Streaming Video Question-Answering with In-context Video KV-Cache Retrieval
Authors: Shangzhe Di, Zhelun Yu, Guanghao Zhang, Haoyuan Li, Tao Zhong, Hao Cheng, Bolin Li, Wanggui He, Fangxun Shu, Hao Jiang Affiliations: Shanghai Jiao Tong University, Alibaba Group arXiv: 2503.00540 Project Page: proceedings.iclr.cc/paper_files/paper/2025/hash/67a9b444cbcd647572c88194619f72d5-Abstract-Conference.html GitHub: Becomebright/ReKV
1. Motivation (研究动机)
这篇论文研究的是 Streaming Video Question-Answering (StreamingVQA):视频流持续到来,模型需要一边看、一边记,并且能在任意时刻立刻回答关于过去内容的问题。
作者指出,现有 Offline VideoQA / Video-LLM 方法直接迁移到 streaming 场景会遇到三类核心矛盾:
- 编码效率不足:传统方法通常在提问后再处理整段视频,视频越长,视觉 token 越多,计算和显存开销越难承受;
- 上下文保留困难:如果只做稀疏采样或强压缩,很多细粒度时序信息会丢失,而这些信息恰恰决定了长视频问答的正确性;
- 重复计算严重:用户在不同时间提出不同问题时,传统方法往往要重新抽帧、重新编码,随着视频长度 和问题数 增大,代价会快速上升。
因此,论文要解决的问题是:如何在不重新训练 Video-LLM 的前提下,把长视频理解从“每次问答都重新看一遍视频”改造成“视频只编码一次,问答时按需取回相关历史证据”。
这个问题非常值得研究,因为真实场景中的机器人、安防监控、直播助手、AR 眼镜,面对的都不是静态短视频,而是持续不断的视频流 + 随时到来的交互问题。
2. Idea (核心思想)
ReKV 的核心思想可以概括成一句话:把视频流编码阶段与问答阶段解耦,前者用 sliding-window attention 增量建模并保存 Video KV-Cache,后者只检索与当前问题最相关的 KV 块,再基于这些块完成回答。
更具体地说,ReKV 有三个关键创新:
- 训练-free 接入现有 Video-LLM:不改训练目标,不做额外训练,而是直接 patch 现有 decoder attention;
- 局部编码 + 全局存档:新来的帧只与最近窗口交互,窗口外的 KV 被转存到 RAM / disk,因此视频可以持续编码;
- 按问题检索历史 KV:问答时不把全部历史帧送进模型,而是通过 external / internal retrieval 只取回最相关的若干帧或块。
与 Flash-VStream / VideoStreaming 这类“把视频压进固定 memory token”的方法相比,ReKV 的根本差异在于:它不把历史信息压缩成一个小 memory bank,而是保留更原始、更可检索的中间状态(KV-Cache)。因此它的解释性更强,也更适合细粒度长时序问答。
3. Method (方法)
3.1 Task definition 与整体框架
论文首先把 StreamingVQA 定义为:给定视频流 和问题集合 ,模型需要在任意时刻 ,只依赖已经看到的前缀视频 来回答当前问题 。
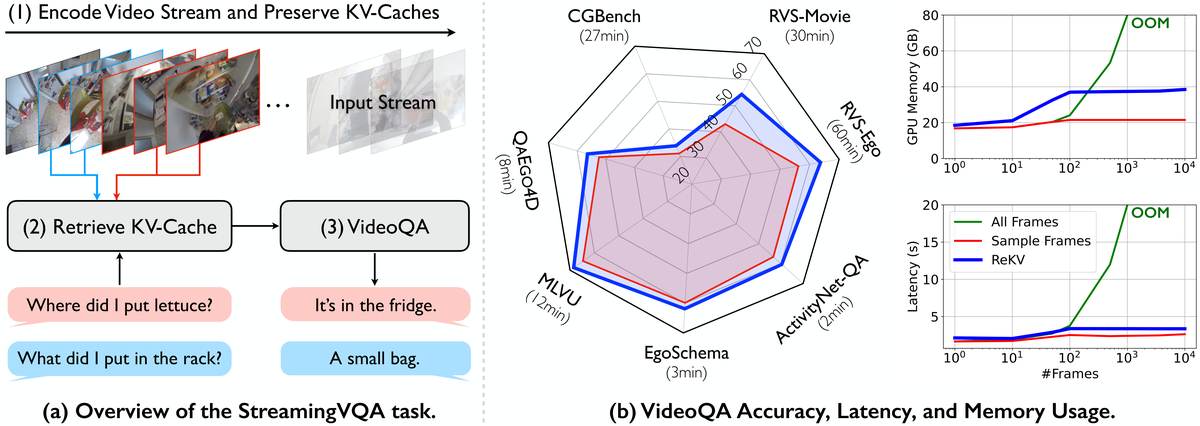
Figure 1 解读: Figure 1 对 ReKV 的目标场景做了最直观的说明。左侧展示 StreamingVQA 的交互方式:视频流持续输入,系统先不断编码并保存 KV-Cache;当用户在不同时间点提问时,系统先检索相关 KV,再做 VideoQA。右侧雷达图显示 ReKV 在多个长视频 benchmark 上整体优于 uniform sampling 基线;两张折线图则说明随着视频帧数增长,ReKV 的 GPU memory 与 latency 基本保持稳定,而“全部帧直接进模型”的方案很快 OOM。也就是说,Figure 1 把整篇论文的目标讲清楚了:不是只追求离线精度,而是同时追求 streaming 场景里的可扩展性、实时性与精度。

Figure 2 解读: Figure 2 是 ReKV 的核心架构图,分成三步:(a) 视频流编码阶段,输入帧在 decoder 中采用 sliding-window attention,窗口外的 Video KV-Cache 被离载到 RAM / disk;(b) 当问题到来后,系统先把问题和历史视频块做 cosine similarity 匹配,只挑出最相关的若干块;(c) 被挑中的 KV 块再被加载回 GPU,和问题 token 一起作为上下文进行自回归回答。这个图最重要的含义是:视频编码与问题回答被明确拆成了两个阶段,这使得同一段视频只需要编码一次,而不同问题只需重复做轻量的检索与解码。
3.2 Video stream encoding with sliding-window attention
ReKV 增量处理视频流。设当前 chunk 的 token 为 ,过去的 KV 为 ,则局部窗口中的 KV 为 。编码时注意力写成:
这里的关键点有两个:
- 只看最近窗口 :新来的 video token 只和局部历史交互,避免注意力复杂度随视频无限增长;
- 全部历史 KV 仍被保存:窗口外 token 虽然不再参与当前编码,但它们的 KV 会被离载保存,供后续问题检索使用。
公开代码里,这一过程对应:
model/abstract_rekv.py::_encode_video_chunk:逐 chunk 提取视觉特征并送入 language model;model/patch.py::patch_hf:把 HuggingFace attention 替换成 ReKV 的 attention;model/attention/rekv_attention.py::rekv_attention_forward:实现编码时的 sliding-window attention 与问答时的 retrieval mode 分流;model/attention/kv_cache_manager.py::ContextManager.append:管理 local KV、global remainder、block offloading 与 GPU/CPU 迁移。
从实现看,LLaVA-OneVision 版本每帧默认有 196 个 visual tokens;默认 n_local=15000,retrieve_size=64,chunk_size=1,并把 max_cached_block=128 个 block 保留在 GPU cache 池中,其余用 MemoryUnit 离载到 CPU memory / pinned memory。需要注意:论文文字写的是 RAM / disk offload,但公开主分支里我能确认的显式实现主要是 CPU(RAM) 侧离载。
3.3 Video KV-Cache retrieval
3.3.1 External retrieval
论文先给了一个外部检索基线:用 CLIP / SigLIP 这类外部模型,把视频帧编码成 ,把问题编码成 ,然后做 cosine similarity:
若把连续 帧先平均成 block,则再在 block 级别做排序,最后取 top- 帧或 个块。论文实验里外部检索默认使用 SigLIP-SO400M。
需要特别说明的是:公开仓库并没有放出 external retriever 的完整脚本。代码只保留了 retrieved_indices 注入接口,即可以把“外部检索得到的 block/frame 索引”传给 question_answering(..., retrieved_indices=...)。因此,external retrieval 的公式与流程来自论文正文,源码级实现细节在公开仓库中并不完整。
3.3.2 Internal retrieval
内部检索更有意思:作者直接复用 Video-LLM 自身 self-attention 里的 key / query 表示来做检索,而不额外引入 retriever。
对第 个 frame 的所有 key 向量做平均,得到 frame representation:
对问题 token 的 query 向量求平均,得到问题表示:
然后同样按相似度选 top-。实现上,ContextManager 会把每个 offloaded block 的代表向量存入 block_k,并在 _calc_block_topk 中按 chunk 聚合后做 top-k 检索。论文公式写成 cosine similarity;但公开实现里的 VectorTensor.get_cosine_similarity() 实际执行的是未归一化的 torch.matmul,更接近 dot-product matching。这个设计有三个实现层面的好处:
- 零额外参数:不需要单独训练检索器;
- 逐层检索:不同层可以检索不同 block,保留更丰富的上下文;
- 低额外开销:直接重用模型已有的 query/key。
3.4 Question answering using retrieved KV
检索到的视频 KV 记作 ,回答阶段的注意力写成:
其中 可以是问题 token,也可以是解码阶段当前生成 token。源码里,model/llava_onevision_rekv.py::question_answering 的流程是:
- 先只输入问题文本,打开 retrieval mode;
- 如果
retrieved_indices is None,就走内部检索;否则按外部检索给的索引装载 block; - 用得到的
past_key_values作为问答上下文,再输入完整 prompt; - 最后做逐 token 自回归生成,直到 EOS 或达到
max_new_tokens。
论文在 positional encoding 上也做了一个重要选择:检索回来的视频 token 不再保留原始绝对位置,而是当作连续 token 重新排列。作者报告说,对 retrieved video token 使用普通 RoPE 比 static 同位置策略更好,因为视频问答仍然需要保留一定的时序感。
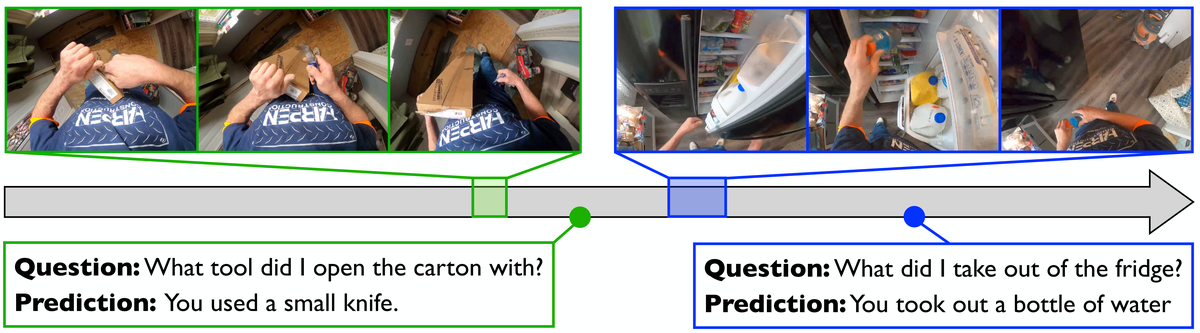
Figure 5 解读: Figure 5 给了一个很有代表性的定性案例。时间轴上有两个提问时刻:绿色问题询问“用什么工具打开纸箱”,蓝色问题询问“从冰箱里拿出了什么”。图中对应颜色的框标出了被检索到的相关视频上下文,模型分别回答出“小刀”和“一瓶水”。这张图非常关键,因为它展示了 ReKV 并不是简单记住一个压缩摘要,而是真的能在很长的视频轨迹里按问题回溯到相关时刻。
3.5 Pseudocode(基于公开实现)
3.5.1 流式任务调度(对应 video_qa/rekv_stream_vqa.py)
from torch import from_numpy
def analyze_stream_video(video_sample, qa_model, sample_fps):
video = load_video(video_sample["video_path"])
video = from_numpy(video)
qa_model.clear_cache()
qa_model.encode_init_prompt()
encoded_until = 0
for qa in video_sample["conversations"]:
end_idx = int(qa["end_time"] * sample_fps)
if end_idx > encoded_until:
qa_model.encode_video(video[encoded_until:end_idx])
encoded_until = end_idx
pred = qa_model.question_answering(
{
"question": qa["question"],
"prompt": qa_model.get_prompt(qa["question"]),
},
max_new_tokens=256,
)
save_result(qa, pred)3.5.2 视频编码与 KV 离载(对应 Abstract_ReKV.encode_video + ContextManager.append)
@torch.inference_mode()
def encode_video(video, encode_chunk_size=64):
for chunk in split_video(video, encode_chunk_size):
pixel_values = processor.video_processor(chunk, return_tensors="pt")
pixel_values = pixel_values.pixel_values_videos.to(device, dtype)
video_features = get_video_features(pixel_values) # (1, Nv * 196, D)
output = language_model(
inputs_embeds=video_features,
past_key_values=kv_cache,
use_cache=True,
return_dict=True,
)
kv_cache = output.past_key_values # each layer owns a ContextManager
def context_manager_append(local_q, local_k, local_v, global_q, global_k, global_v):
init_if_needed(local_q, local_k, local_v, global_q, global_k, global_v)
local_cache.append(local_k, local_v)
global_remainder.append(global_k, global_v)
global_q = rope_one_angle(global_q, index=n_local)
outputs = []
for token_block in split_by_exc_block_size(local_q):
chunk_o = local_window_attention(
q=token_block,
local_kv=last_n_local_tokens(local_cache),
init_kv=init_cache,
)
outputs.append(chunk_o)
offload_full_blocks_to_cpu_and_store_block_repr(global_remainder)
trim_local_cache_to_last_n_local_tokens()
keep_unoffloaded_tail_in_global_remainder()
return concat(outputs)3.5.3 内部检索(对应 ContextManager._calc_block_topk / get_retrieved_kv)
def internal_retrieve(question_ids, kv_cache):
for layer_kv in kv_cache:
layer_kv.set_retrieval()
out = language_model(
input_ids=question_ids,
use_cache=True,
past_key_values=kv_cache,
)
for layer_kv in kv_cache:
layer_kv.reset_retrieval()
return out.past_key_values
def calc_block_topk(global_h_q, block_k, topk, chunk_size):
query_repr = mean_over_question_tokens(global_h_q) # (B, num_heads, dim_head)
query_repr = flatten_heads(query_repr) # (B, D')
logits = cosine_or_dot_similarity(query_repr, block_k) # (B, n_blocks)
chunk_logits = average_by_chunk(logits, chunk_size)
selected_chunks = topk_indices(chunk_logits, k=topk // chunk_size)
block_indices = expand_chunks_to_block_indices(selected_chunks, chunk_size)
return sort_and_clip(block_indices)
def get_retrieved_kv(query=None):
if query is not None:
retrieved_block_indices = calc_block_topk(query, block_k, topk, chunk_size)
load_init_kv_into_global_buffer()
load_selected_blocks_from_cpu_to_gpu(retrieved_block_indices)
return global_buffer_k, global_buffer_v3.5.4 基于检索 KV 的回答生成(对应 LlavaOneVision_ReKV.question_answering)
@torch.inference_mode()
def question_answering(input_text, max_new_tokens=128, retrieved_indices=None):
question_ids = tokenizer(input_text["question"])
for layer_kv in kv_cache:
layer_kv.set_retrieval()
if retrieved_indices is None:
out = language_model(input_ids=question_ids, use_cache=True, past_key_values=kv_cache)
else:
for layer_kv in kv_cache:
layer_kv.set_retrieved_block_indices(retrieved_indices)
out = language_model(input_ids=question_ids, use_cache=True, past_key_values=kv_cache)
retrieved_past = out.past_key_values
for layer_kv in kv_cache:
layer_kv.reset_retrieval()
prompt_ids = tokenizer(input_text["prompt"])
out = language_model(
inputs_embeds=get_input_embeddings()(prompt_ids),
use_cache=True,
past_key_values=retrieved_past,
)
output_ids = []
for step in range(max_new_tokens):
token = greedy_top1(out.logits[:, -1, :])
output_ids.append(token)
if token == eos_token_id:
break
out = language_model(input_ids=[[token]], use_cache=True, past_key_values=out.past_key_values)
return tokenizer.decode(output_ids, skip_special_tokens=True)3.6 Code-to-paper mapping table
| Paper Concept | Source File | Key Class / Function |
|---|---|---|
| 训练-free 的 ReKV 基类 | model/abstract_rekv.py | Abstract_ReKV, encode_init_prompt, encode_video, _encode_video_chunk |
| 将 HF attention 替换为 ReKV attention | model/patch.py | patch_hf |
| 编码阶段 / 检索阶段共享的 attention 前向 | model/attention/rekv_attention.py | rekv_attention_forward |
| KV-Cache 管理、离载、内部检索 | model/attention/kv_cache_manager.py | ContextManager.append, _append_global, _calc_block_topk, get_retrieved_kv |
| ReKV 的 RoPE 适配 | model/attention/rope.py | RotaryEmbeddingESM, apply_rotary_pos_emb_one_angle |
| LLaVA-OneVision 上的问答实现 | model/llava_onevision_rekv.py | LlavaOneVision_ReKV.question_answering, load_model |
| OfflineVQA 评测流程 | video_qa/rekv_offline_vqa.py | ReKVOfflineVQA.analyze_a_video |
| StreamingVQA 评测流程 | video_qa/rekv_stream_vqa.py | ReKVStreamVQA.analyze_a_video |
| 外部检索结果注入接口 | model/llava_onevision_rekv.py | question_answering(..., retrieved_indices=...) |
说明:公开仓库中没有完整放出 external retriever(例如 SigLIP 检索器)脚本;但保留了把外部检索索引注入问答阶段的接口。另外,仓库主实现能直接确认的是 GPU ↔ CPU(RAM/pinned memory) 离载,未看到独立的磁盘级 KV 存储类。因此 external retrieval 的数学形式主要来自论文,源码映射只能精确到接口层。
4. Experimental Setup (实验设置)
4.1 Datasets
论文覆盖了 offline 与 streaming 两类长视频问答 benchmark:
| Benchmark | 平均时长 | 视频数 | QA 数 | 类型 |
|---|---|---|---|---|
| MLVU | 12 min | 1,242 | 2,175 | MC |
| QaEgo4D | 8.3 min | 148 | 500 | MC |
| EgoSchema | 3 min | 5,031 | 5,031 | MC |
| ActivityNet-QA | 2 min | 800 | 8,000 | OE |
| RVS-Ego | 60 min | 10 | 1,465 | OE |
| RVS-Movie | 30 min | 22 | 1,905 | OE |
| CGBench | 27 min | 1,219 | 12,129 | MC |
其中:
- MLVU 强调 long-form 多类型推理;
- QaEgo4D 是长 egocentric 视频问答,并带有相关时间段标注;
- RVS-Ego / RVS-Movie 是真正的 StreamingVQA benchmark,问题带时间戳;
- CGBench 很适合检索型视频问答,因为它要求找到 clue-grounded evidence。
4.2 Baselines 与比较对象
主实验把 ReKV 集成到:
LLaVA-OV-0.5BLLaVA-OV-7B
附录还评测了:
Video-LLaVA-7BLongVA-7BLLaVA-OV-72B
同时论文还与 VideoStreaming、Flash-VStream、LongVA、Video-LLaVA、GPT-4V、GPT-4o、Gemini-1.5 等方法做了比较。
4.3 Metrics
- 多选题:Accuracy;
- 开放问答:
gpt-3.5-turbo-0613打分的 Score (1-5),以及 Accuracy; - 检索分析:Recall / Precision / F1(论文重点报告 Recall);
- Streaming efficiency:Video Encoding FPS、Latency、GPU peak memory、KV-Cache offload size / hour。
4.4 Implementation details
论文强调 ReKV 是 training-free 的,因此没有额外训练超参数;其核心设置是推理与缓存管理:
- GPU:NVIDIA A100 80GB,FP16;
- 视频采样:0.5 FPS;
- local window size:15K tokens;
- external retrieval:SigLIP-SO400M;
- internal retrieval 默认:block size ,retrieved frames ;
- 代码默认视觉 token 数:196 tokens / frame;
- 附录给出的 1 小时视频 KV-Cache 大小:
对 LLaVA-OV-7B,在 时,理论 KV-Cache 大小为 18.8 GB / hour;
对 LLaVA-OV-0.5B,对应为 4.0 GB / hour。
5. Experimental Results (实验结果)
5.1 Offline VideoQA:在四个长视频 benchmark 上普遍提升
主结果最重要的结论是:ReKV 不需要额外训练,却能稳定提升同一个 Video-LLM backbone 的长视频问答能力。
| Method | MLVU | QaEgo4D | EgoSchema | ActivityNet-QA Acc. | ActivityNet-QA Score |
|---|---|---|---|---|---|
| LLaVA-OV-0.5B | 53.2 | 42.6 | 29.6 | 50.5 | 3.02 |
| + ReKV | 56.1 | 50.0 | 31.0 | 52.1 | 3.15 |
| LLaVA-OV-7B | 64.7 | 52.8 | 59.8 | 56.6 | 3.29 |
| + ReKV | 68.5 | 56.0 | 60.7 | 60.4 | 3.52 |
对 LLaVA-OV-7B 而言,提升分别是:
- MLVU:
+3.8 - QaEgo4D:
+3.2 - EgoSchema:
+0.9 - ActivityNet-QA Acc.:
+3.8 - ActivityNet-QA Score:
+0.23
说明 ReKV 的收益不只来自某一个 benchmark,而是对多种长视频问答任务都有效。
5.2 StreamingVQA:精度更高,同时保持稳定效率
在真正的 streaming 场景上,ReKV 同样有效,尤其 internal retrieval 在精度/效率权衡上最好。
| Retrieval Method | RVS-Ego Acc./Score | RVS-Movie Acc./Score | Video Enc. | Latency | GPU | KV-Cache |
|---|---|---|---|---|---|---|
| Flash-VStream-7B | 57.3 / 4.0 | 53.1 / 3.3 | 14 FPS | 2.4s | 20 GB | - |
| LLaVA-OV-7B Uniform | 56.2 / 3.7 | 43.0 / 3.3 | - | 2.9s | 21 GB | - |
| LLaVA-OV-7B External | 62.4 / 3.9 | 53.6 / 3.5 | 11 FPS | 5.8s | 55 GB | 18.8 GB/h |
| LLaVA-OV-7B Internal | 63.7 / 4.0 | 54.4 / 3.6 | 11 FPS | 3.3s | 38 GB | 18.8 GB/h |
这里有两个非常重要的观察:
- Internal retrieval 比 external retrieval 更实用:精度更高,同时 latency 和 GPU 占用更低;
- ReKV 明显优于 uniform sampling:说明性能提升并不是因为“多看了帧”,而是因为它成功找回了真正相关的历史上下文。
对 LLaVA-OV-0.5B,internal retrieval 也把 RVS-Ego / RVS-Movie 从 51.8 / 37.2 提升到 54.7 / 44.6。
5.3 Ablation:检索质量越高,问答越准
在 QaEgo4D 上,检索 Recall 和最终 VideoQA Accuracy 呈明显正相关:
| Model | Retrieval | VideoQA Acc. | Recall |
|---|---|---|---|
| LLaVA-OV-0.5B | Uniform Sampling | 42.6 | 6.1 |
| LLaVA-OV-0.5B | External Retrieval | 48.0 | 58.1 |
| LLaVA-OV-0.5B | Internal Retrieval | 50.0 | 63.4 |
| LLaVA-OV-0.5B | Oracle Retrieval | 52.0 | 100 |
| LLaVA-OV-7B | Uniform Sampling | 53.0 | 6.1 |
| LLaVA-OV-7B | External Retrieval | 54.2 | 58.1 |
| LLaVA-OV-7B | Internal Retrieval | 56.0 | 70.5 |
| LLaVA-OV-7B | Oracle Retrieval | 64.4 | 100 |
这组结果说明:问题不是 Video-LLM 完全不会回答,而是 baseline 根本拿不到对的问题证据。 ReKV 的本质收益,来自检索更对的历史上下文。
在 MLVU 上,LLaVA-OV-7B 的平均分从 64.7 提升到:
- External Retrieval:
66.3 - Internal Retrieval:
68.5
其中 Single Detail 与 Holistic 两类任务提升尤其明显,说明 internal retrieval 同时保住了细节与更大范围上下文。

Figure 3 解读: Figure 3 展示了“检索多少帧最合适”。随着 retrieved frames 从 8 增加到 64,QaEgo4D(蓝线)和 MLVU(红线)整体都在提升,说明更多相关证据确实有帮助;但 MLVU 在 48~64 左右基本进入平台期,80 帧甚至略降,表明太多无关上下文会开始干扰回答。这个图支持了作者的设计选择:固定取 64 帧是一个兼顾精度与开销的折中点。

Figure 4 解读: Figure 4 研究 block size 的影响。随着 block size 从 1 增大到 16,MLVU(红线)持续下降,而 QaEgo4D(蓝线)变化较小。这说明 MLVU 更依赖离散、细粒度的关键线索,而不是大块连续视频片段;也说明固定大 block 会把无关内容一起带回来,削弱检索精度。换句话说,细粒度 block 更适合复杂长视频问答。
5.4 Generalization 与复杂度
附录里,ReKV 在更多 backbone 上也有一致收益:
Video-LLaVA-7B:MLVU46.5 -> 47.2,QaEgo4D37.0 -> 37.9;LongVA-7B:MLVU57.3 -> 58.6,QaEgo4D42.8 -> 45.6;LLaVA-OV-72B:QaEgo4D53.6 -> 57.0,CGBench37.2 -> 40.5。
在公平比较中,Base+ReKV 也在大多数 benchmark 上优于 Base+Flash。此外,随着 QA 频率升高,ReKV 的每问平均计算量下降更快:
360个问题时,TFLOPs / QA:Baseline8.5,Flash-VStream13.8,ReKV Internal5.6;- 同设置下 TMACs / QA:Baseline
4.3,Flash-VStream6.8,ReKV Internal2.8。
这说明 ReKV 特别适合 高频问答 / 多并发 streaming 场景,因为视频编码只做一次,后续问答能持续复用历史计算结果。
5.5 Limitations
论文也很诚实地给出了限制:
- 极长视频下 KV-Cache 仍会持续增长,安防级超长视频仍可能让 cache 规模不可持续;
- 固定 block size 会打断视频语义连续性,未来更好的方案应按语义片段而不是固定帧数分块;
- 固定 retrieval size 不够自适应,不同问题可能需要不同数量的历史证据;
- StreamingVQA benchmark 仍然稀缺,尤其缺少高质量、精确时间标注的数据集。
总体来说,我认为这篇论文最有价值的地方不是提出了某个复杂新模块,而是把一个非常实用的系统设计原则讲清楚了:在 streaming 视频理解里,应优先复用“已经算过的中间状态”,而不是反复重看视频。 ReKV 用 KV-Cache 检索把这个原则落成了一个可运行、可扩展、还能直接接入现有 Video-LLM 的方案。