DMD2: Improved Distribution Matching Distillation for Fast Image Synthesis
Authors: Tianwei Yin, Michael Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, William T. Freeman Affiliations: MIT, Adobe Research arXiv: 2405.14867 Project Page: tianweiy.github.io/dmd2 GitHub: tianweiy/DMD2 Venue: NeurIPS 2024 (Oral)
1. Motivation (研究动机)
1.1 问题背景
Diffusion model 生成质量出色,但采样需要数十到数百步迭代去噪,推理成本极高。蒸馏 (distillation) 是主流加速方案,目标是将多步 teacher diffusion model 压缩为 one-step 或 few-step 的 student generator。
现有蒸馏方法大致分两类:
- 轨迹匹配 (trajectory matching):如 Progressive Distillation、Consistency Distillation,让 student 学习 teacher 的 ODE 采样轨迹。需要 noise-image pair 的 regression loss,学生质量被 teacher 上限约束。
- 分布匹配 (distribution matching):如 DMD (Distribution Matching Distillation),直接对齐 student 和 teacher 的输出分布(KL 散度),不强制 one-to-one 轨迹对应。
1.2 DMD 的关键局限
DMD [Yin et al., 2024] 虽然取得了 SOTA 的 one-step 生成结果,但存在三个核心问题:
-
依赖 regression loss + 昂贵数据集:仅用 distribution matching loss 训练不稳定,需要额外的 regression loss 来稳定训练。这要求预先用 teacher 的 deterministic sampler 生成数百万 noise-image pairs(对 SDXL 需要约 700 A100-days),成本极高,且将 student 质量锁定在 teacher 的采样路径上。
-
仅支持 one-step 生成:无法扩展到 multi-step,对 SDXL 等大模型,one-step 映射过于复杂,质量受限。
-
训练-推理不匹配:multi-step 方法在训练时用真实图像加噪作为中间步输入,推理时中间步来自 student 自身生成,存在 domain gap。
1.3 核心矛盾
DMD 的 distribution matching 理念(不约束具体采样路径,只匹配分布)与 regression loss 的 trajectory-binding 本质上矛盾——regression loss 强迫 student 复现 teacher 的特定采样路径,限制了 student 超越 teacher 的可能性。
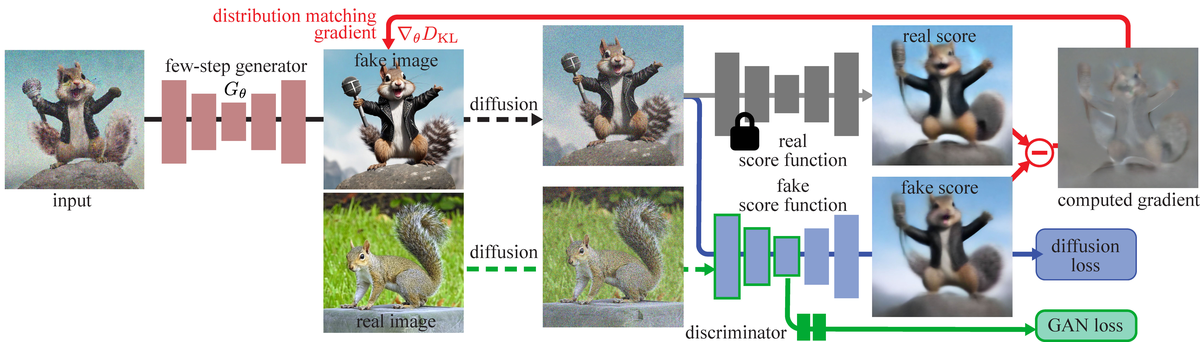
Figure 3 解读:DMD2 整体训练流程。左侧:few-step generator 从噪声生成图像(红色路径),同时用真实图像(绿色路径)做 GAN 训练。右侧:两个 score function——frozen real score (预训练 teacher)和 trainable fake score (在线训练的 critic),两者的差作为 distribution matching gradient(红色箭头)。下方:GAN discriminator 在 fake UNet 的 bottleneck 上加 classification head,区分真假图像(绿色箭头)。训练交替进行两步:(1) 用 DM gradient + GAN loss 更新 generator;(2) 用 denoising loss + GAN classification loss 更新 fake score function 和 discriminator。关键改进:fake score 的更新频率是 generator 的 5 倍(two time-scale update rule)。
2. Idea (核心思想)
2.1 核心洞察一:训练不稳定的根源是 fake critic 跟不上 generator
论文发现,去掉 regression loss 后训练不稳定(亮度/色彩剧烈波动、FID 不收敛),根本原因是 fake diffusion model 无法准确估计快速变化的 generator 输出分布。由于 generator 每步都在更新,fake score function 需要实时跟踪一个 non-stationary 分布,用相同的更新频率会导致 score 估计不准,进而产生有偏梯度。
解决方案:Two Time-scale Update Rule (TTUR)——让 fake score 的更新频率高于 generator(5:1),确保 critic 始终准确跟踪 generator 分布。
2.2 核心洞察二:GAN loss 弥补 teacher score 的近似误差
即使有了 TTUR,student 质量仍被 real score function(即 teacher diffusion model)的近似误差限制。Teacher 并不是数据分布的完美 score estimator,其误差会传导到 student。
解决方案:引入 GAN loss,discriminator 直接在真实图像和生成图像之间判别。GAN loss 不依赖 teacher,直接从真实数据获取监督信号,可以弥补 teacher 的 score 近似误差,甚至使 student 超越 teacher。
2.3 核心洞察三:Backward Simulation 消除训练-推理不匹配
Multi-step 蒸馏方法普遍存在 train/test domain gap:训练时中间步输入是真实图像加噪,推理时是 student 自身生成的中间结果。
解决方案:Backward Simulation——训练时不用真实图像加噪,而是让 student generator 从纯噪声开始实际运行几步,用其输出作为中间步输入。这样训练和推理看到的分布完全一致。

Figure 4 解读:左侧(传统方法):训练时用真实图像做 forward diffusion 得到中间步噪声输入,但推理时中间步来自 student 的 backward process,两者存在 domain gap(红色虚线框)。右侧(DMD2 的 Backward Simulation):训练时直接模拟推理过程——student 从噪声出发做 backward sampling 生成 “fake” 中间步样本,然后在这些样本上继续去噪并计算 loss。这样训练和推理的输入分布完全对齐(绿色框)。
3. Method (方法)
3.1 Background:DMD 的 Distribution Matching Loss
DMD 的核心是最小化 diffused 分布之间的 KL 散度。对于 generator ,其梯度可以表示为两个 score function 的差:
其中 是预训练 teacher(frozen), 是在 generator 输出上动态训练的 fake score function, 是 forward diffusion(加噪)。
在实现中,distribution matching gradient 被计算为:
其中 , 分别是 real/fake UNet 从加噪图像预测的干净图像。
3.2 改进一:去除 Regression Loss + TTUR 稳定训练
原始 DMD 需要:
DMD2 直接去掉 ,但用 TTUR 稳定训练:每 1 次 generator 更新对应 5 次 fake score 更新。
# 伪代码:Two Time-scale Update Rule
for iteration in range(total_iterations):
# ---- Fake Score / Guidance 更新 (5 次) ----
for _ in range(5): # fake_score_updates_per_generator_step
z = sample_noise()
fake_images = generator(z).detach() # 不回传梯度到 generator
# 1. Denoising score matching loss: 让 fake_unet 学会对 fake_images 去噪
t = sample_timestep()
noisy_fake = add_noise(fake_images, t)
pred_noise = fake_unet(noisy_fake, t)
loss_denoise = MSE(pred_noise, added_noise)
# 2. GAN discriminator loss: 区分真假
logits_real = discriminator(real_images)
logits_fake = discriminator(fake_images)
loss_disc = softplus(logits_fake).mean() + softplus(-logits_real).mean()
update(fake_unet, discriminator, loss_denoise + loss_disc)
# ---- Generator 更新 (1 次) ----
z = sample_noise()
fake_images = generator(z)
# Distribution Matching gradient
t = sample_timestep()
noisy = add_noise(fake_images, t)
pred_real = real_unet(noisy, t).detach() # frozen teacher
pred_fake = fake_unet(noisy, t).detach() # 只用来提供梯度方向
grad = normalize(pred_fake - pred_real)
loss_dm = 0.5 * MSE(fake_images, (fake_images - grad).detach())
# GAN generator loss
logits_fake = discriminator(fake_images)
loss_gen = softplus(-logits_fake).mean()
update(generator, loss_dm + loss_gen)3.3 改进二:GAN Loss 集成
GAN objective 采用标准 non-saturating loss,discriminator 加在 fake UNet 的 bottleneck 特征上:
Discriminator 架构极其简洁——在 fake UNet bottleneck(1280 维)上加一个小型 classification head:
# GAN Discriminator: 在 UNet bottleneck 上的分类头
self.cls_pred_branch = nn.Sequential(
nn.Conv2d(1280, 1280, kernel_size=4, stride=2, padding=1),
nn.GroupNorm(32, 1280),
nn.SiLU(),
nn.Conv2d(1280, 1, kernel_size=1, stride=1, padding=0),
)设计亮点:
- 复用 fake UNet 的特征提取能力,不需要独立 discriminator
- 对加噪图像判别(而非干净图像),天然利用 diffusion 的 noise injection 稳定 GAN 训练
- GAN loss 独立于 teacher,不受 teacher score 近似误差影响
3.4 改进三:Multi-step Generator + Backward Simulation
Multi-step 推理:固定 个 timestep ,从纯噪声 开始,交替做去噪和加噪:
4-step model 使用 schedule: (对应 1000 步 teacher)。
Backward Simulation 训练:
# 伪代码:Backward Simulation for Multi-step Training
def backward_simulation_training(generator, real_unet, fake_unet, discriminator):
z = sample_noise() # 纯噪声起点
# 从 denoising_step_list 中随机选择一个起始步
selected_step = random.choice(range(len(denoising_step_list)))
# 模拟推理:student 自身做几步 backward sampling(no grad)
noisy_image = z
with torch.no_grad():
for i in range(selected_step):
t = denoising_step_list[i]
pred_noise = generator(noisy_image, t)
pred_clean = get_x0_from_noise(noisy_image, pred_noise, t)
# 加噪到下一步
next_t = denoising_step_list[i + 1]
noisy_image = add_noise(pred_clean, next_t)
# 在模拟得到的中间步上训练(有梯度)
t_current = denoising_step_list[selected_step]
pred_noise = generator(noisy_image, t_current)
pred_clean = get_x0_from_noise(noisy_image, pred_noise, t_current)
# 对 pred_clean 计算 DM loss + GAN loss(同 3.2 节)
loss = compute_dm_loss(pred_clean, real_unet, fake_unet, t_current)
loss += compute_gan_loss(pred_clean, discriminator, t_current)
loss.backward()3.5 完整训练流程总结
DMD2 的完整 loss 为:
训练交替执行:
- Guidance turn (5x):更新 fake UNet + discriminator head
- Generator turn (1x):更新 student generator
代码对应 (main/train_sd.py → train_one_step):
def train_one_step(self):
# Generator turn
noise = torch.randn(batch_size, 4, latent_h, latent_w)
loss_dict, log_dict = self.model(
noise, text_embedding, real_image,
generator_turn=True, guidance_turn=False
)
loss = loss_dict["loss_dm"] + args.cls_loss_weight * loss_dict["gen_cls_loss"]
loss.backward()
generator_optimizer.step()
# Guidance turn (called more frequently via outer loop)
loss_dict, log_dict = self.model(
noise, text_embedding, real_image,
generator_turn=False, guidance_turn=True
)
loss = loss_dict["loss_fake_mean"] + args.cls_loss_weight * loss_dict["loss_cls"]
loss.backward()
guidance_optimizer.step()代码对应 (main/sd_guidance.py → DM loss 计算):
# Distribution Matching Loss 核心计算
pred_real_noise = predict_noise(self.real_unet, noisy_latents, timesteps, ...)
pred_real_image = get_x0_from_noise(noisy_latents, pred_real_noise, alphas_cumprod, timesteps)
pred_fake_noise = predict_noise(self.fake_unet, noisy_latents, timesteps, ...)
pred_fake_image = get_x0_from_noise(noisy_latents, pred_fake_noise, alphas_cumprod, timesteps)
p_real = latents - pred_real_image # real score direction
p_fake = latents - pred_fake_image # fake score direction
# Normalized gradient
grad = (p_real - p_fake) / torch.abs(p_real).mean(dim=[1,2,3], keepdim=True)
loss_dm = 0.5 * F.mse_loss(original_latents, (original_latents - grad).detach())代码对应 (main/sd_guidance.py → GAN discriminator):
# GAN 判别
rep = self.fake_unet.forward(noisy_latents, timesteps, ..., classify_mode=True)
logits = self.cls_pred_branch(rep).squeeze(dim=[2, 3])
# Discriminator loss
loss_cls = F.softplus(pred_realism_on_fake).mean() + F.softplus(-pred_realism_on_real).mean()
# Generator loss
loss_gen = F.softplus(-pred_realism_on_fake_with_grad).mean()代码对应 (main/sd_unified_model.py → Backward Simulation):
def sample_backward(self, noisy_image, text_embedding, pooled_text_embedding):
for constant in self.denoising_step_list[:selected_step]:
generated_noise = self.feedforward_model(noisy_image, constant, ...)
generated_image = get_x0_from_noise(noisy_image, generated_noise, ...)
noisy_image = self.noise_scheduler.add_noise(generated_image, noise, next_step)
return noisy_image4. Experimental Setup (实验设置)
4.1 Class-conditional Generation (ImageNet-64x64)
- Teacher: EDM (Karras et al., 2022),511 步 ODE sampler
- Student: 与 teacher 同架构的 UNet,one-step generator
- 训练数据: ImageNet-64x64 训练集
- 评估: FID(50K 生成 vs 全部训练集)
4.2 Text-to-Image Synthesis (COCO 2014)
- Teacher: SDXL / Stable Diffusion v1.5
- Student: 与 teacher 同架构,支持 1-step 和 4-step
- 训练 prompts: 3M subset from LAION-Aesthetics
- GAN 真实图像: 500K from LAION-Aesthetic
- 评估: FID、Patch FID(299x299 center crop)、CLIP Score(10K zero-shot COCO prompts)
- 4-step schedule:
4.3 Baselines
- Trajectory-based: Progressive Distillation, Consistency Model, iCT-deep, CTM
- Distribution-based: DMD (original)
- GAN-based: SDXL-Turbo (ADD), SDXL-Lightning, LCM-SDXL
- Hybrid: TRACT, BOOT, Diff-Instruct
4.4 Human Evaluation
- 128 prompts from PartiPrompts
- 5 位评估者对比 Image Quality 和 Prompt Alignment
- 与 SDXL-LCM、SDXL-Turbo、SDXL-Lightning、SDXL Teacher 对比
5. Experimental Results (实验结果)
5.1 ImageNet-64x64 Class-conditional Generation
| Method | # Fwd Pass | FID |
|---|---|---|
| BigGAN-deep | 1 | 4.06 |
| StyleGAN-XL | 1 | 1.52 |
| Consistency Model | 1 | 6.20 |
| iCT-deep | 1 | 3.25 |
| CTM | 1 | 1.92 |
| DMD (original) | 1 | 2.62 |
| DMD2 (Ours) | 1 | 1.51 |
| DMD2 +longer training | 1 | 1.28 |
| EDM Teacher (ODE) | 511 | 2.32 |
| EDM Teacher (SDE) | 511 | 1.36 |
关键发现:
- DMD2 one-step FID 1.28,超越了 511 步 teacher(ODE: 2.32),是首个 one-step generator 在 ImageNet-64x64 上超越 teacher 的方法
- 比 original DMD 提升 1.34 FID points(2.62 → 1.28)
- 比同为 one-step 的 CTM 提升 0.64 points
5.2 SDXL Text-to-Image (COCO 2014)
| Method | # Steps | FID | Patch FID | CLIP |
|---|---|---|---|---|
| LCM-SDXL | 1 / 4 | 81.62 / 22.16 | 154.40 / 33.92 | 0.275 / 0.317 |
| SDXL-Turbo | 1 / 4 | 24.57 / 23.19 | 23.94 / 23.27 | 0.337 / 0.334 |
| SDXL-Lightning | 1 / 4 | 23.92 / 24.46 | 31.65 / 24.56 | 0.316 / 0.323 |
| DMD2 (Ours) | 1 / 4 | 19.01 / 19.32 | 26.98 / 20.86 | 0.336 / 0.332 |
| SDXL Teacher (cfg=6) | 100 | 19.36 | 21.38 | 0.332 |
| SDXL Teacher (cfg=8) | 100 | 20.39 | 23.21 | 0.335 |
关键发现:
- DMD2 4-step FID 19.32,接近 100 步 teacher(19.36),仅用 4% 的计算量
- 1-step FID 19.01 甚至优于 teacher,可能因为 GAN loss 修正了 teacher 的 score 误差
- Patch FID 20.86 超越所有竞争方法和 teacher,表明生成的高频细节质量更高
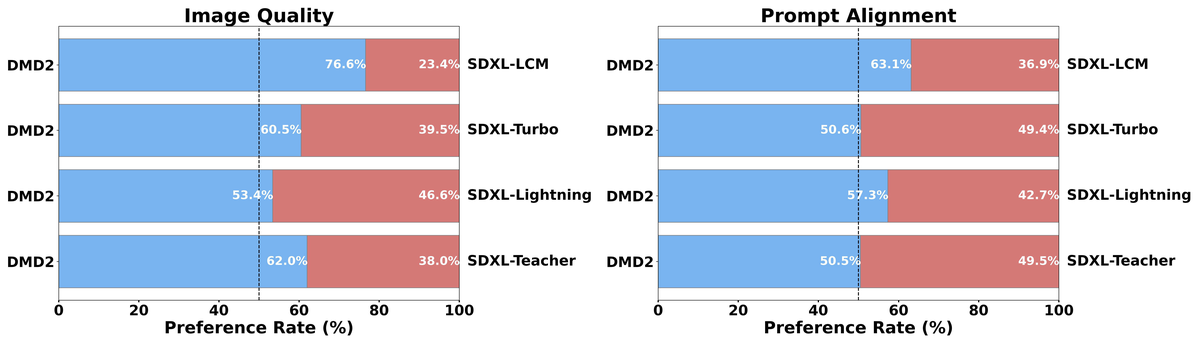
Figure 5 解读:用户偏好评估(128 prompts x 5 评估者)。左图 Image Quality:DMD2 在所有对比中都获得更高偏好率——vs SDXL-LCM(76.6%)、vs SDXL-Turbo(60.5%)、vs SDXL-Lightning(53.4%)、甚至 vs 50 步 SDXL Teacher(62.0%)。右图 Prompt Alignment:DMD2 同样全面领先,但优势略小——vs Teacher 为 50.5% 略高于 49.5%。所有蒸馏模型均使用 4 步,teacher 使用 50 步。这证明 DMD2 在 25 倍加速下不仅不降质,还能超越 teacher。
5.3 Ablation Studies
ImageNet Ablation (Table 3):
| DMD | No Regress. | TTUR | GAN | FID |
|---|---|---|---|---|
| yes | 2.62 | |||
| yes | yes | 3.48 | ||
| yes | yes | yes | 2.61 | |
| yes | yes | yes | yes | 1.51 |
| yes | 2.56 | |||
| yes | yes | 2.52 |
- 直接去掉 regression loss:FID 从 2.62 恶化到 3.48(不稳定)
- 加入 TTUR:恢复到 2.61,匹配原始 DMD(无需数据集构建)
- 加入 GAN:大幅提升到 1.51,比单独 GAN(2.56)或 DM+TTUR(2.61)都好
- DM + GAN 的组合效果远超各自单独使用
SDXL Ablation (Table 4):
| Method | FID | Patch FID | CLIP |
|---|---|---|---|
| w/o GAN | 26.90 | 27.66 | 0.328 |
| w/o Distribution Matching | 13.77 | 27.96 | 0.307 |
| w/o Backward Simulation | 20.66 | 24.21 | 0.332 |
| DMD2 (Full) | 19.32 | 20.86 | 0.332 |
- 去掉 GAN:质量大幅下降(FID 19.32 → 26.90),图像过度饱和/模糊
- 去掉 DM:FID 看似不错(13.77)但 CLIP score 极低(0.307),说明 mode collapse / 缺乏多样性
- 去掉 Backward Simulation:Patch FID 恶化(20.86 → 24.21),高频细节退化

Figure 7 解读:SDXL 定性 ablation。四列分别是 DMD2 (Full)、w/o Distribution Matching、w/o GAN、w/o Backward Simulation。五行不同 prompt。去掉 DM(第二列):图像风格/构图偏差大,文本对齐差。去掉 GAN(第三列):图像过度饱和、过度平滑、缺乏真实感。去掉 Backward Simulation(第四列):细节质量下降但整体可接受。完整 DMD2(第一列)在真实感、细节和文本对齐上都最佳。

Figure 6 解读:与竞争方法的视觉对比。四行不同 prompt,五列分别是 DMD2、LCM、Turbo、Lightning、Teacher。所有蒸馏模型 4 步,teacher 50 步。DMD2 在真实感和 prompt alignment 上显著优于其他蒸馏方法:如 “llama wearing sunglasses on a spaceship” DMD2 生成的太空背景更逼真;“shiba inu wearing a beret” DMD2 的毛发纹理更自然;“young girl playing piano” DMD2 的构图和人物表情更生动。

Figure 1 解读:DMD2 4-step generator 蒸馏自 SDXL 生成的 1024x1024 高质量样本展示。包含人像(小女孩、老人)、动物(骑马、金刚、树懒)、场景(纽约时代广场泰迪熊、帝国大厦)、食物(西瓜)等多种类别,展示了方法在多样化 prompt 下生成高分辨率、高质量图像的能力。

Figure (ImageNet Visual) 解读:ImageNet-64x64 上的 one-step 生成样本。包含不同类别(火烈鸟、金鱼、蘑菇、蝴蝶、教堂、狗等),展示了方法在 class-conditional 生成中的高质量和多样性。FID 1.28 的定量结果在这些样本中得到了直观验证。
5.4 SD v1.5 结果
DMD2 同样适用于较小模型:在 SD v1.5 上实现 one-step FID 8.35(COCO 2014 zero-shot),比原始 DMD 的 11.49 提升 3.14 points,也超越了使用 50 步 PNDM sampler 的 teacher model。
总结
DMD2 通过三个关键改进将 Distribution Matching Distillation 推向新高度:
-
去除 regression loss + TTUR:消除了昂贵的数据集构建需求(节省约 700 A100-days for SDXL),同时通过 two time-scale update rule 保持训练稳定性。核心洞察是 fake critic 需要比 generator 更快地更新以准确跟踪非平稳分布。
-
GAN loss 集成:在 fake UNet bottleneck 上加 classification head,直接从真实数据获取监督信号,突破了 teacher score function 近似误差的限制,使 student 首次能够超越 teacher。
-
Backward Simulation:训练时模拟推理时的 backward process,消除 multi-step 蒸馏中的 train/test domain gap,提升高频细节质量。
最终实现:ImageNet-64x64 one-step FID 1.28(超越 511 步 teacher),SDXL 4-step FID 19.32(匹敌 100 步 teacher),推理加速 500 倍。
Limitations:(1) 图像多样性略低于 teacher(diversity-quality tradeoff);(2) SDXL 仍需 4 步才能匹配 teacher 质量;(3) 使用固定 guidance scale,缺乏灵活性;(4) 训练仍需大量计算资源(但已比 DMD 大幅降低)。