GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Authors: Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Yejin Choi, Jan Kautz, Pavlo Molchanov Affiliations: NVIDIA, HKUST
1. Motivation (研究动机)
1.1 多奖励 RL 的需求
随着 LLM 能力增强,用户期望模型不仅准确,还能满足多样化偏好(效率、安全、格式、逻辑性等)。RL 训练管线开始引入多个奖励信号(如准确性 + 格式合规 + 长度约束),每个奖励捕获一个独立的人类偏好维度。
1.2 GRPO 在多奖励场景下的根本缺陷
GRPO (Group Relative Policy Optimization) 是当前主流 RL 优化算法,但直接用于多奖励场景存在奖励信号坍缩 (reward signal collapse) 问题:
问题本质:GRPO 先对所有奖励求和 ,再对总和做 group-wise normalization。这导致不同的奖励组合被映射到相同的 advantage 值,丢失了跨奖励维度的区分信息。
具体例子:两个二值奖励 ,2 个 rollout。总奖励 共有 9 种组合,但 GRPO normalization 后只剩 2 个 distinct advantage groups。例如 和 本应有不同的 advantage((0,2) 满足两个奖励应更强),但被映射到相同的 。
1.3 移除标准差归一化也不能解决
Dr.GRPO 和 DeepSeek-v3.2 移除标准差归一化项(),虽然略增加 distinct advantage groups 数量,但增幅有限且无法根本解决信息压缩问题。实验显示这一修改反而导致训练不稳定(format reward 完全无法收敛,BFCL-v3 format correctness = 0%)。
2. Idea (核心思想)
解耦归一化:对每个奖励信号独立进行 group-wise normalization,保留跨奖励维度的区分信息;然后对加权求和后的 advantage 做 batch-wise normalization,稳定数值范围。
GDPO 是 GRPO 的 drop-in replacement,仅修改 advantage 计算方式,不改变其他训练流程。核心变化:
- GRPO: 先求和 → 再 normalize
- GDPO: 先 per-reward normalize → 再求和 → 再 batch normalize
3. Method (方法)
3.1 GRPO 的 Advantage 计算(回顾)
给定第 个问题的第 个 rollout, 个奖励的聚合:
Group-wise normalization:
GRPO 优化目标:
3.2 GDPO: 解耦归一化
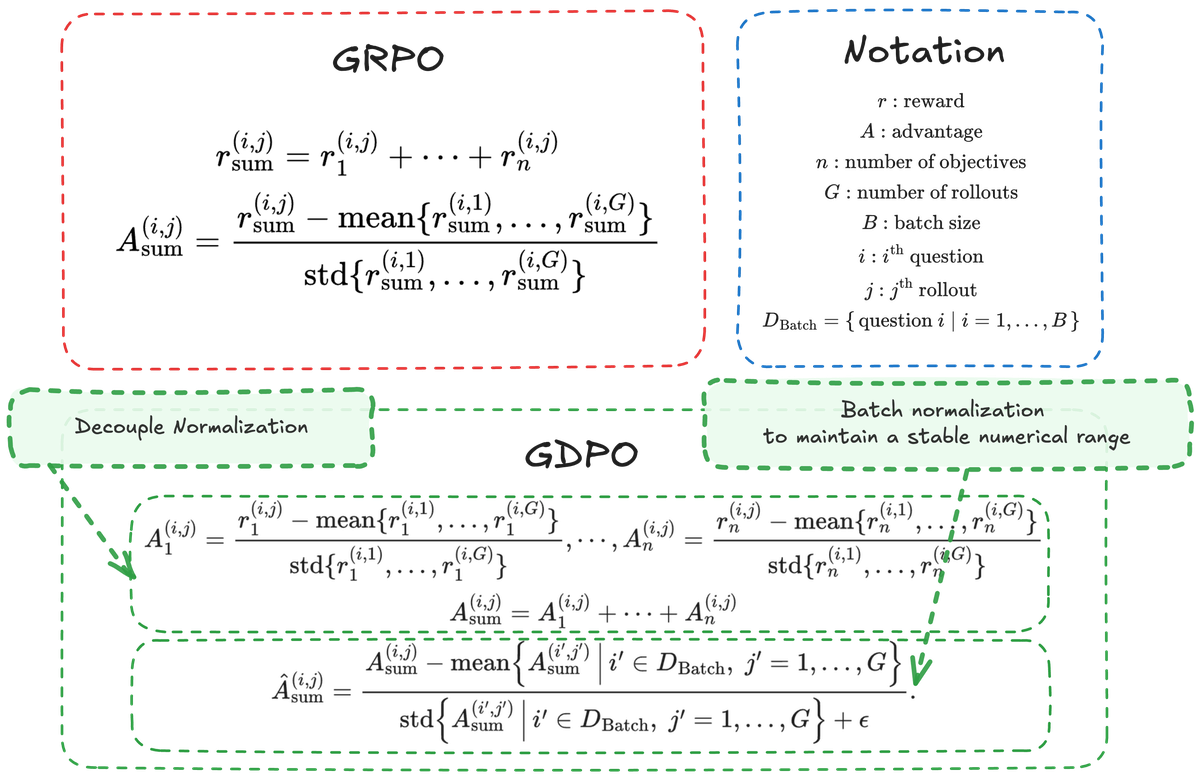
Figure 1a 解读:GDPO 方法概览。上半部分为 GRPO 的计算流程——先对所有奖励求和再做 group-wise normalization。下半部分为 GDPO——对每个奖励独立做 group-wise normalization(Decouple Normalization,绿色虚线框),然后加权求和,最后做 batch normalization(红色虚线框)保持数值稳定。
Step 1: Per-Reward Group-wise Normalization
对每个奖励 独立在 group 内归一化:
Step 2: Weighted Aggregation
加权求和所有奖励的 normalized advantage:
Step 3: Batch-wise Normalization
在整个 batch 上做 normalization,确保 advantage 的数值范围不随奖励数量增长:
3.3 信息保留分析
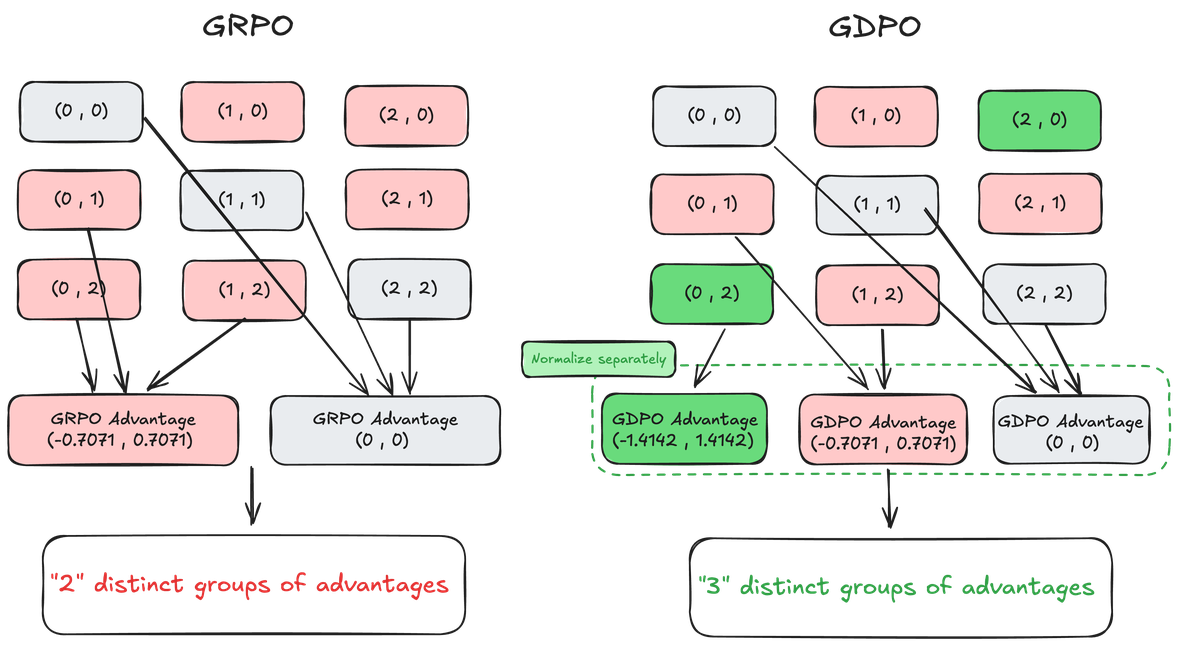
Figure 2 解读:GRPO vs GDPO 的 advantage 计算对比(2 个二值奖励,2 个 rollout)。左侧 GRPO:9 种 组合仅产生 2 个 distinct advantage groups(灰色和红色节点塌缩)。例如 和 被映射到相同的 advantage 。右侧 GDPO:通过独立归一化每个奖励,保留了 3 个 distinct advantage groups。 的 advantage 变为 ,正确反映了两个奖励全部满足带来的更强学习信号。

Figure 3 解读:随 rollout 数量(左图)和奖励数量(右图)增长,GRPO、GRPO w/o std、GDPO 产生的 distinct advantage group 数量对比。GDPO 在所有设置下均显著优于 GRPO 和 GRPO w/o std,且差距随 rollout/奖励数量增加而扩大,表明 GDPO 的信息保留优势在更复杂的多奖励场景下更加突出。
3.4 优先级变异的有效整合
当不同奖励的难度差异很大时(如 length reward 远比 correctness reward 容易优化),模型倾向于优化简单奖励而忽视困难奖励。
方法一:调整奖励权重——降低简单奖励的权重 ,但实验显示仅当 降至很低(0.25)时才有效。
方法二:条件化奖励 (Conditioned Reward)——将简单奖励条件化于困难奖励的满足:
模型只有在正确回答后才能获得 length reward,强制优先满足困难目标。
3.5 伪代码
# 伪代码:GDPO Advantage Computation (核心算法)
# 实际代码: trl-GDPO/trl-0.18.0-gdpo/trl/trainer/grpo_trainer.py
def gdpo_compute_advantages(rewards_per_func, reward_weights, num_generations):
"""
Input:
rewards_per_func: [batch_size * G, n_rewards] - 每个 rollout 的各奖励值
reward_weights: [n_rewards] - 奖励权重
num_generations: G - 每个问题的 rollout 数
Output:
advantages: [batch_size * G] - 最终 advantage 值
"""
n_rewards = len(reward_weights)
rewards_per_func = torch.nan_to_num(rewards_per_func)
# Step 1: Per-reward group-wise normalization (Eq. 4)
all_reward_advantages = []
for i in range(n_rewards):
reward_i = rewards_per_func[:, i] # [batch_size * G]
# Group-wise mean and std (per question)
grouped = reward_i.view(-1, num_generations) # [batch_size, G]
mean_grouped = grouped.mean(dim=1) # [batch_size]
std_grouped = grouped.std(dim=1) # [batch_size]
# Expand back to per-rollout
mean_expanded = mean_grouped.repeat_interleave(num_generations)
std_expanded = std_grouped.repeat_interleave(num_generations)
# Normalize this reward independently
advantage_i = (reward_i - mean_expanded) / (std_expanded + 1e-4)
all_reward_advantages.append(advantage_i)
# Step 2: Weighted aggregation (Eq. 5)
combined = torch.stack(all_reward_advantages, dim=1) # [batch*G, n_rewards]
pre_bn = (combined * reward_weights.unsqueeze(0)).nansum(dim=1) # [batch*G]
# Step 3: Batch-wise normalization (Eq. 6)
bn_mean = pre_bn.mean()
bn_std = pre_bn.std()
advantages = (pre_bn - bn_mean) / (bn_std + 1e-4)
return advantages# 伪代码:GRPO Advantage Computation (对比用)
def grpo_compute_advantages(rewards_per_func, reward_weights, num_generations):
"""Standard GRPO: sum first, then normalize"""
# Step 1: Sum all rewards (Eq. 1)
weighted_sum = (rewards_per_func * reward_weights.unsqueeze(0)).sum(dim=1)
# Step 2: Group-wise normalization on the sum (Eq. 2)
grouped = weighted_sum.view(-1, num_generations)
mean_grouped = grouped.mean(dim=1).repeat_interleave(num_generations)
std_grouped = grouped.std(dim=1).repeat_interleave(num_generations)
advantages = (weighted_sum - mean_grouped) / (std_grouped + 1e-4)
return advantages# 伪代码:Conditioned Length Reward (Eq. 8)
def conditioned_length_reward(response_length, target_length, correctness_reward):
"""Length reward conditioned on correctness"""
if response_length <= target_length and correctness_reward == 1:
return 1.0
else:
return 0.03.6 代码映射
| 论文概念 | 代码文件 | 关键函数/类 |
|---|---|---|
| GDPO advantage 计算 | trl-GDPO/trl-0.18.0-gdpo/trl/trainer/grpo_trainer.py | _generate_and_score_completions() 中 apply_gdpo 分支 |
| Per-reward normalization (Eq. 4) | 同上 | for i in range(len(self.reward_weights)) 循环 |
| Batch-wise normalization (Eq. 6) | 同上 | bn_advantages_mean/std 计算 |
| Reward weights | 同上 | self.reward_weights |
| Tool calling rewards | trl-GDPO/open-r1/src/open_r1/rewards.py | Format reward + Correctness reward |
| GRPO config | trl-GDPO/trl-0.18.0-gdpo/trl/trainer/grpo_config.py | GRPOConfig |
| Training recipe (math) | recipes/Qwen2.5-1.5B-Instruct/gdpo_gsm8k/config.yaml | verl 训练配置 |
4. Experimental Setup (实验设置)
4.1 任务与数据集
| 任务 | 训练数据 | 评测基准 | 奖励数 |
|---|---|---|---|
| Tool Calling | ToolRL (4k samples: ToolACE + Hammar + xLAM) | BFCL-v3 | 2 (format + correctness) |
| Math Reasoning | DeepScaleR-Preview (40k competition-level) | AIME-24, AMC, MATH, Minerva, Olympiad | 2 (accuracy + length) |
| Coding Reasoning | Eurus-2-RL (24k coding problems) | Apps, CodeContests, Codeforces, Taco | 2-3 (pass + length + bug) |
4.2 基线方法
- GRPO: 标准 group-wise normalization
- GRPO w/o std: 移除标准差归一化(Dr.GRPO / DeepSeek-v3.2 方案)
4.3 模型
- Tool Calling: Qwen2.5-Instruct-1.5B, Qwen2.5-Instruct-3B
- Math: DeepSeek-R1-1.5B, DeepSeek-R1-7B, Qwen3-4B-Instruct
- Coding: DeepSeek-R1-7B
4.4 训练配置
- Tool Calling: verl, 100 steps, batch=512, 4 rollouts, max response=1024 tokens
- Math: verl, 500 steps, batch=512, 16 rollouts, max response=8000 tokens, dynamic sampling, higher clipping, token-mean loss (DAPO)
- Coding: verl, 400 steps, 同 math 配置
- Inference: vLLM, temperature=0.6, top_p=0.95, max 32k tokens, 16 samples/question
5. Experimental Results (实验结果)
5.1 Tool Calling (BFCL-v3)
Table 1: Qwen2.5-Instruct-1.5B/3B (5 runs 平均)
| Model | Method | Live Overall Acc ↑ | Multi Turn ↑ | Non-Live ↑ | Avg Acc ↑ | Correct Format ↑ |
|---|---|---|---|---|---|---|
| 1.5B | GRPO | 50.63% | 2.04% | 37.87% | 30.18% | 76.33% |
| 1.5B | GDPO | 55.36% | 2.50% | 40.58% | 32.81% | 80.66% |
| 3B | GRPO | 69.23% | 3.14% | 45.24% | 39.20% | 81.64% |
| 3B | GDPO | 71.22% | 4.59% | 46.79% | 40.87% | 82.23% |
GDPO 在 1.5B 上 Avg Acc 提升 +2.63%,Format Correctness 提升 +4.33%。
GRPO w/o std 的失败:Format Correctness = 0%(完全无法学习输出格式),证明单纯移除 std 引入训练不稳定。
5.2 Math Reasoning

Figure 5 解读:DeepSeek-R1-1.5B 上 GRPO vs GDPO 的训练曲线对比(Correctness Reward, Length Reward, Max Response Length)。两者都迅速最大化 length reward,但 GRPO 约 400 步后 correctness reward 开始下降且 max response length 急剧上升(训练坍缩)。GDPO 则持续改善 correctness 同时稳定控制 response length。
Table 3: DeepSeek-R1-1.5B/7B, Qwen3-4B-Instruct (Pass@1 + Exceed Ratio)
| Model | Benchmark | Base | GRPO Acc | GDPO Acc | GRPO Exceed | GDPO Exceed |
|---|---|---|---|---|---|---|
| DS-R1-1.5B | MATH | 84.3% | 83.6% | 86.2% | 1.5% | 0.8% |
| DS-R1-1.5B | AIME | 29.8% | 23.1% | 29.4% | 10.8% | 6.5% |
| DS-R1-7B | MATH | 93.6% | 94.1% | 93.9% | 0.5% | 0.1% |
| DS-R1-7B | AIME | 55.4% | 50.2% | 53.1% | 2.1% | 0.2% |
| Qwen3-4B | AIME | 63.7% | 54.6% | 56.9% | 2.5% | 0.1% |
GDPO 在 AIME 上对 DS-R1-1.5B 提升 +6.3% accuracy,同时 exceed ratio 从 10.8% 降至 6.5%。
5.3 Reward Priority Analysis

Figure 6 解读:DeepSeek-R1-7B 在不同 length reward weight 下的 MATH/AIME accuracy 和 exceed ratio。上排为 accuracy(越高越好),下排为 exceed ratio(越低越好)。使用原始 时(左两列),降低权重效果有限且不稳定。使用条件化 时(右两列),权重调整效果更可预测,GDPO 在各配置下均优于 GRPO。
5.4 Coding Reasoning
Table 5: DeepSeek-R1-7B (2-obj and 3-obj)
| Benchmark | Base Pass | GRPO₂ Pass | GDPO₂ Pass | GRPO₃ Pass | GDPO₃ Pass |
|---|---|---|---|---|---|
| Apps | 28.1% | 67.2% | 68.3% | 68.1% | 67.8% |
| CodeContests | 47.3% | 63.2% | 65.8% | 65.6% | 65.6% |
| Codeforces | 46.5% | 68.1% | 71.2% | 69.5% | 69.4% |
| Taco | 28.1% | 45.1% | 48.4% | 44.4% | 45.1% |
| Benchmark | GRPO₂ Bug | GDPO₂ Bug | GRPO₃ Bug | GDPO₃ Bug |
|---|---|---|---|---|
| Apps | 25.0% | 23.5% | 20.3% | 18.8% |
| CodeContests | 14.1% | 13.2% | 3.9% | 2.5% |
| Codeforces | 7.0% | 5.6% | 2.5% | 1.8% |
| Taco | 37.7% | 36.2% | 30.0% | 28.0% |
GDPO 在 3-reward 设置下 bug ratio 显著降低(CodeContests: 3.9% → 2.5%),展现了随奖励数量增加优势扩大的趋势。
5.5 Ablation Summary
- GRPO w/o std 不可行:格式 reward 完全无法收敛(0% format correctness)
- Batch normalization 必要:移除 batch-wise normalization 偶尔导致训练发散
- Conditioned reward 有效:配合 GDPO 在 AIME 上 +4.4% accuracy + 16.9% exceed 减少
- GDPO 在 3-reward 下优势更大:distinct advantage groups 随奖励数量增加差距扩大
5.6 局限性
论文未详细讨论局限性。隐含局限包括:(1) 实验仅在 LLM 上验证,未涉及视觉生成等其他领域;(2) 奖励数量最多测试到 3 个;(3) 对 reward scale 差异极大的场景(如一个 reward 在 [-100, 100],另一个在 [0, 1])的鲁棒性未讨论。
总结:GDPO 发现了 GRPO 在多奖励 RL 中的根本问题——奖励信号坍缩,并通过解耦每个奖励的 group-wise normalization + batch-wise normalization 的两步策略解决。方法极其简洁(仅修改 advantage 计算),是 GRPO 的 drop-in replacement。在 tool calling、数学推理、代码推理三个任务上全面优于 GRPO,特别在训练稳定性和多目标平衡上优势显著。