Is Your Video Language Model a Reliable Judge?
Authors: Ming Liu, Wensheng Zhang Affiliations: Iowa State University Year: 2025 Code: 未公开
1. Motivation (研究动机)
1.1 背景
随着视频语言模型 (VLM) 在视频理解任务中的广泛应用,如何可靠、可扩展地评估 VLM 性能成为关键问题。传统人工评估存在一致性差、成本高、不可扩展的问题,因此学界开始探索用 VLM 评估 VLM (VLM-as-Judge) 的自动化方法。
1.2 核心问题
本文提出三个研究问题:
- 当前 VLM 作为评估者是否可靠? 弱模型能否评估强模型?
- 集体智慧 (Collective Thought) 能否提升评估可靠性? 聚合多个 VLM 的评估是否比单一模型更好?
- 集体智慧方法的局限性是什么? 如何改进?
1.3 核心发现
- 弱 VLM 系统性地高估候选模型表现:Video-LLaVA 几乎给所有候选模型打出接近 4.0 的分数
- 集体智慧并不一定有效:混合可靠与不可靠评委的集体评估,结果反而比单独使用 GPT-4o 更差
- 仅提升理解能力不足以提升评估可靠性:微调 Video-LLaVA 后,评分分布仍偏高,Kappa 值仅略微改善
Figure 1 解读:对比单一 VLM Judge 与多 LLM Agent-Debate(参考答案引导)的评估结果。对同一视频问答对,VLM Judge 给出评分 5(高度乐观),而基于参考答案的 LLM Agent Debate 给出评分 1(严格评估)。这种显著不一致性揭示了 VLM 作为评估者的不可靠性问题,是本文的核心动机。
2. Idea (核心思想)
本文的核心思想是:不要默认任何 VLM Judge 都可靠,而是显式建模评委质量,并比较单评委、集体评委和参考基准之间的一致性。
2.1 研究框架概览
作者将评估流程拆成三个阶段:
- 先让多个 VLM candidates 对视频问答任务作答
- 再让多个 VLM judges 独立评分,同时用 LLM Agent-Debate 构造参考评审
- 最后尝试用 Collective Thought 或 Mixture of Judges 聚合多个评审
2.2 核心假设
- 如果 VLM 真能当评委,那么它的评分应与更强的参考评审保持一致
- 如果某些评委更可靠,那么应当能通过选择或加权提升整体一致性
- 若聚合后性能下降,说明简单集成不能自动消除弱评委噪声
3. Method (方法)
3.1 整体框架:三阶段评估流程
本文提出一个三阶段多模型评估框架:
┌─────────────────────────────────────────────────────────────────┐
│ Phase 1: VLM Candidates 生成回答 │
│ (v, t) → M_j → r_{i,j} │
│ 数据集: CVRR-ES (2400 QA pairs, 11 visual dimensions) │
├─────────────────────────────────────────────────────────────────┤
│ Phase 2: Individual VLM Judge 独立评审 │
│ M^J = {M^J_1, ..., M^J_q} → R = {R_1, R_2, ..., R_q} │
│ 同时: LLM Agent-Debate 生成参考评审 (Ground Truth) │
├─────────────────────────────────────────────────────────────────┤
│ Phase 3: Collective Thought 集体评估 │
│ A = M^J_a(r_{i,j}, R_1, R_2, ..., R_q) │
│ 高级模型 (GPT-4o) 综合所有评审给出最终评分 │
│ + Reliability Selection Gate (可选 Mixture of Judges) │
└─────────────────────────────────────────────────────────────────┘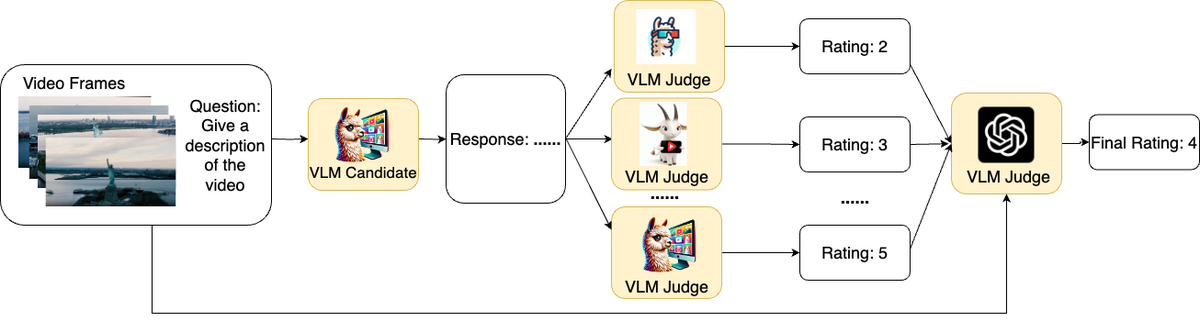
Figure 2 解读:展示了完整的多阶段评估流程。左侧为 VLM Candidate 生成回答,中间多个 VLM Judge 各自独立给出评分和可靠性分数 (Reliability Score),经过 Reliability Selection Gate 筛选后,右侧高级 VLM Judge 综合所有通过筛选的评审给出最终评分。这是本文提出的集体智慧评估范式的核心架构。
3.2 评估指标:Weighted Cohen’s Kappa
用于衡量 VLM Judge 与 LLM Agent-Debate 之间的评分一致性:
其中:
- : Judge 1 给出评分 、Judge 2 给出评分 的观测频率
- : 独立评分假设下的期望频率
- : 不一致权重,采用二次加权方案:
其中 (评分范围 1-5)。
Kappa 值解读标准:
| Kappa 范围 | 含义 |
|---|---|
| < 0 | 无一致性 |
| 0 - 0.20 | 轻微一致 |
| 0.21 - 0.40 | 一般一致 |
| 0.41 - 0.60 | 中等一致 |
| 0.61 - 0.80 | 显著一致 |
| 0.81 - 1.00 | 几乎完全一致 |
3.3 Mixture of Judges 策略
基于每个 visual dimension 的 Kappa 值动态选择可靠评委:
阈值法:选择 Kappa 超过阈值 的模型子集:
Top-K 法:选择每个维度上 Kappa 最高的 K 个模型:
3.4 LLM Agent-Debate (参考基准)
作为”准 Ground Truth”的生成方式:
- 使用 GPT-3.5 和 GPT-4o(文本输入模式,无视觉输入)
- 同时提供 VLM 候选回答和 CVRR-ES 参考答案
- 多轮讨论和辩论后,由另一 LLM agent 汇总形成共识评分
3.5 伪代码
# ============================================================
# VLM-as-Judge Evaluation Framework
# ============================================================
def phase1_generate_responses(dataset, candidates):
"""Phase 1: VLM Candidates 生成回答"""
responses = {}
for (video, question) in dataset: # D = {(v1,t1), ..., (vn,tn)}
for model in candidates: # M = {M1, ..., Mm}
responses[(video, question, model)] = model.generate(video, question)
return responses # r_{i,j}
def phase2_individual_review(responses, judges, agent_debate):
"""Phase 2: Individual VLM Judge 评审 + Agent-Debate 基准"""
reviews = {}
debate_reviews = {}
for (video, question, candidate), response in responses.items():
# VLM Judge 评审
for judge in judges: # M^J = {M^J_1, ..., M^J_q}
reviews[(video, question, candidate, judge)] = judge.review(
video, question, response, rating_scale=(1, 5)
)
# LLM Agent-Debate 评审 (参考引导)
reference = dataset.get_reference(video, question)
debate_reviews[(video, question, candidate)] = agent_debate.debate(
question, response, reference # 多轮讨论达成共识
)
return reviews, debate_reviews
def compute_weighted_kappa(judge_ratings, debate_ratings, k=5):
"""计算 Weighted Cohen's Kappa"""
# 构建混淆矩阵 O_{alpha,beta}
O = confusion_matrix(judge_ratings, debate_ratings)
# 计算期望频率 E_{alpha,beta}
E = expected_frequencies(judge_ratings, debate_ratings)
# 二次加权
w = [[1 - ((a - b) / (k - 1))**2 for b in range(k)] for a in range(k)]
kappa = 1 - sum(w[a][b] * O[a][b]) / sum(w[a][b] * E[a][b])
return kappa
def phase3_collective_thought(responses, reviews, advanced_judge):
"""Phase 3: 集体评估"""
final_ratings = {}
for (video, question, candidate), response in responses.items():
all_reviews = [reviews[(video, question, candidate, j)] for j in judges]
# 高级模型综合所有评审
final_ratings[(video, question, candidate)] = advanced_judge.aggregate(
video, question, response, all_reviews
)
return final_ratings
def mixture_of_judges(reviews, debate_reviews, visual_dimensions, theta):
"""Mixture of Judges: 基于可靠性动态选择"""
selected = {}
for dim in visual_dimensions:
for judge in judges:
kappa = compute_weighted_kappa(
reviews[dim][judge], debate_reviews[dim]
)
if kappa >= theta: # M^{J'} = {M^J_e | kappa_{d,e} >= theta}
selected.setdefault(dim, []).append(judge)
return selected3.6 代码映射表
本文未公开代码。以下为方法到潜在实现的映射:
| 论文组件 | 潜在实现 | 说明 |
|---|---|---|
| CVRR-ES 数据集 | CVRR-ES (Khattak et al.) | 2400 QA pairs, 11 visual dimensions, 217 videos |
| Video-LLaVA | Video-LLaVA | 开源候选/评委模型 |
| LLaMA-VID | LLaMA-VID | 开源候选/评委模型 |
| InternVL2 | InternVL2 | 开源评委模型 |
| GPT-4o / GPT-4o mini | OpenAI API | 闭源,最终评委和高级模型 |
| GPT-3.5 | OpenAI API | Agent-Debate 中的辩论 agent |
| mPLUG-Owl-Video | mPLUG-Owl | 开源候选模型 |
| Video-ChatGPT | Video-ChatGPT | 开源候选模型 |
| Weighted Cohen’s Kappa | sklearn.metrics.cohen_kappa_score(weights='quadratic') | 核心评估指标 |
| VideoChatGPT 数据集 | HuggingFace | 扩展验证数据集 |
4. Experimental Setup (实验设置)
4.1 模型配置
| 角色 | 模型 |
|---|---|
| Candidates (被评估) | Video-LLaVA, LLaMA-VID, GPT-4o mini, Video-ChatGPT, mPLUG-Owl-Video |
| Judges (VLM) | Video-LLaVA, LLaMA-VID, GPT-4o mini, InternVL2, GPT-4o |
| Judges (LLM) | GPT-3.5 (Agent-Debate), GPT-4o (text-only) |
| Final Judge | GPT-4o |
数据集:CVRR-ES — 2,400 个高质量 QA 对,来自 217 个视频,平均时长 22.3 秒,覆盖 11 个 visual dimensions(Multi Actions, Fine Action, Partial Actions, Time Order, Non-exist(E), Non-exist(NE), Cont.&Obj., Unusual Activities, Social Context, Emotional Context, Visual Context)。
4.2 扩展验证数据集
作者还在 VideoChatGPT 数据集(1,000 样本)上做了验证,用于检验结论是否能迁移到其他视频问答数据分布。
5. Experimental Results (实验结果)
5.1 个体 VLM Judge 评分分析
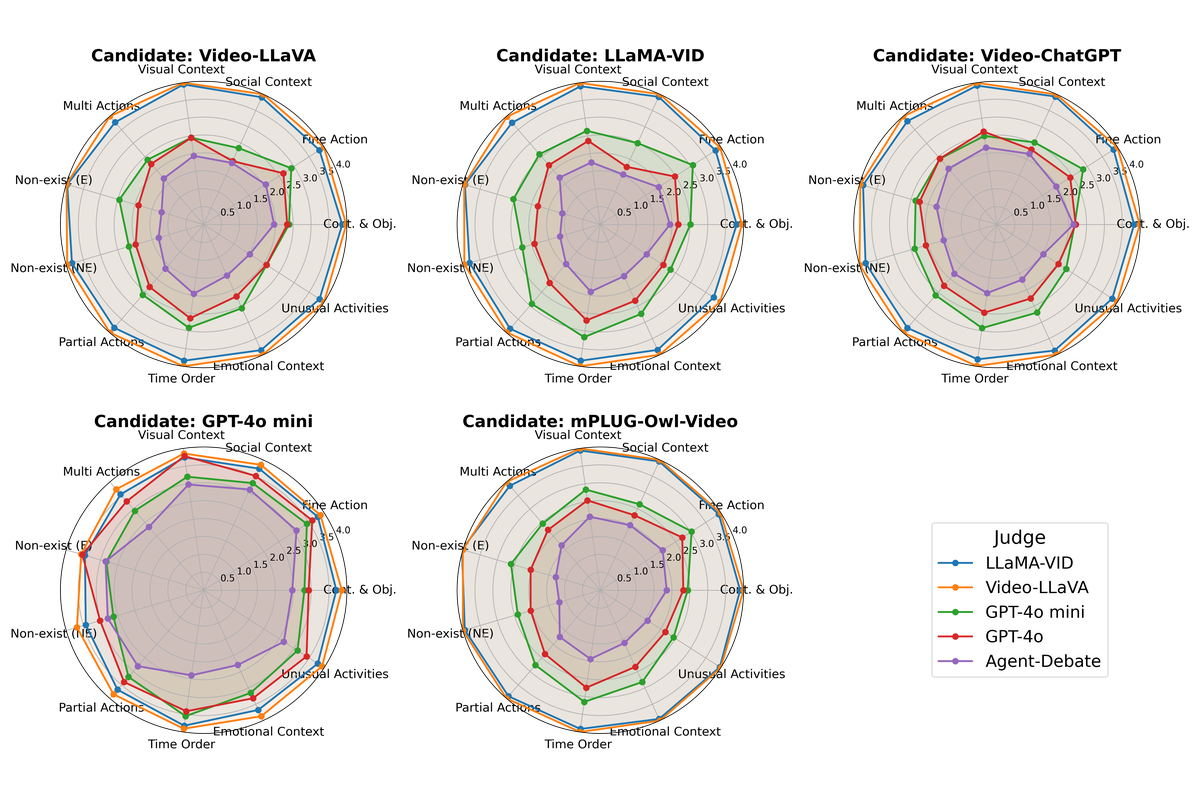
Figure 3 解读:雷达图展示了不同 Judge 对不同 Candidate 在 11 个 visual dimensions 上的评分。关键发现:(1) Video-LLaVA 和 LLaMA-VID 作为 Judge 时几乎在所有维度给出接近 4.0 的高分,存在明显的”评分膨胀”;(2) GPT-4o 和 Agent-Debate 的评分模式最为相似,均倾向给出更严格、更有区分度的评分;(3) Non-exist(E) 和 Non-exist(NE) 维度在所有 Judge 下一致偏低,说明候选模型普遍难以处理不存在实体的推理。
5.2 VLM Judge 与 Agent-Debate 的一致性
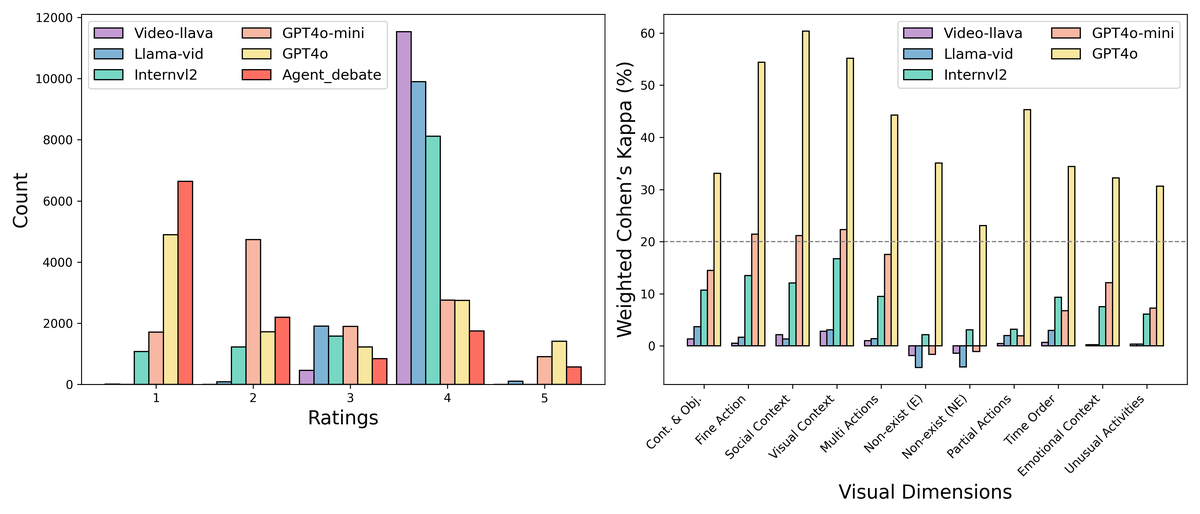
Figure 4 解读:左图为各 Judge 的评分分布统计——Video-LLaVA 和 LLaMA-VID 的评分集中在 4 分,GPT-4o 和 Agent-Debate 分布更均匀。右图为各 VLM Judge 在不同 visual dimensions 上与 Agent-Debate 的 Weighted Cohen’s Kappa 值。GPT-4o 在所有维度上一致性最高(平均 Kappa 约 44.42%),Video-LLaVA 和 LLaMA-VID 的 Kappa 值接近 0 甚至为负,表明它们作为 Judge 几乎不可靠。
关键数值 (Table 5 - Agreement Scores):
| Judge | Average Kappa (%) |
|---|---|
| Video-LLaVA | 1.35 |
| LLaMA-VID | 3.70 |
| GPT-4o mini | 14.50 |
| InternVL2 | 10.69 |
| GPT-4o | 33.11 - 55.18 (跨维度), 平均 44.42 |
GPT-4o 在 Social Context 维度上达到最高一致性 60.38%,在 Visual Context 维度达 55.18%。
5.3 集体智慧评估结果
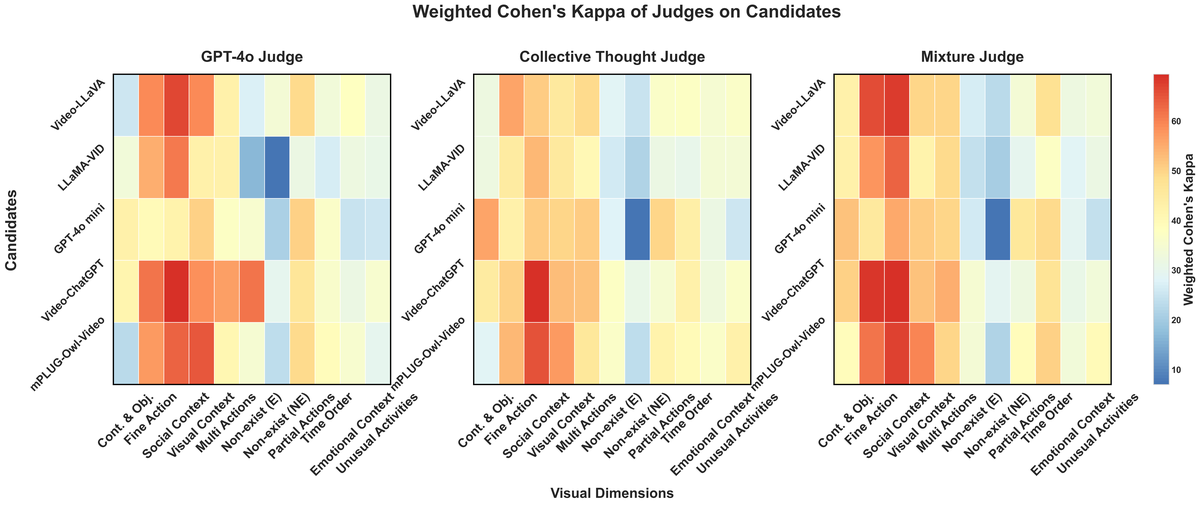
Figure 5 解读:三张热力图分别展示 GPT-4o 单独作为 Judge(左)、Collective Thought Judge(中)、Mixture Judge(右)与 Agent-Debate 的 Weighted Cohen’s Kappa。颜色越亮表示一致性越高。关键发现:GPT-4o 单独评估(左图)整体颜色最亮,而集体评估(中图)和 Mixture 评估(右图)反而颜色变暗。这直观证明了混入不可靠 Judge 会拉低整体评估质量。
核心数值对比 (Table 6 & 7):
| 方法 | 平均 Kappa (%) |
|---|---|
| GPT-4o 单独 | 30.65 (across all candidates avg) |
| Collective Thought (全部 Judge) | 21.61 |
| Mixture of Judges | 33.13 |
- Collective Thought 的维度级 Kappa 范围:2.72% ~ 42.53%
- Mixture of Judges 的维度级 Kappa 范围:2.72% ~ 60.70%
- 即便 Mixture 方法挑选了最可靠的 Judge,整体仍未超过 GPT-4o 单独评估
5.4 Weak-to-Strong 评估问题
Table 5 揭示了显著的弱评强问题:
- Video-LLaVA 评估 GPT-4o mini 时:Kappa 仅 5.34%(Fine Action 维度甚至 -8.05%)
- LLaMA-VID 评估 GPT-4o mini 时:Kappa 10.62%,部分维度达 -17.09%
- 弱模型缺乏理解强模型回答的能力,导致评估结果不可靠
5.5 微调消融实验
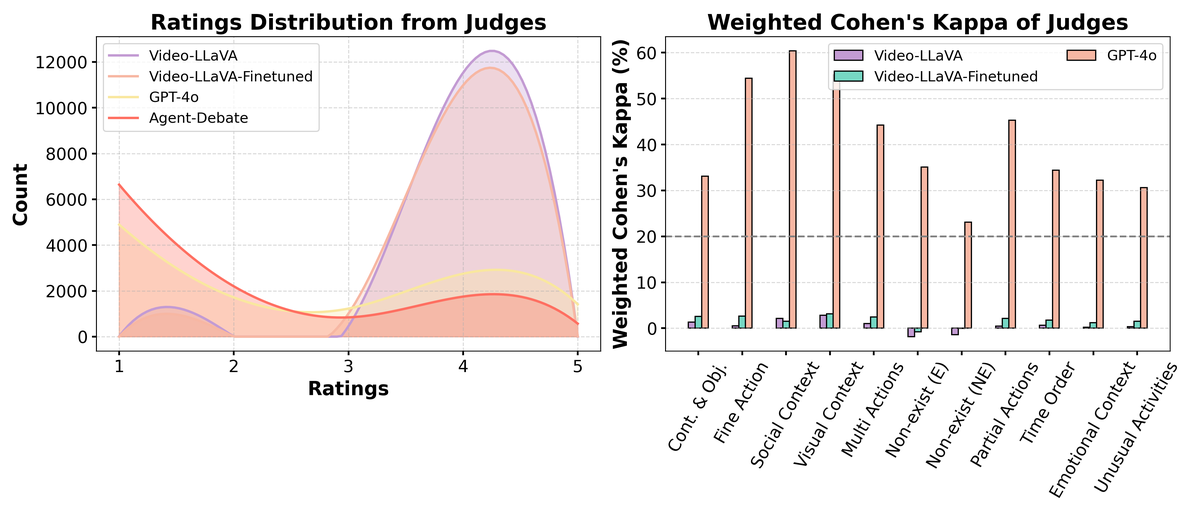
Figure 7 解读:左图对比了 Video-LLaVA 微调前后的评分分布——微调后评分分布依然偏向高分(集中在 4 分),与 GPT-4o 和 Agent-Debate 的均匀分布差距明显。右图对比微调前后的 Kappa 值——微调后 Kappa 仅有微小提升,远未达到 GPT-4o 的水平。结论:仅提升模型理解能力不足以使其成为可靠评估者,还需要专门的评估技能和批判性分析能力。
5.6 VideoChatGPT 数据集扩展验证
在 VideoChatGPT 数据集(1,000 样本)上的验证实验:
| Judge | Average Kappa (%) |
|---|---|
| Video-LLaVA | 1.72 |
| InternVL2 | 25.66 |
| GPT-4o | 44.42 |
结论与 CVRR-ES 一致:弱 VLM 系统性高估,GPT-4o 最可靠。
5.7 结果总结与启示
- GPT-4o 是目前唯一展现显著评估可靠性的 VLM(Kappa ~44%),但仍远未达到”几乎完全一致”的水平
- 简单的集体投票/聚合策略不适用于 VLM 评估,因为不可靠模型引入的噪声会淹没可靠模型的信号
- Weak-to-Strong 评估问题:弱模型无法可靠评估强模型,这与 weak-to-strong generalization 的研究一致
- 未来方向:需要开发能感知个体模型可靠性的加权聚合方法,以及迭代式多轮讨论的集体思考范式
5.8 对 RL for Visual Generation 的潜在意义
- 如果用 VLM 作为 reward model 为视频生成提供 RL 反馈,其评估不可靠性会直接导致reward hacking
- 需要谨慎选择评估模型,GPT-4o 级别模型可能是当前唯一可行的选择
- Agent-Debate 方式虽更可靠但需要参考答案,在生成式任务中获取参考答案本身就是挑战