VideoMem: Enhancing Ultra-Long Video Understanding via Adaptive Memory Management
Authors: Hongbo Jin, Qingyuan Wang, Wenhao Zhang, Yang Liu, Sijie Cheng Affiliations: Peking University, Tsinghua University, RayNeo.AI Code: 未开源
1. Motivation (研究动机)
1.1 问题背景
现有视觉语言模型 (VLM) 在处理超长视频时面临两大根本瓶颈:
- 有限的上下文长度: 注意力机制的二次计算开销限制了可处理的 token 数量
- 低效的长期记忆建模: 导致对早期视频内容的灾难性遗忘
现有方法的局限:
- 压缩类方法 (帧采样/特征压缩): 不可避免地丢失细粒度时序细节
- 静态记忆机制: 使用预定义规则管理记忆,缺乏对不同视频内容和任务的适应性
- RAG方法: 构建外部知识库+检索增强生成,存储和计算开销巨大
1.2 核心贡献
- VideoMem 框架: 首次将长视频理解建模为序列生成任务 + 自适应记忆管理
- PRPO 算法 (Progressive Grouped Relative Policy Optimization): 专为长期 RL 任务设计的训练算法,包含 TCR + PSP 两个核心模块
- SOTA 性能: 在 5 个长视频基准上超越所有可比开源模型,相比基线 Qwen3-VL-8B 分别提升 7.9% (LVBench)、5.7% (VideoMME)、8.9% (LongTimeScope)
2. Idea (核心思想)
VideoMem 将长视频理解重新定义为一个基于查询的序列生成任务 (query-conditioned sequential generation task),配合自适应记忆管理:
- 将长视频切分为多个片段,逐步迭代处理
- 每一步动态更新一个全局记忆缓冲区 (global memory buffer),保留关键信息、丢弃冗余内容
- 处理完所有片段后,综合所有累积的记忆生成最终答案
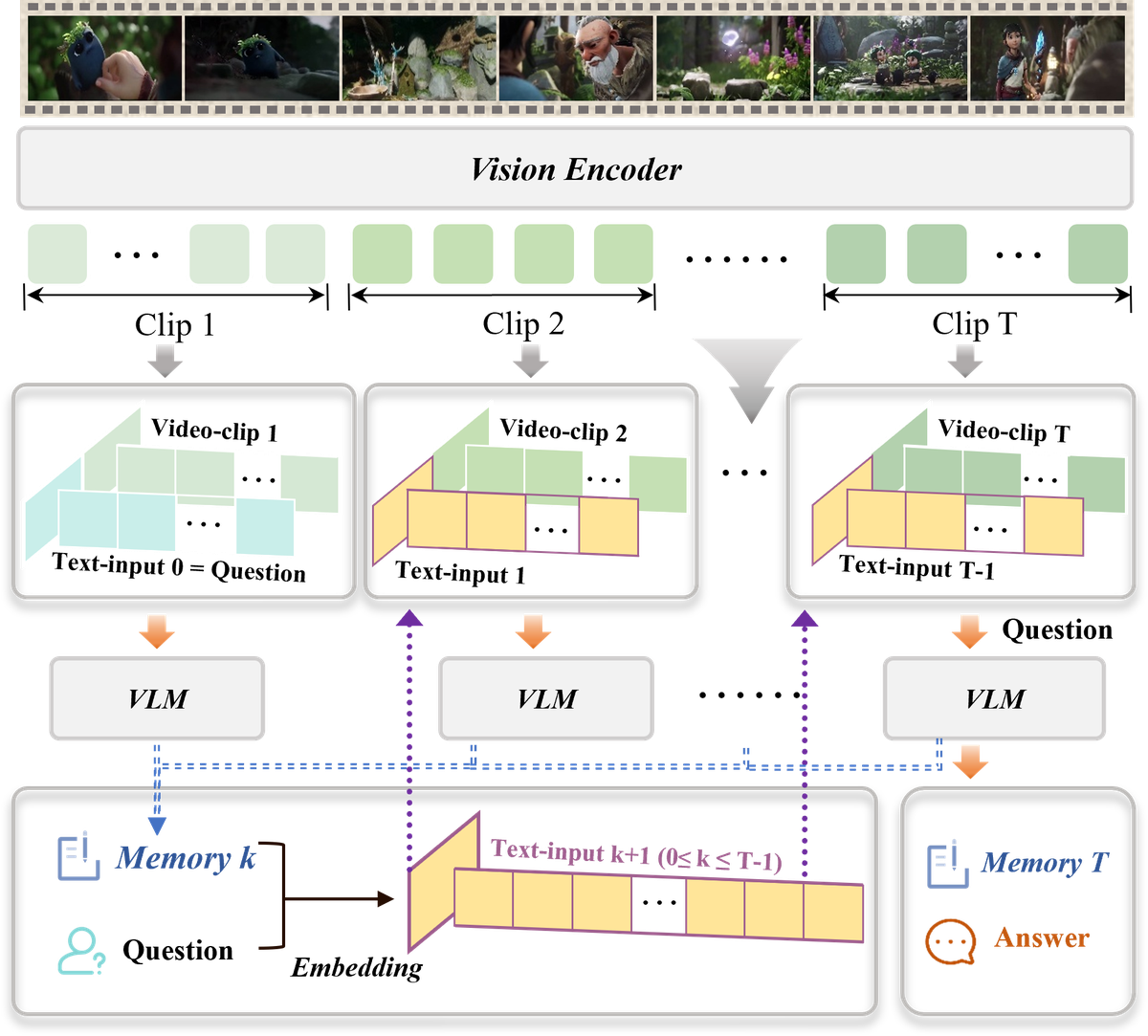
Figure 2 解读: VideoMem 整体框架图。长视频被切分为 Clip 1 到 Clip T,依次送入 VLM。每一步的输入包含三部分: 当前视频片段 、用户查询 、以及上一步的全局记忆缓冲 。VLM 在每一步输出更新后的记忆 ,最终在处理完 Clip T 后生成答案。底部展示了记忆在各步之间的传递和拼接过程。
3. Method (方法)
3.1 自适应记忆管理 (Adaptive Memory Management)
核心机制: 在每一步 ,VLM 接收三类输入:
- 当前视频片段
- 用户查询
- 全局记忆缓冲
模型动态决定:
- 保留哪些关键时序细节 (如重复出现的符号、情节转折)
- 剪枝哪些冗余内容 (如静态背景)
- 输出更新后的记忆
最终,全局记忆 综合所有片段的关键信息,用于生成最终答案。

Figure 1 解读: VideoMem 的实际运行示例。对于查询”什么符号重复出现在场景中,它代表什么?”,VideoMem 逐片段处理视频: Clip 1 的记忆记录了兔子角色和嘉年华元素; Clip 2 更新记忆,注意到兔子服装再次出现; Clip 3 发现场景变为室内,奶酪再次出现; 最终 Clip T 综合所有记忆,识别出奶酪是反复出现的符号,象征觉醒和复活。蓝色文字描述当前场景,红色文字总结先前记忆并进行与问题相关的推理。
3.2 冷启动阶段 (Cold Start Stage)
在 RL 训练之前,通过 SFT 对基座模型进行预热,使其具备基本的记忆管理能力:
数据构建流程:

Figure 3 解读: Chain-of-memory 数据构建流水线。首先从 VideoMarathon 数据集采样视频-问题-答案对,将每个视频切分为多个片段。然后通过三阶段流水线生成高质量的 chain-of-memory 数据: (1) 使用 Qwen3-VL-32B-Instruct 为每个片段生成语义摘要; (2) 使用 Qwen3-8B 逐步迭代过滤无关信息,生成连贯的记忆链; (3) 人工专家检查和过滤,确保数据质量。右侧展示了从 Memory 1 到 Memory 7 逐步精炼的记忆演化过程,红色文字标注了新增和更新的关键信息。
具体步骤:
- 从 VideoMarathon 采样 26k 条记录
- 用
Qwen3-VL-32B-Instruct生成每个片段的语义摘要 - 用
Qwen3-8B逐步过滤无关信息,生成连贯记忆 - 人工专家检查过滤
- 使用标准 SFT 微调基座模型
3.3 Progressive Grouped Relative Policy Optimization (PRPO)
将记忆管理建模为 RL 问题,策略 被优化以生成高质量的记忆轨迹。
PRPO 解决标准 GRPO 在长期任务中的两大挑战:
- 探索空间指数级膨胀
- 稀疏且延迟的奖励信号
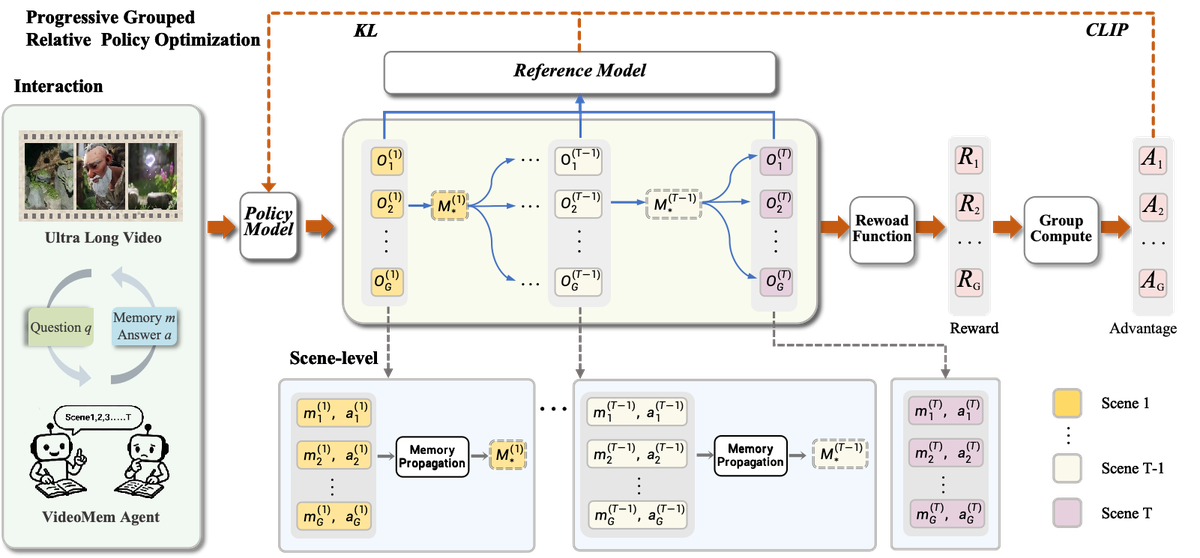
Figure 4 解读: PRPO 的 rollout 和策略优化流水线。左侧展示了交互过程: 策略模型接收超长视频、问题和记忆,生成多个候选轨迹。中间展示了多步展开过程: 在每个场景/片段步骤,模型生成 条轨迹 ,通过 Memory Propagation 选择最优记忆传递到下一步。右侧展示了奖励计算和优势估计: 每步的奖励 通过 Reward Function 计算,然后通过 Group Compute 得到组相对优势 。底部的 Scene-level 视图展示了 PSP 的核心思想——从 条路径中只选择一条最优记忆传播到下一步。
3.3.1 Temporal Cascading Reward (TCR)
问题: 长期 RL 中奖励信号稀疏且延迟,正确回答基于早期视频内容的问题,奖励可能在处理完整个序列后才能观察到。
解决方案: 将稀疏的最终奖励分解为每步更密集的中间奖励。
在每一步 ,模型生成一个临时答案 ,即时奖励 由三部分组成:
其中:
- : 一致性奖励,临时答案匹配真实答案则为 1,否则为 0
- : 格式奖励,输出是否符合
<memory>...<memory><answer>...</answer>格式 - : 记忆惩罚,记忆长度超过阈值 时的惩罚
超参数: , ,
效果: TCR 将奖励频率提升 4.0x (片段数=4),收敛步数减少 30% (0.7x),模型在约 70% 的步数内收敛 (对比 TR 需要 100%)。
3.3.2 Progressive State Propagation (PSP)
问题: 直接对所有 条轨迹在所有 步进行展开,prefilling 复杂度为 ,计算代价过高。
解决方案: 在每步 ,从 条轨迹中仅选择一条最优记忆 传播到下一步。
采样概率通过温度衰减的 softmax 控制:
两大好处:
- 计算效率: prefilling 复杂度从 降至 ,训练速度提升 3.1x
- 训练稳定性: 过滤掉早期噪声,仅传播高一致性、格式合规的轨迹,防止误差累积
3.4 算法伪代码
# PRPO training loop
for example in dataset:
memory = ""
trajectory_buffer = []
for clip in example.video_segments:
outputs = rollout_group(policy, example.question, clip, memory, num_generations=G)
answers = [extract_answer(example.question, output) for output in outputs]
rewards = []
for output, answer_hat in zip(outputs, answers):
consistency_reward = float(answer_hat == example.answer)
format_reward = float(check_format(output))
memory_penalty = max(0, memory_length(output) - max_memory_tokens)
rewards.append(alpha * consistency_reward + format_reward - beta * memory_penalty)
advantages = group_relative_advantage(rewards)
trajectory_buffer.extend(zip(outputs, advantages))
if clip is not example.video_segments[-1]:
memory = extract_best_memory(outputs, advantages)
loss = grpo_objective(policy, trajectory_buffer)
optimize(loss, params=theta)3.5 代码映射与实现细节
3.5.1 代码可用性
当前状态: 论文未提供开源代码链接。GitHub 上也未找到官方实现。
3.5.2 关键模块与潜在实现映射
| 论文模块 | 功能描述 | 潜在实现方式 |
|---|---|---|
| Video Segmentation | 将长视频切分为 T 个等长片段 | 标准视频处理,按帧数等分 |
| Memory Buffer | 全局记忆缓冲区管理 | 文本格式 <memory>...</memory>,作为 prompt 的一部分 |
| Cold Start SFT | 记忆管理能力预热 | 基于 chain-of-memory 数据的标准 SFT |
| PRPO Rollout | 多轨迹展开 | 基于 GRPO 框架,每步生成 G=8 条轨迹 |
| TCR | 时序级联奖励计算 | 每步计算 R_cons + R_format - β*MemPenalty |
| PSP | 渐进式状态传播 | 温度衰减 softmax 采样最优记忆,仅传播 1 条 |
| Vision Encoder | 视频编码 | Qwen3-VL 内置的 Vision Encoder |
| Answer Extraction | 从输出中提取答案 | 正则匹配 <answer>...</answer> 标签 |
3.5.3 训练数据构建伪代码
# Chain-of-Memory 数据构建
def build_chain_of_memory(video, question, answer):
clips = split_video(video, num_segments=T)
# Stage 1: 语义摘要 (Qwen3-VL-32B-Instruct)
summaries = []
for clip in clips:
summary = qwen3_vl_32b.generate_summary(clip)
summaries.append(summary)
# Stage 2: 迭代记忆精炼 (Qwen3-8B)
memory = ""
memories = []
for i, summary in enumerate(summaries):
memory = qwen3_8b.refine_memory(
prev_memory=memory,
new_summary=summary,
question=question
)
memories.append(memory)
# Stage 3: 人工检查过滤
memories = human_expert_filter(memories)
return [(clip, question, memory, answer)
for clip, memory in zip(clips, memories)]4. Experimental Setup (实验设置)
4.1 实验配置
| 配置项 | 值 |
|---|---|
| 基座模型 | Qwen3-VL-8B |
| 视频片段数 (训练) | T = 4 |
| 每片段帧数 | 32 帧 |
| max pixels | 128 * 32 * 32 |
| 推理帧数 | 64 帧 |
| Rollout 组数 G | 8 |
| 记忆 token 预算 L_max | 1024 |
| α / β | 1.0 / 0.005 |
| Batch size | 16 |
| 优化器 | AdamW |
| 硬件 | 16x PPU-ZW810E (96GB) |
| 等效 GPU 时间 | 3200 A100 GPU hours |
| 冷启动数据 | 26k records (VideoMarathon) |
| RL 训练数据 | 147k MC QA (VideoMarathon) + 49k (LLaVA-Video-178K) |
5. Experimental Results (实验结果)
5.1 主实验结果 (Table 1)
| 模型 | Size | VideoMME (Long) | VideoMME (Overall) | LongVideoBench | MLVU | LVBench | LongTimeScope |
|---|---|---|---|---|---|---|---|
| Qwen3-VL* | 8B | 58.6 | 67.9 | 59.1 | 71.6 | 50.6 | 36.2 |
| VideoMem* | 8B | 64.2 | 73.6 | 63.3 | 77.4 | 58.5 | 45.1 |
| 提升 | - | +5.6 | +5.7 | +4.2 | +5.8 | +7.9 | +8.9 |
关键发现:
- 在所有 5 个长视频基准上达到 SOTA (8B 量级开源模型)
- 在最具挑战性的超长视频基准 (LVBench 30-90min, LongTimeScope 300min+) 上提升最大
- 甚至超越部分闭源模型 (GPT-4V, GPT-4o) 在某些指标上的表现
5.2 消融实验 (Table 2)
| 方法 | PSP | TCR | MP | VideoMME | LongTimeScope |
|---|---|---|---|---|---|
| VideoMem (完整) | ✓ | ✓ | ✓ | 73.6 | 45.1 |
| w/o PSP | - | ✓ | ✓ | 71.5 | 43.0 |
| w/o TCR | ✓ | - | ✓ | 69.4 | 40.3 |
| w/o MP | ✓ | ✓ | - | 72.0 | 43.9 |
| SFT only | - | - | - | 67.5 | 38.2 |
关键发现:
- TCR 贡献最大: 移除后 VideoMME 下降 4.2%,LTS 下降 4.9%,因为稀疏奖励导致训练不稳定
- PSP 贡献显著: 移除后性能下降 2.1%,确认其对稳定长期训练的作用
- 记忆惩罚 (MP): 移除后也有一定性能下降
5.3 TCR 奖励机制分析 (Table 3)
| 奖励类型 | 奖励密度 | 收敛步数 | LVBench |
|---|---|---|---|
| TR (终端奖励) | 1.0x | 1.0x | 54.6 |
| TCR (级联奖励) | 4.0x | 0.7x | 58.5 |
5.4 逐片段精度分析 (Table 4)
| 方法 | Seg1-1 | Seg1-2 | Seg1-3 | Seg1-4 |
|---|---|---|---|---|
| Qwen3-VL | 50.3 | 48.5 | 46.2 | 44.8 |
| VideoMem | 51.2 | 55.4 | 57.1 | 58.5 |
关键发现: Qwen3-VL 随片段增加精度持续下降 (灾难性遗忘),而 VideoMem 精度持续上升 (51.2% → 58.5%),证明记忆机制真正有效地整合了后续片段的信息。
5.5 冷启动效果 (Table 5)
| 方法 | VideoMME | LVBench | LVB |
|---|---|---|---|
| Qwen3-VL (未训练) | 58.6 | 50.6 | 59.1 |
| PRPO-only | 59.8 | 53.4 | 59.5 |
| ColdStart-only | 61.9 | 54.4 | 60.7 |
| VideoMem (两阶段) | 64.2 | 58.5 | 63.3 |
冷启动是加速模型收敛、避免无效 rollout 的必要训练阶段。
5.6 计算效率 (Table 6)
| 方法 | 训练速度 | VideoMME | LVBench |
|---|---|---|---|
| GRPO | 1.0x | 72.0 | 56.7 |
| PRPO | 3.1x | 73.6 | 58.5 |
PRPO 在速度提升 3.1 倍的同时,性能还更优。

Figure 5 解读: 推理可扩展性实验。训练时固定片段数 T=4,推理时测试 T=1 到 6。三张图分别对应 LongTimeScope、LongVideoBench、LVBench 三个基准。蓝色线为 VideoMem,灰色线为 Qwen3-VL 基线。关键发现: Qwen3-VL 在 T≈3 时达到瓶颈然后快速下降,说明无法有效利用长期记忆; 而 VideoMem 随着片段数增加,精度稳步提升,展现出良好的推理可扩展性。这证明学到的记忆策略可以无缝泛化到任意片段数。
5.7 个人思考与总结
将长视频理解建模为序列生成任务是本文最核心的贡献。这一范式转换带来了两个关键优势:
- 绕过了上下文长度限制——无论视频多长,每步只需处理一个片段 + 记忆
- 自然地适配 RL 训练——记忆更新可以看作 agent 的动作,答案正确性作为奖励
PRPO 算法的设计精巧:
- TCR 解决了长期任务中奖励稀疏的核心问题,通过每步生成临时答案获得即时反馈
- PSP 是一个优雅的效率优化——只传播一条最优记忆路径,将 降至 ,同时还提升了训练稳定性
5.8 局限性与未来方向
- 仅支持多选题: 当前 是精确匹配,无法处理开放式问答。论文讨论了用 LLM-as-a-judge 替换的可能性
- 固定片段数训练: 训练时 T=4,虽然推理可泛化,但更长的训练序列可能带来更好效果
- 记忆格式为纯文本: 没有利用视觉特征级别的记忆压缩,可能在需要精确视觉细节的任务上受限
- 可推广性: PRPO 的 PSP + TCR 设计不依赖视频模态,可以推广到长文档 QA、多步推理 agent 等场景
5.9 与相关工作的关系
| 方法类型 | 代表工作 | VideoMem 优势 |
|---|---|---|
| 上下文扩展 | Gemini, LongVILA | 不受上下文长度限制,可处理任意长视频 |
| Token 压缩 | LongVU, VideoXL-2 | 保留细粒度时序信息,不丢失关键细节 |
| 静态记忆 | MA-LMM, MovieChat | 自适应记忆管理,无需手工规则 |
| RAG | Ego-R1, M3-Agent | 无需外部数据库,端到端学习 |
| 视频 RL | Video-R1, LongVILA-R1 | PRPO 专为长期序列任务设计,效率更高 |
5.10 关键 takeaway
VideoMem 的核心 insight: 与其扩展上下文窗口来”看到”更多内容,不如训练模型学会”记住”关键信息并”遗忘”冗余内容。这将长视频理解从静态的 one-shot 理解问题,转变为动态的序列决策问题,自然适配 RL 范式。PRPO 的 TCR+PSP 设计不仅解决了长期 RL 的效率和稳定性问题,更展示了 RL 在序列信息管理任务中的巨大潜力。