Flash-VStream: Efficient Real-Time Understanding for Long Video Streams
Authors: Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, Xiaojie Jin Affiliations: Tsinghua University, Tsinghua Shenzhen International Graduate School, Beijing Jiaotong University, ByteDance Inc. arXiv: 2506.23825 GitHub: IVGSZ/Flash-VStream Venue: ICCV 2025
1. Motivation (研究动机)
现有长视频理解方法的问题:
长视频理解面临两个核心挑战:
- 计算开销极大:长视频天然具有大量帧,直接输入 VLM 导致 token 数量爆炸式增长,GPU 显存和推理延迟均无法满足实际应用需求。在资源受限的边缘设备上尤为突出。
- 无法实时响应:现有方法将长视频与短视频同等对待,在长视频场景下需处理超过 12000 个 token,推理延迟超过 1 秒,无法满足实时人机交互(定义:首 token 延迟 ≤ 1 秒)的需求。
两类现有方案的缺陷:
| 方案类型 | 代表方法 | 问题 |
|---|---|---|
| 离线长视频 VLM | LongVA, LLaVA-OneVision, Kangaroo | token 数高(8K-50K),无法实时推理 |
| 在线视频流 VLM | VideoLLM-Online, VideoStreaming | 速度快但精度差(单帧/极低分辨率),性能落后于离线方法 |
本文要解决的问题:
如何设计一个能同时满足实时响应(首 token ≤ 1 秒)和高精度理解的长视频语言模型,在固定 token 预算(11520)下处理极长视频流?
为什么值得研究:
多模态助手、机器人、监控系统等实际应用场景迫切需要在动态视频环境中实时理解并响应用户查询,这是现有方法尚未能有效解决的关键问题。
2. Idea (核心思想)
核心洞见:
视频中存在大量时间冗余——相邻帧内容高度相似,不应平等对待所有帧。通过将连续帧聚类压缩为「上下文摘要(Context Synopsis)」并有选择地保留「关键帧细节(Detail Augmentation)」,可以在固定 token 预算下同时捕获长时序全局信息和关键帧的细节信息。
关键创新(1-3 句话):
Flash-VStream 采用双进程异步框架将视觉处理(帧编码 + 记忆更新)与语言处理(问题响应)解耦,使两者可并行运行。核心是设计了固定容量的 Flash Memory,包含通过 K-means 聚类压缩长时序信息的 Context Synopsis Memory(CSM) 和通过 Feature-Centric 检索保留关键帧高分辨率细节的 Detail Augmentation Memory(DAM),两者互补形成高效紧凑的视频表示。同时提出 Adaptive Multimodal RoPE(AM-RoPE),使位置编码适配 CSM(平均位置,低分辨率)和 DAM(精确位置,高分辨率)两类不同粒度的 token。
与现有方法的根本区别:
| 维度 | 现有在线方法 | Flash-VStream |
|---|---|---|
| 处理框架 | 串行(等帧处理完再回答) | 双进程异步并行 |
| 记忆设计 | 无/简单 KV 压缩 | CSM(全局聚类)+ DAM(关键帧细节) |
| token 分配 | 均匀采样 | 信息密度驱动(cluster size 加权) |
| 位置编码 | 标准 M-RoPE | AM-RoPE(适配双粒度 token) |
3. Method (方法)
3.1 整体框架:双进程异步模型

Figure 3 解读: Flash-VStream 的完整两进程架构图,时间轴从左(Time=t-1)到右(Time=60min 0s)展示长视频流处理过程。上半部分(Frame Handler 进程):视觉编码器持续接收新帧 ,输出高分辨率特征 (经 post 保存至 Feature Bank)和低分辨率特征 (经 pool 池化);随后用 K-means 聚类更新 CSM,从 Feature Bank 检索关键帧高分辨率特征更新 DAM;最终将 CSM 和 DAM 按时序交织成 Flash Memory 。下半部分(Question Handler 进程):完全异步运行,收到用户问题后立即读取当前 Flash Memory,通过 Projector 和 LLM 生成答案,响应时间 ≤ 1 秒。两进程通过共享 Flash Memory 协作,互不阻塞。右侧展示 Flash Memory 的内部结构:(蓝色块,低分辨率聚类 centroid)和 (绿色块,高分辨率关键帧),按时序位置 排列。
骨干模型(基于 Qwen2-VL):
- 视觉编码器:ViT with 3D patch embedding,每两帧时序池化后编码
- Projector:merger projector(MLP),4 个相邻空间 ViT token → 1 个 LLM token
- LLM:Qwen2-7b
帧 经视觉编码器输出两种分辨率特征:
其中 为高分辨率 patch 数(448×448 对应 1024), 为低分辨率(224×224 对应 256),pool 为平均池化()。
3.2 Context Synopsis Memory(CSM)
设计动机: CSM 的目标是用固定容量 个低分辨率特征图表示尽可能多的历史帧,通过聚类 centroid 捕获长时序信息分布。相似帧组成一个 cluster,centroid 是其 synopsis(摘要)。
CSM 内容(公式 3):
每个 cluster 的 centroid = 成员低分辨率特征图的均值。
CSM 增量更新(公式 4):
当新帧 到来时,在线 K-means 聚类:
其中 为特征拼接,K-means 限制 cluster 数为 ,保持 CSM 固定容量。cluster 大小 隐式编码该时段的信息密度——大 cluster 表示该时段内容重复性高、信息密度低。
CSM 时序位置(公式 7):
即 cluster 内所有帧索引的均值,代表该 context 的平均时序位置。
3.3 Detail Augmentation Memory(DAM)
设计动机: CSM 的聚类压缩损失了空间细节(多帧平均会模糊精细纹理)。DAM 通过选择性存储 个关键帧的高分辨率特征图来补充细节。
Feature-Centric 检索策略:
(1) 对 CSM 按 cluster 大小降序排列(取 top- 个最大 cluster):
(2) 从 Feature Bank 中,为每个 top cluster 检索最近邻高分辨率帧:
为欧氏距离,选取 低分辨率特征最近邻 对应的高分辨率帧存入 DAM。这样 DAM 专注于存储 CSM 中信息密度最高的关键帧的空间细节。
DAM 时序位置(公式 8):
即关键帧自身的帧索引。
3.4 Flash Memory 组装
将 CSM 和 DAM 按时序位置交织排列,形成最终的 Flash Memory:
Flash Memory 总 token 数:(默认配置)。
配置参数(Table 1):
| 配置项 | CSM | DAM |
|---|---|---|
| 输入帧数 | 120 | 60 |
| 输入分辨率 H×W | 224×224 | 448×448 |
| 时序尺寸 N | 60 | 30 |
| 空间尺寸 h×w | 256 | 1024 |
| LLM tokens | 60×64 = 3840 | 30×256 = 7680 |
3.5 Adaptive Multimodal RoPE(AM-RoPE)
CSM token 和 DAM token 有不同的分辨率和语义粒度,需要适配的位置编码。AM-RoPE 基于 M-RoPE 扩展,将隐维度分为三个轴(时间 、高度 、宽度 ):
DAM token(位置 at ,高分辨率,索引空间在前):
CSM token(位置 at ,低分辨率,索引空间整体偏移 spa_size):
其中 spa_size = DAM 总 token 数()。实际实现(calc_am_rope)中,DAM(spa)和 CSM(tem)使用相同空间网格坐标,但 CSM 的时序索引在 DAM 索引空间之后整体偏移,使两类 token 在位置编码空间中不重叠。论文图示中的空间坐标 ×2 是概念性描述,源码中通过偏移量实现隔离而非坐标缩放。
3.6 实时推理与训练
实时推理条件:
通过将 Flash Memory token 数控制在 ,可保证 7b 模型首 token 延迟 ≤ 1 秒(实测单 A100 GPU)。
训练设置:
基于 Flash Memory 对 Qwen2-VL-7b 进行 LoRA 微调,训练数据为 LLaVA-Video 的 9k 子集(含 captioning、开放式 VQA、多选 VQA 三类任务)。视觉编码器参数冻结,Projector 和 LLM 所有线性层为 LoRA 微调目标。
3.7 效率对比

Figure 2 解读: EgoSchema 准确率 vs 推理成本(tokens/video)的帕累托前沿图。上方折线图展示延迟(秒)—超过 12000 tokens 即越过实时推理边界(>1 秒)。Flash-VStream(蓝色圆点)在 11520 tokens 预算下,以 68.2% 的准确率位于右上角,同时满足实时性约束(<1 秒)。相比 Kangaroo(绿菱形,~16000 tokens,67%)节省 28% token;相比 Qwen2-VL(蓝三角,~24576 tokens,64.8%)节省 53% token。标注的 “2.0×”、“5.6×” 等数字表示 Flash-VStream 在相同准确率下的 token 效率倍数优势。
3.8 伪代码
# Algorithm 1: Flash Memory Update (Frame Handler)
# Input: new frame V_t, current Flash Memory, Feature Bank E_t_H
# Output: updated Flash Memory M_F
def update_flash_memory(V_t, M_csm, feature_bank, N_csm, N_dam, R_pool=4):
# 1. Encode frame at two resolutions
e_H = visual_encoder(V_t) # high-res [h*w, d]
e_L = visual_encoder(avg_pool(V_t, R_pool)) # low-res [h'*w', d]
# 2. Save high-res to Feature Bank (also maintain low-res bank for CSM)
feature_bank.append(e_H)
small_feature_bank.append(e_L)
# 3. Update CSM via K-means clustering over FULL accumulated low-res history
# (实现中 temporal_compress 接收全部历史低分辨率帧,而非仅 centroid+新帧)
all_small_features = stack(small_feature_bank) # [T, h'*w', d] full history
# K-means with K=N_csm, returns cluster centroids, weights, timestamps, indices
M_csm_new, cluster_sizes, cluster_indices = weighted_kmeans_ordered_feature(
all_small_features, K=N_csm)
# 4. Compute CSM temporal positions
P_csm = [mean(cluster_indices[k]) for k in range(N_csm)]
# 5. Sort CSM by cluster size (descending) -> top-N_dam
sorted_idx = argsort(cluster_sizes, descending=True)[:N_dam]
M_csm_sorted = M_csm_new[sorted_idx] # top-N_dam centroids
# 6. Feature-Centric retrieval: find nearest low-res frame for each centroid
f_k = []
for k in range(N_dam):
dists = euclidean_distance(M_csm_sorted[k], [e_L for e_L in feature_bank])
f_k.append(argmin(dists)) # key frame index
M_dam = stack([feature_bank[i] for i in f_k]) # [N_dam, h*w, d]
P_dam = f_k # DAM temporal positions
# 7. Interleave CSM and DAM by temporal position
all_features = concat(M_csm_new, M_dam)
all_positions = concat(P_csm, P_dam)
sort_idx = argsort(all_positions)
M_F = all_features[sort_idx] # Flash Memory M^F
return M_csm_new, M_F, P_csm, P_dam# Algorithm 2: AM-RoPE Position Encoding
# Input: token position (x, y, k), token type (CSM or DAM)
# Output: rotary position embedding indices (n_t, n_h, n_w)
def compute_amrope_position(x, y, k, token_type, P_csm, P_dam, spa_size):
if token_type == 'DAM':
# High-res token (spa): precise frame index, normal spatial coords
# DAM tokens occupy index space [0, spa_size)
n_t = P_dam[k] # exact frame index t(k)
n_h = y # spatial coords (same grid as CSM)
n_w = x
elif token_type == 'CSM':
# Low-res token (tem): average temporal position, offset by spa_size
# CSM tokens occupy index space [spa_size, spa_size + tem_size)
n_t = P_csm[k] + spa_size # offset so CSM & DAM don't overlap in position space
n_h = y
n_w = x
return n_t, n_h, n_w
# Note: spa_size = N_dam * llm_grid_h * llm_grid_w (total DAM LLM tokens)
# Source: calc_am_rope() -> get_mm_index_with_positions(), tem_pos_ids += spa_size# Algorithm 3: Two-Process Asynchronous Inference
# Frame Handler (continuous) and Question Handler (on-demand) run concurrently
# === Frame Handler Process ===
def frame_handler(video_stream, flash_memory, feature_bank, lock):
for frame in video_stream:
csm, M_F, P_csm, P_dam = update_flash_memory(
frame, flash_memory.csm, feature_bank, N_csm=60, N_dam=30
)
with lock:
flash_memory.M_F = M_F # atomic update of shared memory
flash_memory.csm = csm
# === Question Handler Process ===
def question_handler(question, flash_memory, projector, llm, lock):
with lock:
M_F = flash_memory.M_F # read current Flash Memory snapshot
# Apply AM-RoPE position encoding (embedded in LLM attention)
tokens = projector(M_F) # [N_vtokens, D_llm]
answer = llm.generate(question, tokens, max_new_tokens=512)
# Guarantee: first token latency <= 1s with N_vtokens <= 12000
return answer3.9 代码与论文对应表
| 论文概念 | 对应代码文件 | 关键类/函数 |
|---|---|---|
| Flash Memory 整体 | Flash-VStream-Qwen/models/vstream_qwen2vl_realtime.py | FlashMemory |
| CSM K-means 聚类 | Flash-VStream-Qwen/models/compress_functions.py | weighted_kmeans_ordered_feature |
| CSM 增量更新(公式 4) | Flash-VStream-Qwen/models/vstream_qwen2vl_realtime.py | FlashMemory.temporal_compress() |
| DAM Feature-Centric 检索(公式 6) | Flash-VStream-Qwen/models/vstream_qwen2vl_realtime.py | FlashMemory.spatial_enhance() |
| AM-RoPE 位置计算 | Flash-VStream-Qwen/models/vstream_qwen2vl_realtime.py | get_real_grid_thw() / get_spatial_real_grid_thw() |
| 低分辨率特征池化 | Flash-VStream-Qwen/models/vstream_qwen2vl_realtime.py | FlashMemory.temporal_pool() |
| Flash Memory 默认配置 | Flash-VStream-Qwen/models/flash_memory_constants.py | DEFAULT_FLASH_MEMORY_CONFIG |
| 双进程异步服务 | Flash-VStream-Qwen/cli_server_2gpu.py | 两进程服务入口 |
| 模型架构整体 | Flash-VStream-Qwen/models/vstream_qwen2vl_model.py | FlashVStreamQwen2VL |
| 训练脚本 | Flash-VStream-Qwen/finetune_flash.py | LoRA 微调主程序 |
4. Experimental Setup (实验设置)
骨干模型:
- Qwen2-VL-7b(预训练 MLLM)+ LoRA 微调
- ViT 使用 3D patch embedding,相邻 4 个空间 ViT token 合并为 1 个 LLM token
评估数据集(在线设置,1fps 采帧):
- EgoSchema:长视频 VQA,专为第一视角行为理解设计
- MLVU:多任务长视频理解基准,覆盖多种视频类型
- LVBench:极长视频理解基准,测试长时序理解能力
- MVBench:多任务视频基准,大量时序相关任务
- Video-MME:综合视频分析基准,11秒~1小时视频
评估方式:
- 零样本多选 VQA(zero-shot multiple-choice)
- 实时约束:
- 报告多选准确率
对比基线:
- 离线 VLM:MovieChat、TimeChat、LLaMA-VID、ChatUni-Vi、ShareGPT4-video、VideoChat2-HD、VideoLLaMA2、LongVA、LLaVA-OneVision、LongVILA、Kangaroo、Oryx-MLLM、Qwen2-VL*
- 在线 VLM:VideoLLM-Online、VideoLLM-MOD、VideoStreaming、Qwen2-VL-online†
训练配置:
- 数据集:LLaVA-Video 9k 子集(captioning + 开放式 VQA + 多选 VQA)
- LoRA 应用于 Projector 和 LLM 所有线性层,视觉编码器冻结
- 硬件:单节点 A100 GPU(测速),A100 80GB(训练)
- 精度:BF16 + FlashAttention-2
Flash Memory 配置(表 1 默认值):
- CSM:120 帧输入,224×224,N^CSM=60,64 LLM tokens/帧
- DAM:60 帧输入,448×448,N^DAM=30,256 LLM tokens/帧
- 总计:11520 LLM tokens(1/3 给 CSM,2/3 给 DAM)
5. Experimental Results (实验结果)
5.1 视频问答基准对比(Table 2)
| 模型 | Max N_Vtokens | EgoSchema | MLVU_dev | LVBench | MVBench | Video-MME w/o | Video-MME w/ |
|---|---|---|---|---|---|---|---|
| 离线模型 | |||||||
| LLaMA-VID | 2fps | 38.5 | 33.2 | 23.9 | 41.9 | - | - |
| Video-Chat2-HD | 512 | 55.8 | 47.9 | - | 62.3 | 45.3 | 55.7 |
| VideoLLaMA2 | 9216 | 51.7 | 48.5 | - | 54.6 | 47.9 | 50.3 |
| LongVA | 18432 | - | 56.3 | - | - | 52.6 | 54.3 |
| LLaVA-OneVision | 6272 | 60.1 | 64.7 | - | 56.7 | 58.2 | 61.5 |
| Kangaroo | 16384 | 62.7 | 61.0 | - | 61.0 | 56.0 | 57.6 |
| Qwen2-VL* | 24576 | 64.8 | 66.0 | 41.4 | 65.1 | 61.1 | 65.9 |
| 在线模型 | |||||||
| VideoStreaming | 256 | 44.1 | - | - | - | 53.3 | - |
| Qwen2-VL-online† | 11520 | 64.0 | 62.9 | 39.8 | 63.3 | 59.4 | 65.1 |
| Flash-VStream | 11520 | 68.2 (↑4.2) | 66.3 (↑3.4) | 42.0 (↑2.2) | 65.4 (↑2.1) | 61.2 (↑1.8) | 67.0 (↑1.9) |
Flash-VStream 在相同 token 预算(11520)下,在全部 5 个基准上均显著超越 Qwen2-VL-online†,并在 EgoSchema、LVBench 上超越 token 数更多的 Qwen2-VL*(离线)。
5.2 Video-MME 详细对比(Table 3)
| 模型 | Max N_Vtokens | w/o subs Short | Middle | Long | Avg | w/ subs Short | Middle | Long | Avg |
|---|---|---|---|---|---|---|---|---|---|
| LongVA | 18432 | 61.1 | 50.4 | 46.2 | 52.6 | 61.1 | 53.6 | 47.6 | 54.3 |
| Kangaroo | 16384 | 66.1 | 55.3 | 46.7 | 56.0 | 68.0 | 55.4 | 49.3 | 57.6 |
| Qwen2-VL* | 24576 | 71.3 | 63.1 | 50.7 | 61.1 | 71.1 | 69.0 | 57.6 | 65.9 |
| Qwen2-VL-online† | 11520 | 70.3 | 59.8 | 48.2 | 59.4 | 71.4 | 66.0 | 57.9 | 65.1 |
| Flash-VStream | 11520 | 72.0 | 61.1 | 50.3 | 61.2 | 72.4 | 67.0 | 61.4 | 67.0 |
Flash-VStream 在短视频(Short)和 w/ subs Long 维度超越所有对比方法(含更多 token 的离线模型),平均成绩对齐或超越 token 数多一倍以上的 Qwen2-VL*。
5.3 消融实验(Table 4)
| ID | CSM | DAM | N_Vtokens | MVBench | EgoSchema | Video-MME(w/o) | Avg |
|---|---|---|---|---|---|---|---|
| ① | ✓ | ✓ | 11520 | 65.4 | 68.2 | 61.2 | 64.9 |
| ② | ✓ | Uni.Smp. | 11520 | 64.3 | 67.8 | 60.6 | 64.2 |
| ③ | ✓ | ✗ | 3840 | 64.0 | 66.8 | 60.1 | 63.6 |
| ④ | Uni.Smp. | ✗ | 3840 | 62.4 | 63.4 | 59.0 | 61.6 |
| ⑧ | Uni.Smp. | ✗ | 11520 | 63.3 | 64.0 | 59.4 | 62.3 |
关键发现:
- CSM 贡献:Row ③ vs ④ 说明 K-means CSM 比均匀采样提升平均 2.0%(63.6 vs 61.6)
- DAM 贡献:Row ① vs ③ 说明 DAM 在相同 CSM 下额外提升 1.3%(64.9 vs 63.6)
- Feature-Centric vs Uniform DAM:Row ① vs ② 说明检索策略对 DAM 质量有显著影响(64.9 vs 64.2)
- 容量效率:11520 tokens 的均匀采样(Row ⑧,62.3)仍不如 11520 tokens 的 Flash Memory(Row ①,64.9),证明记忆设计本身(非仅 token 数量)的关键作用
5.4 CSM 聚类策略对比(Table 5)
K-means 在 EgoSchema(66.8)和 MVBench(64.0)上均优于其他聚类方法(DBScan 66.6/63.8,GMM 65.8/59.6,Neighbor Merge 65.0/63.7),比均匀采样高 3.4%(EgoSchema)和 1.6%(MVBench)。
5.5 记忆可视化与案例研究
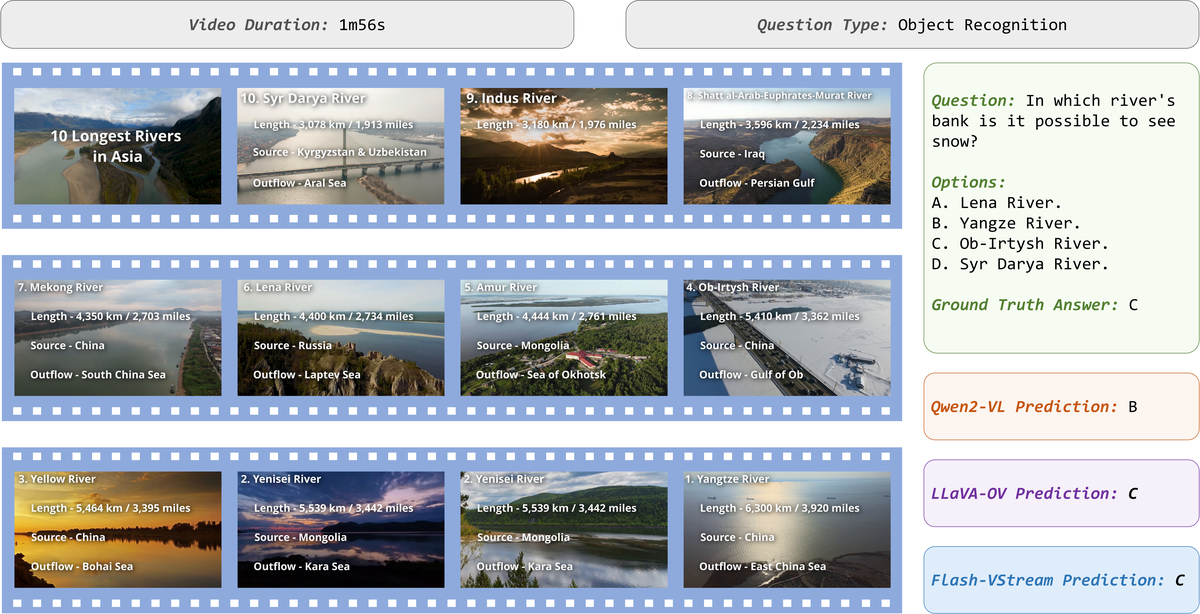
Figure 5 解读: 左侧为 Flash Memory 在特征空间的 PCA 可视化,每个点代表一帧特征图(蓝点)或 CSM/DAM 记忆 token(红六边形)。CSM 记忆特征明显与帧特征分离,呈现聚类分布形态;DAM 记忆特征与帧特征分布更接近但具有更高判别性,说明 CSM 和 DAM 成功编码了不同层次的视频信息。右侧展示两类问题的模型回答案例:上方多选题(“What is the man standing next to?” → C. FIFA World Cup Trophy)和 “Where is FIFA World Cup 2026 Final?” → B. New York/New Jersey)均正确;下方开放式问题关于剧院表演细节和 “Lehman Trilogy” 的摄像设备,均能给出具体精准的答案,验证了 Flash-VStream 对长视频内容的深入理解能力。
5.6 局限性
- Feature Bank 磁盘依赖:高分辨率 Feature Bank 可能需要卸载到磁盘(避免显存溢出),增加 I/O 开销
- 极长视频序列:视频超过数小时时,K-means 聚类的计算开销可能成为瓶颈
- K-means 计算开销:在线 K-means 聚类为帧级实时更新带来固定开销,在帧率极高的场景下需进一步优化(论文提供
fast_kmeans_ordered_feature加速版本)
总体结论:
Flash-VStream 通过将视觉处理与语言推理解耦的双进程异步框架,结合 CSM(K-means 聚类捕获长时序信息密度)和 DAM(Feature-Centric 检索关键帧细节)的 Flash Memory 设计,在 11520 token 预算内实现了对极长视频流的实时理解。在 5 个主流视频理解基准上均超越相同 token 预算的在线方法,并在 EgoSchema 上取得新的 SOTA(68.2%),同时将训练成本大幅降低(仅需 9k 样本 LoRA 微调)。