StreamKV: Streaming Video Question-Answering with Segment-based KV Cache Retrieval and Compression
Authors: Yilong Chen, Xiang Bai, Zhibin Wang, Chengyu Bai, Yuhan Dai, Ming Lu, Shanghang Zhang Affiliations: 北京大学 (State Key Laboratory of Multimedia Information Processing), 淘宝 & 天猫 (Alibaba) GitHub: sou1p0wer/StreamKV Venue: AAAI 2026
1. Motivation (研究动机)
当前 Video-LLM 主要面向离线场景(一次性输入整段视频和所有问题),在流式视频问答中会遇到几个明显问题:
- GPU 显存爆炸:长视频的 KV Cache 随帧数线性增长,导致 OOM
- 延迟不可接受:处理完全部视频后才能回答问题,无法满足自动驾驶、AR 等实时场景需求
- 历史信息检索困难:用户提问时需要快速从海量历史视觉上下文中定位相关信息
1.1 现有方法的不足:ReKV
最新方法 ReKV (Di et al., ICLR 2025) 虽然引入了 KV Cache 检索机制,但仍有三个关键问题:
- 均匀分割破坏语义连续性:将视频流均匀分段,忽略了视频内容的语义边界
- 全量存储 KV Cache:保留所有历史 KV Cache,显存消耗依然很大
- 检索机制不灵活:检索精度不高,需要检索更多帧才能覆盖相关信息
1.2 StreamKV 的解决思路
StreamKV 提出一个 training-free 的框架,核心思想是:
- 语义分割 替代均匀分割 → 更好保留语义完整性
- Guidance Prompt 驱动的压缩 → 在编码阶段就丢弃冗余 KV
- 统一的 Layer-Adaptive 选择模块 → 同时服务于压缩和检索,按层自适应分配预算
对应的整体性能对比见第 5 节,StreamKV 在准确率、显存和首帧延迟三个维度都优于 ReKV。
2. Idea (核心思想)
StreamKV 的核心想法不是“把所有历史都存下来再检索”,而是把长视频流拆成语义完整的段,并在压缩和检索两个阶段复用同一套 Layer-Adaptive 选择逻辑。
2.1 总体流程
视频处理管线(Video Processing Pipeline):
- 视频流 → 语义分割 → 得到语义段
- 每段计算 Summary Vector
- 滑动窗口编码 → 生成 frame-level KV blocks
- Guidance Prompt 驱动压缩 → 压缩后的 KV blocks 存入 KV Bank
问答管线(Question Answering Pipeline):
- 用户提问 → 提取 query vector
- Layer-Adaptive 检索 → 从 KV Bank 取出相关 KV blocks
- 拼接检索到的 KV Cache → 注意力计算 → 生成回答
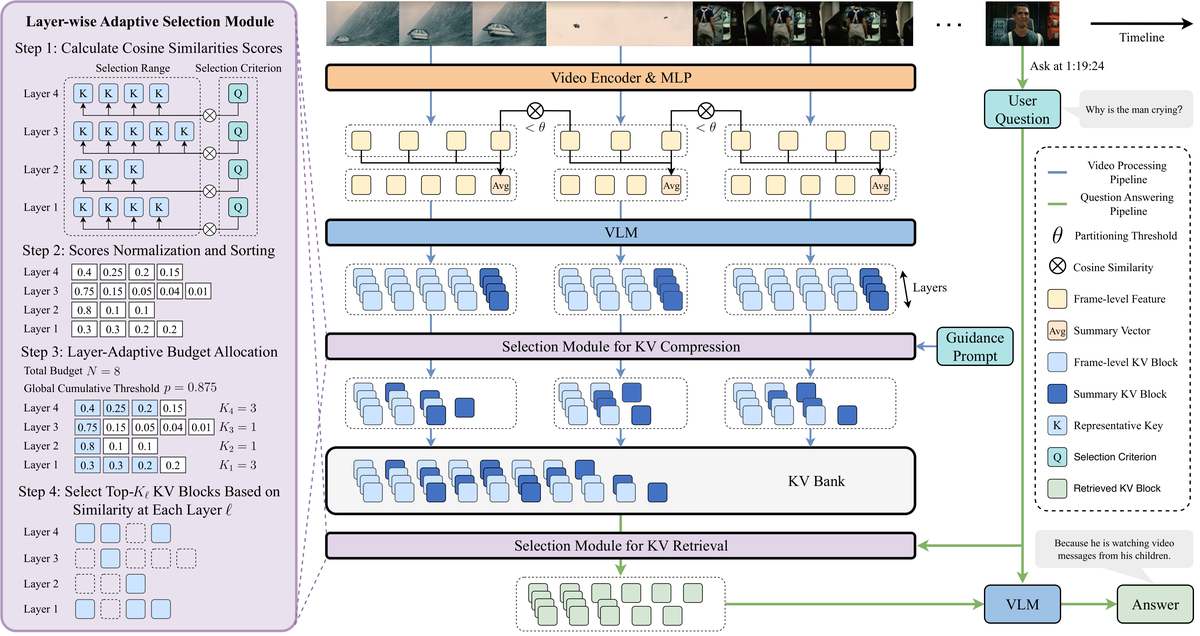
Figure 3 解读: StreamKV 完整工作流程图。上方展示视频处理管线:视频帧经 Video Encoder & MLP 提取特征后,通过余弦相似度检测语义边界( 处切分),每段计算平均特征作为 Summary Vector(灰色方块)。VLM 对每段进行编码生成 frame-level KV blocks(绿色方块)。左侧的 Selection Module for KV Compression 使用 Guidance Prompt(黄色)驱动 layer-adaptive 选择,压缩后的 KV blocks 和 Summary KV Block 一起存入 KV Bank。下方展示问答管线:用户提问后,Selection Module for KV Retrieval 根据 query 从 KV Bank 中检索最相关的 KV blocks(粉色),送入 VLM 生成回答。左侧详细展示了 Layer-wise Adaptive Selection Module 的四步流程。
3. Method (方法)
3.1 语义段分割与编码 (Semantic Segment Partitioning)
这一部分对应前文的段级表示与滑动窗口编码,是 StreamKV 生成 KV blocks 的基础。
语义边界检测
对视频帧提取 ViT 特征 ,计算相邻帧的余弦相似度:
当 (论文中 ),判定为语义边界,开始新的语义段。
段合并机制
为避免段过短(信息不足)或过长(内存压力),设定:
- 最小段长度 帧:边界附近设排除窗口
- 最大段长度 帧:超过阈值时合并最相似的相邻帧对

Figure 2a 解读: 语义分割过程示意。视频帧序列从左到右排列,每对相邻帧之间计算余弦相似度 。当 时(绿色勾号),帧属于同一语义段;当 时(红色叉号),在此处切分。图中展示了三步过程:Step 1 计算相似度,Step 2 根据阈值判断是否切分(最后一行展示了 导致分段),切分后计算每段的 Summary Vector(通过平均帧特征 )。

Figure 2b 解读: 段合并机制示意。当某段超过最大长度 时触发合并。Step 1 找到相邻帧对中相似度最高的一对(图中 0.98)。Step 2 计算这对帧的平均特征替代原来的两帧。Step 3 重新计算合并后帧与相邻帧的相似度(图中 0.92 和 0.94),从而将段长度减少 1 帧。
Summary Vector 与编码
每个语义段 计算 summary vector:
编码时采用滑动窗口注意力,将当前段与局部历史 KV 拼接:
其中 是段内帧与 summary vector 的拼接, 是局部窗口(15K tokens)内的历史 KV。
编码后得到 frame-level KV block:
代表性向量(用于后续检索/压缩的匹配):
3.2 统一 Layer-Adaptive KV 选择模块
这是 StreamKV 的核心创新,同时服务于压缩和检索两个场景。
核心思想
不同 Transformer 层的信息分布不同:某些层的注意力更集中(少量 KV 即可覆盖关键信息),某些层更分散(需要保留更多)。因此应按层自适应分配预算,而非均匀分配。
算法流程(4 步)
Step 1: 计算余弦相似度 对第 层,计算每个候选 representative key 与选择准则向量 的相似度 。
Step 2: Softmax 归一化与排序
按降序排列得到优先级序列。
Step 3: Layer-Adaptive 预算分配
对每层定义:
通过二分搜索找全局阈值 ,使所有层的预算总和等于总预算 :
Step 4: 按层选择 Top- KV Blocks
伪代码
def binary_search_threshold(N: int, sim_sorted: dict, eps: float = 1e-6) -> float:
"""Binary search for global threshold p that distributes budget N across layers.
Args:
N: total KV block budget across all layers
sim_sorted: {layer_l: sorted_softmax_similarities} for all layers
eps: convergence tolerance
Returns:
optimal threshold p
"""
p_lo, p_hi = 0.0, 1.0
while p_hi - p_lo > eps:
p = (p_lo + p_hi) / 2.0
# Compute per-layer budget: min k such that cumsum >= p
total = 0
for l, sims in sim_sorted.items():
cumsum = 0.0
for k, s in enumerate(sims, 1):
cumsum += s
if cumsum >= p:
total += k
break
else:
total += len(sims) # all tokens needed
delta = total - N
if delta == 0:
return p
elif delta < 0:
p_lo = p # need higher threshold to use more budget
else:
p_hi = p # need lower threshold to reduce budget
return p统一选择函数:
3.3 KV 压缩 (Guidance Prompt)
核心问题: 在流式场景中,压缩发生在用户提问之前,不能依赖 query 来指导压缩。
解决方案: 设计 Guidance Prompt,捕获每段的关键语义元素:
- 显著实体 (salient entities): 人、物体、位置、关键视觉概念
- 关键事件与动作 (key events and actions): 发生了什么、何时、何地
- 时间和因果关系 (temporal and causal relationships): 事件如何展开
- 上下文线索 (contextual cues): 场景变化、对话、叙事转移
- 重要数值/事实细节 (numerical or factual details): 用于计数、总结、事实问答
压缩时的选择准则向量:(guidance prompt 的平均 query vector)
压缩预算:,其中 是压缩率
压缩后更新 KV Bank(保留 summary KV block 不压缩):
3.4 KV 检索与问答
用户提问时,选择准则向量变为 query 的平均向量:
检索预算:( 为每层期望检索的帧数,默认 8)
聚合检索到的 KV blocks:
最终注意力计算:
其中 来自检索到的 KV Cache + question + 已生成 tokens。
位置编码策略:
- 编码阶段:RoPE 仅在局部窗口内应用(参考 LM-Infinite)
- 问答阶段:检索到的 tokens 视为连续序列,使用相对位置编码
3.5 代码映射表
注:GitHub 仓库 sou1p0wer/StreamKV 目前为占位仓库,代码尚未发布。以下为根据论文方法推测的代码模块映射。
| 论文组件 | 推测代码模块 | 功能描述 |
|---|---|---|
| Semantic Segment Partitioning | segmentation.py | 余弦相似度计算、语义边界检测、段合并 |
| Summary Vector | segmentation.py | 段内帧特征平均池化 |
| Segment-based Sliding-window Encoding | encoding.py | 滑动窗口注意力编码,生成 KV blocks |
| Representative Key Vector | kv_block.py | Patch-wise key 向量平均,得到帧级代表向量 |
| Unified Layer-Adaptive KV Selection | selection.py | Softmax 归一化、二分搜索全局阈值、按层分配预算 |
| KV Compression via Guidance Prompt | compression.py | Guidance prompt 编码、SelectKV 压缩、KV Bank 更新 |
| KV Retrieval | retrieval.py | Query vector 提取、SelectKV 检索、KV blocks 聚合 |
| Question Answering | qa.py | 拼接检索 KV Cache、RoPE 相对位置编码、注意力计算生成回答 |
| 基础模型集成 | model/llava_ov.py | LLaVA-OneVision-Qwen2-7B-OV 的修改与集成 |
3.6 总结与思考
核心贡献
- 语义分割 + Summary Vector: 打破了均匀分割的局限,按语义边界切分视频流,并通过 summary vector 保留段级全局信息,在高压缩率下优势尤为突出(↓90% 时提升 5.31 points vs uniform)
- Guidance Prompt 驱动的无 query 压缩: 创新性地解决了流式场景中”压缩时用户还没提问”的难题,通过预定义的语义引导 prompt 替代 query 指导 KV 选择
- 统一 Layer-Adaptive 选择模块: 用一个模块同时服务压缩和检索,通过二分搜索自适应分配跨层预算,比均匀分配始终更优
- Training-free: 不需要额外训练,即插即用
局限性与思考
- 依赖视觉编码器的特征质量: 语义分割基于 ViT 特征的余弦相似度,对编码器质量敏感
- Guidance Prompt 的通用性: 论文中 guidance prompt 是手工设计的(覆盖实体/事件/因果等),在特定领域(如医疗、工业)可能需要定制
- 仅在 StreamingBench 上评测: 缺乏在更多 benchmark(如 EgoSchema, MovieChat)上的验证
- 代码未开源: 无法验证实现细节和复现结果
- 与更新方法的对比: 论文仅与 ReKV 等 2025 年初的方法对比,未涉及同期或更新的流式视频理解工作
值得借鉴的设计
- 二分搜索分配预算的思路优雅且高效,可推广到其他需要跨维度分配有限资源的场景
- Guidance Prompt 替代 Query 的策略对所有需要在 query 到来前预处理的系统都有参考价值
- Summary Vector 免于压缩的设计简单有效,确保了即使极端压缩下仍有段级信息可用于检索
4. Experimental Setup (实验设置)
4.1 实验配置
| 项目 | 配置 |
|---|---|
| 基础模型 | LLaVA-OneVision-Qwen2-7B-OV |
| GPU | NVIDIA H20 (96G), FP16 |
| 视频采样率 | 0.5 FPS |
| 局部窗口大小 | 15K tokens |
| 分割阈值 | 0.99 |
| 最小段长度 | 4 帧 |
| 最大段长度 | 64 帧 |
| 检索帧数 | 8 帧 |
| 评测基准 | StreamingBench (18 subtasks, 3 categories) |
5. Experimental Results (实验结果)
5.1 主实验:StreamingBench 性能对比
Table 1: StreamingBench 完整结果
| 模型 | 类型 | Real-Time Avg | Omni-Source Avg | Contextual Avg | Overall |
|---|---|---|---|---|---|
| Gemini 1.5 Pro | 商用 | — | — | — | 67.1 |
| GPT-4o | 商用 | — | — | — | 60.2 |
| Claude 3.5 Sonnet | 商用 | — | — | — | 57.7 |
| Qwen2-VL-7B | 开源离线 | — | — | — | 54.1 |
| LLaVA-OV-7B | 开源离线 | — | — | — | 56.4 |
| Flash-VStream-7B | 流式 | — | — | — | 24.0 |
| VideoLLM-online-8B | 流式 | — | — | — | 32.5 |
| Dispider-7B | 流式 | — | — | — | 53.1 |
| ReKV-7B | 流式 | — | — | — | 53.5 |
| StreamKV-7B (↓60%) | 流式 | — | — | — | 58.9 |
| StreamKV-7B (↓80%) | 流式 | — | — | — | 57.4 |
| StreamKV-7B (↓90%) | 流式 | — | — | — | 56.7 |
关键发现:
- StreamKV (↓60%) 以 58.9 的 Overall 分数超越 ReKV +5.4 points,甚至超过 Claude 3.5 Sonnet (57.7)
- 即使在 90% 压缩率下(仅保留 10% KV Cache),StreamKV 仍达 56.7,超过 ReKV 全量存储的 53.5
- Clips Summarization (CS): StreamKV 87.7 vs ReKV 78.6 (+9.1)
- Anomaly Context Understanding (ACU): StreamKV 45.6 vs ReKV 31.2 (+14.4)
5.2 图 1 的整体比较结论

Figure 1 解读: 该图将 StreamKV 与 ReKV 在 StreamingBench 上的表现进行三维对比。左侧雷达图展示了 18 个子任务的准确率,StreamKV(红色)在大多数子任务上包围面积更大。右上角显示 GPU 显存使用量,StreamKV 在相同帧数下显存增长更缓慢(因为进行了 KV 压缩)。右下角展示首帧延迟,StreamKV(绿线)在长视频下延迟显著低于 ReKV(蓝线),证明检索更精准、需要的帧数更少。整体而言 StreamKV 在准确率 58.9 vs 53.5、显存和延迟三个维度全面超越 ReKV。
5.3 消融实验
Table 2: 语义分割 vs 均匀分割
| 压缩率 | Uniform | Semantic | 提升 |
|---|---|---|---|
| ↓0% | 60.49 | 61.20 | +0.71 |
| ↓60% | 56.33 | 58.89 | +2.56 |
| ↓80% | 53.02 | 57.43 | +4.41 |
| ↓90% | 51.41 | 56.72 | +5.31 |
结论:压缩率越高,语义分割的优势越明显(↓90% 时提升 5.31 points)。
Table 3: Summary Vector 的作用
| 压缩率 | w/o Summary | w/ Summary | 提升 |
|---|---|---|---|
| ↓0% | 60.52 | 61.20 | +0.68 |
| ↓60% | 56.21 | 58.89 | +2.68 |
| ↓90% | 53.85 | 56.72 | +2.87 |
结论:Summary Vector 保留了段级信息,在高压缩率下尤为关键。
Table 4: Layer-Adaptive vs Uniform 预算分配
| Compression | Retrieval | ↓60% | ↓80% | ↓90% |
|---|---|---|---|---|
| Uniform | Uniform | 57.83 | 56.74 | 55.91 |
| Adaptive | Uniform | 58.44 | 57.11 | 56.35 |
| Uniform | Adaptive | 58.36 | 57.06 | 56.42 |
| Adaptive | Adaptive | 58.89 | 57.43 | 56.72 |
结论:压缩和检索同时使用 Adaptive 策略效果最佳;单独对任一环节使用 Adaptive 也优于全 Uniform。
Figure 4: 检索帧数的影响

Figure 4 解读: 该图展示了检索帧数(横轴,4-64 帧)对准确率(纵轴)的影响。StreamKV(实线圆点)在 8 帧时达到最佳性能约 59%,之后随检索帧数增加性能反而下降(因为引入了不相关信息干扰)。ReKV(虚线方块)则相反,需要检索更多帧才能提升性能(因为检索精度低,需要更大召回量来覆盖相关信息)。这证明 StreamKV 的检索精度远高于 ReKV:仅用 8 帧即可精准定位最相关内容,而 ReKV 即使检索 64 帧也不及 StreamKV 的 8 帧效果。更少的检索帧还意味着更低的推理延迟。