Let ViT Speak: Generative Language-Image Pre-training
1. Motivation (研究动机)
当前 MLLM 的视觉侧通常由「vision encoder + connector + LLM」组成,视觉编码器决定了下游 LLM 能拿到的视觉信息上限。主流 VLP 路线有两个关键错位:CLIP/SigLIP 这类 dual-encoder 用 contrastive objective 学全局判别式对齐,但 MLLM 最终按 next-token prediction 工作;CapPa、AIMv2、OpenVision2 这类 generative VLP 又通常把 vision encoder 接到额外 text decoder 上,通过 decoder 间接优化视觉编码器,结构和训练目标都更复杂。
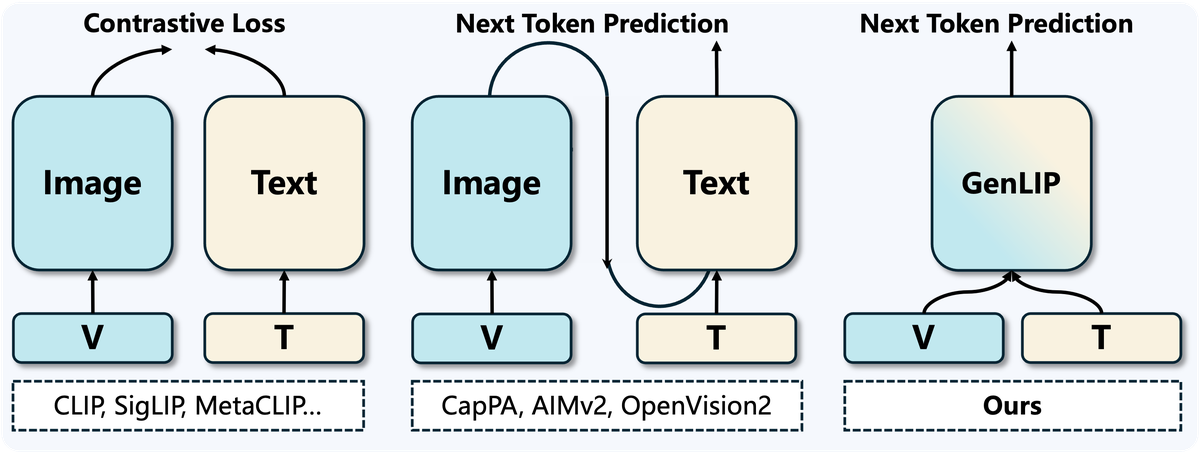 Figure 1 解读:论文用这张对比图把问题说得很直观:contrastive 方法需要图像塔和文本塔,generative encoder-decoder 方法需要视觉编码器外加文本解码器,而 GenLIP 只保留一个 Transformer,把 visual tokens 放在前缀、text tokens 放在后面,直接用语言建模目标训练视觉 backbone。
Figure 1 解读:论文用这张对比图把问题说得很直观:contrastive 方法需要图像塔和文本塔,generative encoder-decoder 方法需要视觉编码器外加文本解码器,而 GenLIP 只保留一个 Transformer,把 visual tokens 放在前缀、text tokens 放在后面,直接用语言建模目标训练视觉 backbone。
本文要解决的具体问题是:能否把 ViT 本身训练成一个更贴近 LLM 生成范式的视觉编码器,使它直接从图像 patch tokens 预测 caption tokens,而不依赖 contrastive batch construction、text encoder 或额外 text decoder。这个问题值得做,是因为若视觉编码器在预训练阶段就以 autoregressive language modeling 方式对齐文本,下游接入 MLLM 时可能更自然、更可扩展,也能减少大规模 VLP 中多塔结构带来的工程复杂度。
2. Idea (核心思想)
GenLIP 的核心洞察是:让 ViT 自己“说话”。也就是说,不把 ViT 当成只输出视觉 embedding 的判别式模块,而是把图像 patch 作为 prefix,让同一个 Transformer 直接预测文本 token;训练信号仍然是最普通的 next-token loss,但 loss 只落在文本 token 上。
关键创新可以概括为三点:第一,单 Transformer 同时处理视觉 token 和文本 token;第二,用 Prefix-LM attention 让视觉 token 内部双向可见、文本 token 对文本因果可见,同时文本可看见视觉前缀;第三,为解决 mixed-modality full/prefix attention 中的 attention sink,加入 gated attention,避免少数视觉 token 吸走过多注意力。
与 SigLIP2 这类「contrastive + generative」混合路线相比,GenLIP 不需要额外 text encoder/decoder,也没有 contrastive loss;与 OpenVision2 这类 encoder-decoder generative VLP 相比,GenLIP 不是通过 decoder 间接优化 vision encoder,而是把 ViT 自身放在语言建模路径里直接更新。
3. Method (方法)
Overall framework. GenLIP 的输入样本是 image-caption pair 。图像 被 convolutional patch embedding 切成 ,文本 用 Qwen3 tokenizer 切成 ,最终拼成:
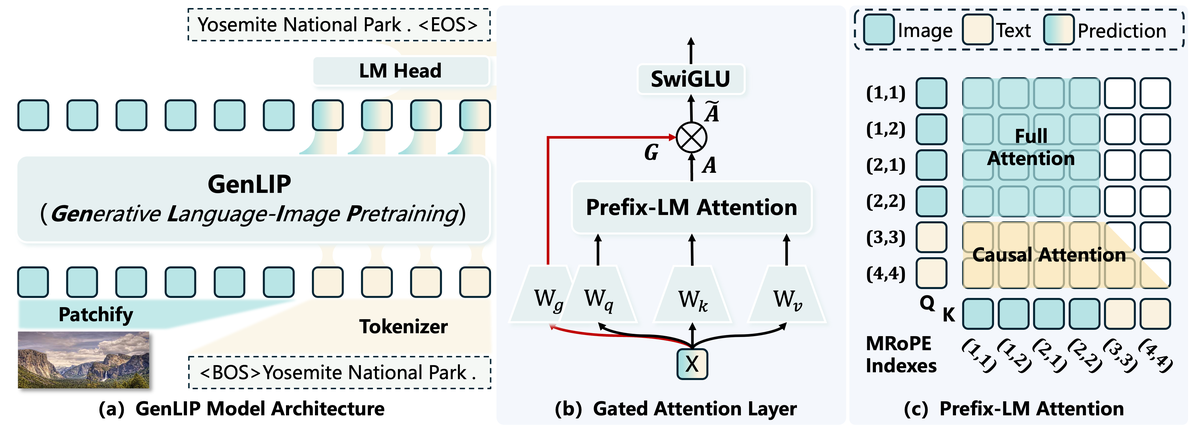 Figure 2 解读:论文图 2 是方法主图。(a) 展示单 Transformer 接收 visual-prefix sequence,并只在 text tokens 上做 next-token prediction;(b) 展示 gated attention 的 gate 分支由输入 hidden states 产生 gating signals,再与 attention output 逐元素相乘;(c) 展示 Prefix-LM mask:image tokens 之间双向 attention,text tokens 只能因果看文本历史,但能访问视觉前缀,MRoPE 注入时空/二维位置。
Figure 2 解读:论文图 2 是方法主图。(a) 展示单 Transformer 接收 visual-prefix sequence,并只在 text tokens 上做 next-token prediction;(b) 展示 gated attention 的 gate 分支由输入 hidden states 产生 gating signals,再与 attention output 逐元素相乘;(c) 展示 Prefix-LM mask:image tokens 之间双向 attention,text tokens 只能因果看文本历史,但能访问视觉前缀,MRoPE 注入时空/二维位置。
Key components. 第一,GenLIPVisionEmbeddings 用 Conv2d(kernel_size=patch_size, stride=patch_size) 产生 patch embeddings;固定分辨率阶段输出 [B, H*W, D],NaViT 阶段也支持按 image_grid_thw 处理 variable-resolution tokens。第二,GenLIPModel.forward 先对 input_ids 做 text embedding,再用 image_mask 把 image placeholder 位置替换成视觉 embedding,随后生成 MRoPE position embeddings 并送入 GenLIPEncoder。第三,loss 只对 labels 中非 IGNORE_INDEX=-100 的 token 生效;代码里非 sequence-parallel 路径会做标准 shift:labels = labels[..., 1:],logits = logits[..., :-1, :],再 CrossEntropyLoss(ignore_index=-100)。
Prefix-LM objective. 论文目标函数是:
直觉上,GenLIP 把“看图说话”变成视觉编码器自己的预训练任务:如果某个视觉 patch 对 caption 预测有用,它就必须在同一个 Transformer 内被组织成可被后续 text token 使用的表示;这比先用 contrastive loss 做全局对齐、再指望 connector/LLM 学会细节要更直接。Prefix-LM mask 又保留了 ViT 需要的视觉双向建模,使视觉前缀不是退化成单向文本序列。
Gated attention. GenLIP 观察到 mixed-modality prefix 序列会出现 attention sink:少数开头视觉 token 成为信息捷径,文本 token 过度依赖这些 sink tokens,导致视觉表征空间多样性下降和训练 loss spike。论文引入 per-token gate:
其中 , 调制 attention output 后进入 residual pathway。
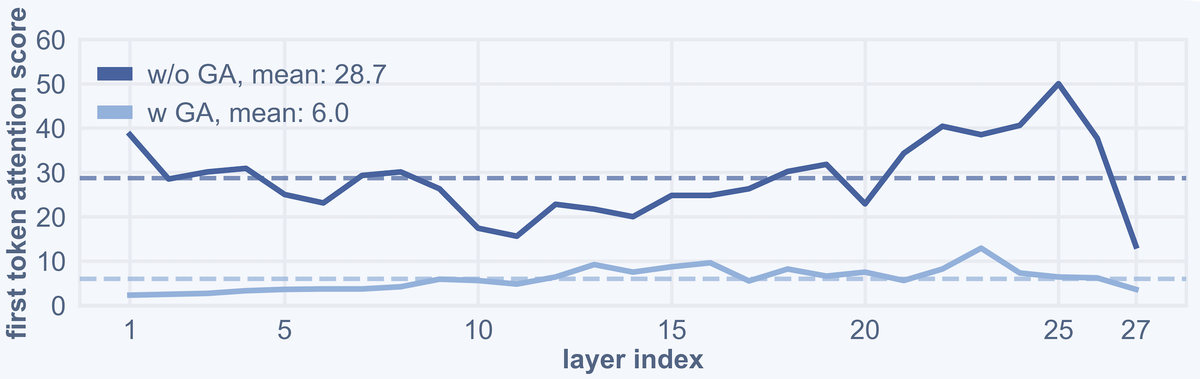 Figure 3 解读:图 3 展示第一 token 的 attention sink 现象。没有 gated attention 时,第一个 token 吸收大量注意力;加入 gate 后,attention output 被逐 token 调制,模型更难把视觉信息压缩到少数 sink token,从而更有利于空间分散的视觉表征。
Figure 3 解读:图 3 展示第一 token 的 attention sink 现象。没有 gated attention 时,第一个 token 吸收大量注意力;加入 gate 后,attention output 被逐 token 调制,模型更难把视觉信息压缩到少数 sink token,从而更有利于空间分散的视觉表征。
Two-stage pretraining. Stage 1 在 Recap-DataComp-1B 上以固定 训练 8B samples(8 epochs over 1B unique image-text samples)。Stage 2 用 BLIP3o-Long-Caption 的 27M 和 Infinity-MM-Stage1 的 10M,共 37M 高分辨率长 caption 数据,按 native aspect ratio 处理,把视觉 token 数控制在 ,只训练 1 epoch。部署为 MLLM vision encoder 时,丢弃 tokenizer 和 LM head,保留视觉 backbone,从最后一层 Transformer 后的 LN 输出抽视觉 features,再接 2-layer MLP projector 到 LLM。
Pseudocode 1 — 数据样本构造(对应 process_sample + Qwen2VLPretrainTemplate)
import torch
from PIL import Image
IGNORE_INDEX = -100
IMAGE_INPUT_INDEX = -200
def build_genlip_example(sample, processor, chat_template, max_len=16384):
image = Image.open(sample["jpg"]).convert("RGB")
image_inputs = processor.image_processor(
images=[image], input_data_format="channels_last", return_tensors="pt"
)
num_patches = int(image_inputs["image_grid_thw"].prod().item())
conversations = [
["user", ("image", None), ("text", "Describe the image in detail.")],
["assistant", ("text", sample["json"]["caption"])],
]
tokenized = chat_template.encode_messages(
conversations, {"image": [num_patches]}, no_special_tokens=True
)
image_mask = tokenized["input_ids"] == IMAGE_INPUT_INDEX
assert int(image_mask.sum()) == num_patches
tokenized["position_ids"] = get_position_ids(
image_mask=image_mask.unsqueeze(0), image_grid_thw=image_inputs["image_grid_thw"]
).squeeze()
tokenized["flex_indicators"] = torch.zeros_like(tokenized["input_ids"])
tokenized["flex_indicators"][image_mask] = 1
tokenized["input_ids"][image_mask] = 0
return constraint_max_len(tokenized | image_inputs, max_len=max_len)Pseudocode 2 — Prefix-LM mask(对应 _create_single_modality_attn_mask / get_hybrid_attn_mask)
import torch
def prefix_lm_attention_mask(image_mask: torch.Tensor) -> torch.Tensor:
# image_mask: [batch, seq], True for image tokens.
bsz, seq_len = image_mask.shape
is_image = image_mask.int()
segment_change = torch.diff(torch.cat([torch.zeros(bsz, 1, device=image_mask.device, dtype=is_image.dtype), is_image], dim=-1), dim=-1)
segment_ids = torch.cumsum((segment_change != 0).int(), dim=-1)
pair_ids = (segment_ids + 1) // 2
same_pair = pair_ids[:, :, None] == pair_ids[:, None, :]
image_to_image = same_pair & image_mask[:, None, :]
text_q = ~image_mask[:, :, None]
text_k = ~image_mask[:, None, :]
causal = torch.tril(torch.ones(seq_len, seq_len, dtype=torch.bool, device=image_mask.device))[None]
text_to_text = same_pair & text_q & text_k & causal
hybrid = image_to_image | text_to_text
last_pair = pair_ids[:, -1].unsqueeze(1)
hybrid[:, -1, :] = hybrid[:, -1, :] | (pair_ids == last_pair)
return hybridPseudocode 3 — Gated attention(对应 GenLIPAttention.forward)
import torch
import torch.nn.functional as F
class GatedSelfAttention(torch.nn.Module):
def __init__(self, dim, num_heads):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.q_proj = torch.nn.Linear(dim, dim * 2) # q and gate_score
self.k_proj = torch.nn.Linear(dim, dim)
self.v_proj = torch.nn.Linear(dim, dim)
self.out_proj = torch.nn.Linear(dim, dim)
def forward(self, x, attn_mask, rope):
bsz, seqlen, dim = x.shape
q, gate = self.q_proj(x).chunk(2, dim=-1)
q = q.view(bsz, seqlen, self.num_heads, self.head_dim).transpose(1, 2)
k = self.k_proj(x).view(bsz, seqlen, self.num_heads, self.head_dim).transpose(1, 2)
v = self.v_proj(x).view(bsz, seqlen, self.num_heads, self.head_dim).transpose(1, 2)
q, k = apply_mrope(q, k, rope)
score = (q @ k.transpose(-1, -2)) * (self.head_dim ** -0.5)
score = score.masked_fill(~attn_mask[:, None], torch.finfo(score.dtype).min)
out = (F.softmax(score.float(), dim=-1).to(v.dtype) @ v).transpose(1, 2)
out = out * torch.sigmoid(gate.view(bsz, seqlen, self.num_heads, self.head_dim))
return self.out_proj(out.reshape(bsz, seqlen, dim))Pseudocode 4 — GenLIP forward/loss(对应 GenLIPModel.forward)
import torch
import torch.nn.functional as F
class GenLIPForward(torch.nn.Module):
def forward(self, input_ids, pixel_values, image_mask, image_grid_thw, labels=None):
input_embeds = self.in_proj(self.embeddings(input_ids))
image_embeds = self.vision_embeddings(pixel_values.to(self.lm_head.weight.dtype), image_grid_thw)
input_embeds = input_embeds.masked_scatter(
image_mask[..., None].expand_as(input_embeds), image_embeds
)
attn_mask = self.get_hybrid_attn_mask(image_mask=image_mask)
position_ids = self.get_position_id_func()(input_ids=input_ids, image_grid_thw=image_grid_thw)["position_ids"]
rope = self.rotary_emb(input_embeds, position_ids)
hidden, _ = self.visual(input_embeds, attention_mask=attn_mask, position_embeddings=rope)
hidden = self.proj(self.ln_post(hidden))
logits = self.lm_head(hidden)
if labels is None:
return {"logits": logits}
loss = F.cross_entropy(
logits[:, :-1].contiguous().view(-1, logits.size(-1)).float(),
labels[:, 1:].contiguous().view(-1),
ignore_index=IGNORE_INDEX,
)
return {"loss": loss, "logits": logits}Pseudocode 5 — Stage-2 native aspect ratio resize(对应 veomni/models/transformers/genlip/image_processor.py 的 module-level smart_resize)
import math
def smart_resize(height: int, width: int, factor: int = 16, min_pixels: int = 4096, max_pixels: int = 262144):
if max(height, width) / min(height, width) > 200:
raise ValueError("absolute aspect ratio must be smaller than 200")
h_bar = round(height / factor) * factor
w_bar = round(width / factor) * factor
if h_bar * w_bar > max_pixels:
beta = math.sqrt((height * width) / max_pixels)
h_bar = max(factor, math.floor(height / beta / factor) * factor)
w_bar = max(factor, math.floor(width / beta / factor) * factor)
elif h_bar * w_bar < min_pixels:
beta = math.sqrt(min_pixels / (height * width))
h_bar = math.ceil(height * beta / factor) * factor
w_bar = math.ceil(width * beta / factor) * factor
return h_bar, w_barCode reference:
main@07ee8288(2026-05-04) — pseudocode and mapping based on this commit; verified withgh api repos/YanFangCS/GenLIP/commits/HEAD.
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| 单 Transformer GenLIP backbone | veomni/models/transformers/genlip/genlip_modeling.py | GenLIPConfig, GenLIPModel, GenLIPEncoder, GenLIPVisionEmbeddings |
| Patch embedding + image placeholder replacement | veomni/models/transformers/genlip/genlip_modeling.py | GenLIPVisionEmbeddings.forward, GenLIPModel.forward |
| Prefix-LM / hybrid attention mask | tasks/train_genlip_stage1.py, veomni/models/transformers/genlip/genlip_modeling.py | _create_single_modality_attn_mask, get_hybrid_attn_mask |
| Gated attention | veomni/models/transformers/genlip/genlip_modeling.py | GenLIPAttention.forward, GenLIPSdpaAttention.forward |
| MRoPE / 3D position ids | tasks/train_genlip_stage1.py, tasks/train_genlip_navit.py, veomni/models/transformers/genlip/genlip_modeling.py | get_position_ids, get_rope_index, GenLIPRotaryEmbeddings |
| Caption sample preprocessing | veomni/data/multimodal/preprocess.py, veomni/data/multimodal/multimodal_chat_template.py | recap_datacomp_1b_preprocess, mmpretrain_mixed_preprocess, Qwen2VLPretrainTemplate.encode_messages |
| Stage-1 fixed-resolution training | tasks/train_genlip_stage1.py, configs/pretrain/genlip/stage1/*.yaml | process_sample, main, train_genlip_*_224_recap.yaml |
| Stage-2 NaViT/native aspect adaptation | tasks/train_genlip_navit.py, veomni/models/transformers/genlip/image_processor.py, configs/pretrain/genlip/stage2/*.yaml | process_sample, GenLIPNaViTImageProcessor, smart_resize |
| Training loop / LM loss backprop | tasks/train_genlip_stage1.py, tasks/train_genlip_navit.py | micro-batch loop calling model(**micro_batch).loss, loss.backward() |
4. Experimental Setup (实验设置)
| Item | Exact setup |
|---|---|
| Pretraining datasets | Stage 1: Recap-DataComp-1B, 1.0B unique image-text samples, trained for 8.0B samples at ; Stage 2: BLIP3o-Long-Caption 27M + Infinity-MM-Stage1 10M, total 37M samples, AnyRes/native aspect ratio, visual patches, 1 epoch. |
| Model scales | 论文表 1 报告:GenLIP-L 0.3B / 24 layers / dim 1024 / 16 heads / FFN width 2816;GenLIP-So 0.4B / 27 layers / dim 1152 / 16 heads / FFN width 3072;GenLIP-g 1.1B / 40 layers / dim 1536 / 24 heads / FFN width 4096。源码锚点 main@07ee8288 的 released configs 与论文表存在可见差异:configs/model_configs/genlip/genlip_l16_224.json 为 hidden_size=1152, intermediate_size=2752, text_embed_dim=1024,configs/model_configs/genlip/genlip_g16_224.json 为 num_attention_heads=16;本笔记实验数值按论文表记录,代码伪代码/映射按实际 repo 记录。 |
| Baselines | Contrastive: CLIP, SigLIP, SigLIP2; generative: AIMv2, OpenVision2; standard LLaVA-NeXT comparison also includes MLCD and RICE-ViT. |
| Frozen evaluation protocol | LLaVA-NeXT framework; frozen vision encoder; 2-layer MLP projector; LLM backbones Qwen2.5-1.5B-Instruct and Qwen2.5-7B-Instruct; SFT data replaced by LLaVA OneVision, more than 3M SFT samples. |
| Benchmarks / metrics | Doc&OCR: ChartQA, OCRBench, DocVQA, TextVQA, AI2D, InfoVQA, SEED-Bench-2-Plus; General VQA: VQAv2, GQA, ScienceQA, MME-P; Caption: NoCaps, COCO, TextCaps, reported by CIDEr. MME-P is divided by 2000 and mapped to before ALL AVG. |
| Training hyperparameters | AdamW; , ; peak LR in Stage 1 and in Stage 2; min LR ; cosine decay; warmup ratio 0.007 for L/16 and So/16, 0.02 for g/16; gradient clipping 1.0; max packing length 16,384; Stage-1 batch size 32K for L/16/So16 and 48K for g/16; Stage-2 global batch size 3.6K; layer scale 0.1; drop path 0.1/0.1/0.2; vocab size 151,936; RoPE theta 10,000. |
| Hardware | 论文未详细说明 GPU type/count;官方 repo configs 显示训练实现使用 FSDP1、mixed precision、gradient checkpointing、micro-batch size 16、PyTorch flex-attention。 |
直接生成能力的 probe 设置也有明确细节:prompt 为 “Describe the image in details.”,temperature=,top,最多 256 new tokens,无 beam search,遇到 EOS 停止。
5. Experimental Results (实验结果)
Frozen visual representation 主结果. GenLIP 用 8.0B pretraining samples 对比 SigLIP2 的 40.0B 数据,在同尺度下总体平均分更高,尤其 Doc&OCR 更强。
| Setting | Scale | SigLIP2 ALL AVG | GenLIP ALL AVG |
|---|---|---|---|
| Qwen2.5-1.5B frozen | L/16 | 58.7 | 61.5 |
| Qwen2.5-1.5B frozen | So/16 | 60.6 | 62.6 |
| Qwen2.5-1.5B frozen | g/16 | 61.5 | 65.2 |
| Qwen2.5-7B frozen | So/16 | 69.4 | 71.8 |
| Qwen2.5-7B frozen | g/16 | 68.9 | 73.6 |
Qwen2.5-7B 下最强 GenLIP-g/16 的逐项结果为:ChartQA 57.1、OCR-B 65.9、DocVQA 69.0、TextVQA 66.8、AI2D 81.0、InfoVQA 43.6、SEED-2 61.1、VQAv2 64.4、GQA 54.5、SQA 87.0、MME-P 1483、NoCaps 85.0、COCO 75.5、TextCaps 144.8、ALL AVG 73.6。
Qwen2.5-1.5B 下,论文还报告了 Doc&OCR 7 项平均:GenLIP L/16、So/16、g/16 分别为 49.3、50.1、53.2,比 SigLIP2 分别高 4.3、3.3、5.9;这解释了为什么总分提升主要来自细粒度 OCR/文档理解。
 Figure 4 解读:图 4 不是下游 benchmark 表,而是直接让 GenLIP “Describe the image”。stage 2 输出通常更长、更细;在 Bulbasaur 示例里,L16/So16 把对象错认为 Charmander,而 g16 识别正确,说明能力随模型规模提升。
Figure 4 解读:图 4 不是下游 benchmark 表,而是直接让 GenLIP “Describe the image”。stage 2 输出通常更长、更细;在 Bulbasaur 示例里,L16/So16 把对象错认为 Charmander,而 g16 识别正确,说明能力随模型规模提升。
 Figure 5 解读:图 5 把选中 image patch 的 hidden feature 直接经过 LM head unembed 成 top tokens。较大的 GenLIP-g/16 能把局部区域读出与语义相关的 token,stage 2 后这些 tokens 与选中区域更贴近,说明生成式预训练让局部视觉 patch 与语言概念发生了可读出的对齐。
Figure 5 解读:图 5 把选中 image patch 的 hidden feature 直接经过 LM head unembed 成 top tokens。较大的 GenLIP-g/16 能把局部区域读出与语义相关的 token,stage 2 后这些 tokens 与选中区域更贴近,说明生成式预训练让局部视觉 patch 与语言概念发生了可读出的对齐。
Standard LLaVA-NeXT evaluation. 在 unfrozen vision encoder 的标准 LLaVA-NeXT 设置中,GenLIP-So/16 也保持竞争力:576 patches 时 ALL AVG 68.5,优于 RICE-ViT 68.1;729 patches 时 ALL AVG 70.3,优于 RICE-ViT 68.6 和 SigLIPv2 67.5。729 patches 下 GenLIP 的关键项为 ChartQA 83.0、DocVQA 76.9、TextVQA 69.6、OCR-B 64.7、LiveVQA 50.4、AI2D 79.1、MMBench 78.1、MME-C 54.5、MME-P 80.1、POPE 89.4、RWQA 65.1、MMStar 53.2、ALL AVG 70.3。
Scaling and ablation. Stage-2 native aspect adaptation 对所有尺度都有收益:ALL AVG 从 GenLIP-S1 到 GenLIP-S2 分别为 L/16 55.2→61.5、So/16 58.9→62.6、g/16 60.0→65.2。受控 2.0B data budget 下,GenLIP-So/16 的 OCR AVG/VQA AVG 为 44.2/55.2,高于 SigLIP 的 40.2/53.6 和 OpenVision2 的 42.0/54.3;唯一显著落后项是 OCRBench,GenLIP 36.9 低于 OpenVision2 43.2,论文认为这与该设置没有做高分辨率 adaptation、低分辨率预训练难处理 dense text 有关。
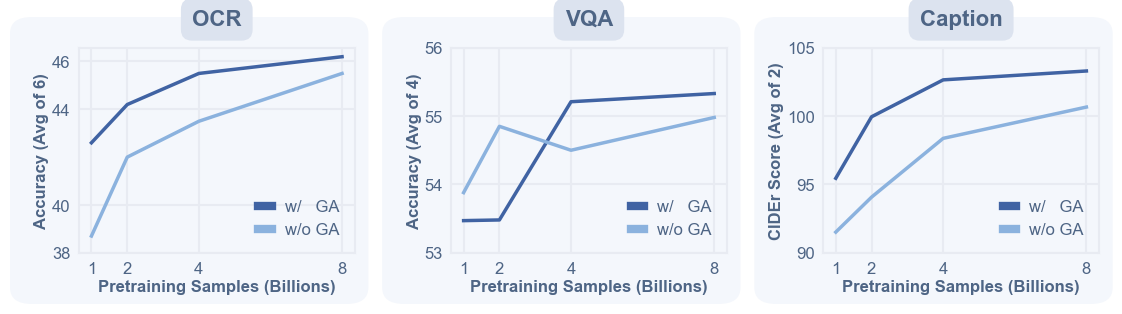 Figure 6 解读:图 6 展示从 1.0B 到 8.0B samples 的 data scaling。Doc&OCR、VQA、Caption 都随数据增加而提升,但 1.0B→4.0B 增益更陡,4.0B→8.0B 尤其在 VQA 和 Caption 上趋于变平,因此主实验采用 8.0B 作为默认规模。
Figure 6 解读:图 6 展示从 1.0B 到 8.0B samples 的 data scaling。Doc&OCR、VQA、Caption 都随数据增加而提升,但 1.0B→4.0B 增益更陡,4.0B→8.0B 尤其在 VQA 和 Caption 上趋于变平,因此主实验采用 8.0B 作为默认规模。
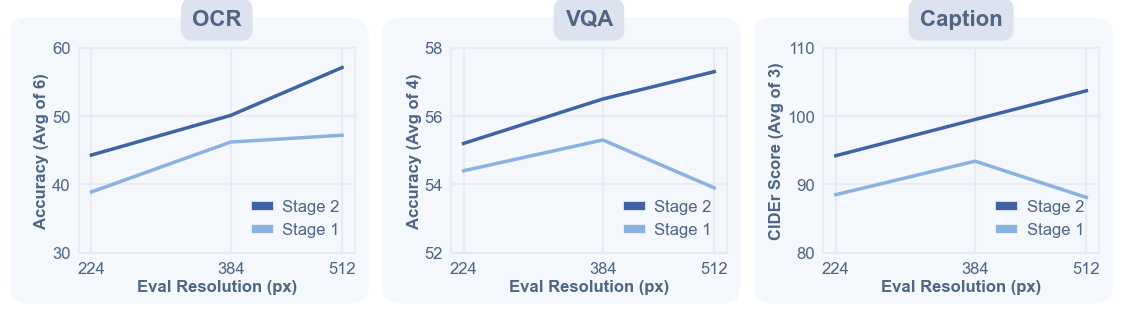 Figure 7 解读:图 7 验证 native-aspect-ratio adaptation:同一 GenLIP-So/16 在 Stage 2 后,OCR、VQA、Caption 三类平均分随评估分辨率变化更稳,说明高分辨率长 caption 数据和 native aspect ratio 训练能改善细节敏感任务。
Figure 7 解读:图 7 验证 native-aspect-ratio adaptation:同一 GenLIP-So/16 在 Stage 2 后,OCR、VQA、Caption 三类平均分随评估分辨率变化更稳,说明高分辨率长 caption 数据和 native aspect ratio 训练能改善细节敏感任务。
Gated attention and discriminative ability. 论文报告 gated attention 对 attention sink 和判别式表征有明显帮助:GenLIP-So/16 w/o GA 在 ImageNet-1K 只有 76.2 top-1;加入 GA 后 GenLIP-So/16 达到 84.3 top-1 / 42.8 ADE20K mIoU。最大 GenLIP-g/16 达到 85.2 ImageNet-1K top-1 和 44.5 ADE20K mIoU;ADE20K 上超过 CLIP L/14 的 39.0 和 SigLIP So/14 的 40.8,但仍低于带 dense supervision 的 SigLIP2 So/14 的 45.4。
 Figure 8 解读:附录 OCR-heavy 例子显示 GenLIP-g16-S2 对收据表格、几何图形、飞机编号等细节最稳定;较小模型会漏读长数字、重复输出,或把形状/空间关系判断错。这支持主表中 Doc&OCR 增益主要来自更细粒度的视觉-文本对齐。
Figure 8 解读:附录 OCR-heavy 例子显示 GenLIP-g16-S2 对收据表格、几何图形、飞机编号等细节最稳定;较小模型会漏读长数字、重复输出,或把形状/空间关系判断错。这支持主表中 Doc&OCR 增益主要来自更细粒度的视觉-文本对齐。
 Figure 9 解读:附录 patch semantics 继续展示局部区域到语言 token 的 readout。stage-2 结果通常更语义相关,说明长 caption + higher resolution adaptation 不只是提高 benchmark 分数,也让局部 patch 表征更可解释。
Figure 9 解读:附录 patch semantics 继续展示局部区域到语言 token 的 readout。stage-2 结果通常更语义相关,说明长 caption + higher resolution adaptation 不只是提高 benchmark 分数,也让局部 patch 表征更可解释。
Limitations. 作者明确列出三点限制:第一,验证主要在 academic-scale MLLM 设置 LLaVA-NeXT 上,是否泛化到最前沿 MLLM 仍待验证;第二,预训练数据规模限制在 1.0B unique samples,超过该规模的 scaling 行为尚未探索;第三,方法依赖高质量 captions,数据获取成本较高。