GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents
Paper: arXiv:2604.26752
1. Motivation (研究动机)
当前 multimodal agent 的瓶颈不只是“看图回答问题”,而是在真实任务中同时处理图像、视频、网页、文档、GUI 和工具调用,并把视觉感知融入推理、规划与执行。许多 VLM 仍把 vision 当作语言模型的外挂输入,导致 GUI 操作、网页生成、视觉搜索、文档解析等 agentic tasks 上能力不稳定。
本文想解决的具体问题是:构建一个面向 multimodal agents 的 native foundation model,使 multimodal perception 不只是前置识别模块,而是 reasoning / planning / tool use / execution 的核心组成。
这个问题值得研究,因为 agentic deployment 的成功取决于端到端任务执行:模型既要懂视觉上下文,又不能牺牲 text coding、tool orchestration 和 long-horizon action 的基础能力。
2. Idea (核心思想)
核心 insight 是把“视觉编码器、multimodal token prediction、agentic RL infrastructure”一起设计,而不是只在语言模型前面拼一个视觉塔。GLM-5V-Turbo 的目标是让视觉 token 从预训练、SFT、RL 到工具生态都被原生处理。
关键创新包括 CogViT vision encoder、Multimodal Multi-Token Prediction (MMTP)、覆盖 30+ task categories 的 multimodal RL,以及面向 GUI/Claw/Claude Code/OpenClaw 的工具链整合。
与典型 VLM benchmark model 不同,GLM-5V-Turbo 的评价重点不是单张图 QA,而是 multimodal coding、visual search、GUI agents、text coding 与 Claw-style execution 的联合能力。
3. Method (方法)
3.1 CogViT vision encoder
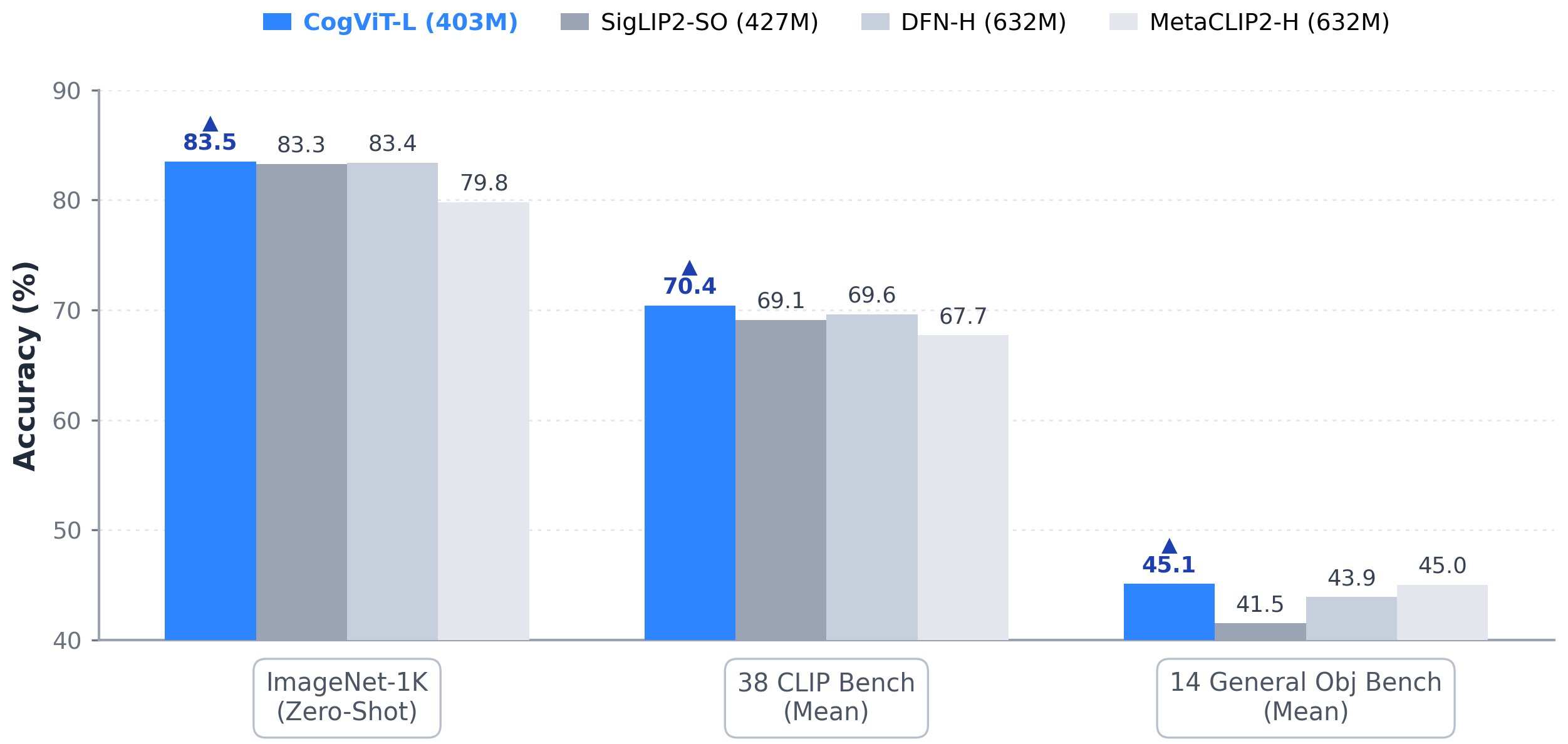
Figure 1 解读:CogViT-L (403M) 在 ImageNet-1K zero-shot 上为 83.5%,略高于 SigLIP2-SO 83.3% 和 DFN-H 83.4%;在 38 CLIP Bench mean 上为 70.4%,高于 SigLIP2-SO 69.1、DFN-H 69.6、MetaCLIP-H 67.7;在 14 General Obj Bench mean 上为 45.1%,与 MetaCLIP-H 45.0 接近。图的重点是 CogViT 用更小参数量覆盖 general / fine-grained / object-centric 能力。
CogViT 使用两阶段 pretraining。第一阶段是 distillation-based masked image modeling:35% masking ratio、$224\times224$ resolution,用 SigLIP2 提供 semantic representation、DINOv3 提供 texture features;数据混合为 80% high-quality natural images、10% instruction-following data、10% scientific imagery,并用 Muon optimizer + cosine decay + QK-Norm 稳定大规模 attention。第二阶段转向 contrastive image-text pretraining,用 NaFlex 支持 variable-size inputs 和原始 aspect ratio,SigLIP loss 的 global batch size 扩到 64K,并使用 8B Chinese-English image-text corpus。
3.2 Multimodal Multi-Token Prediction (MMTP)
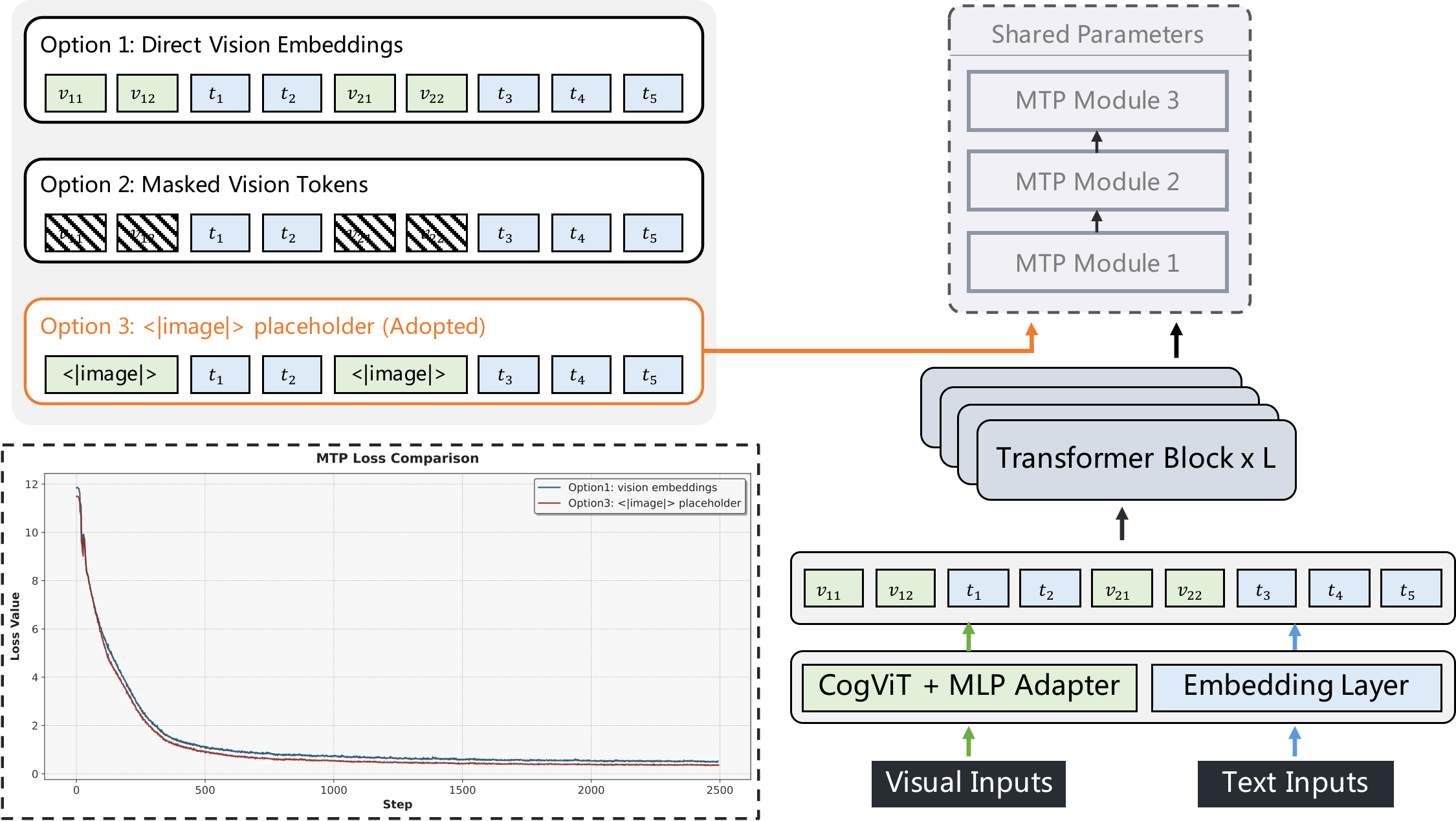
Figure 2 解读:MMTP 比较三种把视觉 token 送入 MTP head 的方式:直接传 visual embeddings、mask visual tokens、用共享 <|image|> placeholder。GLM-5V-Turbo 采用第三种,因为它保留视觉位置结构,又避免在 pipeline-parallel stages 之间传递大视觉 embedding,训练 loss 更低且系统实现更稳定。
论文没有给出新的 closed-form MMTP loss;可把它理解为 multimodal prefix 上的 multi-token prediction objective:
其中 visual input 在 adopted design 中不是原始 visual embedding,而是在对应位置放入 shared <|image|> token,让 MTP head 接收更接近 text embedding distribution 的输入。
3.3 Broad multimodal training and RL
预训练阶段混合 plain text 与 multimodal data,覆盖 world knowledge、interleaved image-text、OCR、coding、GUI、video、multimodal tool-use、spatial perception、grounding、academic problem-solving,并特别强调 multimodal coding data。
RL 阶段进行 30+ task categories 的 joint RL optimization。相对 SFT,RL 带来:RefCOCO-avg +4.8%、PointBench +3.2%、MVBench +5.6%、SUNRGBD +7.7%、OCRBench +4.2%、CharXiv +7.7%、STEM benchmarks +1.8%、OSWorld +4.9%、CC-Backend +0.2%、MMSearch +3.5%。论文强调 multi-task RL 的价值不只是覆盖任务更广,还能在不同任务间迁移 thinking patterns。
训练 stack 为 multimodal RL 做了四类系统改造:统一 task/reward abstraction;rollout inference、reward evaluation、batch construction、weight transfer 的全 pipeline decoupling;对 ViT/projector 做 targeted recomputation 与 CPU offloading;对 long-video visual inputs 做 topology-aware partitioning 和 dynamic load balancing,并报告 GPU communication buffer overhead 实际减少约 7 GB。
3.4 Tool ecosystem and agent integration
GLM-5V-Turbo 与外部 agent frameworks 结合,包括 Claude Code、AutoClaw、OpenClaw,以及 official skills。这里的核心不是单次调用工具,而是把 multimodal observation 变成可被 agent planner 和 coding workflow 使用的上下文。
代码搜索未找到开源实现:arXiv 页面未提供 GitHub;GitHub search 只找到 zai-org/GLM-V 和 zai-org/z-ai-sdk-python 等相关仓库,但没有 GLM-5V-Turbo 的模型训练代码、CogViT/MMTP implementation 或 RL stack source。因此本笔记不设置 github / github_ref,也不做 released-code mapping。
3.5 Paper-level pseudocode (not source-anchored)
import torch
import torch.nn.functional as F
def cogvit_stage1_mim(student_vit, siglip_teacher, dinov3_teacher, images, mask_ratio=0.35):
masked_images, mask = random_mask(images, ratio=mask_ratio, resolution=(224, 224))
student_features = student_vit(masked_images, mask=mask, qk_norm=True)
with torch.no_grad():
semantic_targets = siglip_teacher(images)
texture_targets = dinov3_teacher(images)
loss = F.mse_loss(student_features.semantic, semantic_targets) + F.mse_loss(student_features.texture, texture_targets)
return loss
def mmtp_forward(llm, cogvit, mlp_adapter, text_tokens, images, mtp_heads):
vision_tokens = mlp_adapter(cogvit(images))
image_placeholders = torch.full_like(vision_tokens[..., 0].long(), fill_value=IMAGE_TOKEN_ID)
backbone_input = interleave(text_tokens, vision_tokens)
mtp_input = interleave(text_tokens, image_placeholders)
hidden = llm.transformer(backbone_input)
losses = []
for k, head in enumerate(mtp_heads, start=1):
logits = head(hidden, mtp_input)
losses.append(F.cross_entropy(logits[:, :-k].reshape(-1, logits.size(-1)), text_tokens[:, k:].reshape(-1)))
return sum(losses) / len(losses)
def multimodal_rl_step(policy, ref_policy, tasks, reward_system):
rollouts = async_rollout(policy, tasks)
rewards = reward_system.verify_async(rollouts) # rule-based + model-based verifiers
batch = build_balanced_batch(rollouts, rewards, keys=["sequence_length", "vit_token_count"])
ref_logprob = ref_policy.forward_cpu_prefetch(batch)
loss = policy_gradient_loss(policy, batch, rewards, ref_logprob)
loss.backward()
return loss4. Experimental Setup (实验设置)
- Datasets / data scale:CogViT stage-1 使用 80% high-quality natural images、10% instruction-following data、10% scientific imagery;stage-2 使用 8B bilingual Chinese-English image-text corpus;RL 覆盖 30+ task categories。论文没有给出所有 SFT/RL 数据的样本总量。
- Baselines:CogViT 对比 SigLIP2-SO, DFN-H, MetaCLIP-H;benchmark figures 对比 Kimi K2.5、Claude Opus 4.6、GLM-4.5-Turbo。
- Evaluation metrics:ImageNet-1K zero-shot accuracy、38 CLIP Bench mean、14 General Obj Bench mean;agent/coding benchmarks 包括 Design2Code, Flame-VLM-Code, Vision2Web, ImageMining, BrowseComp-VL, MMSearch, MMSearch-Plus, SimpleVQA, Facts, V*, OSWorld, AndroidWorld, WebVoyager, CC-Bench-V2, PinchBench, ClawEval, ZClawBench。
- Training config:论文明确给出 CogViT 35% masking、
$224\times224$、NaFlex variable-size contrastive stage、SigLIP loss global batch size 64K、Muon optimizer、QK-Norm;没有公开 GPU type/count、learning rate、total training steps 或 batch composition 的完整 config。
5. Experimental Results (实验结果)
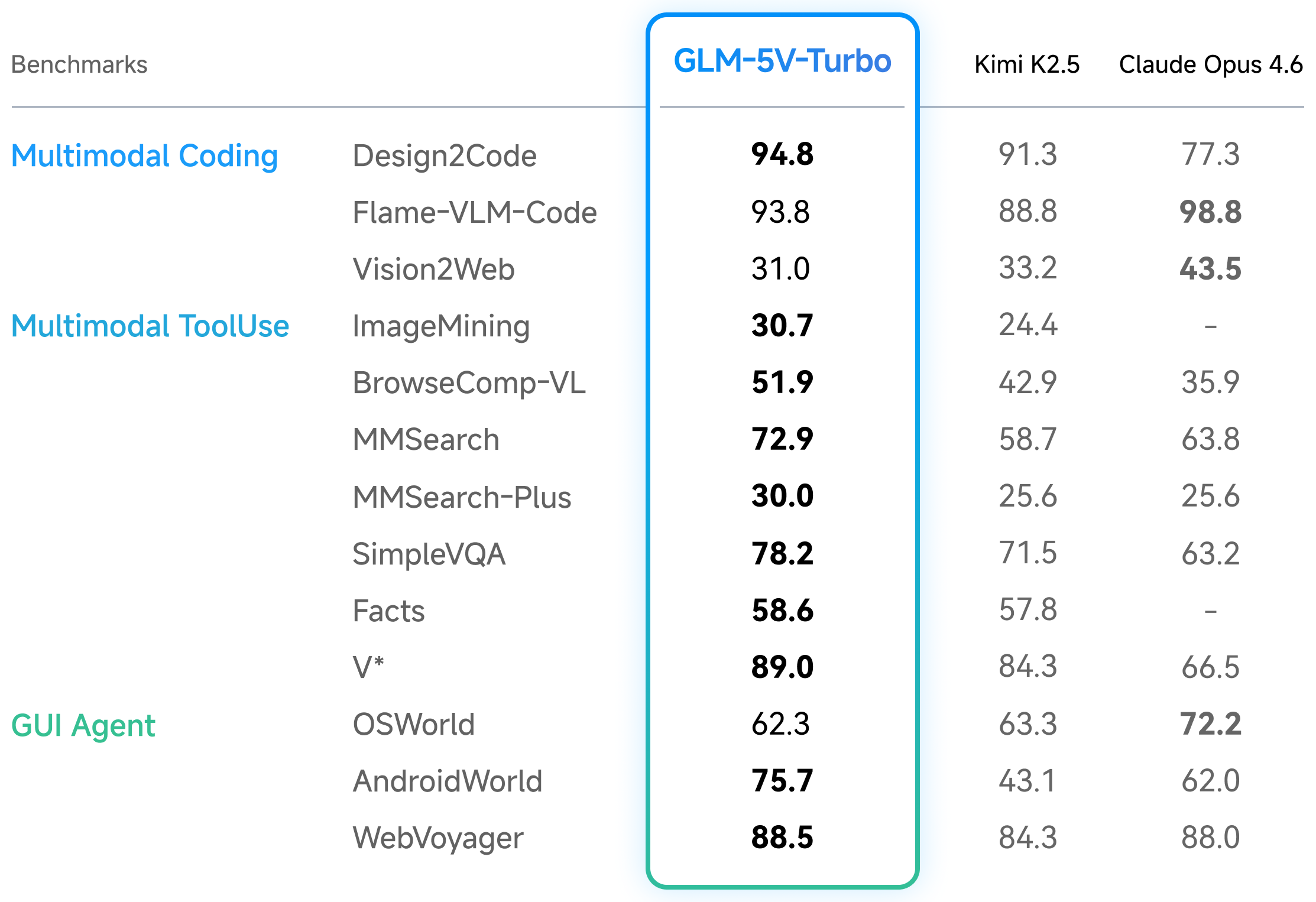
Figure 3 解读:GLM-5V-Turbo 在 multimodal coding/tool-use/GUI agent 上强。Design2Code 94.8(Kimi 91.3, Claude 77.3),Flame-VLM-Code 93.8(Kimi 88.8, Claude 98.8),Vision2Web 31.0(Kimi 33.2, Claude 43.5);ImageMining 30.7、BrowseComp-VL 51.9、MMSearch 72.9、MMSearch-Plus 30.0、SimpleVQA 78.2、Facts 58.6、V* 89.0;GUI agent 中 OSWorld 62.3、AndroidWorld 75.7、WebVoyager 88.5。
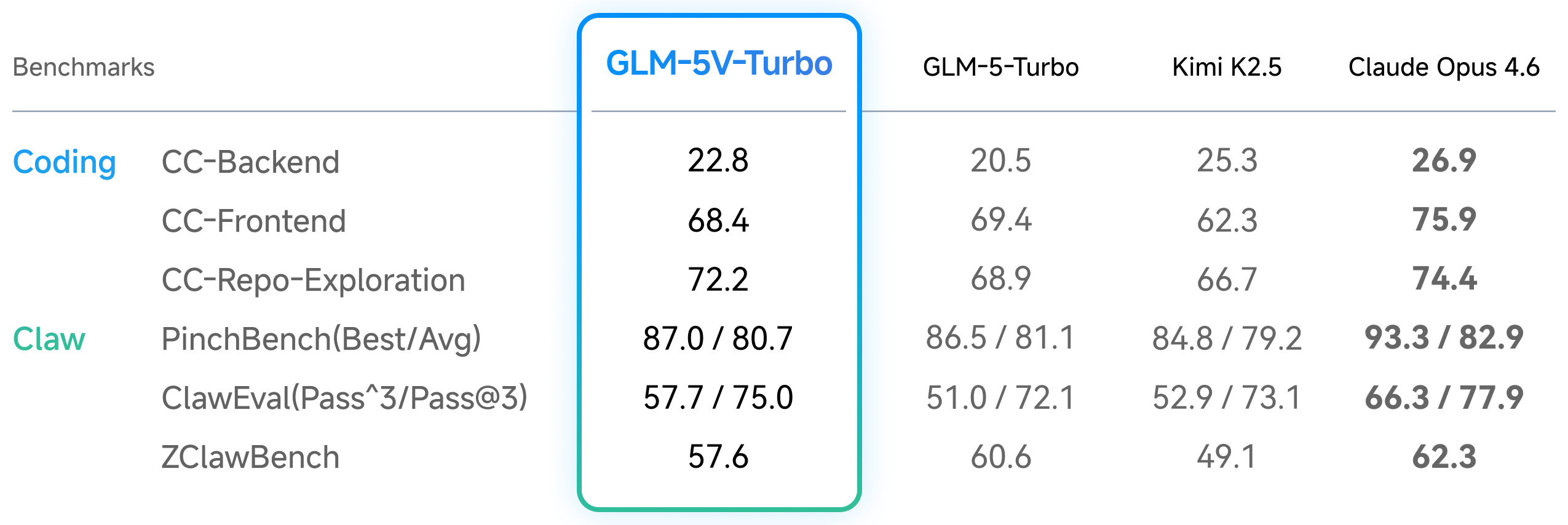
Figure 4 解读:text coding / Claw agent 上,GLM-5V-Turbo 并非全部第一,但保持可用的 coding base:CC-Backend 22.8、CC-Frontend 68.4、CC-Repo-Exploration 72.2;PinchBench Best/Avg 为 87.0/80.7;ClawEval Pass/Pass@3 为 57.7/75.0;ZClawBench 57.6。Claude Opus 4.6 在这些 execution-oriented metrics 上仍普遍更强,例如 PinchBench 93.3/82.9、ClawEval 66.3/77.9、ZClawBench 62.3。
关键结论是:GLM-5V-Turbo 在视觉 agentic 能力上相对同类模型有竞争力,同时没有完全牺牲 text-first coding/reasoning。作者列出的 remaining challenges 包括:agentic strategy emergence 仍依赖 hand-crafted/filtered cold-start trajectories;long-horizon multimodal context management 仍困难;model capability 与 harness design 越来越纠缠,评价结果不只反映模型本身。