Learning to Discover at Test Time
Paper: arXiv:2601.16175 Code: test-time-training/discover Code reference:
main@bf205118(2026-03-30)
1. Motivation (研究动机)
现有 test-time scaling 主要是让 frozen LLM 通过 prompt/search 多试几次,例如 AlphaEvolve 类方法维护历史尝试 buffer,再用人工设计的 mutation / crossover / replay heuristic 诱导模型继续改答案;问题是模型权重不变,不能把某个 test problem 中失败尝试提供的新经验内化成参数更新。对于 scientific discovery,这个限制更明显:目标不是在一组任务上平均泛化,而是在一个具体问题上找到一个超过当前 SOTA 的单个解。
本文要解决的具体问题是:给定一个有可执行验证器和连续 reward 的科学/工程问题,如何在 test time 继续训练 LLM,让它针对这个单一问题学习,从而发现一个更高 reward 的 state ,即 。这类问题包括数学构造、GPU kernel、AtCoder heuristic competition、single-cell denoising;共同点是可以自动执行候选代码并得到连续分数。
这个问题值得研究,因为一旦 test-time compute 不只是采样更多 frozen rollout,而是能把 rollout experience 变成针对当前问题的梯度更新,AI system 就更像一个自动 R&D loop:它能在少数几万美元甚至几百美元级别的 problem-specific compute 内,产出一个可验证、可复现、可能超过人类专家/现有 AI 的具体 artifact。
2. Idea (核心思想)
核心 insight:discovery problem 的优化目标不是“让 policy 平均表现更好”,而是“找到一个最好解”;因此 test-time RL 的 objective 和 search/reuse 都应该偏向 reward distribution 的右尾,而不是平均 reward。TTT-Discover 把一个 test problem 视作单独的 RL environment,并在解题过程中持续更新 LLM 的 LoRA weights。
关键创新是两件事的组合:用 entropic utility objective 让高 reward rollout 获得指数级更大权重,并用 adaptive 控制每个初始 state 上的 reweighting KL;同时用 PUCT-style archive sampler 选择最有潜力的历史 state 作为下一批 rollout 的起点。与 AlphaEvolve / OpenEvolve 这类 frozen-model evolutionary search 相比,TTT-Discover 的根本差异是经验不仅进入 prompt buffer,也进入参数更新;与普通 PPO/GRPO 相比,它显式服务于 best-solution discovery,而非 expected return maximization。
3. Method (方法)
Overall framework
科学问题先被写成一个 MDP:文本描述 固定进入上下文,state 是候选解,action 是 thinking tokens + code,transition 通过 parse/execute code 得到 ,reward 来自验证器或 benchmark。TTT-Discover 初始化 archive ,每一步用 PUCT 从 archive 选 state/context,采样 个 rollout,计算 reward,再用 entropic advantage 训练一次 LoRA policy。

Figure 1 解读:上方表格给出跨领域主结果,下方展示 TriMul H100 reward/runtime 分布随 test-time training step 变化。 表示第 个训练 step 后的 policy;从 step 0 到 49,分布右尾逐渐移动,最终超过 best human kernel,并显著优于同等 sampling budget 的 Best-of-。这张图表达的核心不是“采样更多”,而是 rollout 反馈逐步改变了生成分布。
Environment formulation
每个 application 的 state/action/reward 被统一成 code-producing RL:数学问题执行 Python 得到 step-function/sequence 证书,reward 是 或 lower bound;GPU/AtCoder/denoising 直接 parse code 并跑 benchmark,失败、超时或格式错误 reward 为 0。形式化地,discovery 是找到 使得
Best-of- 从空 state 或 SOTA state 独立采样:
State reuse 则维护 archive :
直觉上,state reuse 把“从前一个好解继续改”变成了额外 horizon;TTT-Discover 再把这些改动的成败变成梯度信号,让模型在同一个 problem 上学会更偏向有效修改。
Entropic utility objective
普通 RL 最大化 expected reward:
但 discovery 更关心 max。TTT-Discover 使用 entropic objective:
其 policy-gradient 权重为
为避免固定 在早期过于尖锐、后期又优势消失,论文对每个 initial state 解一个 KL-constrained tilt:
其中 ,用 bisection 求 。实际 batch estimator 使用 leave-one-out normalization:
代码中 ttt_discover/rl/train.py 的 compute_advantages(..., adv_estimator="entropic_adaptive_beta") 与该公式一致:先以 解 ,再计算 LOO entropic advantage;KL-to-base penalty 在 incorporate_kl_penalty 中加到 token-level advantages。
PUCT state reuse
PUCT 对 archive 中每个 state 打分:
其中 若该 state 已被展开,否则 ; 是从该 parent 直接产生过的 best child reward。rank prior 为
展开 parent 后用
其中 是该 parent 的 best child reward。实现里还保留每个 parent 的 top-2 children,并把全局 archive 控制在 top-1000 states,同时保留初始 seed states。
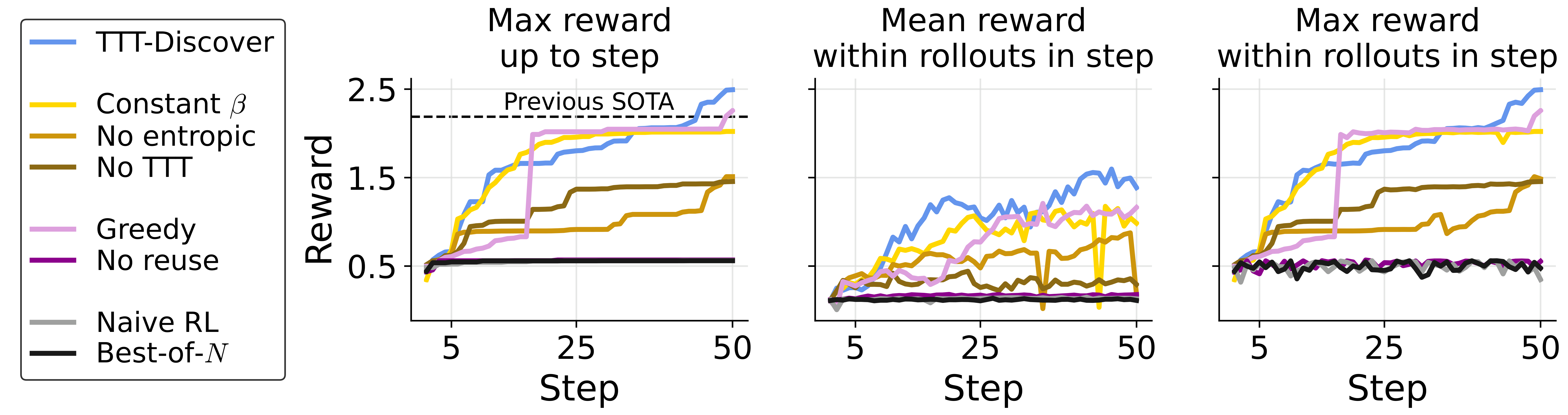
Figure 4 解读:这组 ablation 的 reward distribution 表明两个组件都关键:只有 adaptive entropic objective + PUCT 的 full TTT-Discover 能最快把右尾推向低 runtime;constant 后期提升变弱,expected reward/no TTT 容易停滞,无 reuse 或 naive RL 基本退化到 Best-of- 附近。
Released-code pseudocode
import math
import torch
import torch.nn.functional as F
def adaptive_entropic_advantages(rewards: torch.Tensor, gamma: float = math.log(2.0)) -> torch.Tensor:
# ttt_discover/rl/train.py::compute_advantages, adv_estimator="entropic_adaptive_beta"
k = rewards.numel()
if k < 2:
beta = rewards.new_tensor(0.0)
else:
def kl_hat(beta_scalar: float) -> float:
logits = beta_scalar * (rewards - rewards.max())
logq = logits - torch.logsumexp(logits, dim=0)
q = torch.exp(logq)
return float((q * (logq + math.log(k))).sum().item())
lo, hi = 0.0, 1.0
while hi < 1e6 and kl_hat(hi) < gamma:
hi *= 2.0
for _ in range(60):
mid = 0.5 * (lo + hi)
if kl_hat(mid) < gamma:
lo = mid
else:
hi = mid
beta = rewards.new_tensor(hi)
centered = rewards - rewards.max()
e = torch.exp(beta * centered)
z_loo = (e.sum() - e) / max(k - 1, 1)
return e / (z_loo + 1e-12) - 1.0
def train_on_rollouts(training_client, data, lr: float, loss_fn: str = "importance_sampling"):
# ttt_discover/rl/train.py::train_step; Tinker handles forward/backward + optimizer RPCs.
loss_inputs = [datum.loss_fn_inputs for datum in data]
loss = importance_sampling_loss(loss_inputs) if loss_fn == "importance_sampling" else ppo_loss(loss_inputs)
loss.backward()
training_client.optim_step(learning_rate=lr)
return loss.detach()import numpy as np
def sample_puct_states(states, n_visits, best_child, total_expansions, batch_size, c=1.0, initial_ids=frozenset()):
# ttt_discover/tinker_utils/sampler.py::PUCTSampler.sample_states
values = np.array([s.value if s.value is not None else -np.inf for s in states], dtype=float)
non_initial = np.array([s.id not in initial_ids for s in states])
scale_values = values[non_initial] if non_initial.any() else values
scale = max(scale_values.max() - scale_values.min(), 1e-6)
ranks = np.argsort(np.argsort(-values))
prior = (len(states) - ranks).astype(float)
prior = prior / prior.sum()
scored = []
for i, state in enumerate(states):
n = n_visits.get(state.id, 0)
q = best_child.get(state.id, values[i]) if n > 0 else values[i]
bonus = c * scale * prior[i] * np.sqrt(1.0 + total_expansions) / (1.0 + n)
scored.append((q + bonus, values[i], state))
scored.sort(reverse=True, key=lambda x: (x[0], x[1]))
picked, blocked_ids = [], set()
children_map = build_children_map(states)
for _, _, state in scored:
if state.id in blocked_ids:
continue
picked.append(state)
blocked_ids.update(full_lineage_ids(state, children_map)) # ancestors + descendants blocked within this batch
if len(picked) >= batch_size:
break
return picked
def update_archive(parent, children, archive, n_visits, best_child, topk_children=2, max_buffer=1000):
# Keep only valid children, top-k per parent, then top-1000 globally.
valid = [child for child in children if child.value is not None]
valid.sort(key=lambda s: s.value, reverse=True)
kept = valid[:topk_children]
if kept:
best_child[parent.id] = max(best_child.get(parent.id, -float("inf")), kept[0].value)
for ancestor in [parent.id] + [p["id"] for p in (parent.parents or []) if p.get("id")]:
n_visits[ancestor] = n_visits.get(ancestor, 0) + 1
archive.extend(kept)
archive.sort(key=lambda s: s.value if s.value is not None else -float("inf"), reverse=True)
return archive[:max_buffer]async def ttt_discover_loop(config, dataset, training_client, service_client):
# ttt_discover/rl/train.py::do_sync_training + ttt_discover/rl/rollouts.py::do_group_rollout
sampling_client = await training_client.save_weights_and_get_sampling_client_async()
for step in range(config.num_epochs):
builders = dataset.get_batch(0) # 8 groups; each group has 64 envs by default.
trajectory_groups = []
for builder in builders:
envs = await builder.make_envs()
group = []
for env in envs:
ob, stop = await env.initial_observation()
tokens = await TwoPhaseTokenCompleter(sampling_client, config.temperature)(ob, stop)
result = await env.step(tokens.tokens, step)
group.append((tokens, result.reward, result.metrics))
trajectory_groups.append(group)
rewards_by_group = [torch.tensor([traj[1] for traj in group]) for group in trajectory_groups]
advantages = [adaptive_entropic_advantages(r) for r in rewards_by_group]
data = assemble_training_data(trajectory_groups, advantages)
if config.kl_penalty_coef > 0:
data = add_kl_penalty_against_base_model(data, service_client, config.model_name, config.kl_penalty_coef)
await train_step(data, training_client, config.learning_rate, config.num_substeps, config.loss_fn)
sampling_client = await save_checkpoint_and_get_sampling_client(training_client, step + 1, config.log_path, config.save_every)Code-to-paper mapping
Code reference:
main@bf205118(2026-03-30) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| User-facing discovery config | ttt_discover/discovery.py | DiscoverConfig, discover_impl |
| Single-problem MDP dataset | ttt_discover/tinker_utils/dataset_builder.py | SingleProblemDataset, Environment.step |
| Rollout execution | ttt_discover/rl/rollouts.py | do_single_rollout, do_group_rollout |
| Entropic/adaptive- advantage | ttt_discover/rl/train.py | compute_advantages |
| KL penalty to base model | ttt_discover/rl/train.py | incorporate_kl_penalty, prepare_minibatch |
| Synchronous online training loop | ttt_discover/rl/train.py | do_sync_training, do_train_step_and_get_sampling_client, train_step |
| PUCT archive reuse | ttt_discover/tinker_utils/sampler.py | PUCTSampler.sample_states, update_states, flush |
| Two-phase generation / forced final answer | ttt_discover/tinker_utils/completers.py | TwoPhaseTokenCompleter |
| GPU reward environment | examples/gpu_mode/env.py | GpuModeRewardEvaluator, discover_gpu_mode |
| Math environments | examples/erdos_min_overlap/env.py, examples/ac_inequalities/env.py, examples/circle_packing/env.py | reward evaluators and discover_* launchers |
| AtCoder environment | examples/ahc/env.py | AhcEnv, discover_ahc039, discover_ahc058 |
| Denoising environment | examples/denoising/env.py, examples/denoising/utils.py | DenoisingEnv, DenoisingRewardEvaluator, run_denoising_eval |
论文公式与 released code 实现差异:核心 entropic advantage 与 PUCT 公式未发现实质差异;但实验配置有两个需要显式区分的 paper-vs-code gap。第一,论文 Appendix 写 denoising 使用 3GB memory、400s time limit,released code 在 examples/denoising/env.py 当前 launch 只设置 eval_timeout=530,而 sandbox 默认 TASK_MEMORY=1024**3(1GB)。第二,论文写 TTT-Discover 和 Best-of- denoising max tokens 为 20,000,但 released discover_denoising() 没有覆盖 phase1_max_tokens,因此按 DiscoverConfig 默认会是 26,000。KL penalty 方面,论文写相对 ;fresh run 代码用 service_client.create_sampling_client(base_model=model_name) 作为 base policy,若从 checkpoint/local model 加载,代码注释提示未来要替换。
4. Experimental Setup (实验设置)
Datasets / tasks and scale
- Mathematics:Erdős minimum overlap、AC1、AC2、circle packing ;数学 state 是 step function / sequence certificate。Erdős 最终发现 600-piece asymmetric step function;AC1 最终发现 30,000-piece step function。论文没有把这些任务写成 conventional dataset sample count。
- Kernel Engineering:GPUMode TriMul competition(A100/H100/B200/AMD MI300X leaderboard)与 DeepSeek MLA Decode(AMD MI300X)。训练 TriMul 时只用 H100 runtime 作 reward,最终跨 GPU 报告。
- Algorithm Engineering:AtCoder Heuristic Contest AHC039(Purse Seine Fishing)和 AHC058(Apple Incremental Game),本地 public tests 选算法,再提交官方 private tests。
- Single-cell denoising:OpenProblems denoising task,使用 Pancreas 训练,PBMC 与 Tabula Muris Senis Lung held-out 评估;论文未详细说明三者的 cell/gene sample count,代码中训练 loader 是
examples/denoising/utils.py的load_pancreas(test=False, keep_techs=["inDrop1"])。
Baselines
主要 baseline 包括 Best-of-(与 rollout budget 匹配)、OpenEvolve、AlphaEvolve / AlphaEvolve V2、ThetaEvolve、ShinkaEvolve、ALE-Agent,以及各 benchmark 的 best human / top-5 human submissions。数学里还额外报告 Qwen3-8B 版本以便与 ThetaEvolve 的 R1-Qwen3-8B 比较。
Metrics
- Discovery criterion:是否找到 ;数值越过现有 best human / best AI 即为 discovery。
- Math:Erdős 与 AC1 是 certified upper bound(越低越好);AC2 与 circle packing 是 lower/packing score(越高越好)。
- Kernel:runtime in microseconds(越低越好),B200/MI300X 用 10 trials + 95% CI。
- AtCoder:官方 contest score(越高越好)。
- Denoising:OpenProblems score(normalized MSE 与 normalized Poisson 的均值,越高越好),同时报告 MSE/Poisson(越低越好)。
Training config / hardware
训练配置必须以 actual launch/config 为准:核心默认来自 ttt_discover/discovery.py 的 DiscoverConfig 和 ttt_discover/rl/train.py 的 Config;应用覆盖来自 examples/*/env.py 的 discover_* launchers。
- Model / runtime:OpenAI
gpt-oss-120bon Tinker;reported reasoning effort 为 high;LoRA rank 32。 - Rollout / optimization:50 training steps;每步 512 rollouts = 8 groups × 64 rollouts;temperature 1.0;learning rate 默认 ;每 batch 做 1 个 gradient step;importance sampling correction;save every 2 steps。
- Context / generation:Tinker context window 32,768 tokens;大多数任务
phase1_max_tokens=26000,AtCoder AHC039 为 22000、AHC058 为 25000;two-phase completer 在 thinking budget 耗尽时强制 final answer。 - Task-specific overrides:Algorithm engineering 使用 KL coefficient 0.01(
examples/ahc/env.py),其他多数任务使用 0.1;AHC058 learning rate 是 ;数学/AC eval timeout 可到 1100s;TriMul 训练 reward 在 H100 上,MLA Decode 训练用 H200 因 MI300X 云资源不足。Denoising 的 paper-reported setup 是 3GB memory、400s task time limit、max tokens 20,000,但 released code atmain@bf205118当前对应为eval_timeout=530、sandbox memory 1GB、未覆盖phase1_max_tokens(继承默认 26,000),这属于 paper-vs-code gap。 - AtCoder evaluation details:训练时用 official input generator 的 seeds 0–149 生成 150 public cases;程序必须在 2s time limit 内通过全部 correctness checks 才有非零 reward;最终提交本地 top-3 programs 到 AtCoder hidden tests,语言为 C++23 (GCC 15.2.0),官方 memory limit 为 1024MB。
5. Experimental Results (实验结果)
Main results
| Domain | Best human / prior | Best-of- | TTT-Discover | 结论 |
|---|---|---|---|---|
| Erdős min overlap ↓ | human 0.380927; AlphaEvolve 0.380924 | 0.380906 | 0.380876 | 新 SOTA;改进幅度约为 AlphaEvolve 相对旧 SOTA 的 16× |
| AC1 upper bound ↓ | human 1.50973; AlphaEvolve V2 1.50317; ThetaEvolve+reuse 1.50314 | 1.51004 | 1.50287 | 新 SOTA;从 scratch 找到 30,000-piece construction |
| AC2 lower bound ↑ | AlphaEvolve V2 0.9610 | 0.9344 | 0.9591 | 未超过 AlphaEvolve V2 |
| Circle packing ↑ | best known 2.635983 / 2.939572 | 论文未列 | 2.635983 / 2.939572 with Qwen3-8B | 匹配已知最好结果,未改进 |
| TriMul H100 runtime ↓ | best human 1371.1 µs | 5390.3 µs | 1161.2 µs | 新 SOTA;A100/H100 已提交官方 leaderboard |
| TriMul A100 runtime ↓ | best human 4531.5 µs | 9219.7 µs | 2198.2 µs | 约 50% faster than top human |
| MLA Decode MI300X runtime ↓ | best human 1653.8 / 1688.6 / 1668.7 µs | 2286.0 / 2324.1 / 2275.2 µs | 1669.1 / 1706.1 / 1671.3 µs | 优于 Best-of,但没有统计显著超过 top human |
| AHC039 score ↑ | 1st human 566,997; ShinkaEvolve 558,026 | 554,171 | 567,062 | 若比赛期间提交将排第 1 |
| AHC058 score ↑ | 1st human 847,674,723; ALE-Agent 848,373,282 | 772,429,752 | 848,414,228 | 超过已有 AI/human 最好分 |
| Single-cell PBMC score ↑ | MAGIC(A,R) 0.64 | 0.62 | 0.71 | OpenProblems denoising benchmark 上改进 |
| Single-cell Tabula score ↑ | MAGIC(A,R) 0.64 | 0.65 | 0.73 | held-out dataset 仍提升 |

Figure 2 解读:图中比较 AlphaEvolve 与 TTT-Discover 在 Erdős minimum overlap 上的 normalized step function。TTT-Discover 的 600-piece construction 明显非对称,而 AlphaEvolve 是 95-piece,human best 是 51-piece;这说明 test-time training 不只是局部微调已有形状,而可能走向更复杂、非对称的构造。

Figure 3 解读:图中 overlay 了 AC1 的 step functions 和 autoconvolutions。TTT-Discover 从 scratch 找到 30,000-piece step function,证得 ;AlphaEvolve/ThetaEvolve construction 是 1319-piece,ThetaEvolve 又初始化自 AlphaEvolve,因此形状更相近。这里的突破来自后期针对 near-tight convolution constraints 的 LP/gradient heuristic,而不是人工介入优化过程。
Detailed result tables
| Math method | Model | Erdős ↓ | AC1 ↓ | AC2 ↑ |
|---|---|---|---|---|
| best human | — | 0.380927 | 1.50973 | 0.9015 |
| AlphaEvolve | Gemini-2.0 Pro + Flash | 0.380924 | 1.50530 | 0.8962 |
| AlphaEvolve V2 | Gemini-2.0 Pro + Flash | 0.380924 | 1.50317 | 0.9610 |
| ThetaEvolve | R1-Qwen3-8B | n/a | 1.50681 | 0.9468 |
| ThetaEvolve w/ SOTA reuse | R1-Qwen3-8B | n/a | 1.50314 | n/a |
| OpenEvolve | gpt-oss-120b | 0.380965 | 1.50719 | 0.9449 |
| Best-of- | gpt-oss-120b | 0.380906 | 1.51004 | 0.9344 |
| TTT-Discover | Qwen3-8B | 0.380932 | 1.50525 | 0.9472 |
| TTT-Discover | gpt-oss-120b | 0.380876 | 1.50287 | 0.9591 |
| TriMul method | A100 ↓ | H100 ↓ | B200 ↓ [95% CI] | AMD MI300X ↓ [95% CI] |
|---|---|---|---|---|
| 1st human | 4531.5 | 1371.1 | 1038.9 [1016.3, 1061.6] | 2515.8 [2510.9, 2520.7] |
| Best-of- | 9219.7 | 5390.3 | 3254.9 [3252.5, 3257.4] | 4902.0 [4897.6, 4906.4] |
| TTT-Discover | 2198.2 | 1161.2 | 914.2 [907.3, 921.1] | 1555.7 [1550.8, 1560.6] |
| MLA Decode MI300X method | Instance 1 ↓ [95% CI] | Instance 2 ↓ [95% CI] | Instance 3 ↓ [95% CI] |
|---|---|---|---|
| 1st human | 1653.8 [1637.3, 1670.3] | 1688.6 [1672.8, 1704.3] | 1668.7 [1637.0, 1700.3] |
| Best-of- | 2286.0 [2264.2, 2307.8] | 2324.1 [2306.0, 2342.1] | 2275.2 [2267.3, 2283.1] |
| TTT-Discover | 1669.1 [1649.2, 1688.9] | 1706.1 [1685.9, 1726.3] | 1671.3 [1646.0, 1696.5] |
MLA Decode 结论:TTT-Discover 明显优于同预算 Best-of-,但论文强调 MI300X instance variance 很大,三个 instance 上都没有相对 top human submission 达到统计显著更优。
| AHC method | Geometry ahc039 ↑ | Scheduling ahc058 ↑ |
|---|---|---|
| 1st human | 566,997 | 847,674,723 |
| ALE-Agent | 550,647 | 848,373,282 |
| ShinkaEvolve | 558,026 | n/a |
| Best-of- | 554,171 | 772,429,752 |
| TTT-Discover | 567,062 | 848,414,228 |
| Denoising method | PBMC Score ↑ | PBMC MSE ↓ | PBMC Poisson ↓ | Tabula Score ↑ | Tabula MSE ↓ | Tabula Poisson ↓ |
|---|---|---|---|---|---|---|
| MAGIC (A,R) | 0.64 | 0.19 | 0.05 | 0.64 | 0.18 | 0.03 |
| ALRA (S,RN) | 0.50 | 0.26 | 0.05 | 0.47 | 0.27 | 0.03 |
| OpenEvolve | 0.70 | 0.16 | 0.05 | 0.71 | 0.15 | 0.03 |
| Best-of- | 0.62 | 0.20 | 0.05 | 0.65 | 0.18 | 0.03 |
| TTT-Discover | 0.71 | 0.15 | 0.05 | 0.73 | 0.14 | 0.03 |
Ablations
| Variant | train | reuse | Best runtime ↓ (µs) |
|---|---|---|---|
| Best Human Kernel | — | — | 1371.1 |
| TTT-Discover | TTT with adaptive entropic | PUCT | 1203.10 |
| Train ablation | TTT with constant entropic | PUCT | 1483.83 |
| Train ablation | TTT with expected reward | PUCT | 1985.67 |
| Train ablation | No TTT | PUCT | 2060.70 |
| Reuse ablation | TTT with adaptive entropic | -greedy | 1328.89 |
| Reuse ablation | TTT with adaptive entropic | no reuse | 5274.03 |
| Naive test-time RL | TTT with expected reward | no reuse | 5328.73 |
| Best-of- | no TTT | no reuse | 5352.36 |
关键发现:adaptive entropic objective 解决 constant 后期 advantage 变弱的问题;PUCT reuse 则避免从空 state 反复重启导致 horizon 太短。两者缺一时,runtime 都明显差于 full TTT-Discover。
Limitations
作者明确指出当前方法只适用于有连续 reward、可自动验证的任务;未来最重要方向是 sparse/binary reward 或 non-verifiable domain 的 test-time training。Single-cell 部分也有 expert caveat:benchmark metric 改进不必然等价于更好的生物学下游发现,需要更多 biologically relevant evaluation。