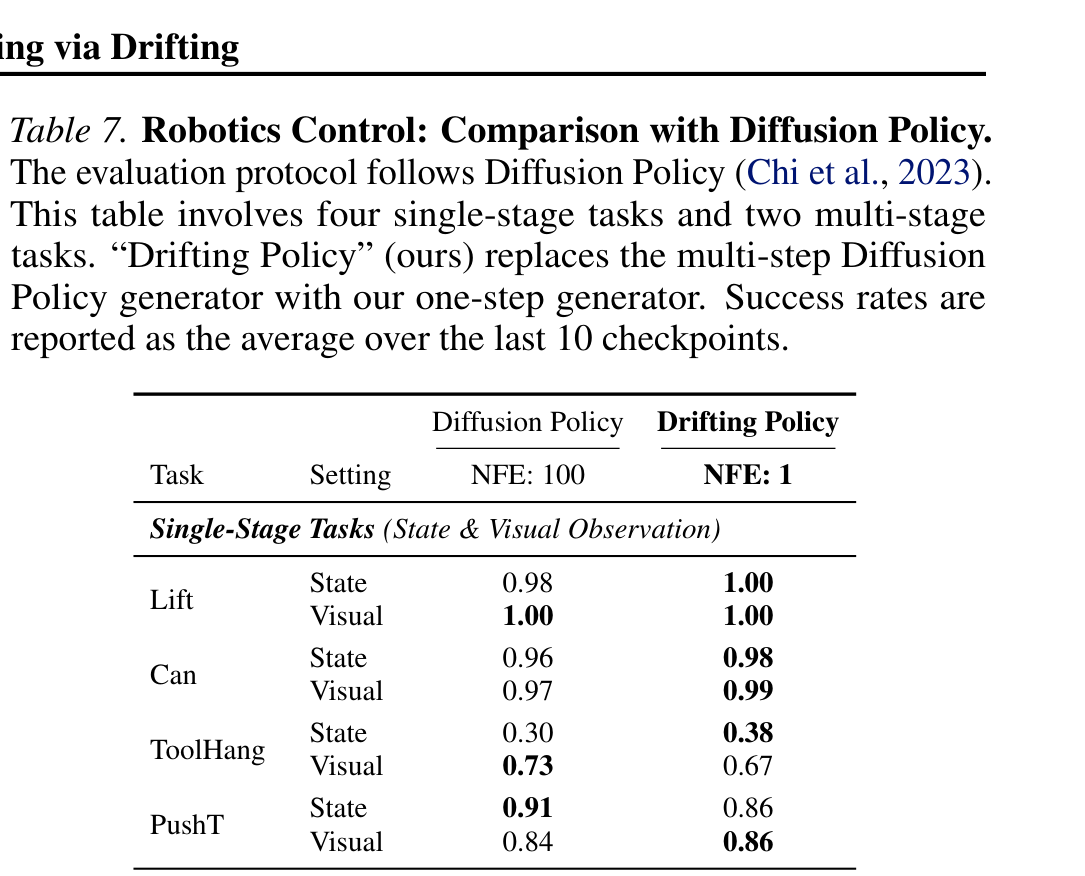
Table 7 解读:作者把 Diffusion Policy 的多步 generator 直接替换为 one-step Drifting Policy,在 1 NFE 下仍能匹配甚至超过 100 NFE 的 Diffusion Policy。比如 Lift(state) 从 0.98 升到 1.00,Can(visual) 从 0.97 升到 0.99,BlockPush phase 2 从 0.11 升到 0.16。但也不是全面占优,例如 ToolHang(visual) 从 0.73 降到 0.67,PushT(state) 从 0.91 降到 0.86。总体结论是:Drifting 不是只适合图像 FID 的技巧,而是一个更广义的生成建模训练机制。
5.5 局限性
论文和代码都暴露了几个很真实的限制:
- 理论还不闭合:作者只证明了 ,而不是一般性地证明 。
- 强依赖 feature encoder:在 ImageNet 上若没有好的 representation,kernel 会变“太平”,drift 不够有效。
- 很多设计仍是 heuristic:kernel 形式、温度列表、feature normalization、drift normalization、sample queue、CFG mixing 都还有继续优化空间。
- 目前验证集中在 class-conditional ImageNet:虽然 robotics 结果不错,但视觉生成主实验仍然比较集中在一个标准 benchmark。
- 训练代价依然很大:虽然推理是一步,但训练侧明显依赖长时训练、大 batch、强表征器和 TPU-friendly JAX 实现。
5.6 Overall Conclusion
我对这篇论文的总体评价是:它提出的是一个“范式级”想法,而不是单纯的 one-step trick。
它最有价值的地方在于:
- 重新解释了 generator training:不是学一个静态映射,而是让 pushforward distribution 在训练中持续演化;
- 用 drifting field 把“分布不匹配”转换成“样本该往哪走”的局部向量场;
- 在这个新视角下,自然得到 1-NFE inference,而且结果真的足够强。
如果后续有人把这套思想进一步和更强的 representation learning、video generation、multimodal generation 甚至 world model 结合,这条路线很可能会继续发展。