QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
Authors: Weizhou Shen*, Ziyi Yang*, Chenliang Li*, Zhiyuan Lu, Miao Peng, Huashan Sun, Yingcheng Shi, Shengyi Liao, Shaopeng Lai, Bo Zhang, Dayiheng Liu, Fei Huang, Jingren Zhou, Ming Yan† Affiliations: Tongyi Lab, Alibaba Group arXiv: 2512.12967 GitHub: Tongyi-Zhiwen/Qwen-Doc
1. Motivation (研究动机)
-
长上下文推理的关键缺口:尽管 LLM 的上下文窗口不断扩展,但现有工作主要集中在 pre-training 和 mid-training 阶段的上下文延伸,或架构层面的改进。post-training 阶段缺乏一套成熟的端到端系统,包括:(1) 高质量长上下文推理数据的合成 pipeline;(2) 适配长上下文训练的 RL 方法;(3) 能超越物理上下文窗口的 agent 架构。
-
现有数据合成方法局限:大多数方法仅生成简单的 “needle-in-a-haystack” 检索任务或 single-hop RAG 任务,无法训练模型进行跨文档多跳推理和全局信息聚合。
-
长上下文 RL 训练不稳定:传统 GRPO 在长上下文多任务训练中面临严重的不稳定性问题——多类型任务的 reward 分布差异大,随机采样导致 mini-batch 内分布不均衡,高熵 token 产生的大梯度进一步加剧训练振荡。
-
物理上下文窗口限制:即使扩展到 256K,仍无法处理 1M~4M token 级别的超长任务,需要 memory management 机制来突破物理窗口限制。
2. Idea (核心思想)
QwenLong-L1.5 提出了一套完整的 post-training recipe,包含三大核心创新:
- 数据合成 Pipeline:通过 Knowledge Graph 多跳推理、Structural Tabular Data Engine 数值推理、Multi-Agent Self-Evolved (MASE) 框架通用推理,三条路径系统性生成高质量长上下文 RL 训练数据。
- 稳定化 RL 训练:提出 Task-Balanced Sampling + Task-Specific Advantage Estimation + Adaptive Entropy-Controlled Policy Optimization (AEPO),从采样、优势估计、梯度控制三个层面解决长上下文 RL 的不稳定性。
- Memory-Augmented 架构:将超长文档分块处理,模型迭代更新 memory 并生成导航计划,通过 trajectory-level GRPO 优化,将能力扩展到 4M token。
与 QwenLong-L1 相比,核心差异在于:数据规模从 1.6K 扩展到 14.1K,引入合成数据;RL 算法从 naive GRPO 升级到 AEPO;新增 Memory Agent 能力并通过模型合并统一到单一模型中。
3. Method (方法)
3.1 整体框架
QwenLong-L1.5 基于 Qwen3-30B-A3B-Thinking 模型,采用渐进式多阶段后训练范式:

Figure 6 解读:训练流程分为四个全上下文 RL 阶段和一个 Memory-RL 分支。Stage 1-3 逐步扩展输入/输出长度(20K/12K → 60K/20K → 120K/50K)。在 Stage 3 之后分支训练 Memory-RL 专家(128K 输入,32K chunk,15K memory),然后通过 SCE 算法将 Memory 专家与 Stage 3 模型合并,最终在 Stage 4 进行全上下文融合训练(120K/50K),得到同时具备直接长上下文推理和 Memory Agent 能力的统一模型。
3.2 长上下文数据合成 Pipeline

Figure 4 解读:端到端数据合成框架包含三条并行路径。上方路径:从文档语料库提取跨文档 Knowledge Graph,通过子图采样和三元组混淆生成多跳推理 QA(涵盖因果分析、假设场景等)。中间路径:提取语料表格,通过 Schema 指导和 SQL 操作生成数值推理 QA(统计聚合、数值计算等)。下方路径:MASE 多智能体框架通过 Proposer-Solver-Verifier 迭代自进化生成通用长上下文 QA(观点分析、长上下文学习等)。右侧所有合成数据经过 Knowledge Grounding Check 和 Contextual Robustness Check 两道验证后进入最终 RL 数据集。
3.2.1 多跳推理 QA 合成
三阶段流程:
- KG 构建:从多领域文档抽取三元组 → 跨文档聚合 → 实体/关系聚类精炼
- 推理路径采样:通过 Random Walk 和 BFS 采样关系相关子图,强制路径节点分散在多文档中,并进行实体混淆增加难度(如时间模糊化、机构匿名化)
- 问题生成:基于推理路径生成多范式问答对,涵盖 Multi-fact Reasoning、Temporal Reasoning、Causal Analysis、Hypothetical Scenarios
3.2.2 数值推理 QA 合成
采用 Structural Tabular Data Engine:
- Document Collection → Schema Extraction → Data Table Aggregation → 跨文档统一表格
- 并行生成 NL Queries → NL2SQL 转换 → SQL 执行获取 Ground Truth
- 专攻 Statistical Aggregation、Numerical Calculation、Temporal Reasoning
3.2.3 通用长上下文 QA (MASE 框架)

Figure 5 解读:MASE 多智能体自进化数据合成框架。Document Corpus 与历史 QA 对拼接后输入 Proposer 生成新问题 ,Solver 尝试回答得到预测 ,Verifier 判断语义等价性。通过的 QA 对存入 History Buffer 和 RL Dataset,History Buffer 反馈给 Proposer 指导生成更难更多样的问题,形成迭代自进化循环。
3.2.4 数据验证
所有合成数据必须通过两道检验:
- Knowledge Grounding Check:移除源文档后测试模型能否仅凭内部知识回答——能答对的样本被过滤
- Contextual Robustness Check:在上下文中插入无关文档后验证答案稳定性——pass@k 降为 0 的样本被丢弃
最终从 42.7K 合成样本中筛选出 14.1K 高质量训练样本,平均输入长度 34,231 tokens。
# Data verification pipeline
verified_dataset = []
for q, answer, context in synthesized_pairs:
answer_no_ctx = policy.generate(q)
if is_correct(answer_no_ctx, answer):
continue
extended_context = insert_irrelevant_docs(context)
robust_answers = sample_k(policy.generate(q, extended_context))
if pass_at_k(robust_answers, answer) == 0:
continue
verified_dataset.append((q, answer, context))
return verified_dataset3.3 稳定化长上下文 RL 训练
3.3.1 背景:GRPO
给定 篇文档 和问题 ,目标是优化策略 最大化 KL 正则化期望奖励:
GRPO 采样 个候选回复 ,通过 group-wise z-score 归一化计算优势,无需 value network。在 on-policy 设定(, 单步更新)下,目标简化为:
其中 为 group-relative 优势,采用 token-level policy gradient loss 按总 token 数归一化。
3.3.2 Task-Balanced Sampling
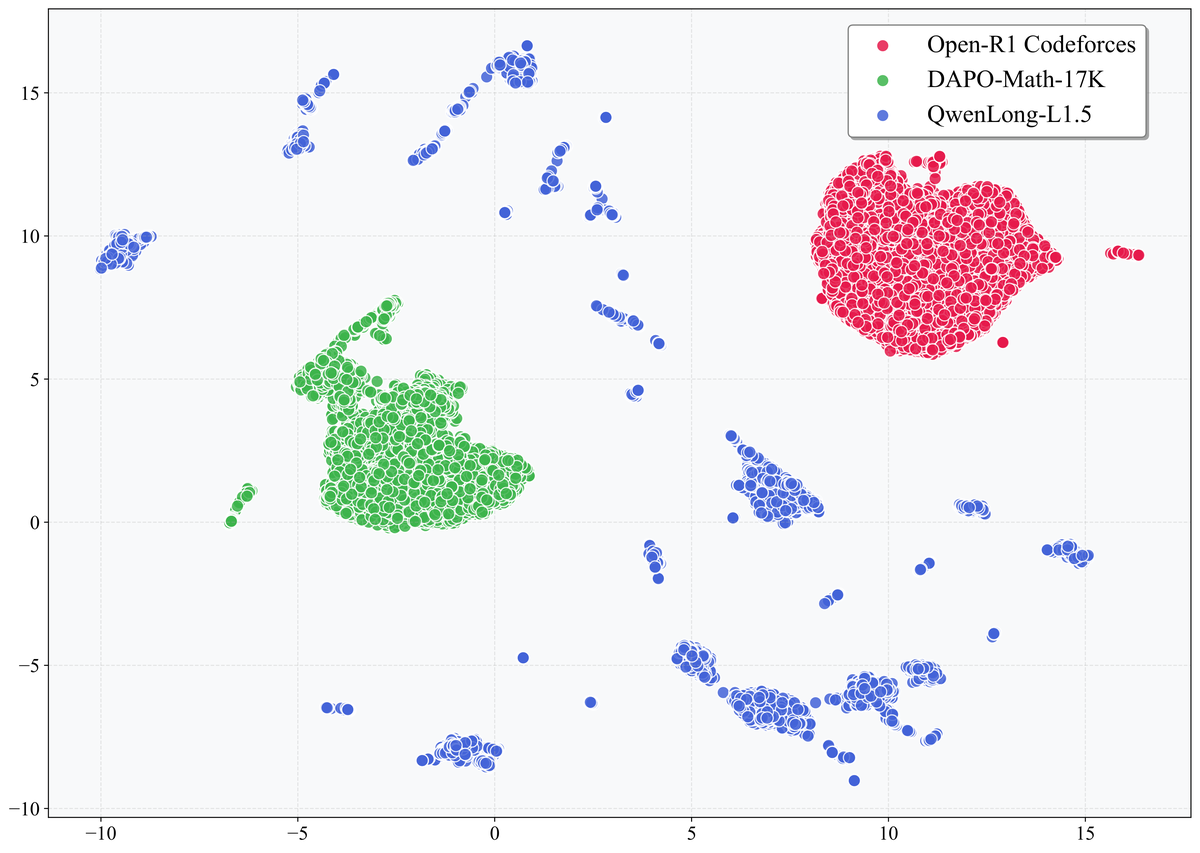
Figure 7 解读:三个数据集(Open-R1 Codeforces、DAPO-Math-17K、QwenLong-L1.5 训练集)的 UMAP 二维投影。传统短上下文 RL 数据(红色、绿色)各自聚成紧凑的单簇,而 QwenLong-L1.5 长上下文数据(蓝色)呈现多簇分布,簇间差异显著。这说明随机采样容易导致 mini-batch 内分布不均,造成训练不稳定。
解决策略:
- 训练前:对各来源数据预推理,按 pass@k 分数分层,各 bin 均匀采样
- 训练中:用
DomainSampler替代随机采样,从 5 类任务(multiple choice, doc multi-hop reasoning, general reading comprehension, dialogue memory, corpus-level numerical calculation)中等量抽取
# Task-balanced sampling
domain_weights = {domain: 1.0 / len(domains) for domain in domains}
domain_counts = {domain: int(batch_size * domain_weights[domain]) for domain in domains}
remaining = batch_size - sum(domain_counts.values())
for domain in sorted(domains, key=lambda d: domain_weights[d], reverse=True):
if remaining == 0:
break
if len(domain_indices[domain]) > domain_counts[domain]:
domain_counts[domain] += 1
remaining -= 1
batch = []
for domain, count in domain_counts.items():
if len(iterator[domain]) < count:
iterator[domain] = refill_and_shuffle(domain_indices[domain])
batch.extend(iterator[domain][:count])
iterator[domain] = iterator[domain][count:]
shuffle(batch)
return batch3.3.3 Task-Specific Advantage Estimation
标准 GRPO 使用 group-level 标准差归一化优势,但在 task-balanced 批次中,不同任务的 reward 分布差异大(如 NIAH 任务 reward 范围 0~1 为稠密型,QA 任务 reward 在 {0,1} 为稀疏型),统一归一化会引入偏差。
改进:将标准差计算范围从 group-level 缩小到 task-level:
即均值仍在 group 内计算(同一 prompt 的 个 rollout),但标准差使用当前 batch 内同任务所有样本的奖励来计算。这样隔离了稠密/稀疏 reward 任务的归一化尺度。
# Task-specific advantage estimation
scores = token_level_rewards.sum(dim=-1)
prompt_mean = {}
task_std = {}
for prompt_id in unique(index):
prompt_scores = scores[index == prompt_id]
prompt_mean[prompt_id] = prompt_scores.mean()
for task in unique(data_source):
task_scores = scores[data_source == task]
task_std[task] = task_scores.std()
advantages = scores.clone()
for i in range(batch_size):
advantages[i] = (scores[i] - prompt_mean[index[i]]) / (task_std[data_source[i]] + eps)
return advantages * response_mask3.3.4 Negative Gradient Clipping
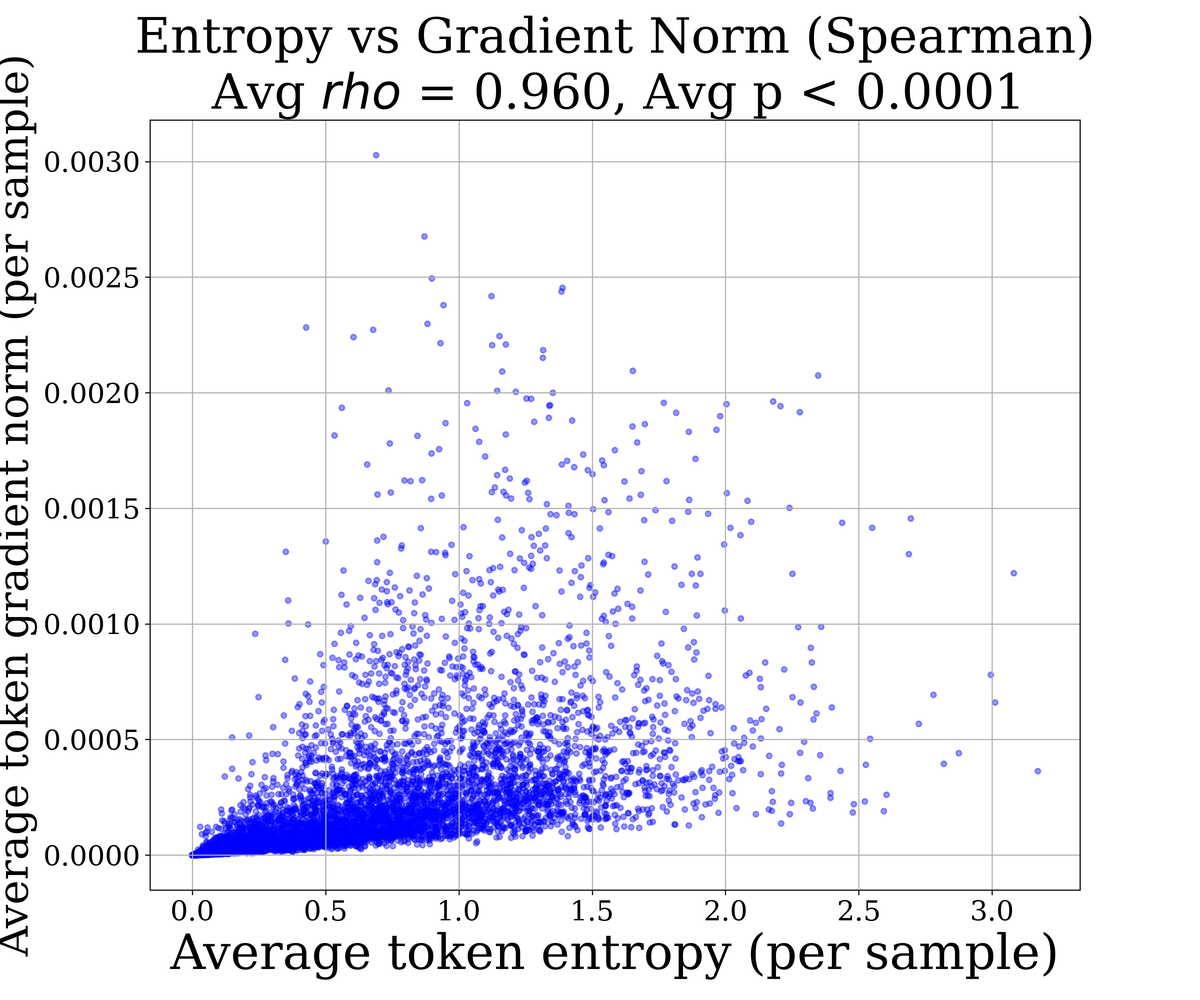
Figure 9 解读:散点图展示负样本 rollout 中每个 token 的平均熵与梯度范数的关系。Spearman 相关系数 ,说明高熵 token 与大梯度范数高度正相关。这些高熵 token 会增加参数更新的方差,导致训练不稳定。
长上下文任务的特殊性:正确/错误回复之间相似度很高(DocMath 的 ROUGE-L 达 45.37),因为模型必须基于相同长上下文推理,错误回复中包含大量正确的中间步骤。过度惩罚这些 token 会损害模型的探索能力。
解决方案:裁剪负样本中高熵 token/序列的梯度贡献:
其中指示函数 定义为:
- :token-level 熵
- :sequence-level 平均熵
 Figure 10a 解读:Token-level:裁剪高熵或低熵 token 都会降低整体熵,但实验表明裁剪高熵 token 效果更好(Table 4 中 +57.02 vs +55.56)。
Figure 10a 解读:Token-level:裁剪高熵或低熵 token 都会降低整体熵,但实验表明裁剪高熵 token 效果更好(Table 4 中 +57.02 vs +55.56)。

Figure 10b 解读:Sequence-level:裁剪高熵序列同样降低熵且更稳定,但裁剪低熵序列可能导致熵坍缩(step 30-40 性能下降)。最终选择 sequence-level 高熵序列裁剪作为最佳策略(Avg 57.36)。
3.3.5 Adaptive Entropy-Controlled Policy Optimization (AEPO)
基于 Negative Gradient Clipping 的发现,AEPO 进一步将动态熵控制提升到 batch 级别:
定义 batch-level 策略熵:
设定目标熵范围 :
- 当 :启用 NGC,mask 所有负优势样本,仅用正样本更新(等价于 advantage-weighted online rejection sampling),降低熵
- 当 :关闭 NGC,重新引入负梯度,防止熵坍缩

Figure 11 解读:AEPO 在 Qwen3-30B-A3B-Thinking 上的熵动态。蓝色(w/ Negative Gradient)和橙色(w/o Negative Gradient)曲线交替出现,说明 AEPO 在 exploration(有负梯度,熵上升)和 exploitation(无负梯度,熵下降)之间自适应切换,维持熵在目标范围内振荡,避免坍缩或爆炸。这种动态平衡使 RL 训练可以稳定扩展到更多步数而不退化。
# AEPO batch filtering
if H_current > H_high:
aepo_ngc_enabled = True
elif H_current < H_low:
aepo_ngc_enabled = False
if aepo_ngc_enabled:
advantages = batch.advantages[:, 0]
rewards = batch.token_level_rewards.sum(dim=-1)
kept_indices = where((advantages > 0) & (rewards > 0))
kept_indices = kept_indices[: (len(kept_indices) // world_size) * world_size]
filtered_batch = batch[kept_indices]
else:
filtered_batch = batch
return filtered_batch3.4 Memory Agent 架构

Figure 2 解读:Memory Agent 工作流程。用户查询首先被分解为核心问题 和格式指令 。长文档被切分为 个 chunk 。在 Memory Pipeline 中,模型依次处理每个 chunk:观察当前 chunk 和历史状态 ,生成新的 memory 更新 和导航计划 。处理完最后一个 chunk 后,将累积 memory 与格式指令 结合生成最终回答。
Sequential Memory Processing 的状态转移:
最终回答生成:
Memory Optimization via RL:采用 trajectory-level GRPO 优化。对每个问题采样 条轨迹 ,其中 。基于最终答案 的正确性计算 trajectory-level reward ,广播到轨迹内所有 action。
3.5 训练阶段详细配置
| Stage | 输入长度 | 输出长度 | 说明 |
|---|---|---|---|
| Full-context RL Stage-1 | 32K | 12K | 基础长上下文推理 |
| Full-context RL Stage-2 | 60K | 20K | 中等长度扩展 |
| Full-context RL Stage-3 | 120K | 50K | 长上下文推理成熟 |
| Memory-RL | 128K input, 32K chunk, 15K memory | - | 独立训练 Memory 专家 |
| Model Merging w/ SCE | - | - | 合并 Stage-3 模型与 Memory 专家 |
| Full-context RL Stage-4 | 120K | 50K | 最终全上下文融合训练 |
阶段间转换策略:采用 difficulty-aware retrospective sampling,使用下一阶段的输入/输出长度设置对训练数据进行难度过滤。
3.6 代码-论文映射表
| Paper Concept | Source File / Location | Key Class/Function |
|---|---|---|
| Task-Balanced Sampling | QwenLong-L1.5/README.md (code snippet) | DomainSampler class |
| Task-Specific Advantage | QwenLong-L1.5/README.md (code snippet) | compute_grpo_task_norm_outcome_advantage() |
| AEPO Algorithm | QwenLong-L1.5/README.md (code snippet) | AEPO entropy control logic in training loop |
| RL Framework | verl v0.4 | VeRL (HybridFlow) |
| Base Model | HuggingFace | Qwen3-30B-A3B-Thinking |
| Training Data (v1) | HuggingFace | QwenLong-L1 数据集 |
4. Experimental Setup (实验设置)
数据集
训练数据:14.1K 高质量样本(从 42.7K 合成样本筛选),来源涵盖代码仓库、学术文献、专业文档、通用知识/文学、对话数据。平均输入长度 34,231 tokens,最大 119,932 tokens。
评测基准(≤128K tokens):
| 类型 | 基准 | 说明 |
|---|---|---|
| Multiple Choice | LongBench-V2 (LBV2) | 503 题,6 类深度理解 |
| NIAH | MRCR | 多轮对话中的多 needle 检索 |
| Multi-hop QA | Frames, LongBench-V1-QA, DocMath, CorpusQA | 跨文档推理、数值推理 |
超长评测(>128K tokens):MRCR 128K512K, 512K1M; CorpusQA 1M, 4M
泛化评测:MMLU-PRO, AIME24/25, GPQA-Diamond (通用); BFCL-V4 Memory (agentic); LongMemEval (对话记忆)
Baseline
- 旗舰推理模型:Gemini-2.5-Pro, GPT-5, DeepSeek-R1-0528, Qwen3-235B-A22B-Thinking, Qwen3-Max-Thinking-Preview
- 轻量推理模型:Gemini-2.5-Flash-Thinking, GPT-5-Nano, GPT-OSS-120B, QwenLong-L1, Qwen3-30B-A3B-Thinking-2507
- Memory Agent:MemAgent-14B, Qwen3-30B-A3B-Thinking-2507 (in agent framework)
训练配置
- Base Model: Qwen3-30B-A3B-Thinking-2507
- RL Framework: VeRL (HybridFlow) v0.4
- Sampling: temperature=0.7, top-p=0.95, group size
- Training: batch size=128, learning rate=, purely on-policy (single gradient update per batch)
- Reward: 混合验证 = rule-based check + LLM-as-a-judge (gpt-oss-120b)
- Evaluation: max input 128K tokens, max generation 50K tokens, middle truncation strategy
5. Experimental Results (实验结果)
主要结果(≤128K tokens)
| Models | Avg. | DocMath | LBV2 | Frames | MRCR | CorpusQA | LBV1-QA |
|---|---|---|---|---|---|---|---|
| Gemini-2.5-Pro | 72.40 | 62.38 | 65.72 | 74.51 | 79.92 | 80.62 | 71.28 |
| GPT-5 | 74.74 | 67.62 | 62.82 | 84.59 | 77.29 | 81.56 | 73.70 |
| DeepSeek-R1-0528 | 68.67 | 63.44 | 59.48 | 76.86 | 64.88 | 77.50 | 69.90 |
| Qwen3-30B-A3B-Thinking-2507 | 61.92 | 62.26 | 49.11 | 70.27 | 51.27 | 71.56 | 67.10 |
| QwenLong-L1.5-30B-A3B | 71.82 (+9.90) | 66.26 (+4.00) | 55.27 (+6.16) | 74.76 (+4.49) | 82.99 (+31.72) | 81.25 (+9.69) | 70.40 (+3.30) |
关键发现:
- QwenLong-L1.5 平均 71.82 分,接近 Gemini-2.5-Pro (72.40),与 GPT-5 (74.74) 有竞争力
- MRCR 得分 82.99 为所有模型最高,较 baseline 提升 31.72 分
- CorpusQA 81.25 与 GPT-5 的 81.56 几乎持平
- 提升主要集中在需要多跳推理和信息聚合的任务
超长上下文结果(>128K tokens)
| Models | MRCR 128K~512K | MRCR 512K~1M | CorpusQA 1M | CorpusQA 4M |
|---|---|---|---|---|
| Gemini-2.5-Pro | 53.83 | 39.51 | 53.11 | - |
| MemAgent-14B | 6.78 | 3.11 | 9.70 | 9.09 |
| Qwen3-30B-Thinking-2507 | 16.55 | 4.24 | 15.32 | 9.52 |
| QwenLong-L1.5-30B-A3B | 34.87 | 22.53 | 20.72 | 14.29 |
Memory Agent 框架使 QwenLong-L1.5 在 MRCR 128K~512K 上达到 34.87(超 baseline 18.32 分),在 4M token CorpusQA 上达到 14.29。
泛化能力
| Benchmark | Qwen3-30B-Thinking-2507 | QwenLong-L1.5-30B-A3B | Δ |
|---|---|---|---|
| AIME25 | 82.81 | 86.46 | +3.65 |
| GPQA-Diamond | 75.88 | 76.78 | +0.90 |
| Memory-KV (BFCL-V4) | 10.97 | 16.77 | +5.80 |
| LongMemEval | 60.80 | 76.40 | +15.60 |
长上下文训练带来的推理能力提升可迁移到通用数学推理、agentic memory 和对话记忆等领域,未发生灾难性遗忘。
Ablation Studies
Multi-task RL 策略 (Table 2, Qwen3-4B-Thinking):
- Naive GRPO: 56.07 → +Task-balanced sampling: 56.86 (+0.79) → +Task-batch-std: 58.62 (+2.55)
Negative Gradient Clipping (Table 4):
- 最佳策略为 sequence-level clip high entropy seqs: 57.36,较 GRPO 56.07 提升 1.29
AEPO (Table 5):
- GRPO 56.07 → +AEPO: 59.36 (+3.29),在所有 benchmark 上均有提升
渐进式训练 (Table 10):
- Stage 1~4 逐步提升:61.92 → 69.59 → 70.46 → 71.59 → (merge) 71.18 → 71.82
- Memory Agent MRCR 512K~1M:4.24 → 17.14 → 17.05 → 12.66 → 20.34 → 21.68 → 22.53
局限性
- 数据合成 pipeline 仅覆盖文本模态,未扩展到多模态
- 当前仅优化长输入场景,未涉及长输出(如章节级文档修订、报告生成)
- Reward 模型依赖 rule-based + LLM-judge,对开放式/主观任务效果有限
- GRPO 的 credit assignment 是 trajectory-level 的,缺乏 token-level 精细化信号