VideoScan: Enabling Efficient Streaming Video Understanding via Frame-level Semantic Carriers
Authors: Ruanjun Li, Yuedong Tan, Yuanming Shi, Jiawei Shao Affiliations: TeleAI, China Telecom, ShanghaiTech University, Xidian University arXiv: 2503.09387 GitHub: LyliAgave/VideoScan
1. Motivation (研究动机)
VideoScan 研究的是 高效的 streaming video understanding。作者指出,当前视频 VLM 在走向实时应用时面临一个最直接的瓶颈:
- 每一帧会被编码成大量 visual tokens;
- 当视频长度持续增长时,这些 token 会带来巨大的计算与显存开销;
- 即便已有一些 token-efficient 或 streaming 方法,通常也只能减少 30%–50% 的视觉 token,仍不足以支撑真正长时间的视频流交互。
作者因此提出一个更激进的问题:能不能让每一帧只保留 1 个 token,同时仍维持有竞争力的长视频理解能力?
这个问题重要在于,它直接瞄准了实时视频助理、机器人、AR 设备等应用里的核心限制:latency 和 memory 必须稳定,而不仅仅是模型精度高。
2. Idea (核心思想)
VideoScan 的核心思想是引入一个 semantic carrier token 作为每一帧的“语义承载体”:
- 它的输入 embedding 来自该帧全部视觉 token 的平均池化;
- 它在 LLM 的 KV cache 中继续吸收前文语义,形成一种论文称作 semantic flow 的时序信息传递。
换句话说,VideoScan 认为:
- 一帧的局部视觉 token 不必在解码阶段反复保留;
- 如果能训练一个 frame-level semantic carrier,使其同时承载当前帧语义和历史上下文,那么在 decoding 阶段只依赖 semantic carrier 就足够。
这与常见的 token pruning / frame sampling 不同,VideoScan 不是简单删 token,而是试图让 LLM 自身“把这一帧的语义压进一个特殊 token 里”。
3. Method (方法)
3.1 Semantic flow observation

Figure 1 解读: Figure 1 展示了作者对 LLaVA-OneVision 的注意力可视化分析。左侧是 token-level attention map,可以看到模型存在明显的 attention sink;右侧把生成 token 的平均注意力投影回图像空间,结果表明模型重点关注的并不一定是人类直觉上最重要的主体区域,而往往偏向与输出更接近的局部 token。作者据此提出“semantic flow”:在 transformer 深层中,后续 token 会逐步吸收前面 token 的语义,因此真正有价值的可能不是原始视觉 token 本身,而是某些已经携带汇聚语义的后续 token。
作者把这一点写成 self-attention 的基本形式:
由于输出 token 本身就是对先前 value 的加权聚合,因此作者认为,在深层 transformer 中,后续 token 天然具备“语义总结器”的作用,这就是 semantic carrier 的理论基础。
3.2 Semantic carrier token
作者设计的 semantic carrier token 有两个组成:
- frame-level visual summary embedding:来自当前帧 visual embeddings 的平均池化;
- semantic flow in KV:carrier token 在 KV cache 中继续积累上下文信息,继承前面帧的语义。
对第 帧,其 semantic carrier 的输入向量定义为:
其中 是 vision encoder 产生的 frame-level visual embeddings。
这个 carrier token 被放在每一帧视觉 token 的末尾,从而让后续 LLM 在递归推理过程中,可以把语义继续传给这个 carrier。于是它不仅是一个压缩 token,还是一个跨时间持续演化的语义记忆单元。
3.3 VideoScan inference framework
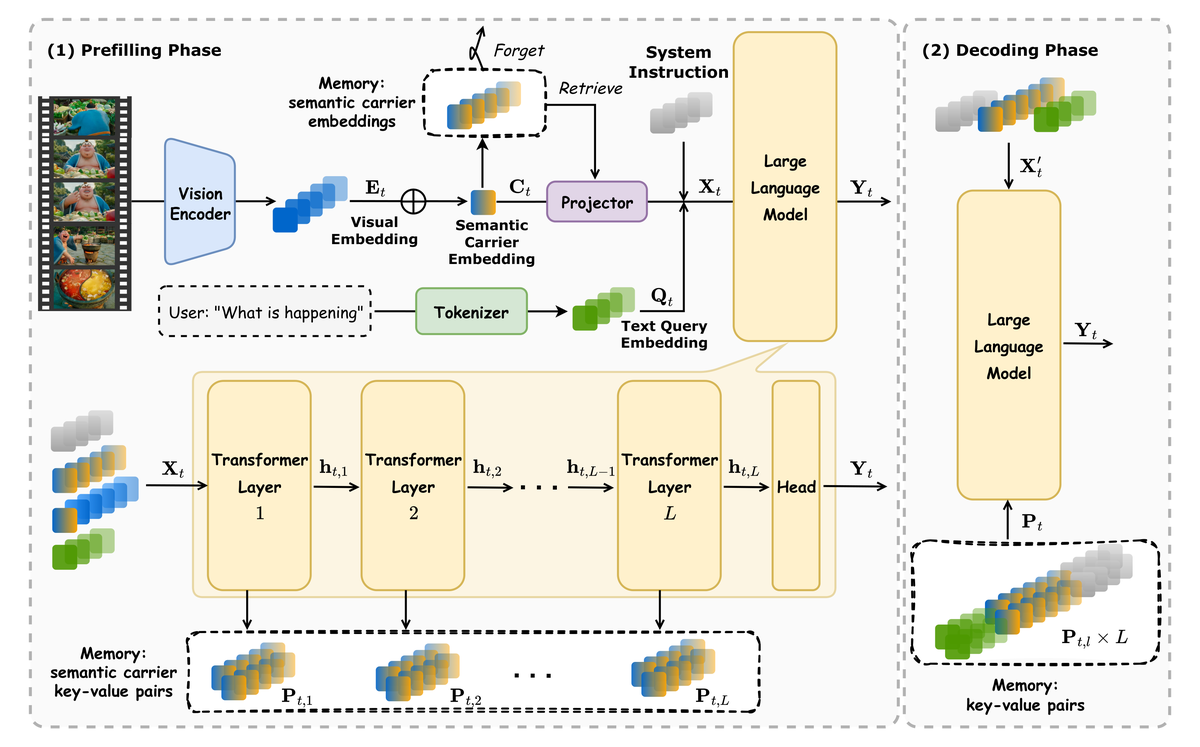
Figure 2 解读: Figure 2 给出了 VideoScan 的整体推理框架。系统分成 prefilling 和 decoding 两阶段:prefilling 阶段,当前帧通过 vision encoder 变成视觉 token,再平均池化出 semantic carrier,并将其 embeddings 与对应 KV 写入 memory bank;decoding 阶段,原始 frame-level visual tokens 被丢弃,模型只从 semantic carrier token 中读取视觉信息。图中还画出了 memory mechanism:当 memory bank 达到上限 时,会根据新旧 semantic carrier 之间的相似度删除最冗余的旧 token,从而让显存保持稳定。
在 prefilling 阶段:
- 输入帧 经 vision encoder 编码成 ;
- 构造 semantic carrier ;
- 从 memory bank 中检索最多 个历史 carrier;
- 与系统 prompt / 文本 token 一起组成 LLM 输入。
在 decoding 阶段:
- 当前帧的原始 visual tokens 不再重复使用;
- 解码所需视觉信息全部来自 semantic carrier;
- 因而避免了对 frame-level token 的重复计算。
3.4 Memory mechanism
VideoScan 的 memory bank 维持固定容量 。当容量到达上限时,作者采用一种基于特征重复度的 eviction 策略:
- 比较相邻 semantic carrier embedding 的 cosine similarity;
- 删除与新 token 最相似、最冗余的旧 token;
- 保留更具区分性的历史 carrier。
这使得 VideoScan 在长时间流式交互中显存保持稳定,同时保留时间上有代表性的关键语义片段。
3.5 Two-stage training strategy

Figure 3 解读: Figure 3 展示了 VideoScan 的两阶段训练。Stage 1 只让每帧由 semantic carrier token 表示,重点训练视觉编码器与 LLM backbone 适应“单 token 表示一帧”的输入范式。Stage 2 则把 semantic token 放在每帧 token 序列末尾,并引入 semantic-aware causal mask,强制后续 token 只能通过 semantic carrier 访问历史视觉语义,从而强化 semantic flow。这个训练设计保证 semantic carrier 不只是一个平均池化特征,而是真正成为跨时间的信息汇聚中心。
两阶段的目标分别是:
- Stage 1:让模型学会用 1 个 semantic carrier 代表每帧;
- Stage 2:通过 semantic-aware causal mask,增强 semantic flow,使后续文本 / 未来帧只能通过 carrier 获取先前信息。
3.6 Pseudocode(基于公开实现)
组件 A:构造 semantic carrier
# Algorithm: Build semantic carrier for each frame
# Input: frame-level visual embeddings E_t
# Output: one semantic carrier token C_t
def build_semantic_carrier(E_t):
# E_t: [N, d]
C_t = mean(E_t, dim=0)
return C_t组件 B:流式推理(prefill + decode)
# Algorithm: VideoScan streaming inference
# Input: video stream, memory budget M
# Output: answer / commentary tokens
def videoscan_stream_infer(video_stream, model, M=128):
memory_bank = []
for frame in video_stream:
E_t = vision_encoder(frame)
C_t = build_semantic_carrier(E_t)
# prefill current frame
outputs = model.prefill(frame_tokens=E_t, carrier=C_t, memory=memory_bank)
# discard raw frame tokens after prefilling
memory_bank = update_memory(memory_bank, C_t, outputs.kv, max_size=M)
# decode using memory bank only
answer = model.decode(memory_bank)
return answer组件 C:memory bank 更新
# Algorithm: Memory update by redundancy-aware eviction
# Input: old carriers, new carrier C_t, memory size M
# Output: updated memory bank
def update_memory(memory_bank, C_t, kv_t, max_size):
memory_bank.append((C_t, kv_t))
if len(memory_bank) > max_size:
sims = [cosine(memory_bank[i][0], memory_bank[i + 1][0]) for i in range(len(memory_bank) - 1)]
drop_idx = argmax(sims) # remove the most redundant older carrier
memory_bank.pop(drop_idx)
return memory_bank组件 D:semantic-aware causal mask
# Algorithm: Stage-2 semantic-aware causal masking
# Input: multimodal sequence with frame tokens and semantic carrier
# Output: causal mask enforcing semantic flow
def build_semantic_aware_mask(seq):
mask = causal_mask(seq)
for each_frame in seq.frames:
allow_future_tokens_to_attend_only_to(carrier_token_of(each_frame))
return mask3.7 Code-to-paper mapping table
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Streaming inference demo | infer.py, stream_infer.py | example entrypoints |
| Core streaming loop | llava/video_streamer.py | stream_generate_only_tok, stream_generate_inf, vscan_add_kv |
| Semantic-aware causal mask | llava/model/llava_arch.py | build_causal_mask |
| Memory limit and carrier handling | llava/model/llava_arch.py | MAX_MEMORY_LIMIT, prepare_inputs_labels_for_multimodal |
| Training entry | llava/train/train.py | training pipeline |
| Base model loading | llava/model/builder.py | load_pretrained_model |
4. Experimental Setup (实验设置)
4.1 Backbone and training
- 基础模型:LLaVA-Video 7B
- 训练数据:来自 LLaVA-Video-178K 的采样子集
- 训练分两阶段:
- 适配单-carrier 表示;
- semantic-aware 训练(仅微调 LLM)
- 推理时:输入视频按 1 FPS 处理
- memory bank 上限:主要评测 /
4.2 Benchmarks
Offline:
- MVBench
- MLVU
- LongVideoBench
- VideoMME
Online / streaming:
- VStream-QA(RVS-Ego / RVS-Movie)
4.3 Baselines
作者比较了:
- GPT-4V / GPT-4o / Gemini-1.5 系列
- Video-LLaMA / Video-LLaVA / LongVA / LLaVA-OV / LLaVA-Video
- Token-efficient 方法:MovieChat, TimeChat, MA-LMM, LLaVA-Mini, LLaMA-VID
- Streaming 方法:Flash-VStream, ReKV
5. Experimental Results (实验结果)
5.1 Offline benchmarks

Figure 4 解读: Figure 4 总结了 VideoScan 在 MLVU benchmark 上的定位:在把每帧压缩到 1 个 semantic carrier token、即视觉 token 减少超过 99% 的情况下,仍然保持有竞争力的性能,甚至显著超过 LLaVA-Mini 等高效方法。图中箭头强调了一个关键点:VideoScan 不是简单地牺牲精度换效率,而是在极高压缩率下仍能保住较强的语义理解能力。
论文主表给出的代表性结果如下:
| Method | Frames | Tokens / frame | MVB | MLVU | LVB | V-MME Overall | Avg |
|---|---|---|---|---|---|---|---|
| LLaVA-OV-7B | 64 | 196 | 56.7 | 64.7 | 56.3 | 58.2 | 59.0 |
| LLaVA-Video-7B | 64 | 210 | 58.6 | 70.8 | 58.2 | 63.3 | 62.7 |
| VideoScan (M=64) | 1fps | 1 | 48.9 | 59.7 | 47.1 | 54.0 | 52.4 |
| VideoScan (M=128) | 1fps | 1 | 48.9 | 61.3 | 49.5 | 55.1 | 53.7 |
结论是:
- 在每帧只用 1 个 token 的极端压缩下,VideoScan 仍能保留 LLaVA-Video 较大比例的能力;
- 与更小、更高效但能力偏弱的方法相比,VideoScan 在 MLVU 等 benchmark 上明显更强;
- 它不是为了超过最强离线大模型,而是为了在极低开销下维持可用性能。
在 MLVU token-efficient 对比表中,VideoScan() 达到:
- Topic Reasoning: 81.8
- Anomaly Recognition: 64.0
- Needle QA: 67.9
- Ego Reasoning: 62.5
- Plot QA: 64.9
- Action Order: 44.0
- Action Count: 31.6
- Avg: 61.3
显著超过 LLaVA-Mini 的 42.8 平均分。
5.2 Online streaming QA
| Method | FPS | Tokens | RVS-Ego Acc / Score | RVS-Movie Acc / Score | Latency | VRAM |
|---|---|---|---|---|---|---|
| Flash-VStream-7B | 1fps | - | 57.3 / 4.0 | 53.1 / 3.3 | 2.1s | 19GB |
| ReKV (LLaVA-OV-7B) | 1fps | offload | 63.7 / 4.0 | 54.4 / 3.6 | 2.7s | 36GB |
| VideoScan (M=128) | 1fps | 1 | 60.9 / 4.0 | 54.1 / 3.5 | 2.1s | 18GB |
这里最重要的结论不是绝对精度,而是精度–效率平衡:
- VideoScan 在 streaming QA 上精度接近 ReKV;
- 但显存从 36GB 降到 18GB;
- 延迟从 2.7s 降到 2.1s;
- 因而相对先前流式方法,论文强调可达到 1.29× 更低 latency,并保持稳定显存。
5.3 Efficiency / deployment perspective
论文摘要和 README 都强调:
- VideoScan 支持大约 6 serving FPS;
- 相对原始 LLaVA-Video,整体推理速度可达到 约 5×;
- GPU memory 在长时间 streaming 下保持基本稳定,约 18GB,且与视频总时长无关。
这意味着 VideoScan 的核心贡献实际上是:把一个原本更偏离线的 video-VLM 变成了可在线部署的 streaming framework。
5.4 Ablation studies
(1) semantic carrier 组成
| Setting | Overall | Short | Medium | Long |
|---|---|---|---|---|
| w/o emb | 44.5 | 47.7 | 45.1 | 40.7 |
| w/o KV | 42.6 | 44.0 | 43.0 | 40.9 |
| VideoScan | 54.0 | 62.1 | 53.2 | 46.6 |
结果表明:
- carrier 的输入 embedding 与其在 KV 中的语义继承,两者都缺一不可;
- 如果没有 embedding summary,或者没有 semantic flow in KV,性能都会显著下降。
(2) memory mechanism
在“无 memory bank,只做离线均匀采样”时:
- 32 帧 Overall = 51.4
- 64 帧 Overall = 52.8
- 128 帧 Overall = 53.8
而有 memory 时:
- :Overall = 54.0
- :Overall = 55.1
这说明 memory bank 不只是让显存稳定,也确实增强了长程语义保留。
5.5 Limitations
论文在 Conclusion 中明确写了两个限制:
- 不适用于纯 Transformer encoder 架构:因为 VideoScan 的 semantic flow 和 causal mask 依赖 autoregressive decoding;
- 极端 token reduction 会牺牲细粒度时空信息:每帧只有 1 个 token,在某些需要精细视觉推理的任务上天然有上界。
作者也指出,未来可以考虑在 carrier 之外额外保留少量高价值视觉 token,但这可能破坏它目前在 GPU memory 与 latency 上的优势。
总体而言,VideoScan 的最大贡献在于:证明了“每帧 1 token”的极端压缩,在合适的 semantic carrier 与训练策略下,依然可以支撑流式长视频理解。