InternVL-U: Democratizing Unified Multimodal Models for Understanding, Reasoning, Generation and Editing
Authors: Changyao Tian, Danni Yang, Guanzhou Chen, Erfei Cui, Zhaokai Wang, Yuchen Duan, Penghao Yin, Sitao Chen, Ganlin Yang, Mingxin Liu, Zirun Zhu, Ziqian Fan, Leyao Gu, Haomin Wang, Qi Wei, Jinhui Yin, Xue Yang, Zhihang Zhong, Qi Qin, Yi Xin, Bin Fu, Yihao Liu, Jiaye Ge, Qipeng Guo, Gen Luo, Hongsheng Li, Yu Qiao, Kai Chen, Hongjie Zhang Affiliations: Shanghai AI Laboratory, CUHK MMLab, Fudan University, Shanghai Jiao Tong University, Tsinghua University, University of Science and Technology of China, South China University of Technology, Nanjing University, Xiamen University arXiv: 2603.09877 Project Page: huggingface.co/InternVL-U/InternVL-U GitHub: OpenGVLab/InternVL-U
1. Motivation(研究动机)
这篇论文要解决的核心矛盾是:统一多模态模型(UMM)想同时具备 understanding、reasoning、generation、editing 能力,但现有路线往往会在“语义理解能力”和“视觉生成能力”之间发生明显 trade-off。
作者先把已有方法分成两类:
- Fully-native UMMs:从头联合训练 understanding 与 generation。问题是训练代价大、工程复杂,而且很难直接复用现成最强的 MLLM / ViT。
- Fully-ensemble UMMs:把已有 MLLM 和图像生成器后融合。问题是条件接口往往割裂,生成头要么特别大、要么 conditioning pipeline 很复杂,很难和单一 MLLM 的 hidden-state 空间自然对齐。
作者进一步指出,更深层的矛盾并不只在 architecture,而在 训练目标与数据分布:
- 传统 image generation 更强调 aesthetics、texture、fidelity;
- multimodal understanding 更强调 OCR、knowledge、structured reasoning;
- 两者的数据分布和 supervision 重点并不一致。
因此,这篇工作想回答两个问题:
- 能不能在 4B 量级 做出一个真正统一、而且不严重牺牲理解能力的 UMM?
- 能不能通过 high-semantic-density data + CoT-driven data synthesis,让统一模型不仅会“画得像”,还会“按复杂语义要求准确地画、改、推理后再画”?
这也是这篇论文值得看的原因:它不是简单把 MLLM 接一个 diffusion head,而是试图同时回答 架构统一性 与 训练数据语义密度 这两个根因问题。
2. Idea(核心思想)
这篇论文的核心思想可以概括为三句话:
- 统一 context,不统一 target:文本和图像在语义建模阶段共享一个统一的 multimodal context space,但在输出端分别采用 AR text prediction 和 Flow Matching image generation。
- 统一 backbone,模块化 head/stem:用 InternVL3.5-2B 作为强 understanding backbone,再接一个专门的 MMDiT-based visual generation head,而不是让同一套模块同时负责 reasoning 和 pixel synthesis。
- 用 CoT 数据合成把“抽象意图”翻译成“可执行视觉规范”:特别针对 text rendering、science reasoning、meme、spatial editing 等高语义密度任务,显式加入 reasoning trace,提升 controllability。
更具体地说,InternVL-U 的创新点并不是单点 trick,而是一个成体系的设计:
- Unified Contextual Modeling:在 context 阶段统一建模 text token 与 visual token;
- Modality-Specific Modular Design:理解端用 ViT + MLLM,生成端用独立 MMDiT;
- Decoupled Visual Representations:理解用 semantic ViT feature,生成用可重建的 VAE latent;
- Reasoning-centric Data Synthesis:把短 prompt 扩写成带约束、带步骤、带知识补全的 supervision。
与很多“把生成头外挂到 VLM 上”的工作相比,这篇论文最本质的不同在于:它把“统一模型”理解为 semantic space 的统一,而不是 tokenization / decoder 形式的强行统一。
3. Method(方法)
3.1 整体框架

Figure 3 解读:Figure 3 给出了 InternVL-U 的总架构。左侧是统一 backbone:文本 prompt 经过 tokenizer,图像输入经过 visual understanding encoder,二者都进入统一的 multimodal context backbone 做语义建模。上方分成两个输出分支:文本分支做 next-token prediction,图像分支则把 context embedding 送入 visual generation head 做 velocity prediction。右侧三条文字直接对应论文的三条总原则:统一 context + 模态自适应 target、模态特化模块化设计、理解/生成视觉表征解耦。也就是说,Figure 3 不是单纯的系统图,而是整篇论文设计哲学的压缩表达。
如 Figure 3 所示,InternVL-U 的前向过程可以拆成四步:
- 理解端编码:输入图像先由 pre-trained ViT 提取 semantic feature;文本走标准 tokenizer。
- 统一语义上下文建模:视觉 token 与语言 token 投影到共享 latent space,在统一 backbone 中做 causal multimodal modeling。
- 双输出目标:文本直接做 AR token prediction;图像不做离散 token prediction,而是进入 MMDiT-based visual generation head,在连续 VAE latent 空间内做 Flow Matching。
- 训练期三阶段 curriculum:先只训 generation head,再做 any-resolution continued pretraining,最后全模型 unified SFT。
从公开实现看,端到端入口在 internvlu/pipeline_internvlu.py 的 InternVLUPipeline:
generation_mode="text":只走 VLM 文本生成;generation_mode="image":直接生成或编辑图像;generation_mode="text_image":先让 VLM 产出 reasoning / CoT,再把文本 reasoning 接到<img>token 后进入图像生成。
3.2 Visual Generation Head:Dual Projectors + Dual-Stream MMDiT + Unified MSRoPE

Figure 4 解读:Figure 4 把 visual generation head 进一步拆开。Figure 4(a) 展示 noisy image latent、timestep embedding 和 multimodal context embedding 如何一起送入双流 MMDiT;Figure 4(b) 展示 dual-stream attention/FFN block 内部,文本流与图像流共享交互但参数分离;Figure 4(c) 展示 Unified MSRoPE 如何同时给生成 latent 与 multimodal context token 赋予 3D 位置编码。这个 figure 的重点是:InternVL-U 并不是“把 VLM hidden states 当文本条件喂进普通 DiT”,而是重新设计了一个能同时容纳 image latent、text condition、image condition 的统一双流 transformer。
3.2.1 Dual Projectors
论文指出,multimodal hidden states(context)与 VAE image latents(target)统计分布不同,因此需要独立 projector。公开实现里这个思想分散落在两层:
InternVLUGenerationDecoder.decoder_projector:先把 VLM hidden states 映射到 decoder 所需维度;InternVLUTransformer2DModel.txt_norm + txt_in与img_in:分别处理文本条件和图像 latent patch。
其中,VLM 分支额外用了 txt_norm 做 normalization,这和论文里“VLM context embedding 有更大幅值与更强 outlier,因此先做 variance normalization”的叙述是对应的。
3.2.2 Dual-Stream MMDiT Block with Gated Attention
论文给出的注意力门控公式是:
这里 是 sigmoid, 是 attention 输入, 是 attention 输出, 是可学习门控矩阵。
在公开代码 internvlu/diffusion/internvlu_transformer.py 里,这个 block 由 InternVLUTransformerBlock 和 InternVLUDoubleStreamFlashAttnProcessor 实现,关键点有三层:
- 图像流 / 文本流参数解耦:
img_mod、txt_mod,img_mlp、txt_mlp分开。 - 联合 self-attention:attention 时文本 token 与图像 token 会一起进入 joint attention,但 Q/K/V 的投影按 stream 分离。
- 门控增强:从公开实现看,除了论文正文强调的 attention gating 外,代码里还保留了基于 timestep modulation 的 residual gate(
gate1/gate2),因此 block 的非线性控制比正文公式更丰富。
这套设计解决的是统一模型最棘手的问题:既要让 text/image token 深度交互,又不能因为完全参数共享而破坏图像生成所需的低层统计结构。
3.2.3 Unified MSRoPE with Resolution Interpolation
论文强调不是把 visual token 简单 flatten 成 1D 序列,而是给 context image token 和 generation latent token 都施加统一的 3D positional encoding(frame, height, width)。
公开实现里:
UnifiedMSRoPE负责计算 3D rotary embedding;create_position_ids_3d_v2/create_position_ids_3d_v3负责构造不同输入布局下的位置索引;video_position_scale_factor与vlm_cond_position_scale_factor对应论文里的 resolution interpolation / scale factor 设计。
这点对 image editing 特别关键,因为编辑任务需要严格的空间对应关系:被编辑区域、保留区域、条件图像与输出图像之间不能只有 semantic 对齐,还要有 geometry 对齐。
3.3 数据构造:从 general synthesis 到 text/science/reasoning-centric synthesis
3.3.1 General synthesis pipeline

Figure 6 解读:Figure 6 展示了 general data synthesis 的主干流程。最左边先做 filtering、retrieval-based expansion、synthesis-based expansion 和 deduplication,得到高质量 source pool;随后分成两条支路:一条做 T2I caption synthesis,另一条做 image editing instruction + edited image synthesis;最后再用 task-aware verification 从 instruction following、editing consistency、generation quality 三个维度做过滤。Figure 6 说明作者并不是单纯“收集更多数据”,而是设计了一条以质量控制和语义覆盖为中心的自动化合成流水线。
General data synthesis 的关键点有三项:
- 先做强过滤:aesthetic score、resolution、NSFW、水印过滤;
- 再做双支路扩增:retrieval-based 扩长尾概念,synthesis-based densify visual manifold;
- 对 editing data 做路由与验证:router 决定属于 global/object/attribute/compositional 哪类编辑,再交给对应 agent 合成与验证。
开放数据池(Table 1)主要包括:
- T2I:LAION、BLIP-3o、ShareGPT-4o-Image、OSP、Echo-4o-Image、OpenGPT-4o、FaceCaption、Flux-Reason-6M、HumanCaption、POSTER-TEXT、AutoPoster、CTW;
- IT2I:InstructPix2Pix、AnyEdit、PIPE、ImgEdit、SEED-Data-Edit、OmniEdit、UltraEdit、HQEdit、X2Edit、X2I2、UniWorld perception、NHR-Edit、GPT-hqedit、GPT-omniedit、GPT-ultraedit、Nano-consistent-150k、Pico Banana 等。
3.3.2 Text-centric synthesis
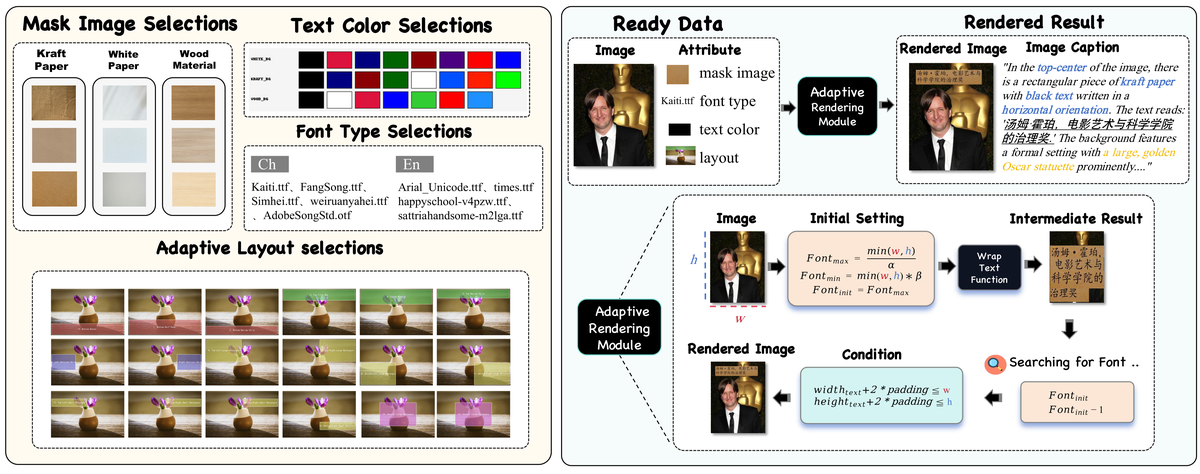
Figure 8 解读:Figure 8 对 text rendering 数据合成给出了非常具体的工程图。左侧准备 mask image、text color、font type、adaptive layout;中间 adaptive rendering module 会根据文本长度、区域大小和字体动态调整字号、换行与布局;最后再生成 rendered result 与 caption。这个 figure 表明作者把“文字渲染能力弱”视作统一模型的系统性短板,因此单独为它做了一条 typography-aware pipeline,而不是依赖通用图文数据自然学出来。

Figure 9 解读:Figure 9 展示 text editing triplet 的生成过程:先用 OCR 检出候选文本区域,再让 instruction generator 生成语义明确的编辑指令,最后把文本、polygon 与 instruction 交给 text-editing agent 生成 target image。这个 figure 的重点在于 text edit 不是普通 image edit,它需要局部定位、文本正确性、背景保持三者同时成立,因此作者把 OCR、instruction generation、editing agent 串成一个专门的数据引擎。
text-centric 数据分三类:
- 自然图像上叠加语义相关文本;
- 纯色背景上的文字渲染;
- 真实 / 虚拟场景中的文本编辑。
这条数据线直接服务于论文里最亮眼的结果之一:LongText-Bench 和 TextEdit 上的显著提升。
3.3.3 Science-centric synthesis

Figure 10 解读:Figure 10 展示 science-centric data generation 的三条来源:general science T2I、SVG-based physics editing、computer science editing。其中特别重要的是 physics 分支使用 PaddleOCR 从文档抽图与上下文,再用大模型生成 SVG code 对,最后渲染成 image pair;computer science 分支则直接定义任务、调用 Python libraries 渲染图结构/树/FSM。这说明作者没有把“科学图像”当成普通 captioned image,而是把它当成强结构、强规则、强知识依赖的数据类型来单独建模。
science-centric pipeline 的亮点在于:
- general science T2I:来自科学理解数据集、教材、竞赛题的高知识密度图像;
- physics editing:用 SVG 而不是昂贵 proprietary editing model 来构造成对样本,论文报告单样本成本从
$0.16降到$0.03; - computer science editing:显式定义树、图、FSM 等任务,并通过固定 anchor point 保证 input-output 的空间一致性。
3.3.4 Reasoning-centric synthesis

Figure 16 解读:Figure 16 很直观地展示了 reasoning-centric synthesis 的作用:左侧原始 prompt 很短、很抽象;中间通过 CoT reasoning 自动补出对象属性、空间关系、编辑约束、执行步骤;右侧最终生成/编辑结果和评测分数明显更可靠。这个 figure 说明 CoT 在 InternVL-U 中不是一个“推理时可选增强器”,而是训练数据构造阶段的核心 supervision 设计。
reasoning-centric synthesis 的本质,是把短 prompt 变成包含以下信息的“可执行规格书”:
- refined objective;
- decomposed sub-tasks;
- verifiable constraints;
- ordered editing operations。
论文主要把它用在四类场景:
- General Images:补足 scene/object/style 细节;
- Knowledge-infused Images:把隐式知识显式化;
- Meme Images:补 humor structure、caption placement 等隐含约束;
- Science Images:把 scientific concept / algorithmic procedure 变成逐步视觉执行说明。
3.4 训练目标与训练流程
3.4.1 文本目标:Next-Token Prediction
给定 multimodal context ,文本分支优化标准 NTP:
这个 objective 保证 InternVL-U 不会因为接入生成头而丢掉原始 MLLM 的 instruction following 与 reasoning 能力。
3.4.2 图像目标:Flow Matching with velocity parameterization
图像分支不预测离散 visual token,而是在连续 latent 空间里做 Flow Matching。论文定义:
其中 ,,随后优化:
也就是说,InternVL-U 的 visual head 学的是 velocity field,而不是传统 discrete VQ token。
3.4.3 联合目标
最终总损失是:
其中 和 会在不同训练阶段动态调整。根据 Table 3:
- Stage 1 / Stage 2:
Loss weight (NTP:VP) = 0:1,先把生成头训稳; - Stage 3:
Loss weight (NTP:VP) = 1:20,再把 reasoning 与 generation 做 end-to-end 协同。
3.4.4 三阶段训练 curriculum
-
Stage 1: Generation Head Pre-training
冻结 backbone,只训练 visual gen head;250k steps,batch size 2048,固定 512 分辨率,数据为T2I + IT2I,ratio4:1。 -
Stage 2: Any-resolution Continued Pre-training
继续冻结 backbone,但允许 any-resolution 训练;60k steps,batch size 1024,分辨率(512, 1024),数据 ratio3:4;编辑任务显式注入 condition image 的 VAE latent。 -
Stage 3: Unified Supervised Finetuning
全模型解冻;20k steps,batch size 1024,数据为T2I + IT2I + Und,ratio1:1:2;额外混入 CoT 数据,让模型学会“先推理,再执行生成/编辑”。
3.5 伪代码(基于官方公开推理代码;训练阶段仅按论文描述)
说明:官方 GitHub 已公开 inference code,但没有公开完整 training code。因此下面伪代码优先对应公开实现;凡仅来自论文描述的部分,我会明确说明。
3.5.1 组件一:构造三路条件输入(完整条件 / drop text / drop all)
# Corresponds to: InternVLUProcessor.__call__
def build_generation_batch(prompts, images, generation_mode, resolution):
if generation_mode == "text":
drop_types = ["none"]
else:
drop_types = ["none", "text", "all"]
texts = []
generation_flags = []
image_tensors = []
gen_image_tensors = []
gen_grids = []
for prompt, image in zip(prompts, images):
messages = build_messages(prompt, no_image=(image is None))
for drop_type in drop_types:
dropped_messages = get_drop_messages(copy_messages(messages), drop_type)
template = choose_template(image is None)
prompt_text = apply_chat_template_with_conv(
dropped_messages,
template,
add_generation_prompt=True,
).replace("<image>", "<IMG_CONTEXT>")
if generation_mode == "image":
prompt_text = prompt_text + "<img>"
prompt_text, image_patches = insert_media_placeholders(prompt_text, image)
texts.append(prompt_text)
if image is not None and drop_type in ["none", "text"]:
image_tensors.append(image_patches.pixel_values)
gen_image_tensors.append(image_patches.pixel_values_gen)
gen_grids.append(image_patches.image_grid_thw)
generation_flags.extend([0] * image_patches.num_real_images)
gen_grids.append(make_target_grid(resolution))
generation_flags.append(1)
tokenized = tokenizer(texts, padding=True)
return {
"input_ids": tokenized.input_ids,
"attention_mask": tokenized.attention_mask,
"pixel_values": concat_if_needed(image_tensors),
"pixel_values_gen": concat_if_needed(gen_image_tensors),
"image_grid_thw_gen": concat(gen_grids),
"generation_flags": tensor(generation_flags),
}3.5.2 组件二:从 VLM hidden states 构造 diffusion conditioning
# Corresponds to: InternVLUPipeline._prepare_diffusion_inputs
# and _prepare_hidden_state_mask / _prepare_image_hidden_state_mask
def prepare_diffusion_inputs(input_ids, attention_mask, generation_flags, vlm_hidden_states):
# 1. pick selected VLM layers and concatenate them
stacked_states = concat_selected_layers(vlm_hidden_states)
# 2. for each <img> to be generated, collect the hidden states
# from the second <|im_start|> up to that image token
state_mask = build_hidden_state_mask(
input_ids=input_ids,
attention_mask=attention_mask,
generation_flags=generation_flags,
)
encoder_hidden_states = [stacked_states[m] for m in state_mask]
encoder_image_token_mask = [is_img_context_token(input_ids)[m] for m in state_mask]
# 3. if editing, gather previous real images in the same sequence
cond_image_mask = build_image_condition_mask(
input_ids=input_ids,
attention_mask=attention_mask,
generation_flags=generation_flags,
)
conditional_images = collect_previous_images(cond_image_mask)
condition_fhw = collect_condition_shapes(cond_image_mask)
return {
"encoder_hidden_states": encoder_hidden_states,
"encoder_image_token_mask": encoder_image_token_mask,
"conditional_image": conditional_images,
"image_fhw_cond": condition_fhw,
}3.5.3 组件三:Dual-Stream MMDiT block with gated attention
# Corresponds to: InternVLUTransformerBlock._forward_ve
# and InternVLUDoubleStreamFlashAttnProcessor._call_ve
def dual_stream_block(hidden_states, temb, enc_token_mask, rotary_emb):
img_mod_params = img_mod(temb)
txt_mod_params = txt_mod(temb)
img_mask = 1.0 - enc_token_mask
txt_mask = enc_token_mask
mod_params = img_mod_params * img_mask + txt_mod_params * txt_mask
mod1, mod2 = split_in_half(mod_params)
# attention branch
normed = mix(
img_norm1(hidden_states),
txt_norm1(hidden_states),
txt_mask,
)
modulated, gate1 = adaptive_modulate(normed, mod1)
attn_output = joint_flash_attention(
hidden_states=modulated,
enc_token_mask=enc_token_mask,
rotary_emb=rotary_emb,
)
hidden_states = hidden_states + gate1 * attn_output
# ffn branch
normed2 = mix(
img_norm2(hidden_states),
txt_norm2(hidden_states),
txt_mask,
)
modulated2, gate2 = adaptive_modulate(normed2, mod2)
mlp_output = mix(img_mlp(modulated2), txt_mlp(modulated2), txt_mask)
hidden_states = hidden_states + gate2 * mlp_output
return hidden_states3.5.4 组件四:三路 CFG 的 Flow Matching 采样
# Corresponds to: InternVLUDiffusionPipeline.__call__
def sample_image(prompt_embeds, conditional_images, scheduler, num_steps,
all_cfg_scale=3.5, part_cfg_scale=1.5):
latents = randn_latents(batch_size=len(prompt_embeds) // 3)
timesteps = scheduler.get_timesteps(num_steps)
for t in timesteps:
latent_input = concat([latents, latents, latents])
noise_pred = transformer(
hidden_states=latent_input,
encoder_hidden_states=prompt_embeds,
conditional_input=conditional_images,
timestep=t,
)
noise_pred_cond, noise_pred_part, noise_pred_uncond = chunk3(noise_pred)
guided_noise = (
noise_pred_uncond
+ part_cfg_scale * (noise_pred_part - noise_pred_uncond)
+ all_cfg_scale * (noise_pred_cond - noise_pred_part)
)
latents = scheduler.step(guided_noise, t, latents)
return vae.decode(latents)3.5.5 组件五:先生成 CoT,再生成图像
# Corresponds to: InternVLUPipeline._generate_image_with_cot
def cot_guided_image_generation(input_ids, attention_mask, pixel_values):
# first third: normal condition branch, used to generate reasoning text
text_ids = input_ids[: len(input_ids) // 3]
text_mask = attention_mask[: len(attention_mask) // 3]
cot_tokens = vlm_generate(
input_ids=text_ids,
attention_mask=text_mask,
pixel_values=pixel_values,
max_new_tokens=200,
)
# truncate at eos or <img>, then append <img> token explicitly
cot_prefix = trim_to_eos_or_img(cot_tokens)
new_input_ids, new_attention_mask = concat_back_to_three_branches(
original_input_ids=input_ids,
original_attention_mask=attention_mask,
cot_prefix=cot_prefix,
)
new_input_ids = append_img_token(new_input_ids)
new_attention_mask = append_one(new_attention_mask)
return generate_image(
input_ids=new_input_ids,
attention_mask=new_attention_mask,
pixel_values=pixel_values,
)3.6 Code-to-paper mapping table
| Paper Concept | Source File | Key Class / Function |
|---|---|---|
| 统一 UMM 端到端入口 | internvlu/pipeline_internvlu.py | InternVLUPipeline.__call__, _generate_image, _generate_image_with_cot |
| 多模态 prompt 组装与条件 dropout | internvlu/processing_internvlu.py | InternVLUProcessor.__call__, get_drop_messages, _insert_media_placeholders |
| VLM hidden state 导出与 image token 替换 | internvlu/vlm/modeling_internvlu_chat.py | InternVLUChatModel.generate_hidden_states, extract_feature |
| context projector / decoder 输入准备 | internvlu/diffusion/modeling_internvlu_generation_decoder.py | InternVLUGenerationDecoder.prepare_forward_input, decoder_projector |
| Dual-Stream MMDiT block | internvlu/diffusion/internvlu_transformer.py | InternVLUTransformerBlock._forward_ve |
| Gated joint attention | internvlu/diffusion/internvlu_transformer.py | InternVLUDoubleStreamFlashAttnProcessor._call_ve |
| Unified MSRoPE 与 3D 位置构造 | internvlu/diffusion/internvlu_transformer.py | UnifiedMSRoPE, create_position_ids_3d_v2, create_position_ids_3d_v3 |
| Flow Matching / 三路 CFG 采样 | internvlu/diffusion/pipeline_internvlu_generation_decoder.py | InternVLUDiffusionPipeline.__call__ |
| 三阶段训练 curriculum | 论文公开,训练代码未完整开源 | Section 3.2.2, Table 3 |
4. Experimental Setup(实验设置)
4.1 数据与任务
训练数据由两部分组成:
- 开放数据池:T2I 与 IT2I 数据集(见上文 Table 1 列表);
- 定向合成数据:general、text-centric、science-centric、spatial-centric、meme、reasoning-centric 数据。
评测任务覆盖五大块:
- Multimodal understanding / reasoning:MME-P、SEED、ChartQA、OCRBench、MMMU、MathVerse、LogicVista;
- General T2I:GenEval、DPG-Bench、TIIF、OneIG-EN / ZH;
- Text-centric T2I:CVTG-2k、LongText-Bench;
- Knowledge-informed T2I:WISE、GenExam;
- Image Editing:ImgEdit、GEdit-Bench、TextEdit、RISEBench。
其中文中自建的 TextEdit benchmark 含 2,148 个样本,覆盖 real scene 与 virtual scene 两类文本编辑场景。
4.2 评测指标
- 理解 / 推理:直接使用 benchmark score;
- 生成 / 编辑:通过作者开源的
GenEditEvalKit统一管理推理与评测; - TextEdit classic metrics:OA、OP、OR、F1、NED、CLIPScore、AES;
- TextEdit MLLM-based metrics:TA、TP、SI、LR、VC、Avg。
4.3 模型配置
根据 Table 2,InternVL-U 由三部分组成:
| 模块 | 层数 | Heads (Q/KV) | Hidden / Intermediate | 其他 | 参数量 |
|---|---|---|---|---|---|
| Visual Understanding Encoder | 24 | 16 / 16 | head size 64, intermediate 4096 | patch size 14 | 0.3B |
| Context Backbone | 28 | 16 / 8 | head size 128, intermediate 6144 | - | 2B |
| Visual Generation Head | 20 | 12 / 12 | head size 128, intermediate 6144 | scale factor 2 | 1.7B |
总参数量约 4B。
4.4 训练超参数
根据 Table 3:
| Stage | Trainable modules | LR | Steps | Batch | Resolution | Data / ratio |
|---|---|---|---|---|---|---|
| Stage 1 | 只训 visual gen. head | 3e-4 | 250k | 2048 | (512, 512) | T2I + IT2I, 4:1 |
| Stage 2 | 继续冻结 backbone | 1e-4 | 60k | 1024 | (512, 1024) | T2I + IT2I, 3:4 |
| Stage 3 | 全模型解冻 | 1e-5 | 20k | 1024 | (512, 1024) + understanding 448 | T2I + IT2I + Und, 1:1:2 |
另外:
- inference 用 Flow-DPM-Solver;
- 默认 20 inference steps;
- inference 时 CFG scale:
all_cfg_scale = 3.5,part_cfg_scale = 1.5; - 训练时 T2I condition dropout 10%,editing 时全条件 dropout 5%,仅 text dropout 5%。
4.5 未说明的信息
- 训练硬件:论文未详细说明;
- 训练总样本规模 / token 数:论文未给出完整统计;
- 完整训练代码:官方仓库暂未完整公开。
5. Experimental Results(实验结果)
5.1 多模态理解与推理能力保留得比较好
Table 4 表明 InternVL-U 在加上生成头之后,并没有明显牺牲理解能力:
| Benchmark | InternVL-U | 对比结论 |
|---|---|---|
| MME-P | 1607.5 | 明显高于 Janus-Pro 1444.0、Ovis-U1 1508.0* |
| OCRBench | 83.9 | 明显高于 Janus-Pro 48.7,也优于 BAGEL 73.3 |
| MMMU | 54.7 | 接近大得多的 BAGEL 55.3 |
| MathVerse | 45.6 | 高于 Ovis-U1 30.6*,略低于 InternVL3.5-2B 的 53.4 |
这说明作者的设计目标基本达成:在统一模型里加入 generation / editing 后,understanding backbone 没有被严重拖垮。
5.2 General T2I:小参数统一模型里表现很强
| Benchmark | InternVL-U | 关键信息 |
|---|---|---|
| GenEval | 0.85 | 高于所有 open-source unified baselines;BAGEL 为 0.82 |
| DPG-Bench | 85.18 | 略高于 BAGEL 85.07,尤其在 Global / Entity 上更强 |
| TIIF (short) | 74.9 | 高于 BAGEL 71.5 |
| TIIF (long) | 73.9 | 高于 BAGEL 71.7 |
| OneIG-EN | 0.50 | 在 unified models 中最高 |
| OneIG-ZH | 0.50 | 同样在 unified models 中最高 |
不过论文也明确承认:在 TIIF 上,统一模型和专门的 generation model 仍然有明显差距,例如 Qwen-Image 在 long prompt TIIF 上是 86.8。因此 InternVL-U 虽然已经很强,但 instruction following 上仍未追平专门大模型。
5.3 Text-centric generation 是最亮眼的结果之一

Figure 21 解读:Figure 21 展示了中英文、数学公式等文本渲染 qualitative case。和 BAGEL、Ovis-U1 相比,InternVL-U 的字符清晰度、排版稳定性和公式可读性明显更好;和 Qwen-Image、Nano Banana Pro 相比,它在更小参数量下也能保持较高的文本可读性。这张图很好地支撑了 Table 11 和 Table 12 的定量结果:作者专门构造的 text-centric data pipeline 确实显著改善了 unified model 的文字渲染短板。
对应的定量结果:
| Benchmark | InternVL-U | 对比结论 |
|---|---|---|
| CVTG-2k average word accuracy | 0.623 | 远高于 Ovis-U1 0.093、BAGEL 0.356 |
| LongText-Bench-EN | 0.738 | 显著高于 BAGEL 0.373 |
| LongText-Bench-ZH | 0.860 | 显著高于 BAGEL 0.310 |
这部分结果非常关键,因为它表明 “高语义密度的文字图像”是可以通过专门数据设计显著补强的。
5.4 CoT 对 knowledge-intensive generation 非常重要
| Benchmark | InternVL-U | InternVL-U (w/ CoT) | 结论 |
|---|---|---|---|
| WISE overall | 0.46 | 0.58 | 提升 0.12,超过 BAGEL 0.49 |
| GenExam overall | 20.8 | 22.9 | unified models 中最高 |
尤其在 GenExam 上,CoT 版 InternVL-U 在 Physics、Chemistry、Biology 等需要显式知识推理的维度上都有提升。这个结果和方法部分的 reasoning-centric data synthesis 是强对应关系:不是简单增加 prompt 长度,而是把知识与步骤显式注入到 supervision 中。
5.5 General editing:统一架构已经具备实用竞争力
| Benchmark | InternVL-U | InternVL-U (w/ CoT) | 对比 |
|---|---|---|---|
| ImgEdit overall | 3.67 | 3.82 | 高于 BAGEL 3.20,接近 Ovis-U1 3.97 |
| GEdit-Bench Avg | 6.66 | 6.88 | 高于 BAGEL 6.52、Ovis-U1 6.42 |
说明 InternVL-U 不只会 T2I,也能在实际 edit 任务里保持不错的 instruction alignment 和 visual consistency。
5.6 Text-centric editing 是另一个非常强的结果

Figure 24 解读:Figure 24 展示了真实商品包装、标牌、界面文字替换等 TextEdit 场景。InternVL-U 可以比较稳定地定位待替换文本区域,并在保持背景风格、材质和局部几何一致的同时替换成目标文本;相比 BAGEL 和 Ovis-U1,错误字符、背景破坏和文本漏删都更少。这张图和 TextEdit 的定量结果互相支撑,说明作者构造的 OCR + instruction generation + text-editing agent 数据线是有效的。
TextEdit 上的核心数字:
| Setting | Classic F1 | MLLM Avg | 对比结论 |
|---|---|---|---|
| Real scene | 0.71 | 0.88 | F1 与 Nano Banana Pro 持平,MLLM Avg 显著高于 BAGEL 0.53 |
| Virtual scene | 0.75 | 0.83 | 明显高于 Ovis-U1(F1 0.39, Avg 0.19) |
这部分结果几乎可以看作论文最有辨识度的卖点之一:一个 3.7B 级 unified model,在 text editing 上已经接近甚至匹敌一些 closed-source / specialized model。
5.7 Reasoning-informed editing:CoT 带来质变
| Benchmark | InternVL-U | InternVL-U (w/ CoT) | 对比 |
|---|---|---|---|
| RISEBench overall | 3.6 | 9.4 | 超过 BAGEL 6.1,也超过 Qwen-Image-Edit 8.9 |
| IR | 35.6 | 43.9 | 明显提升 |
| AC | 52.7 | 64.4 | 明显提升 |
| VP | 75.9 | 79.7 | 也有提升 |
这说明在复杂 edit 任务里,CoT 不只是“锦上添花”,而是 决定模型能否正确执行多步逻辑约束 的关键组件。
5.8 论文反映出的局限性
作者没有单列一个 limitations section,但从实验描述里可以明确看出几件事:
- TIIF 等复杂 instruction-following benchmark 上,仍落后于最强专用 generation model;
- GEdit-Bench 等编辑任务上,仍低于 Qwen-Image-Edit 这类大规模专用编辑模型(例如 Qwen-Image-Edit 平均 8.01,而 InternVL-U w/ CoT 为 6.88);
- 训练规模、硬件、完整训练代码未公开,因此当前更适合作为技术路线和系统设计参考,而不是可完全复现的 recipe;
- 论文虽然展示了大量 qualitative case,但 failure cases 与负面分析还不够系统。
5.9 总结结论
如果把这篇论文放在“统一多模态模型”这个大方向里看,我认为它最重要的价值有三点:
- 架构层面:提出了一种比“强行 token 统一”更自然的 unified design——统一语义空间、分离生成目标;
- 数据层面:明确证明 high-semantic-density data 和 CoT synthesis 对 unified model 极其关键;
- 结果层面:在 4B 量级上同时做到 understanding 不掉太多、text rendering/text editing 很强、knowledge/reasoning editing 有明显提升。
因此,InternVL-U 更像一个 面向 AGI-oriented UMM 的强 baseline:它未必在所有子任务上都是最强,但它把“怎么同时保住 understanding,又把 generation/editing 做起来”这件事讲清楚了。