HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding
Authors: Haowei Zhang, Shudong Yang, Jinlan Fu, See-Kiong Ng, Xipeng Qiu Affiliations: Fudan University, Shanghai Innovation Institute, National University of Singapore arXiv: 2601.14724 Project Page: hermes-streaming.github.io GitHub: haowei-freesky/HERMES
1. Motivation (研究动机)
这篇论文研究的是 streaming video understanding 场景下,如何让视频 MLLM 同时满足三件事:
- 理解稳定:不能因为长视频和 memory budget 受限而忘掉早期内容;
- 实时响应:用户提问到模型输出首 token 的延迟(TTFT)要很低;
- 显存可控:不能像 ReKV 那样靠缓存所有 KV 再 offload 才勉强工作。
作者认为,现有方法的问题不只是 memory budget 太小,而是不同 decoder layer 对视频信息的偏好并不相同,但以往方法通常用统一的 FIFO / uniform eviction 去管理所有层的 KV cache,因此浪费了 layer-wise 结构信息。
换句话说,HERMES 的出发点是:KV cache 本身就应该被视作分层记忆系统,而不是一堆同质 token buffer。
2. Idea (核心思想)
HERMES 的核心洞见来自 attention 机制分析:
- 浅层的注意力强烈偏向最近 token,像 sensory memory;
- 中层介于 recency 与语义抽象之间,像 working memory;
- 深层会在帧级语义 anchor token 上出现节律性峰值,像 long-term memory。
于是作者提出:
- 不同层使用不同的 token 保留策略;
- 再通过 cross-layer smoothing 防止层间 memory 断裂;
- 最后用 position re-indexing 保证长流式序列下 RoPE 不崩坏。
它和很多 streaming video MLLM 方法最关键的区别在于:HERMES 不在 query 到来时做额外 retrieval/compression,而是提前把 memory 管理好,因此 TTFT 极低。
3. Method (方法)
3.1 Layer-wise preference analysis

Figure 1 解读: Figure 1 展示了深层 attention 的模式:在 layer 26 中,局部峰值呈现接近固定间隔,图中直接标出间隔 ,恰好对应一帧在 LLaVA-OV 中编码出的 token 数量。这说明深层会自然形成 frame-level anchor token,更像在存储长期、语义化的帧记忆,而不是仅仅关注最近输入。这一发现正是 HERMES 把 KV cache 分成浅/中/深三类记忆层的依据。
作者在 mechanistic investigation 中把视频 token 的层间注意力分成三种阶段:
- Shallow Layers = Sensory Memory:极强 recency bias,几乎只关注最新 token;
- Middle Layers = Working Memory:从 recency 逐步过渡到语义 anchor;
- Deep Layers = Long-term Memory:在帧级 token 上出现规则峰值,承载长期语义信息。
3.2 Overall framework

Figure 2 解读: Figure 2 给出了 HERMES 的整体框架。左边视频流经 vision encoder / projector 进入分层 KV cache;中间是“KV Cache as Hierarchical Memory”,显式划分为浅层 sensory memory、中层 working memory、深层 long-term memory,并在不同层采用不同 importance score;右边则通过 cross-layer smoothing 让更深层的记忆信号反向影响较浅层,同时结合 tokenizer、prefilling、multimodal decoding,在用户提问时直接复用已经组织好的 cache 实时回答,而不需要额外 retrieval。
3.3 Hierarchical KV Cache Management
设 layer 中第 个视频 token 的重要性为 。HERMES 按层类型定义不同的重要性分数。
(1) 浅层:recency / forgetting curve
浅层被看作 sensory memory,采用类似遗忘曲线:
这里 是当前 cache 中的总 token 数, 越大表示 token 越旧,因此分数越低。
(2) 深层:attention-based long-term memory
深层被视作 long-term memory,直接按 pseudo query attention 权重定义:
其中 是第 层中 token 对用户问题(在 streaming 场景用 generic guidance prompt 代替真实问题)所对应的注意力权重。
(3) 中层:attention 与 recency 插值
中层是 working memory,按 layer depth 插值 recency 与 attention:
其中默认 。最终:
其中 和 分别是 attention-based 与 recency-based 的标准化分数。
3.4 Cross-Layer Memory Smoothing
单独按层做 token eviction 会带来一个问题:同一个 cache index 在不同层可能被不同步地删除,导致跨层语义断裂。HERMES 用 cross-layer smoothing 缓解这个问题:
然后用平滑后的分数做 Top-K 选择:
并保留对应的 。
另外,对 deep layer 中被删掉的 token,HERMES 不直接扔掉,而是聚合成一个 summary token 保存长期信息。Supplementary 的算法给出其核心思想:
- value 直接做均值聚合;
- key 先通过 rotary delta 对齐 phase,再做均值聚合;
- 最后把 summary token 拼回 KV cache。
3.5 Position Re-Indexing
流式视频越长,位置索引越可能超过模型支持的上限,进而严重影响生成质量。HERMES 提出两种位置重映射:
- Lazy Re-Indexing:只在 position 接近上限时触发,适合 streaming;
- Eager Re-Indexing:每次压缩都重映射,适合 offline long-video。
作者还分别给出了对 1D RoPE (LLaVA-OV) 和 3D M-RoPE (Qwen2.5-VL) 的实现方式。
从公开脚本 inference/llavaov_online_official.py 可以看到:
- HERMES 在代码中显式维护
short_term_ratio=0.3、long_term_ratio=0.3; - 有
_shrink_positions_and_rerotate_keys(),说明确实在实现 position compaction 与 rotary 修正; - deep layer 会把被删 token 聚合成 summary token,再写回 cache。
这说明论文的三个方法模块不是纯概念设计,而是已经在 inference 脚本里部分落地。
3.6 Pseudocode(基于公开 inference 脚本)
组件 A:Hierarchical importance scoring
# Algorithm: Hierarchical KV importance scoring
# Input: layer index l, token index i, attention weight W_i^l, recency score R_i^l
# Output: token importance S_i^l
def importance_score(layer_idx, token_idx, attn_score, recency_score):
if layer_idx in shallow_layers:
return alpha(token_idx, layer_idx) * exp(-k * delta_t(token_idx))
elif layer_idx in deep_layers:
return alpha(token_idx, layer_idx) * attn_score
else:
omega = omega0 - gamma * (layer_idx - l_short) / (l_long - l_short)
return (1 - omega) * attn_score + omega * recency_score组件 B:Cross-layer memory smoothing and eviction
# Algorithm: Cross-layer smoothing + Top-K keep
# Input: raw scores S^l, budget M
# Output: kept KV indices per layer
def smooth_and_select(scores_per_layer, budget):
smoothed = []
for l in range(num_layers - 1):
smoothed_l = (1 - lambda_l[l]) * scores_per_layer[l] + lambda_l[l] * scores_per_layer[l + 1]
smoothed.append(smoothed_l)
smoothed.append(scores_per_layer[-1])
keep_indices = []
for l in range(num_layers):
keep_indices.append(topk(smoothed[l], budget))
return keep_indices组件 C:Summary token aggregation
# Algorithm: Summary token aggregation
# Input: pruned keys/values K_p, V_p and their original positions P_p
# Output: one summary token appended to cache
def summary_token_aggregation(K_p, V_p, P_p, target_pos):
v_sum = mean(V_p)
delta_theta = rotary_delta(P_p, target_pos)
K_aligned = apply_delta(K_p, delta_theta)
k_sum = mean(K_aligned)
return k_sum, v_sum组件 D:Lazy / eager position re-indexing
# Algorithm: Position re-indexing
# Input: current cache positions, mode in {lazy, eager}
# Output: compacted positions in [0, |M|)
def reindex_positions(cache_positions, mode, threshold):
if mode == 'eager':
return arange(len(cache_positions))
if mode == 'lazy' and max(cache_positions) > threshold:
return arange(len(cache_positions))
return cache_positions3.7 Code-to-paper mapping table
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| HERMES inference framework | inference/llavaov_online_official.py | LlavaOneVision_Hermes |
| Layer partition / memory hierarchy | inference/llavaov_online_official.py | short_term_ratio, long_term_ratio, thresholds |
| Position re-indexing & RoPE correction | inference/reindex_1d_official.py | compute_cos_sin_for_positions, rotary_delta, apply_rotary_delta_to_keys_only |
| Position compaction in cache | inference/llavaov_online_official.py | _shrink_positions_and_rerotate_keys |
| Summary token algorithm | appendix/I_aggre.tex | Summary Token Aggregation |
| Full refined training-free code | GitHub README | “will be released soon” |
4. Experimental Setup (实验设置)
4.1 Benchmarks
Streaming benchmarks:
- StreamingBench
- OVO-Bench
- RVS-Ego / RVS-Movie
Offline benchmarks:
- MVBench
- VideoMME
- EgoSchema
作者覆盖了 multiple-choice 与 open-ended QA 两类任务。
4.2 Models
为了验证通用性,HERMES 适配了两条主流 open-source MLLM 线:
- LLaVA-OneVision:0.5B / 7B
- Qwen2.5-VL:7B / 32B
同时也在论文分析中与 ReKV、LiveVLM、StreamForest、Dispider、StreamingTOM 等 streaming / training-free baseline 对比。
4.3 Inference / Memory settings
- video 按 chunk 编码,每个 chunk = 16 frames
- token compression 在 memory budget 超限时触发
- 层划分:10% shallow / 60% middle / 30% deep
- HERMES 主结果通常报告 4K / 6K video tokens memory budget
- 全部评测使用 FP16 mixed precision
- efficiency 测试在 单张 A800 GPU 上完成
- accuracy 评测可在 一张 H200 上完成
5. Experimental Results (实验结果)
5.1 StreamingBench / OVO-Bench 主结果
| Model | StreamingBench | OVO Real-Time | OVO Backward | OVO Avg |
|---|---|---|---|---|
| LLaVA-OV-7B | 71.34 | 63.06 | 43.64 | 53.35 |
| + HERMES (6K) | 72.63 | 65.07 | 48.80 | 56.94 |
| + HERMES (4K) | 73.23 | 66.34 | 50.20 | 58.27 |
| Qwen2.5-VL-7B | 73.31 | 59.90 | 44.65 | 52.28 |
| + HERMES (4K) | 79.44 | 68.98 | 49.43 | 59.21 |
| Qwen2.5-VL-32B | 74.27 | 64.40 | 50.33 | 57.37 |
| + HERMES (6K) | 80.20 | 71.93 | 57.71 | 64.82 |
这部分结果说明:
- HERMES 在多个 backbone 上都有效;
- Qwen2.5-VL-7B + HERMES(4K) 相比 base model,StreamingBench 提升 +6.13,OVO Avg 提升 +6.93;
- 即使在更大模型上,HERMES 也仍然持续提升,不只是“小模型补丁”。
5.2 Open-ended streaming QA:RVS
| Method | RVS-Ego Acc / Score | RVS-Movie Acc / Score |
|---|---|---|
| LLaVA-OV-7B | 56.2 / 3.7 | 43.0 / 3.3 |
| ReKV | 63.7 / 4.0 | 54.4 / 3.6 |
| HERMES (6K) | 60.3 / 4.0 | 54.4 / 3.6 |
| HERMES (4K) | 58.3 / 3.9 | 54.4 / 3.6 |
论文中强调的最大增益来自 RVS-Movie accuracy 43.0 → 54.4,即 +11.4。这说明 HERMES 在 open-ended、需要长期时序回溯的场景中尤其有效。
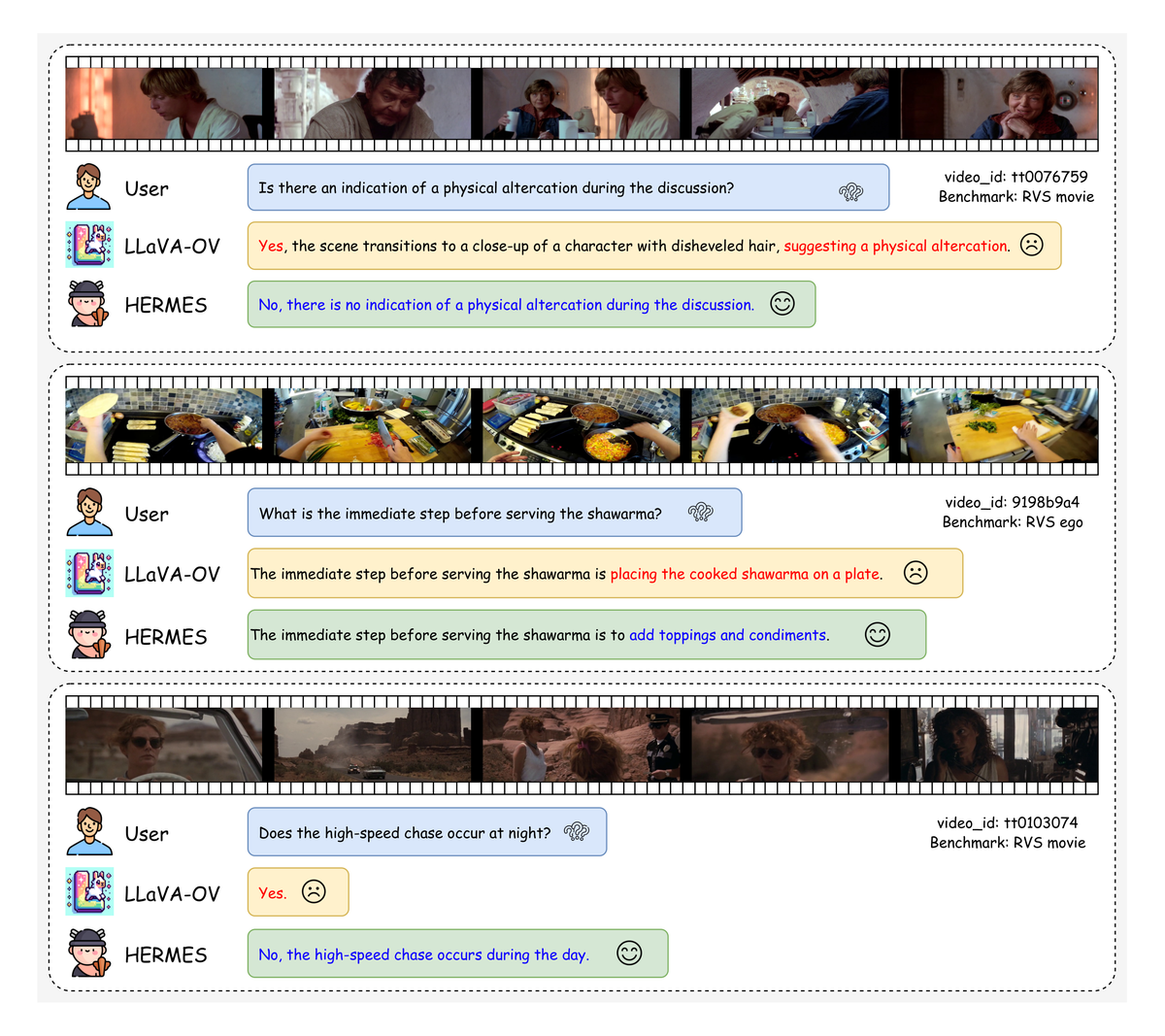
Figure 3 解读: Figure 3 是 temporal case study。作者给出多个 RVS 问题,对比 base model 与 HERMES 的回答。可以看到 LLaVA-OV 往往会抓住局部显眼线索,但忽略跨时间顺序与上下文;而 HERMES 能更准确恢复“某个动作发生前后”的关系,说明其 hierarchical memory 确实改善了长程时序依赖的保留。
5.3 Offline benchmarks
| Method | MVBench | EgoSchema | VideoMME Long | VideoMME Avg |
|---|---|---|---|---|
| LLaVA-OV-7B | 57.02 | 59.93 | 48.00 | 57.67 |
| ReKV | 56.83 | 60.70 | 46.89 | 57.74 |
| HERMES (4K) | 56.92 | 60.29 | 49.22 | 58.85 |
| Qwen2.5-VL-7B | 65.00 | 58.47 | 53.89 | 64.52 |
| HERMES (6K) | 65.40 | 59.47 | 54.44 | 62.00 |
| HERMES (4K) | 65.53 | 59.97 | 53.44 | 60.63 |
离线任务里,HERMES 的信息更 nuanced:
- 在 LLaVA-OV-7B 上,HERMES(4K) 在 VideoMME Long / Avg 上最好;
- 在 Qwen2.5-VL-7B 上,VideoMME Avg 反而低于 base model,但 long subset 和其他指标有提升;
- 说明 HERMES 并不是在所有离线任务上无条件超过 full-context offline inference,而是更突出于 memory-bounded streaming-like usage。
5.4 Efficiency:HERMES 为什么快

Figure 4 解读: Figure 4 左图比较显存,右图比较 TTFT。随着输入帧数从 16 增加到 256,HERMES 的显存几乎保持稳定,而 Dispider / ReKV / StreamingTOM 更容易随帧数增长;TTFT 方面,HERMES 始终保持极低延迟,图中直接标出约 27ms / 29ms / 28ms,而其他方法会显著变慢。这张图非常直观地说明:HERMES 的优势不只是精度,还有“query 到来时无需额外检索”的实时性。
根据表格,HERMES(4K budget, chunk size 8)的效率为:
- GPU Mem:16.54 / 16.66 / 16.66 / 16.66 GB(16 / 64 / 256 / 512 frames)
- TTFT:27.01 / 28.41 / 28.44 / 28.41 ms
- TPOT:24.43 / 23.89 / 24.02 / 23.98 ms
而论文特别强调:在 256 帧设定下,相比 prior SOTA:
- 对 LiveVLM,peak memory 1.04× 更低;
- 对 StreamingTOM,TTFT 10× 更快。
5.5 Ablation studies
(1) Cross-layer smoothing
最优超参为:
此时 VideoMME Avg = 58.44,而无 smoothing 只有 54.74。说明层间一致性确实是必要的。
(2) Summary token
| Variant | VideoMME Avg |
|---|---|
| HERMES w/o summary token | 57.96 |
| HERMES w/ summary token | 58.44 |
虽然提升不算巨大,但 long subset 从 47.78 → 49.11,说明 summary token 对长程记忆保留是有意义的。
(3) Position re-indexing
- Streaming task:lazy better,OVO Avg = 56.94 vs eager 的 56.06
- Offline task:eager better,VideoMME Avg = 58.44 vs lazy 的 54.93
这与论文的直觉一致:streaming 更需要保留最近 token 的原始位置信息,offline 则更受益于严格连续的 index。
5.6 Limitations / 结论
论文没有把 limitation 独立成一节,但从正文和 README 可以看出几个边界:
- 当前 GitHub 只公开了 部分 inference 脚本,完整 refined code 还没放出;
- HERMES 的优势最强地体现在 memory-bounded streaming setting,在部分 offline 指标上并不一定全面胜过 full-context base model;
- 层级划分与 smoothing 超参对效果有较大影响,说明方法仍然依赖一些 carefully tuned 设计。
总的来说,HERMES 的主要贡献是:
- 把 KV cache 从“统一缓存”重新解释成 分层记忆系统;
- 通过 hierarchical eviction + cross-layer smoothing + re-indexing 同时解决准确率、实时性和显存问题;
- 在 streaming video understanding 上给出了一个非常强的 training-free inference-time 基线。