DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
Paper: arXiv:2603.26164 Code: OpenDCAI/DataFlex Code reference:
main@f57037f8(2026-05-13)
1. Motivation (研究动机)
现有 LLM 训练通常把数据集、采样顺序和领域比例当成静态输入,但 data-centric training 的关键问题恰恰是:训练过程中哪些样本应被选中、不同来源数据应如何混合、每个样本对梯度更新应有多大权重。LESS、NICE、TSDS、DoReMi、ODM、loss reweighting 等方法已经覆盖了这些方向,但它们通常散落在方法专属 repo 中,接口、依赖、训练协议和评测协议不一致,导致复现与公平比较困难。
这篇论文要解决的具体目标不是再提出一个单点 data selection 算法,而是构建一个 Data-Centric Dynamic Training System:在不重写 LLM 训练栈的前提下,把 dynamic sample selection、domain mixture adjustment、sample reweighting 三类 data-control 信号统一接入训练循环。它选择 LLaMA-Factory 作为底座,保留模型管理、数据处理、优化器、DeepSpeed/FSDP 等成熟能力,只替换 trainer 层并增加少量数据加载适配。
这个问题值得研究的原因在于,许多 data-centric 方法都需要访问 model-dependent signals,例如 sample embedding、inference output、validation feedback、loss、gradient、optimizer state。没有统一抽象时,每个算法都要重新实现训练循环和分布式工程;有了统一系统后,研究者可以在同一框架里比较 selector/mixer/weighter,也能把这些策略部署到 ZeRO-3、多节点、多 GPU 的实际训练中。
2. Idea (核心思想)
核心洞察:data selection、data mixture、data reweighting 看起来控制对象不同,但都可以抽象为同一个闭环——观察当前模型状态或训练反馈,计算一个 data-control signal,再把该信号反馈到后续 optimizer step。DataFlex 因此把“算法差异”封装为 selector/mixer/weighter 组件,把“训练接入点”封装为 Select Trainer、Mix Trainer、Weight Trainer。
关键创新是把 data-centric 方法做成 LLaMA-Factory training layer 的 drop-in replacement,而不是外部 pipeline。这样,LESS 这类 gradient-based selector、DoReMi/ODM 这类 domain mixer、loss-based weighter 都共享模型加载、数据处理、分布式训练和日志体系;新增算法只需要注册一个组件,而不是复制整套训练脚本。
与原始方法 repo 的本质差异在于工程边界:LESS/DoReMi/ODM 原实现主要验证各自算法,DataFlex 则把它们放进同一 trainer-component-registry 架构中,并统一 embedding/inference/gradient 等 model-data interaction。论文特别强调这不是只支持 online 方法;offline TSDS/NEAR 和 offline DoReMi Step 3 也通过预计算结果或 static mixer 接入同一接口。
3. Method (方法)
3.1 Overall framework:三层架构
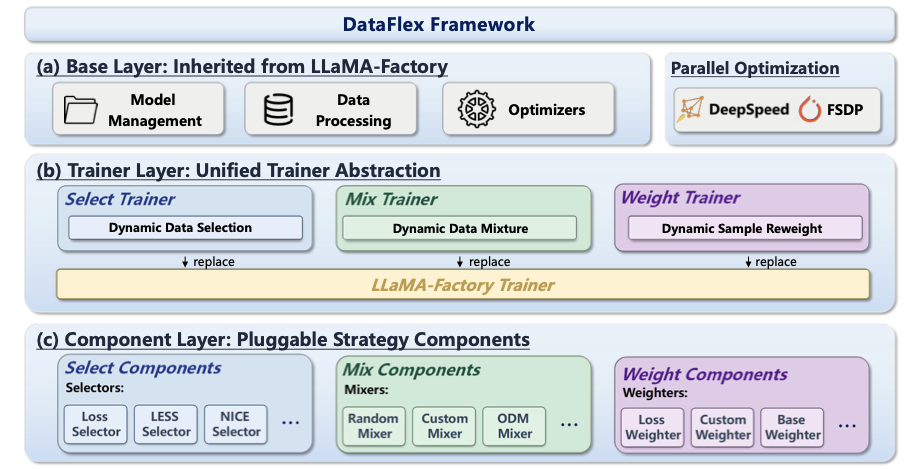
Figure 1 解读:DataFlex 分为 Base Layer、Trainer Layer、Component Layer。Base Layer 继承 LLaMA-Factory 的 model management、data processing、optimizer,以及 DeepSpeed/FSDP 等 parallel optimization;Trainer Layer 用 Select/Mix/Weight 三个动态 trainer 替换原 LLaMA-Factory Trainer;Component Layer 则挂载 Loss/LESS/NICE selector、Random/ODM mixer、Loss/Custom/Base weighter 等策略组件。这个图的重点是“只替换 trainer 层”,而不是把 data-centric 算法做成训练外部的独立流水线。
DataFlex 的三层设计如下:
- Base Layer:直接复用 LLaMA-Factory 的模型管理、数据处理、PEFT/full fine-tuning、优化器和分布式训练能力,避免重复实现通用训练逻辑。
- Trainer Layer:
SelectTrainer负责动态选样,MixTrainer负责动态领域混合,WeightTrainer负责样本级 loss 加权;三者都保留 HuggingFace/LLaMA-Factory 的训练循环语义。 - Component Layer:selector/mixer/weighter 通过 centralized registry 注册和实例化。组件只实现算法逻辑,trainer 决定何时调用、如何更新 dataloader 或 loss。

Figure 2 解读:左侧是 LESS dynamic selection 的示例 YAML,右侧是 DoReMi dynamic mixture 的示例 YAML。二者都保留 LLaMA-Factory 的 model/dataset/train 字段,只增加 dataflex 相关字段:train_type 选择训练范式,component_name 选择具体算法,warmup_step、update_step、update_times 控制动态更新频率。注意 released repo 中这些 example YAML 是 demo 配置,和论文实验中的 Mistral/Llama-3.2/SlimPajama 规模配置不完全一致。
3.2 Unified trainer-component interaction
三类方法的共同形式可以写成:
其中 是 selector/mixer/weighter 组件, 分别对应 sample indices、domain proportions 或 per-sample weights, 表示当前 batch loss、gradient、optimizer state、scheduler state 等运行时信号。DataFlex 的核心是让 trainer 固定这个闭环,而让组件决定 的具体算法。
论文统一的方法清单如下:
| 范式 | DataFlex 组件 | 已集成方法 | 是否 model-in-the-loop | 官方原实现状态 |
|---|---|---|---|---|
| Data Selection | selector | LESS, NICE, Loss, Delta Loss, NEAR, TSDS | LESS/NICE/Loss/Delta Loss 是;NEAR/TSDS 否 | LESS/NICE/DoReMi/ODM 部分可用或不稳定;TSDS 有官方实现;Loss/Delta Loss/NEAR/Loss Reweighting 无官方 repo |
| Data Mixture | mixer | DoReMi, ODM, static, random | DoReMi/ODM 是 | DoReMi/ODM 原 repo 存在但工程约束较多 |
| Data Reweighting | weighter | loss-based weighting | 是 | 论文中作为统一实现提供 |
3.3 Dynamic sample selection
SelectTrainer 的行为是:先用 warmup_step 训练/采样一段稳定模型状态;之后每隔 update_step 暂停训练,调用 selector.select(...) 生成下一段训练所需的样本索引;每次选择的样本数是 total_train_batch_size * update_step。在 released code 中,trainer 会把 optimizer_state、scheduler_state、current_update_times、update_times、tokenizer 传给 selector,之后基于新索引重建 dataloader。
以 LESS 为例,代码中的实际选择分数是 projected gradient 与 validation projected gradient 的平均相似度:
这里 是随机投影器,gradient_type 可取 adam 等;LessSelector.select 会分别缓存 train/eval projected gradients,主进程计算 train_projected_grads @ eval_projected_grads.T 并广播 top- indices。
Select Trainer 调度伪代码:
def select_trainer_update(trainer, model, step_in_epoch, total_batch_size):
if step_in_epoch < trainer.args.warmup_step:
indices = trainer.selector.warmup(total_batch_size * trainer.args.warmup_step)
return trainer.get_train_dataloader(indices)
should_update = (
step_in_epoch == trainer.args.warmup_step
or (step_in_epoch > trainer.args.warmup_step
and (step_in_epoch - trainer.args.warmup_step) % trainer.args.update_step == 0)
)
if not should_update:
return trainer.current_dataloader
new_indices = trainer.selector.select(
model=model,
step_id=trainer.state.global_step,
num_samples=total_batch_size * trainer.args.update_step,
optimizer_state=trainer.optimizer.state,
scheduler_state=trainer.lr_scheduler.state_dict(),
current_update_times=trainer.current_update_times,
update_times=trainer.args.update_times,
tokenizer=trainer.tokenizer,
)
return trainer.get_train_dataloader(new_indices)LESS Selector 伪代码:
def less_select(model, train_dataset, valid_dataset, num_samples, cache_dir):
train_grads = collect_projected_gradients(model, train_dataset, gradient_type="adam")
valid_grads = collect_projected_gradients(model, valid_dataset, gradient_type="sgd")
scores = (train_grads @ valid_grads.T).mean(dim=1)
return torch.topk(scores, k=num_samples, largest=True).indices.tolist()3.4 Dynamic data mixture:DoReMi 与 ODM
MixTrainer 处理 domain mixture:warmup 阶段用初始比例重建数据集;到更新点时调用 mixer.mix(model, step_id, batch, domain_ids, ...) 得到新的 domain proportions,再用 mixture_manager.set_proportions(probs) 和 mixture_manager.rebuild(...) 更新 dataloader。对于 DoReMi,MixTrainer.compute_loss 还会读取 batch 的 domain_id,按当前 domain weights 对 per-sample loss 加权。
DoReMi 在代码中的 per-domain excess loss 是 token 级裁剪后再按 domain 平均:
代码更新权重时会先对有效 domain 的 score 去均值,并把 score clip 到 ,再做指数更新和平滑:
论文实验中 DoReMi 的 ,,初始 ,。released code 的 DoremiMixer.mix 返回 uniform sampling weights,并把 主要用于 loss reweighting;这与论文“三步 DoReMi:Step 2 学权重、Step 3 用最终权重做 static mixture”的描述并不冲突,但实现路径上要理解为 Step 2 的采样和 loss 权重被拆开处理。
ODM 使用 Exp3 风格的 online bandit。代码中的探索率是:
每个 domain 的 reward estimate 用 moving average,而不是标准 Exp3 的累积和:
策略更新近似为:
DoReMi Mixer 伪代码:
def doremi_mix(mixer, model, batch, domain_ids, step_id):
proxy_loss, valid_mask = per_token_loss(model, batch)
ref_loss, _ = per_token_loss(mixer.reference_model, batch)
excess = torch.clamp(proxy_loss - ref_loss, min=0.0)
scores = torch.zeros(mixer.num_domains)
for domain_id in range(mixer.num_domains):
mask = (domain_ids == domain_id).unsqueeze(1) & valid_mask
scores[domain_id] = (excess * mask).sum() / mask.sum().clamp_min(1)
centered = torch.clamp(scores - scores[scores.isfinite()].mean(), -5.0, 5.0)
alpha_prime = mixer.domain_weights * torch.exp(mixer.eta * centered)
mixer.domain_weights = (1 - mixer.eps) * alpha_prime / alpha_prime.sum() + mixer.eps / mixer.num_domains
mixer.weight_history.append(mixer.domain_weights.clone())
return torch.ones(mixer.num_domains) / mixer.num_domainsODM Mixer 伪代码:
def odm_mix(mixer, previous_batch_loss, previous_domain_id, step_after_warmup):
if previous_batch_loss is not None:
reward = previous_batch_loss * mixer.reward_scale
prob = max(mixer.domain_weights[previous_domain_id], 1e-8)
mixer.estimated_rewards[previous_domain_id] = (
mixer.alpha * mixer.estimated_rewards[previous_domain_id]
+ (1 - mixer.alpha) * (reward / prob)
).clip(-10000.0, 10000.0)
eps = max(mixer.min_eps, min(1 / mixer.num_domains,
math.sqrt(math.log(mixer.num_domains) / (mixer.num_domains * step_after_warmup))))
logits = (mixer.prev_eps * mixer.estimated_rewards).clip(-5.0, 0.0)
weights = torch.exp(logits)
mixer.domain_weights = weights * ((1 - mixer.num_domains * eps) / weights.sum()) + eps
return mixer.domain_weights / mixer.domain_weights.sum()3.5 Sample reweighting 与分布式梯度支持
WeightTrainer 在 global_step >= warmup_step 后把每个 batch 的训练步骤委托给 weighter.training_step(...)。released code 的 LossWeighter 先在所有 GPU 上 all-gather per-sample losses,再归一化、应用策略、指数缩放并归一化权重:
默认策略 linupper 为 ,最终 loss 为 。这一实现把 sample reweighting 做成跨 GPU 一致的 per-sample loss 权重,而不是每张卡各自归一化。
def loss_weighted_loss(losses, strategy="linupper", delta=1.0, world_size=1):
gathered = all_gather(losses.detach())
l_min, l_max = gathered.min(), gathered.max()
normalized = 2 * delta * gathered / (l_max - l_min).clamp_min(1e-6) - delta * (l_max + l_min) / (l_max - l_min).clamp_min(1e-6)
if strategy == "linupper":
scores = torch.minimum(normalized + delta, delta * torch.ones_like(normalized))
elif strategy == "quadratic":
scores = 1 - normalized.pow(2) / delta**2
elif strategy == "extremes":
scores = normalized.abs()
else:
scores = normalized
weights = torch.exp(scores - scores.max())
weights = weights / weights.sum().clamp_min(1e-12)
local_weights = shard_for_current_rank(weights)
return (local_weights * losses).sum() * world_size分布式方面,DataFlex 的关键工程点是 ZeRO-3 下的 full gradient acquisition:许多 gradient-based selector/weighter 需要完整参数梯度,但 ZeRO-3 会把梯度切分到不同设备。论文和代码都强调通过 DeepSpeed 的 safe_get_full_grad 和 safe_get_full_optimizer_state 从 shard 中重建 full gradients / optimizer states,并用 configurable interval 与 cache 减少开销。
3.6 Code-to-paper mapping
Code reference:
main@f57037f8(2026-05-13) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| 中央注册表:selector/mixer/weighter 统一构建 | src/dataflex/core/registry.py | Registry, register_selector, register_mixer, register_weighter |
| Select Trainer:warmup 后按周期重选样本并重建 dataloader | src/dataflex/train/trainer/select_trainer.py | SelectTrainer.__init__, _inner_training_loop, get_train_dataloader |
| LESS gradient-similarity selector | src/dataflex/train/selector/less_selector.py | LessSelector._collect_and_save_projected_gradients, _merge_and_normalize_info, select |
| Mix Trainer:按 domain weights 重建 mixture dataloader | src/dataflex/train/trainer/mix_trainer.py | MixTrainer.compute_loss, _inner_training_loop, print_mixture_info |
| DoReMi mixer:reference loss、excess loss、指数权重更新 | src/dataflex/train/mixer/doremi_mixer.py | DoremiMixer.compute_batch_excess_losses, _update_domain_weights, mix |
| ODM mixer:Exp3 + EMA reward 的 online domain allocation | src/dataflex/train/mixer/odm_mixer.py | ODMMixer._compute_exploration_rate, _update_reward_from_batch, _update_policy, mix |
| Weight Trainer:warmup 后调用 weighter 的 training step | src/dataflex/train/trainer/weight_trainer.py | WeightTrainer._inner_training_loop |
| Loss-based sample reweighting | src/dataflex/train/weighter/loss_weighter.py | LossWeighter.normalize_losses, apply_strategy, get_weighted_loss |
| 组件默认参数与 demo 配置 | src/dataflex/configs/components.yaml, examples/train_*/*.yaml | less, doremi, odm, loss entries |
论文公式与 released code 实现差异:released repo 中未找到与论文报告完全一致的 Mistral-7B/Llama-3.2-3B selection 配置、SlimPajama-6B/30B mixture 配置或 paper-scale launch script;examples/ 下 YAML 是 demo(例如 Llama-3.1-8B + Alpaca、wiki_demo/c4_demo),不能当作论文实验配置。论文实验超参数因此以 paper text 为准。另一个实现细节是 ODM 论文设置写到 6B clipping threshold 、30B clipping threshold ,而 src/dataflex/train/mixer/odm_mixer.py 在当前 commit 中对 exponent logits 固定 np.clip(x, -5.0, 0.0),并对 reward estimate clip 到 ;未在 released configs 中看到 paper-scale 的 run-specific clipping threshold 覆盖。
4. Experimental Setup (实验设置)
4.1 Data selection 与 sample reweighting
- Dataset:训练池是 Open-Hermes-2.5 的 examples 子集;validation/test set 分别来自 MMLU validation/test splits。
- Models:Mistral-7B-v0.1 与 Llama-3.2-3B,均从官方 pretrained weights 初始化。
- Methods:online data selection 包括 LESS、NICE、Loss、Delta Loss、Random;offline selection 包括 NEAR、TSDS;sample reweighting 是 Reweight;full-data baseline 使用完整 训练集。
- Training config:PEFT LoRA 作用于所有 linear layers,rank 、scaling factor ;训练 epoch;optimizer 为 AdamW;cosine LR scheduler;warmup ratio ;learning rate ;global batch size ,由 per-device batch size 和 gradient accumulation steps 实现;online selection warmup 为
warmup_step=100,之后每update_step=50更新一次,共update_times=30;full-data baseline 使用相同 warmup;硬件为 NVIDIA H20 GPUs。
4.2 Data mixture
- Dataset:SlimPajama,包含 CommonCrawl (54.1%)、C4 (28.7%)、GitHub (4.2%)、Book (3.7%)、ArXiv (3.4%)、Wikipedia (3.1%)、StackExchange (2.8%) 七个 text domains;实验使用 SlimPajama-6B 与 SlimPajama-30B 两个 token scale。
- Models:目标模型是 Qwen2.5-1.5B;DoReMi 的 Step 1 reference model 与 Step 2 proxy model 使用 Qwen2.5-0.5B;所有模型从随机初始化开始训练,用于隔离 data mixture 的影响。
- Baseline:Qwen2.5-1.5B 用 default SlimPajama proportions 训练 static mixer;6B setting peak LR 、per-device batch size ;30B setting peak LR 、per-device batch size 。
- DoReMi:Step 1 训练 Qwen2.5-0.5B reference;Step 2 训练 Qwen2.5-0.5B proxy 并基于 excess loss 更新 domain weights;Step 3 用最终 weights 静态训练 Qwen2.5-1.5B。初始化 、、、。6B:LR 、batch size ,Step 2 gradient accumulation ,warmup steps,every steps update。30B:Steps 1—2 LR 、batch size ,warmup ,every steps update;Step 3 LR ;Step 2 两个 setting 都做 次 weight updates。
- ODM:单次训练中用 Exp3 multi-armed bandit + exponential moving average 动态调 domain weights。domain weights 从 default SlimPajama proportions 初始化;warmup steps;两个 setting 共享 和 reward scale 。6B:LR 、batch size 、、clipping threshold 、每 steps 更新。30B:LR 、batch size 、、clipping threshold 、每 steps 更新。
- Distributed/precision:所有 mixture experiments 训练 full epoch,linear LR decay,warmup ratio ,BFloat16 mixed precision,DeepSpeed ZeRO Stage-3,FlashAttention-2,Qwen tokenizer,random seed 。6B 所有 runs 在 single node GPUs;30B 扩展到 nodes,每 node H20 GPUs,总计 GPUs,用
torchrun协调多节点通信。
4.3 Efficiency evaluation
online selection 的效率实验比较 DataFlex LESS 与原始 LESS codebase。训练池来自最多 examples 的 Open-Hermes-2.5 子集,validation/test 使用带 GPT-5-generated trajectories 的 MMLU splits;base model 是 Llama-2-7b-hf。单 selection cycle 的主要调度改为 warmup_step=100、update_step=100、update_times=1;单 GPU 实验用 NVIDIA H20,扩展性实验用 NVIDIA H20,并设 warmup_step=100、update_step=200、update_times=3。
offline selection 的效率实验比较原始 TSDS operator 与 DataFlex re-implementation。每个 tokenized sample 用 qwen3-embed-0.6B 编码成 sentence-level embedding,再做 nearest-neighbor retrieval 与 KDE density estimation。固定 TSDS 超参数:max_K=5000、kde_K=1000、sigma=0.75、alpha=0.6、C=5。两个 scaling 维度分别是 training set 且 validation set 固定 ,以及 training set 固定 且 validation set 。
5. Experimental Results (实验结果)
5.1 Data selection 与 reweighting:MMLU accuracy
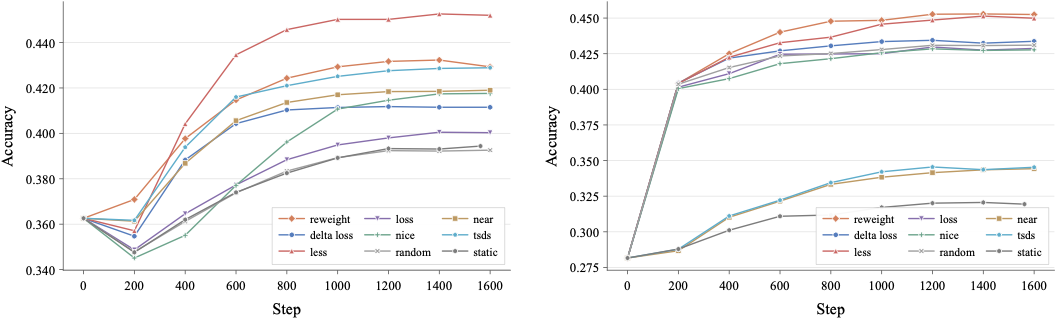
Figure 3a–3b 解读:左图是 Mistral-7B,右图是 Llama-3.2-3B,横轴为训练 step,纵轴为 MMLU accuracy。Mistral-7B 上 LESS 后期拉开明显差距,说明 gradient-based selection 在较大模型上更能找出对 validation 目标有帮助的样本;Llama-3.2-3B 上 static baseline 明显落后,所有 online methods 都超过 ,说明较小模型更依赖随训练状态更新的 model-aware data control。
最终 MMLU accuracy 的精确数值:
| Backbone | Static | LESS | Reweight | TSDS | NEAR | NICE | Delta Loss | Loss | Random |
|---|---|---|---|---|---|---|---|---|---|
| Mistral-7B | 0.394 | 0.452 | 0.429 | 0.429 | 0.419 | 0.418 | 0.412 | 0.400 | 0.393 |
| Llama-3.2-3B | 0.319 | 0.450 | 0.453 | 0.345 | 0.344 | 0.428 | 0.434 | 0.429 | 0.431 |
关键结论:Mistral-7B 上 LESS 比 static baseline 高 percentage points;Reweight 和 TSDS 都达到 。Llama-3.2-3B 上 static baseline 只有 ,Reweight 达到 ,LESS 达到 ,Delta Loss 达到 ;NEAR/TSDS 仅 ,说明 offline embedding/distribution selection 对小模型不如在线 model-aware selection 稳定。
5.2 Data mixture:MMLU 与 SlimPajama perplexity
SlimPajama-6B:
- Baseline:MMLU ;PPL ALL/CC/C4/SE/Wiki/GitHub/ArXiv/Book = 。
- DoReMi:MMLU ;PPL = 。DoReMi 在 overall PPL、CC、C4 上最好。
- ODM:MMLU ;PPL = 。ODM 在 MMLU、SE、ArXiv、Book 上最好。
SlimPajama-30B:
- Baseline:MMLU ;PPL ALL/CC/C4/SE/Wiki/GitHub/ArXiv/Book = 。
- DoReMi:MMLU ;PPL = 。DoReMi 在 MMLU 和 C4 上最好。
- ODM:MMLU ;PPL = overall,domain PPL = 。ODM 在 overall PPL 和 CC、SE、Wiki、GitHub、ArXiv、Book 上最好。
DoReMi 和 ODM 的差异是:DoReMi 通过 minimax/excess-loss 优化更偏向全局或高资源域的稳定改进;ODM 的 bandit exploration 更积极上调 minority/specialized domains,因此在 ArXiv、GitHub、Book 等专门域上更强。30B scale 下,static baseline 不再是任何 domain 的最优,说明动态 mixing 在更长训练预算下收益更稳定。
5.3 Efficiency:相对原实现的运行时间
LESS online selection 的效率表:
| Sample Ratio | Method | Accuracy (%) | Training Time (s) | Reduction |
|---|---|---|---|---|
| 0.05 | LESS | 34.91 | 1,640 | - |
| 0.05 | DataFlex | 38.35 | 1,579 | 3.72% |
| 0.1 | LESS | 37.97 | 3,735 | - |
| 0.1 | DataFlex | 40.25 | 3,573 | 4.34% |
| 0.5 | LESS | 41.57 | 14,398 | - |
| 0.5 | DataFlex | 40.93 | 13,377 | 7.09% |
| 1.0 | LESS | 40.38 | 30,239 | - |
| 1.0 | DataFlex | 42.37 | 28,734 | 4.98% |
| 1.0 | DataFlex (8-GPUs) | 43.01 | 12,965 | 57.13%* |
论文表中 是相对 DataFlex single-GPU at ratio 1.0 计算。DataFlex 在单 GPU 下已稳定快于原 LESS;8-GPU 设置把 1.0 ratio 的时间从 s 降到 s,同时 accuracy 达到 。
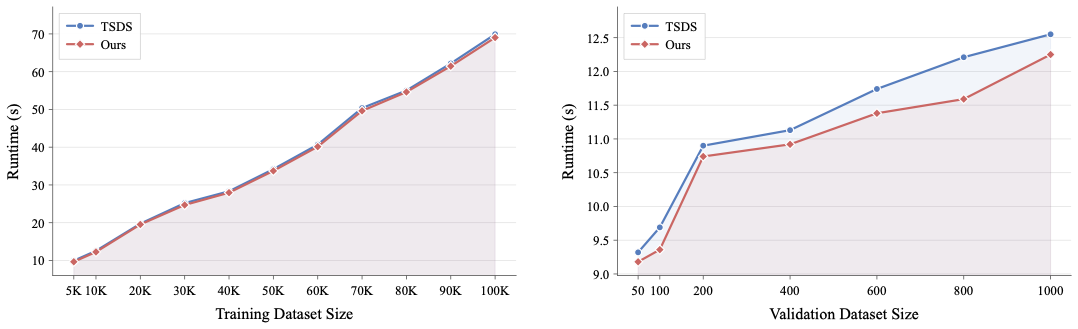
Figure 4a–4b 解读:左图固定 validation set size 为 ,让 training set 从 扩到 ;右图固定 training set size 为 ,让 validation set 从 扩到 。两种 setting 下 DataFlex TSDS re-implementation 的曲线都低于原 TSDS,说明虽然绝对加速不大,但在需要频繁重跑 selection operator 的实验中可以稳定节省迭代时间。
TSDS offline selection 的端点结果:training set 从 到 时,原 TSDS 从 s 到 s,DataFlex 从 s 到 s,约 — 改进;validation set 从 到 时,原 TSDS 从 s 到 s,DataFlex 从 s 到 s,约 — 改进。
5.4 Ablation-like findings, limitations, and conclusion
论文没有单独的 ablation table;最接近 ablation 的证据来自三组对照:static full-data vs dynamic selection、default static mixture vs DoReMi/ODM、original codebase vs DataFlex re-implementation。结果共同说明:动态 data-control 信号本身能带来性能收益,而统一系统实现还能降低运行时间或支持原 repo 不支持的分布式场景。
作者未单列 limitations。需要注意的可复现性风险是:released repo 在 main@f57037f8 中提供了 framework、components、demo configs 和文档,但没有包含与论文报告完全一致的 paper-scale launch configs;因此实验超参数应以论文正文为准,代码映射主要用于理解框架实现和算法组件,而不是逐行复现论文表格。整体结论是 DataFlex 把 data selection、data mixture、sample reweighting 统一成可扩展的 LLaMA-Factory training layer,能提高 data-centric LLM training 的可复现性、可比较性与工程可部署性。