VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
Authors: Xinhao Li, Yi Wang, Jiashuo Yu, Xiangyu Zeng, Yuhan Zhu, Haian Huang, Jianfei Gao, Kunchang Li, Yinan He, Chenting Wang, Yu Qiao, Yali Wang, Limin Wang Affiliations: Shanghai AI Laboratory, Nanjing University, Shenzhen Institutes of Advanced Technology (CAS), Shanghai Innovation Institute GitHub: OpenGVLab/VideoChat-Flash Venue: ICLR 2026 | arXiv: 2501.00574
Affiliations: Shanghai AI Laboratory, Nanjing University, Shenzhen Institutes of Advanced Technology (CAS), Shanghai Innovation Institute
Published: ICLR 2026 | arXiv: 2501.00574
1. Motivation (研究动机)
长视频理解的核心挑战
当前多模态大语言模型 (MLLM) 在处理长视频时面临三大困境:
- 计算开销爆炸: 以 Gemini-1.5-Pro 为例, 一小时视频会被转换为 921,600 个 token, 导致训练和推理成本极高
- 压缩与性能的矛盾: 已有压缩方法 (如 LLaMA-VID 将每帧压缩为 2 个 token) 虽然高效, 但信息损失严重, 在长视频理解 benchmark 上甚至不如一些图像模型
- 长视频训练数据匮乏: 现有长视频数据集缺乏 instruction-following 格式的 (video, instruction, answer) 三元组, 难以支撑多模态推理能力训练
- 评估基准不充分: 已有 Needle-In-A-Video-Haystack (NIAH) 评测容易信息泄露, 且仅考察视觉检索能力而缺少推理评估
与已有方法的本质区别
- 扩展 context window 路线 (如 LongVILA): 虽能处理长视频, 但无法降低计算开销
- token 压缩路线 (如 LLaMA-VID): 压缩过激导致细节丢失
- 本文路线: 提出分层压缩 (HiCo), 在 Clip-level 和 Video-level 两阶段分别压缩, 实现约 1/50 压缩比且几乎无性能损失

Figure 1 解读: 该图展示了 VideoChat-Flash 与主流长视频 MLLM 的对比。横轴为 NIAH 评测中达到 95% 准确率时可处理的帧数, 纵轴为 VideoMME 准确率, 圆圈大小表示 TFLOPs。可以看到 VideoChat-Flash (红色) 在效率和性能两个维度上均大幅领先: 它能在 10,000 帧下达到 99.1% NIAH 准确率, 同时 VideoMME 分数最高 (~67.5%), 计算量仅约 500 TFLOPs, 而 LongVA/LongVILA 等模型虽然能处理较多帧但计算量高出 10-100 倍。
2. Idea (核心思想)
核心思想: 分层视频 token 压缩 (HiCo)
本文的关键洞察是 长视频中存在两种层级的视觉冗余:
- Clip-level 冗余 (帧间局部冗余): 相邻帧之间存在大量重复的背景、物体, 可通过 spatio-temporal attention + similar token merging 在视频编码阶段压缩
- Video-level 冗余 (全局上下文冗余): 在 LLM 推理时, 对于给定问题, 大部分视频片段是无关的。浅层 LLM 注意力分散在全局, 深层才聚焦到关键局部, 因此可在 LLM 不同层渐进式丢弃无关 visual token
配套创新
- Duration-based Sampling: 根据视频时长自适应调整采样密度, 短视频密采样 (捕捉快速动作), 长视频稀采样 (关注事件理解)
- LongVid 数据集: 114,228 个长视频, 3,444,849 个 QA 对, 覆盖 5 种任务类型
- Multi-Hop NIAH: 插入推理链而非单张图片, 模型需沿正确推理路径找到 needle 并回答问题, 同时避免干扰路径的误导
- Short-to-Long 多阶段训练: 4 阶段渐进式训练, 从图像/短视频对齐逐步过渡到长视频指令微调
3. Method (方法)
3.1 整体框架

Figure 3 解读: VideoChat-Flash 的整体架构。输入视频经 Duration-based Sampling 后分成多个 clip, 每个 clip 经共享的 Video Encoder (UMT-L) 进行 spatio-temporal attention 编码, 再通过 Connector (Similar Token Merging + MLP) 实现 Clip-level 压缩, 每帧压缩为平均 16 个 token。所有压缩后的 visual token 与 text token 一起送入 LLM (Qwen2-7B), 在 LLM 的不同层通过 Progressive Visual Dropout 实现 Video-level 压缩。最终 LLM 输出答案。
3.2 Duration-based Sampling
根据视频时长 自适应确定采样帧数 :
采样密度 定义为:
- 短视频 (): , 视频越短采样越密, 捕捉快速动作
- 长视频 (): , 视频越长采样越稀, 关注事件级理解
- 最优参数: , (平衡短视频和长视频性能)
同时在视频上下文后附加 Timestamp Prompt: “The video lasts for N seconds, and T frames are uniformly sampled from it.”, 使模型无需额外模块即可感知时间戳。
伪代码: Duration-based Sampling
─────────────────────────────────
输入: 原始视频 (时长 D 秒), T_min=64, T_max=256
输出: 采样帧序列, timestamp prompt
1. T = min(T_max, max(D, T_min))
2. 从视频中均匀采样 T 帧
3. 将 T 帧划分为 N_c 个 clip, 每个 clip 包含 4 帧
4. 生成 timestamp prompt: "The video lasts for {D} seconds, and {T} frames are uniformly sampled from it."
5. 返回 (clips, timestamp_prompt)3.3 Clip-level 压缩: Spatio-Temporal Encoding + Similar Token Merging

Figure 10 解读: 四种 token 压缩策略的对比: (a) Spatial Downsampling (如 pixel shuffle) 仅在空间维度下采样, 忽略时间关系; (b) Uneven Downsampling 对首帧保留更多细节, 后续帧更激进压缩; (c) Spatio-temporal Resampler 使用 Q-Former 或 cross-attention 进行时空压缩, 但训练收敛困难; (d) Similar Token Merging (本文方法) 直接合并相似 token, 无参数、无训练开销, 且在极端压缩比 (2%) 下仍保持大部分性能。
编码过程: 将采样帧序列划分为 个 clip, 每个 clip 的帧 经视频编码器 和连接器 压缩:
其中 由 parameter-free similar token merge 操作和 MLP projection 组成。每帧最终被压缩为平均 16 个 token (从原始约 196 个 token, 压缩比约 8%)。
所有 clip 的压缩 token 拼接为 LLM 输入:
伪代码: Clip-level 压缩
─────────────────────────
输入: 采样帧序列 (T 帧), clip_size=4
输出: 压缩后的 visual token 序列 X_V
1. 将 T 帧划分为 N_c = T/4 个 clip
2. for each clip j in 1..N_c:
a. 将 4 帧送入 UMT-L 视频编码器 (spatio-temporal attention)
→ 每帧产生约 196 个 token, 每个 clip 共 784 个 token
b. Similar Token Merging:
- 计算 token 间的余弦相似度
- 迭代合并最相似的 token 对 (取平均)
- 直到每帧剩余约 16 个 token (每个 clip 64 个 token)
c. MLP Projection: 将 visual token 投射到 LLM 的 embedding 空间
3. X_V = Concat(所有 clip 的压缩 token)
4. 返回 X_V // 总 token 数 = N_c × 64 = T × 163.4 Video-level 压缩: Progressive Visual Dropout
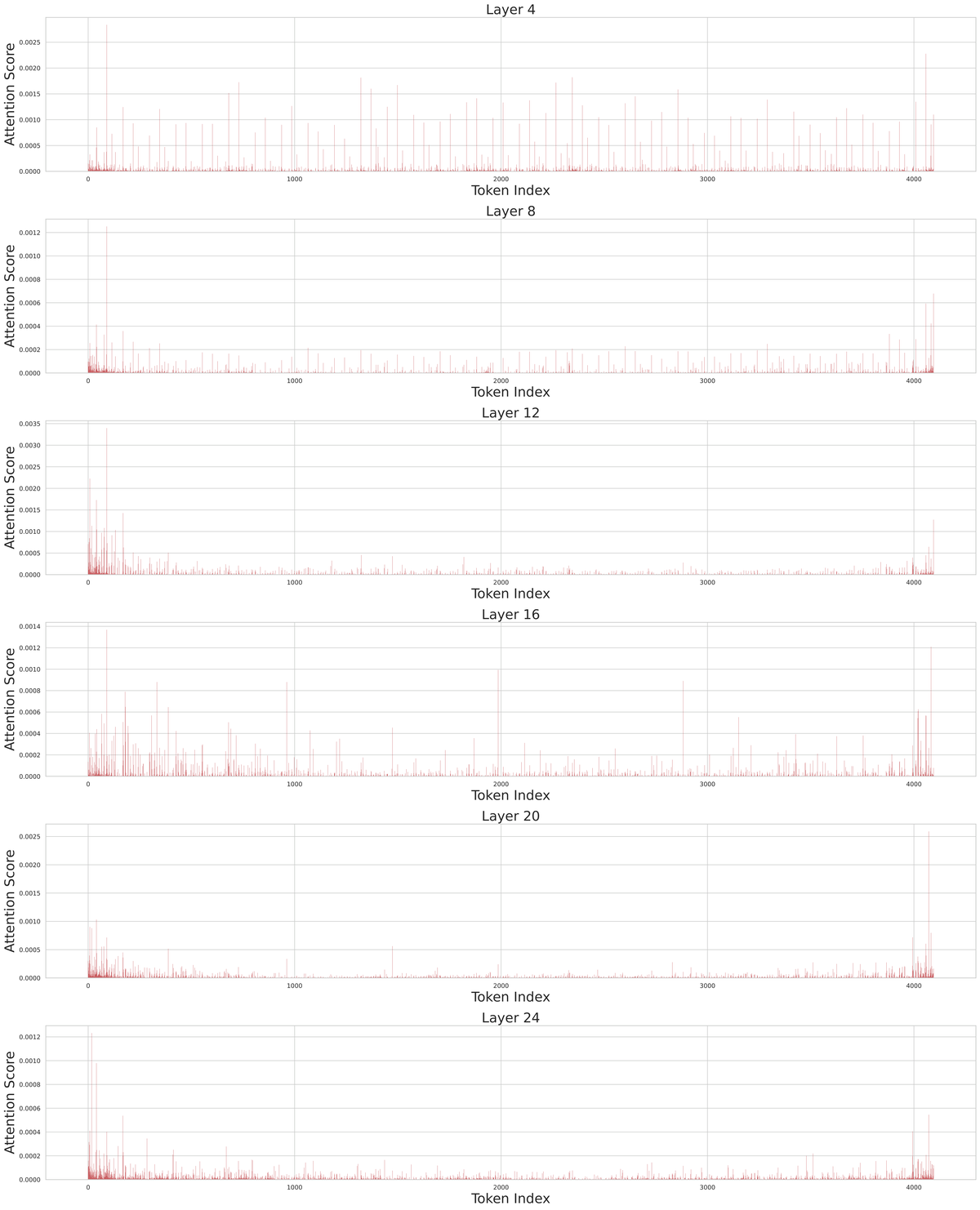
Figure 8 解读: Qwen2-7B 不同层 (Layer 4, 8, 12, 16, 20, 24) 中 text token 对各 visual token 的注意力分数分布可视化。每个子图的 x 轴为 Token Index (0~4000+), y 轴为 Attention Score。关键观察: (1) 在浅层 (Layer 4, 8), 注意力分布较为分散, 几乎均匀地分配在所有 visual token 上, 说明浅层尚未形成对特定 token 的聚焦; (2) 随着层数加深 (Layer 12, 16, 20, 24), 注意力逐渐集中到少数 token 上, 出现明显的尖峰, 说明深层能有效区分重要与冗余的 visual token; (3) 这一观察为渐进式丢弃策略提供了依据: 浅层用 uniform drop (因注意力分散, 基于注意力的选择不可靠), 深层用 attention-based selection (因注意力已聚焦到关键 token)。
渐进式丢弃策略 (仅推理时使用):
- 浅层 (前 ~1/7 层): Uniform Drop — 均匀丢弃一小部分 visual token (drop ratio 0.5), 保持视频时空结构
- 深层 (后 ~6/7 层): Attention Select — 基于 text token 对 visual token 的注意力分数, 保留最相关的 token (keep ratio 0.75 或 0.25)
伪代码: Progressive Visual Dropout (推理时)
────────────────────────────────────────────
输入: LLM 各层, visual tokens V, text tokens T
参数: shallow_layer=4, deep_layer=18, uni_drop_ratio=0.5, attn_keep_ratio=0.75/0.25
1. for layer_idx in range(num_layers):
2. if layer_idx == shallow_layer:
# Uniform Drop: 随机均匀丢弃 50% visual tokens
keep_indices = random_sample(len(V), int(len(V) * (1 - uni_drop_ratio)))
V = V[keep_indices]
3. if layer_idx == deep_layer:
# Attention Select: 基于 text→visual 注意力分数选择
attn_scores = compute_attention(T, V) # text 对每个 visual token 的注意力
top_indices = top_k(attn_scores, int(len(V) * attn_keep_ratio))
V = V[top_indices]
4. 正常执行 LLM layer forward
5. 返回 LLM 输出3.5 LongVid 数据集
大规模长视频指令微调数据集:
- 规模: 114,228 个长视频, 3,444,849 个 QA 对
- 来源: Ego4D, HowTo100M, HD-Vila, MiraData
- 视频类型: 电影、第一人称视频、新闻、访谈、教程等
- 5 种任务: video captioning, temporal grounding, event relation recognition, scene relation recognition, video event counting
- 标注流程: 利用已有高质量 caption (Panda-70M, CosMo, Ego4D-HCap 等), 筛选可重组为长视频序列的连续片段, 生成事件标签和时间戳, 最后基于 caption/事件标签/时间戳构建 QA 对
3.6 Multi-stage Short-to-Long Learning
| Stage | 分辨率 | 帧数 | 数据 | 样本数 | 可训练模块 | 参数量 |
|---|---|---|---|---|---|---|
| Stage-1: Video-Language Alignment | 224 | 4 | Image & Short Video | 1M | Projector | 20.0M |
| Stage-2: Short Video Pre-training | 224 | 8 | Image & Short Video | 4M | Full Model | 7.9B |
| Stage-3: Joint Short & Long SFT | 224 | 64~512 | (Multi-)Image & Short/Long Video | 3.2M | Full Model | 7.9B |
| Stage-4: High-Res Post-finetuning | 224→448 | 64~512 | (Multi-)Image & Short/Long Video | 0.3M | ViT & Projector | 0.3B |
关键训练超参数:
- Stage-1: batch size 512, LR (ViT) , LR (connector & LLM) , epoch 1
- Stage-2: batch size 256, LR (ViT) , LR (connector & LLM) , epoch 1
- Stage-3: batch size 256, LR (ViT) , LR (connector & LLM) , epoch 1
- Stage-4: batch size 256, LR (ViT) , LR (connector & LLM) , epoch 1, LLM frozen
3.7 Multi-Hop Needle In A Video Haystack (MH-NIAH)

Figure 4 解读: Multi-Hop NIAH 的示例。在长视频中插入一条由多张图片组成的推理路径 (正确路径标为 1→2→3, 蓝色), 每张图片附有文字线索指向下一张。同时插入多条干扰路径 (X1→X2→X3, 红色)。模型需要: (1) Q1: 从起始线索出发, 沿正确推理路径找到最终 needle 图片, 选择最匹配的描述; (2) Q2: 回答关于 needle 图片内容的问题。所有图片来自 MS-COCO, 即使模型记住了 COCO 内容也无法 “作弊”。两个指标: CAP (找到正确 needle 的准确率) 和 QA (正确回答问题的准确率)。
4. Experimental Setup (实验设置)
模型配置
| 组件 | 具体模型 | 说明 |
|---|---|---|
| Visual Encoder | UMT-L (224分辨率) | Spatio-temporal attention, 每 clip 4 帧 |
| Connector | Similar Token Merging + MLP | 无参数合并 + 线性投射 |
| LLM | Qwen2-7B | 28 层, 支持长上下文 |
| 替代 Visual Encoder | InternVideo2-1B | 更强时间建模能力 |
评测基准
Short Video QA:
- MVBench (短视频多选 QA, 平均时长 16s)
- Perception Test (感知能力测试, 平均时长 23s)
Long Video QA:
- LongVideoBench (长视频交错理解, 平均时长 473s)
- MLVU (多任务长视频理解, 平均时长 651s)
- LVBench (极长视频理解, 平均时长 4101s)
综合:
- VideoMME (含/不含字幕, 覆盖多种时长, 平均 1010s)
时间定位:
- Charades-STA (时间活动定位, 平均时长 30s)
视频描述:
- AuroraCap (视频细节描述, 平均时长 28s)
长上下文检索:
- Single-Hop NIAH (10,000 帧)
- Multi-Hop NIAH (10,000 帧)
Baseline 模型
- 闭源: GPT-4V, GPT-4o, Gemini-1.5-Pro
- 开源 (同尺寸): VideoChat2-HD, InternVideo2-HD, LLaVA-OneVision, LLaVA-Video, VITA1.5, InternVL2, Qwen2-VL, Qwen2.5-VL
- 开源 (长视频): LLaMA-VID, LongVU, LongVA, LongVILA, Kangaroo
5. Experimental Results (实验结果)
5.1 综合视频理解评测

Figure 2 解读: VideoChat-Flash 与 GPT-4o、Gemini-1.5-Pro、Previous SOTA (7B) 在 7 个 benchmark 上的对比。在短视频 QA (MVBench, Perception Test, LongVideoBench) 和长视频 QA (MLVU, VideoMME, LVBench) 上, VideoChat-Flash 全面领先。特别是在 MLVU 上达到 74.7, 显著超过 GPT-4o (64.6) 和 Gemini-1.5-Pro (64.0)。在 Charades-STA 时间定位和 AuroraCap 视频描述上也取得最优。
Table 1 核心数据 (VideoChat-Flash @448 vs 最强 baseline):
| Benchmark | VideoChat-Flash @448 (7B) | 次优开源 (7B) | GPT-4o | Gemini-1.5-Pro |
|---|---|---|---|---|
| MVBench | 76.2 | 72.0 (InternVL2.5) | - | - |
| Perception Test | 75.6 | 69.6 (Qwen2.5-VL) | - | - |
| LongVideoBench | 64.7 | 67.0 (Qwen2.5-VL) | 66.7 | 64.0 |
| MLVU M-Avg | 74.7 | 73.2 (InternVL2.5) | 64.6 | - |
| VideoMME Overall | 65.3/69.7 | 70.2 (Qwen2.5-VL) | 71.9/77.2 | 75.0/81.3 |
| LVBench | 55.4/63.3 | 65.1/71.6 (Qwen2.5-VL) | 65.3/72.1 | 67.4/77.4 |
| Charades-STA | 48.2 | 45.3 (Qwen2.5-VL) | 30.8 | 33.1 |
| AuroraCap | 42.9 | 41.6 (InternVL2.5) | - | 41.7 |
关键发现: 仅用 16 tokens/frame (其他模型通常 196-1924), VideoChat-Flash 在多数 benchmark 上超过 GPT-4o 和远大参数模型。
5.2 Single-Hop NIAH

Figure 5(c) 解读: VideoChat-Flash 在 10,000 帧 Single-Hop NIAH 上的热力图。横轴为帧数, 纵轴为 needle 插入深度百分比。几乎全绿 (高准确率), 达到 99.1% 总体准确率。相比之下, LongVA 在 3,000 帧时约 91.8%, LLaMA-VID 在 10,000 帧时仅 55.0%。

Figure 5(a) 解读: LongVA 在 3,000 帧时的 NIAH 热力图, 准确率为 91.8%。可以看到随着帧数增加, 准确率明显下降, 尤其在中间深度位置出现较多失败区域。
5.3 Multi-Hop NIAH

Figure 6 解读: Multi-Hop NIAH 在 10,000 帧下各模型的 CAP 和 QA 准确率随帧数变化。VideoChat-Flash (红色) 在 CAP 和 QA 两个指标上均稳定领先, CAP 和 QA 分别比 LongVA 高约 8 个百分点。Multi-Hop NIAH 比 Single-Hop 难度大幅增加, 更能反映模型真实的长上下文推理能力。
5.4 消融实验
Table 2: 各设计的增量贡献:
| 设计 | MVB Avg | MLVU M-Avg | VMME Overall | Charades mIoU |
|---|---|---|---|---|
| Baseline (SigLiP, 196 tok/frame) | 60.2 | 63.7 | 52.8 | - |
| + HiCo (16 tok/frame) | 61.1 | 60.6 | 53.2 | - |
| + short video pretraining | 66.5 | 62.4 | 53.9 | - |
| + duration-based sampling | 67.0 | 64.5 | 55.5 | - |
| + LongVid data | 66.5 | 68.3 | 55.8 | - |
| + Joint short & long SFT | 73.2 | 74.5 | 64.0 | 48.4 |
| + High-res post-finetuning | 74.0 | 74.7 | 65.3 | 48.0 |
| - timestamp prompt | 73.4 | 73.2 | 63.4 | 44.2 |
关键发现:
- HiCo 将 token 数从 196 降至 16, 性能几乎不降 (MVB +0.9, VMME +0.4), MLVU 略降 3.1 (因长视频需更多帧数补偿)
- Joint short & long SFT 带来最大提升 (MLVU +6.2, VMME +8.2)
- Timestamp prompt 对时间定位任务至关重要 (Charades: 48.0 → 44.2)
5.5 Token 压缩策略对比 (Table 4)
| Connector | Token/Frame | MVBench | MLVU | VideoMME | Avg |
|---|---|---|---|---|---|
| MLP (无压缩) | 729 | 59.4 | 64 | 55.3 | 59.6 |
| Spatial Downsampling | 196 (27%) | 60.2 | 63.7 | 52.8 | 58.9 |
| Similar Token Merging | 196 (27%) | 62.8 | 66.7 | 56.8 | 62.1 |
| Similar Token Merging | 49 (7%) | 61.4 | 63.3 | 55.3 | 60.0 |
| Similar Token Merging | 16 (2%) | 60.2 | 62.4 | 53.5 | 58.7 |
关键发现: Similar Token Merging 在所有压缩比下均优于其他策略。即使在极端 2% 压缩比 (16 tok/frame) 下, 仍保持 58.7 的平均分, 接近无压缩的 59.6。
5.6 计算效率 (Table 6)
| 输入帧数 | 模型 | Avg tokens/frame | FLOPs (T) | Memory (G) Train | Memory (G) Infer |
|---|---|---|---|---|---|
| 64 | LongVILA | 196 | 224.8 | 15.4 | 16.7 |
| 64 | LongVA | 144 | 155.9 | 12.3 | 16.3 |
| 64 | VideoChat-Flash | 16 | 14.8 | 4.8 | 15.4 |
| 1000 | LongVILA | 196 | 14336.9 | oom | 37.7 |
| 1000 | LongVA | 144 | 8278.9 | oom | 31.8 |
| 1000 | VideoChat-Flash | 16 | 303.3 | 18.6 | 17.1 |
| 10000 | LongVILA | 196 | 1184250.0 | oom | oom |
| 10000 | LongVA | 144 | 644632.0 | oom | oom |
| 10000 | VideoChat-Flash | 16 | 9969.5 | oom | 33.6 |
关键发现: VideoChat-Flash 的计算量比 LongVILA 低约 两个数量级 (10,000 帧: 9,969.5 vs 1,184,250.0 TFLOPs)。唯一能在单卡 A100-80G 上完成 10,000 帧推理的模型 (33.6G 显存)。
5.7 Duration-based Sampling 消融

Figure 7(a) 解读: 固定 , 调整 的影响。 时短视频和长视频性能均最优。较大的 能更好捕捉短视频中的快速动作, 但过大 (128) 则无提升。

Figure 7(b) 解读: 固定 , 调整 的影响。 从 64 增大到 256, 长视频性能持续提升 (更多帧 = 更多信息)。 时长视频性能进一步提升但短视频略降, 是最佳平衡点。
5.8 Visual Dropout 消融 (Table 5)
| Drop 类型/比例 | Drop 层 | FLOPs (G) | Latency (s) | MLVU | VideoMME |
|---|---|---|---|---|---|
| 无 dropout | - | 341.4 | 2.6 | 71.8 | 61.2 |
| Uni./0.5 | 4 | 242.8 | 1.9 | 71.2 | 60.4 |
| Attn./0.5 | 4 | 242.8 | 1.9 | 70.7 | 60.8 |
| Uni./0.5 | 18 | 295.2 | 2.2 | 71.7 | 61.8 |
| Attn./0.5 | 18 | 295.2 | 2.2 | 72.1(+0.3) | 61.7(+0.5) |
| Attn./0.75 + Attn./0.25 | 4,18 | 245.8 | 1.9 | 71.4 | 60.9 |
| Uni./0.75 + Attn./0.25 | 4,18 | 245.8 | 1.9 | 72.0(+0.2) | 61.1(-0.1) |
关键发现: 浅层 uniform drop + 深层 attention select 的组合最优, FLOPs 减少 28% (341.4→245.8G), 延迟减少 27% (2.6→1.9s), MLVU 反而提升 0.2。
5.9 Code-to-Paper Mapping
| 论文组件 | 代码位置 | 说明 |
|---|---|---|
| Video Encoder (UMT-L) | llava-train_videochat/llava/model/multimodal_encoder/umt_encoder.py | Spatio-temporal attention 编码, 每 clip 4 帧 |
| Video Encoder (InternVideo2) | llava-train_videochat/llava/model/multimodal_encoder/internvideo2_encoder.py | 替代编码器, 更强时间建模 |
| Connector (Token Merging + MLP) | llava-train_videochat/llava/model/multimodal_projector/builder.py | Similar token merging 压缩 + MLP 投射, 配置中标记为 tome16_mlp |
| Stage-1 训练 | llava-train_videochat/scripts/ (stage1 脚本) | Projector alignment, 1M samples |
| Stage-2 训练 | llava-train_videochat/scripts/ (stage2 脚本) | Short video pre-training, 4M samples |
| Stage-3 训练 | llava-train_videochat/scripts/ (stage3 脚本) | Joint short & long SFT, 3.2M samples |
| Stage-4 训练 | llava-train_videochat/scripts/ (stage4 脚本) | High-res post-finetuning, 0.3M samples |
| InternVideo2.5 微调 | xtuner-train_internvideo2_5/ | 使用 XTuner 框架的替代训练流程 |
| QA & Grounding 评测 | lmms-eval_videochat/ | 基于 lmms-eval 框架的评测脚本 |
| NIAH 评测 | xtuner-eval_niah/ | Single-Hop 和 Multi-Hop NIAH 评测 |
| 训练数据格式 | llava-train_videochat/data/ | 遵循 LLaVA-NeXT 数据格式 |
| 数据集详情 | DATA.md | LongVid 数据集说明和下载链接 |
5.10 总结
VideoChat-Flash 的核心贡献在于提出了 分层视频 token 压缩 (HiCo) 范式:
- Clip-level: 利用 spatio-temporal attention + similar token merging, 将每帧从 ~196 token 压缩到 16 token (8% 压缩比)
- Video-level: 利用 LLM 浅层注意力分散、深层聚焦的特性, 渐进式丢弃无关 visual token (浅层 uniform drop + 深层 attention select)
配合 Duration-based Sampling (自适应采样密度)、LongVid (114K 长视频 QA 数据集)、Short-to-Long 4 阶段训练 和 Multi-Hop NIAH (更具挑战性的长视频评测), 在 7B 参数量下实现了:
- 10,000 帧 NIAH 99.1% 准确率 (开源 SOTA)
- 计算量比 LongVILA 低 两个数量级
- 在 MVBench, MLVU, Charades-STA, AuroraCap 等 benchmark 上超越 GPT-4o