StreamingTOM: Streaming Token Compression for Efficient Video Understanding
1. Motivation (研究动机)
一句话总结: 首个 training-free 的流式视频理解 pre-LLM token 压缩框架,通过 Causal Temporal Reduction (CTR) 在 LLM 前将每帧 N=196 个 token 压缩到 G=50 个,再通过 Online Quantized Memory (OQM) 在 LLM 后以 4-bit 量化存储 kv-cache,实现 15.7x kv-cache 压缩、1.2x 更低峰值显存、2x 更快 TTFT。
1.1 流式视频理解的两大约束
与离线视频处理不同,流式(streaming)视频 VLM 面临两个根本性约束:
- 因果性 (Causality): 系统无法访问未来帧,离线方法依赖的全局时序分析不可用
- 累积性 (Accumulation): 随帧到达,有效序列长度 持续增长,kv-cache 线性膨胀
kv-cache 增长速率公式:
以 LLaVA-OV-7B 为例(, FP16, 0.5fps),1小时视频的 kv-cache 约 18.8 GB,远超单 GPU 显存容量。
1.2 现有方法的不足
| 方法类型 | 代表工作 | 局限 |
|---|---|---|
| 离线 token 压缩 | DyCoke, VisionZip, HoliTom | 依赖全局时序分析/双向注意力,违反因果性 |
| Training-based 流式 | MovieChat, Dispider, Flash-VStream | 需要昂贵的模型重训练 |
| Training-free 流式 | ReKV, LiveVLM, StreamMem | 仅管理 post-LLM kv-cache,pre-LLM prefill 计算 完全未减少 |
核心 Gap: 没有任何 training-free 流式方法在 LLM 之前执行严格因果的 token 压缩。

Figure 1 解读: 左图展示 StreamingTOM 的整体框架,视频流经 Vision Encoder 后先通过 Causal Temporal Reduction 将每帧 N 个 token 压缩为 G 个,再经 LLM prefill 后通过 Online Quantized Memory 以 4-bit 格式存储。查询时按需检索相关 group 并反量化。右图显示在 GPU Memory vs TTFT 的比较中,StreamingTOM 在两个指标上均优于 LiveVLM、ReKV 和 Dispider。
2. Idea (核心思想)
2.1 两阶段协同:CTR + OQM
StreamingTOM 的核心思想是把“前端计算压缩”和“后端存储压缩”串联起来:
- : LLM 前将每帧 token 从 压缩到固定配额
- : LLM 后将 FP16 kv-cache 量化为 4-bit 存储
总压缩比:
计算复杂度: 从 降至 存储: 从 bits 降至 bits
这也是论文的关键贡献:training-free 流式方法第一次把优化点前移到 LLM 之前,而不是只压缩 post-LLM kv-cache。
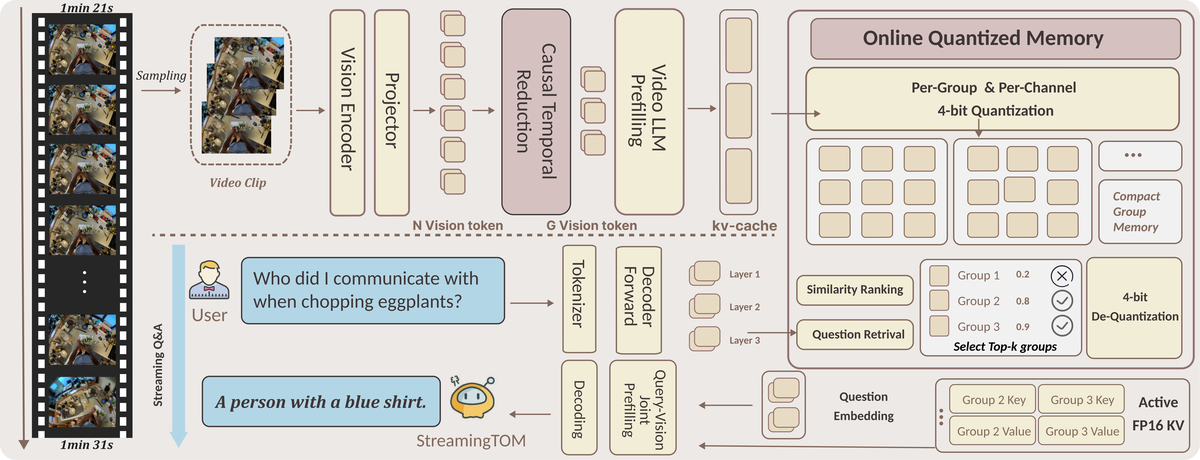
Figure 2 解读: StreamingTOM 的详细架构图。上方是 Vision Pipeline:视频帧经 Vision Encoder 编码后,CTR 将冗余 token 压缩为紧凑的 group,写入在线存储。下方是 Query Pipeline:用户提问后,OQM 基于问题嵌入检索相关 group,反量化为 FP16 后进行解码生成答案。核心设计是 group 抽象——每帧固定 G 个 token 的单元,作为 CTR 和 OQM 之间的接口。
2.2 设计原则
CTR 和 OQM 的组合遵循三个直观原则:
- 严格因果:只看当前帧与上一帧,避免依赖未来信息
- 固定预算:每帧都压到固定的 G 个 token,保证延迟可控
- 存储与计算分离:CTR 负责减少 prefill 计算,OQM 负责控制历史 kv-cache 膨胀
3. Method (方法)
3.1 Causal Temporal Reduction (CTR)
CTR 的三个设计原则:严格因果(2帧窗口)、单次处理、固定每帧预算 G。
Step 1: 时序相似度计算
对于相邻帧 和 的特征 ,计算逐 token 余弦相似度:
Step 2: 静态/动态 Token 分类
基于阈值 将 token 分为静态(时序冗余)和动态(新信息):
Step 3: 自适应预算分配
按静态/动态 token 比例分配 G 个预算:
Step 4: 双路径处理
- 动态路径: 按空间显著性(attention score )选 top-
- 静态路径: 密度聚类合并为 个 token
输出: ,(固定大小)。
状态内存: ,仅保留上一帧特征,与流长度无关。 每帧复杂度: ,其中 。

Figure 3 解读: CTR 的完整压缩流程。左侧展示 4 帧视觉 token 序列通过 2 帧滑窗进行相似度评估,高相似度标记为静态 token(白色),低相似度标记为动态 token(灰色)。右侧展示双路径处理:动态 token 通过 TopK Attention Selection 挑选最显著的 token,静态 token 通过 Cluster Merge 聚合。最终每帧输出固定 G 个 token。
3.2 Online Quantized Memory (OQM)
OQM 解决 LLM 后 kv-cache 线性增长问题,通过 4-bit 量化 + 按需检索实现有界内存。
量化过程
对每个 group tensor ,per-head, per-channel 量化:
其中 scale 和 offset:
代表键 为量化前 key 的平均值,用于高效检索。
内存结构
系统 token(指令、任务描述)保持 FP16,视觉 token 以 4-bit 存储。
检索与反量化
反量化算子:
查询时按需检索 top-k 相关 group:
关键特性:
- 总存储: — 保留完整历史
- 活跃 kv: , — 有界解码内存
3.3 伪代码
def streaming_tom(video_stream: list, G: int = 50, tau_c: float = 0.9):
"""StreamingTOM: CTR + OQM streaming video understanding."""
memory: list = [] # stores (quantized_kv, representative_key) per frame
F_prev = None # previous frame features, O(Nd) state
# ========= Vision Pipeline (per frame) =========
for t, v_t in enumerate(video_stream):
# 1. Encode
H_t = vision_encoder(v_t) # H_t: [N, d]
alpha_t = attention_scores(H_t) # saliency from encoder (zero-cost)
# 2. CTR: Causal Temporal Reduction
if t == 0:
G_t = topk(alpha_t, G) # first frame: select by saliency
else:
# Temporal similarity with previous frame
s_t = cosine_sim_per_token(H_t, F_prev) # [N]
# Static/Dynamic partition
S_t = [i for i in range(N) if s_t[i] > tau_c] # static tokens
D_t = [i for i in range(N) if s_t[i] <= tau_c] # dynamic tokens
# Adaptive budget allocation
k_s = int(G * len(S_t) / N)
k_d = G - k_s
# Dual-path processing
G_d = topk(alpha_t[D_t], k_d) # dynamic: attention selection
G_s = dpc_merge(H_t[S_t], k_s) # static: density clustering
G_t = concat(G_d, G_s) # |G_t| = G
# 3. LLM Prefill (only G tokens, not N) -> O(GLd^2)
K_t, V_t = llm_prefill(G_t)
# 4. OQM: Quantize and store
k_bar_t = K_t.mean(dim=1) # representative key
Q4_t = quantize_4bit(K_t, V_t) # per-head, per-channel
memory.append((Q4_t, k_bar_t))
F_prev = H_t # update state (O(Nd))
return memory
def streaming_tom_query(query: str, memory: list, k: int) -> str:
"""Query pipeline: retrieve and decode from quantized memory."""
q_emb = tokenize_and_embed(query)
# Retrieval: find top-k relevant groups
scores = [cosine_sim(q_emb, m[1]) for m in memory]
R = topk_indices(scores, k)
# Dequantize selected groups -> O(k * G * d)
KV_active = dequantize([memory[i][0] for i in R])
# Decode with bounded active KV
answer = llm_decode(q_emb, KV_sys_fp16, KV_active)
return answer3.4 代码映射表
由于截至 2026-03-12 官方代码尚未开源,以下基于论文方法给出预期的代码模块映射:
| 论文组件 | 预期代码模块 | 功能描述 |
|---|---|---|
| Vision Encoder | model/vision_encoder.py | SigLIP 视觉编码,输出 tokens/frame |
| CTR - 时序相似度 | compression/ctr.py::compute_similarity() | 逐 token 余弦相似度,Eq.(4) |
| CTR - 静态/动态分类 | compression/ctr.py::partition_tokens() | 阈值 分类,Eq.(5) |
| CTR - 预算分配 | compression/ctr.py::allocate_budget() | 按比例分配 ,Eq.(6) |
| CTR - 动态选择 | compression/ctr.py::topk_attention() | 基于 attention score 的 TopK,Eq.(7) |
| CTR - 静态合并 | compression/ctr.py::dpc_merge() | 密度聚类合并静态 token,Eq.(7) |
| OQM - 4-bit 量化 | memory/oqm.py::quantize_group() | Per-head, per-channel 量化,Eq.(8-9) |
| OQM - 代表键 | memory/oqm.py::compute_rep_key() | 计算 用于检索 |
| OQM - 相似度检索 | memory/oqm.py::retrieve_groups() | Top-k group 检索,Eq.(13) |
| OQM - 反量化 | memory/oqm.py::dequantize_group() | 4-bit → FP16 恢复,Eq.(12) |
| 流式推理主循环 | inference/streaming.py | 协调 CTR + LLM Prefill + OQM |
4. Experimental Setup (实验设置)
4.1 模型与部署
- Backbone: LLaVA-OV-7B
- 方法类型: training-free、plug-and-play
- 目标场景: 流式视频理解,强调因果约束和长序列显存控制
4.2 数据集与评测任务
论文中记录的主要评测包括:
- VideoMME: Long / Med / Short / Overall
- MLVU
- EgoSchema
- RVS-Ego
- RVS-Movie
4.3 关键实验设置
- 离线对比常用帧数:32 frames
- 流式设置:0.5fps / 0.2fps / 1fps
- 长序列效率测试:16 / 64 / 256 / 512 frames
- Batch Size = 8
- 公平比较时限制 GPU 28GB,并且 无 CPU offloading
- 若需更细的训练与优化超参,论文未详细说明
5. Experimental Results (实验结果)
5.1 离线视频评估 (Table 1)
| 方法 | 类型 | Frames | VideoMME Long | Med | Short | Overall | MLVU | EgoSchema | Avg |
|---|---|---|---|---|---|---|---|---|---|
| LLaVA-OV-7B | 离线基线 | 32 | 48.8 | 56.4 | 70.1 | 58.4 | 64.7 | 60.1 | 61.0 |
| +DyCoke | 离线压缩 | 32 | - | - | - | 54.3 | - | 59.5 | - |
| +VisionZip | 离线压缩 | 32 | - | - | - | 58.2 | - | 60.3 | - |
| +HoliTom | 离线压缩 | 32 | - | - | - | 58.9 | - | 61.2 | - |
| MovieChat-7B | 流式训练 | 2048 | 33.4 | - | - | 38.2 | 25.8 | 53.5 | 39.2 |
| Dispider-7B | 流式训练 | 1fps | 49.7 | 53.7 | - | 56.5 | 61.7 | 55.6 | 57.9 |
| +LiveVLM | 流式免训 | 0.5/0.2fps | 48.8 | 56.4 | 66.7 | 57.3 | 66.3 | 59.0 | 60.9 |
| +StreamMem | 流式免训 | 0.5/0.2fps | 50.1 | 56.6 | 71.5 | 59.4 | 66.9 | 63.0 | 63.1 |
| +StreamingTOM | 流式免训 | 0.5/0.2fps | 50.6 | 57.8 | 71.3 | 59.9 | 67.9 | 63.7 | 63.8 |
关键发现: StreamingTOM 以 training-free 方式超越所有流式方法(含训练方法 Dispider-7B),并超越离线压缩方法 HoliTom、VisionZip、DyCoke。
5.2 在线流式评估 (Table 2 - RVS)
| 方法 | RVS-Ego Acc | Score | RVS-Movie Acc | Score | Avg Acc | Avg Score |
|---|---|---|---|---|---|---|
| ReKV (w/ CPU offload) | 63.7 | 4.0 | 54.4 | 3.6 | 59.0 | 3.8 |
| ReKV (w/o offload) | 55.8 | 3.3 | 50.8 | 3.4 | 53.3 | 3.4 |
| Flash-VStream | 57.0 | 4.0 | 53.1 | 3.3 | 55.0 | 3.6 |
| InfiniPot-V | 57.9 | 3.5 | 51.4 | 3.5 | 54.6 | 3.5 |
| StreamMem | 57.6 | 3.8 | 52.7 | 3.4 | 55.2 | 3.6 |
| StreamingTOM | 58.3 | 3.9 | 53.2 | 3.5 | 55.8 | 3.7 |
注: 公平比较限制 GPU 28GB、无 CPU offloading。ReKV 的 59.0 依赖 CPU-GPU 传输,不适用于实时流式部署。
5.3 效率分析 (Table 3)
| Frames | GPU Mem (GB) | TTFT (s) | Throughput (tok/s) |
|---|---|---|---|
| 16 | 16.0 | 0.17 | 36.7 |
| 64 | 16.0 | 0.20 | 32.6 |
| 256 | 16.3 | 0.30 | 20.8 |
| 512 | 16.7 | 0.30 | 20.9 |
| 0.2fps streaming | 16.9 | 0.31 | 20.8 |
| 0.5fps streaming | 18.4 | 0.36 | 20.9 |
(Batch Size = 8)
核心数据:
- 内存从 16 帧到 512 帧仅增长 0.7 GB (16.0→16.7),体现 亚线性增长
- 对比 LiveVLM (256帧): 1.2x 更低峰值显存, 2x 更快 TTFT
- 1 小时流式: kv-cache 从 18.8 GB 降至 1.2 GB

Figure 5 解读: 完整处理流水线时间对比。上行为 baseline,下行为 StreamingTOM。64帧、batch=8、50 tokens/frame 设置下,CTR 将 prefill 从 337.8ms 加速至 92.8ms(3.6x 加速)。OQM 额外开销极小:kv 存储 7.3ms、检索 6.9ms、4-bit 重建 28.7ms。最终 query TTFT 仅 0.20s。

Figure 6 解读: Memory 和 TTFT 随帧数变化的对比柱状图。StreamingTOM 在所有帧数设置下均优于 Dispider、ReKV、LiveVLM,且优势随帧数增加而扩大——256帧时相比 LiveVLM 实现 1.2x 更低内存和 2x 更快 TTFT。
5.4 消融实验 (Table 4)
| Token数 | 量化位数 | 压缩比(%) | VideoMME Short | Med | Long | Overall |
|---|---|---|---|---|---|---|
| 40 | 4-bit | 5.1% | 70.1 | 56.8 | 49.9 | 58.9 |
| 40 | 2-bit | 2.6% | 69.1 | 57.1 | 48.0 | 58.1 |
| 50 | 4-bit | 6.4% | 71.3 | 57.8 | 50.6 | 59.9 |
| 50 | 2-bit* | 3.2% | 69.3 | 57.3 | 48.8 | 58.5 |
| 60 | 4-bit | 7.7% | 69.9 | 57.6 | 50.4 | 59.3 |
| 60 | 2-bit | 3.8% | 68.9 | 56.8 | 50.3 | 58.7 |
最优配置: 50 tokens + 4-bit,压缩至 baseline 的 6.4%(即 15.7x 压缩比),同时保持最佳精度。
- 40 tokens: 丢失关键细节,精度下降
- 60 tokens: 固定内存下时序覆盖减少,也导致精度下降
- 2-bit vs 4-bit: 4-bit 在所有设置下均优于 2-bit

Figure 4 解读: RVS Movie 的两个定性案例。上例询问 “描述主角跟踪目标的方法”,StreamingTOM 准确回答涉及 “subway station” 等细粒度语义,与 ground truth 一致(GPT 评分 5/5)。下例询问 “追逐是否涉及多方”,StreamingTOM 正确回答 “Yes” 并描述多人互动细节(GPT 评分 5/5)。展示了模型在因果流式约束下的长程推理能力。
5.5 个人思考与总结
5.5.1 核心贡献
- 首创 pre-LLM 流式 token 压缩: 此前所有 training-free 流式方法仅优化 post-LLM kv-cache,pre-LLM prefill 计算 完全未动。StreamingTOM 是第一个在 LLM 前进行严格因果 token 压缩的方法。
- 两阶段协同设计: CTR (pre-LLM 计算) + OQM (post-LLM 内存) 的组合实现了计算和内存的双重优化,单独任一阶段都不够——pre-LLM 压缩无法阻止 kv-cache 累积,post-LLM 压缩无法减少已产生的计算量。
- Group 抽象: 每帧固定 G 个 token 的 group 是 CTR 和 OQM 之间的接口,解耦了 token 选择和存储优化,确保可预测的延迟。
5.5.2 方法精妙之处
- 零成本显著性分数: 直接复用 vision encoder 的 attention score,无额外计算
- 2帧窗口 + 单次处理: 极简因果设计,状态内存仅 ,与流长度无关
- Chunked attention: 避免 注意力矩阵的内存峰值
- 代表键检索: 每个 group 仅需一个 维向量,检索开销极低
5.5.3 局限性与思考
- 固定 budget G 的限制: 对所有帧使用相同的 G=50,但实际中不同帧的信息密度差异很大。动态调整 G(在总预算约束下)可能进一步提升效果。
- 静态/动态分类仅基于相邻帧: 如果 camera 整体平移(所有 token 都”变化”),可能把大量背景误判为动态 token。引入光流补偿或全局运动估计可能有帮助。
- 代表键的局限: 取 key 平均值作为 group 代表,在语义多样的帧中可能丢失细节。可考虑多代表键或层次化检索。
- 未在更大模型上验证: 仅在 LLaVA-OV-7B 上实验,更大模型(如 72B)的效果待验证。
- 与训练方法的差距: 在 RVS 上不如 ReKV (w/ CPU offload) 的 59.0,但后者依赖 CPU-GPU 传输。未来可以考虑将 CTR/OQM 思想融入训练流程。
5.5.4 数据汇总
| 指标 | 数值 |
|---|---|
| kv-cache 压缩比 | 15.7x |
| 峰值显存降低 | 1.2x (vs LiveVLM) |
| TTFT 加速 | 2x (vs LiveVLM) |
| Prefill 加速 | 3.6x (337.8ms → 92.8ms) |
| 离线 Avg 精度 | 63.8% (VideoMME + MLVU + EgoSchema) |
| RVS 流式精度 | 55.8% / 3.7 |
| 1小时 kv-cache | 18.8 GB → 1.2 GB |
| 每帧保留 token | 50 / 196 (25.5%) |
| 内存占比 | 6.4% of baseline |