ThinkGen: Generalized Thinking for Visual Generation
Authors: Siyu Jiao, Yiheng Lin, Yujie Zhong, Qi She, Wei Zhou, Xiaohan Lan, Zilong Huang, Fei Yu, Yingchen Yu, Yunqing Zhao, Yao Zhao, Yunchao Wei Affiliations: Beijing Jiaotong University, ByteDance arXiv: 2512.23568 Project Page: huggingface.co/JSYuuu/ThinkGen GitHub: jiaosiyuu/ThinkGen
1. Motivation(研究动机)
现有视觉生成中的 CoT(Chain-of-Thought)方法大多只在单一场景内有效,例如只服务于 reasoning generation,或者依赖手工设计的“分步骤生成/指令改写”机制;一旦迁移到 text rendering、image editing、reflection 等任务,往往要重新定制流程,泛化性很差。
本文想解决两个核心问题:
- 如何把 MLLM 的显式推理能力真正迁移到视觉生成里,而不是只在某一个 benchmark 上临时奏效;
- 如何稳定地把“长而冗余”的 CoT 表征交给 DiT 使用,避免推理文本噪声拖累生成质量。
作者进一步指出,若直接把“思考”和“画图”绑成一个端到端大模型,会带来训练复杂、奖励设计困难、GPU 显存占用高等问题。因此,ThinkGen 试图构建一个可泛化、可分治、可强化学习优化的视觉生成框架,在 text-to-image、text rendering、image editing、reasoning generation、reasoning editing、reflection 等多场景上统一工作。
2. Idea(核心思想)
ThinkGen 的核心思想是:把“思考”与“绘制”解耦。具体来说,先用一个 pretrained MLLM(Qwen3-VL-8B-Think)做 CoT reasoning,把用户意图重写成更适合图像生成的 instruction;再用一个 DiT(初始化自 OmniGen2-DiT-4B)根据这些 instruction 生成图像。
论文的关键创新有三点:
- VGI-refine(Visual Generation Instruction Refinement):只保留
</think>之后真正用于生成的 instruction hidden states,并拼接 learnable Prepadding States,减轻冗余 CoT token 对 DiT 的干扰; - SepGRPO:把 RL 分成两段,先固定 DiT 优化 MLLM,再固定 MLLM 优化 DiT;
- 多场景联合训练:把 semantic composition、reasoning generation、text rendering、image editing、reflection 放在统一框架下训练,让“会思考的生成”从特例变成通用能力。
相对已有方法,ThinkGen 的根本差异不在于“多加一个 prompt rewrite 模块”,而在于:它把 MLLM 的 CoT 作为统一的中间推理层,并用 separable RL 让 reasoning module 与 generation module 各自朝最合适的方向优化。
3. Method(方法)
3.1 整体框架

Figure 3 解读:这张图给出了 ThinkGen 的主结构。左侧是 MLLM,负责接收文本或参考图像并进行 autoregressive CoT reasoning;中间是 VGI-refine,把 </think> 后的 instruction hidden states 抽取出来,再与 learnable Prepadding States 拼接;右侧是 DiT,把 refined text condition、噪声 latent、以及可选的参考图像 latent 一起送入 joint attention 生成最终图像。图中最重要的信息是:作者没有把“思考”和“绘制”做成一个单体网络,而是明确拆成 reasoning 模块与 generation 模块,这也是后续 SepGRPO 能成立的前提。
ThinkGen 的前向流程可以概括为四步:
- MLLM 理解用户意图:输入可以是 caption、editing instruction,或者“参考图 + 文本要求”;
- 生成 CoT 与 rewrite instruction:MLLM 输出带
<think> ... </think>的推理过程与最终 instruction; - VGI-refine 过滤 CoT:截取
</think>之后的 token hidden states,并拼接 个 learnable Prepadding States; - DiT 生成图像:DiT 接收 refined text states,以及可选的参考图像 latent,执行 flow matching / diffusion denoising 得到图像。
作者使用的骨干分别是:
- MLLM:Qwen3-VL-8B-Think
- DiT:OmniGen2-DiT-4B
- VAE:用于把参考图编码成 visual latent
3.2 MLLM:从 CoT 到生成指令
论文在 supervised pre-training 与 SepGRPO 两个阶段使用不同输入模板:
- Stage 1–3(pseudo-CoT):
- Stage 4–5(真实 CoT rollout):
这里 是统一 system prompt, 是 caption 或 editing instruction。前者用于在没有真实 reasoning annotation 的大规模生成数据上“伪造”一个空 think 段,从而让 DiT 学会消费 reasoning-style condition;后者用于 RL 阶段让 MLLM 真正探索对 DiT 更友好的 rewrite instruction。
开源代码中,这个过程对应 ThinkGen/pipelines/pipeline_thinkgen.py 里的 _apply_chat_template() 与 _get_qwen3_prompt_embeds():
think=True时,会先让 MLLM 生成完整 CoT;- 然后取 最后两层 hidden states 拼接成条件表示;
- 再根据特殊 token 位置,裁掉
</think>之前的部分,只把 instruction hidden states 留给 DiT。
3.3 VGI-refine:去冗余 + Prepadding States
论文指出,MLLM 的 CoT token 很长、很冗余,若把整段 hidden states 直接喂给 DiT,会显著拖累生成。于是作者提出 VGI-refine,两步完成:
- CUT:只保留
</think>之后的 hidden states; - Prepadding:在前面拼接 个 learnable Prepadding States,帮助调整 representation distribution,尤其改善 short prompt 场景。
这一点在论文 ablation 中非常关键:
- 只用
CUT(而不是ALL)时,GenEval / WISE / CVTG / ImgEdit 都更好; - 加入 Prepadding States 后,short-prompt benchmark 明显提升。
从公开实现看,VGI-refine 对应两部分代码:
find_next_token_index():找到</think>之后的切分点;ThinkGenTransformer2DModel.forward():将prepad_embed与文本 hidden states 拼接。
需要注意一个代码-论文差异:论文补充材料写的是 ,但公开推理代码中的 prepad_embed 形状为 1 x 23 x 8192。这说明当前公开仓库与论文描述之间存在一个小的不一致,读代码时应以 checkpoint/实现为准。
3.4 DiT:文本条件、参考图条件与联合注意力
在 DiT 侧,ThinkGen 把三类信息统一进 transformer:
- noisy latent(当前待去噪图像)
- refined text condition(来自 MLLM)
- optional reference image latents(image editing / in-context generation 时)
论文强调,作者最后选用的是简单 linear connector,而不是 MLP 或更复杂的 transformer connector。补充材料进一步说明,该 connector 将 Qwen3-VL-8B-Think 最后两层 hidden states 拼接后的 8192 维特征映射到 2520 维,以匹配 DiT 的条件输入需求;补充实验也显示,Linear 在 Stage1 上优于 MLP / Transformer connector。
公开代码中,DiT 的实现位于 ThinkGen/models/transformers/transformer_thinkgen.py,关键机制包括:
x_embedder:把 noisy latent patch 投影到 transformer hidden space;ref_image_patch_embedder:把参考图 latent patch 投影到相同空间;image_index_embedding:给不同参考图加上区分性 embedding;context_refiner/noise_refiner/ref_image_refiner:分别细化 text / noise / reference-image token;- joint hidden states 拼接后进入主干 transformer blocks。
3.5 训练配方:3 个 supervised stage + 2 个 RL stage

Figure 4 解读:这张图展示了 ThinkGen 的五阶段训练流程。前三阶段是 supervised pre-training:先只训练 connector 完成 MLLM–DiT 对齐,再做 60M 规模的预训练,最后用 0.7M 高质量子集做高分辨率微调;后两阶段是 SepGRPO:先固定 DiT 做 MLLM-GRPO,让 MLLM 学会生成更适合 DiT 的指令;再固定 MLLM 做 DiT-GRPO,让 DiT 在这些指令上继续提升生成质量。图里最重要的信号是,作者并没有尝试“一次性联合优化所有参数”,而是把 credit assignment 拆开处理。
五个阶段分别是:
- Stage1 Alignment:只训练 connector,引入 learnable Prepadding States,对齐 MLLM 与 DiT;
- Stage2 Pre-training:训练全部 DiT 参数,使用约 60M 图像样本;
- Stage3 High-quality fine-tuning:用 0.7M 高质量数据做 1024 分辨率微调;
- Stage4 MLLM-GRPO:固定 DiT,对 MLLM 做多场景 GRPO;
- Stage5 DiT-GRPO:固定 MLLM,对 DiT 做 FlowGRPO 风格优化。
SepGRPO 训练场景共 5 类:
| Scenario | Dataset | Rule Model |
|---|---|---|
| Semantic composition | 5K semantic prompts | GenEval |
| Reasoning generation | 10K reasoning prompts | HPSv3 |
| Text rendering | 3K text rendering prompts | Word Accuracy |
| Image editing | 3K editing samples | SigLIP2 |
| Reflection | 3K reflection samples | NED |
3.6 关键公式
(1) Rectified Flow / Flow Matching loss
其中
这对应 Stage1–3 中 DiT 的监督训练目标。
(2) Group-relative advantage
对于同一输入的 个 MLLM rollout,奖励归一化为:
(3) GRPO 目标
其中 clipped surrogate 项为:
这里 是当前策略与旧策略在 token 级别的概率比。
3.7 SepGRPO 的实现细节
补充材料给出的 RL 细节如下:
- 训练分辨率:
- rollout 去噪步数:20 steps
- CFG:4,仅在前 60% steps 开启
- (MLLM rollout 数)
- (DiT rollout 数)
- DiT-GRPO 只对前 60% denoising steps 回传梯度
作者显式采用 Denoising Reduction 来降低 RL 数据收集成本,这一点继承自 Flow-GRPO。
3.8 基于公开代码的伪代码
说明:截至 2026-03-11,公开仓库已提供 推理代码与模型权重,但未公开 SepGRPO 的完整训练脚本。因此下面的伪代码严格对应已发布实现;对于 Stage4/5 的训练流程,本文仅保留论文公式与文字说明,不伪造代码细节。
伪代码 1:CoT prompt 构造与 hidden-state 提取
# file: ThinkGen/pipelines/pipeline_thinkgen.py
def build_cot_condition(instruction, input_images, think):
prompt = apply_chat_template([
{"role": "system", "content": SYS_PROMPT},
{"role": "user", "content": add_image_tokens(input_images) + instruction},
])
if think:
prompt = prompt + "<|im_start|>assistant\n<think>\n"
generated = mllm.generate(
prompt,
output_hidden_states=True,
return_dict_in_generate=True,
max_new_tokens=4096,
)
hidden = concat_last_two_layers(generated.hidden_states)
split_idx = find_next_token_index(generated.sequences, split_seq=[151668])
cond_hidden = hidden[:, split_idx:]
cond_ids = generated.sequences[:, split_idx:]
output_text = decode_new_tokens(generated.sequences)
else:
prompt = prompt + "<|im_start|>assistant\n<think>\n</think>" + instruction
tokens = tokenizer(prompt)
hidden = mllm(tokens, output_hidden_states=True).hidden_states
hidden = concat(hidden[-2], hidden[-1], dim=-1)
split_idx = find_next_token_index(tokens.input_ids, split_seq=[151668])
cond_hidden = hidden[:, split_idx:]
cond_ids = tokens.input_ids[:, split_idx:]
output_text = ""
return cond_hidden, cond_ids, output_text伪代码 2:VGI-refine(CUT + Prepadding)
# file: ThinkGen/models/transformers/transformer_thinkgen.py
def vgi_refine(text_hidden_states, text_attention_mask, prepad_embed, prepad_mask):
bs = text_hidden_states.shape[0]
prepad = repeat(prepad_embed, bs, axis=0)
prepad_attn = repeat(prepad_mask, bs, axis=0)
refined_states = concat([prepad, text_hidden_states], dim=1)
refined_mask = concat([prepad_attn, text_attention_mask], dim=1)
return refined_states, refined_mask伪代码 3:DiT 采样与双条件 CFG 融合
# file: ThinkGen/pipelines/pipeline_thinkgen.py
def generate_with_dit(prompt_embeds, neg_prompt_embeds, input_images, steps, seed):
ref_latents = encode_reference_images_with_vae(input_images)
latents = randn(seed=seed)
timesteps = scheduler.set_timesteps(steps)
for i, t in enumerate(timesteps):
pred = transformer(latents, t, prompt_embeds, ref_latents)
if text_guidance_scale > 1.0 and image_guidance_scale > 1.0:
pred_ref = transformer(latents, t, neg_prompt_embeds, ref_latents)
pred_uncond = transformer(latents, t, neg_prompt_embeds, None)
pred = pred_uncond \
+ image_guidance_scale * (pred_ref - pred_uncond) \
+ text_guidance_scale * (pred - pred_ref)
elif text_guidance_scale > 1.0:
pred_uncond = transformer(latents, t, neg_prompt_embeds, None)
pred = pred_uncond + text_guidance_scale * (pred - pred_uncond)
latents = scheduler.step(pred, t, latents)
image = vae.decode(latents)
return image3.9 Code-to-paper mapping
| Paper Concept | Source File | Key Class / Function |
|---|---|---|
| 用户侧统一接口 | ThinkGen/model.py | ThinkGen_Chat, generate_image() |
| CoT chat template | ThinkGen/pipelines/pipeline_thinkgen.py | _apply_chat_template() |
只截取 </think> 之后的 hidden states | ThinkGen/pipelines/pipeline_thinkgen.py | find_next_token_index(), _get_qwen3_prompt_embeds() |
| VGI-refine 的 Prepadding States | ThinkGen/models/transformers/transformer_thinkgen.py | prepad_embed, prepad_mask, forward() |
| 文本/噪声/参考图联合建模 | ThinkGen/models/transformers/transformer_thinkgen.py | img_patch_embed_and_refine() |
| 参考图编码 | ThinkGen/pipelines/pipeline_thinkgen.py | prepare_image(), encode_vae() |
| 采样主循环与 CFG 融合 | ThinkGen/pipelines/pipeline_thinkgen.py | processing(), predict(), __call__() |
| Scheduler | ThinkGen/schedulers/scheduling_flow_match_euler_discrete.py | FlowMatchEulerDiscreteScheduler |
| 可选 DPM-Solver++ | ThinkGen/schedulers/scheduling_dpmsolver_multistep.py | DPMSolverMultistepScheduler |
| SepGRPO 训练脚本 | 公开仓库未找到 | 截至 2026-03-11 未公开 |
4. Experimental Setup(实验设置)
4.1 训练数据
监督训练的数据构成如下:
- Text-to-image:约 51M 样本(补充材料);
- Text rendering:约 3M 样本;
- Image editing:约 5M 样本;
- In-context generation:约 0.2M 样本;
- Stage3 高质量子集:0.7M;
- 论文正文还给出一个更粗粒度表述:Stage2 训练语料总计约 60M 图像样本。
SepGRPO 使用的多场景数据为:
- 5K semantic prompts
- 10K reasoning prompts
- 3K text rendering prompts
- 3K editing samples
- 3K reflection samples
4.2 评测 benchmark
- WISEBench:1000 prompts,评估 reasoning generation
- RISEBench:360 pairs,评估 reasoning editing
- GenEval:553 prompts,评估 compositional T2I
- DPG-Bench:1065 prompts,评估长文本生成能力
- CVTG:2000 prompts,评估 text rendering
- ImgEdit:737 pairs,评估 image editing
4.3 Baselines
论文比较了大量 generation-only 与 unified generation-understanding 模型,包括:
- generation-only:SDXL, SD3-Medium / SD-3.5-large, FLUX.1-dev, PixArt-, Sana-1.6B, TextCrafter, Step1X-Edit 等
- unified / multimodal:Janus-Pro, BLIP3-o-8B, BAGEL, OmniGen2, UniWorld, VILA-U, MetaQuery-XL 等
- closed-source 参照:GPT-4o, Gemini-2.0
4.4 指标与训练配置
评测指标:
- WISEBench / RISEBench:各 benchmark 的官方 score
- GenEval:Counting / Position / Overall
- DPG:Global / Entity / Attribute / Relation / Overall
- CVTG:Word Accuracy, NED
- ImgEdit:多编辑类型人工/模型评分综合结果
模型与训练配置:
- MLLM:Qwen3-VL-8B-Think
- DiT:OmniGen2-DiT-4B
- 训练目标:Rectified Flow / Flow Matching
- Stage1 / 2 / 3 超参数:
- LR: / /
- Batch size:512 / 1280 / 64
- Steps:47K / 100K / 11K
- Resolution: / /
- RL 阶段:,20 denoising steps,,
硬件说明:论文没有明确给出 GPU 型号、卡数或总训练时长,属于实现细节中的信息缺口。
5. Experimental Results(实验结果)
5.1 主结果
(1) Reasoning generation:WISEBench
- ThinkGen:0.55
- ThinkGen*:0.76
- 最强开源对比(同类表内):BAGEL* 为 0.70,STAR 为 0.66
- closed-source GPT-4o:0.80
结论:开启 CoT 后,ThinkGen 在 WISE 上提升 +0.21,并把开源方法上限推到接近 GPT-4o 的水平。
(2) Reasoning editing:RISEBench
- ThinkGen:3.6
- ThinkGen*:13.0
- 最强开源对比:BAGEL* 为 11.9
- Gemini-2.0:13.3
- GPT-4o:28.9
结论:ThinkGen 在 reasoning editing 上提升非常明显(3.6 13.0),已经接近 Gemini-2.0,但距离 GPT-4o 仍有明显差距,尤其 logical reasoning 子项仍只有 1.1。
(3) Text-to-image / long prompt / text rendering
| Model | GenEval Overall | DPG Overall | CVTG Acc. | CVTG NED |
|---|---|---|---|---|
| BAGEL | 0.82 | 85.07 | 0.35 | 0.65 |
| OmniGen2 | 0.80 | 83.57 | 0.52 | 0.77 |
| ThinkGen | 0.88 | 85.14 | 0.80 | 0.91 |
| ThinkGen* | 0.89 | 85.87 | 0.84 | 0.94 |
结论:ThinkGen 在 GenEval / DPG / CVTG 上都很强,尤其 text rendering 提升最显著,CVTG Accuracy 从 0.80 提到 0.84,远高于 BAGEL 的 0.35。
(4) Image editing:ImgEdit
- ThinkGen:4.14
- ThinkGen*:4.21
- GPT-4o:4.20
- OmniGen2:3.44
- UniWorld:3.26
结论:ThinkGen* 在 ImgEdit 上整体达到表中最高分,略高于 GPT-4o。
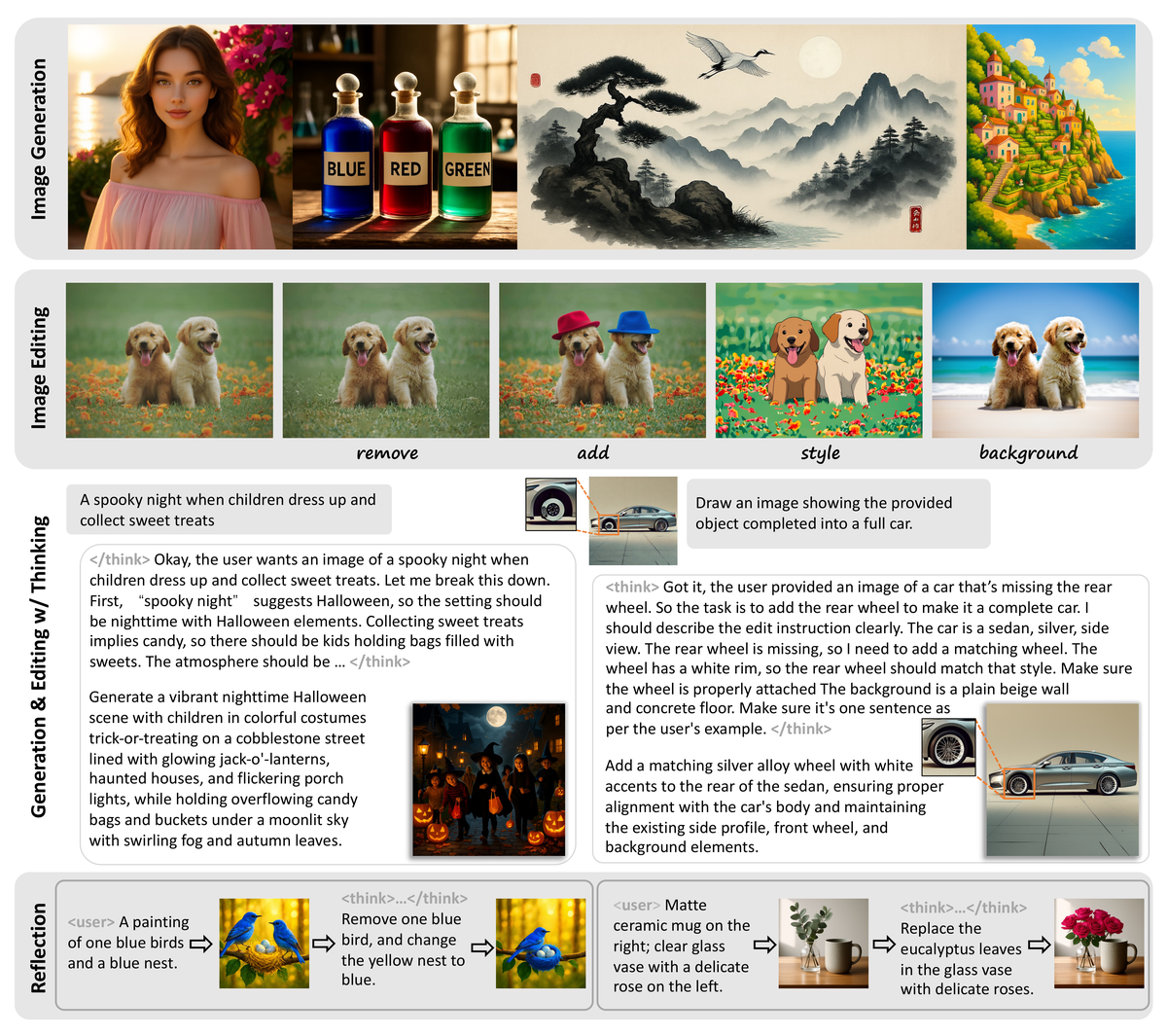
Figure 2 解读:这张 teaser 直观展示了 ThinkGen 的任务覆盖面。最上方是 image generation,中间是 image editing,下面两行是 reasoning generation / reasoning editing / reflection。它想传达的重点不是“单个样例很漂亮”,而是 同一个框架可以在多种生成场景里都使用 think-driven instruction,这是本文相对特定场景 CoT 方法的真正卖点。
5.2 消融实验
(1) 训练阶段消融
| Stage | GenEval | WISE | CVTG |
|---|---|---|---|
| Stage1 Alignment | 0.78 | 0.46 | 0.28 |
| Stage2 Pre-training | 0.88 | 0.55 | 0.63 |
| Stage3 H.Q. Tuning | 0.88 | 0.55 | 0.75 |
| Stage4 MLLM-GRPO | 0.86 | 0.54 | 0.75 |
| Stage4 MLLM-GRPO* | 0.86 | 0.76 | 0.79 |
| Stage5 DiT-GRPO* | 0.89 | 0.76 | 0.84 |
关键信息:
- Stage2 解决的是基础生成质量;
- Stage3 解决的是高质量与 text rendering;
- Stage4 真正带来 reasoning boost;
- Stage5 再把 instruction-following 与 rendering 继续抬高。
(2) Prepadding States 有效性
- GenEval:0.64 0.78
- WISE:0.37 0.46
- CVTG:0.24 0.28
- ImgEdit:3.46 3.93
- DPG:80.90 80.86(几乎持平)
说明 Prepadding States 主要提升的是 short-prompt / 对齐敏感任务,对 long-prompt DPG 几乎没有副作用。
(3) CUT vs ALL(VGI-refine)
CUT:GenEval 0.78 / WISE 0.46 / CVTG 0.28 / ImgEdit 3.93ALL:GenEval 0.66 / WISE 0.31 / CVTG 0.18 / ImgEdit 3.43
这说明“把整个 CoT hidden states 全送进 DiT”是有害的,作者关于“CoT 冗余需要裁剪”的判断是成立的。
(4) 训练策略对比
- Stage3 baseline:GenEval 0.88 / WISE 0.55 / CVTG 0.75
- 10K reasoning data 直接做 SFT:0.85 / 0.58 / 0.67
- 10K reasoning data 做 MLLM-GRPO:0.80 / 0.74 / 0.73
- 24K multitask data 做 MLLM-GRPO:0.86 / 0.76 / 0.79
说明:提升 reasoning generation 的关键不是“多喂 reasoning 数据”,而是 MLLM-GRPO 这种 reward-driven 学习方式。

Figure 5 解读:这张图可视化了 MLLM-GRPO 的训练过程。横轴是训练步数,图中同时展示了 reward score、CoT length 和生成图像样例。可以看到随着训练推进,reward 稳步上升、CoT 长度增加,而图像质量也逐渐改善。它说明作者的 SepGRPO 并不是仅靠最终 benchmark 提升“碰巧有效”,而是在训练动态上也表现出越来越会思考、越来越会生成的趋势。
5.3 局限性
- 训练代码未公开:公开仓库目前主要是 inference code + weights,SepGRPO 的完整训练实现无法复现;
- 论文缺少硬件信息:没有明确 GPU 型号、卡数与训练时长;
- reasoning editing 仍未逼近 GPT-4o:尤其 logical reasoning 子项很弱;
- 代码/论文存在轻微不一致:例如 Prepadding States 的 值,论文补充材料写 25,公开代码看起来是 23。
5.4 总结
ThinkGen 最有价值的地方,不只是把 CoT 搬进视觉生成,而是提出了一个可泛化的“先想再画”范式:
- MLLM 负责 reasoning 与 instruction rewrite;
- VGI-refine 负责把冗余 CoT 压缩成对 DiT 有用的条件;
- SepGRPO 负责分别优化“想得对”和“画得好”。
从结果看,ThinkGen 在 reasoning generation、text rendering、image editing 上都很强;从方法看,它为后续把 RL、MLLM、DiT 组合到统一视觉生成框架里提供了一个非常清晰的模板。