Recursive Language Models
Paper: arXiv:2512.24601 Code: alexzhang13/rlm Code reference:
main@8467a580(2026-05-13)
1. Motivation (研究动机)
当前长上下文 LLM 的核心问题不是“能否把更多 token 塞进窗口”,而是模型在长 prompt 内做有效语义工作的能力会随长度和任务复杂度退化。论文把这个现象称为 effective context window / context rot:在 S-NIAH、OOLONG、OOLONG-Pairs 这类从常数级、线性到近似二次复杂度的任务上,GPT-5 即便处于上下文窗口内也会随输入长度上升而掉点;超过 GPT-5 的 token 窗口后,普通调用直接不可用。
这篇论文要解决的具体目标是:给一个基础模型 ,在不要求一次性读入完整 prompt 的情况下,让它能处理 的输入、产生可超过窗口限制的输出,并能执行 甚至 级别的语义工作。传统 compaction / retrieval / coding-agent 方法要么把原 prompt 或摘要不断塞回上下文,要么只能把子调用作为外部动作,缺少“程序化地构造子问题并递归调用同一接口”的能力。
这个问题值得研究,因为它把长上下文从“静态输入长度扩展”转成“inference-time scaling 接口设计”:如果 LM 可以把 prompt 当作外部环境中的对象,用代码读取、过滤、切分,再对片段递归调用自身,那么有效上下文长度不再直接受模型窗口 限制,且复杂任务的计算量可以随任务需要动态增长。
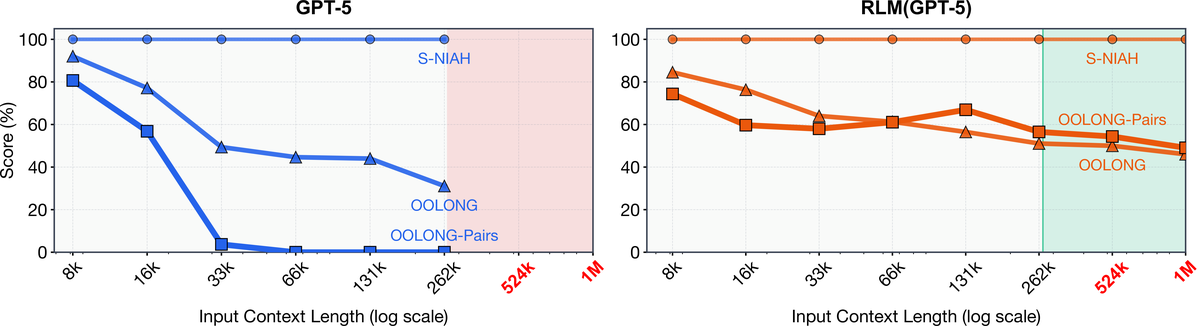
Figure 1 解读:Figure 1 对比 GPT-5 与 RLM(GPT-5, depth=1) 在 S-NIAH、OOLONG、OOLONG-Pairs 上随输入长度从 到 增长的表现。红色区域外超过 GPT-5 的 token context window;随着任务从常数复杂度到线性、二次复杂度,普通 GPT-5 退化更快,而 RLM 的曲线下降更慢,说明问题难度来自“需要做多少语义工作”,不只是 token 数。
2. Idea (核心思想)
核心洞察:不要把超长 prompt 当作必须进入上下文窗口的 token 序列,而是把它变成 REPL 环境 里的外部变量;root LM 只需要看到变量的元信息和执行历史,然后用代码对变量做查询、切片、聚合,并在必要时对程序构造出的片段递归调用子 RLM / sub-LM。
本文的关键创新是提出 Recursive Language Model (RLM) 作为一个可替换普通 llm.completion(prompt) 的 inference paradigm:外部接口仍是 text-to-text,但内部是“LLM 生成代码 → REPL 执行 → 只把 stdout 元信息和历史反馈给 LLM → 若需要则递归 subcall”的循环。
与 compaction agent 的根本区别是:compaction 仍依赖把压缩后的文本塞回上下文;RLM 给模型一个 symbolic handle,让它能对原始 prompt 做程序化操作。与 CodeAct / ReAct 的区别是:普通 agent 通常把 prompt 放进历史、用 Finish 直接生成答案;RLM 的答案可以在 REPL 内被逐步构造,并且 REPL 内部可以调用 rlm_query,形成符号递归。
3. Method (方法)
3.1 Overall framework:把 prompt 放进环境,而不是放进上下文
给定基础模型 、上下文窗口 、任意长度 prompt ,RLM 定义为一个围绕 的 inference scaffold:它与持久化环境 交互,并返回字符串 。论文希望满足:
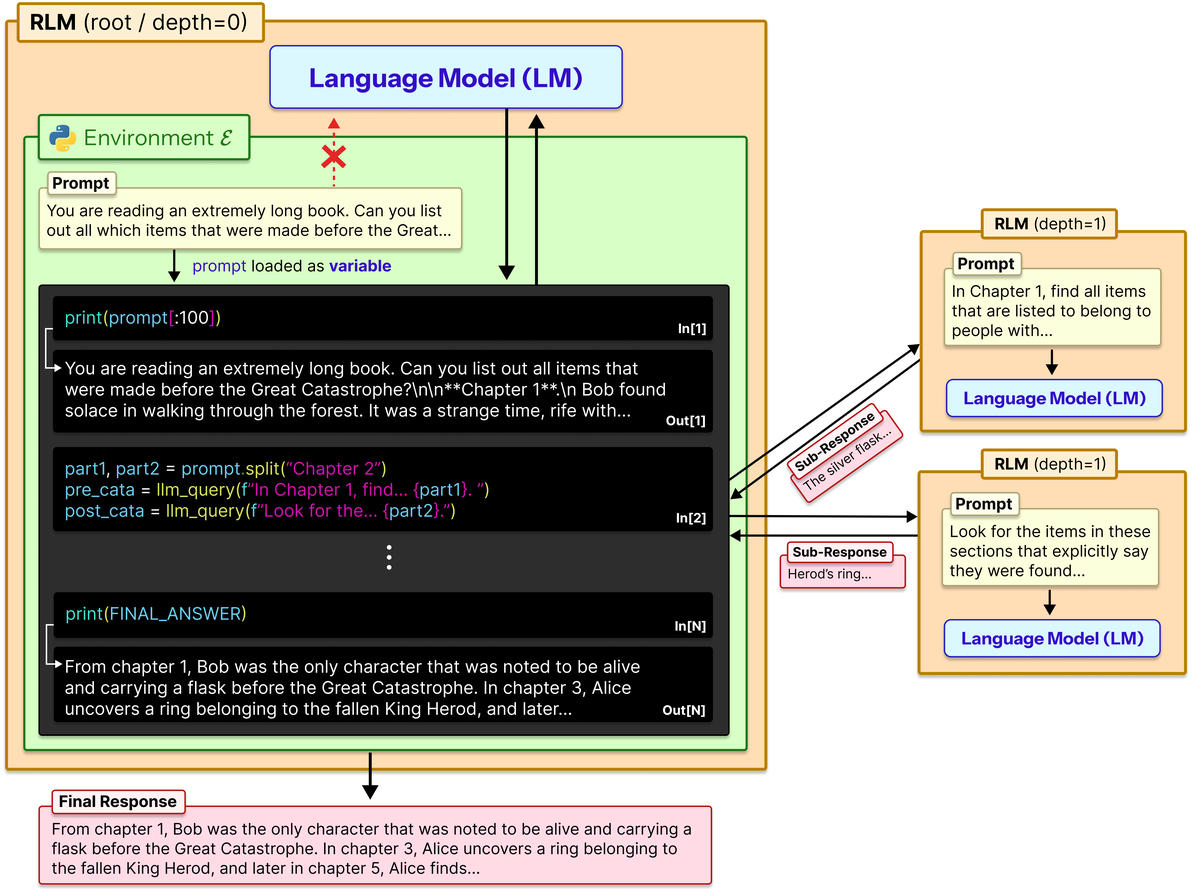
Figure 2 解读:Figure 2 是 RLM 架构图。输入 prompt 不直接作为完整上下文传给 LM,而是加载到 REPL 环境 的变量中;LM 看到的是系统提示、上下文长度元信息和前几轮代码 / stdout 摘要,然后生成代码来 inspect、filter、split 这个变量。关键点是环境内暴露 sub_RLM / rlm_query,所以 root model 可以对程序构造出的片段发起递归调用,并把子结果拼回最终答案。
直觉上,RLM 之所以有效,是因为它把“读长文”拆成两层:token-level 的存储和访问交给外部环境,semantic-level 的判断交给 LM。LM 不需要在每一步重新携带整篇文档,只需要决定下一步应该读哪里、怎样切分、何时把子任务交给更小的 LM/RLM 调用。这使得长上下文处理更像算法执行:上下文变量是内存,REPL 是控制流,LM 是生成下一步程序的策略。
3.2 Paper algorithm:RLM 递归调用循环
论文 Algorithm 1 可以写成:
当 state[Final] 被设置时返回最终答案 。论文用一个 bad scaffold 做对照:它把 直接放进 hist、让模型发 Finish 动作、且 sub_LM 只是动作集合中的一个工具;这三个设计会分别导致上下文窗口受限、输出长度受限、以及无法在程序内任意循环 / 分支地递归调用。
3.3 Released code 实现:completion loop
论文伪代码与 released code 实现差异:论文 Algorithm 1 是最小定义;released code 在 rlm/core/rlm.py 中额外实现了 max_depth fallback、budget / timeout / token / error checks、compaction、logger metadata、multiple code-block execution,以及通过 answer["ready"] / REPLResult.final_answer 触发结束,而不是字面上的 state[Final]。
def rlm_completion(rlm, prompt: str, root_prompt: str | None = None):
if rlm.depth >= rlm.max_depth:
return plain_lm_completion(prompt)
with spawn_lm_handler_and_environment(prompt) as (lm_handler, env):
message_history = setup_system_prompt_and_metadata(prompt)
for iteration_id in range(rlm.max_iterations):
check_timeout_and_iteration_limits()
if should_compact(message_history):
message_history = compact_history(lm_handler, env, message_history)
user_prompt = build_user_prompt(
root_prompt=root_prompt,
iteration=iteration_id,
context_count=env.get_context_count(),
history_count=env.get_history_count(),
)
response = lm_handler.completion(message_history + [user_prompt])
code_blocks = find_code_blocks(response)
results = []
for code in code_blocks:
repl_result = env.execute_code(code)
results.append((code, repl_result))
if repl_result.final_answer is not None:
return RLMChatCompletion(response=repl_result.final_answer)
message_history.extend(format_iteration(response, results))
return ask_lm_for_default_answer(message_history, lm_handler)这段伪代码对应 released code 的 RLM.completion 与 _completion_turn:模型输出 Markdown code block,代码被环境执行;每轮执行结果被格式化后进入下一轮历史。最终答案不是普通自然语言直接返回,而是 REPL 内设置 answer["content"] 并把 answer["ready"] = True。
3.4 REPL environment:上下文变量、final answer 和工具
class LocalREPL:
def setup(self):
self.globals = {
"SHOW_VARS": self.show_vars,
"llm_query": self.llm_query,
"llm_query_batched": self.llm_query_batched,
"rlm_query": self.rlm_query,
"rlm_query_batched": self.rlm_query_batched,
}
self.locals = {
"answer": AnswerDict(on_ready=self.capture_answer),
}
def add_context(self, payload, index: int = 0):
path = write_payload_to_temp_file(payload)
self.execute_code(f"context_{index} = read_from({path!r})")
if index == 0:
self.execute_code("context = context_0")
def execute_code(self, code: str):
self.pending_lm_calls = []
stdout, stderr = capture_stdout_stderr(lambda: exec(code, self.globals, self.locals))
final_answer = self.last_final_answer
self.last_final_answer = None
return REPLResult(stdout=stdout, stderr=stderr, locals=self.locals, final_answer=final_answer)这里的关键不是 sandbox 本身,而是变量命名和持久状态:context_0 / context 持有原 prompt,answer 是一个特殊 dict,llm_query 和 rlm_query 是模型能在代码里调用的函数。代码库还提供 LocalREPL、IPythonREPL、DockerREPL、E2BREPL、ModalREPL、PrimeREPL 等环境,以适配不同隔离和执行需求。
3.5 Recursive subcall:从 sub-LM 到 child RLM
def rlm_query(prompt: str, model: str | None = None) -> str:
if subcall_fn is None:
return llm_query(prompt, model)
completion = subcall_fn(prompt, model)
pending_lm_calls.append(completion)
return completion.response
def subcall(parent, prompt: str, model: str | None = None):
next_depth = parent.depth + 1
if next_depth >= parent.max_depth:
return direct_lm_completion(prompt, model=model)
child = RLM(
backend=parent.backend,
backend_kwargs=override_model(parent.backend_kwargs, model),
environment=parent.environment_type,
depth=next_depth,
max_depth=parent.max_depth,
max_iterations=parent.max_iterations,
max_budget=remaining_budget(parent),
max_timeout=remaining_timeout(parent),
custom_tools=parent.custom_sub_tools,
max_concurrent_subcalls=parent.max_concurrent_subcalls,
)
try:
result = child.completion(prompt, root_prompt=None)
parent.cumulative_cost += result.usage_summary.total_cost
return result
finally:
child.close()这对应论文的 symbolic recursion:在 REPL 内部可以在任意 Python 控制流中构造 prompt 并调用 rlm_query;若 max_depth 已到,则退化成普通 LM call。released code 还实现了 rlm_query_batched,用 bounded thread pool 并行多个独立 subcall,保持返回顺序稳定。
3.6 Prompt / history 设计
def build_rlm_prompt(system_prompt, query_metadata, root_prompt, iteration):
metadata = (
f"Your context is a {query_metadata.context_type} with "
f"{query_metadata.context_total_length} total characters, "
f"broken into chunks: {query_metadata.context_lengths}."
)
if iteration == 0:
user = "You have not interacted with the REPL yet; inspect the context first."
else:
user = "The history before is your previous REPL interactions. Continue."
if root_prompt:
user += f" Original prompt: {root_prompt}"
return [
{"role": "system", "content": system_prompt},
{"role": "user", "content": metadata},
{"role": "user", "content": user},
]released code 的 build_rlm_system_prompt 会把 context type、总字符数、分块长度写进 prompt;若 chunk 超过 100 个只展示前 100 个长度。build_user_prompt 首轮明确要求模型先操作 REPL,不要直接 final answer;后续轮次提醒模型历史是之前的 REPL 交互。
Code reference:
main@8467a580(2026-05-13) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| RLM 外部 text-to-text 接口 | rlm/core/rlm.py | RLM.completion |
| 单轮 LM→code→REPL 执行 | rlm/core/rlm.py | RLM._completion_turn |
| 递归子调用 / depth fallback | rlm/core/rlm.py | RLM._subcall |
| prompt 作为环境变量 | rlm/environments/local_repl.py | LocalREPL.load_context, LocalREPL.add_context |
| REPL 内 final answer 触发 | rlm/environments/local_repl.py | _AnswerDict, LocalREPL.execute_code |
| batched recursive subcalls | rlm/environments/local_repl.py | LocalREPL._rlm_query_batched |
| 系统提示和每轮 user prompt | rlm/utils/prompts.py | build_rlm_system_prompt, build_user_prompt |
| code block 解析与历史格式化 | rlm/utils/parsing.py | find_code_blocks, format_iteration, format_execution_result |
| 多后端 LM 客户端 | rlm/clients/ | OpenAIClient, AnthropicClient, GeminiClient, BaseLM |
| 多 sandbox 环境 | rlm/environments/ | LocalREPL, IPythonREPL, DockerREPL, E2BREPL, ModalREPL, PrimeREPL |
4. Experimental Setup (实验设置)
4.1 Datasets / tasks
| Dataset / Task | Scale | Metric / Output |
|---|---|---|
| S-NIAH | 50 single tasks;输入长度从 到 tokens | 找到特定 phrase / number;信息量相对长度为 |
| BrowseComp-Plus (1K documents) | 150 randomly sampled instances;每题给 1000 个随机文档,gold/evidence documents 保证存在;总输入 6M–11M tokens | answer correctness (%) |
OOLONG trec_coarse | 50 tasks;输入约 131K tokens | semantic labeling + aggregation;线性复杂度 |
| OOLONG-Pairs | 20 queries;输入约 32K tokens | answer list 的 F1;需要遍历 pair,近似二次复杂度 |
| LongBench-v2 CodeQA | 23K–4.2M token code repository understanding instances | multi-choice accuracy |
| LongCoT-mini | MATH / CHEM / CS / LOGIC / CHESS compositional reasoning | solve rate |
| LongBenchPro | 750 English tasks used for trajectory collection | 训练数据来源;收集 2250 candidate trajectories |
| MRCRv2 | train: 32K–64K token split with 2 needles;eval: 512K–1M token split with 8 needles | RLVR length generalization |
4.2 Baselines
主要比较 GPT-5、Qwen3-Coder-480B-A35B、Claude Opus 4.1 及其 task-agnostic scaffold:Base Model、CodeAct (+ BM25)、CodeAct (+ sub-calls)、Compaction agent、OpenCode、OpenCode (+ context offloading)、Claude Code、Claude Code (+ context offloading)、RLM(depth=0/1/2/3)。LongCoT-mini 额外比较 GPT-5.2 base、RLM(GPT-5.2, depth=1)、以及带 decomposition hints 的 RLM。
4.3 Training config
论文和 released repo 的边界需要明确:公开代码仓库 alexzhang13/rlm 是 inference library,当前 main@8467a580 未包含 RLM-Qwen3-8B / MRCRv2 的训练 launch script 或 config;因此下面训练数值来自论文 Appendix “Additional Training Details”,不是从 released repo 的训练配置复核得出。
RLM-Qwen3-8B SFT / rejection fine-tuning
- Teacher / source trajectories: RLM(Qwen3-Coder-480B-A35B-Instruct) on 750 English LongBenchPro tasks。
- Candidate trajectories: 2250。
- Filtering: 移除 score exactly 0.0 或不超过一轮的 trajectory 后剩 1072;再按 Qwen3-8B 约 100k characters context limit 去除过长 turns,并 programmatically 修正模板错误。
- Model / library: Qwen3-8B,
prime-rllibrary。 - Training: batch size 64,300 steps,48 H100 hours。
- Template issues reported by authors: 16% turns 错误使用 FINAL answers;13% turns 错误把 REPL variable (
FINAL_VAR) 当 final answer。
MRCRv2 RLVR training
- Model: Qwen3-4B-Instruct-0527 as RLM(depth=1)。
- Platform / library: Prime Intellect
Lab+prime-rl。 - Training split: 32K–64K tokens,2 needles。
- Steps / batch / rollouts: 150 steps,batch size 128,4 rollouts per example。
- Per-turn constraints: max output tokens 4096,max RLM iterations 20。
- Evaluation: every 50 steps starting from step 0;eval on 512K–1M tokens,8 needles。
5. Experimental Results (实验结果)
5.1 Main benchmark results
表 1 的分数如下;括号内是 average API cost standard deviation,N/A 表示论文未报告可比成本,* 表示方法有时遇到 input context limit。
| Model / Method | CodeQA | BrowseComp+ (1K) | OOLONG | OOLONG-Pairs |
|---|---|---|---|---|
| Task length | 23K–4.2M | 6M–11M | 131K | 32K |
| GPT-5 Base | 24.0* () | 0.0* (N/A) | 44.0 () | 0.1 () |
| GPT-5 CodeAct + BM25 | 22.0* () | 51.0 () | 38.0 () | 24.7 () |
| GPT-5 CodeAct + sub-calls | 24.0* () | 0.0* (N/A) | 40.0 () | 28.4 () |
| GPT-5 Compaction agent | 58.0 () | 70.5 () | 46.0 () | 0.1 () |
| GPT-5 OpenCode | 18.0* (N/A) | 0.0* (N/A) | 32.0 (N/A) | 3.1 (N/A) |
| GPT-5 OpenCode + context offloading | 64.0 (N/A) | 94.0 (N/A) | 52.0 (N/A) | 4.8 (N/A) |
| GPT-5 RLM depth=0 | 58.0 () | 88.0 () | 36.0 () | 43.9 () |
| GPT-5 RLM depth=1 | 62.0 () | 91.3 () | 56.0 () | 58.0 () |
| GPT-5 RLM depth=2 | 66.0 () | 92.0 () | 56.5 () | 65.5 () |
| GPT-5 RLM depth=3 | 58.0 () | 92.0 () | 58.0 () | 76.0 () |
| Qwen3-Coder Base | 20.0* () | 0.0* (N/A) | 36.0 () | 0.1 () |
| Qwen3-Coder CodeAct + BM25 | 24.0* () | 12.7 () | 38.0 () | 0.3 () |
| Qwen3-Coder CodeAct + sub-calls | 26.0* () | 0.0* (N/A) | 32.0 () | 0.1 () |
| Qwen3-Coder Compaction agent | 50.0 () | 38.0 () | 44.1 () | 0.31 () |
| Qwen3-Coder OpenCode | 12.0* (N/A) | 0.0* (N/A) | 36.0 (N/A) | 0.0 (N/A) |
| Qwen3-Coder OpenCode + context offloading | 40.0 (N/A) | 58.0 (N/A) | 24.0 (N/A) | 2.1 (N/A) |
| Qwen3-Coder RLM depth=0 | 66.0 () | 46.0 () | 43.5 () | 17.3 () |
| Qwen3-Coder RLM depth=1 | 56.0 () | 44.7 () | 48.0 () | 23.1 () |
| Qwen3-Coder RLM depth=2 | 54.0 () | 68.0 () | 26.0 () | 19.0 () |
| Qwen3-Coder RLM depth=3 | 44.0 () | 68.7 () | 32.0 () | 21.1 () |
| Claude Code | 12.0* () | 0.0* (N/A) | 40.2 () | 0.1 () |
| Claude Code + context offloading | 62.0 () | 84.0 () | 48.0 () | 6.5 () |
关键结论:RLM 在 10M+ token 输入上仍可工作。GPT-5 RLM(depth=1) 在 BrowseComp+ (1K) 平均成本 美元,优于 compaction 和 retrieval baseline 超过 ;在 OOLONG 上,GPT-5 / Qwen3-Coder 的 RLM(depth=1) 相对 base 分别提升 和 ;在 OOLONG-Pairs 上,base F1 都几乎为 ,而 RLM(depth=1) 分别达到 与 。
5.2 Main qualitative / ablation figures
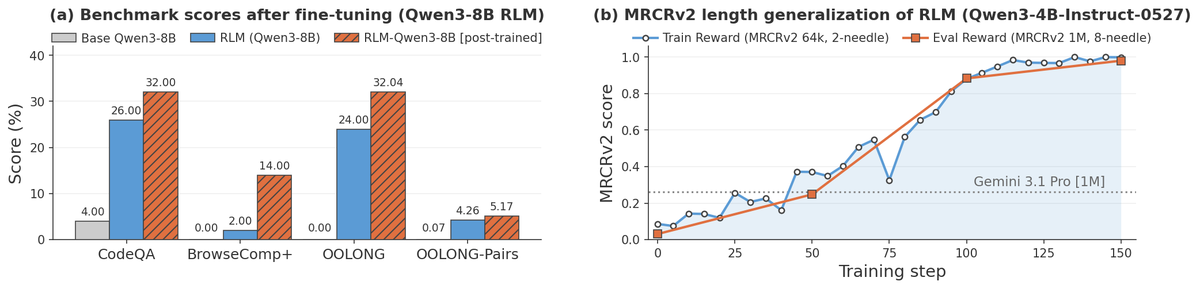
Figure 3 解读:Figure 3a 显示用 Qwen3-Coder-480B-A35B 的 RLM trajectories 对 Qwen3-8B 做 rejection fine-tuning 后,RLM-Qwen3-8B 在表 1 各任务上明显优于 base Qwen3-8B。Figure 3b 显示 MRCRv2 上用较短 32K–64K、2 needles split 做 RLVR 训练后,可以泛化到更长的 512K–1M、8 needles split;这支持“训练 root model 如何操作 REPL / 何时 subcall”具有跨长度迁移性。
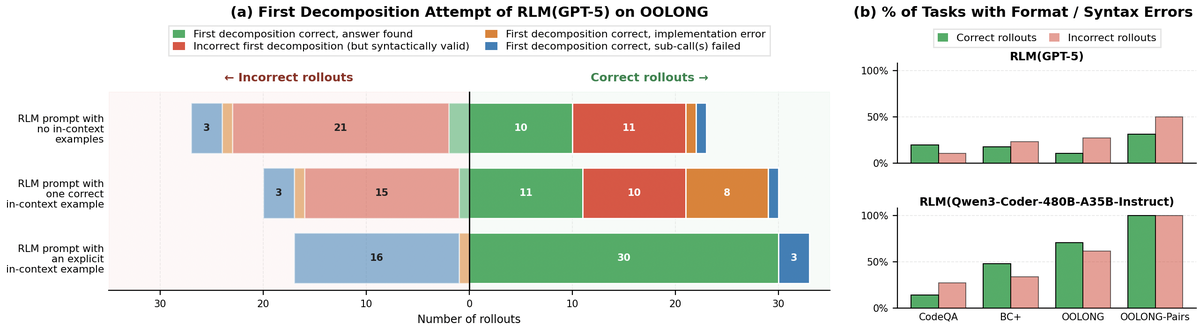
Figure 4 解读:Figure 4a 是 prompt example / decomposition pattern 的敏感性实验:即使示例任务和目标无关,给出 in-context RLM trajectory example 也能提升 OOLONG 上的初始 decomposition 质量和最终性能。Figure 4b 把 depth=1 的 runs 按 correct / incorrect 分桶统计 syntax error,显示 Qwen3-Coder trajectories 更常出现语法错误;这解释了为什么 Qwen3-Coder 的更高 recursion depth 平均反而可能更差,因为子 RLM 会传播 root 的代码错误。
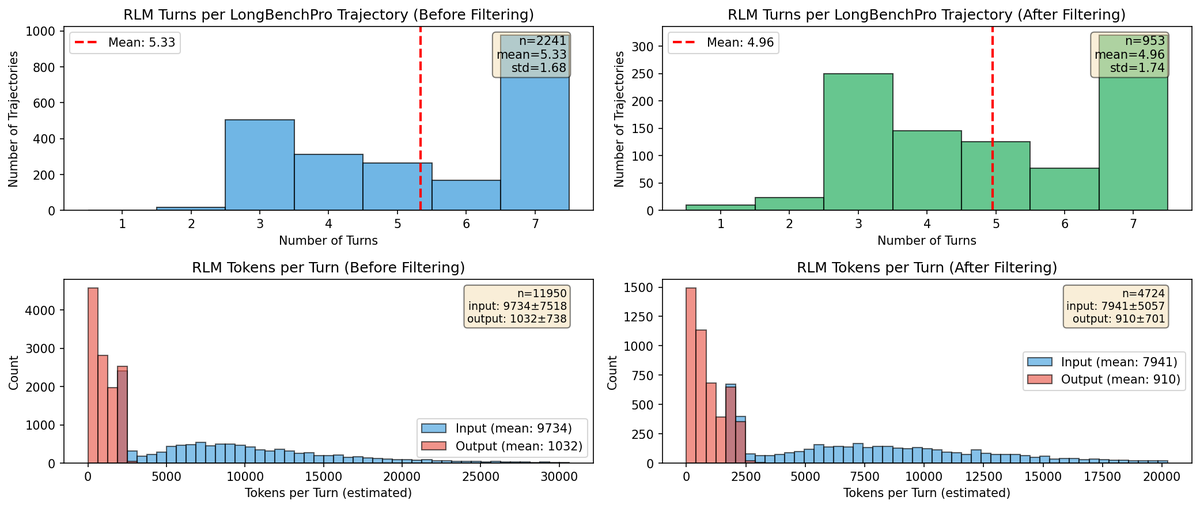
Figure 5 解读:Figure 5 展示 LongBenchPro trajectory filtering 前后的数据分布。过滤逻辑不是简单随机采样,而是去掉 0 分、单轮、超过 Qwen3-8B 约 100k characters 的 turns,并修复常见模板错误;这说明 RLM-Qwen3-8B 的提升很大程度来自让小模型学会 root RLM 的操作规范。
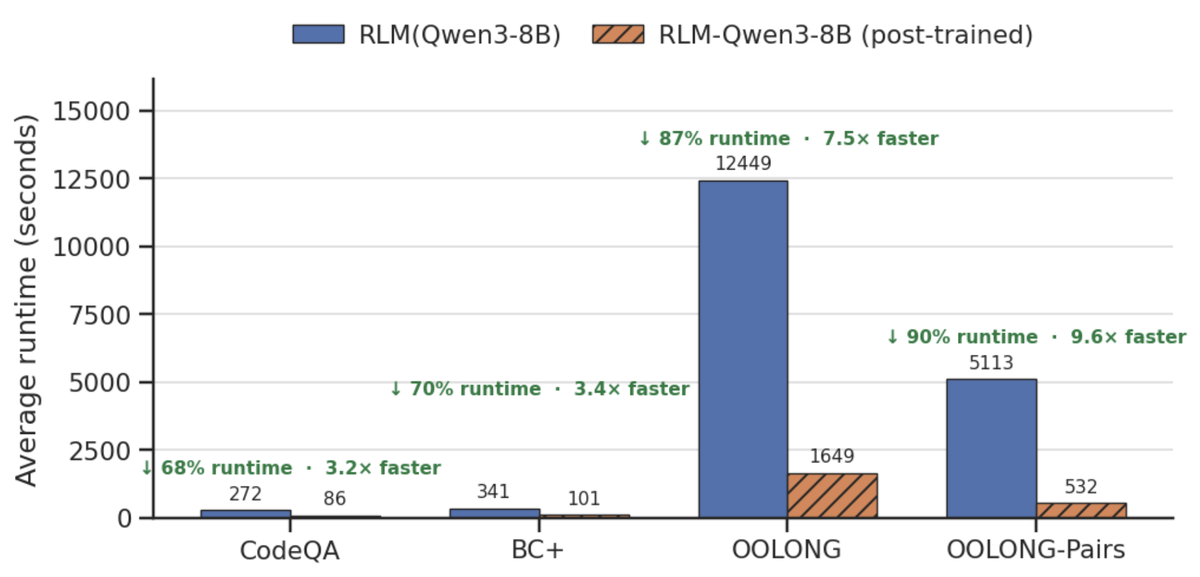
Figure 6 解读:Figure 6 说明 post-trained RLM-Qwen3-8B 不只是得分更好,也更高效:它在 trajectory 中更少走错方向、减少无效调用,因此运行时间相对 base Qwen3-8B as RLM 明显下降。论文称整体超过 更快。
5.3 LongCoT-mini:递归接口也提升长推理
| Model | Overall | MATH | CHEM | CS | LOGIC | CHESS |
|---|---|---|---|---|---|---|
| GPT-5.2 (base) | 38.7 | 26.0 | 37.0 | 40.4 | 53.6 | 36.6 |
| RLM (GPT-5.2, depth=1) | 50.6 | 5.6 | 50.0 | 11.0 | 86.7 | 93.0 |
| RLM (GPT-5.2, depth=1) + decomposition hints | 65.6 | 32.0 | 52.0 | 46.0 | 99.0 | 99.0 |
LongCoT-mini 结果说明 RLM 不只是“长文档读取器”:当 prompt 内包含相互依赖的 compositional subproblems 时,REPL + subcall 可以把问题显式图结构化,按节点递归求解,再程序化遍历整张 reasoning graph。带 decomposition hints 后 overall 从 38.7 提到 65.6,相对提升 。
5.4 Appendix quantitative figures
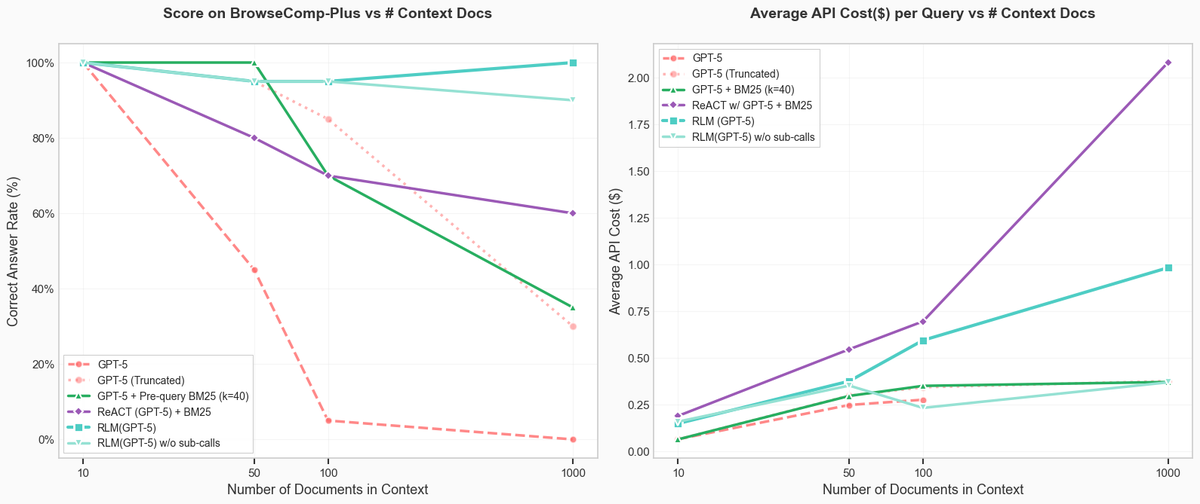
Figure 7 解读:Figure 7 在 BrowseComp-Plus 的 20 个随机 query 上扩展文档数量。RLM(GPT-5) 是唯一能在 1000-document scale 维持 perfect performance 的方法;no-recursion ablation 也能达到约 ,说明“context as environment”本身已很强,而 recursion 进一步增强高难检索和聚合。

Figure 8 解读:Figure 8 汇总 RLM trajectories 的常见模式:使用 regex 过滤上下文、把上下文分解成可递归调用的子问题、以及在长输出任务中把多个 sub-LM outputs stitch 成最终输出。这些行为对应 RLM 的三项关键能力:符号句柄、代码控制流、递归调用。
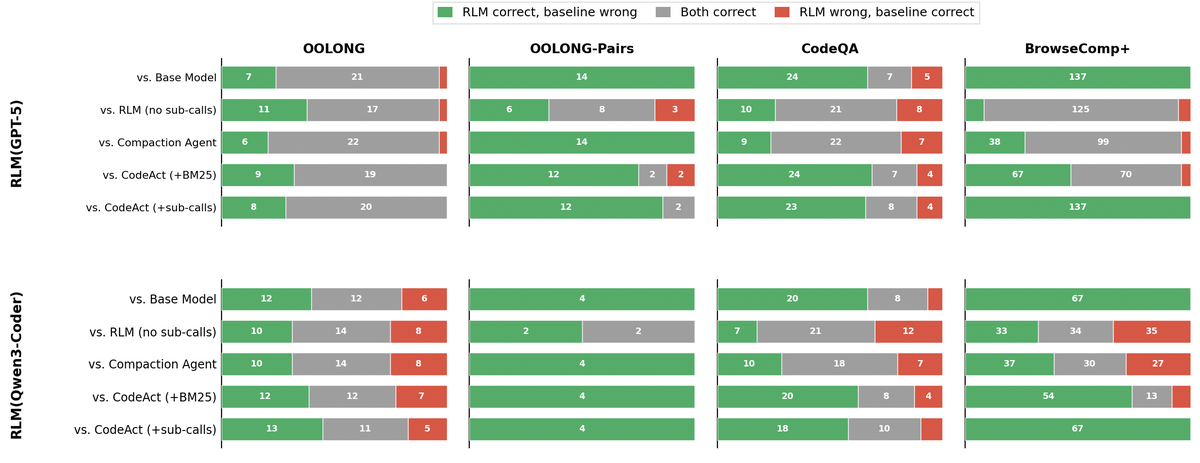
Figure 9 解读:Figure 9 把表 1 中 RLM(depth=1) 与各 baseline 的成功集合做交集分析:绿色表示只有 RLM 答对、灰色表示都答对、红色表示只有 baseline 答对。该图支持论文的观察:RLM 不是只解决同一批容易样本,而是在多个任务上覆盖了 baseline 没覆盖的样本。
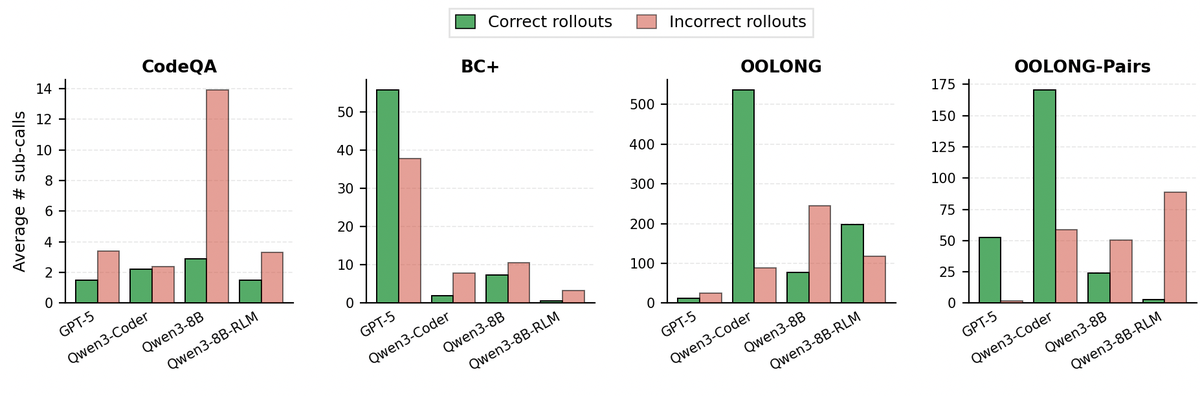
Figure 10 解读:Figure 10 展示不同任务、不同模型在正确/错误 rollout 中的平均 subcall 数。RLM 的计算不是固定模板,而是随任务和模型策略变化;正确答案不一定意味着更多 subcall,错误 rollout 也可能出现过度调用,说明 decomposition policy 本身是未来训练的重要对象。
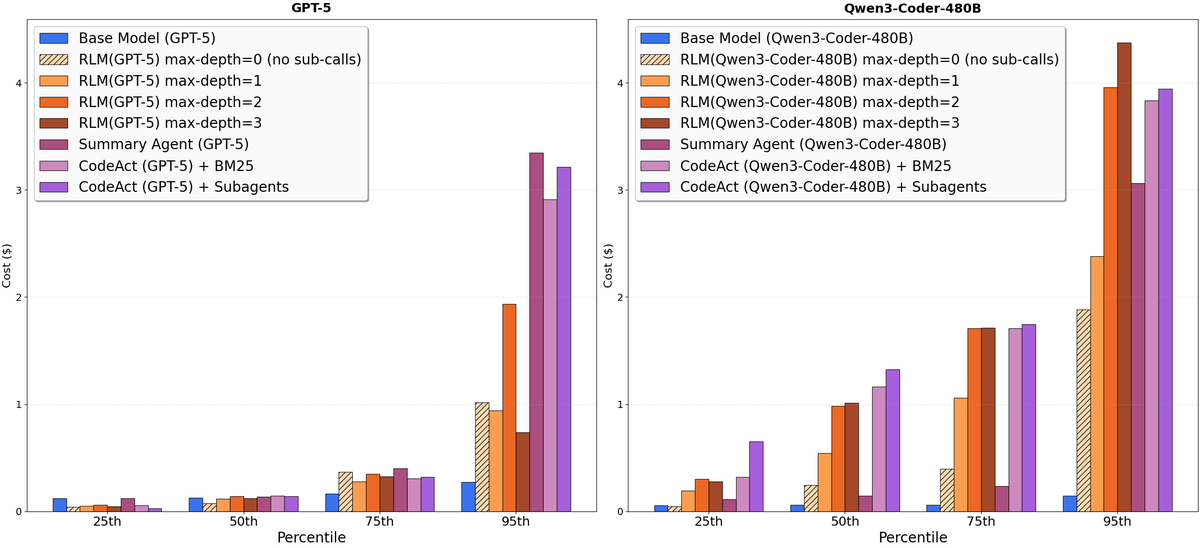
Figure 11 解读:Figure 11 用 25/50/75/95 percentile 展示 API cost 分布。论文的关键结论是 median RLM run 可以比 median base run 更便宜,但 tail cost 会因少量长 trajectory 明显上升;因此 RLM 的部署风险主要在 outlier 控制,而非平均成本。
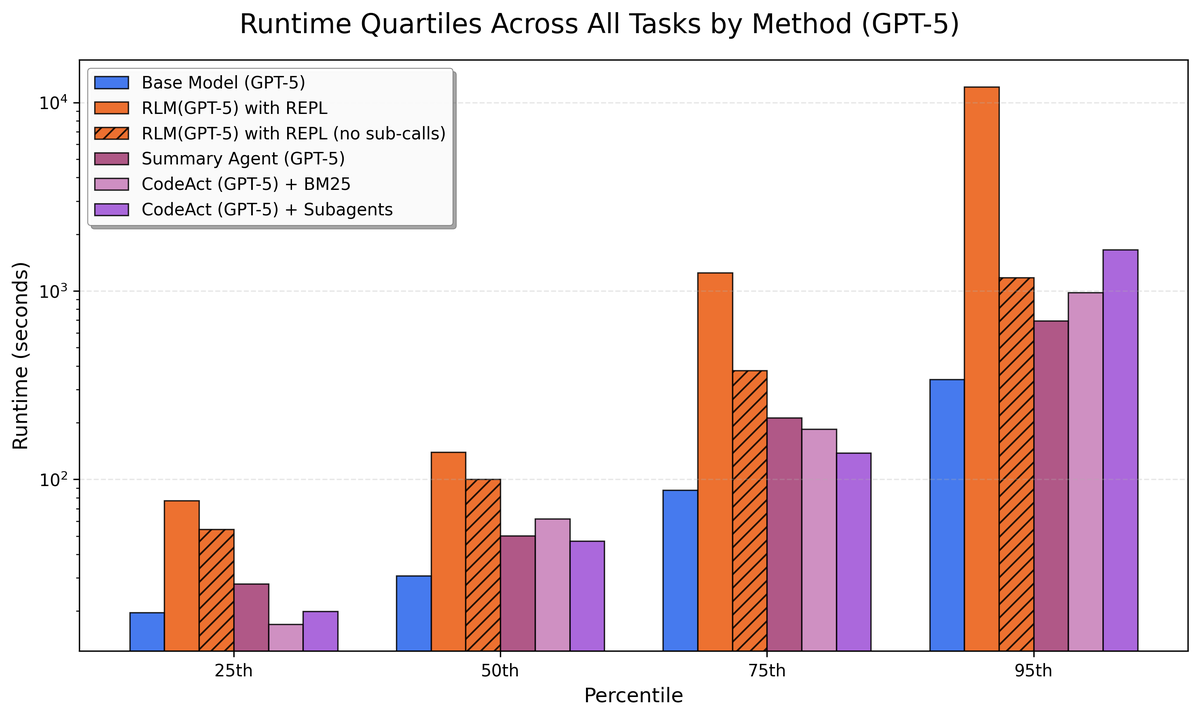
Figure 12 解读:Figure 12 展示 GPT-5 相关方法的 runtime quartiles。runtime 与 API cost 不完全等价,受实现、并发、顺序 sub-LM calls 影响较大;95th percentile 的长尾主要来自 RLM trajectory 中顺序子调用耗时。
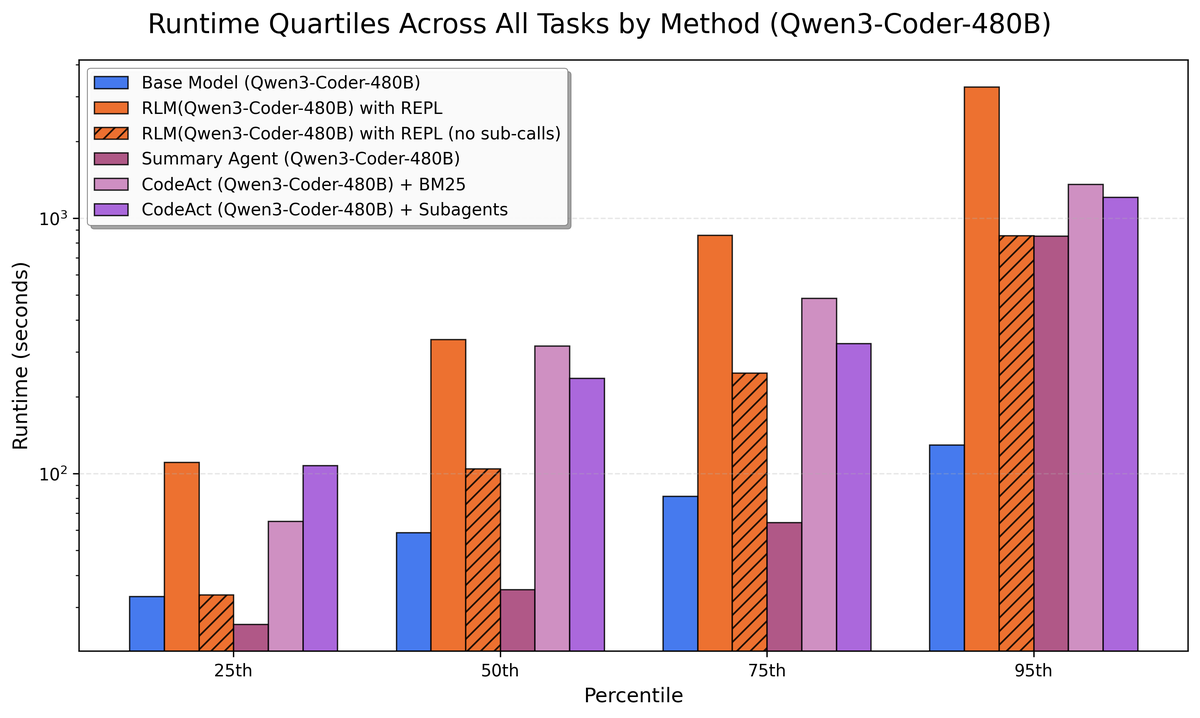
Figure 13 解读:Figure 13 对 Qwen3-Coder-480B-A35B-Instruct 展示同样的 runtime quartiles。与 Figure 12 一样,它提醒读者:RLM 的质量收益依赖模型写代码和分解任务的稳定性;当模型更容易出现 syntax/runtime error 时,高 recursion depth 可能放大失败。
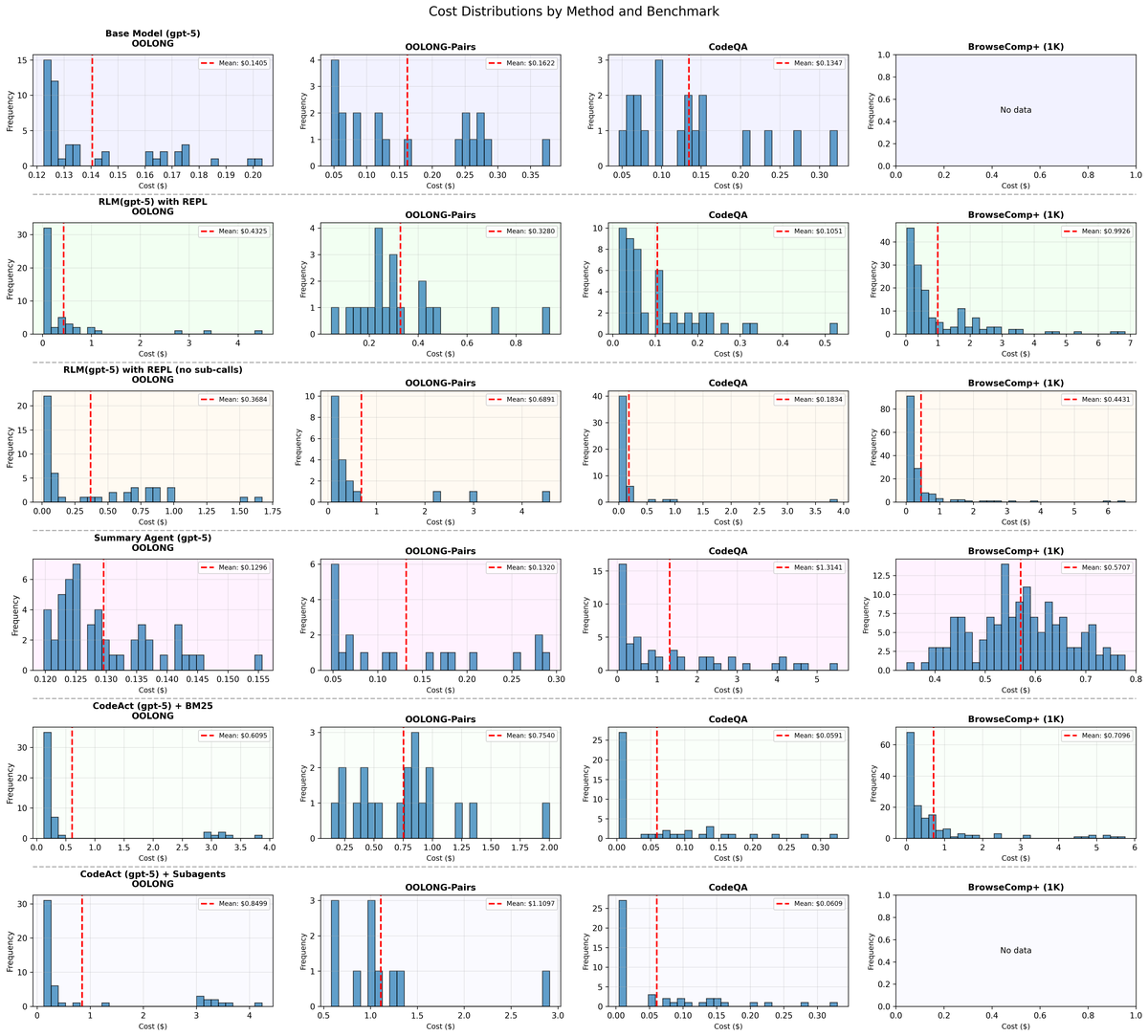
Figure 14 解读:Figure 14 是 GPT-5 各方法 API cost histogram,用于观察平均数背后的分布形态。RLM 有较多低成本成功案例,也有少数高成本探索轨迹;这与 Figure 11 的 tail-cost 结论一致。
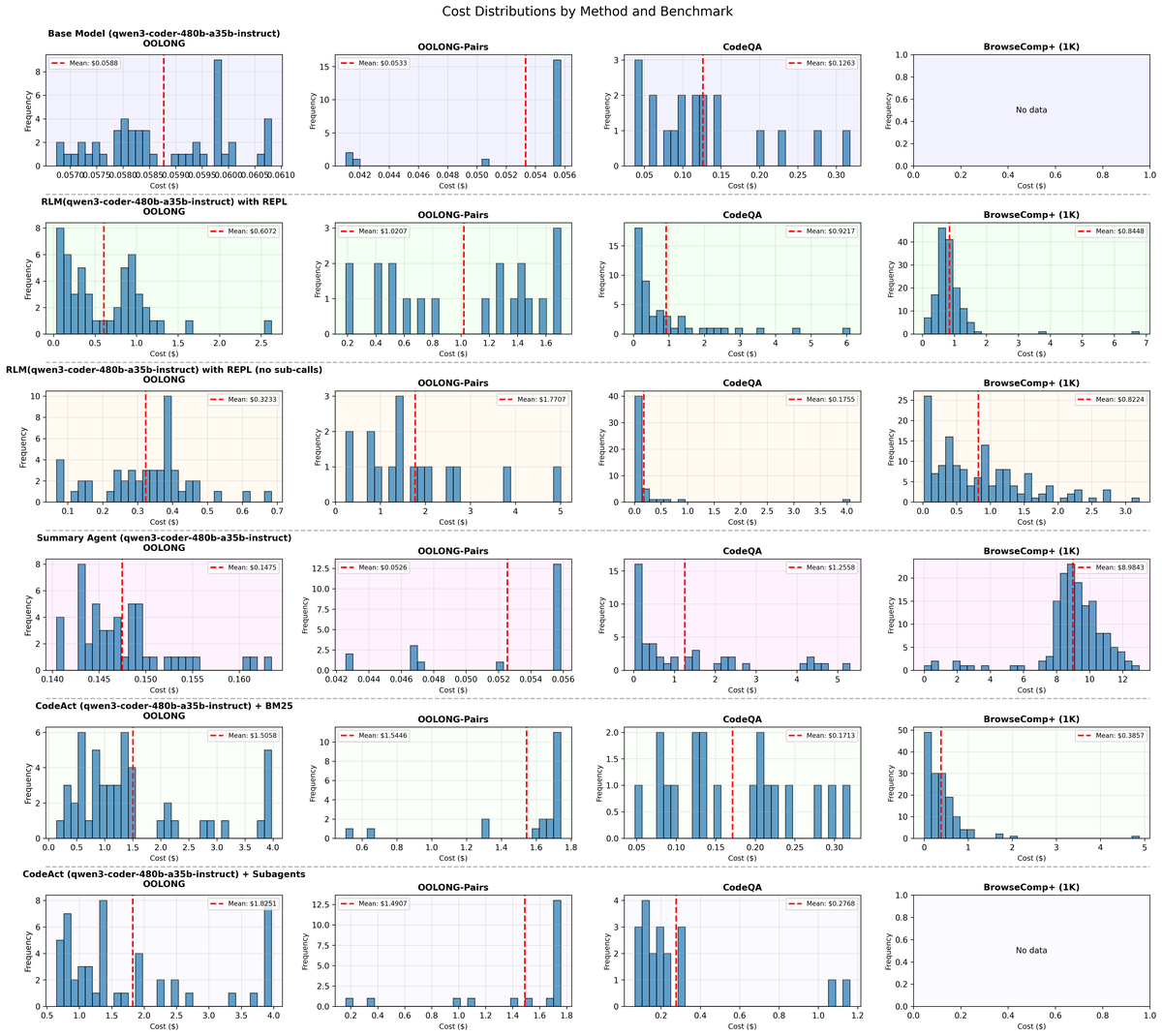
Figure 15 解读:Figure 15 是 Qwen3-Coder 各方法 API cost histogram。相较 GPT-5,Qwen3-Coder 的代码执行错误和递归策略不稳定性会影响成本分布,因此论文在结果中也指出 Qwen3-Coder 的 depth>1 平均效果并不单调变好。
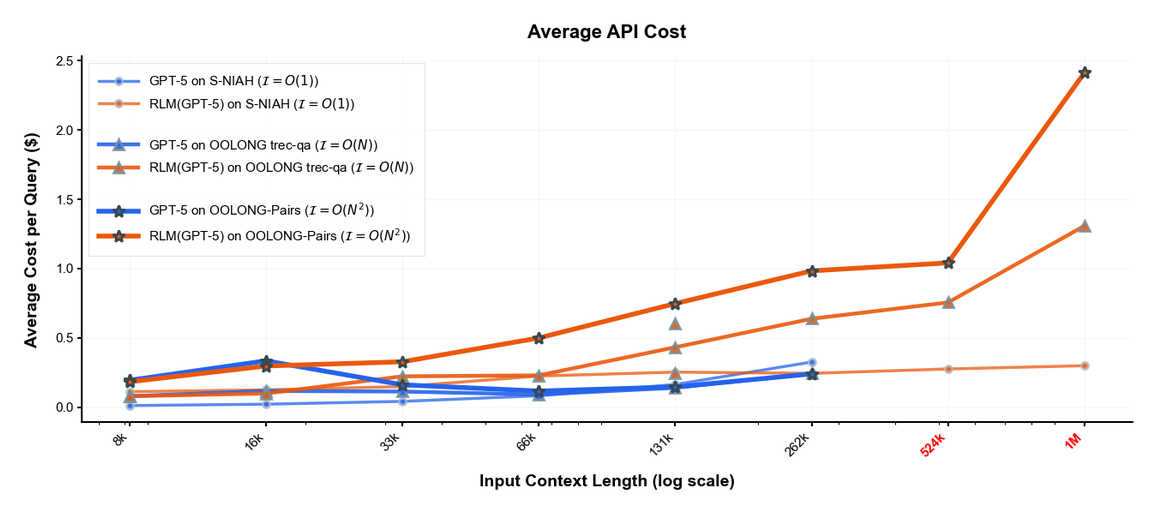
Figure 16 解读:Figure 16 给出 Figure 1 scaling runs 的 API cost。它补充说明 RLM 在超长输入下不是通过把全部 token 发给 API 来“硬买上下文”,而是用 REPL 读取和递归子调用把成本与任务复杂度绑定。
5.5 Limitations
作者明确承认两类限制。第一,当前评估还需要更多更自然、更困难的长上下文任务,尤其是需要保证 correct-by-construction 或 safety 的场景;RLM 把更多控制权交给模型写代码和调用子模型,错误控制机制仍不充分。第二,训练只给出了小规模初步证据:RLM-Qwen3-8B 和 MRCRv2 RLVR 说明 native RLM 训练有潜力,但要最大化效果,未来需要更大模型、更多样的 examples、更多 on-policy / online rollouts,以及更系统的 decomposition policy 学习。