RIVER: A Real-Time Interaction Benchmark for Video LLMs
Authors: Yansong Shi*, Qingsong Zhao*, Tianxiang Jiang*, Xiangyu Zeng, Yi Wang, Limin Wang† Affiliations: University of Science and Technology of China, Shanghai AI Laboratory, Fudan University, Nanjing University GitHub: OpenGVLab/RIVER Year: 2026
1. Motivation (研究动机)
在线视频交互评估的核心痛点
当前多模态大语言模型 (MLLM) 几乎全部在 离线范式 下运行 — 先看完整个视频, 再回答问题。然而真实应用 (AR 导航、机器人监控、实时对话) 要求模型在 流式视频 中与人类进行持续交互。这引出了三个核心能力需求:
- 长期记忆 (Long-term Memory): 追踪过去发生的视觉叙事, 即使事件发生在数十分钟之前
- 精确时序锚定 (Temporal Grounding): 对动态查询做出及时、准确的响应
- 前瞻推理 (Proactive Reasoning): 预判未来状态, 主动在合适时机给出答案
已有 Benchmark 的不足
| Benchmark | Videos | Questions | 时间粒度覆盖 | 主动响应 | 流式描述 |
|---|---|---|---|---|---|
| VStream-QA | 32 | 3,500 | 仅 General | No | No |
| StreamingBench | 900 | 4,500 | 仅 General | No | No |
| OV-Bench | 1,463 | 4,874 | 仅 General | No | No |
| OVO-Bench | 644 | 3,100 | 仅 General | Instant | No |
| RIVER (Ours) | 1,067 | 4,278 | Short/Med/Long/VeryLong | Instant | Stream |
现有 benchmark 共同的问题:
- 不量化记忆衰减: 无法测量模型随时间间隔增大而遗忘的程度 (forgetting curve)
- 不评估响应及时性: 仅看回答是否正确, 不关注回答是否在正确的时间窗口内给出
- 缺乏精细时间分段: 未按 short (15-30s) / medium (30-60s) / long (300-900s) / very long (1800-3600s) 分类评估

Figure 1 解读: 该图展示了 RIVER Bench 定义的四种在线交互任务类型。左上 Retro-Memory: 视频线索 (Cue ◆) 出现在过去, 查询 (Query ▶) 和回答 (Answer ●) 在当前时刻, 模型需回忆”视频开头有多少鸟?” 右上 Live-Perception: 线索与查询同时出现在当前窗口, 模型即时感知”草地是什么颜色?” 左下 Pro-Response Instant: 模型需等待未来线索出现后再回答”擦完锅我还做了什么?”, 考验预判与及时响应能力。右下 Pro-Response Streaming: 模型持续实时描述视频中正在发生的事件, 类似 dense video captioning。四种任务覆盖了过去 → 现在 → 未来的完整时间轴。
2. Idea (核心思想)
核心思路: 定义在线视频交互的完整评估体系
RIVER 的关键洞察: 一个有效的在线 MLLM (oMLLM) 必须同时具备 回顾记忆、实时感知、前瞻响应 三种能力, 而这三种能力需要在精确的时间维度上进行度量。
三大任务定义
设视频事件发生时间为 , 查询时间为 , 历史时间窗口起始为 :
| 任务 | 时间关系 | 核心考察 | 样本量 |
|---|---|---|---|
| Retro-Memory | (事件在过去) | 长期记忆保持能力 | ~1,500 MC QA |
| Live-Perception | (事件在当前窗口) | 实时多模态理解 | ~400 |
| Pro-Response Instant | (事件在未来) | 预判 + 及时触发 | ~1,400 |
| Pro-Response Streaming | 持续描述 | 实时叙述生成 | ~1,200 |
配套创新
- Long-Short Term Memory 模块: 通用的离线→在线适配方案, 使任意离线 MLLM 支持流式推理
- Response Accuracy Metric: 联合评估响应准确性与时间及时性
- 交互式训练数据集: 通过随机化查询时间戳 (非固定 0 秒), 提升泛化能力
3. Method (方法)
3.1 问题建模
将在线交互建模为 窗口式 video-text-to-text 任务:
其中:
- : oMLLM 参数化模型
- : 从 到 的流式视频帧
- : 用户查询
- : 历史建模 (长期记忆)
- : 此前已生成的响应
注意 中可以包含多个 EOS token, 模拟对话中的沉默或停顿。
3.4 Long-Short Term Memory 模块

Figure 4 解读: 该图展示了将离线 MLLM 改造为在线推理模型的完整 pipeline。底层: Vision Encoder 从 sliding window 中的当前帧提取特征, 分别存入 Short-Term Memory (当前窗口的帧 token) 和 Long-Term Memory (历史帧的压缩 token)。中层: LLM 接收长短期记忆拼接后的 visual embedding, 结合用户 Query (如 “Did I wash my hands just now?“) 进行推理。顶层: LLM Head 通过 Y/N 决策判断是否输出 (Silent 或 Output), 实现主动响应。Query 在任意时间 发出, 模型在每个时间窗口被查询, 直到决定回答。
核心设计:
- Short-term memory: 当前窗口的原始帧 token
- Long-term memory: M 个固定大小的 memory slot, 每个 slot 与 short-term memory token 数相同
- 压缩策略: 最近邻平均 (nearest-neighbor averaging)
- 存储上限: 16 帧特征存入长期记忆
def long_short_term_memory(video, model, question_text: str, options: list,
max_memory: int = 16) -> str:
"""Long-Short Term Memory for offline-to-online MLLM adaptation."""
# 1. Preprocessing and memory initialization
video = reshape_and_move_to_gpu(video)
long_embeddings: list = []
short_embeddings: list = []
# 2. Batch encoding
for batch in video_batches:
with torch.no_grad():
embeddings = model.encode(batch)
long_embeddings.append(embeddings)
short_embeddings.append(embeddings)
# 3. Memory update: merge most similar adjacent segments when over capacity
if len(long_embeddings) > max_memory:
similarities = calculate_similarities(long_embeddings)
while len(long_embeddings) > max_memory:
merge_most_similar_pairs(long_embeddings, similarities)
# 4. Combine long/short-term memory and generate response
final_embeddings = combine_embeddings(long_embeddings, short_embeddings)
question = format_question(question_text, options)
response = get_model_response(model, question, final_embeddings)
return response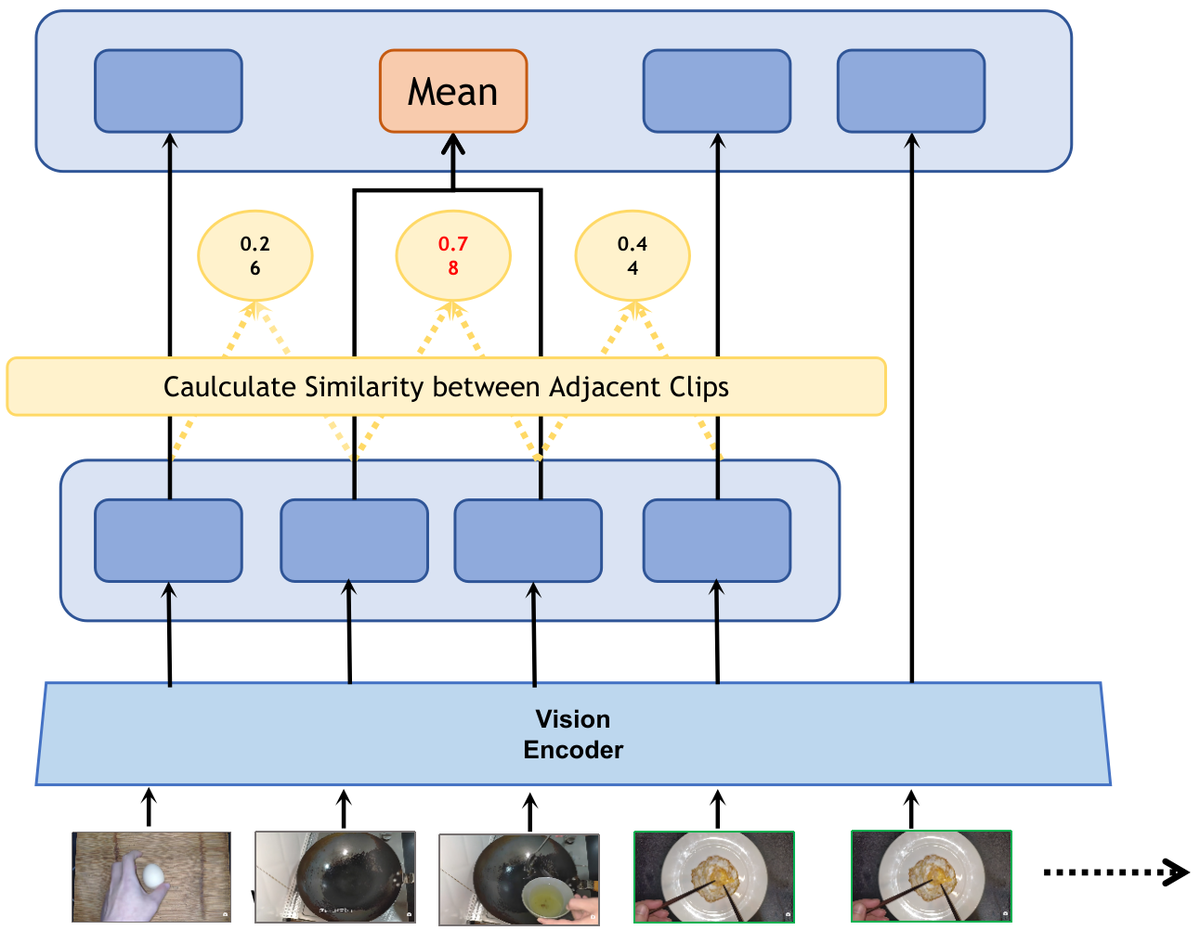
Figure 7 解读: 长期记忆的详细设计。视频帧经 Sliding Window 送入 Vision Encoder 编码, 得到每帧的 token 表示。多帧 token 经 Average Pooling 压缩后存入 long-term memory slots。当 slot 数量超出上限时, 计算相邻 slot 之间的 Cosine Similarity (图中标注 0.26, 0.78, 0.44), 将相似度最高的相邻对 (0.78) 合并 (avg pool), 从而保持 memory 容量恒定。这种策略让语义相近的片段被优先合并, 保留了时间跨度大的独特事件。
推理时的 Prompt 模板:
Prompt for Memory-Aware Inference:
──────────────────────────────────
"Carefully watch the video and pay attention to the cause and
sequence of events, the detail and movement of objects, and the
action and pose of persons. Based on your observations, select
the best option that accurately addresses the question.
This contains a long memory of 0.0 to {end} seconds.
<Long-Term Memory>
This contains a short clip sampled from {start} to {end} seconds.
<Short-Term Memory>
Question: <Question>"
4. Experimental Setup (实验设置)
4.1 数据构建流水线

Figure 3 解读: RIVER Bench 的数据处理流程分四个阶段: (1) Collection — 从 Vript-RR、LVBench、LongVideoBench、Ego4D、QVHighlights 五个数据集收集视频和原始标注 (dense caption & QA); (2) Filtering — 通过规则过滤 (去除含特定人名、过长视频段、过于笼统的问题) 和 LLM 过滤 (去除不需视觉即可回答的问题); (3) Generating Annotation — 生成包含 basic (路径/时长)、clue (事件时间)、question (时间/问题/选项)、answer (时间/GT) 的结构化标注; (4) Verification — 再次通过 LLM 验证标注质量。
三阶段质量控制:
def data_quality_control(raw_annotations: list, dense_annotations: list) -> list:
"""Three-stage quality control for RIVER benchmark data."""
# Stage 1: Rule-Based Filtering
filtered = []
for qa in raw_annotations:
if contains_personal_names(qa.question):
continue
if qa.video_segment_length > max_length:
continue
if is_overly_general(qa.question):
continue
if qa.action in ("standing", "walking", "looking"):
continue
if qa.action_repeat_count > max_repeats:
continue
filtered.append(qa)
# Stage 2: LLM-Based Filtering (remove language-prior solvable)
stage2 = []
for qa in filtered:
response = unimodal_llm.answer(qa.question) # no visual input
if response == qa.correct_answer:
continue # solvable by language prior alone
if answerable_with_few_frames(qa):
continue
stage2.append(qa)
# Stage 3: Semantic Curation
anchors = []
for event in dense_annotations:
embedding = sentence_encoder.encode(event)
similarity_matrix = compute_pairwise_similarity(all_embeddings)
key_event = select_most_distinctive(similarity_matrix)
anchors.append((key_event, event.precise_timestamp))
return stage2, anchors4.2 Benchmark 数据统计

Figure 2 (左) 解读: 饼图展示了 RIVER Bench 各任务的数据分布。Retro-Memory 占比最大 (42.9%), 分为 short/medium/long/very long 四个时间段; Live-Perception 占 13.6%; Proactive Anticipation 占 18.0%, 分为 instant 和 streaming 两个子类型。右侧两个柱状图分别展示了视频时长分布 (大部分集中在 0-2500s, 长尾分布至 17500s) 和查询时间比例分布 (在 0.0-1.0 之间较均匀, 0.8-1.0 略多)。词云图显示高频词包括 video、stage、appear、blue 等, 反映了问题内容的多样性。
4.3 评估指标
Retro-Memory & Live-Perception:
- MC (Multiple-Choice): 正则匹配提取选项, 计算准确率
- OE (Open-Ended): 使用 Qwen2.5-72B 评估响应与参考答案的一致性
Pro-Response: Response Accuracy Metric, 设 ground-truth 时间戳为 , 容忍窗口为 :
这个设计直觉: 早响应 = 误报 (严格惩罚为零), 迟响应 = 还有部分价值 (线性递减)。
4.4 在线模型训练
架构:
- Visual Encoder: SigLIP-Large-Patch16
- Projection: Two-layer MLP
- LLM Backbone: LLaMA3-8B
- Adaptation: LoRA (r=128, alpha=256)
关键训练参数 (Table 6):
| 参数 | 值 |
|---|---|
| Attention | flash_attention_2 |
| Learning Rate | 0.0002 (即 , 论文正文写 ) |
| Optimizer | AdamW (torch) |
| LR Scheduler | Cosine |
| Frame FPS | 4 |
| Frame Resolution | 384 |
| Max Frames | 1024 |
| LoRA r / alpha | 128 / 256 |
| Frame Token | CLS + 3x3 spatial pool |
| 每帧 Token 数 |
关键创新 — 随机化查询时间戳: 训练时不将用户查询固定在 0 秒位置, 而是随机采样查询时间, 显著提升模型在真实交互场景中的泛化能力。
5. Experimental Results (实验结果)
5.1 核心在线能力评估 (Table 2)

Figure (Supp) 解读: 补充图展示了离线模型通过 sliding window + long-short term memory 改造为在线推理的详细流程。原始离线模型一次性处理全部帧, 而改造后的在线版本按 1fps 滑动窗口逐步接收帧, 短期记忆保持当前窗口帧, 长期记忆存储历史压缩 token, 两者拼接后送入 LLM。
Retro-Memory 性能 (MC 准确率):
| 模型 | F | OE | MC | 特点 |
|---|---|---|---|---|
| GPT-4o | 50 | 39.09 | 59.56 | 闭源最强 |
| Gemini-1.5-pro | 50 | 24.24 | 36.35 | |
| VideoChat2 (adapted) | 1fps | 19.65 | 35.52 | |
| InternVL2.5 (adapted) | 1fps | 21.13 | 39.72 | |
| LLaVA-Video (adapted) | 1fps | 24.51 | 42.71 | |
| VideoChat-Flash (adapted) | 1fps | 25.68 | 45.75 | 开源最强 |
| Flash-VStream | 1fps | 10.43 | 27.28 | 原生在线最弱 |
Live-Perception 性能 (MC 准确率):
| 模型 | OE | MC |
|---|---|---|
| GPT-4o | 40.08 | 61.05 |
| InternVL2.5 (adapted) | 34.68 | 58.84 |
| VideoChat-Flash (adapted) | 33.60 | 56.35 |
| Flash-VStream | 12.43 | 29.28 |
Pro-Response 性能:
| 模型 | Instant Loc | Instant MC | Streaming OE |
|---|---|---|---|
| VideoChat-Flash (adapted) | 20.24 | 35.90 | 6.21 |
| VideoLLM-Online | — | 23.88 (Loc) | 4.41 |
| VideoLLM-Online + RIVER | 35.16 | 10.53 | 5.47 |
核心发现: 在 RIVER 数据上微调 VideoLLM-Online 后, Pro-Response Instant 的 Loc 从 23.88 → 35.16, 提升 11.28%, 验证了 RIVER 训练集的有效性。
5.2 记忆能力随时间衰减 (Table 4)
| 模型 | Short (15-30s) MC | Medium (30-60s) MC | Long (300-900s) MC | Very Long (1800-3600s) MC |
|---|---|---|---|---|
| GPT-4o | 63.26 | 63.26 | 58.01 | 52.21 |
| VideoChat-Flash (adapted) | 43.92 | 48.90 | 43.92 | 37.85 |
| LLaVA-Video (adapted) | 44.20 | 43.65 | 41.44 | 37.29 |
| Flash-VStream | 28.73 | 10.50 | 27.90 | 26.52 |
关键观察: 所有模型在 short → very long 都出现性能下降, GPT-4o 从 63.26% 降到 52.21% (下降 ~11%), 但 Flash-VStream 例外 — 虽然绝对性能低, 但跨时间段保持一致, 说明其 memory cache 机制有效抵抗了遗忘。
5.3 模型记忆曲线 (Figure 5)

Figure 5 解读: 该图展示了不同模型在不同回忆时间间隔 (0s → 3600s) 下的 MC 准确率变化曲线。蓝色三角线 (w/ memory) 代表配备 long-short term memory 的模型, 绿色菱形线 (w/o memory) 代表无记忆模块的基线, 橙色方形线 (video-agent) 代表 video agent 方法。核心发现: (1) 加入记忆模块后, 性能衰减斜率降低约 12%, 在 0-3600s 全程保持更高准确率; (2) 与经典 Ebbinghaus 遗忘曲线不同, 配备记忆模块的 MLLM 在 1 小时内展现出更优的记忆保持稳定性; (3) 无记忆的模型在 300s 后急剧下降, 而有记忆的模型衰减更为平缓。
5.4 不同视觉线索类型的性能 (Table 5)
| 模型 | FC (细粒度) MC | CC (因果) MC | BC (背景) MC |
|---|---|---|---|
| LLaVA-Video (16F) | 53.16 | 38.25 | 47.04 |
| InternVL2.5 (16F) | 48.74 | 37.36 | 46.23 |
| VideoChat-Flash (adapted) | 50.39 | 40.92 | 54.10 |
关键发现: 所有模型在 Causal Cues (CC) 上表现最差, 表明因果推理 (事件动态、时序依赖) 是当前 Video LLM 的最大短板。改造后的 VideoChat-Flash 在 CC 和 BC 上都有提升, 说明 memory 模块有助于保留因果链信息。
5.5 Pro-Response 训练效果 (Table 3)
| 模型 | F | Instant Loc | Instant MC | Streaming OE |
|---|---|---|---|---|
| Flash-VStream | 1fps | — | — | 1.31 |
| VideoLLM-Online | 2fps | 23.88 | 6.67 | 4.41 |
| VideoLLM-Online + RIVER | 2fps | 33.28 | 9.84 | 5.03 |
| VideoLLM-Online + RIVER (4fps) | 4fps | 35.16 | 10.53 | 5.47 |
RIVER 训练数据带来了全面提升, 尤其是 Instant Loc 从 23.88% → 35.16%, 说明交互式训练数据对模型的时间锚定能力至关重要。
6. Limitations & Future Work
当前局限
- 缺乏音频模态: RIVER 仅评估视觉通道, 而真实在线交互中音频是重要信息源
- 离线评估方法: 当前评估仍是事后分析, 未做真正的 real-time deployment 评测
- Pro-Response 评估的单一性: 当前的 Response Accuracy Metric 对早回答一律零分可能过于严格
未来方向
- 集成音频数据, 构建多模态在线交互 benchmark
- 开发 real-time deployment 评估框架
- 扩展到更长视频时长 (> 1 小时)
- 探索多轮交互场景
Code Mapping (代码与论文对应)
| 论文内容 | GitHub 路径 (推测) | 说明 |
|---|---|---|
| Benchmark 标注 | annotations/ | 4,278 条结构化 QA 标注 |
| 数据过滤脚本 | 待发布 | Rule-based + LLM-based filtering |
| Long-Short Term Memory | 待发布 | 通用离线→在线适配模块 |
| 评估脚本 | 待发布 | MC/OE/Response Accuracy Metric |
| 训练数据 | HuggingFace | 交互式训练集 |
数据格式示例 (来自 Appendix B):
{
"video_source": "LVBench",
"video_id": "Cm73ma6Ibcs",
"duration_sec": 3665.5,
"fps": 24,
"question_id": "Cm73ma6Ibcs@1",
"question": "What year appears in the opening caption of the video?",
"choices": ["(A) 1636", "(B) 1366", "(C) 1363", "(D) 1633"],
"correct_answer": "D",
"time_reference": [15, 19],
"question_type": "Recalling@short",
"question_time": 64.756,
"video_path": "00000000.mp4"
}
Figure 6 解读: 数据过滤的详细流程。左侧为 Rule-based 过滤: 对 Normal QA 数据集去除含特定人名、对应过长视频段、过于笼统的问题; 对 Dense Annotation 数据集去除太通用的动作 (如 standing, walking, looking around)、重复过多的动作、定义过于宽泛的活动。右侧为 LLM-based 过滤: 对 Normal QA 去除单模态模型可解和少量帧即可回答的问题; 对 Dense Annotation 则先选出特殊活动作为锚点生成预测前/后动作的 QA, 再同样过滤掉单模态可解的问题。

Figure (词云) 解读: 词云展示了 RIVER Bench 中问题和标注文本的高频词分布。突出的词汇包括 “video”、“color”、“black”、“first”、“stage”、“appear”、“blue”、“woman”、“man”、“vlogger”、“girl” 等, 反映了 benchmark 中问题内容的多样性, 涵盖视觉属性 (颜色、外观)、人物描述、场景和事件等维度。

Figure (Memory 详细架构) 解读: Long-Short Term Memory 的完整架构图。展示了 memory slot 的组织方式: 每个 slot 包含与 short-term memory 相同数量的 token, 当 long-term memory 超出 M 个 slot 时, 通过计算相邻 slot 的 cosine similarity 并合并最相似的 pair 来维持固定容量。这确保了语义独特的事件得到保留, 而冗余的相似片段被合并压缩。

Figure (查询时间分布) 解读: 展示了 RIVER Bench 中查询时间在视频时长中的位置分布。查询时间比例 (question_time / duration) 在 0.0-1.0 之间分布较均匀, 在视频后半段 (0.8-1.0) 略有集中, 这保证了 benchmark 能全面评估模型在视频不同阶段的交互能力。

Figure (视频时长分布) 解读: 展示了 RIVER Bench 中视频时长的分布。大部分视频集中在 0-2500 秒 (约 42 分钟), 有少量长尾分布至 17500 秒 (约 5 小时)。这种分布覆盖了从短视频到超长视频的广泛范围, 使得 benchmark 能在不同时间尺度上评估模型的在线交互能力。